河合塾全統記述模試と駿台全国模試の偏差値変換モデル【全面修正】

駿台全国模試の目標ラインの定義を私が勘違いしていたことが判明しました。記事の内容を全面的に修正しています。間違った解釈で分析結果を公開していたこと、お詫びいたします。
ただし、全統記述模試の判定偏差値は2.5刻みのランク制なので、全統記述模試の数値で+3.3の修正が全体で行われただけです(2次回帰の切片の変更のみ)。そのため、分析の骨格は大きく変わっていません。(2024.10.12)
最近の全統記述模試の東大理一C判定偏差値を見たら、67.5になってました。この記事は理一C判定70.0の時期に作成しています。事例で引用している個別大学の判定偏差値はタイミングによって変動していると思われます。そのため、駿台全国=全統記述−7の補正値「7」もタイミングによって変動するはずです。その点はご留意ください。(2025.1.12)
高校生の子供が駿台全国模試を受けるようになりました。結果が帰ってきた時には偏差値を見るのですが、自分が高校時代に受けていたのが河合塾の全統記述模試だったので、数字をみても、どうにも直感的にわかりません。
2つの模試では母集団が違うので、もちろん偏差値の変換は厳密にはできません。ただ、インターネット上では、「駿台全国模試=全統記述模試−10」とか「全統記述模試ー7=駿台判定模試=駿台全国模試+3」(⇔駿台全国模試=全統記述模試−4)というような偏差値変換の記述が書き込まれています。
「この変換式のマイナス10とかマイナス4とかの数字は妥当か?根拠有るのか?」と思い、自分でデータを集めて検証してみました。やっていることは、統計の初歩の回帰分析だけです。
0. 結論(全統記述模試と駿台全国模試の偏差値変換モデル)
ざっくり言うと、全統記述模試の偏差値45〜70の範囲なら「駿台全国模試=全統記述模試ー7」でした。逆に見れば、駿台全国模試の偏差値が41〜66の範囲で「全統記述模試=駿台全国模試+7」となります。
分析から考案した変換モデルは以下となります。全統模試の偏差値をK、駿台全国模試の偏差値をSで表現しています。^記号は累乗です(S^2はSの2乗)。
◆概算する場合
全統記述模試の偏差値
40未満: S = K +2
40以上45未満: S = K ー 2
45以上50未満: S = K ー 5
45以上50未満: S = K ー 7
50以上55未満: S = K ー 9
55以上60未満: S = K ー 9
60以上65未満: S = K ー 9
65以上70未満: S = K ー 9
70以上: S = K −6
※45以上70未満の区間の平均で、S = K ー 7
◆回帰式で計算する場合
K = -0.0196 x S^2 + 3.1496 x S -50.821
(二次回帰、決定係数=0.9937)S = 0.0191 x K^2 - 1.3153 x K + 62.076
(二次回帰、決定係数=0.9856)
1. 変換モデルの考え方
「全統記述模試と駿台全国模試は模試を受験する母集団の特性が違うので、2つの模試の偏差値は比較できない」というのが一般論です。実際に東大理一のボーダー偏差値も、全統記述模試では70(C判定50%)=75(A判定80%)に対して、駿台全国模試では68(目標ライン80%)と違います。
でも、模試を受験した母集団は違っても、その中の標本としての「全統記述模試の受験者のうち東大理一の受験者の標本」と「駿台全国模試の受験者のうち東大理一の受験者の標本」は、「東大理一の受験者」という同じ母集団にも属するはずです。つまり、それぞれは「東大理一の受験者のうち全統記述模試の受験者の標本」と「東大理一の受験者のうち全統記述模試の受験者の標本」とも言えるはずです。
そうであれば、それぞれの予備校が過去の統計から算定して同じ合格率になる偏差値であれば、模試が違っても東大理一受験者の母集団の中では同じ学力の集合になるはずです。こう考えると、何らかのやり方で、2つの模試の偏差値を変換することはできそうです。
ところが、全統記述模試では東大のボーダーは、理三以外は全て70.0なのに対して、駿台全国模試では文一:67、文二:67、文三:66、理一:68、理二:66とバラバラです。他の大学・学部でも同様に、2つの模試のボーダー偏差値の関係にはバラツキがあります。
バラツキがあるなら、データ数を増やして統計処理をすれば、一般化した変換モデルを作れるはずです。そこで、全統記述模試と駿台全国模試の偏差値の関係を、以下の手順で統計分析してみました。
2. 分析対象の母集団
全統記述模試と駿台全国模試の両方でボーダー偏差値の設定のある国公立大学の学部学科を分析対象としています。私立大学は受験科目の差や入試形式がいろいろあるのと、併願受験ができるので、バラツキが大きくなりすぎる懸念があり、除外しています。
同じ大学でも、学部学科ごとに募集され、ボーダー偏差値が設定されている場合は、異なるデータとして扱います。また、同じ学部学科でも入試形式が違うことがあります。例えば、北海道大学・総合入試理系に化学重点・数学重点などがあるケースです。このように入試形式ごとにボーダー偏差値が設定されている場合は、入試形式ごとに異なるデータとして扱います。さらに、前期日程・後期日程などの違うも異なるデータとして扱います。
結果、分析対象の母集団は125大学の1,911データとなっています。
データは2つの変数を持ちます。1つは全統記述模試の80%合格率偏差値(C判定+5)、もう1つは駿台全国模試の80%合格率偏差値(目標ライン)です。駿台全国模試の判定偏差値は学年ごと(開催回ごと)に変動しますが、目標ラインは調べたところ高3の偏差値(浪人含む母集団)の数字のようです。全統記述模試は2023年7月時点、駿台全国模試は2023年3月時点の偏差値の数値を採用しています。
なお、全統記述模試の偏差値は大学ごとの科目・配点の加重平均ですが、駿台全国模試の目標ラインは科目や国私立の違いの補正後です。そのため、本来はそのまま比較はできません。ただ、今回は国立大学が分析対象であり、科目数にそれほど大きな違いはないため、科目数の調整は行っておりません。
データのサンプルはこのようなものになります。前にある数字が全統記述模試の偏差値(A判定80%)、後ろにある数字が駿台全国模試の偏差値(目標ライン80%)です。
東京大学理科一類・前期:(75.0、68)
※類型で募集、前期日程のみ横浜市立大学・国際教養学部・国際教養学科・A方式・前期:(62.5、52)
横浜市立大学・国際教養学部・国際教養学科・B方式・前期:(67.5、53)
※方式ごとにデータを作る一橋大学・経済学部・経済学科・前期:(70.0、63)
一橋大学・経済学部・経済学科・後期:(72.5、71)
※前期と後期にわけてデータを作る
3. データ分布と回帰分析
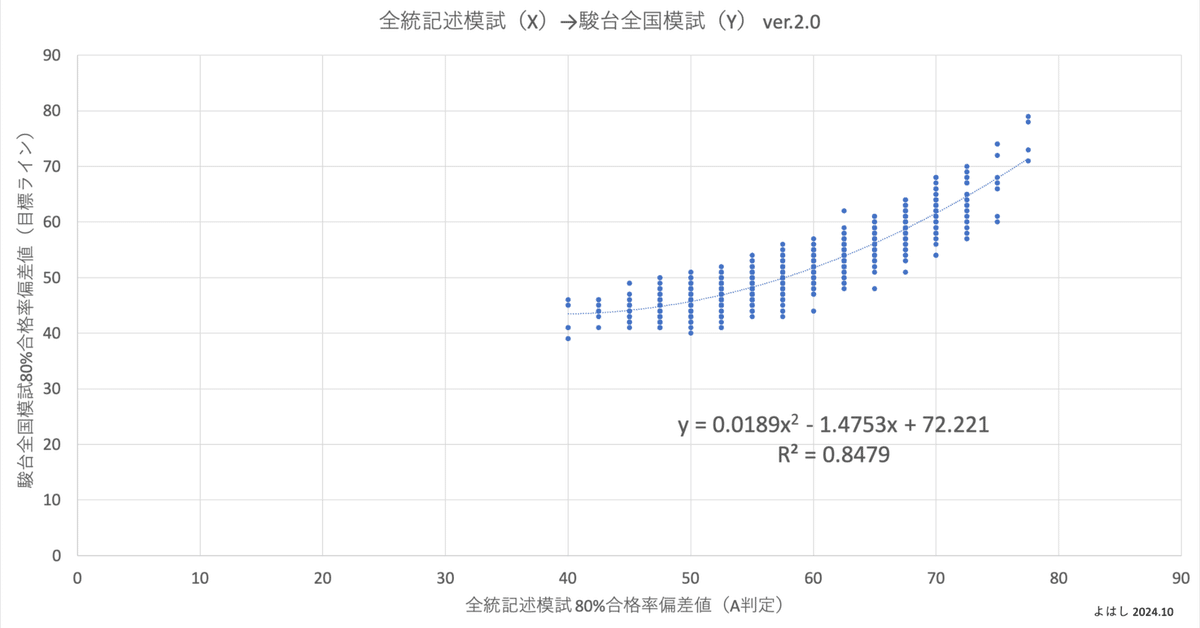
この母集団(1,911データ)に対して、横軸(X)を全統記述模試の80%合格率偏差値、縦軸(Y)を駿台全国模試の80%合格率偏差値とした場合、散布図はこうなります。回帰分析は1次回帰より2次回帰の方が相関係数が高いため、2次回帰で回帰式を算定しています。

同じ母集団に対して、横軸と縦軸を逆転させた散布図はこうなります。

どちらを見ても、2つの模試の偏差値には一定の相関があることがわかります。ただ、全統記述模試のボーダー偏差値が2.5刻みなので、同じ全統記述模試の偏差値でも、駿台全国模試の偏差値は10程度の幅で分布してしまっています。
これに対して、もう一段の統計処理を行います。
4. 同一偏差値の標本の分布
グラフ2のY軸(全統記述模試の80%合格率偏差値)が55.0のデータを抽出した標本を作ってみます。この標本には、例えば、以下のようなデータが含まれます。
東京農工大・農学部・地域生態システム学科・前期:(55.0、54)
岐阜大学・工学部・化学学科・生命化学・前期:(55.0、48)
北九州大学・国際環境工学部・情報システム学科・後期:(55.0、43)
この標本(全統記述模試の80%合格率偏差値=55.0)には、317のデータが含まれています。そのデータを、駿台全国模試の80%合格偏差値ごとに度数集計したヒストグラムはこうなります。

正規分布にかなり近い分布をしていることが見てわかると思います。検証のために、他の偏差値帯でも同じようにヒストグラムを作ってみると、同様に正規分布に近い分布をしています。

全統記述模試の80%合格率偏差値が同じ数値のデータを抽出しているので、この標本は無作為抽出ではありません。ただ、河合塾でボーダー偏差値を設定した社員が、標本の大学・学部・学科に対して有為に同じボーダー偏差値を設定したとは考えにくいです。結果として、偶然にも同じボーダー偏差値が設定され、この標本ができたと考える方が自然です。
そして、この標本はそこに含まれる大学・学部・学科を受験した学生の母集団が背後にあります。例えば、全統記述模試の80%合格率偏差値が55.0の大学・学部・学科(317データ)を集めた標本は、偏差値55.0〜57.4)の学生の母集団から抽出された標本でもあります。
ここで、一つ一つの大学・学部・学科の駿台全国模試の80%合格率偏差値は、そこを受験した受験生の標本平均と同等に扱えると仮定します。これはその偏差値=標本平均の分布が正規分布になっていることから、中心極限定理を元に、概ね正しと言えそうです。
そうなると、やや強引に中心極限定理を適用すると、それぞれの大学・学部・学科データの駿台全国模試の80%合格率偏差値(=標本平均)の平均は、全統記述模試の80%合格率偏差値が55.0の受験生全体(=母集団)の平均値に近似できるのです。
このように考えると、全統記述模試の80%合格率偏差値が同じデータに対して、駿台全国模試の80%合格率偏差値の平均を計算すれば、2つの模試の間の偏差値の変換を行っていることになるのです。
※前に書きましたが、大学で統計学を専攻したわけでなく、2コマしか取っていないので、アカデミズムの文脈で正しいかどうかはわかりません。
5. 同一偏差値の標本平均に対する回帰分析
このロジックを元に、全統記述模試の80%合格率偏差値、駿台全国模試の80%合格率偏差値に対して、同じ数字のデータを集めた標本の平均を使って、散布図と回帰分析をしてみました。

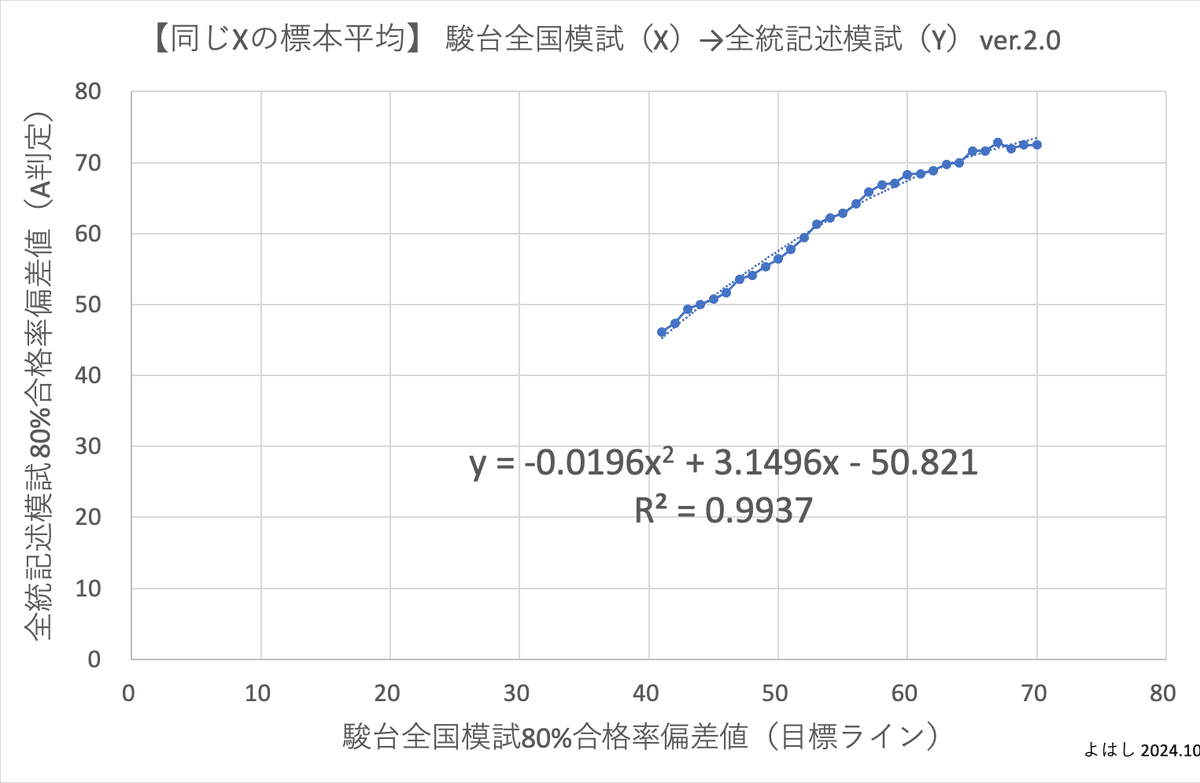
上記の前提が正しければ、このグラフは同じ学力の学生が全統記述模試と駿台全国模試を受験した場合に、それぞれの模試の偏差値がいくつになるかを示しています。そして驚くことに、決定係数は約0.99であり、2つの模試の偏差値はほぼ相関していると言えます。
6. 簡易計算表
上記の通り、全統記述模試の偏差値と駿台全国模試の偏差値は2次回帰式で変換可能であることがわかりました。ただ、2次回帰は計算が一手間かかるので、簡易計算できるようにグラフの点(標本平均のデータ)を集計したのが、この表です。

扱いやすいように、全統記述模試の偏差値5の幅で集約しています(緑の表)。たとえば、全統記述模試の偏差値が57.0の人は55以上60未満の幅に入るので、駿台ー全統の偏差値の差は-8.5です。つまり、全統記述模試の偏差値57.0から8.5を引いた48.5が駿台全国模試の偏差値になります。
ただし、40未満と70以上はデータ数が少なく、精度が低いと考えられます。また、45未満は定数の正負が逆転しています。そのため、これらを除外して、全統記述模試の偏差値が45以上70未満の区間(薄緑)で定数を計算すると、-7.2となりました。
つまり、概算であれば、「全統記述模試の偏差値が45以上70未満の区間では、駿台全国模試の偏差値=全統記述模試の偏差値 − 7」であると言えます。
7. まとめ
上記の分析から、全統記述模試の偏差値が45以上70未満の区間では、全統記述模試と駿台全国模試の偏差値の差は、「7」と算定されました。細かく見る場合は、冒頭の結論にある変換式を使ってください。
なお、親の世代(1990年代)から子の世代(現在)の間で、大学進学率が上がったことで、模試を受ける母集団が変わっています。おそらく、駿台全国模試の母集団はほぼ変わらず、全統記述模試の母集団が下に膨らんだと思います。
以前に記事にしましたが全統記述模試の偏差値は、今の45以上70未満の区間では、親の世代よりも3〜7くらい大きい数字になります。そのため、ざっくり計算するなら、こんな感じです。
全統記述模試の偏差値(現在) = 全統記述模試の偏差値(親の世代)+5
駿台全国模試の偏差値(現在) = 全統記述模試の偏差値(親の世代)−2
趣味の分析としては以上となります。