
[初心者]PythonでTwitterの自動リプライ自作して遊ぶ

以下のような投稿をTwitterでしました。
このツイートにリプすると室長AIプログラムが1分以内に自動返答するよ!
— 松浦悠人|松浦機械DX推進室長 (@yuto_matsuura) April 18, 2022
何かリクエストしてみてね(例:元気出るやつください)
室長AIがあなたにピッタリの画像をプレゼントするよ!
このツイートにリプすると室長AIプログラムが1分以内に自動返答するよ!
— 松浦悠人|松浦機械DX推進室長 (@yuto_matsuura) April 6, 2022
クイズ
室長がこの世で一番好きな食べ物と言えば○○?(回答2文字1人1回まで)
今回は前者のTwitterでの投稿に関して、Python初心者なりに試行錯誤して作成した自動リプライのコードを紹介します。解説は初心者の方向けです。
しかし、自己研鑽のためにやっているので、完全な初心者から見れば、易しくないやり方していたり、上級者から見れば高度ではないという、中途半端な感じだと思うのでご容赦ください。
やりたかったことの概要
まずは自分が実現したかった自動リプライの概要を説明します。あまりにも分かりにくくなりそうなので、他者から自分の投稿についたリプライをリプライ、そのリプライに対して自分がするリプライを返信と呼ぶことにします。
自分のあるTweetに対してついたリプライに、即時に返信をする。
これを以下のようなフローで実装しました。
Tweetを投稿
1で投稿したTweetについたリプライの情報を取得
過去にすでに返信済みでないか確認
まだ返信してないリプライに返信
返信したリプライを返信済みリストに追加
[2→3→4→5]を定期実行する。
1も定期実行の中に組み込み、初回だけ実行するようなスマートなプログラムが絶対かっこいいと思いますが、面倒くさくて1は手動で実現しました。
コード全文
pythonのバージョンは3.10.2です。
コード全文をまず先に書いて、後で各詳細を解説しています。
定期実行用コード
# twitter.py
# 定期実行用
import tweepy
import pandas as pd
import sqlite3
import random
import glob
import MeCab
def twitter_API_keys():
# Twitter APIの認証キー
api_key = "************"
api_secret = "************"
access_key = "************"
access_secret = "************"
# tweepy設定
# インスタンスの作成
auth = tweepy.OAuthHandler(api_key, api_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth, wait_on_rate_limit=True)
return auth, api
def make_tweet():
auth, api = twitter_API_keys()
text="このツイートにリプすると室長AIプログラムが1分以内に自動返答するよ!\n\n何かリクエストしてみてね(例:元気出るやつください)\n\n室長AIがあなたにピッタリの画像をプレゼントするよ!"
tweet=api.update_status(status=text)
tweet_id=tweet.id_str
return tweet_id
def Who_reply(tweetid):
auth, api = twitter_API_keys()
mentions=tweepy.Cursor(api.mentions_timeline).items(20)
tweet_data=[]
for mn in mentions:
tweet_data.append([ mn.user.name,
mn.user.screen_name,
mn.text,
mn.id,
mn.in_reply_to_status_id_str])
labels=[
"ユーザー名",
"ユーザーID",
"ツイート内容",
"TweetID",
"リプ先TweetID"]
df=pd.DataFrame(tweet_data, columns=labels)
user_list=df[df["リプ先TweetID"]==tweetid]
return user_list
def create_db(DB_name):
#接続、なければdb作成
conn = sqlite3.connect(DB_name)
conn.close()
def add_df_to_id_list(df):
DB_name="to_id_list.db"
conn = sqlite3.connect(DB_name)
c = conn.cursor()
df.to_sql("to_id_list",conn,if_exists="append",index=None)
conn.commit()
conn.close
def read_to_id_list_to_df():
DB_name="to_id_list.db"
conn = sqlite3.connect(DB_name)
c = conn.cursor()
df_new=pd.read_sql_query('SELECT DISTINCT * FROM to_id_list', conn)
conn.close
return df_new
class CustomMeCabTagger(MeCab.Tagger):
COLUMNS = ['表層形', '品詞', '品詞細分類1', '品詞細分類2', '品詞細分類3', '活用型', '活用形', '原形', '読み', '発音']
def parseToDataFrame(self, text: str) -> pd.DataFrame:
"""テキストを parse した結果を Pandas DataFrame として返す"""
results = []
for line in self.parse(text).split('\n'):
if line == 'EOS':
break
surface, feature = line.split('\t')
feature = [None if f == '*' else f for f in feature.split(',')]
results.append([surface, *feature])
return pd.DataFrame(results, columns=type(self).COLUMNS)
def answer_and_username(df, to_id):
answer = df[df["TweetID"]==to_id].iloc[0,2].split("@yuto_matsuura ")[1]
username = df[df["TweetID"]==to_id].iloc[0,1]
tagger = CustomMeCabTagger()
try:
df_tag=tagger.parseToDataFrame(answer)
df_new=df_tag[df_tag["品詞"]=="名詞"]
df_test=df_new[df_new["原形"].notna()]
df_test2=df_test[df_test["品詞細分類1"]!="代名詞"]
if df_test2.empty:
final_answer="EMPTY"
else:
final_answer=df_test2.iloc[0,0]
except Exception:
final_answer="EMPTY"
print(final_answer)
return final_answer, to_id, username
def reply_tweet(answer,to_id,username):
if answer == "EMPTY":
text = random.choice(["良く分からないけどこれあげる!",
"これ…受け取ってくださいっ!",
"そんな時はこれを見なよ…"])
else:
text = random.choice([ f"{answer}ね!ほらよ!",
f"{answer}!?仕方ねぇなぁ!",
f"{answer}って笑。こいつでどうだ!",
f"{answer}ね!ぴったりのがあるよ!",
f"{answer}かぁ…。これが助けにならないかな?"])
reply_text = "@"+str(username) +" "+ text
files=glob.glob("image/*.jpg")
file = random.choice(files)
auth, api = twitter_API_keys()
api.update_status_with_media(status = reply_text,filename=file, in_reply_to_status_id = int(to_id))
def main(tweetid):
#リプ情報を取得
df = Who_reply(tweetid=tweetid)
to_id_list=list(df["TweetID"])
#完了リストを読み込み
df_done=read_to_id_list_to_df()
done_to_id_list=list(df_done["TweetID"])
#差分を取得
new_to_id_list=list(set(to_id_list)-set(done_to_id_list))
#新規をDBに登録
df_new_to_id_list=pd.DataFrame(new_to_id_list,columns=["TweetID"])
add_df_to_id_list(df_new_to_id_list)
for to_id in new_to_id_list:
try:
answer, to_id, username = answer_and_username(df=df, to_id=to_id)
reply_tweet(answer=answer,to_id=to_id,username=username)
except Exception as e:
print(e)
if __name__== '__main__':
main(tweetid="********")手動実行用
# manual.py
# 手動実行用
# %%
import twitter
tweetid=twitter.make_tweet()
print(tweetid)
# %%
import twitter
twitter.create_db("to_id_list.db")コード解説
モジュールインストール
import tweepy
import pandas as pd
import sqlite3
import random
import glob
import MeCabtweepy : Twitter API操作用
pandas : DataFrameを扱うためのライブラリ
sqlite3 : 返信済みリストの管理のために今回はデータベース使ってます
glob : 返信に添付する画像ファイルのパスをリストで取ってくる
MeCab : 日本語形態素解析ライブラリ。リプライの中の名詞を特定するために入れています
Twitter APIのおまじない
def twitter_API_keys():
# Twitter APIの認証キー
api_key = "************"
api_secret = "************"
access_key = "************"
access_secret = "************"
# tweepy設定
# インスタンスの作成
auth = tweepy.OAuthHandler(api_key, api_secret)
auth.set_access_token(access_key, access_secret)
api = tweepy.API(auth, wait_on_rate_limit=True)
return auth, apiTwitterをAPIを通じて操作するためのログインIDとパスワードみたいなものです。ここは理解するというより、おまじないの感覚で行きましょう。
Twitter APIの認証キーの取得方法はネットで探せばいくらでも見つかるのでここでは割愛します。(申請は少し面倒です)
wait_on_rate_limit=Trueの引数を入れることで、TwitterAPI取得上限(〇時間に○○件までという制限)を超えそうになった場合、自動的に解除されるまで待つようになります。
元Tweet投稿
def make_tweet():
auth, api = twitter_API_keys()
text="このツイートにリプすると室長AIプログラムが1分以内に自動返答するよ!\n\n何かリクエストしてみてね(例:元気出るやつください)\n\n室長AIがあなたにピッタリの画像をプレゼントするよ!"
tweet=api.update_status(status=text)
tweet_id=tweet.id_str
return tweet_idtext内の文言をtwitterに投稿する関数の定義です。
その際、投稿したtweetのIDを取得します。このIDはすべての投稿に固有に存在する識別番号みたいなものです。
このIDのTweetについたリプをリストアップしたい!
この目的のために取得します。
リプライ取得
def Who_reply(tweetid):
auth, api = twitter_API_keys()
mentions=tweepy.Cursor(api.mentions_timeline).items(100)
tweet_data=[]
for mn in mentions:
tweet_data.append([ mn.user.name,
mn.user.screen_name,
mn.text,
mn.id,
mn.in_reply_to_status_id_str])
labels=[
"ユーザー名",
"ユーザーID",
"ツイート内容",
"TweetID",
"リプ先TweetID"]
df=pd.DataFrame(tweet_data, columns=labels)
user_list=df[df["リプ先TweetID"]==tweetid]
return user_list
mentions=tweepy.Cursor(api.mentions_timeline).items(20)これで、自分の投稿についた最新リプライ20件を取得します。()内の数字を変えれば、件数は任意に設定できます。(上限有)
この20件には特定のTweetへのリプライではなく、自分のアカウントについた全リプライを取得します。(どうやら、自分が自分にしたリプライは取得されない。)
よって、
user_list=df[df["リプ先TweetID"]==tweetid]の一文で、指定したtweetidに対して行われたリプライのみを抽出します。
データベース作成
def create_db(DB_name):
#接続、なければdb作成
conn = sqlite3.connect(DB_name)
conn.close()引数に"****.db"と入れて関数を実行することで、その名称のデータベースを同ディレクトリ内に作成する関数の定義です。
定期実行の度にプログラムで扱われる変数の中身はリセットされます。そのため、過去に返信済みのリプライを記憶させるには外部で管理する必要があります。
今回はSQLベースのデータベースを使っていますが、CSV等のファイルで十分事足りるので、抵抗感がある方はCSVで管理するのがベターだと思います。
データベース作成自体は、定期実行の前に1回だけ実行すればよいです。そのため、この関数の実行は手動実行用のファイルで行います。(後で解説)今回のデータベースの名前は"to_id_list.db"にしました。
データベースとのやり取り
def add_df_to_id_list(df):
DB_name="to_id_list.db"
conn = sqlite3.connect(DB_name)
c = conn.cursor()
df.to_sql("to_id_list",conn,if_exists="append",index=None)
conn.commit()
conn.close
def read_to_id_list_to_df():
DB_name="to_id_list.db"
conn = sqlite3.connect(DB_name)
c = conn.cursor()
df_new=pd.read_sql_query('SELECT DISTINCT * FROM to_id_list', conn)
conn.close
return df_new前者はDataFrame型のデータを"to_id_list.db"に追加する関数です。
後者は"to_id_list.db"から、DataFrame型のデータを取得する関数です。
df_new=pd.read_sql_query('SELECT DISTINCT * FROM to_id_list', conn)の
'SELECT DISTINCT * FROM to_id_list'はSQL文ですが、"to_id_list.db"から重複を排除して取得するという意味です。
前者のDataFrame型のデータを"to_id_list.db"に追加する関数は、差分をとって新規のみを登録するので、基本的には重複は生まれないとは思いますが念のためです。
MeCabのクラス定義
class CustomMeCabTagger(MeCab.Tagger):
COLUMNS = ['表層形', '品詞', '品詞細分類1', '品詞細分類2', '品詞細分類3', '活用型', '活用形', '原形', '読み', '発音']
def parseToDataFrame(self, text: str) -> pd.DataFrame:
"""テキストを parse した結果を Pandas DataFrame として返す"""
results = []
for line in self.parse(text).split('\n'):
if line == 'EOS':
break
surface, feature = line.split('\t')
feature = [None if f == '*' else f for f in feature.split(',')]
results.append([surface, *feature])
return pd.DataFrame(results, columns=type(self).COLUMNS)こちらはMeCab用のクラスを定義しています。MeCabは日本語形態素解析用のライブラリです。
「元気出るやつください」をMeCabに通すと、

上記のように単語ごとに分けてくれるのです。これはリプライの中のキーワードを特定するために使いました。
ここのコードは、以下のQiitaで紹介しているのをコピペしました。
ただなぜかうまくいかない場合があったんですよね。例えば、「マッスル」という単語を入れると、カラム数のミスマッチみたいなエラーで止まってしまいます。
当日はこのエラーにより、ちょっとした暴走をしてしまいました。結果的に例外処理をいれて対応しました。例外処理大事です。後に解説しています。
ここまでやらなくてもいいという人は、実装しなくていいと思います。わたしはリプの内容を返信文に反映させたかったのでこのようなことを考えました。
個別のリプライから必要な情報を取り出す
def answer_and_username(df, to_id):
answer = df[df["TweetID"]==to_id].iloc[0,2].split("@yuto_matsuura ")[1]
username = df[df["TweetID"]==to_id].iloc[0,1]
tagger = CustomMeCabTagger()
try:
df_tag=tagger.parseToDataFrame(answer)
df_new=df_tag[df_tag["品詞"]=="名詞"]
df_test=df_new[df_new["原形"].notna()]
df_test2=df_test[df_test["品詞細分類1"]!="代名詞"]
if df_test2.empty:
final_answer="EMPTY"
else:
final_answer=df_test2.iloc[0,0]
except Exception:
final_answer="EMPTY"
print(final_answer)
return final_answer, to_id, username answer = df[df["TweetID"]==to_id].iloc[0,2].split("@yuto_matsuura ")[1]
username = df[df["TweetID"]==to_id].iloc[0,1]の2文でリプライのDataFrameから指定のtweetIDのリプライを抽出し、ツイート内容とリプライしたアカウント名を取得しています。
.ilocで取り出しているのは、カラムとかインデックスが残っているとなんか変な挙動するかもしれない…と思いこんなスライシングをしています。
リプライのツイート文にはリプライ先として、@yuto_matsuura␣が付いています。以下によって、分離して後半部分をツイート内容としています。
.split("@yuto_matsuura ")[1]なお、誰かがリツイートしたTweetにリプライすると、リツイートしたアカウントもリプライ先に含まれてしまいます。
このプログラムでは未対応です。返信は問題なくされますが、リプライの内容を正確に把握できないと思われます。(Mecabの処理でなんとかなってたりして…?)
tagger = CustomMeCabTagger()CustomMeCabTaggerのクラスでインスタンス化しています。初心者の方は何を言っているか分からないかもですが、taggerという名前のファイルみたいなものをクラスを基に生成し、その中にある関数を使えるようにするみたいな認識でいます。
try:
df_tag=tagger.parseToDataFrame(answer)
df_new=df_tag[df_tag["品詞"]=="名詞"]
df_test=df_new[df_new["原形"].notna()]
df_test2=df_test[df_test["品詞細分類1"]!="代名詞"]
if df_test2.empty:
final_answer="EMPTY"
else:
final_answer=df_test2.iloc[0,0]
except Exception:
final_answer="EMPTY"この"try"と"except"で例外処理を対応しています。簡単に言うと、エラーが起きたら、そこでプログラムを停止するのではなく、スキップして次に進めるということです。
前述の通り、
df_tag=tagger.parseToDataFrame(answer)で謎のエラーを吐き出す場合があるので、そこでエラーがあった場合、”except”以下の文に飛びます。"except Exception"とすることで、システム的な割込み中断等のエラー以外のエラーをキャッチしてくれます。こちらを参考にしました。
なにかMeCabの処理でエラーが発生したら、"final_answer"に”EMPTY”を入れて無理やり続行するようにしています。
df_new=df_tag[df_tag["品詞"]=="名詞"]
df_test=df_new[df_new["原形"].notna()]
df_test2=df_test[df_test["品詞細分類1"]!="代名詞"]こちらはリプライのキーワードを絞るための条件です。
まず、キーワードは名詞で定義しています。
名詞だけで定義すると顔文字の(°-°)を打っている人の "(" や "°" も候補に入るので、原形がNoneでないものを抽出することで、省いています。
”これ”や”やつ”の代名詞が候補に入るのも嫌なので、更に代名詞を省いています。
if df_test2.empty:
final_answer="EMPTY"
else:
final_answer=df_test2.iloc[0,0]もし、候補がない(適切な名詞がなかった)場合は、キーワードをEMPTYと設定しています。
名詞がある場合は、最初に出てきた方をキーワードとしています。
返信文を生成
def reply_tweet(answer,to_id,username):
if answer == "EMPTY":
text = random.choice(["良く分からないけどこれあげる!",
"これ…受け取ってくださいっ!",
"それを聞いて、今こんな気分です"])
else:
text = random.choice([ f"{answer}ね!ほらよ!",
f"{answer}!?仕方ねぇなぁ!",
f"{answer}って笑。こいつでどうだ!",
f"{answer}ね!ぴったりのがあるよ!",
f"{answer}かぁ…。これが助けにならないかな?"])
reply_text = "@"+str(username) +" "+ text
files=glob.glob("image/*.jpg")
file = random.choice(files)
auth, api = twitter_API_keys()
api.update_status_with_media(status = reply_text,filename=file, in_reply_to_status_id = int(to_id))
if answer == "EMPTY":
text = random.choice(["良く分からないけどこれあげる!",
"よーし、いい子だ",
"そんな時はこれを見なよ…"]) これはキーワードがEMPTYだった場合の処理です。random.choiceとすることで、リスト内からランダムに選出します。
else:
text = random.choice([ f"{answer}ね!ほらよ!",
f"{answer}!?仕方ねぇなぁ!",
f"{answer}って笑。こいつでどうだ!",
f"{answer}ね!ぴったりのがあるよ!",
f"{answer}かぁ…。これが助けにならないかな?"])こちらはキーワードに応じて対応する返信です。
f"{answer}ね!ほらよ!"とすることで、answerの中身が返信文に反映されます。answer="元気"だった場合、こちらの返信が「元気ね!ほらよ!」となるわけです。
reply_text = "@"+str(username) +" "+ text返信文もリプライなので、リプライ相手のユーザー名が必要です。先ほど生成した返信文の前に”@相手␣”をつけます。
files=glob.glob("image/*.jpg")
file = random.choice(files)用意していた複数の画像からランダムに返信に添付するものを選ぶ処理です。
pythonファイルのあるフォルダに"image"という名前のフォルダを作り、その中にjpg形式の画像を複数入れておきます。
globのライブラリを使用することで、指定したフォルダ内のファイルパスをリストで取得します。さらにその中からランダムで選択しています。
auth, api = twitter_API_keys()
api.update_status_with_media(status = reply_text,filename=file, in_reply_to_status_id = int(to_id))
この文で投稿を実行します。
メインプログラム
def main(tweetid):
#リプ情報を取得
df = Who_reply(tweetid=tweetid)
to_id_list=list(df["TweetID"])
#完了リストを読み込み
df_done=read_to_id_list_to_df()
done_to_id_list=list(df_done["TweetID"])
#差分を取得
new_to_id_list=list(set(to_id_list)-set(done_to_id_list))
#新規をDBに登録
df_new_to_id_list=pd.DataFrame(new_to_id_list,columns=["TweetID"])
add_df_to_id_list(df_new_to_id_list)
for to_id in new_to_id_list:
try:
answer, to_id, username = answer_and_username(df=df, to_id=to_id)
reply_tweet(answer=answer,to_id=to_id,username=username)
except Exception as e:
print(e)定義した関数を呼んで実行していくメインプログラムをこれまた関数で定義します。
#リプ情報を取得
df = Who_reply(tweetid=tweetid)
to_id_list=list(df["TweetID"])
df_to_id_list=df["TweetID"]引数のTweetIDの投稿についたリプライの情報を取得します。
現時点で付いているリプライのtweetIDのリストをto_id_listにしています。
#完了リストを読み込み
df_done=read_to_id_list_to_df()
done_to_id_list=list(df_done["TweetID"])すでに返信済みのリプライの情報を取得します。
#差分を取得
new_to_id_list=list(set(to_id_list)-set(done_to_id_list))現時点での全リプライ ー 前回に返信済みの全リプライをして未返信のリプライのリストを取得します。
#新規をDBに登録
df_new_to_id_list=pd.DataFrame(new_to_id_list,columns=["TweetID"])
add_df_to_id_list(df_new_to_id_list)データベースを更新します。
for to_id in new_to_id_list:
try:
answer, to_id, username = answer_and_username(df=df, to_id=to_id)
reply_tweet(answer=answer,to_id=to_id,username=username)
except Exception as e:
print(e)今回の返信先のTweetIDを1つずつ取り出し、返信文を生成します。
そして、返信を実行します。こちらでも念のため、例外処理を入れています。
おまじない
if __name__== '__main__':
main(tweetid="********")これはおまじないと思っていただければと思います。
簡単に説明すると、このpythonファイルが直接実行されると
main(tweetid="********")の関数を実行するという意味です。
tweetidの引数には手動で投稿した元TweetのIDを入れておくのを忘れないでください。このIDの取得方法は下の手動実行用のコードで説明します。
手動実行用Pythonファイル
# manual.py
# 手動実行用
# %%
import twitter
tweetid=twitter.make_tweet()
print(tweetid)
# %%
import twitter
twitter.create_db("to_id_list.db")これは今まで説明したtwitter.pyとは別のファイルにしてあります。
基本的にこのプログラムの実行は1回だけ行います。なので、手動での対応です。
VS codeを使ってコードを書いているのですが、jupyterの拡張機能でセルごとの実行が可能です。(ワケワカメ)
簡単に言うと、”# %%”から次の”# %%”の間だけを、独立して実行できるということです。
# %%
import twitter
twitter.create_db("to_id_list.db")を実行することで”to_id_list.db”というデータベースを作成します。これは前日等に作っておいて構いません。
# %%
import twitter
tweetid=twitter.make_tweet()
print(tweetid)を実行して元Tweetを投稿します。この際、その投稿のTweetIDが表示されるので、コピーして
if __name__== '__main__':
main(tweetid="********")のtweetid="********"にペーストして、twitter.pyのファイルを保存しておきます。(なんてスマートなやり方)
定期実行
私はWindowsのPCを使用していますので、タスクスケジューラという定期実行用のアプリケーションを使います。
今回は1分以内の返答ということで、上記のtwitter.pyを毎分実行するように設定します。(別に1秒でも、5分でも問題ないです。)
タスクスケジューラでPythonを実行する方法は以下を参考にしました。
繰り返し間隔の選択肢に1分間がないように見えますが、ボックスをクリックして直接入力することで、1分間の繰り返しは設定可能です。
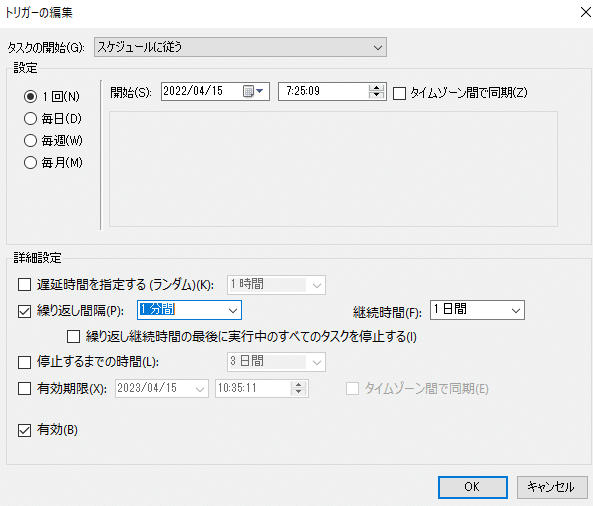
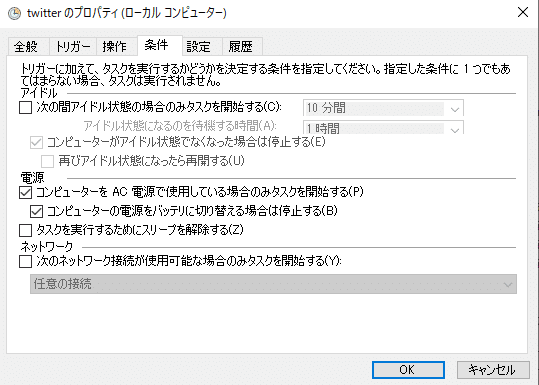
また、条件の設定も確認ください。私は、AC電源で使用している場合のみタスクを開始するの☑がデフォルトなのを知らず、電源プラグを抜いたら定期実行されていなくて焦りました。
終わりに
私はこの数か月でプログラミングを学んだ完全初心者ですが、とても面白いですね。
これからも自己研鑽で何か面白いモノを作っていければと思います。
Twitterにてリプライを頂いた方、ありがとうございました。
もし、ご興味あれば私のTwitterのフォローお願いします!
あのファナックが内部を公開…ッッ!!
— しつちょう【DX推進室】@松浦機械製作所 (@yuto_matsuura) January 30, 2023
工作機械の頭脳…松浦機械の信頼性を支えるFANUCの秘密をしつちょうと探る7分間!
諸事情により再アップロードすることになりました🙇♀️
良かったらもう一度見てください🙇♀️
フル動画はYouTubeで公開中!https://t.co/KOtL1VLauL#惜しまれる高評価63件 pic.twitter.com/QlOesGcI7E
最後まで読んでいただき、誠にありがとうございました。