
GPTsでデータベースを管理しよう③:リレーショナルデータベースとは?

前回までの記事で、データベースの基本概念とGPTsでデータベースを管理する方法について学びましたね。今回は、もう一歩踏み込んで、RDB(Relational Database)について解説していきます。
この記事で目指す目標は、あなたがプログラマーになることではなく
AIやノーコードツールなどを活用し
「作りたいものを作れる能力」
を養うこと
です。そのためにおいてRDBの仕組みの理解は必須知識となりますので、慣れるまで少し難しいかもしれませんが頑張ってみてください。
ちなみにChatGPTのGPTsに組み込むのは少し難易度は高いかも知れません。また、今回わかりやすく説明するためにGoogleスプレッドシートでお見せしていますが、実際にGoogleスプレッドシートでデータベースを構築することはあまりおすすめはしません。処理が複雑になるほど、実行が遅くなりますし、GASのコーディングが複雑になります。
👇全部読めば、データベースの仕組みやGASの仕組みも理解できます
リレーショナルデータベースとは?
今まで学んだスプレッドシートのデータは、シートが1枚の単純なものでした。しかし複数のシートにデータが跨っているような複雑なデータベースを構築するためには、新たな仕組みを理解する必要があります。
そう、リレーショナルデータベース(RDB)とは、複数のシートの情報を関連付けさせ、より複雑なシステムを作るためのシステムなんです。
このRDBは、多くのデータベースで用いられているシステムですので、仕組みを理解することでGPTsだけでなく、様々な応用に役立つことと思います。
RDBの関連付け
それでは、RDBの仕組みを理解するために例題として複数のシートが必要となるパターンをいくつか考えてみたいと思います。GPTsの例で考える前に、まずは一般的なアプリで考えてみましょう。その一般的なアプリがGPTsに置き換わることでボタンのタップ操作から会話での操作に切り替わるようなイメージが分かりやすいと思います。
例:図書館の本の貸し出しを管理するアプリ
例えば図書館の本の貸し出しを管理するアプリがあったとします。
スプレッドシートには、どのような項目と管理が必要でしょうか。
こういったイメージを考えることは慣れないうちは難しいので訓練がある程度必要になってきます。
例えば、こんな項目を考えてみました。
本の貸出アプリで管理する項目:
会員番号(会員ID)
本を借りる人の名前(会員名)
会員のメールアドレス
本の管理番号(本ID)
借りる本のタイトル
本の著者
本の出版社
貸した日時
返した日時
貸出状態(貸出可または貸出中を分かるようにしたい)
とりあえず、こんなところでしょうか。他にも実際には借りる人の住所や電話番号、本の発行日や購入日、返却予定日など様々な項目があるかと思いますが、例題なのでこのぐらいにしておきます。
では、これをスプレッドシートにどのように表記すれば管理しやすいですか。
考えてみてください。実は、この場合「会員情報」のテーブルと「本」のテーブル、そしてその会員と本をつなげる「貸出管理」のテーブルという、3つのテーブル(シート)を作ると管理ができます。
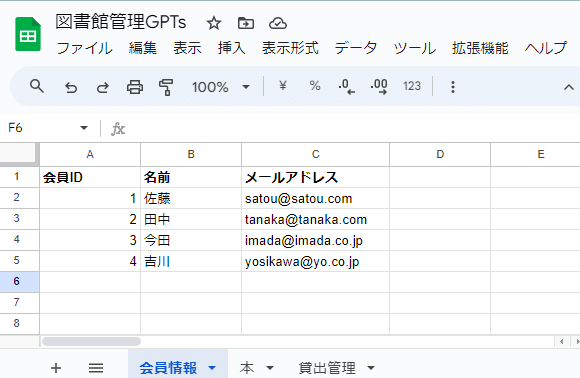


3つのテーブルを比較する
貸出管理テーブルでは、「会員ID」によって本を貸した会員が分かり、「本ID」によってどの本を貸したのかが分かります。これをみれば、会員IDの1の佐藤さんは、ワンピースの1巻と2巻を10月10日に借りていて、どちらも10月12日に返却していることが理解できるでしょう。また、田中さんは、3巻を、今田さんは4巻を借りていてまだ返却は済んでいないことなども表から読み取れますので、じっくり確認してみてください。
貸出テーブルでは、どこにも田中さんや今田さんといった名前は書かれていません。また、ワンピース何巻を借りているかも書いてはいません。しかしIDから他のテーブルを参照することでそれが田中さんであったり田中さんのメールアドレスや、ワンピース何巻を借りているかなどが判別できるということです。
ユニークIDの重要性
このように、関連付けを行う上で、非常に重要な役割を果たすのが「ユニークID」です。ユニークIDとは、各レコード(行)を一意に識別するための値のことです。多くの場合、自動的に増加する整数値(オートインクリメント)が使用されます。
一意性: 各顧客に対して唯一無二の値が割り当てられます。これにより、同姓同名の顧客がいても混同することなく識別できます。
不変性: 顧客の名前や連絡先が変更されても、IDは変わりません。これにより、データの一貫性が保たれます。
効率的な関連付け: 他のテーブルとの関連付けに使用されます。先ほどの例では、会員情報(会員ID)と本情報(本ID)を参照する際に使用されています。
つまり、メールアドレスや電話番号も1人に1つの固有のものではありますが、それをIDとして設定してしまうとメールアドレスや電話番号を変更したときにアカウントと紐づけられなくなるためIDには不向きということです。IDは変更のない普遍的であることが何よりも重要な要素です。
リレーショナルデータベースのメリット
データの一貫性: 関連付けられたテーブルを使うことで、データの重複を減らし、一貫性を保つことができます。
柔軟な検索: 複数のテーブルを組み合わせて、複雑な検索や分析が可能です。
データの整合性: ルールを設定することで、誤ったデータの入力を防ぐことができます。
セキュリティ: データへのアクセス権限を細かく設定できます。
テーブル間の関係性
先ほどは、3つのテーブル(シート)を使っていました。実はテーブル間の関係性は、大きく分けて3つのタイプがあります。これらの関係性を理解することで、より効果的なデータベース設計が可能になります。
1対1(One-to-One)関係
1対1の関係は、一方のテーブルのレコードが、他方のテーブルの1つのレコードにのみ対応する関係です。
例:「会員情報」テーブルと「図書カード」テーブル

この例では、1人の会員が1枚の図書カードを持ち、1枚の図書カードは1人の会員にのみ属しています。この関係性は以下のような場合に使用されます:
各会員に一意の図書カードを発行する
図書カードの情報を会員情報と分離して管理したい
図書カードのデータにアクセス制限を設けたい場合
1対1の関係を使用することで、セキュリティの強化やデータの論理的な分離が可能になります。例えば、図書カードの詳細情報へのアクセスを制限しつつ、一般的な会員情報には広くアクセスできるようにするといった設計が可能です。
また、1対1の場合はテーブルを分離しないで1つのシートで管理することも可能です。

今回は、分離してシートを分けていきたいと思います。
1対多(One-to-Many)関係
1対多の関係は、一方のテーブルの1つのレコードが、他方のテーブルの複数のレコードに対応する関係です。
例:会員情報と会員種別


この例では、1つの会員種別(例:一般会員や特別会員)に多数の会員が属することができます。しかし、各会員は1つの会員種別にのみ属します。
この関係性により、以下のようなメリットが得られます:
効率的なデータ管理: 会員種別の情報を一箇所で管理できるため、種別の追加や変更が容易です。
データの一貫性: 全ての会員が有効な会員種別に属していることを保証できます。
柔軟なクエリ: 特定の会員種別に属する全会員を簡単に取得したり、各会員種別の会員数を集計したりすることが容易になります。
多対多(Many-to-Many)関係
多対多の関係は、一方のテーブルの複数のレコードが、他方のテーブルの複数のレコードに対応する関係です。この関係は通常、中間テーブルを使用して表現します。
例:「会員」テーブルと「本」テーブル、そしてそれらを関連付ける「貸出」テーブル(貸出テーブルが中間テーブルとなります。)
この例では、1人の会員が複数の本を借りることができ、1冊の本も複数の会員によって(異なる時期に)借りられることができます。「貸出」テーブルが中間テーブルとなり、会員と本の貸出関係を管理しています。
この関係性により、以下のようなメリットが得られます:
柔軟な貸出管理: 1人の会員が複数の本を借りることも、1冊の本が(異なる時期に)複数の会員に借りられることも表現できます。
履歴の保持: 貸出の履歴を保持することで、過去の貸出状況の分析や、延滞管理などが可能になります。
効率的なクエリ: 特定の会員が借りている本のリストや、特定の本を借りたことのある会員のリストなど、複雑な情報の取得が容易になります。
このように、多対多の関係を使うことで、複雑な関係性を持つデータを効率的に管理し、必要な情報を柔軟に取得することが可能になります。
RDBの関係性理解度チェック
RDBの1対1の関係、1対多の関係、多対多の関係は理解できたでしょうか。慣れるまでは少し難しい概念だと思います。
しかし、ご自身のアイデアを形にするためにはこの関係性を理解してスプレッドシートを作る必要があります。
そこで、少し問題を出してみますので答えを見ないでご自身で考えてみてください。答えはこの記事の1番下にありますので、ご自身で答えを考えてから見てくださいね。
問題
noteプラットフォームが仮にRDBの仕組みでデータベースが構築されていたと仮定したとき、次の関係はどれに該当しますか。
A~Cで答えてください。
A:1対1関係
B:1対多関係 または 多対1関係
C:多対多関係
(1)アカウントとそのアカウントのプロフィール情報の関係
(2)アカウントとそのアカウントの作成した記事の関係
(3)アカウントとフォローの関係
(4)アカウントとフォロワーの関係
(5)記事とスキの関係
(6)アカウントとバッジの関係
(7)アカウントとマガジン作成の関係
(8)アカウントとマガジンフォローの関係
RDBの仕組みを理解してノーコードアプリを作るなら
adaloかclickというアプリを使うのがお薦めです。
どちらもRDBの仕組みを理解していれば簡単にアプリが作成できるようになります。
特徴としてはadaloはアメリカのサービスなので日本語対応していません。英語が苦手な人は、翻訳をして使うことが必要になります。(日本語でもアプリ作成はできますが、やや不便)。しかし、無料でたくさんのアプリを作成することが可能です。
clickは日本で作られたノーコード作成サービスなので日本語対応だけでなくサポートも日本語で対応されています。ただし、無料ではレコード登録ができないため作成したアプリを使うには有料契約をした方がよいでしょう。
遊花はどちらも有料サービスの経験があります。
どちらもバグのようなエラーがちょくちょくあり不安定ですが、仕組みを理解すればとても便利です。
今流行のdifyなどのようにAIチャットボットもアプリに組み込めますよ。
今の時代、アプリ開発も素人で作れる選択肢が山のようにあるのです。
必要なのは、やる気だけです。
まとめ
リレーショナルデータベースは、データを表形式で管理し、それらの表を関連付けることで複雑なデータ構造を効率的に扱うことができるシステムです。1対1、1対多、多対多といった関係性を理解し適切に設計することで、GPTsのような高度なAIシステムやノーコードアプリなどでもデータを効果的に管理・活用することができるようになります。また、アプリ開発を人に依頼するときもスムーズに伝えることが可能になることでしょう。
皆さんも、ご自身のアイデアを形にできるプログラムを書かない「ノーコード開発者」を目指しましょう!
問題の答え
(1)A,(2)B,(3)C,(4)C,(5)C,(6)C,(7)B,(8)C