
レジスタスピルとパイプラインハザード

超高性能プログラミング技術のメモ(3)
自分のための備忘録として、技術のメモを残しています。
第3回は、アセンブラ言語における主要なチューニングであるパイプラインハザードの回避とデータ転送の時間稼ぎについて書こうと思います。
レジスタスピル
演算器が直接利用できるレジスタメモリ(以下、レジスタ)は、有限個しかありません。SIMD命令が使用できるXMM, YMM, ZMMレジスタは、x86アーキテクチャで8個、x86_64アーキテクチャで16個しかありません。そのため、大量のデータを扱う場合には、レジスタの内容を次々と上書きして使用します。
多くのアルゴリズムでは、後で使うために上書きしてはいけないデータがあります。このような場合、レジスタを空けるために汎用メモリのスタック領域へ一時的にデータを退避させます。これを、レジスタスピルと言います。高級プログラミング言語のコンパイラが出力するアセンブラコードを見ると、スピル処理が自動的に挿入されており、高級言語ではレジスタ数を気にせずにプログラミングできるようになっています。

しかし、スピル処理は汎用メモリへの余計なデータ転送で、非常に低速です。データを再利用するために、レジスタにロードする処理もデータ転送になります。そのため、超高性能プログラミングでは、可能な限りスピル処理をしないようにします。
このことから、超高性能プログラミングでは、コンパイラの最適化機能は邪魔な存在になります。コンパイラは自動変数をレジスタに割り当てようとするので、使用する変数の個数をレジスタ数以下に抑えることで、ある程度スピル処理を回避できる場合があります。例えば、次のような変数宣言をします。
int main( int argc, char** argv ){
double xmm0 ,xmm1 ,xmm2 ,xmm3;
double xmm4 ,xmm5 ,xmm6 ,xmm7;
double xmm8 ,xmm9 ,xmm10,xmm11;
double xmm12,xmm13,xmm14,xmm15;
xmm1 = 1.0;
xmm3 = 1.0;
xmm4 = 1.0;
xmm6 = 1.0;
xmm7 = 1.0;
xmm9 = 1.0;
xmm10= 1.0;
xmm11= 1.0;
xmm13= 1.0;
xmm14= 1.0;
xmm0 = xmm1 + xmm3;
xmm2 = xmm4 + xmm6;
xmm5 = xmm7 + xmm9;
xmm8 = xmm9 + xmm10;
xmm12 = xmm10 + xmm14;
xmm15 = xmm13 + xmm11;
return 0;
}
XMMレジスタ16個(x86_64の場合)の変数だけを使ったコードにすると、レジスタを意識したプログラミングになり、レジスタスピルが起きにくいです。実際、このコードをgcc -O0 -Sでアセンブラ出力すると、レジスタスピルは起こっていません。(コードが簡単すぎるせいですが)
# %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $16, %rsp
xorl %eax, %eax
movsd LCPI0_0(%rip), %xmm0 ## xmm0 = mem[0],zero
movl $0, -4(%rbp)
movl %edi, -8(%rbp)
movq %rsi, -16(%rbp)
movsd %xmm0, -32(%rbp)
movsd %xmm0, -48(%rbp)
movsd %xmm0, -56(%rbp)
movsd %xmm0, -72(%rbp)
movsd %xmm0, -80(%rbp)
movsd %xmm0, -96(%rbp)
movsd %xmm0, -104(%rbp)
movsd %xmm0, -112(%rbp)
movsd %xmm0, -128(%rbp)
movsd %xmm0, -136(%rbp)
movsd -32(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -48(%rbp), %xmm0
movsd %xmm0, -24(%rbp)
movsd -56(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -72(%rbp), %xmm0
movsd %xmm0, -40(%rbp)
movsd -80(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -96(%rbp), %xmm0
movsd %xmm0, -64(%rbp)
movsd -96(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -104(%rbp), %xmm0
movsd %xmm0, -88(%rbp)
movsd -104(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -136(%rbp), %xmm0
movsd %xmm0, -120(%rbp)
movsd -128(%rbp), %xmm0 ## xmm0 = mem[0],zero
addsd -112(%rbp), %xmm0
movsd %xmm0, -144(%rbp)
addq $16, %rsp
popq %rbp
retq
.cfi_endprocパイプラインハザード
スピルなしのプログラムをコーディングしようとすると、有限個のレジスタを上手く使い回す必要が出てきます。この時、注意しなければならないのが、パイプラインハザードです。
CPUの内部処理は、複数のステージ(工程)に分けられ、違うステージを同時に処理するパイプライン処理で実行されています。自動車生産で言えば、1台を一人で組み立てるのではなく、エンジン搭載、ギアの実装、ドア取り付け、窓の取り付け、カラーリングといった工程の連なり(パイプライン)を、複数人で分担して組み立てることと同じです。この場合、一部の工程が停止するとパイプライン全体が停止することになります。これでは、稼働率が低下してしまいます。これを、パイプラインハザードと言います。
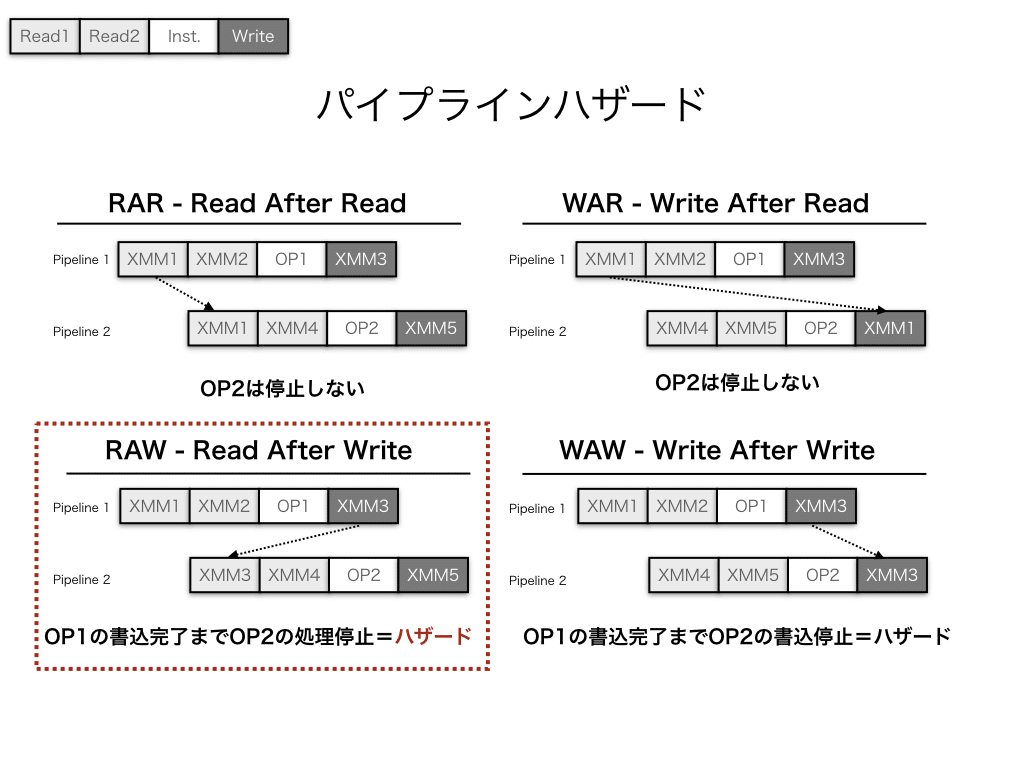
CPUで起こるパイプラインハザードは、レジスタの使い回し不可能が主な理由です。レジスタは処理命令によって、書き込み(Write)と読み込み(Read)が行われます。このことから、レジスタは次の4つの状況のいずれかにあります。
1. Read after Read (RAR) :ハザードは発生しない
2. Write after Read (WAR) :ハザードは発生しない
3. Read after Write (RAW) :書込完了まで読込不可のためパイプライン停止
4. Write after Write (WAW):書込完了まで次の書き込みができない
パイプラインハザードが起こり得るのは、WAWとRAWの場合です。WAWの場合、パイプライン1の書き込みが終わるまで、パイプライン2の書き込みができないため、しばらくパイプライン2が停止する可能性があります。しかし、本当に問題なのはRAWの場合で、読み込みができないためパイプライン2は完全に停止します。すなわち、最も注意しなければならないのはRAWハザードになります。
転送時間稼ぎ
基本的な演算処理である、ロード(メモリからレジスタにデータ転送)+演算処理+ストア(レジスタからメモリにデータ転送)という最小の演算処理は、全ての処理でRAWハザードが発生します。

このような単純なアセンブラ命令順では、全パイプラインが順番に処理され、パイプライン処理が全く活かされません。しかも、ロード(LD)命令はメモリアクセスをするため、運が良くて4cycle(L1キャッシュ上にデータが存在した場合)、運が悪いと数百cycle(全てのキャッシュにデータが無かった場合)と処理時間がかかり、性能が著しく減衰します。
これは、ロード命令と演算命令、演算命令とストア命令の間隔を開け、ロード時間と演算時間を稼ぐことで解消できます。時間稼ぎは、間に無関係な命令(RAWハザードを発生させるレジスタを使用しない命令)を詰め込むことで実現できます。
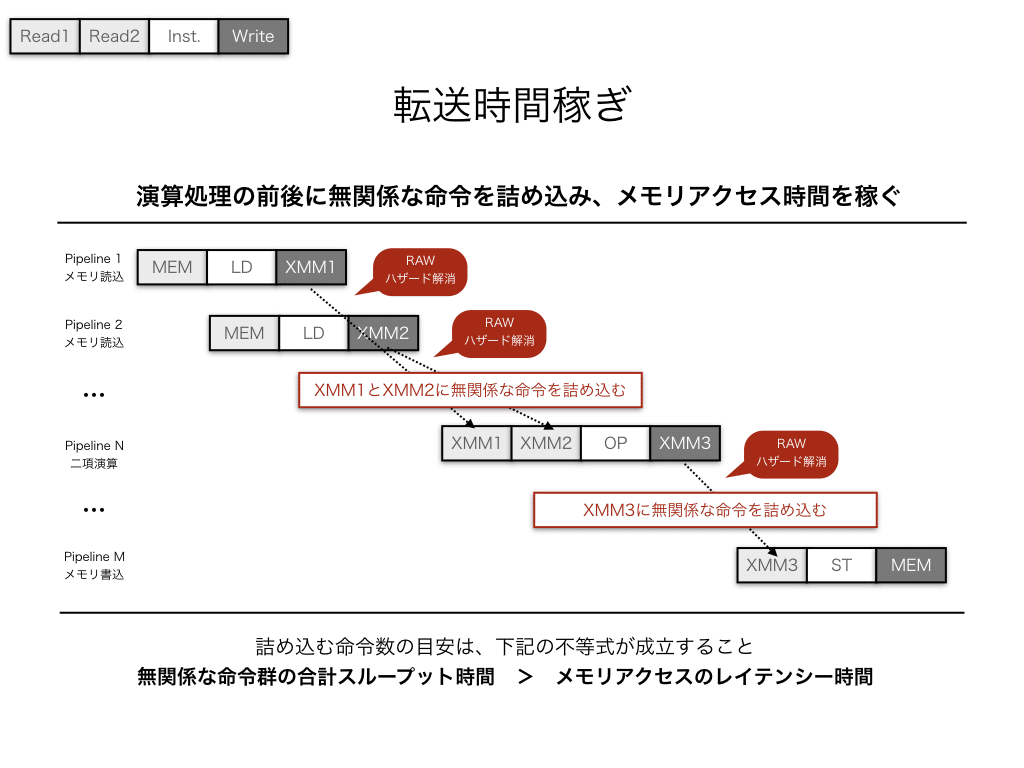
各アセンブラ命令は、スループット時間(次の命令に移れるまでの時間)とレイテンシー時間(処理の実行が完了するまでの時間)が設定されています。ここで、詰め込んだ無関係な命令のスループット時間の合計が、ロード命令のデータ転送時間より大きければ、演算処理の開始時にはロード処理が完了していることになります。すなわち、パイプラインを停止せずに多くの処理を実行でき、非常に効率が高まります。
しかしながら、レジスタは有限個であり、無関係な命令を詰め込むにも限度があります。かといって、レジスタを使い回すためデータを退避しても、レジスタスピルにより効率が低下します。したがって、スピルのない無関係な命令を詰め込むことが重要になりますが、これはアルゴリズムに依存しています。
まとめ
今回は、アセンブラレベルの効率化で重要な概念を3つ書きました。
・レジスタスピル
・パイプラインハザード
・転送時間稼ぎ
次回は、ループの構成方法について書こうと思います。