
【Python×SEO】robots.txtテスターが使えなくなったので複数URLの一括チェックができるコードを作った

Search Consoleのrobots.txtテスターは2023年12月12日に廃止されてしまいました。
その後Search Consoleには「robots.txtレポート」という機能が追加されましたが、以前のrobots.txtテスターのように個別URLをチェックする機能がなく、「ちょっと求めてるツールじゃないんだよな感」があります。
一応、個別URLのクロール可否を確認する方法として、Search ConsoleのURL検査もありますが、1URLあたりのチェックに数十秒~数分が必要です。大量のURLをチェックするには不向きです。
またPythonのurllibにはrobots.txtを処理するためのurllib.robotparserというものも存在しますが、私が確認したところrobots.txtの処理方法がGooglebotの挙動とは異なっていたため、こちらもそのままSEOには活用できそうにありませんでした。
少し前置きが長くなってしまいましたが、今回は上記を解決するために、Pythonを使って複数URLのクロール可否を一括チェックするコードを作成しましたので、こちらのnoteにまとめています。
手順①:Polarsのインストール
このnoteで紹介しているコードでは、Polarsというデータフレームライブラリを使用しています。
PythonのデータフレームライブラリといえばPandasが有名ですが、PolarsはRustで作成されており、高速な処理ができることが特徴です。
まずはターミナルで以下のコマンドを実行して、Polarsをインストールしてください。
pip install polars手順②:robots.txtファイルの準備
このnoteのコードは、ローカルに保存されているrobots.txtに対してチェックを行うように作成しています。
すでに公開されているサイトをお持ちなのであれば、サイトからrobots.txtをダウンロードしておいてください。
今回はサンプルとして、以下のrobots.txtを使用します(コメントについては後ほど補足します)
#User-agent: *
#Disallow:
User-agent: Googlebot
#disallow: /?
# 基本的にはパスの文字数が長いルールが優先される
disallow: /about/c
allow: /about/
# パスの文字数が同じ場合はallowが優先
disallow: /blog/
allow: /blog/
# 優先順位の判定ではワイルドカードは1文字分として計算
disallow: /contact/?q=
allow: /contact/*
# ワイルドカードありで同じ文字数の場合はallowが優先
disallow: /news/
allow: /new*/
# ワイルドカードの位置に関わらずパスが長いルールが優先される
disallow: /mypa*e/profile/
allow: /mypage/pro*/
# 処理速度テスト用の条件
disallow: /products/*/voice/?
disallow: /products/*/edit/
disallow: /products/zz*
disallow: /products/b-
allow: /products/b-3
disallow: /products/c-
allow: /products/c-2手順③:URL一覧を含めた.txtファイルの準備
チェック対象とするURLは、ローカルに保存されている.txtファイルから読み込むようにしています。
.txtファイルの1行ごとに1URLを記載してください。
※以下のようなイメージ
https://example.com/
https://example.com/?param=sns
https://example.com/index.html
https://example.com/about/
https://example.com/about/company/
https://example.com/about/culture/
https://example.com/about/mission/サンプルでは処理速度のチェックも兼ねて、50,000URLほど記載した以下のファイルを使用しています。
手順④:以下のコードを.pyファイルで保存する
以下のコードを任意のファイル名で保存します。今回は「robots_txt_checker.py」という名前にしています。
10行目~13行目にファイルパスや保存先を指定する箇所があるので、適宜変更してください。
from urllib.parse import urlparse
import pandas as pd
import os
import re
import time
import datetime
import polars as pl
# チェック対象ファイルのパス指定
ROBOTS_TXT = "./robots.txt"
URLS_TXT = "./urls.txt"
OUTPUT_FOLDER = "./output/"
USER_AGENT = "googlebot"
PRINT_LOG = False # Trueにすると実行時にURL毎にログを出力する
def parse_rule(line):
"""robots.txtの1行を解析し、ルールの種類とマッチングパターンを返す
Args:
line (str): robots.txtからの1行
Returns:
rule_type (str): ルールの種類
pattern (re.Pattern): マッチングパターン
pattern_str (str): マッチングパターンの文字列表現
path_length (int): マッチングパターンの長さ
"""
rule_type, path = line.split(':', 1)
path = path.strip()
path_length = len(path)
pattern_str = re.escape(path)
# Process paths with `*` specially
if "*" in pattern_str:
pattern_str = pattern_str.replace("\*", ".*")
# Process paths with `/$` specially
if "\$" in pattern_str:
pattern_str = pattern_str.replace("\$", "$")
pattern = re.compile(pattern_str)
return rule_type, pattern, pattern_str, path_length
def parse_robots_txt(robots_txt_path):
"""robots.txtファイルを解析し、ルールを含むDataFrameを返す
Args:
robots_txt_path (str): robots.txtファイルのパス
Returns:
rules_df (pd.DataFrame): robots.txtファイルから取得したルールを含むDataFrame
データ型:
user_agent (str): ユーザーエージェント
rule_type (str): ルールの種類("allow"または"disallow")
path (re.Pattern): マッチングパターン
pattern_str (str): マッチングパターンの文字列表現
path_length (int): robots.txtパスの長さ
"""
with open(robots_txt_path, "r", encoding="utf-8") as f:
robots_txt = f.read()
user_agent = None
rules_df = pl.DataFrame()
for line in robots_txt.splitlines():
line = line.strip()
# user_agentを設定して次の行に進む
# ユーザーエージェント行にはルールがないため
if line.startswith('User-agent:'):
user_agent = line.split(':')[1].strip().lower()
continue
# allowまたはdisallowで始まる行の場合にルールを解析する
if user_agent and (line.lower().startswith('allow:') or line.lower().startswith('disallow:')):
rule_type, pattern, pattern_str, path_length = parse_rule(line)
tmp_df = pl.DataFrame({
"user_agent": [user_agent],
"rule_type": [rule_type],
"path": [pattern],
"pattern_str": [pattern_str],
"path_length": [path_length]
})
rules_df = pl.concat([rules_df, tmp_df])
# ルールをrule_typeとpath_lengthでソートする
# Googlebotはrobots.txtを最も長いパスを優先するため、path_lengthで優先順位をつける
# path_lengthが同じ場合は、disallowよりもallowを優先する
if not rules_df.is_empty():
rules_df = rules_df.sort("rule_type").sort("path_length", descending=True)
return rules_df
def get_rule_type_for_url(url, rules_df):
"""指定されたURLのルールタイプを取得します。
Args:
url (str): チェックするURL
rules_df (pd.DataFrame): robots.txtファイルからのルール
データ型:
user_agent (str): ユーザーエージェント
rule_type (str): ルールの種類("allow"または"disallow")
path (re.Pattern): マッチングパターン
pattern_str (str): マッチングパターンの文字列表現
path_length (int): robots.txtパスの長さ
Returns:
rule_type (str): ルールの種類("allow"または"disallow")
"""
parsed_url = urlparse(url)
path_with_query = f"{parsed_url.path}?{parsed_url.query}" if parsed_url.query else parsed_url.path
matched_df = pl.DataFrame()
for row in rules_df.to_dicts():
if row["path"].match(path_with_query):
matched_df = pl.concat([matched_df, pl.DataFrame(row)])
if PRINT_LOG == True:
print(f"{url}, matched: \"{row['pattern_str']}\", type: \"{row['rule_type']}\"")
return row["rule_type"]
# ルールにマッチしない場合はallowを返す
if PRINT_LOG == True:
print(f"{url}, matched: \"\", type: \"allow\"")
return "allow"
def get_urls_from_txt(file_path):
with open(file_path, "r", encoding="utf-8") as f:
urls = f.read().splitlines()
return urls
def get_current_datetime_as_string():
current_datetime = datetime.datetime.now()
datetime_string = current_datetime.strftime("%Y%m%d_%H-%M-%S")
return datetime_string
# メイン処理
if __name__ == "__main__":
start_time = time.time()
# robots.txtファイルを解析する
rules_df = parse_robots_txt(ROBOTS_TXT)
urls = get_urls_from_txt(URLS_TXT)
if rules_df.is_empty():
print("No rules found in the robots.txt file")
exit()
if urls == []:
print("No URLs found in the urls.txt file")
exit()
fileterd_by_user_agent_df = rules_df.filter(
pl.col("user_agent") == USER_AGENT
)
# URLをチェックする
results_df = pl.DataFrame({
"url": [url for url in urls if url],
"rule_type": [get_rule_type_for_url(url, fileterd_by_user_agent_df) for url in urls if url]
})
current_datetime = get_current_datetime_as_string()
# 保存先フォルダが存在しない場合は作成する
if not os.path.exists(OUTPUT_FOLDER):
os.makedirs(OUTPUT_FOLDER)
print(f"Created folder: \"{OUTPUT_FOLDER}\"")
# CSVファイルに結果を保存する
results_df.to_pandas().to_csv(f"{OUTPUT_FOLDER}results_{USER_AGENT}_{current_datetime}.csv", index=False, encoding="utf-8_sig")
print(f"Results saved to \"{OUTPUT_FOLDER}results_{USER_AGENT}_{current_datetime}.csv\"")
end_time = time.time()
elapsed_time = end_time - start_time
print(f"Elapsed time: {elapsed_time:.2f} seconds")手順⑤:各ファイルを同じフォルダに格納する
各ファイルを以下のように同じフォルダに格納します。
./
├── robots.txt
├── urls.txt
└── robots_txt_checker.pyファイル名や保存先を変更している場合は、そちらに合わせてください。
手順⑥:コード実行
ターミナルからrobots_txt_checker.pyを実行します。
python robots_txt_checker.py実行後に以下のようなメッセージが表示されれば、無事にテスト完了です。
$ python robots_txt_checker.py
Results saved to "./output/results_googlebot_20240316_23-38-38.csv"
Elapsed time: 2.70 seconds今回の約50,000URLは2.7秒でチェックできたので、Pythonを活用するメリットを受けられているかと思います。
実行結果について
コードの実行結果はrobots_txt_checker.pyが保存されているフォルダに作成される「output」というフォルダに、CSVファイルで格納されています。
Excelの表計算ツールでCSVファイルを開くと、A列にはチェックを行ったURL、B列にはrobots.txtでのクロール可否が記載されています。
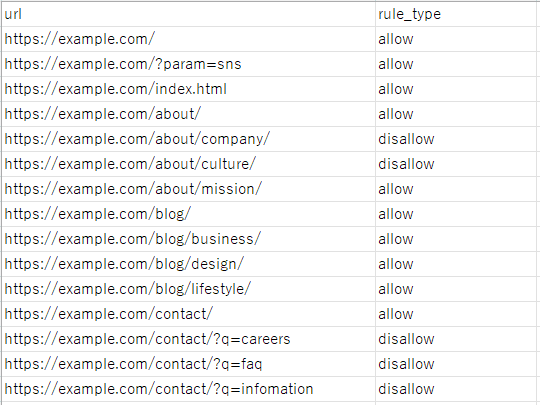
あとは各URLのクロール可否が意図したとおりになっているかをチェックすればOKです。
Googlebotのrobots.txtルールの優先順位について補足
Googlebotがrobots.txtを処理する際、各ルールの優先順位付けは少しクセのある基準で決まります。
まず前提として、Google検索セントラルには「Google による robots.txt の指定の解釈」というページがあり、以下のように記載されています。
robots.txt ルールと URL との一致判定を行う際、クローラーはルールのパスの長さに基づいて最も限定的なルールを使用します。ワイルドカードを含むルールが競合する場合は、最も制限の少ないルールを使用します。
ただし上記の記述からでは詳細なルールがわからない箇所があり、私が自身のサイトで実験してみたところ、具体的には以下のように処理されていることがわかりました。
基本的にはrobots.txtで指定するパスの文字数が長いルールが優先される
パスの文字数が同じ場合はallowが優先される
ワイルドカード*は1文字として、パスの文字数にカウントされる
ワイルドカードありで、パスが同じ文字数の場合はallowが優先される
ワイルドカードの位置に関わらず、パスが長いルールが優先される
それぞれかんたんに説明します。
1. 基本的にはrobots.txtで指定するパスの文字数が長いルールが優先される
ご存知かと思いますが、robots.txtでは「allowもしくはdisallow」と「対象とするパス」を1セットとして記述します。
URLが複数の条件にマッチしている場合には、基本的に「対象とするパス」の文字数が長いルールが優先されます。
例えば、https://example.com/about/company/というURLがあり、robots.txtの記述が以下のようだった場合には、
# 基本的にはパスの文字数が長いルールが優先される
# 以下の両方にマッチする場合は、文字数が長いdisallowになる
disallow: /about/c
allow: /about/パスの文字数が長い「/about/c」が優先されて、https://example.com/about/company/はdisallowとなります。
2. パスの文字数が同じ場合はallowが優先される
こちらは見出しのとおりで、指定したパスの文字数が同じ場合には制限の緩いallowが優先されます。
# パスの文字数が同じ場合はallowが優先
disallow: /blog/
allow: /blog/上記のrobots.txtに対して、https://example.com/blog/ というURLであればallowとなります。
3. ワイルドカード*は1文字として、パスの文字数にカウントされる
個人的にGoogle検索セントラルの文章だけでは、もっとも仕様が掴めなかったのがこちらです。
ワイルドカードを含むルールが競合する場合は、最も制限の少ないルールを使用します。
ワイルドカード有り無しのパスがそれぞれがある場合には、制限の少ないルール(allow)が優先されるのか?
ワイルドカード有りのパス同士が競合している場合には、allowが優先されるのか?
もしくは「制限の少ない」とはallow・disallowの話ではなく、パスの詳細度(文字数)による優先度なのか?
これらの仕様がいまいち分からなかったので、いくつかテストを行ってみたところ、ワイルドカードは他の文字と同様に1文字分としてカウントされ、ワイルドカード有り無しでの競合、ワイルドカード有り同士での競合に関わらず、文字数が多いルールが優先されることがわかりました。
# 優先順位の判定ではワイルドカードは1文字分として計算される
# 以下の両方にマッチする場合は、文字数の多いdisallowになる
disallow: /contact/?q=
allow: /contact/*例えば、https://example.com/contact/?q=faq というURLであれば、上記のrobots.txtではdisallowになります。
4. ワイルドカードありで、パスが同じ文字数の場合はallowが優先される
先ほど記載したようにワイルドカードは1文字分としてカウントされるため、ワイルドカード有り無しで同じ文字数だった場合には、allowが優先されます。
# ワイルドカードありで同じ文字数の場合はallowが優先
disallow: /news/
allow: /new*/上記のrobots.txtでは、https://example.com/news/ はallowになります。
5. ワイルドカードの位置に関わらず、パスが長いルールが優先される
「最も制限の少ないルール」という記述について、パスで指定しているディレクトリのことを指している可能性も考えられたため、念のため違うディレクトリ内にワイルドカードが含まれているケースもテストしています。
こちらの場合ではワイルドカードの位置によってルールの優先順位が変わることはなく、これまでと同様にワイルドカードは1文字分としてカウントされて、指定しているパスが長いほうのルールが優先されていました。
# ワイルドカードの位置に関わらずパスが長いルールが優先される
# 以下の両方にマッチする場合は、disallowになる
disallow: /mypa*e/profile/
allow: /mypage/pro*/まとめ
今回はPythonを使って、複数URLのrobots.txtテストを行うコードを紹介しました。
約50,000URLを2.7秒で処理できるので、Excelを使って処理したり、Search Consoleからチェックするより何倍も早くチェック可能です。
ぜひご活用ください。