
キャッシュをコントロールする方法

超高性能プログラミング技術のメモ(9)
技術を忘れないようにノートに書き残しています。
今回は、キャッシュメモリにデータを乗せておく処理について書こうと思います。この処理は、行列積計算のようなアルゴリズムには必要になります。
メモリアクセス1回目を速くする
ブロッキングは、キャッシュに乗るサイズにデータ利用領域を制限する技術でした。この領域制限により、一度キャッシュにデータが格納されると、その後もデータがキャッシュサイズを越えて溢れることがなくなり、キャッシュ上のデータを再利用できるようになります。この再利用によって、汎用メモリへのアクセス回数が削減され、結果として高性能化されます。
しかし、アンローリングでループ内に独立な処理を充填し、ループずらしでロード処理と演算処理の間に独立な処理を最大限差し込んだとしても、ループの前に移した1回目のロード命令とループ内の最初の演算命令の間には、詰め込む独立処理がありません。そして、1回目のロード処理では、キャッシュにデータが格納されておらず、必ずメインメモリへのアクセスが必要になります。そのため、1回目の演算命令は、ほとんどの場合、一時停止してしまいます。(その後は、ロード時間を稼げるので効率的になります)
そのため、高性能なアルゴリズムでは、1回目のロード処理を高性能化することが課題になります。
これを解決するには、ループ処理に入る前にキャッシュにデータを乗せておくしかありません。
では、どうすればそんなことができるでしょうか?
ロード命令かストア命令か
キャッシュにデータが書き込まれるのは、メモリ-レジスタ間でデータを転送した時です。つまり、ロード命令かストア命令を実行するしかありません。
まず、ストア命令だけを実行するのは意味がありません。実行中にレジスタが保持するデータをキャッシュメモリに書き込んでも、その後のループで使用するデータはメインメモリに存在しているためです。
次に、ロード命令だけを実行する場合を考えます。
ロード命令は、指定されたメモリアドレスがどのキャッシュにも登録されていないと、メインメモリからデータを転送します。この時、ロード命令で読み出すデータサイズがどんなに小さくとも、キャッシュラインサイズ=64Bのデータを転送します。転送されたキャッシュラインは、各階層のキャッシュメモリに書き込まれながら、レジスタまで転送されます。

したがって、本格的な処理の前に一度ロード命令を実行しておく、という対策が考えられます。これを、たしかプリロード処理と言ったりします。メインメモリ上のデータに何も加工を施さない場合は、プリロード処理を行うと良いでしょう。例えば、1次元配列のように、メインメモリ上のデータ配置が連続的で、単純に先頭からアクセスしていくアルゴリズムの場合です。
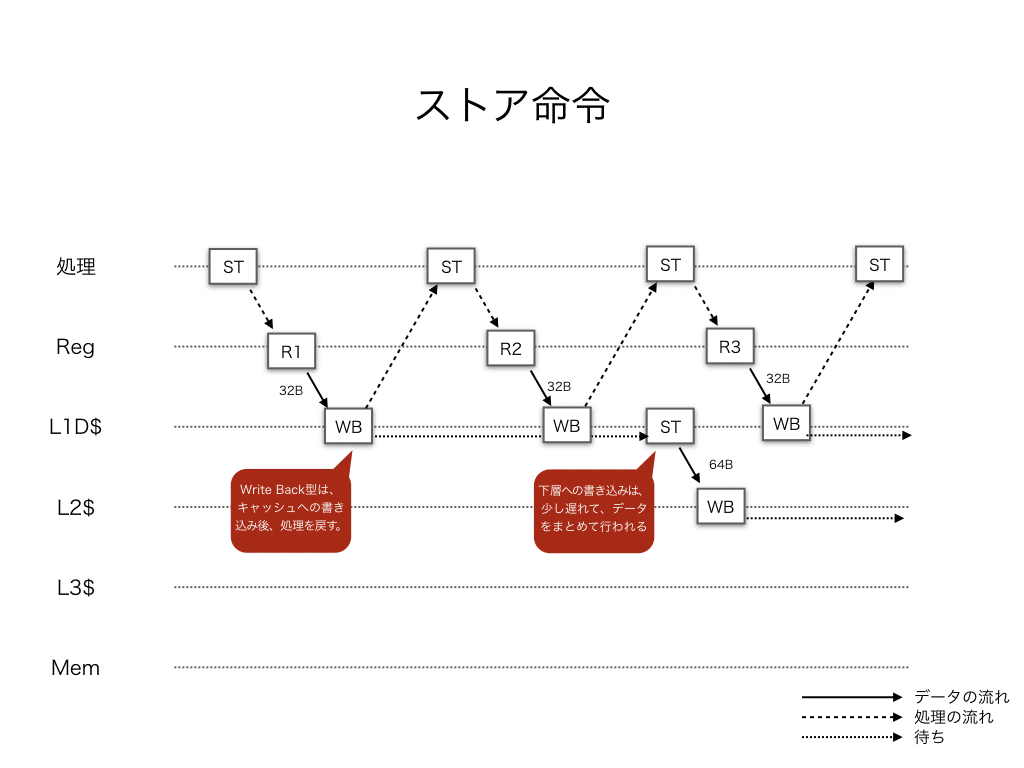
しかし、メインメモリ上のデータに何らかの加工を施す必要がある場合は、ロード&加工後に、ストア命令を実行する必要があります。なぜなら、キャッシュ上のデータは加工の結果が反映されていないためです。ストア命令によって、加工後のデータをキャッシュに書き込みます。最近のCPUのキャッシュメモリは、Write Back 型(WB)なので、キャッシュメモリへの書き込み後、すぐに次の処理を開始することができます。
何かしらの加工を含みますが、この場合はロード命令とストア命令の組み合わせなので、擬似的なコピー処理に相当します。
なぜ加工が必要なのか?
もし、使用するデータが1次元配列ならば、メモリ配置が連続なため、最後のキャッシュラインを除いて未使用データが存在しません。このとき、キャッシュラインの使用効率は最大となります。
一方、前回出てきたような多次元配列のブロック1つ1つは、配列の一部を取り出しているため、メモリ配置は不連続になります。このとき、不連続なメモリ配置の切れ目ごとにキャッシュラインの一部しか使用しない可能性があり、データ転送の無駄を増やしてしまいます。

この無駄を防ぐには、ブロック毎にシリアライズ(直列化)しておくことです。シリアライズされたデータを使うアルゴリズムは、キャッシュラインの無駄が最小限なので、データ転送が最も効率化されています。
そして、このシリアラズとキャッシュへ乗せるコピー処理は、同時に実行できてしまいます。そのため、シリアライズが必要なアルゴリズムで、コピー処理をしても性能上の問題がない場合には、ストアでキャッシュされたデータを使うようにコピー処理でキャッシュメモリにデータを載せます。
では、コピー処理をしても性能上の問題が無い場合とは、どのような場合でしょうか?
どんなアルゴリズムならコピーしても良いのか?
これまでのノートで記述してきたように、高性能化のポイントはロード命令によるデータ転送時間を無関係な処理で隠蔽することです。主な無関係な処理は、アンローリングによる別の反復の処理です。
特に、演算処理がデータ転送時間を隠蔽するのに重要です。なぜなら、本当に時間稼ぎができるのは、ロードやストア以外の処理で、その中でもスループット時間が長いのは演算処理(加算や乗算など)だからです。
そのため、データ転送量を決めるデータ数と演算処理の時間を決める演算数の大小関係が重要になってきます。これは、3つの場合に分けることができます。
(1)データ数が演算数よりも圧倒的に多い(データ数≫演算数)
(2)データ数と演算数がだいたい同じ (データ数〜演算数)
(3)演算数がデータ数よりも圧倒的に多い(データ数≪演算数)
(1)の場合の典型例は、メモリコピーです。演算数は0なので、データ数Nがいくつであろうと、(1)の場合になります。この場合は、演算処理によるデータ転送時間の隠蔽は不可能なので、プリロード処理やソフトウェアプリフェッチ処理を考えるべきです。
(2)の場合の典型例は、内積計算(=x1*y1+x2*y2+...+xN*yN)です。データ数が2N、演算数が2N-1なので、ほぼ同数になります。この場合、キャッシュに乗せるためのコピー処理をしてしまうと、トータルのデータ転送量がデータ数の2倍4N程度になってしまいます。こうなると、(1)に近い状況となるので、演算処理によるデータ転送時間の隠蔽は難しくなります。
(3)の場合が、キャッシュに乗せるためのコピー処理をしても良い場合になります。行列積計算(A*B=C)が典型的です。データ数が3N^2なのに対し、演算数は2N^3と一桁上のオーダーになります。そのため、行列A、Bのコピー処理を使いしたとしても、トータルのデータ転送量は、3N^2+2N^2=5N^2程度で、演算数に比べて圧倒的に小さいままになります。このような状況だと、演算処理でデータ転送時間を隠蔽可能になります。
コピーは下層から
キャッシュに乗せるためのコピー処理を追加する場合、コピー処理順にも気をつけます。なぜなら、後からコピーしたデータによって、先にコピーしたデータがキャッシュから追い出されてしまう可能性があるからです。

L1キャッシュよりもL2キャッシュの方が大きいため、先にL2キャッシュに乗せるデータ(上図のData1)をコピーし、次にL1キャッシュに乗せるデータ(上図の2)をコピーします。この時、先にコピーされたデータ(Data1)のL1キャッシュに残っていたデータは、追い出されてしまいます。
まとめ
今回は、キャッシュメモリ上にデータを配置する方法について書きました。演算数がデータ数よりも圧倒的に大きい場合は、シリアライズを伴うコピー処理によってストア命令でキャッシュに乗せます。それ以外の場合は、事前にロード命令を実行するか、ソフトウェアプリフェッチでキャッシュにデータを転送しておきます。
この記事が気に入ったらサポートをしてみませんか?