
アセンブラによるベクトル化|行列積高速化#17

この記事は、以下の記事を分割したものです。
[元の記事]行列積計算を高速化してみる
一括で読みたい場合は、元の記事をご覧ください。
アセンブラ命令を選択したら、インラインアセンブラ機能を使ってプログラムを実装していきます。
前節では、MxNxKが4x4x8にアンロールされた場合だけを検討しましたが、実際には3×3×4=36通りの場合があります。
もっとも、K≧8, K&4, K&2, K&1のば場合の違いは、命令数が違うだけです。K≧8の場合さえ実装できてしまえば、K&4のコードはK≧8の命令数を半分に、K&2のコードはK&4の命令数を半分に、K&1のコードはK&2の命令数を半分にしていくだけです。コピー&ペーストと行削除を何回か繰り返せば簡単に実装できてしまいます。
しかし、MxNのアンロール段数の違いは、アセンブラコードの実装自体を変更する必要に迫られます。そこで、本節では、レジスタゼロクリアの説明をした後、下記の9通りについて実装を説明します。
1-1. N≧4かつM≧4の場合
1-2. N≧4かつM&2の場合
1-3. N≧4かつM&1の場合
2-1. N&2かつM≧4の場合
2-2. N&2かつM&2の場合
2-3. N&2かつM&1の場合
3-1. N&1かつM≧4の場合
3-2. N&1かつM&2の場合
3-3. N&1かつM&1の場合
17-1. ゼロクリアの方法
アンロールした段階で導入した一時変数c00~c33は、Kループに入る直前でゼロを代入していました。ベクトライズに当たって、変数c00~c33はYMMレジスタに置き換えられます。そのため、YMMレジスタをゼロクリアしておかなければなりません。
YMMレジスタをゼロクリアするには、排他的論理和XORを使用します。例えば、01010101というデータ同士のXORを計算すると、
01010101 XOR 01010101 -> 00000000
というように、同じデータのXORは必ず全てのビットがゼロになります。これを利用してゼロクリアを行います。
AVX命令には、VXORPD命令(倍精度用)やVPXOR命令(整数用)といった排他的論理和命令があります。ゼロクリアをするだけなら、どちらの命令を使っても構いません。歴史的な理由で、VPXOR命令の方が対応演算器が多いCPUもあるので、VPXOR命令を使っておいた方が無難かもしれません。
実際のコードは、下記のようになります。
<修正前>
c00=0e0;c01=0e0;c02=0e0;c03=0e0;
c10=0e0;c11=0e0;c12=0e0;c13=0e0;
c20=0e0;c21=0e0;c22=0e0;c23=0e0;
c30=0e0;c31=0e0;c32=0e0;c33=0e0;
<修正後>
__asm__ __volatile__ (
"\n\t"
"vpxor %%ymm12, %%ymm12, %%ymm12\n\t"
"vpxor %%ymm13, %%ymm13, %%ymm13\n\t"
"vpxor %%ymm14, %%ymm14, %%ymm14\n\t"
"vpxor %%ymm15, %%ymm15, %%ymm15\n\t"
::);見ての通り、今回はymm12~ymm15を行列Cのレジスタとして使用します。
以降、各場合の実装方法については、有料にさせていただきます。
次の記事
17-2. N≧4かつM≧4の場合
この場合は、前節まででベクトライズの設計を行なっていたケースですので、その設計に従って、下記のように書き換えます。
<変更前>
a00 = *(A + 0 + 0*4 ); a01 = *(A + 0 + 1*4 ); a02 = *(A + 0 + 2*4 ); a03 = *(A + 0 + 3*4 );
a10 = *(A + 1 + 0*4 ); a11 = *(A + 1 + 1*4 ); a12 = *(A + 1 + 2*4 ); a13 = *(A + 1 + 3*4 );
a20 = *(A + 2 + 0*4 ); a21 = *(A + 2 + 1*4 ); a22 = *(A + 2 + 2*4 ); a23 = *(A + 2 + 3*4 );
a30 = *(A + 3 + 0*4 ); a31 = *(A + 3 + 1*4 ); a32 = *(A + 3 + 2*4 ); a33 = *(A + 3 + 3*4 );
b00 = *(B + 0 + 0*4 ); b01 = *(B + 0 + 1*4 ); b02 = *(B + 0 + 2*4 ); b03 = *(B + 0 + 3*4 );
b10 = *(B + 1 + 0*4 ); b11 = *(B + 1 + 1*4 ); b12 = *(B + 1 + 2*4 ); b13 = *(B + 1 + 3*4 );
b20 = *(B + 2 + 0*4 ); b21 = *(B + 2 + 1*4 ); b22 = *(B + 2 + 2*4 ); b23 = *(B + 2 + 3*4 );
b30 = *(B + 3 + 0*4 ); b31 = *(B + 3 + 1*4 ); b32 = *(B + 3 + 2*4 ); b33 = *(B + 3 + 3*4 );
c00 = a00 * b00; c00 += a01 * b01; c00 += a02 * b02; c00 += a03 * b03;
c01 = a00 * b10; c01 += a01 * b11; c01 += a02 * b12; c01 += a03 * b13;
c02 = a00 * b20; c02 += a01 * b21; c02 += a02 * b22; c02 += a03 * b23;
c03 = a00 * b30; c03 += a01 * b31; c03 += a02 * b32; c03 += a03 * b33;
c10 = a10 * b00; c10 += a11 * b01; c10 += a12 * b02; c10 += a13 * b03;
c11 = a10 * b10; c11 += a11 * b11; c11 += a12 * b12; c11 += a13 * b13;
c12 = a10 * b20; c12 += a11 * b21; c12 += a12 * b22; c12 += a13 * b23;
c13 = a10 * b30; c13 += a11 * b31; c13 += a12 * b32; c13 += a13 * b33;
c20 = a20 * b00; c20 += a21 * b01; c20 += a22 * b02; c20 += a23 * b03;
c21 = a20 * b10; c21 += a21 * b11; c21 += a22 * b12; c21 += a23 * b13;
c22 = a20 * b20; c22 += a21 * b21; c22 += a22 * b22; c22 += a23 * b23;
c23 = a20 * b30; c23 += a21 * b31; c23 += a22 * b32; c23 += a23 * b33;
c30 = a30 * b00; c30 += a31 * b01; c30 += a32 * b02; c30 += a33 * b03;
c31 = a30 * b10; c31 += a31 * b11; c31 += a32 * b12; c31 += a33 * b13;
c32 = a30 * b20; c32 += a31 * b21; c32 += a32 * b22; c32 += a33 * b23;
c33 = a30 * b30; c33 += a31 * b31; c33 += a32 * b32; c33 += a33 * b33;
A+=16;
B+=16;
<変更後>
__asm__ __volatile__ (
"\n\t"
"vbroadcastf128 0*8(%[a]), %%ymm0 \n\t"
"vbroadcastf128 2*8(%[a]), %%ymm1 \n\t"
"vbroadcastf128 4*8(%[a]), %%ymm2 \n\t"
"vbroadcastf128 6*8(%[a]), %%ymm3 \n\t"
"vmovapd 0*8(%[b]), %%ymm4 \n\t"
"vmovapd 4*8(%[b]), %%ymm5 \n\t"
"\n\t"
"vshufpd $0x00, %%ymm4, %%ymm4, %%ymm8 \n\t"
"vshufpd $0x0f, %%ymm4, %%ymm4, %%ymm9 \n\t"
"vshufpd $0x00, %%ymm5, %%ymm5, %%ymm10\n\t"
"vshufpd $0x0f, %%ymm5, %%ymm5, %%ymm11\n\t"
"vfmadd231pd %%ymm0 , %%ymm8 , %%ymm12\n\t"
"vfmadd231pd %%ymm1 , %%ymm8 , %%ymm13\n\t"
"vfmadd231pd %%ymm0 , %%ymm9 , %%ymm14\n\t"
"vfmadd231pd %%ymm1 , %%ymm9 , %%ymm15\n\t"
"vfmadd231pd %%ymm2 , %%ymm10, %%ymm12\n\t"
"vfmadd231pd %%ymm3 , %%ymm10, %%ymm13\n\t"
"vfmadd231pd %%ymm2 , %%ymm11, %%ymm14\n\t"
"vfmadd231pd %%ymm3 , %%ymm11, %%ymm15\n\t"
"\n\t"
"vbroadcastf128 8*8(%[a]), %%ymm0 \n\t"
"vbroadcastf128 10*8(%[a]), %%ymm1 \n\t"
"vbroadcastf128 12*8(%[a]), %%ymm2 \n\t"
"vbroadcastf128 14*8(%[a]), %%ymm3 \n\t"
"vmovapd 8*8(%[b]), %%ymm6 \n\t"
"vmovapd 12*8(%[b]), %%ymm7 \n\t"
"\n\t"
"vshufpd $0x00, %%ymm6, %%ymm6, %%ymm8 \n\t"
"vshufpd $0x0f, %%ymm6, %%ymm6, %%ymm9 \n\t"
"vshufpd $0x00, %%ymm7, %%ymm7, %%ymm10\n\t"
"vshufpd $0x0f, %%ymm7, %%ymm7, %%ymm11\n\t"
"vfmadd231pd %%ymm0 , %%ymm8 , %%ymm12\n\t"
"vfmadd231pd %%ymm1 , %%ymm8 , %%ymm13\n\t"
"vfmadd231pd %%ymm0 , %%ymm9 , %%ymm14\n\t"
"vfmadd231pd %%ymm1 , %%ymm9 , %%ymm15\n\t"
"vfmadd231pd %%ymm2 , %%ymm10, %%ymm12\n\t"
"vfmadd231pd %%ymm3 , %%ymm10, %%ymm13\n\t"
"vfmadd231pd %%ymm2 , %%ymm11, %%ymm14\n\t"
"vfmadd231pd %%ymm3 , %%ymm11, %%ymm15\n\t"
"\n\t"
"addq $16*8, %[a]\n\t"
"addq $16*8, %[b]\n\t"
"\n\t"
:[a]"+r"(A),[b]"+r"(B)
:);このコードは、K&4の場合のコードです。見てのとおり、ロード処理(VMOVAPD/VBROADCASTF128)・詰め替え処理(VSHUFPD)・演算処理(VFMADD231PD)の処理セットが2つあります。
他の場合については、下記の手順で比較的簡単に実装できます。
(1)既存コードをコピー&ペーストする
(2)処理セットを増減する
(K≧8は4セット、K&2は1セット、K&1はハーフセット)
(3)アドレスの数値を変更する(ロード処理とADDQ命令の部分)
行列Aのロード処理は、VBROADCASTF128命令で2要素(128bit)ずつロードしているので、アドレスのシフト定数は2跳びになっています。一方、行列BはVMODAPD命令で4要素(256bit)ずつロードしているので、4跳びになっています。
VSHUFPD命令の動作と、0x00や0x0fなどの設定の意味は下記のとおりです。
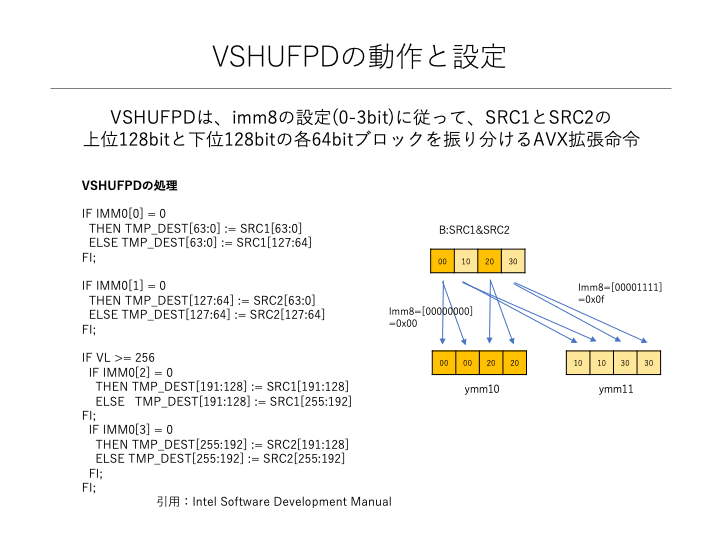
また、FMA命令は3種類がありますが、行列積計算では計算式と一致するVFMADD231PD命令を使用しています。

ここから先は
¥ 100
この記事が気に入ったらチップで応援してみませんか?