
【ComfyUI】 Stable Diffusion 3 Mediumが公開されたので動作させてみる

いよいよStable Diffusion 3のweightsであるStable Diffusion 3 MediumがHugging Faceで公開されました。早速触ってみたいと思います。
1. ダウンロード
SD3には、以下のweightsがあります。
sd3_medium.safetensors: MMDiTとVAEの重みのみを含みます。
sd3_medium_incl_clips_t5xxlfp8.safetensors: fp8バージョンのT5XXLテキストエンコーダーを含む、すべての必要な重みが含まれています。
sd3_medium_incl_clips.safetensors: T5XXLテキストエンコーダー以外のすべての必要な重みが含まれています。
今回は、テキストエンコーダーも含めたsd3_medium_incl_clips_t5xxlfp8.safetensorsを利用します。
これをComfyUI/models/checkpointsに格納します。
次に、サンプルワークフローをダウンロードします。サンプルワークフローには、以下の3種類が用意されていました。
sd3_medium_example_workflow_basic.json
プロンプトを入力し、Stable Diffusion 3 Medium で画像を生成するシンプルなワークフロー
sd3_medium_example_workflow_multi_prompt.json
複数のプロンプトを個別に設定し、それぞれの影響度合いを調整しながら画像を生成するワークフロー
より複雑な画像や、複数の要素を組み合わせた画像を生成するのに役立つ
sd3_medium_example_workflow_upscaling.json
Stable Diffusion 3 Medium で生成した画像を、ESRGAN モデルを使って高画質にアップスケールするワークフロー
生成した画像をより高精細にしたい場合に便利
今回は、basicを試してみたいと思います。
2. basic workflowで画像生成
まず、basicを試したいと思います。basicのworkflowの全体像は以下になります。

シンプルなworkflowになっています。ここで、Load Modelsグループを編集します。
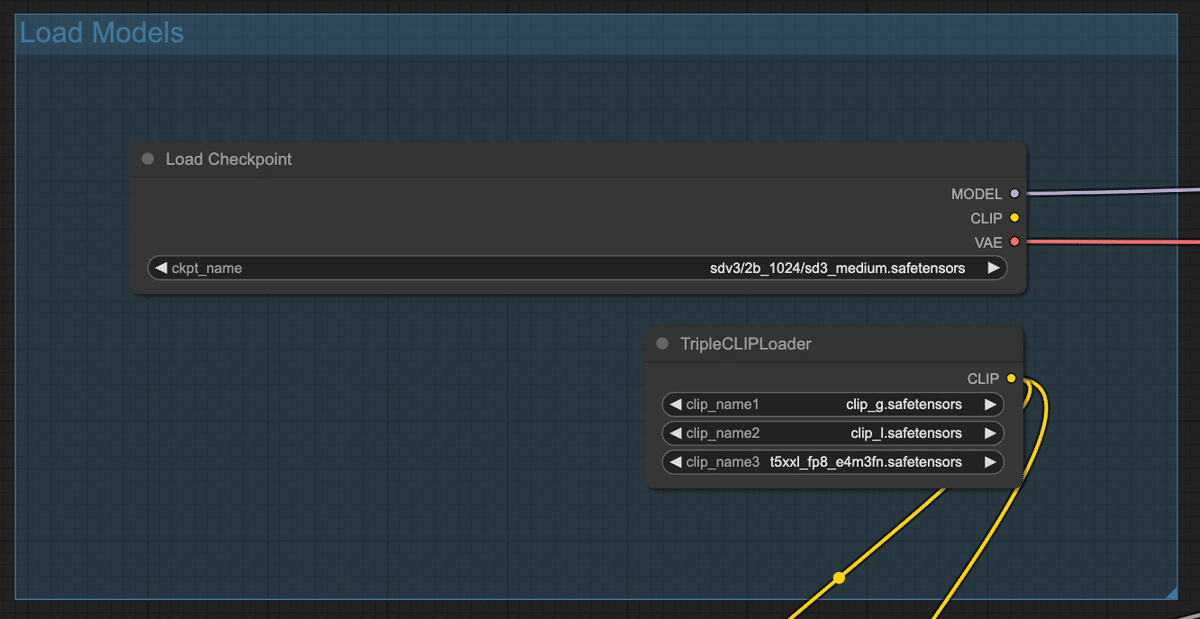
まず、Load Checkpointで読み込むcheckpointをsd3_medium_incl_clips_t5xxlfp8.safetensorsに変更します。

次に、TripleCLIPLoaderを削除し、Load CheckpointのCLIPをText Encoderに接続します。TripleCLIPLoaderを削除するのは、sd3_medium_incl_clips_t5xxlfp8.safetensorsがText Encoderも含めたモデルのため、別途Text Encoderを用意する必要がないためです。
最終的に以下のようなフローになります。

これで準備が整ったので実行してみます。無事に以下のように画像が出力されました。
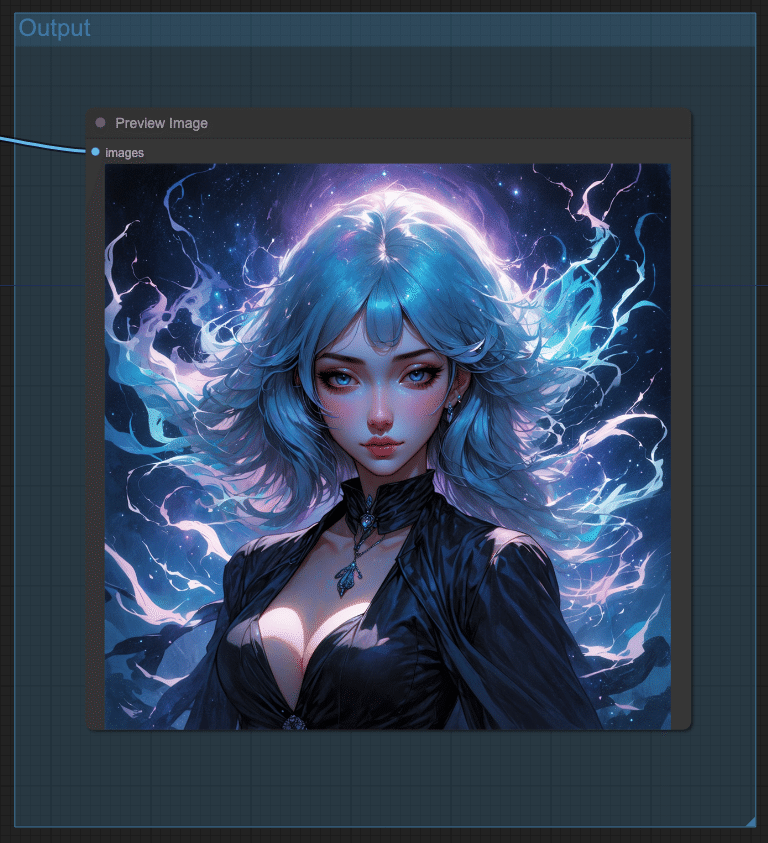
Seedが固定されているため、このままだと毎回同じ画像が出力されます。Seedはrandomizeに変更しておきましょう。

3. 色々試してみる
Positive promptを見ると、単語の羅列ではなく、文章で書かれていることが分かります。
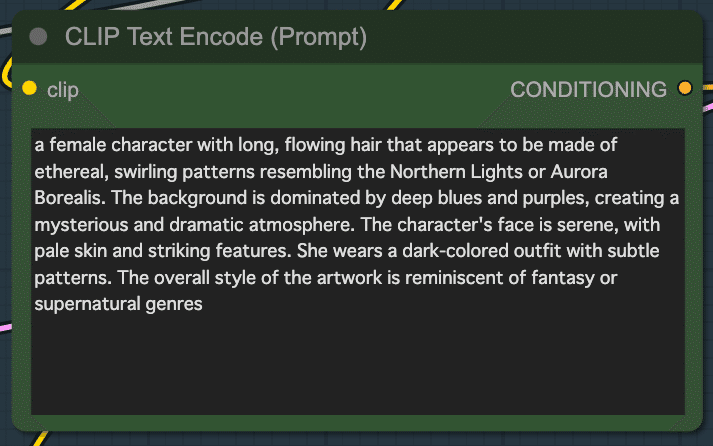
文字がどのように出力されるか試すために、「18歳の日本人の女性が「東京駅まで」と書かれた段ボールを持ってヒッチハイクしている写真」を生成するプロンプトをChatGPTに考えてもらいました。以下がそのプロンプトです。
A photograph of an 18-year-old Japanese woman hitchhiking, holding a cardboard sign that reads '東京駅まで' (To Tokyo Station). She is standing by the roadside with a hopeful expression, wearing casual clothing and a backpack. The background shows a bustling urban street with cars passing by and city buildings. The scene is lively and vibrant, capturing the energy of Tokyo. Cinematic composition, trending on artstation.
生成された結果が以下になります。英語と中国語が混ざったような文字になってしまっています。また、左手の指の数がおかしいですね。その他に、後ろの看板の文字がおかしかったり、横断歩道も少し変になっていますが、女性は結構しっかり生成されている気がします。

英語なら表示できるか確認するために、プロンプトの「東京駅まで」を「To Tokyo Station」に変えて実行してみました。すると、文字がしっかり描画されていることが確認できました。

NSFWへの対応はどうか試したところ、何度やっても裸の女性は出力できませんでした。しっかり対応できているようです。

生成速度は、かなり速いです。28stepsでこの速度です。
あと、気がついた点が、同じプロンプトでも出力される女性の顔のバリエーションが多い気がします。Midjourneyのように様々な顔の写真を生成できそうです。

4. まとめ: 素のモデルで精度が良い
SD3を試してみた結果、素のモデルで簡単なプロンプトで綺麗な画像を出力できるので、単体の性能は上がっていると感じました。今後、このweightsを元に様々な種類のモデルが開発されるでしょうから、新たなモデルの誕生が楽しみです。
この記事でご紹介したAI技術の応用方法について、もっと詳しく知りたい方や、実際に自社のビジネスにAIを導入したいとお考えの方、私たちは、企業のAI導入をサポートするAIコンサルティングサービスを提供しています。以下のようなニーズにお応えします。
AIを使った業務効率化の実現
データ分析に基づくビジネス戦略の立案
AI技術の導入から運用までの全面サポート
専門家によるカスタマイズされたAIソリューションの提案
初回相談無料ですので、お気軽にご相談ください。以下のリンクからお問い合わせください。
この記事が気に入ったらサポートをしてみませんか?