一撃 按分 端数も計算 SQL について

せっかく note 書きますので、社会貢献ということで、前職で苦労しました「比例加重 按分 」の記事を記載します。
以下に結論として公式を乗せておきますので結果を先に知りたい方はどうぞ。
さて。比例加重 按分 というのは、以下のような計算のことです。
伝票値引きなどを明細に振り分ける計算で利用します。
例①:
1伝票で、商品A:2000円を3つ買いました。
このとき、「伝票で」1000円値引きがありました。
1行あたりいくら値引いたでしょうか?
例②:
1伝票で、商品A:4000円を3つ買いました。
このとき、「伝票で」2円値引きがありました。
1行あたりいくら値引いたでしょうか?
例③
1伝票で、商品A:1000000円、商品B:1円、商品C:1円買いました。
このとき、「伝票で」4円値引きがありました。
1行あたりいくら値引いたでしょうか?
表にすると以下のような感じです。
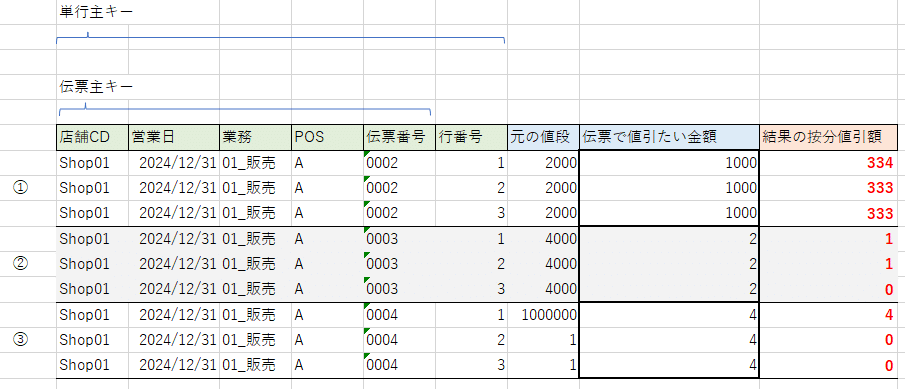
例①のケースでは各行は2000円。構成比は全て 33.33..%です。
3明細で1000円引きしていますので全行333円引きにする…のでいいのですが、3行足すと999円になり1円足りません。
そのため、通常は、販売明細を1伝票内で価格の高い順 > 行の若い順 に並べて高い方にその按分端数差額(最大、行数-1円)を割り振ります。
例②のケースも同様。各行は4000円。構成比は全て 33.33..%です。
3明細で2円引きたいのですが、3行ありますので上から1行分だけ1円ずつ引きたい感じです。
例③のケースはややこしいパターンです。1行目に他明細の100倍を超える大きな金額、2・3行目に小さい金額が入ります。構成比が1行目がほぼ100%、他は1%未満になります。
3明細で4円引きたいのですが、構成比の都合で一番上から満額引かないと、2行目、3行目は売価1円のため2円以上引けません。
これをプログラム側で実装しますと、結構ややこしく、大抵バグりまくり、処理がとても遅いです。
①構成比の端数切捨計算をし、②伝票値引き金額で各行を割り、③価格順&高いもの順に並べ、端数を1円ずつ乗せる作業が発生します。
多重ループ分をぐるぐる回し、1伝票内でカレント計算行を前に行ったり後ろに行ったり「ぐっちゃぐっちゃ」しないといけません。明細件数によっては処理に何百万回もループさせますし、バグが起こりやすいものになります。
じつは、この複雑なものが SQL 1行でループ無しで計算できてしまいます。
KAZAMAI_NaruTo 様の以下の記事が基本であり秀逸です。
(おかげさまでいろいろ助かり、ありがとうございます)
彼の分析は賢いです。私にはちんぷんかんぷんです。

さて、彼のSQLは正しいのですが、業務システムの立ち位置においては、ユーザーがシステム誤打をする可能性があり、データクレンジング前のデータを扱う場合、彼のSQLでは若干漏れがあります。
それを修正したものを公開しておきます。
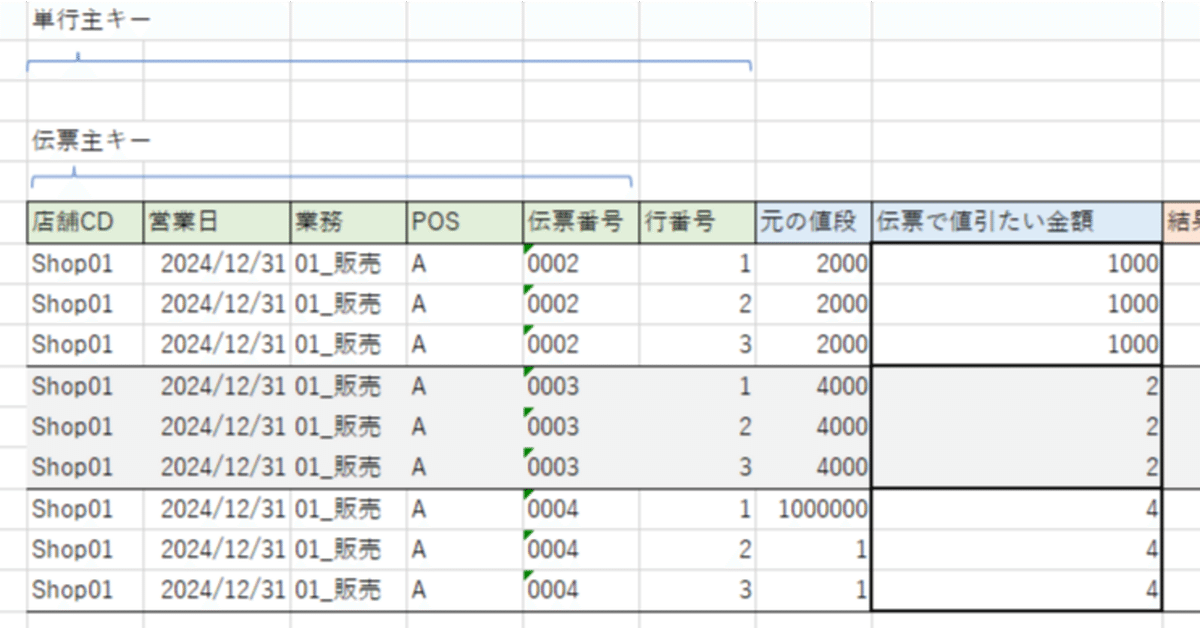
上記のような販売の明細計算用のテーブルがあり、青のフィールド値までを事前に渡し以下SQLを投げると、赤の結果値が自分のテーブルに導き出せるSQLです。
100万明細ぐらいのDBに投げてみましたが、速度は速い。
プログラムでは出せない処理速度が出ます。
(Visual Studio .NETの処理速度には勝ります。)
さて、事前に注意事項があります。
まず、「元の値段(値引比例計算のシード値)」ですが、0円以下の商品の価格は0に変換してください。マイナス値を入れると構成比率が変になり誤差が出ます。プラス値で入れてください。
次いで、「伝票で値引きしたい列」ですが、こちらもプラス値にし伝票総合計金額を超えないでください。
では以下が答えです。
-- 比例按分値の算出
-- テーブル再起結合で自分テーブルの隣のフィールドに按分値を入れる。
UPDATE [t_計算用の販売ワークテーブル]
SET
<結果の按分値引額> = tmp_anbun_kin
FROM [t_計算用の販売ワークテーブル]
LEFT OUTER JOIN
( -- T4 -- ★★★★ 比例按分計算の定型処理 ★★★★
SELECT -- T3
p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no, p_t_line_no, -- 単行認識できるキー値
<field値引前単価>, -- [比例算出売価] 比例按分計算元の売価。0 以上の正の数である事。
<field値引前伝票値引額>, -- [伝票単位の按分元] 按分元の値引明細などの売価。0 以上の正の数である事。
PROVISIONAL_DIVISION_VALUE_2
+ IIF(ROW_NUMBER()
OVER (PARTITION BY p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no -- 伝票認識できるキー値
ORDER BY
DIVIDABLE_2,
sign(TOTAL_DIFF_2) * sign(PROVISIONAL_DIVISION_VALUE_2) DESC,
DIFF2 DESC,
p_t_line_no ASC) <= ABS(TOTAL_DIFF_2) ,SIGN(TOTAL_DIFF_2), 0)
AS tmp_anbun_kin -- [按分計算値]
FROM
(SELECT -- T2
p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no, p_t_line_no,
<field値引前単価>, -- [比例算出売価] 比例按分計算元の売価。0 以上の正の数である事。
<field値引前伝票値引額>, -- [伝票単位の按分元] 按分元の値引明細などの売価。0 以上の正の数である事。
RAW_DIVISION_VALUE,
PROVISIONAL_DIVISION_VALUE_2,
IIF(PROVISIONAL_DIVISION_VALUE_2 * DENOMINATOR = NUMERATOR2, 1, 0) AS DIVIDABLE_2,
ABS(NUMERATOR2 - PROVISIONAL_DIVISION_VALUE_2 * DENOMINATOR) AS DIFF2,
<field値引前伝票値引額> -- [伝票単位の按分元]
- SUM(PROVISIONAL_DIVISION_VALUE_2) OVER (PARTITION BY p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no) AS TOTAL_DIFF_2
FROM
(SELECT -- T1
p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no, p_t_line_no,
<field値引前単価>, -- [比例算出売価] 比例按分計算元の売価。0 以上の正の数である事。
<field値引前伝票値引額>, -- [伝票単位の按分元] 按分元の値引明細などの売価。0 以上の正の数である事。
NUMERATOR2, -- 分子
DENOMINATOR, -- 分子
(CASE WHEN DENOMINATOR = 0 THEN 0 ELSE FLOOR(NUMERATOR2 / DENOMINATOR) END) AS PROVISIONAL_DIVISION_VALUE_2, -- 0割エラー防止。FLOORが大事。無いと小数が出る
(CASE WHEN DENOMINATOR = 0 THEN 0 ELSE CAST(NUMERATOR2 AS DECIMAL) / DENOMINATOR END) AS RAW_DIVISION_VALUE
FROM
(SELECT
p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no, p_t_line_no,
<field値引前単価>, -- [比例算出売価] 比例按分計算元の売価。0 以上の正の数である事。
<field値引前伝票値引額>, -- [伝票単位の按分元] 按分元の値引明細などの売価。0 以上の正の数である事。
-- ★修正 ver3.桁オーバーフロー対策 ---->
-- CAST(<field値引前伝票値引額> AS BIGINT) * <field値引前単価> AS NUMERATOR2, -- 分子 [伝票単位の按分元] * [売価]
CAST(<field値引前伝票値引額> AS DECIMAL(38,4)) * CAST(<field値引前単価> AS DECIMAL(38,4)) AS NUMERATOR2, -- 分子 [伝票単位の按分元] * [売価]
-- SUM(<field値引前単価>) OVER (PARTITION BY p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no) AS DENOMINATOR -- 分母 [比例算出売価]
SUM(CAST(<field値引前単価> AS DECIMAL(38,4))) OVER (PARTITION BY p_t_shop_cd, p_t_check_date, p_t_service, p_t_pos, p_t_check_no) AS DENOMINATOR -- 分母 [比例算出売価]
-- <---- ★修正 ver 3.桁オーバーフロー対策
FROM
[t_計算用の販売ワークテーブル]
) T1
) T2
) T3
) T4
ON
[t_計算用の販売ワークテーブル].p_t_shop_cd = T4.p_t_shop_cd
AND [t_計算用の販売ワークテーブル].p_t_check_date = T4.p_t_check_date
AND [t_計算用の販売ワークテーブル].p_t_service = T4.p_t_service
AND [t_計算用の販売ワークテーブル].p_t_pos = T4.p_t_pos
AND [t_計算用の販売ワークテーブル].p_t_check_no = T4.p_t_check_no
AND [t_計算用の販売ワークテーブル].p_t_line_no = T4.p_t_line_no -- 行番号まで結合させる
基本的には、KAZAMAI_NaruTo 様の記事の通りです。
が、上記★修正の部分が重要です。
システムによっては数量と金額を誤打し「5800円を1個」と入力するところを「1円を5800個」と誤入力するパターンがあり、彼のSQLでは桁オーバーフローします。
ここの値はかなり大きくなりますので(元の値段 x 値引きたい数ぐらいの桁になります)、例外データクレンジングが事前にできないシステム用に、CAST ~ AS DECIMAL(38,4)というかなり広いメモリ空間を割り当てています。(そんなに負荷は高くならないです)
あとは、彼の計算は結果出力、上記ではT3のサブクエリまでを実施していますが、バルク出力バッチ処理の場合、結果をDBへ書くほうが処理が速いケースがあります。
プログラムのオンメモリを使うよりDBのメモリの方が速い場合が多いのです。
そのためT4までサブクエリを投げ、テーブルの自己再起結合で自分のテーブルを見て、自分のテーブルに結果を書くということになります。
あとはプログラム側でデータをText出力するなり、どこかのDBに放るなりで問題ないと思います。
以上です。
上記SQLを日常生活で欲する人は少ないと思いますが(汗)、かなり高速で正しい数字を出します。
Stored Procedure化するとかなり高速に計算しますのでオススメです。
いつもみなさんに頂いてばかりですから、私も貢献しておきます。