
【ComfyUI】 CogVideoXでテキストから動画を作成しよう!

近年、AI技術の進歩により、テキストから画像を生成する技術が広く知られるようになりました。しかし、静止画だけでなく、テキストから動画を生成する技術も急速に発展しています。
本記事では、オープンソースの動画生成モデルであるCogVideoXと、強力なUIツールであるComfyUIを用いて、高画質かつ高フレームレートな動画を生成する方法を紹介します。
1. 使用するモデル
今回使用するモデルは、CogVideoXです。CogVideoXは、清華大学とZhipu AIの研究チームによって開発されたオープンソースのビデオ生成モデルです。このモデルは、テキストプロンプトに基づいてビデオを生成するために設計されています。
CogVideoXには主に2つのバージョンがあり、それぞれ異なる特性と用途があります。
CogVideoX-2B
エントリーレベルのモデルで、互換性とコスト効率を重視しています。
Apatche 2.0で提供されているので、商用利用可能です。
CogVideoX-5B
より大規模なモデルで、高品質なビデオ生成と優れた視覚効果を提供します。
CogVideoXという特殊なライセンスで提供されており、制限は以下の通りとなります。
商用利用を希望する場合は、https://open.bigmodel.cn/mla/form から基本商用ライセンスを取得する必要があります。ライセンスを取得した場合、無料で商用利用が可能です。ただし、月間訪問者数が100万件を超える場合は、追加の商用ライセンスが必要です。
ソフトウェアを使用する際には、著作権声明とライセンス声明を全てのコピーに記載する必要があります。
軍事利用や違法な目的での使用、中国の国家安全保障や社会の公序良俗を害する行為も禁止されています。
ライセンスは、中国の法律に基づき、紛争は北京の海淀区人民法院で解決されます。
CogVideoXは以下のような機能を提供します。
テキストからビデオ生成: テキストプロンプトを入力すると、それに基づいたビデオを生成します。
高フレームレートビデオ生成: 4秒間のクリップで32フレームのビデオを生成できます。
多言語対応: 現在は主に英語と簡体字中国語に対応しています。
2. 使用するカスタムノード
ComfyUI-CogVideoXWrapper
ComfyUIには、CogVideoXをラッパーしたカスタムノード「ComfyUI-CogVideoXWrapper」が提供されています。今回は、このカスタムノードを使用します。ComfyUI-CogVideoXWrapperは、ComfyUI Managerからインストールすることができます。以下がComfyUI-CogVideoXWrapperのリポジトリです。
ComfyUI-VideoHelperSuite
生成した画像を動画ファイルとして出力するために「ComfyUI-VideoHelperSuite」を使用します。ComfyUI-VideoHelperSuiteは、ComfyUI Managerからインストールすることができます。以下がComfyUI-VideoHelperSuiteのリポジトリです。
3. CLIPのダウンロード
CLIPに使用するテキストエンコーダーが必要になります。今回は、SD3 Mediumのテキストエンコーダー「t5xxl_fp8_e4m3fn.safetensors」を使用します。以下からダウンロードし、「ComfyUI/models/clip」に格納してください。
4. ワークフローのロード
ComfyUI-CogVideoXWrapperのリポジトリでサンプルのワークフローを提供しています。今回は、その中の「cogvideox_5b_example_01.json」を使用します。以下のリンクからワークフローをダウンロードし、ComfyUIにロードしてください。
以下がワークフローの全体図です。

以下より各ノードの解説をします。
(Down)load CogVideo Model
モデルの選択は、「(Down)load CogVideo Model」ノードで行います。このノードのmodelウィジェットでCogVideoX-2bまたはCogVideoX-5bを選択します。モデルはワークフローの実行時に自動でダウンロードされます。モデルが格納されるフォルダは、「ComfyUI/models/CogVideo」になります。
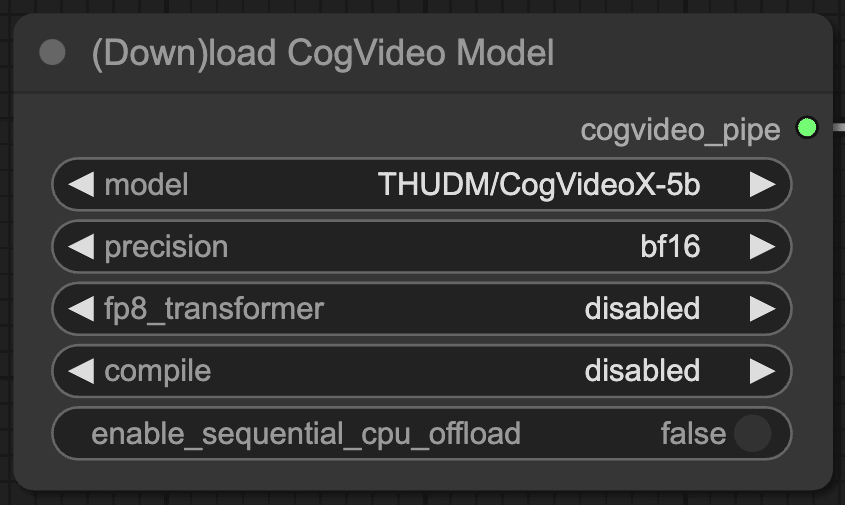
以下は、各ウィジェットの詳細になります。
model: 使用する CogVideoX モデルを選択します。利用可能なオプションは、「THUDM/CogVideoX-2b」(軽量版) と「THUDM/CogVideoX-5b」(高精度版) です。
precision: モデルの推論に使用する精度を指定します。選択肢は 「fp16」(半精度浮動小数点数)、「fp32」(単精度浮動小数点数)、「bf16」(bfloat16) です。デフォルトは「bf16」で、これは特に5bモデルで良好なパフォーマンスとメモリ効率のバランスを提供します。2bモデルには、fp16が推奨されます。

fp8_transformer: Transformer コンポーネントを torch.float8_e4m3fn 型にキャストするかどうかを指定します。選択肢は 「disabled」(無効)、「enabled」(有効)、「fastmode」(高速モード) です。デフォルトは「disabled」です。「enabled」を選択するとメモリ使用量が削減されますが、精度がわずかに低下する可能性があります。「fastmode」は最新の NVIDIA GPU でのみ利用可能で、さらなる高速化を実現します。
compile: 推論速度向上のため、モデルをコンパイルするかどうかを指定します。選択肢は「disabled」(無効)、「onediff」、「torch」です。デフォルトは「disabled」です。コンパイルは Linux 環境でのみ利用可能です。「onediff」と「torch」は異なるコンパイル方法を提供します。
enable_sequential_cpu_offload: CPU オフロードを有効にするかどうかを指定します。デフォルトは False です。True に設定すると、モデルの一部を CPU メモリにオフロードすることで GPU メモリ使用量を削減できます。ただし、推論速度は低下する可能性があります。
Load CLIP
「Load CLIP」ノードでテキストエンコーダーを読み込みます。ここでは、clip_nameに「t5xxl_fp8_e4m3fn.safetensors」、typeに「sd3」を選択します。

各ウィジェットの用途は以下の通りです。
clip_name: 使用するCLIPを選択します。
type: CLIPモデルの種類を決定します。これにより、モデルの初期化および設定方法に影響を与えます。
CogVideo TextEncode
次にポジティブプロンプトとネガティブプロンプトを「CogVideo TextEncode」ノードに入力します。

今回は、ポジティブプロンプトのみに以下のプロンプトを入力しています。プロンプトの日本語訳も記載します。
A golden retriever, sporting sleek black sunglasses, with its lengthy fur flowing in the breeze, sprints playfully across a rooftop terrace, recently refreshed by a light rain. The scene unfolds from a distance, the dog's energetic bounds growing larger as it approaches the camera, its tail wagging with unrestrained joy, while droplets of water glisten on the concrete behind it. The overcast sky provides a dramatic backdrop, emphasizing the vibrant golden coat of the canine as it dashes towards the viewer.ゴールデンレトリバーが、艶やかな黒いサングラスをかけ、長い毛を風になびかせながら、軽い雨に濡れたばかりの屋上テラスを楽しげに走り回っている。遠くからその光景が展開し、犬の元気な跳躍がカメラに近づくにつれて大きくなり、しっぽを制限のない喜びで振っている。コンクリートには水滴がキラキラと光り、犬の後ろに残る。曇り空が劇的な背景を提供し、犬の鮮やかな金色の毛並みが強調されながら、カメラに向かって駆け寄ってくる。
CogVideo Sampler
このノードは、CogVideoEncodePrompt ノードまたは CogVideoTextEncode ノードから出力されたテキスト情報と、CogVideoImageEncode ノードから出力された潜在空間 (またはランダムノイズ) をもとに、CogVideoX モデルを用いて新たな潜在空間をサンプリングします。このサンプリングされた潜在空間は、デコードされることで最終的なビデオとなります。

以下は、入力や出力、ウィジェットの詳細になります。
height: 生成するビデオの高さ (ピクセル単位) を指定します。値は 128 から 2048 の範囲で、8 の倍数である必要があります。
width: 生成するビデオの幅 (ピクセル単位) を指定します。値は 128 から 2048 の範囲で、8 の倍数である必要があります。
num_frames: 生成するビデオのフレーム数を指定します。値は 16 から 1024 の範囲で設定可能です。
steps: サンプリングステップ数を指定します。大きな値ほど生成されるビデオの品質は向上しますが、処理時間も増加します。
cfg: Classifier Free Guidance (CFG) スケールを指定します。CFG は、ポジティブプロンプトとネガティブプロンプトのバランスを調整することで、生成されるビデオの内容を制御する手法です。大きな値ほどポジティブプロンプトの影響が強くなります。
seed: 乱数シードを指定します。同じシード値を使用すると、同じビデオが生成されます。
control_after_generate: 生成処理後のシード値の制御方法を設定します。fixed, increment, decrement, randomizeから選択可能です。
scheduler: サンプリングに使用するスケジューラを選択します。選択肢は DDIM, DPM, DDIM_tiledです。
DDIM (Denoising Diffusion Implicit Models): 高速なサンプリングが可能なスケジューラです。
DPM (Denoising Diffusion Probabilistic Models): DDIM よりも高品質なビデオを生成できるスケジューラですが、処理速度は遅くなります。
DDIM_tiled: DDIM をベースとしたスケジューラで、時間方向のタイリングを用いることでメモリ使用量を削減します。
t_tile_length: 時間方向のタイリングの長さを指定します。タイリングは、ビデオを複数のセグメントに分割して処理することで、メモリ使用量を削減する手法です。値は 2 から 128 の範囲で設定可能です。
t_tile_overlap (必須): 時間方向のタイリングのオーバーラップを指定します。値は 2 から 128 の範囲で設定可能です。
denoise_strength (任意): ノイズ除去強度を指定します。値は 0.0 から 1.0 の範囲です。
CogVideo Decode
このノードは、CogVideoSampler ノードから出力された潜在空間を、人間が認識できる画像 (ビデオフレーム) に変換します。具体的には、VAE を用いて潜在空間をデコードします。

以下は、入力や出力、ウィジェットの詳細になります。
enable_vae_tiling: VAE のタイリングを有効にするかどうかを指定します。タイリングは、画像を複数のタイルに分割して処理することで、メモリ使用量を削減する手法です。True に設定すると、VAE タイリングが有効になり、GPU メモリ使用量が削減されます。False に設定すると、VAE タイリングは無効になり、画像全体が一度に VAE に入力されます。
tile_sample_min_height: VAE タイリングの最小高さを指定します。タイルの高さがこの値よりも小さい場合、タイルは結合され、より大きなタイルとして処理されます。
tile_sample_min_width: VAE タイリングの最小幅を指定します。タイルの幅がこの値よりも小さい場合、タイルは結合され、より大きなタイルとして処理されます。
tile_overlap_factor_height: VAE タイリングの高さ方向のオーバーラップ係数を指定します。オーバーラップとは、隣接するタイルが重なる部分のことです。オーバーラップを設けることで、タイルの境界部分におけるアーティファクトを軽減できます。この値は、タイルの高さに対するオーバーラップの割合を表します。例えば、0.1 に設定すると、タイルの高さの 10% がオーバーラップします。
tile_overlap_factor_width: VAE タイリングの幅方向のオーバーラップ係数を指定します。この値は、タイルの幅に対するオーバーラップの割合を表します。
enable_vae_slicing: VAE のスライスを有効にするかどうかを指定します。デフォルトは True です。True に設定すると、VAE の処理を複数のステップに分割することで GPU メモリ使用量を削減できます。
Video Combine
Video Combineは、画像または潜在空間のシーケンスから、GIF、WebP、またはビデオファイルを作成します。

frame_rate: 1秒間に表示されるフレーム数を指定します。フレームレートが高いほど、ビデオは滑らかに見えますが、ファイルサイズも大きくなります。逆に、フレームレートが低いほど、ビデオはカクカクして見えますが、ファイルサイズは小さくなります。
loop_count: ビデオのループ回数を指定します。0 を指定すると、ビデオは無限にループします。正の整数を指定すると、ビデオはその回数だけループします。
filename_prefix: 出力されるビデオファイルのファイル名のプレフィックスを指定します。ファイル名のプレフィックスは、ファイル名のはじめに付加される文字列です。ファイル名を識別しやすくするために使用します。
format: 出力されるビデオファイルのフォーマットを指定します。サポートされているフォーマットは、"image/gif"、"image/webp"、および ffmpeg がサポートするビデオフォーマットです。ffmpeg がサポートするビデオフォーマットには、"video/mp4"、"video/webm"、"video/avi" などがあります。
pix_fmt: ビデオフレームのピクセルデータの表現形式を指定します。ピクセルフォーマットは、色情報やアルファチャンネルの有無、ビット深度など、ピクセルデータの構造を定義します。適切なピクセルフォーマットを選択することで、ビデオの品質、ファイルサイズ、互換性などを調整できます。
yuv420p: 一般的なフォーマットで、多くのデバイスやソフトウェアでサポートされています。ファイルサイズが比較的小さくなります。
yuv420p10le: 10ビットの色深度を持つYUV 4:2:0フォーマットです。HDRコンテンツに適しています。より広いダイナミックレンジとより滑らかな階調表現が可能です。
crf: ビデオの圧縮率を制御します。crf は、ビデオ圧縮における品質とファイルサイズのトレードオフを調整するためのパラメータです。値が小さいほど画質は向上しますが、ファイルサイズも大きくなります。逆に、値が大きいほどファイルサイズは小さくなりますが、画質は低下します。
save_metadata: 出力ビデオファイルにメタデータを埋め込むかどうかを指定します。メタデータには、プロンプト情報や生成日時などが含まれます。メタデータを埋め込むことで、ビデオファイルの情報管理が容易になります。
pingpong: ピンポン再生を有効にするかどうかを指定します。ピンポン再生が有効になっている場合、ビデオは最初のフレームから最後のフレームまで再生された後、最後のフレームから最初のフレームまで逆再生されます。そして、このサイクルが繰り返されます。
save_output: 出力されるビデオファイルを保存するかどうかを指定します。save_output が True の場合、ビデオファイルは output ディレクトリに保存されます。save_output が False の場合、ビデオファイルは temp ディレクトリに一時的に保存されます。
5. ワークフローの実行
それでは、これまでの設定でワークフローを実行します。
以下は、CogVideoX-2bの生成結果です。足が破綻していたり、後ろのフェンスが歪んでしまっています。

以下は、CogVideoX-5bの生成結果です。2bに比べて破綻が少なく、動画として成立しているように見えます。


この記事でご紹介したAI技術の応用方法について、もっと詳しく知りたい方や、実際に自社のビジネスにAIを導入したいとお考えの方、私たちは、企業のAI導入をサポートするAIコンサルティングサービスを提供しています。以下のようなニーズにお応えします。
AIを使った業務効率化の実現
データ分析に基づくビジネス戦略の立案
AI技術の導入から運用・教育までの全面サポート
専門家によるカスタマイズされたAIソリューションの提案
初回相談無料ですので、お気軽にご相談ください。以下のリンクからお問い合わせください。
https://www.ponotech.net/contact/
この記事が気に入ったらサポートをしてみませんか?