Outcomes over Output: Productivityの高い組織への変革

Outcomes over Outputとは「Output (つくったもの) よりもOutcome (成果) に目を向ける」というシンプルで本質を表した概念です。
最近邦訳版が出版されたMelissa Perri著「プロダクトマネジメント - ビルドトラップを避け顧客に価値を届ける」では、Output志向の問題をビルドトラップという言葉で表現しています。Silicon Valley Product Groupの記事 "Product vs. Feature Teams" では、Product TeamはOutcome志向でFeature TeamはOutput志向のように対比しています。そのままのタイトルの本 "Outcomes Over Output: Why customer behavior is the key metric for business success" (Joshua Seiden著) もあります。
この記事では、Outcomes over OutputとProductivity、そして組織を結び付けて解説します。少し時間が空いてしまいましたが、2020年7月21日のDevelopers Summit (通称デブサミ) 2020 Summerで発表したスライドに説明を加える形で書いていきます。
そもそも生産性とは
生産性とは何を表すのでしょうか?これは人によって大きく認識の異なる言葉です。この記事では、英語のProductivityとして生産性を説明します。
元々Productivityは、動詞のProduce (生産する) に「…の性質・傾向・活動をもつ」という接尾語ivityが付加されてできた単語です。つまり、Productivityは生産する活動の度合いを意味し、それはよくOutput/Input (投入量あたりの生産量) と表現されます。

しかし、生産性をこのように認識することは辞書どおりの説明の落とし穴だと私は思います。プロダクト (Product) を開発して提供する会社では、Productivityを名詞のProductと接尾語ivityの合成語として捉えるべきと考えます。
では、Productとは何でしょうか?最も抽象度の高いレベルで言うと、Productは会社のMissionやVisionを達成するためのものです。Mission/Visionが達成するということは、Productによってお客さまの行動を変えるということです。つまり、お客さまが価値を認めて使うものがProductであり、最終的に計測される数値としてKGI (Key Goal Indicator) を上げるものがProductです。
*KGIは会社のステージ・状況により異なります。Active User数、売上、利益率などがあります。
このように考えると、ProductivityはMissionやVisionを達成するための活動の度合いを表します。それはお客さまの行動を変えるための活動の度合いであり、さらにお客さまが価値を認めてProductを使ってくれるための活動の度合いであり、最終的な数値としてはKGIを上げるための活動の度合いと言えます。

では、Outcomes over Outputの考えをProductivityと結びつけてみます。Output (つくったもの) にばかり注目していると、それはProductの成果になっているか不明な状態になってしまいます。Productがお客さまの行動を変えているか不明ですし、お客さまの価値になっていないかもしれないからです。さらに最終的にKGIを上げているかも不明です。
Outcome (成果) に目が向いている場合、それはProductが成果を出しているかきちんと認識している状態です。Productがお客様の行動を変えている、つまりお客さまがProductの価値を認めて使っている状態であり、最終的にはKGIを上げている状態です。

Inputとなる社員の仕事からOutcome (成果) まで繋げて考えると以下の図のようになります。Inputとなる社員の仕事が組織に集まり、そのOutput (つくったもの) までしか注目しないのが狭い意味での生産性です。そこからさらにOutputがOutcome (成果) になっているかまで注目するのが真の広い意味での生産性でありProductivityです。真の広い意味での生産性を得るためには、成果となるか不明瞭なOutputが成果に結びつくように事前に考えて行動をとる必要があります。

「不明瞭なOutputが成果に結びつくように」と書きましたが、プロダクト開発においては2つの不確実性として表現されます。目的不確実性と方法不確実性です。目的不確実性はWhyやWhatに相当するもので、何をつくればお客さまに受け入れられるか不確実なことです。方法不確実性はHowやWhenに相当するもので、どのようにつくるか、どのようにつくれば効率的か、あるいはいつできるか不確実なことです。
*広木大地さんの「エンジニアリング組織論への招待」では通信不確実性についても書かれていますが、この記事ではシンプルに2つの不確実性のみ言及します。

これら不確実性を減らしていくための組織やプロセスを構築していくことが重要です。目的不確実性に対しては、機能をつくることだけに満足せず、OutputがOutcome (成果) になっているか検証・学習して改善する組織やプロセスをつくります。方法不確実性に対しては、検証のためのOutputを頻度高く出せる組織やプロセスをつくります。これらを満たすと適応力、成果の再現性、勝つ確率が高いと言えます。

目的不確実性と方法不確実性を削減するプロセスとして、デザイン思考 (Design Thinking)・リーンスタートアップ (Lean Startup)・アジャイル (Agile) を組み合わせたものが有名です (紹介記事)。デザイン思考とリーンスタートアップで目的不確実性を減らし、アジャイルで方法不確実性を減らします。
この記事では、指標を用いながらどのように目的不確実性と方法不確実性を減らしていくかを見ていくことにします。
目的不確実性を減らす
目的不確実性を減らすのは、図の右側半分に相当します。OutputがOutcome (成果) になっているか検証・学習することです。

そのためには、お客さまにとっての価値の検証を頻度高く回すことが不可欠です。長い期間WIP (Work In Progress: 作業中) の状態を続けて最後に大きなリリースをするのでなく、こまめにリリースを繰り返すのです。時間をかけて大きなリリースをしてもそれがお客さまに価値があるか不確実なままですが、小さなリリースを重ねればその間にお客さまの反応を元に学習して不確実性を下げることができます。

また、WIPはお客さまから見てまったく価値がないと気づくことも重要です。チームがどれだけ忙しく開発を続けたとしても、お客さまにはまったく価値が届いていないのです。これがアジャイル開発でWIP制限する理由のひとつです。一方で、リリースを繰り返していくことは、その度に検証中ではあるもののお客さまにとって価値がある可能性があります。お客さまの反応を見ながら方向性を正していくことで実際に価値に繋げることができます。

では検証のために計測するにはどうすれば良いでしょうか?重要なことは、大枠で捉える指標から計測することです。

この記事の読者はEngineering Backgroundを持っている方が多いと思うので、Engineeringを例にして考えてみます。Mike Julian著 "Practical Monitoring" (日本語版: 入門 監視) では以下のように書いています。
- The first check is an HTTP GET / (non-200 response codes, latency)
- This one check gives a wealth of information that the webapp is actually working.
動作していることの監視として、お客さまに接する大枠から計測することが基本と説明しています。そのハイレベルなチェックの例として、"HTTP GET /" の監視がウェブアプリケーションが実際動作しているか示す大きな情報と説明しています。

EngineeringからKPIマネジメントに視点を移しても同様です。中尾隆一郎著「最高の結果を出すKPIマネジメント」では、以下の順でKPIを設計することを説明しています。
1. KGI (Key Goal Indicator) = 最終的な目標数値
2. CSF (Critical Success Factor) = 最重要プロセス
3. KPI (Key Performance Indicator) = 最重要プロセスの目標数値
KPIマネジメントの視点でも、ゴールとなる大枠からモデル化して可視化・指標化することが重要だとわかります。

少しだけ具体的な話に移そうと思います。大きな会社になると、複数チームで1つのプロダクトを開発することはよくあります。この場合、1回のリリースで複数の機能 (あるいはユーザ体験) が追加されることがあります。複数機能が1リリースでまとめてユーザに提供されると、どの機能がどの指標に影響を与えたか判別できない問題が発生します。

この問題の解決策として、A/Bテスト (Online Controlled Experimentなどとも呼ばれる) を導入することがよくあります。これはお客さまを複数のグループ (Bucket = バケツとも呼ぶ) に分け、グループごとに見せる機能範囲に違いを出す手法です。プラセボ (偽薬) と実際の薬をグループごとに使い分けて薬の有効性を検証する手法があります。これをオンラインサービスに適用したものなのです。Controlグループに振り分けられたお客さまには新しい機能は見せず、特定のTreatmentグループに振り分けられたお客さまにだけ特定機能を見せるようにします。ControlグループとTreatmentグループを比較することにより、他の機能から切り分けて特定機能が指標に与えた変化を計測することができます。

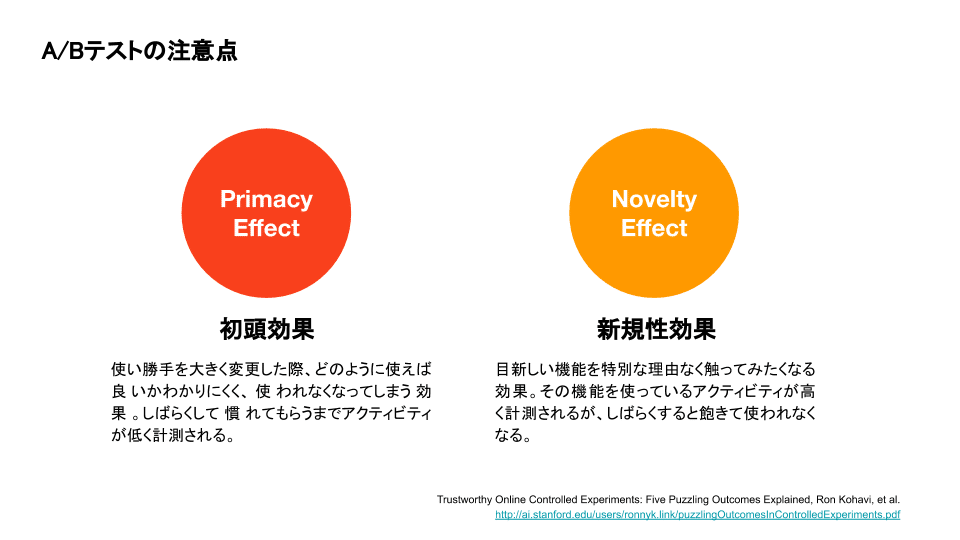
A/Bテストには注意する点があります。A/Bテストの第一人者Ron Kohaviの論文 "Trustworthy Online Controlled Experiments: Five Puzzling Outcomes Explained" から新機能リリースに関するもの2つを紹介します。
1つ目はPrimacy Effect (初頭効果) です。これは、ナビゲーションなど使い勝手を大きく変更した際、どのように使えば良いかわからず、効率よく使えなくなってしまう現象です。しばらく慣れてもらうまでアクティビティが低く計測されます。
2つ目はNovelty Effect (新規性効果、あるいは新奇性効果) です。これは逆に、目新しい機能を特別な理由なく触ってみたくなる現象です。新機能を使っているアクティビティが高く計測されますが、しばらくすると飽きて使われなくなったりします。
Primacy Effectが出た場合、リリース直後は結果が悪いように見えてもしばらく経つと狙った結果が出てきます。Novelty Effectが出た場合は、リリース直後は結果が良いように見えてもしばらく経つと良い結果ではなかったと結論づけられることになります。対象にもよりますが、一喜一憂せずに最低でも数週間はA/Bテストを続けることが必要です。
以下、目的不確実性についてまとめのスライドです。

方法不確実性を減らす
次に方法不確実性を減らすことに話を移します。下の図で言うと左側半分のパートに相当します。アジャイル・スクラムなどのプロセスは他の記事に譲るとして、ここでは指標に関して見ていきます。

ソフトウェア開発を行う組織のパフォーマンスについて大規模調査をまとめた本として、Nicole Forsgren著 "Accelerate: The Science of Lean Software and DevOps" (日本語版「LeanとDevOpsの科学」) が有名です。以下を満たす指標としてデリバリのパフォーマンス指標を定義しています。
- 各チームが衝突するのでなく、組織全体の成果にフォーカスすること
- OutputでなくOutcomesにフォーカスすること (組織全体のゴールの達成に繋がらないのに、仕事が忙しいことで評価しないこと)
この本でも、Outcomes over Outputの考えに従っています。単にOutput量を表す指標でなく、その先のOutcome (成果) に相関性がある4つの指標を出しています。
1. Delivery lead time (デリバリのリードタイム)
2. Deployment frequency (デプロイ頻度)
3. MTTR (Mean time to restore: 平均修復時間)
4. Change fail percentage (変更失敗率)
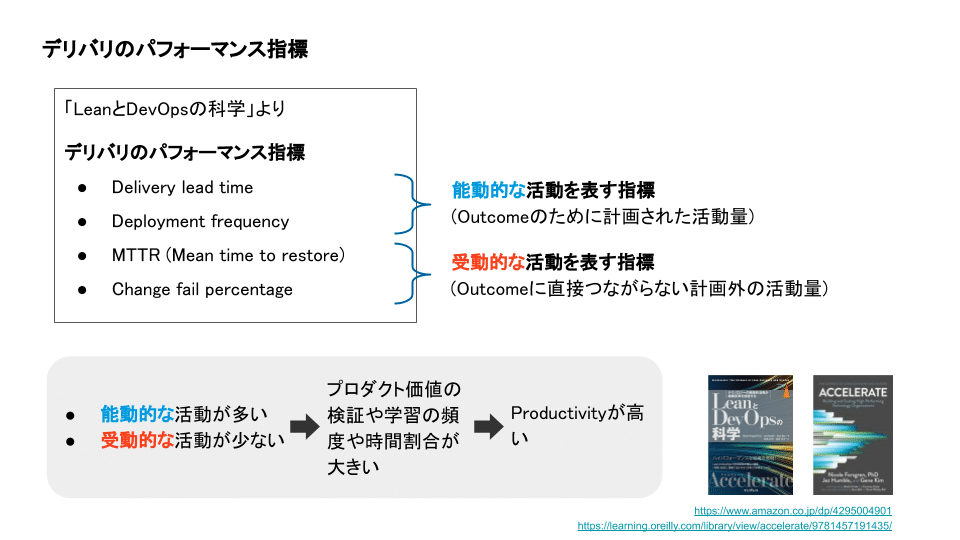
Delivery lead timeとdeployment frequencyは、開発結果をお客さまに届けるデリバリのテンポを表す指標です。これらはお客さまにとっての価値を届ける能動的な活動を表す指標と言えます。つまり、Outcome (成果) のために計画された活動量です。MTTRとchange fail pecentageはシステムの安定性を表す指標です。これは、障害対応など受動的な活動を表す指標と言えます。つまり、Outcome (成果) に直接つながらない計画外の活動量です。
Outputを出す場においても、Outcome (成果) を基準に考えることが重要です。それが真の意味のProductivity (生産性) を高めることになります。Outcome (成果) のための能動的な活動が多く、Outcome (成果) にならない受動的な活動を少なくできる開発組織は、価値検証の頻度や時間割合を多くできる状態です。つまり、組織の方法不確実性が低い状態です。これをデリバリのパフォーマンス指標として計測しているのです。
では、実際にデリバリのパフォーマンス指標を計測し始めると何を経験するでしょうか?それは、なかなか指標が改善しないことです。
先に説明したKGIと同様に、組織状態を大枠で捉えた指標は遅行指標であることが多いです。これは改善の行動をとってから計測できる結果に現れるまでに時間差がある指標です。これに対し、時間差が小さな先行指標を設定することがポイントです。その際に、遅行指標と無関係な指標は先行指標となりません。組織の大きな目標を表す指標 (目的変数) に対し、それを分解した施策やアクションの結果となる指標 (説明変数) をとります。遅行指標がすぐに改善しなくても焦らずに、先行指標を見ながら日々の施策やアクションをとっていきます。

デリバリのパフォーマンスを改善する施策やアクションとして、Accelerate (LeanとDevOpsの科学) では以下のカテゴリに分けて例を書いています。
- Continuous delivery (継続的デリバリ)
- Lean management and monitoring (リーンなマネジメントとモニタリング)
- Architecture (アーキテクチャ)
- Product and process (プロダクトとプロセス)
- Culture (文化)

これらを参考に、組織の課題のうち最もレバレッジの効くものを見つけ、その解決を先行指標として追っていくと良いでしょう。
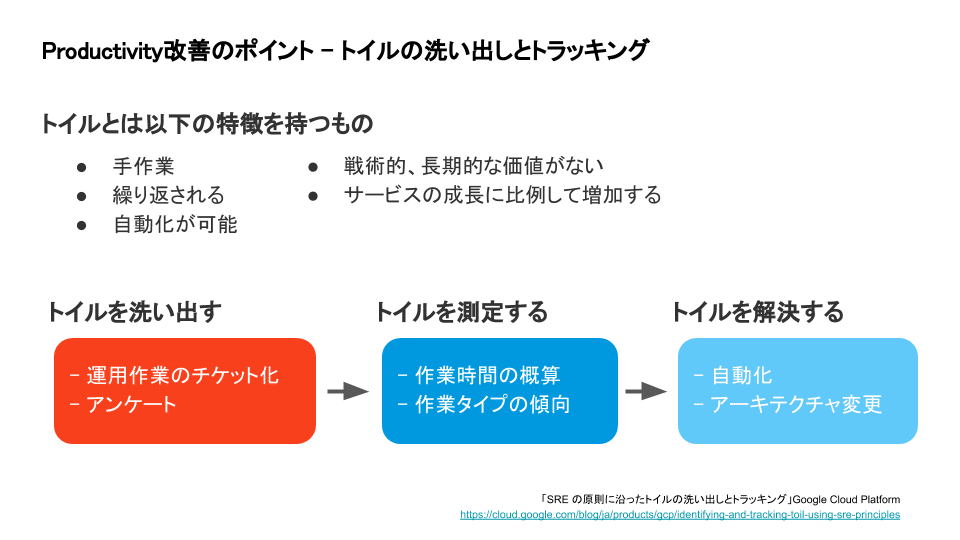
受動的な活動の削減によるProductivityの改善については、Google Cloudのブログ記事「SRE の原則に沿ったトイルの洗い出しとトラッキング」も参考になります。手作業・繰り返し・長期的な価値がないなどの特徴を持ったトイルの洗い出しから改善まで具体例とともに書かれています。システムから取得できるデータの他に、アンケートをとる方法も書かれています。
組織の変革
目的不確実性や方法不確実性を削減できる組織をつくるのは、組織の変革と言えるほどに難易度の高いものです。それは集団の習慣を変えるからです。集団での例として、エスカレーターの片側にだけ立つ習慣があります。反対側を歩く人による危険性をなくすため、片側でなく両側に立つ習慣に変えようとする取り組みがあります。ですが、定着した習慣をなかなか変えられない難しい課題になっています。
Google Cloudの記事 "DevOps culture: How to transform" では、組織の変革においても、プロダクト同様に改善の繰り返しが必要と説明しています。1回の取り組みだけでは十分に変化しないですし、変化したとしてもそれが新な課題を産む場合もあります。そのため、一定期間 (イテレーション) ごとに現状と目標を認識し、その差を埋める改善アクションを継続していきます。

以下、方法不確実性についてまとめのスライドです。

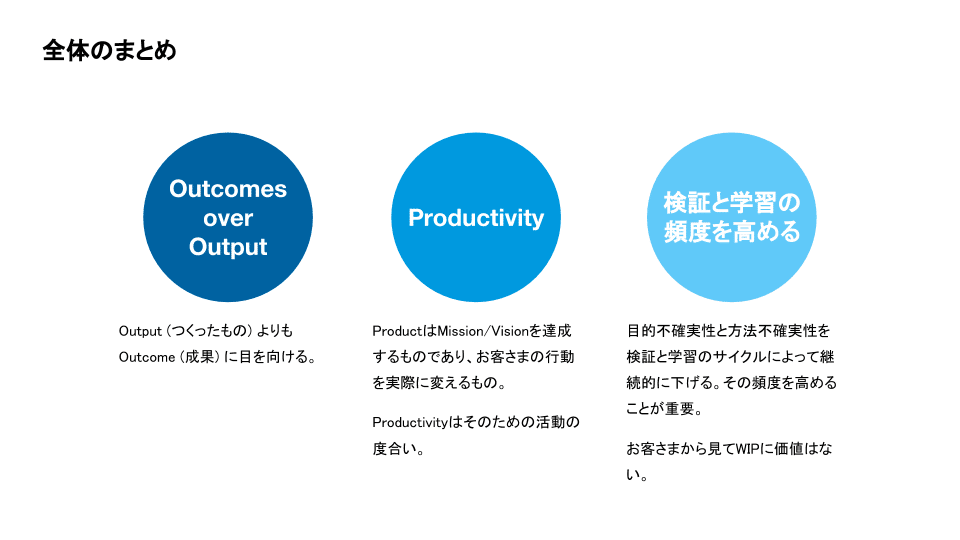
まとめ
Outcomes over Outputというシンプルな表現で、Output (つくったもの) よりもOutcome (成果) に目を向ける重要性を説明しました。Productivityは単にOutputを出す効率ではなく、お客さまの価値となってお客さまが実際に行動を変えるようなProductをつくる活動度合いを表します。そのようなProductをつくるために、目的不確実性と方法不確実性を削減していきます。検証と学習のサイクルをつくりその頻度を高めることが重要です。
以上、Outcome志向となって、真の意味でProductivityの高い組織やプロセスをつくっていく助けになれば幸いです!