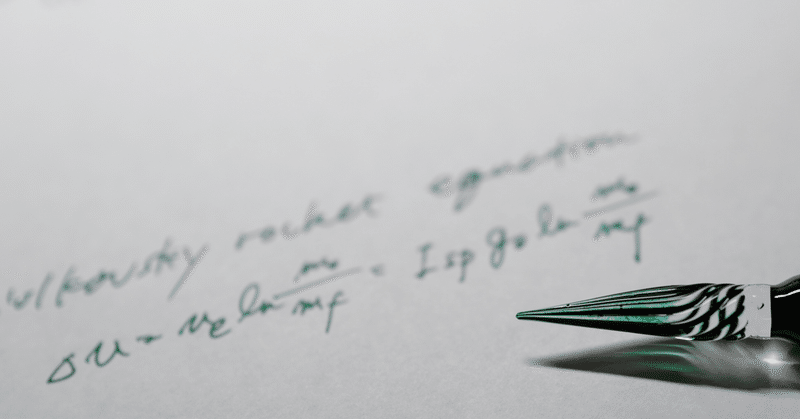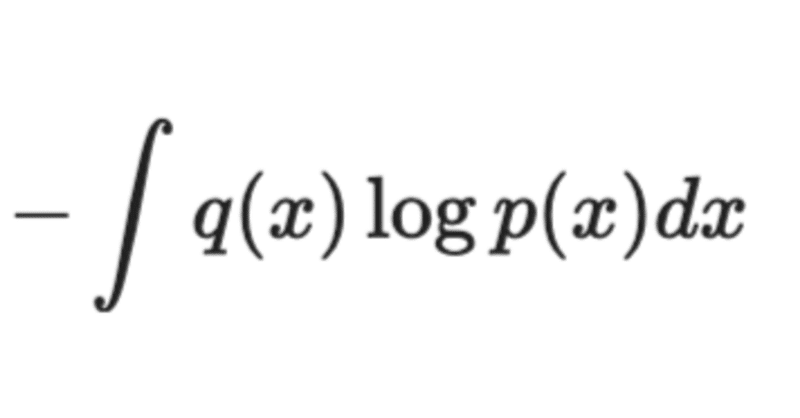シードを固定する必要性 GANの学習では、乱数から発生させたノイズデータを生成器の入力に用います。乱数シードが固定されていないと、毎回結果が変わってしまいます。計算の結果に再現性を持たせるためには、シードを固定する必要があります。コードを以下に示します。 ソースコード # ライブラリの読み込みimport osimport randomimport numpy as npimport torch# シードを固定するための関数def torch_fix_seed(seed
Least Squares GAN(LSGAN)とは? Generative Adversarial Network(GAN)[1]は、一般的に学習が不安定であることが知られています。学習が不安定になる原因として、JS Divergenceの最小化に基づくGANでは、勾配消失が起きやすいことが挙げられます[2]。LSGAN[3]は、GANの損失関数を最小二乗誤差にすることで、この問題の解決を目指したGANです。 GANの勾配消失 GAN[1]は、識別器の損失関数にシグモ
はじめに 前回は、GANの考え方について述べました。今回は、GANの数式について触れようと思います。本記事は、しくみがわかる深層学習(2018, 朝倉書店)」を参考にしています。 損失関数の導出 早速見ていきましょう。まず、識別器に与えられるデータが本物か偽物かを表す変数を$${r}$$とおきます。 「実際に本物であること」は$${r=1}$$ 「実際に偽物であること」は$${r=0}$$ と表します。 次に、本物か偽物かの判定結果を$${y}$$で表します。つま
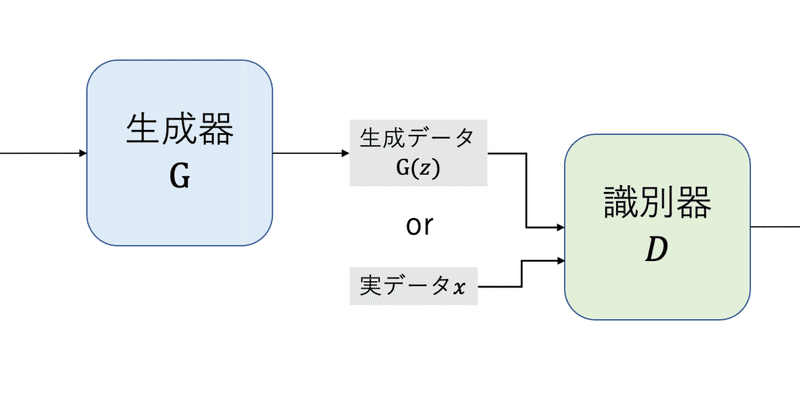
はじめに 機械学習の主なタスクは「分類」と「回帰」であり、この二つを行うものは識別モデルに区別されます。機械学習モデルにはもう一つ、生成モデルというものがあります。今回は、生成モデルである敵対的生成ネットワークについて述べます。 生成モデル 識別モデルと生成モデルの違いは何でしょうか?それは、モデルが決定的であるか確率的であるかということです。識別モデルは決定的なモデルです。入力データに対して出力データは一意に決まります。一方、生成モデルは確率的なモデルです。確率的であ
はじめに 機械学習では損失関数にしばしば「交差エントロピー誤差」が用いられます。自身の研究で用いるモデルの損失関数にもこれを用いており、今回はその基本概念であるクロスエントロピーの意味について「しくみがわかる深層学習(2018, 朝倉書店)」を参考に調べました。 情報量 ある出来事の起こりにくさを情報量といいます。出来事$${x}$$の情報量を測る関数$${L}$$が存在するとき、$${x}$$が発生する確率を$${p(x)}$$とすると、$${L(p(x))}$$とな
ヒープソートとは? ソートとは、入力として与えられた数字を小さい順に並び替えることです。ソートの中でも、データ構造のヒープを利用したソートをヒープソートと言います。ヒープについて知りたい方は「アルゴリズム図鑑(2017, 翔泳社)」を参照して下さい。 ヒープソートの実装 pythonで実装を行います。pythonにはheapqという配列をヒープに並び替えることのできるライブラリがあり、これを利用します。ヒープソートを行う関数を以下に示します。 import heapq