
NZFE について_fendoap

1.NZFEについて
NZFEはNzworkdownさんの音源をfendoapが変換するという手法によって作品を制作する共作プロジェクト。変換を通して変換の手法、課題を考えたりする。
時の崖よりリリースされました:
NZFE:Collecting fragments of our signature
https://tokinogake.bandcamp.com/album/collecting-fragments-of-our-signature
https://t.co/EH4PcBopqj pic.twitter.com/Crew4aTQ02
— 時の崖_tokinogake_ (@tokinogake) September 9, 2021
元々この作品は時の崖collective 047がきっかけとなり企画された。
ここで047について解説。047は1階のマルコフ連鎖を用いて元波形から波形の生成を行い16種類の再生速度で波形を再生しながら生成を更新していくプロセスで作成した。読み込ませるのは振幅値。047での問題点はマルコフ連鎖が1階であること、振幅の分解能(12000段階)、また読み取りを1サンプルごとにではなく一定時間(0.1s)ごとに読み取るという部分。音源がノイズであり作成された047もノイズであったため音的な違和感はなかったが実際には音色は再現されていない可能性が高かった。今回はその部分を作り直すことで当初の波形の再現、生成をコンセプトとして成立させることも目標の一つにした。
2.制作プロセス
(1) nzworkdownさんの制作したA B Cの3つのノイズwav音源を受け取った。
(2)マルコフ連鎖
二階のマルコフ連鎖を用いてA B Cの3つのノイズwav音源を生成変換した。事前に試してみた結果負荷の問題から一度に数分程度の音源にマルコフ連鎖を用いる事は不可能であることが分かった。様々試してみた結果、数秒程度ごとであればマルコフ連鎖を用いる事が出来ることが分かった。
1秒程度であっても処理に数分必要となり手作業での作業は困難であったため音源を切り分けマルコフ連鎖を適用し波形を生成、wav音源として保存するまでを自動で行うMaxパッチを作成した。この部分が出来なければマルコフ連鎖を用いる事はあきらめようと思っていた。
2.2 作成したMaxパッチを用いてA B Cの音源の生成切り分けを行った。音源が長くなるほど処理は加速度的に時間がかかる感じがした。Aについては1週間ほど生成に時間がかかった。B,Cについては3~2日ほどかかった。これはおそらく音源の長さによる。それぞれLR各256個のwavファイルに切り分けられてA B C各々512個のwavファイルが作成された。
(3)オシレータ数、パラメータなど
作成したwav音源を前回同様にオシレータのように制御する方法で音源を作成しようと検討した。事前にmaxで前回と同様の再生方法のパッチを制作して試してみてサウンドのクオリティはある程度確保できると確認した。試した中でオシレータの数が多ければよいものではないと感じた。多すぎれば濁りすぎて雑音になってしまうと感じたのでおおよそ32,16~1の範囲で制御する方向性とした。
(4)制御パラメータを変換によって制御する方向性を検討した。映像と音楽の変換や他データの音響化などはポピュラーな手法としてありそのような手法を自らの学習もかねて取り入れてみることにした。
(5)具体的な全体を検討する前に各種パラメータを用意していくことにした。
(6)テキストデータ
禅の公案集、無門関の翻訳版のテキストgutenberg.org/ebooks/34619を用いて数字のテキストデータを作成した。時の崖関係のテキストを探したがフリーのものではなかったので様々検討して無門関とした。
翻訳書としたのは入手のしやすさもあるが翻訳というのも変換の一形態であるととらえた。
Project goutenbergよりテキストデータを入手し一文ごとの文字数から6900x1行の行列を作成した。これを300x24行の行列に並べなおした。要素数の足りない部分は0となっている。これを用いて列ごとに四則演算を繰り返した。

その時に用いる数字として無門関の公案数48の約数の1,2,3,4,6,8,12,16,24,48を用いる事とした。しかし実際にはこれは制約の無い、少ないルールであると感じた。例えば/10なら/(2+8)とすれば良いので、組み合わせで大体の事が出来る。このルールによって制約が課されることはほとんどないが制約が少なくてもルールとして取り決めることと自由に作ることの違いは大きいと感じる。制作において自由に恣意的に作る部分が出てきたときそこだけ他のかっちりしたプロセスと浮き立ってしまう感じがある。そのような場合に恣意的な工程を出来るだけ制約の無いルールで置き換えていくとおさまりが良いような感じがする。このパラメータはミリ秒として音源の切り替えのタイミングなどに使った。
(7)気象庁の公開している世界の天候データツール
https://www.data.jma.go.jp/gmd/cpd/monitor/dailyview/
よりwavファイルを作成した。
気象庁の公開している世界の天候データツールより世界各地約8000地点の日平均気温、約2週間分を使ってwav音源を作成した。平均値をとり全体から引いたのち極端な数値を取り除き(南極や寒冷地はとげのようになる)-1~1の範囲に数値が収まるようにした。このデータはパンのlfoの周波数決めなどに使った。
(8)コンセプトを詰めることから楽しい事へという感じに変化がある。
>ここ一週間いろいろ考えてて、スタンス気持ちが変わってきたような感じがあります。ワクワクするもの、びっくり箱みたいに楽しんで作りたいですね。出来るものは同じかもしれませんが気持ち的にはだいぶ変化がありました。(discord ログより)
(9)ヒッパルコス星表
ヒッパルコス星表のデータより気象データと同じ要領でwavファイルを作成した。データからwavファイルを作成する手法が同じだったので変化を付けたいと考えてウェーブシェービング合成を使おうと思った。
>このデータから気候データと同様にwavファイルを作ります。今回はそこからもうひと工夫入れようと思っていて、また別のデータ、今ちょっと考えているのは味覚のデータですがそれからwavファイルを作成します。それら二つをウェーブシェーピング合成で掛け合わせようと思っています。(discord ログより)
(10)味覚とワインディストーション
味覚データを探したが思うように見つからなかった。サンプル数が少ないものなどが多かった。機械学習用のデータ等にワインのデータがあることを思い出した。
https://www.atmarkit.co.jp/ait/articles/2008/05/news011.html
データセットは変換用として適しているのではと思い探した。
(11)方向性がわからなくなりnzさんと相談した。nzさんからパラメータ用に写真データをいくつかもらった。(12)ワインディストーション
ワインのデータからwavを作成した。天体のデータとウェーブシェービング合成したが思うような効果はなかった。ホワイトノイズのようになってしまった。その原因はおそらく波形が複雑すぎるからではないかと思い波形をシンプルにすればと考えた。例えば小さい順に並び替えるなど。そうしているうちに歪みエフェクトが出来た。(データを小さい順に並び替え双曲線関数を通したものを使ったウェーブシェービング合成)
これが元のデータ

これが小さい順に並び替えたもの シンプルになった。

双曲線関数をいくつか通すとこのように曲がる。このようなS字で-1や1に漸近するような波形はディストーションエフェクトとして使えるのではと思う。

このような実データを使う事の利点は波形が上下非対称になるので偶数倍音が発生するという事。以下は通常のディストーションとワインディストーションの比較

(13)動画、画像の処理のためjitterを試す。

動画、画像を扱うためjitterを試した。
動画、画像から数値を取り出すことが出来た。

試しに画像からトリガーするmaxパッチを作ることが出来た。
(14)1サンプルサンプリング
サンプル単位のサンプリングによってある波形にかなり近い波形を作る手法を試した。これを使って環境音などを電子音から再現することが出来た。これを使ってAの音源からサイン波を作成することが出来た。

サイン波が作れたのでFM合成などで積極的に音作りが出来るようになった。方向性としてABC元のサウンドに近い音源とFM合成などで積極的に音を作る音源を作ることになった。
(15)FM合成を使って100個ほど短いサウンドを生成した。これを写真のパラメーターでトリガーして音源を作成した。写真はピクセルごとに三原色それぞれ0~255段階のパラメータを取ることが出来る。閾値を設定してトリガーとした。
(16)サイン波だけではなく様々なサウンドもサンプリングによって作ることが出来るので通常のkickやsnareやclapなどのサウンドも試験的に入れてみることにした。いくつかのドラムサンプルをAよりサンプリングして作成した。画像よりトリガーして試してみていくつかの音源を作成した。

(17)5曲ほど20分ほどの構成ではなくそのまま試しで作成した音源を羅列する方向性も出てきた。
(18)FM合成やサイン波より短いサウンドを数百個ほど設定を変えて生成した。それぞれ画像よりトリガーするなどして音源を作成していった。
(19) 引き続きFM合成やサイン波より短いサウンドを数百個ほど設定を変えて生成した。それぞれ画像よりトリガーするなどして音源を作成していった。モジュレーションなども入れていった。
(20)A B Cの512音源を制御するmaxパッチの制作をした。音で制御しようと思ったのでそれ用に作っていった。また周波数を画像によりパラメータ取得するために画像トリガーのpatchと合体させた。様々な部分にパラメータ用のwavを取り付けた。
(21)パッチについてなど部分的に
画像からパラメータ出力まで
画像を一定区間ごとに切り分けて数値を取得する。

一定区間の数値を合計する。0~8192の区間となる。これを-1~1.の範囲にスケーリングしてシグナル信号とする。これを指定区間でスケーリングするようにする。

DC成分を除去する部分に通される。除去するかどうか選択可能

等間隔に分布される部分に通される。スケーリング範囲については対数スケールではなくリニアスケールで指定された区間から等間隔区間に配置されるようにスケーリングされる。


パラメータとして出力される。
(22)最終的にオートメーションでパラメータを動かしながら即興的に手でパラメータを調節しながら録音して音源を作成した。パラメータについてはまだまだ試行錯誤の余地があると思う。今回は音源も多くなってきたので切りのいいところで閉じた。
用いた手法、道具:
マルコフ連鎖
Max
MATLAB
csvファイルからのwav作成など:サンプルサンプリング
気象データ、無門関翻訳版テキストデータ、ワインデータのディストーション..など
思ったことなど気づき:
実データのソートによるディストーションエフェクト:
ワインの分析データをソートし双曲線関数を通した音源を用いたウェーブシェービング合成によりディストーションエフェクトを適用した。
実データを用いる事で波形が上下非対称になる。波形が非対称になることで奇数倍音に加え、偶数倍音が含まれるようになる可能性がある。
実データの選択と双曲線関数の掛け具合でディストーションエフェクトを調整することが出来る可能性がある。
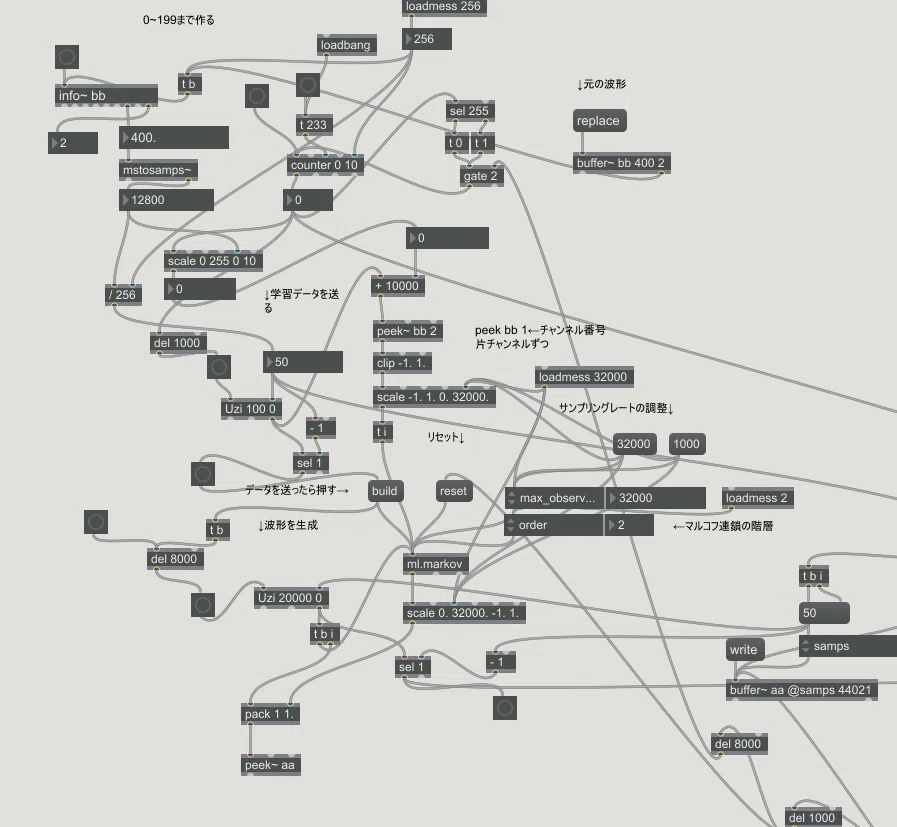
マルコフ連鎖による振幅値を用いた波形の再現:
波形の振幅値を32000通りの値で1サンプルごとにマルコフ連鎖により学習させ波形の再現を試みた。高階マルコフ連鎖には外部オブジェクトml.*を用いた
: https://www.benjamindaysmith.com/ml-machine-learning-toolkit-in-max
マルコフ連鎖による振幅値を用いた波形の再現では高階マルコフ連鎖を用いる事で音色的な類似を持った波形が再現できる可能性がある。一方でマルコフ連鎖やAIなどによる生成の分野での面白みは再現できることだけではなく予想外の結果が出るという事にもある。
今回PCの処理の限界の点と波形を再現しすぎないという点から2階のマルコフ連鎖を用いた。波形そのものを扱う場合取り扱う数値量が膨大になり計算や処理が膨大になる可能性がある。RAMの限界からあまり多くの学習データを読み込ませることが出来なかった。
マルコフ連鎖の場合学習データの個数が学習データの取りうる値の数以下の場合ただ学習したとおりに再生するのみになる可能性がある。例えば10通りの値をとるデータを9個学習させた場合、学習させたままに再生する可能性がある。今回振幅を32000通りの値で読み取らせたのでサンプル学習数は32000以上の範囲とした。
実データ等のwav化
様々なcsvファイル形式のデータからwavファイルを作成した。作成にはMATLABを用いた。csvファイルを読み込み全体の平均値をとり各要素データから平均値を引いた。それから突出した値を取り除き-1~1の範囲にスケーリングしwav出力した。Wavデータとして作成するならデータはかなりたくさん必要となる。48000個でも1秒なのでデータの数の時点で使えるデータが限られてくると感じた。
制約の無いルール
無門関のテキストデータの変換では列ごとに四則演算を繰り返す際に、用いる数字として無門関の公案数48の約数の1,2,3,4,6,8,12,16,24,48を用いる事とするルールを設けた。しかし実際にはこれは制約の無い、少ないルールであると感じた。例えば/10なら/(2+8)とすれば良い。つまり四則演算では1,2,3,4,6,8,12,16,24,48の組み合わせで大体の事が出来る。このルールによって制約が課されることはほとんどない。制約が少なくてもルールとして取り決めることと自由に作ることの違いはどこにあるのか。制作において自由に恣意的に作る部分が出てきたときそこだけ他のかっちりしたプロセスと浮き立ってしまう感じがある。そのような場合に恣意的な工程を出来るだけ制約の無いルールで置き換えていくとおさまりが良いような感じがする。同様な制約の無いルール、手法として1サンプル単位でのサンプリングがある。
本当に気象データか
>気象庁の公開している世界の天候データツールより世界各地約8000地点の日平均気温、約2週間分を使ってwav音源を作りました。
考えてみると面白いと思う。これは気象データか?というと違うと思う。これは気象データではなくて天候データツールが並べた順番のデータ。あるデータを音データにするというとき個々の数値よりも並びとか変遷が重要だと思う。一か所の定点観測のデータなどだと変遷に意味合いがあるけどここの並びは気象とあまり関係がない。ここでの並びは気象データツールの作成者が並べた並びでこれは気象とはあまり関係がない。なにかデータを変換する場合本当にそれがデータと関係があるか考える必要があると感じた。

1サンプル単位でのサンプリング
Aなどを元に1サンプル単位でのサンプリングを行い様々なサウンドを作成した。
方法は1サンプルづつ振幅を元の音源から探して並べていくというシンプルなもの。
厳密に振幅の値だと見つからないこともあるので微小な幅を持たせた範囲に当てはまればそれを持ってくるという形で作成した。これはサンプリングではあるけれど1サンプルのサンプリングは元の音源の何の情報を引き継いでいるのだろう。音は波形でいえば遷移による振動だと思う。遷移による振動には最低2つの状態の変化が必要で1サンプルの繰り返しでは振動することは出来ない。音の情報というのは遷移の状態を記録したものだと考えれば1サンプルからは音に関する元の音源の何の情報も引き継いでいないのかもしれない。すべてが元の音源から作られているのに全く構造を持っていない音源が出来るのが1サンプル単位でのサンプリングかもしれない。
スパゲティコードですが以下がコード。
[y1,Fs1]=audioread('A.wav'); %サンプリング元
[y2,Fs2]=audioread('kick.wav'); %サンプリング参照
y1L=y1(:,1); %元ベクトル
y1R=y1(:,2); %元ベクトル
y2L=y2(:,1); %参照ベクトル
y2R=y2(:,2); %参照ベクトル
y2L=y2L.*0.9999;
y2R=y2R.*0.9999;
LeY1=length(y1); %元サンプル数
LeY2=length(y2); %参照サンプル数
maxY1L=max(y1L); %元最大振幅L
minY1L=min(y1L); %元最小振幅L
maxY1R=max(y1R); %元最大振幅R
minY1R=min(y1R); %元最小振幅R
youtL=zeros(LeY2,1); %保存用 参照と同じ長さになる
youtR=zeros(LeY2,1); %保存用
youtTWO=zeros(LeY2,2); %最終保存用
refLow=0; %参照振幅
refHigh=0; %参照振幅
for i=1:LeY2 %参照サンプル数
for j=1:LeY1 %元サンプルの中から探す
if (y2R(i)-0.0008<=minY1L)
refLow=minY1L;
else
refLow=y2R(i)-0.0008;
end
if (y2R(i)+0.0008>=maxY1L)
refHigh=maxY1L;
else
refHigh=y2R(i)+0.0008;
end
if ( refLow<=y1L(j))&&( y1L(j)<=refHigh )
youtR(i)=y1L(j);
break;
elseif refLow<=minY1L
youtR(i)=minY1L;
elseif refHigh>=maxY1L
youtR(i)=maxY1L;
end
end
end
for i=1:LeY2 %参照サンプル数
for j=1:LeY1 %元サンプルの中から探す
if (y2L(i)-0.0008<=minY1L)
refLow=minY1L;
else
refLow=y2L(i)-0.0008;
end
if (y2L(i)+0.0008>=maxY1L)
refHigh=maxY1L;
else
refHigh=y2L(i)+0.0008;
end
if ( refLow<=y1L(j))&&( y1L(j)<=refHigh )
youtL(i)=y1L(j);
break;
elseif refLow<=minY1L
youtL(i)=minY1L;
elseif refHigh>=maxY1L
youtL(i)=maxY1L;
end
end
end
youtTWO(:,1)=youtL(:,1);
youtTWO(:,2)=youtR(:,1);
audiowrite('outPut.wav',youtTWO,Fs2);似ていることと再現できていること
047で気になったことがあってそれはそれっぽいから再現できているかのように錯覚してしまったこと。047でノイズのようなサウンドが出来た時、元の音源と同じノイズにも聞こえたから何かしら再現できていると思った。でも試しに他の様々な音源を入れてみると全部047のようになってしまった。つまり再現出来ていなかった。音的に似ているからと言って正しく成立しているわけではないんだと思った。その部分をやはり詰めないといけないんだろうなと思った。
signatureとそれそのもの・集める
前に読んだ井筒俊彦の本『コーラン』を読むの中でイスラムにおけるアッラーの名前というのはあるものを指し示す(ここではアッラー)ものではなくてそれ自身だというようなことが書いてあった。名前とかは代理じゃなくてそれそのもので、かつアッラーも畏怖の対象だから名前もそれに近い感覚(名前を呼んではいけないあの人的な)というような感じのことが書いてあったと思う。そういう意味でsignatureというのは代理ともとれるんだけどそれそのものともとれる。our signature は代理するものとも分身ともとれるんだけどもっと近づいてもよくてそれそのものともとれる。そうすると主語の問題が出てくる感じがして面白い。代理するものだったら集める主語は自分たちでも良いけど、それそのものだったら再帰代名詞みたいに自分たちで自分たちを集める形になるので集める主語は自分たちではないのかも。初めnzさんと何か生成的なプロセスがあるのだからタイトルに半自動とか自動とか言う意味でautoとかどうかという話をしていた。それでautographとかautobiographどうかなとなってそれは結局signatureとなったのだけどautographと違ってsignatureにはauto的な意味はないのかな。signatureを代理ではなくてそれそのものと考えると他者性が感じられてauto的な意味が含まれる感じもする。生成は自分じゃないという意味では他者性と似ているかもしれない。signatureをそれそのもの、もしくは作品ととらえる。それを集めるというのは集めたものから作品を作る意味合いとも似ている。自分自身の作品か再帰的に自分自身の作品が作られる。ある作品には他の作品を構成する要素、部品が含まれている。けれどそれはある作品には他の作品が含まれているというわけではない。ばらばらに分解できる要素の単純な組み合わせで全体が構成されているようなシステムではなく、ばらばらにすると本質が抜け落ちてしまうようなシステムを『複雑』なシステムというらしい。ある作品がそうなら、作品を要素に分解してしまった時点で本質≒作品らしさは抜け落ちてしまう。要素自体だけでなく組み合わせ、並びも意味を持っている。大まかに言ったらマルコフ連鎖は組み合わせ、並びに着目していて1サンプルサンプリングは要素のみに着目している。
いいなと思ったら応援しよう!
