
APIを使ったFF-Dataによる訪日外国人の動態分析

国土交通省が出しているFF-Data(Flow of Foreigners-Data:訪日外国人流動データ)があります。
オープンデータとして提供されているのでダウンロードすれば誰でも利用でききます。
今回はこのデータを使って、外国人旅行者の動態分析をしてみたいと思います。
はじめに:APIでデータを取得する
今回、このFF-Dataを利用するにあたりいくつかの方法を試しました。
RESAS-APIでのトライ
なんと、提供終了になるらしいのでスキップしました。流石に国の施策で簡単にAPIを止めるというのは。。
e-Stat-API
e-Statにも同様にデータがあるように見えます。分かりにくかったのですが、ここにはxlsのデータしかアップロードされておらず、APIではリクエストできないようです。
国土交通データプラットフォームのAPIを利用する
最終的にはこの方法を使いました。以下からAPIキーの取得ができます。
https://www.mlit-data.jp/#/DeveloperInfo?id=developerInfo_registerApp
「このサービスは、国土交通データプラットフォームの API 機能を使用していますが、最 新のデータを保証するものではありません。」
APIでFF-Dataを取得する
では、早速APIでFF-Dataを取得してみましょう
import os
import requests
import json
import pandas as pd
from typing import Union
# APIキーを環境変数から取得
API_KEY = mlit_api_key
if not API_KEY:
raise ValueError("環境変数MLIT_API_KEYが設定されていません。")
# MLITのAPIエンドポイント
END_POINT = "https://www.mlit-data.jp/api/v1/"
def send_request(query: str) -> dict:
"""MLITのAPIにリクエストを送信する関数"""
response = requests.post(
END_POINT,
headers={
"Content-type": "application/json",
"apikey": API_KEY,
},
json={"query": query},
)
response.raise_for_status()
return response.json()["data"]
def get_ffdata(year: Union[str, int]) -> pd.DataFrame:
"""指定した年のFF-Dataを取得する関数"""
graphql_query = """
query {
search(
term: "",
attributeFilter: {
attributeName: "DPF:dataset_id"
is: "ffd_%d"
}
first: 0,
size: 3000,
) {
totalNumber
searchResults {
id
metadata
shape
}
}
}
""" % year
data = send_request(query=graphql_query)
df = pd.json_normalize(data["search"]["searchResults"])
selected_columns = [
"id",
"shape.coordinates",
"metadata.DPF:year",
"metadata.FFD:departure_point",
"metadata.FFD:destination_point",
"metadata.FFD:bus",
"metadata.FFD:railway",
"metadata.FFD:taxi_n_chauffeur",
"metadata.FFD:rental_car",
"metadata.FFD:other_car",
"metadata.FFD:domestic_flight",
"metadata.FFD:other_transportation",
"metadata.FFD:transportation_unknown",
]
return df[selected_columns]
# データ取得
years = [2017, 2018, 2019, 2022] # 2020,2021はデータがない
ff_data = pd.concat(map(get_ffdata, years), ignore_index=True)
# データの整形
renamed_data = ff_data.rename(
columns={
"shape.coordinates": "geometry",
"metadata.DPF:year": "year",
"metadata.FFD:departure_point": "dept",
"metadata.FFD:destination_point": "dest",
"metadata.FFD:bus": "bus",
"metadata.FFD:railway": "railway",
"metadata.FFD:taxi_n_chauffeur": "taxi",
"metadata.FFD:rental_car": "rental_car",
"metadata.FFD:other_car": "other_car",
"metadata.FFD:domestic_flight": "domestic_flight",
"metadata.FFD:other_transportation": "other",
"metadata.FFD:transportation_unknown": "unknown",
}
)
# データを縦持ちに変換
longer_data = pd.melt(
renamed_data,
id_vars=["id", "geometry", "year", "dept", "dest"],
value_vars=[
"bus",
"railway",
"taxi",
"rental_car",
"other_car",
"domestic_flight",
"other",
"unknown",
],
var_name="mode",
value_name="n",
)
# 結果の表示(最初の10行)
print(longer_data.head(10))
# データの保存(オプション)
longer_data.to_csv("ff_data.csv", index=False)おおよそこのようなデータが取得できるはずです。
id,geometry,year,dept,dest,mode,n
b4b7abff-c417-4c1d-b462-96f2cf4ffbcb,"[[141.15277777777777, 39.703611111111115], [136.62555555555556, 36.594722222222224]]",2017,岩手,石川,bus,0.0
fba64210-c0f8-40c3-a7d5-4de964fa7ca5,"[[141.15277777777777, 39.703611111111115], [138.56833333333333, 35.663888888888884]]",2017,岩手,山梨,bus,0.0
出発地から目的地に対して、なんの経路で移動したか、が書かれているようです。
分析に使ったソースコード:python
以下で実装しています。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語フォント対応のためのライブラリ
# CSVファイルを読み込む
ff_data = pd.read_csv('ff_data.csv')
# 都道府県リスト(47都道府県)
prefectures = [
'北海道', '青森', '岩手', '宮城', '秋田', '山形', '福島', '茨城', '栃木', '群馬',
'埼玉', '千葉', '東京', '神奈川', '新潟', '富山', '石川', '福井', '山梨', '長野',
'岐阜', '静岡', '愛知', '三重', '滋賀', '京都', '大阪', '兵庫', '奈良', '和歌山',
'鳥取', '島根', '岡山', '広島', '山口', '徳島', '香川', '愛媛', '高知', '福岡',
'佐賀', '長崎', '熊本', '大分', '宮崎', '鹿児島', '沖縄'
]
# 1. 各出発地からの総移動回数(移動量を考慮)
dept_counts = ff_data.groupby('dept')['n'].sum().sort_values(ascending=False)
print("各出発地からの総移動量:")
print(dept_counts)
print("\n未出現の出発地:")
print(set(prefectures) - set(dept_counts.index))
# 2. 各目的地への総移動回数(移動量を考慮)
dest_counts = ff_data.groupby('dest')['n'].sum().sort_values(ascending=False)
print("\n各目的地への総移動量:")
print(dest_counts)
print("\n未出現の目的地:")
print(set(prefectures) - set(dest_counts.index))
# 3. 最も多い移動ルート
route_counts = ff_data.groupby(['dept', 'dest'])['n'].sum().sort_values(ascending=False)
print("\n最も多い移動ルート:")
print(route_counts.head(10))
# 4. 移動のない都道府県ペア
all_pairs = pd.MultiIndex.from_product([prefectures, prefectures], names=['dept', 'dest'])
existing_pairs = ff_data.groupby(['dept', 'dest']).size().index
missing_pairs = all_pairs.difference(existing_pairs)
print("\n移動のない都道府県ペアの数:", len(missing_pairs))
print("\n移動のない都道府県ペアの例(最初の10件):")
print(missing_pairs[:10])
# 5. 基本的な統計情報
print("\n移動量(n)の基本統計:")
print(ff_data['n'].describe())
# 6. 年別の移動量
yearly_movement = ff_data.groupby('year')['n'].sum()
print("\n年別の総移動量:")
print(yearly_movement)
# 7. 交通手段別の移動量
mode_movement = ff_data.groupby('mode')['n'].sum().sort_values(ascending=False)
print("\n交通手段別の総移動量:")
print(mode_movement)
# 8. 年別の交通手段別移動量
year_mode_movement = ff_data.groupby(['year', 'mode'])['n'].sum().unstack().fillna(0)
print("\n年別の交通手段別移動量:")
print(year_mode_movement)
# 9. 各都道府県からの移動量のヒートマップ
plt.figure(figsize=(16, 12))
heatmap_data = ff_data.pivot_table(index='dept', columns='dest', values='n', aggfunc='sum', fill_value=0)
# 都道府県コード順にソート
heatmap_data = heatmap_data.reindex(index=prefectures, columns=prefectures)
sns.heatmap(heatmap_data, cmap='YlGnBu', annot=False, fmt='g')
plt.title("各都道府県からの移動量ヒートマップ", fontsize=16)
plt.xlabel("目的地", fontsize=12)
plt.ylabel("出発地", fontsize=12)
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.tight_layout()
plt.savefig('./img/heatmap.png')
plt.show()
# 10. 交通手段別の移動量の棒グラフ
plt.figure(figsize=(12, 6))
mode_movement.plot(kind='bar')
plt.title("交通手段別の総移動量", fontsize=16)
plt.xlabel("交通手段", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('./img/mode_movement.png')
plt.show()
# 11. 年別の移動量の棒グラフ
plt.figure(figsize=(12, 6))
yearly_movement.plot(kind='bar')
plt.title("年別の総移動量", fontsize=16)
plt.xlabel("年", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig('./img/yearly_movement.png')
plt.show()
# ヒートマップ上の上位20都道府県のペアを抜き出して、それぞれのペアで交通手段別の移動量の棒グラフを作成する
top20_pairs = route_counts.head(20).index
for i, (dept, dest) in enumerate(top20_pairs):
# 出発地と目的地が一致するデータのみ抽出
pair_data = ff_data[(ff_data['dept'] == dept) & (ff_data['dest'] == dest)]
# 交通手段別の移動量を計算
mode_counts = pair_data.groupby('mode')['n'].sum()
# 棒グラフを作成
plt.figure(figsize=(12, 6))
mode_counts.plot(kind='bar')
plt.title(f"{dept}から{dest}への移動量(交通手段別)", fontsize=16)
plt.xlabel("交通手段", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.savefig(f'./img/mode_movement_{i}.png')
plt.show()
# ヒートマップの上位20個の都道府県のペアを移動量と一緒に棒グラフで表示
top20_pairs = route_counts.head(20)
plt.figure(figsize=(12, 6))
plt.bar(range(len(top20_pairs)), top20_pairs.values)
plt.xticks(range(len(top20_pairs)), [f"{dept}から{dest}" for dept, dest in top20_pairs.index], rotation=90)
plt.title("上位20都道府県ペアの移動量", fontsize=16)
plt.xlabel("都道府県ペア", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.tight_layout()
plt.savefig('./img/top20_pairs.png')
plt.show()分析1:各都道府県ごとの移動量のヒートマップ
次に、先ほどのデータを使って、dept,destの県のルートの数を表示してみましょう。
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib # 日本語フォント対応のためのライブラリ
# CSVファイルを読み込む
ff_data = pd.read_csv('ff_data.csv')
# 都道府県リスト(47都道府県)
prefectures = [
'北海道', '青森', '岩手', '宮城', '秋田', '山形', '福島', '茨城', '栃木', '群馬',
'埼玉', '千葉', '東京', '神奈川', '新潟', '富山', '石川', '福井', '山梨', '長野',
'岐阜', '静岡', '愛知', '三重', '滋賀', '京都', '大阪', '兵庫', '奈良', '和歌山',
'鳥取', '島根', '岡山', '広島', '山口', '徳島', '香川', '愛媛', '高知', '福岡',
'佐賀', '長崎', '熊本', '大分', '宮崎', '鹿児島', '沖縄'
]
# 1. 各出発地からの総移動回数(移動量を考慮)
dept_counts = ff_data.groupby('dept')['n'].sum().sort_values(ascending=False)
print("各出発地からの総移動量:")
print(dept_counts)
print("\n未出現の出発地:")
print(set(prefectures) - set(dept_counts.index))
# 2. 各目的地への総移動回数(移動量を考慮)
dest_counts = ff_data.groupby('dest')['n'].sum().sort_values(ascending=False)
print("\n各目的地への総移動量:")
print(dest_counts)
print("\n未出現の目的地:")
print(set(prefectures) - set(dest_counts.index))
# 3. 最も多い移動ルート
route_counts = ff_data.groupby(['dept', 'dest'])['n'].sum().sort_values(ascending=False)
print("\n最も多い移動ルート:")
print(route_counts.head(10))
# 4. 移動のない都道府県ペア
all_pairs = pd.MultiIndex.from_product([prefectures, prefectures], names=['dept', 'dest'])
existing_pairs = ff_data.groupby(['dept', 'dest']).size().index
missing_pairs = all_pairs.difference(existing_pairs)
print("\n移動のない都道府県ペアの数:", len(missing_pairs))
print("\n移動のない都道府県ペアの例(最初の10件):")
print(missing_pairs[:10])
# 5. 基本的な統計情報
print("\n移動量(n)の基本統計:")
print(ff_data['n'].describe())
# 6. 年別の移動量
yearly_movement = ff_data.groupby('year')['n'].sum()
print("\n年別の総移動量:")
print(yearly_movement)
# 7. 交通手段別の移動量
mode_movement = ff_data.groupby('mode')['n'].sum().sort_values(ascending=False)
print("\n交通手段別の総移動量:")
print(mode_movement)
# 8. 年別の交通手段別移動量
year_mode_movement = ff_data.groupby(['year', 'mode'])['n'].sum().unstack().fillna(0)
print("\n年別の交通手段別移動量:")
print(year_mode_movement)
# 9. 各都道府県からの移動量のヒートマップ
plt.figure(figsize=(16, 12))
heatmap_data = ff_data.pivot_table(index='dept', columns='dest', values='n', aggfunc='sum', fill_value=0)
# 都道府県コード順にソート
heatmap_data = heatmap_data.reindex(index=prefectures, columns=prefectures)
sns.heatmap(heatmap_data, cmap='YlGnBu', annot=False, fmt='g')
plt.title("各都道府県からの移動量ヒートマップ", fontsize=16)
plt.xlabel("目的地", fontsize=12)
plt.ylabel("出発地", fontsize=12)
plt.xticks(rotation=90)
plt.yticks(rotation=0)
plt.tight_layout()
plt.show()
# 10. 交通手段別の移動量の棒グラフ
plt.figure(figsize=(12, 6))
mode_movement.plot(kind='bar')
plt.title("交通手段別の総移動量", fontsize=16)
plt.xlabel("交通手段", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
# 11. 年別の移動量の折れ線グラフ
plt.figure(figsize=(12, 6))
yearly_movement.plot(kind='line', marker='o')
plt.title("年別の総移動量", fontsize=16)
plt.xlabel("年", fontsize=12)
plt.ylabel("移動量", fontsize=12)
plt.grid(True)
plt.tight_layout()
plt.show()
これをみると
東京から東京と、大阪から京都、と沖縄から沖縄のデータが数多くあるようです。沖縄から沖縄のデータが多いのは謎ですね。
分析2:総移動量
また、先ほどのコードで全国のデータを組み合わせて総移動量を表示することも可能です。
交通手段別で見てみると鉄道とバスが多いことがわかります。レンタカーは少ないですね。

年別の総移動量で見てみると2019まで右肩上がりでしたが、2022で大きく落ち込んでいます。コロナの影響か、2020,2021は調査データがありませんでした。

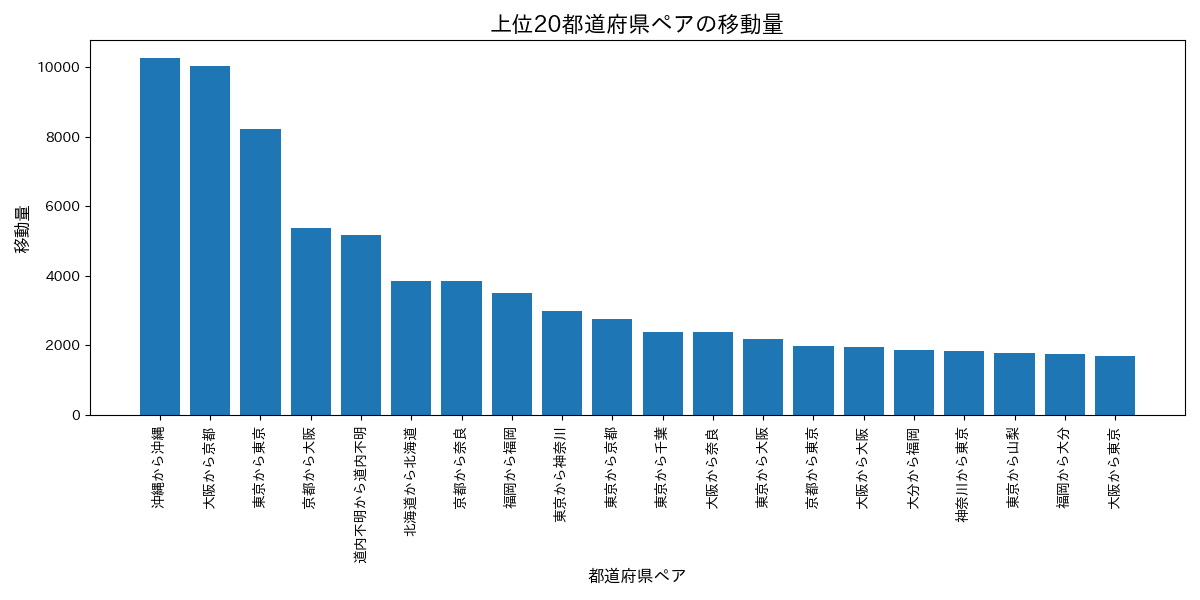
分析3:上位20都道府県の移動量が多いペア
先ほどのヒートマップのデータを棒グラフにしています。なぜか沖縄・沖縄の移動が多いのですが。。他のルートでどんな移動手段を使ったかを調査してみましょう。
沖縄から沖縄の移動
どうもレンタカーの移動が数を稼いでいるようです。

大阪から京都への移動
これは電車移動がほとんどですね。

東京から東京への移動
こちらは電車もあれば、バス・タクシーも少しあります。

まとめ
今回は観光のデータ活用の一環で、FF-DataのAPIを使った分析をしてみました。今後、別の分析も行う予定ですので、ぜひお楽しみに。