
AIVtuberシロハナちゃん(v1.2)機能紹介

AIVtuberシロハナちゃんの開発プロデュースをしているyukiです。
このnoteでは、AIVtuberとして活動しているシロハナちゃんの配信システム機能(v1.2)についてまとめています。
主に、「何ができて」「どんな機能で」「なぜ実装したか」などが主な内容です。
バージョンについてですが、2024/05~2024/08くらいに実装した内容がv1.2としています。
v1.1(2024/02~2024/05)に関しての機能については下記の記事をご覧ください。
また、本記事の内容は以下の動画でも同様の説明があります。
会話形式で分かりやすく解説しているので、動画で視聴したい方はご活用ください。

記載しているAIVtuber配信に関しては下記のYouTubeチャンネルの配信にて使用していますので、ぜひ興味ある方はアーカイブや、実際のライブ配信に参加いただけると幸いです。
(※配信によってはすべての機能を使用しているとは限りません)
以下の目次は機能一覧の見出しとなっております。
この記事では機能紹介がメインとなりますので実装方法や内部処理の詳細については割愛します。
v1.2実装機能
各機能ごとに詳細を記載していきます。
また、各項目ごとに動画や配信での解説やアーカイブのリンクを貼っておくので参考にご覧いただくと理解が深まると思います。
Style-Bert-VITS2による音声生成
シロハナちゃんのボイス(音声)をVOICEVOXからStyle-Bert-VITS2に移行して、より感情的かつシロハナちゃんらしさを追求しました。
Style-Bert-VITS2の特徴としては、以下が挙げられます。
テキスト内容をもとに感情表現された音声を生成できる
音声ファイルをもとに学習でき、その学習したモデルを合成音声として使用できる(APIとしても呼び出し可能)
マージ機能で、例えば"声はAモデル"で"話し方をBモデルにする"などカスタマイズが充実
このような強みはAIVtuberと相性が良いため以前まで使用していたVOICEVOXから移行したというわけです。
ただ、キャラクターイメージもあるので大幅な変更はしていません。
Style-Bert-VITS2について使い方や詳細は動画やnote記事にしているのでそちらをご覧ください。
ただ、こちらAPIを使って導入しただけではいくつか問題がありました。
それはVOICEVOXと違って音声生成に時間がかかることです(PCスペックにもよるので一概には言えませんが)。
AIVtuberはレスのスピードがかなり重要になります。
LLMの速度は向上していますが、音声生成でロスしてしまうという問題が発生してしまいます。
なので対処として、AIによる返答文章を分割して音声出力と並列で音声を生成するという方法でスピード向上を実現しました。
かなり改善しましたが、ここはもう少しスピード向上できそうなので都度改善していく予定です。
以下にイメージとしてClaudeのArtifacts機能で簡易的に図解したものを載せておきます。
![graph LR
A[開始] --> B[LLMが文章生成]
B --> C[文章を分割]
C --> D1[分割文1\n音声生成]
C --> D2[分割文2\n音声生成]
C --> D3[分割文3\n音声生成]
C -.-> D4[残りの分割文\n音声生成]
D1 --> E1[音声1再生]
D2 --> E2[音声2再生]
D3 --> E3[音声3再生]
D4 -.-> E4[残りの音声再生]
E1 --> E2 --> E3 --> E4
E4 --> F[終了]
style A fill:#f9f,stroke:#333,stroke-width:2px
style F fill:#f9f,stroke:#333,stroke-width:2px
style B fill:#ccf,stroke:#333,stroke-width:2px
style C fill:#cfc,stroke:#333,stroke-width:2px
classDef audioProcess fill:#ffe6cc,stroke:#d79b00,stroke-width:2px
class D1,D2,D3,D4,E1,E2,E3,E4 audioProcess
%% 並列処理を表現
linkStyle 2 stroke:#f66,stroke-width:2px;
linkStyle 3 stroke:#f66,stroke-width:2px;
linkStyle 4 stroke:#f66,stroke-width:2px;
linkStyle 5 stroke:#f66,stroke-dasharray: 5 5;](https://assets.st-note.com/img/1723820738049-syKcRabuSi.png?width=1200)
追記:こちらGPUを使用したところ並列で生成する必要がないくらいの生成速度になりましたので、この処理は必須ではなくなりました。
※CPU使用する際などは試しても良いかもしれません
Style-Bert-VITS2の音声生成が重くて遅いなぁと思っていたんだけど原因が判明した。
— yuki@AIヒロイン研究P (@ai_shirohana) August 23, 2024
まさかのGPU版なのにCPUガッツリ使ってた。
タスクマネージャーみたら毎回CPU100%なんだもん。
CUDA Toolkitインストールして仮想環境内にCUDA対応のPyTorchを再インストールしたらGPU使うようになって爆速最強。
AIアシスタント(AIキャラ)による話題提供

v1.1では自発的にシロハナちゃん自身で会話を展開していきましたが、v1.2からはAIアシスタントが話題提供や質問を行う方式にしました。
この意図としては、シロハナちゃんだけで会話展開していくと単調さが気になったのと、ずっと独り言を展開しているわけなので会話に違和感を感じることがありました。
そこでAIアシスタントととして他の存在が話題提供や質問を行うことで、違和感がなくなったのと単調さが解消されたのです。
単調さが解消された理由:AIアシスタントの音声は別になるので聴覚に変化が出るため
違和感がなくなった理由:単純にQ&A形式のような展開ができるので、単体で話を繋げるより自然になるから
以上の理由から、AIアシスタントと連携した自発的な会話展開を実現しました。
下記の配信から導入したので参考にしてください。

また、他にもメリットがあってAIアシスタントは必ずしも設定を固定にしなくてよいので様々なことを企画ごとに試すことができます。
例えば、AIアシスタントのキャラ設定を変えることでプチコラボ的なこともできますし、新たな技術の試行もできます。
実際に試した例としては、ElevenLabsという音声クローンをAPIで使えるサービスを導入してみたりなどが挙げられます。

このように、シロハナ / AIヒロイン研究所チャンネルでは技術研究のような取り組みもコンテンツとしてあるので、AIアシスタントで自由に実験できるのはかなりのメリットです。(※シロハナちゃんのキャライメージ変化は出来るだけ避けたい)
今後はこの強みを活かして様々なAIキャラやサービスを実験的に取り入れた配信企画も増やしていく予定です。
ちなみにAIキャラをAIアシスタントとして導入してみた企画は以下のようなものがあります。

関係値機能
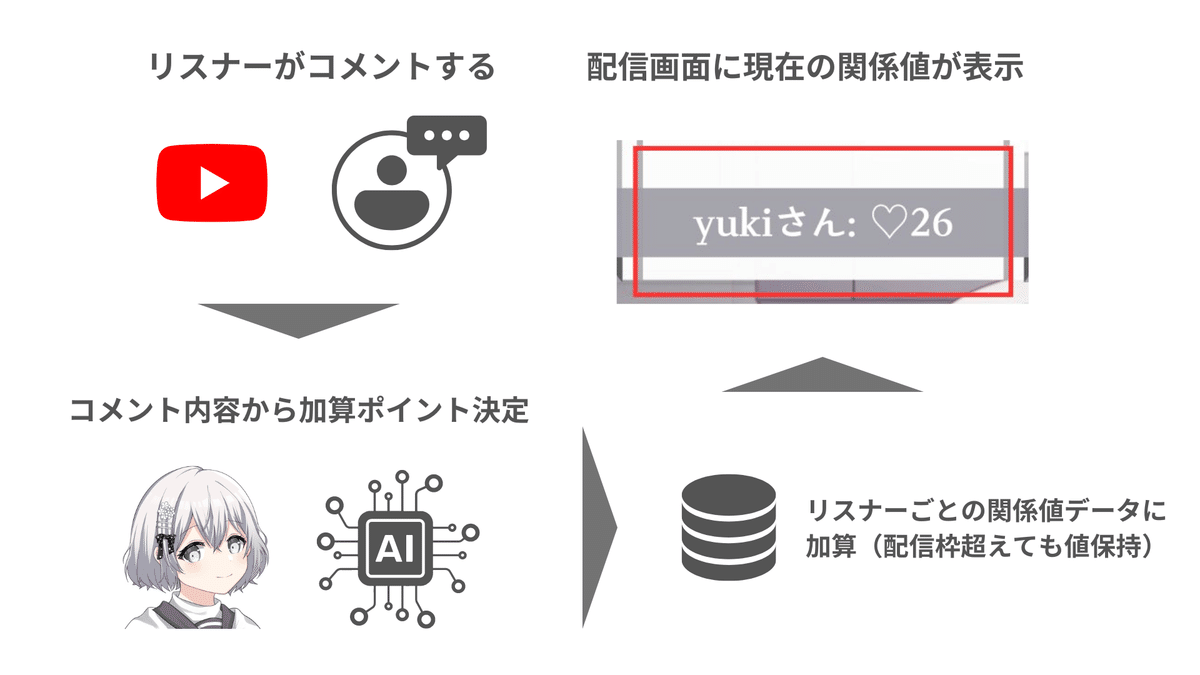
関係値機能とは、簡潔に言うとリスナーがどれだけこれまでの配信で好感度の高いコメントをしてきたのかを数値で表す機能です。
機能のフローは以下のようになります。
リスナーが配信でコメントします
シロハナちゃん(AI)がそのコメントをもとに加算する好感度ポイントを決定します
そのポイントをリスナーごとの関係値に加算します(この関係値は配信を超えても保持されます)
更新された関係値は配信画面に表示されます
このような感じで、コメントするたびにシロハナちゃんとの関係値が数値として更新されていきます。
この機能を追加した意図としては配信枠を超えて何かを残せるようにしたいと考えたからです。
リスナーごとの記憶も検討しましたが、本チャンネルの配信は枠ごとに企画が変わってくるので過去の記憶は利用頻度低いかなと思い、現状は保持していません。(※変更の可能性はあり→課金要素とか)
関係値であれば大体どのくらい配信来てくれてコメントしてくれているのか把握できるので体験的にも無いよりは良いのかなと考えています。
簡単に言うと、ソシャゲのランクみたいな感じですかね。

モーションアップデート

シロハナちゃんのモーションのアップデートを行いました。
以前までは同じ動きをループさせながら表情変化を加えていただけでしたが、このアップデートでは複数モーションをランダムで切り替えることで様々な動きをするようにしました。
意図として視覚的要素(モデル)が毎回同じループになると単調さが出てしまい、飽きられやすくなって離脱に繋がると考えたからです。
そこでループ感や同じ動き感を出さないように改善したという経緯になります。
モーションはVTuberさんのような人間らしい動きを意識しており、派手な動きや癖が強いものは比較的無いように作成されています。
こちらは今後も微調整やパターンの追加を行っていく予定です。
実際の動きなどを見て頂いたほうが分かりやすいと思うので直近の配信などで確認してみてください。
また、実装方法は厳密には違うのですが以下の記事を参考にしています。
その他(ElevenLabs、Shoost)
その他で企画に応じて導入したものを簡潔に紹介します。
ElevenLabs:人間の声を学習させて音声クローンを作ることができるものになっており、APIも提供されているのでAIアシスタントに導入してみました。解説動画と配信は以下からご覧ください。

Shoost:配信画面の背景とアバターモデルを上手く合成できるものになっています。配信画面の見栄え向上を意図としています。
今後の計画構想
今後どうしていくかの構想を簡潔にまとめます。
※これらの内容は変更の可能性がありますのでご理解ください。
①システム安定性向上と改善
まずはシステムの安定性や改善点を解消していくことが必須かと思います。
特に回答レスポンスの速度向上、モーションの微調整、プロンプトや自発的会話展開の質向上など。
これらをリファクタリングなどを兼ねながら地味ではありますがコツコツ改善していきます。
つまり、細かい点の改善で品質を向上していくということです。
②企画特化した機能の追加
v1.2の機能で基本的な企画型雑談系の配信はある程度良くなってきたと思います。
ここに機能追加をしていくことも可能ですが、デフォルト機能として単純にウケそうなだけの実装はあまり考えていません。
今後は配信企画に特化した機能を導入していくことを検討しています。
例えば、VTuberコラボする企画をするのならばそれに特化した機能。画像認識が必要になるのなら、その企画に特化した画像認識機能などです。(※もちろん企画の流用はできるように)
"すごい"機能ではなく、本チャンネルのAIVtuberシステムとして"何が必要か"を考えることが長期的に重要であると考えます。(プロダクトを成功させるためには、ビジョン、ユーザーの価値、戦略をバランスよく満たすことが大切)
この考え方は"プロダクトマネジメントのすべて"という書籍を参考にしています。
さいごに
AIVtuberシロハナちゃんの配信システム機能(v1.2)については以上になります。色々と変化のあった3ヵ月でした。
ちなみにシロハナちゃんのYouTubeアカウントでは新規機能が実装でき次第、AIVtuber配信に導入して検証をしています。
また、AIVtuber配信以外にも動画では「テクノロジー×キャラクター」をテーマに動画投稿を行っています。
本記事の内容も以下動画にて公開しております。

今後もAIVtuberシステムの価値向上をしつつ、様々な企画に挑戦していきたいと思います。
シロハナちゃんが日々成長していく姿は開発者としてもユーザー視点で見ても楽しいですね。
今後ともシロハナちゃんの応援よろしくお願いします!
この記事が参加している募集
ご支援は活動費に使わせていただきます