
動画も高精度に!ComfyUIとSegment Anything Model 2(SAM 2)でセグメンテーションをマスターしよう

コンピュータビジョンの世界に革命をもたらした画像セグメンテーションモデル「Segment Anything Model(SAM)」。その登場から約1年、METAが新たな進化を遂げた「Segment Anything Model 2(SAM 2)」を発表しました。画像だけでなく動画にも対応したこの最新モデル、使い方によってはかなり実用的になり得るでしょう。
本記事では、SAM 2の特徴や機能、そして将来の可能性について詳しく解説します。また、ComfyUIで実際に動作させる方法についても解説します。
1. Segment Anything Model 2(SAM 2)とは

2024年7月29日、METAは画像と動画の両方に対応した最新のオブジェクトセグメンテーションモデル「Segment Anything Model 2(SAM 2)」を発表しました。SAM 2は、昨年リリースされた画像セグメンテーションモデル「Segment Anything Model(SAM)」の後継として開発され、画像だけでなく動画にも対応した革新的な機能を備えています。
SAM 2の主な特徴
統合モデル: SAM 2は、画像と動画の両方でオブジェクトセグメンテーションを行える初めての統合モデルです。
リアルタイム処理: プロンプトベースのセグメンテーションをリアルタイムで実行できます。
ゼロショット汎化: 事前に学習していない物体や視覚ドメインでもセグメンテーションが可能です。
高性能: 画像と動画の両方で最先端の性能を達成しています。
柔軟性: カスタム適応なしに多様な用途に適用できます。
技術的詳細
SAM 2は、統一されたプロンプト可能なモデルアーキテクチャを採用しています。このモデルは、1100万枚のライセンス画像とプライバシーを尊重した画像、110万枚の高品質セグメンテーションマスクデータ、10億以上のマスクアノテーションという過去最大のデータセットで訓練されています。
また、SAM2は、画像と動画のセグメンテーションを統合する革新的なアーキテクチャを採用しています。

画像エンコーダー: 入力フレームを高次元の特徴表現に変換します。
アーキテクチャ: Vision Transformer (ViT)ベース
出力: 空間的に構造化された特徴マップ
マスクデコーダー: セグメンテーションマスクを生成します。
アーキテクチャ: Transformer decoder
入力: 画像特徴、プロンプト埋め込み
出力: 2D確率マスク
メモリメカニズム:
メモリエンコーダー: 現在のマスク予測からメモリトークンを生成
メモリバンク: 過去フレームとプロンプトからのメモリを保存
メモリアテンション: 現在フレーム埋め込みとメモリを統合
オクルージョンヘッド: オブジェクトの可視性を予測します。
アーキテクチャ: 軽量なMLPネットワーク
出力: フレームごとの可視性スコア
SAM 2の特筆すべき機能の一つが「メモリバンク」です。これは最近のフレームや以前にプロンプトされたフレームの情報を空間特徴マップとして保持する機能で、短期的な物体の動きを符号化し、オブジェクトトラッキング能力を向上させています。
応用分野
SAM 2は以下のような幅広い分野での活用が期待されています。
クリエイティブ産業: ビデオ編集の改善、ユニークな視覚効果の作成
医療画像処理: 解剖学的構造の正確な識別
自動運転: 知覚能力の向上、ナビゲーションと障害物回避の改善
科学研究: 海洋科学での音波画像のセグメンテーション、サンゴ礁の分析
災害救援: 衛星画像の分析
データアノテーション: アノテーション作業の高速化
オープンソースとデータセット
METAは、SAM 2のコードとモデルのweightsをApache 2.0ライセンスで公開しています。さらに、SAM 2の開発に使用されたSA-Vデータセットも公開されており、約51,000本の実世界の動画と60万以上のマスクレット(時空間マスク)が含まれています。このデータセットはCC BY 4.0ライセンスで提供され、研究者やデベロッパーが自由に利用できます。
2. ComfyUIでの実行準備
まずは、SAM2をComfyUIで実行するための準備をしましょう。
カスタムノード
以下のカスタムノードをインストールしてください。すべてComfyUI Managerからインストール可能です。
ComfyUI-segment-anything-2
Kijai氏が作成したSAM2用のカスタムノード
SAM2に必要なモデルは、Kijai氏のHugging Faceのリポジトリから自動でダウンロードされる
ComfyUI-Florence2
Florence2を使用するためのカスタムノード
Florence2でプロンプトからのオブジェクト検出を実現する
KJNodes for ComfyUI
ImageAndMaskPreview: 画像とマスクを両方合わせてプレビューするためのノード
Resize Image: 画像サイズの変更に使用されるノード
comfyui-tensorop
ComfyUI-Florence2で必要
ComfyUI-VideoHelperSuite
動画を処理するためのカスタムノード
ワークフロー
ComfyUI-segment-anything-2のリポジトリで配布しているサンプルを使用します。サンプルは、オブジェクト自動検出による画像のセグメンテーション、同様の手法による動画のセグメンテーション、指定した箇所のセグメンテーションの3種類があります。以下のリポジトリからワークフローのJSONファイルをダウンロードし、ComfyUIのキャンバスにロードしてください。
オブジェクト自動検出による画像のセグメンテーション
オブジェクト自動検出による動画のセグメンテーション
指定箇所のセグメンテーション
3. ワークフローの解説: オブジェクト自動検出による画像のセグメンテーション
グラフの全体像
以下がグラフの全体図になります。

以下に今回使用するグラフのフローチャートと詳細を示します。
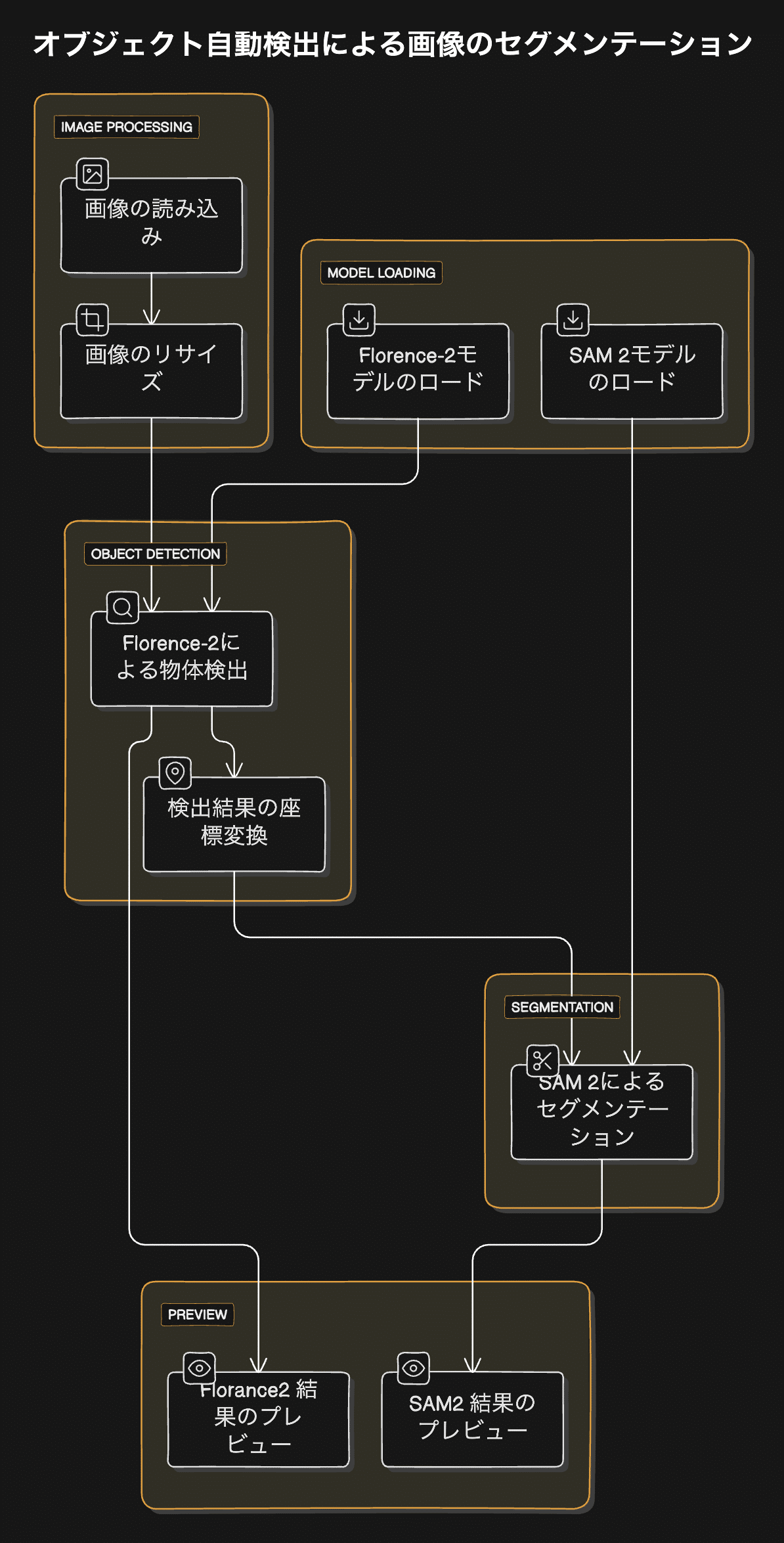
このグラフは、Florence-2とSAM 2を組み合わせて画像内のオブジェクトを検出し、セグメンテーションを行うプロセスを示しています。以下に詳細な解説を提供します。
グラフの主要コンポーネント
画像の読み込み (LoadImage ノード)
Florence-2モデルのロード (DownloadAndLoadFlorence2Model ノード)
SAM 2モデルのロード (DownloadAndLoadSAM2Model ノード)
画像のリサイズ (ImageResizeKJ ノード)
Florence-2による物体検出 (Florence2Run ノード)
検出結果の座標変換 (Florence2toCoordinates ノード)
SAM 2によるセグメンテーション (Sam2Segmentation ノード)
結果のプレビュー (ImageAndMaskPreview ノード)
グラフの詳細な解説
画像の読み込み:
「truck.jpg」という画像ファイルを読み込みます。
Florence-2モデルのロード:
「microsoft/Florence-2-base」モデルをFP16精度でロードします。
SAM 2モデルのロード:
「sam2_hiera_small.safetensors」モデルをCUDAデバイスでBF16精度でロードします。
画像のリサイズ:
入力画像を768x512ピクセルにリサイズします。(大きすぎる画像を小さくしているだけなので、このノードをスキップしても問題ありません)
Florence-2による物体検出:
リサイズされた画像に対してFlorence-2モデルを実行します。
「wheel」(車輪)をプロンプトとして使用し、画像内の車輪を検出します。
出力には検出されたオブジェクトの情報(バウンディングボックスなど)が含まれます。
検出結果の座標変換:
Florence-2の出力をSAM 2で使用可能な座標形式に変換します。
SAM 2によるセグメンテーション:
Florence-2で検出されたバウンディングボックスを使用して、SAM 2モデルでセグメンテーションを実行します。
結果として、検出されたオブジェクト(車輪)の詳細なセグメンテーションマスクが生成されます。
結果のプレビュー:
元の画像とセグメンテーションマスクを組み合わせて表示します。
マスクは赤色(RGB: 255, 0, 0)で表示されます。
4. ワークフローの解説: オブジェクト自動検出による動画のセグメンテーション
グラフの全体像
以下がグラフの全体図になります。
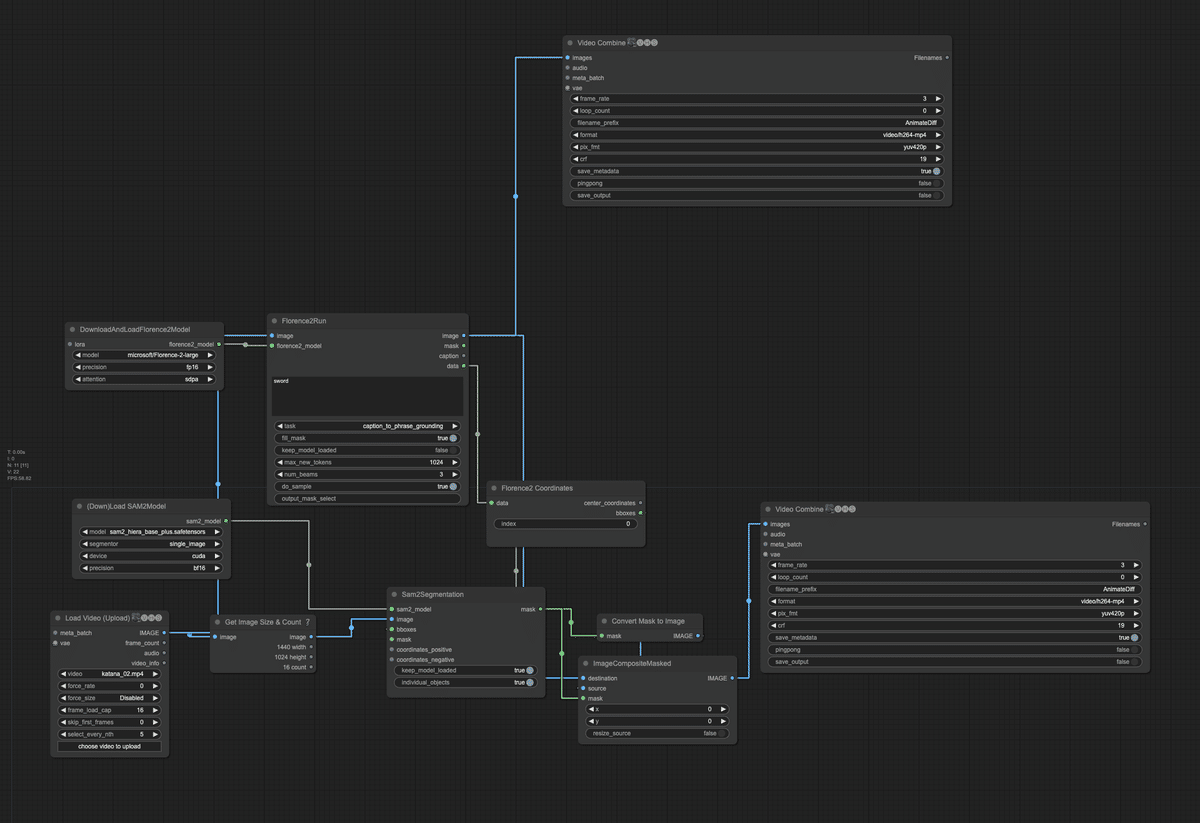
以下に今回使用するグラフのフローチャートと詳細を示します。
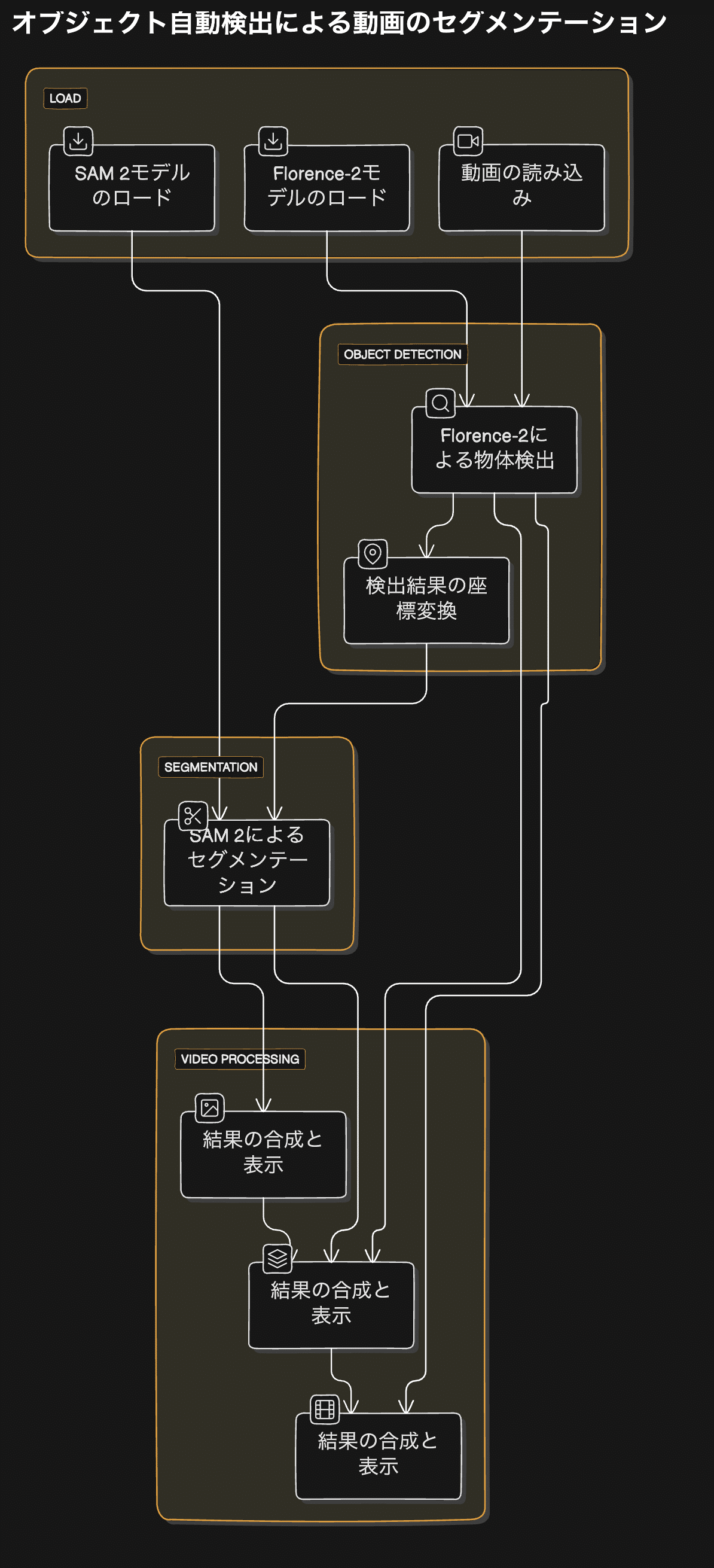
グラフの主要コンポーネント
動画の読み込み (VHS_LoadVideo ノード)
Florence-2モデルのロード (DownloadAndLoadFlorence2Model ノード)
SAM 2モデルのロード (DownloadAndLoadSAM2Model ノード)
Florence-2による物体検出 (Florence2Run ノード)
検出結果の座標変換 (Florence2toCoordinates ノード)
SAM 2によるセグメンテーション (Sam2Segmentation ノード)
結果の合成と表示 (MaskToImage, ImageCompositeMasked, VHS_VideoCombine ノード)
グラフの詳細な解説
動画の読み込み:
「katana_02.mp4」という動画ファイルを読み込みます。
16フレームを上限とし、5フレームごとに1フレームを選択して処理します。
Florence-2モデルのロード:
「microsoft/Florence-2-large」モデルをFP16精度でロードします。
SAM 2モデルのロード:
「sam2_hiera_base_plus.safetensors」モデルをCUDAデバイスでBF16精度でロードします。
Florence-2による物体検出:
読み込んだ動画フレームに対してFlorence-2モデルを実行します。
「sword」(剣)をプロンプトとして使用し、画像内の剣を検出します。
検出結果の座標変換:
Florence-2の出力をSAM 2で使用可能な座標形式(バウンディングボックス)に変換します。
SAM 2によるセグメンテーション:
Florence-2で検出されたバウンディングボックスを使用して、SAM 2モデルでセグメンテーションを実行します。
結果として、検出されたオブジェクト(剣)の詳細なセグメンテーションマスクが生成されます。
結果の合成と表示:
セグメンテーションマスクを画像に変換し、元の動画フレームと合成します。
合成された画像をフレームごとに処理し、最終的な動画として出力します。
5. ワークフローの解説: 指定箇所のセグメンテーション
グラフの全体像
以下がグラフの全体図になります。
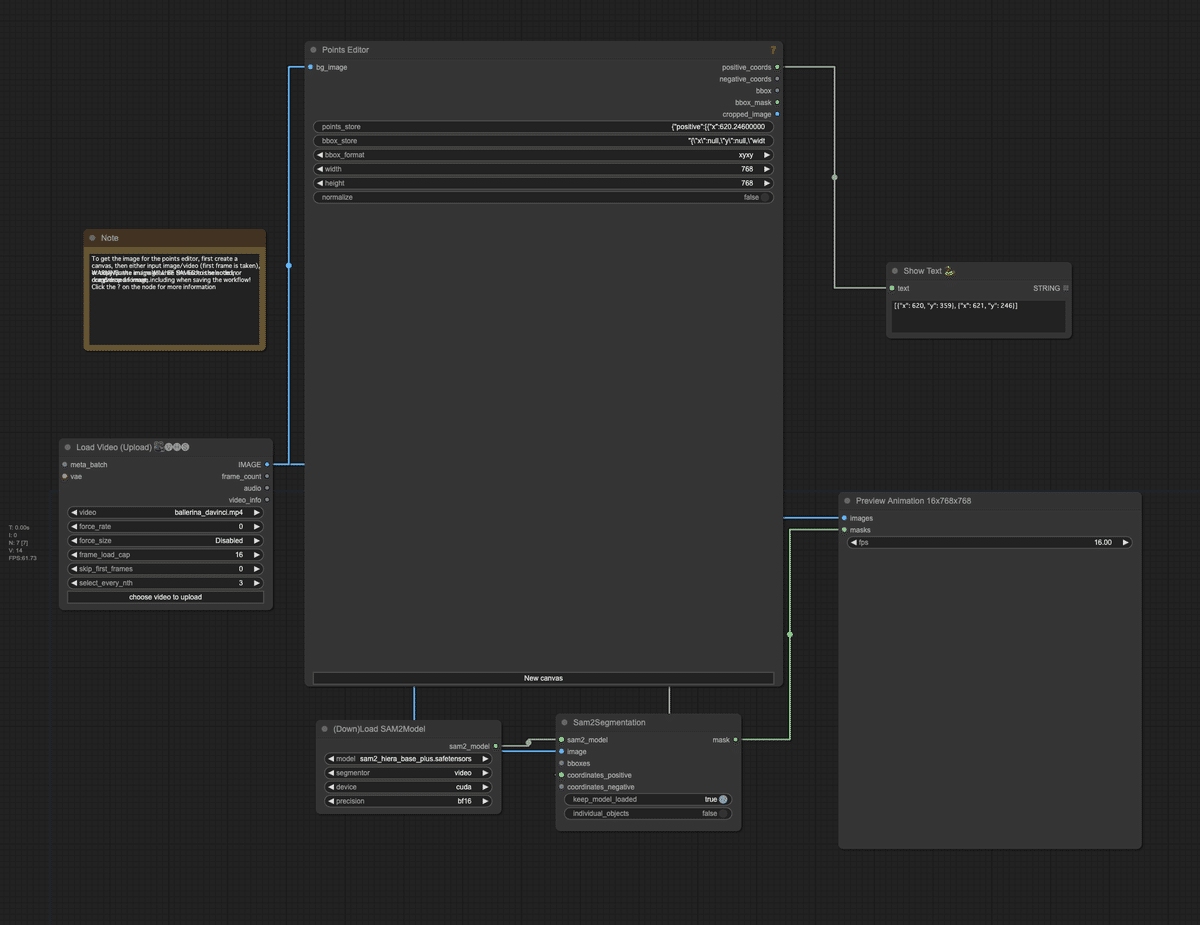
以下に今回使用するグラフのフローチャートと詳細を示します。

グラフの主要コンポーネント
動画の読み込み (VHS_LoadVideo ノード)
SAM 2モデルのロード (DownloadAndLoadSAM2Model ノード)
ユーザーによる点の指定 (PointsEditor ノード)
SAM 2によるセグメンテーション (Sam2Segmentation ノード)
結果のアニメーションプレビュー (PreviewAnimation ノード)
座標情報の表示 (ShowText ノード)
グラフの詳細な解説
動画の読み込み:
「ballerina_davinci.mp4」という動画ファイルを読み込みます。
16フレームを上限とし、3フレームごとに1フレームを選択して処理します。
SAM 2モデルのロード:
「sam2_hiera_base_plus.safetensors」モデルをCUDAデバイスでBF16精度でロードします。
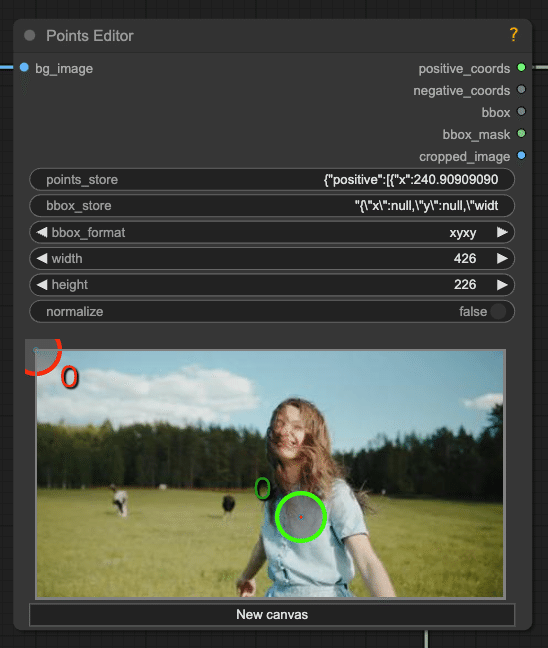
ユーザーによる点の指定:
動画の最初のフレームを表示し、ユーザーがセグメンテーションしたいオブジェクト(この場合はダンサー)上に点を配置できるインターフェースを提供します。
この例では、ダンサーの上半身に2つの正の点が配置されています。
SAM 2によるセグメンテーション:
ユーザーが指定した点の情報と動画フレームを入力として、SAM 2モデルでセグメンテーションを実行します。
結果として、指定されたオブジェクト(ダンサー)の詳細なセグメンテーションマスクが生成されます。
結果のアニメーションプレビュー:
元の動画フレームとSAM 2で生成されたセグメンテーションマスクを組み合わせて、アニメーションとして表示します。
これにより、ユーザーはセグメンテーション結果をリアルタイムで確認できます。
座標情報の表示:
ユーザーが指定した点の座標情報を表示します。
6. ワークフローの実行
オブジェクト自動検出による画像のセグメンテーション
今回使用した画像は以下になります。

これを「truck.jpg」という名前でLoad Imageの「choose file to upload」でComfyUI上にアップロードします。

画像サイズに合わせて、Resize Imageのwidthとheightを変更します。

検出するオブジェクトは、wheelのままにします。

これでワークフローを実行してみます。メニューの「Queue Prompt」をクリックしてください。
しばらくすると、検出結果が出力されます。まずは、Florance2によるオブジェクトの検出結果です。しっかり写真に写っているタイヤがすべて検出されています。

次にSAM2によるセグメンテーションの結果です。Florance2で検出したタイヤがしっかりとマスクされています。

オブジェクト自動検出による動画のセグメンテーション
まず、検証に使用する動画素材を入手します。以下のリンクから動画をダウンロードします。今回選んだ動画は、女性が牧場ではしゃいでいる動画になります。
https://www.pexels.com/ja-jp/video/4919748/
今回は実験的にSAM2を動かすので、426x226の小さいサイズをダウンロードします。
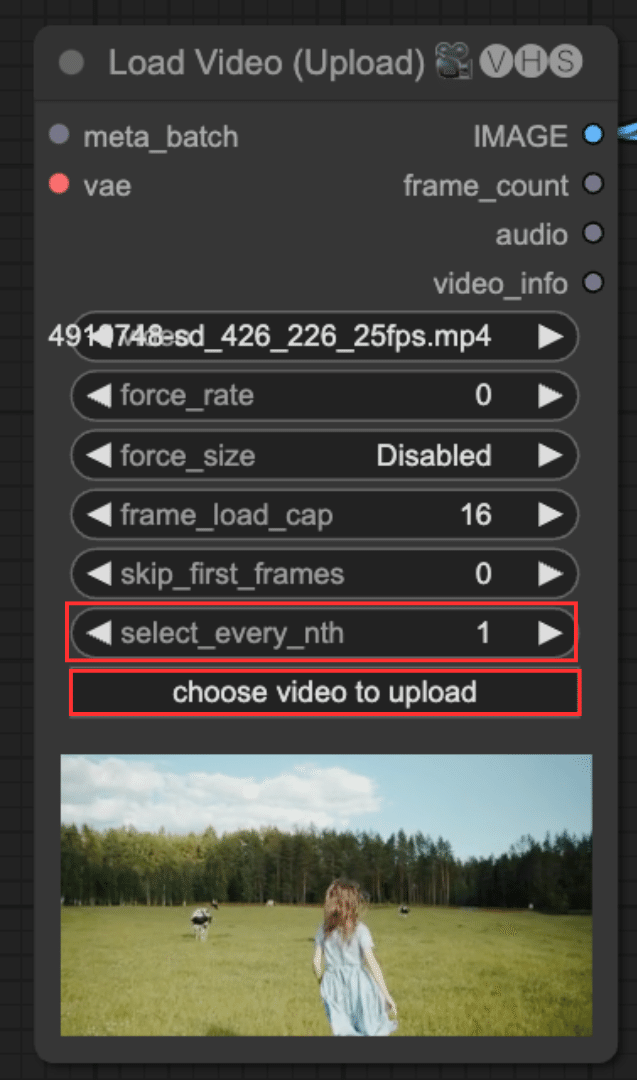
ダウンロードした動画をComfyUIにアップロードします。Load Video (Upload)の「choose video to upload」から動画をアップロードします。
Load Video (Upload)の初期設定では、frame_load_cap(*1)が16になっており、最初の16フレーム(*2)のみを読み込むようになっています。検証としては、それで問題ないですが、もし動画を全て読み込んで欲しい場合は、frame_load_capを0に設定してください。
また、初期設定では、select_every_nthが5になっていますが、これは1に変更してください。select_every_nthは、何フレームごとに1フレームを選択するかを指定するウィジェットです。1を設定することで、フレームをスキップせずに、全てのフレームが対象になります。
*1 読み込むフレーム数を指定するウィジェット。例えば、24fpsの動画で、frame_load_capに16を指定すると、16/24 ≒ 0.7秒となる。
*2 動画を構成する個々の静止画であり、1秒間に表示されるフレーム数(fps: frames per second)によって動きの滑らかさが決まります。
次に、Florence2Runのプロンプトを変更します。今回は、女性をセグメンテーションするため、「girl」を入力します。

これで生成を実行(Queue Prompt)します。以下が最終的な実行結果です。最初に後ろの牛を誤検出しているように見えますが、それ以外は問題ないように見えます。

指定箇所のセグメンテーション
前項の「オブジェクト自動検出による動画のセグメンテーション」で使用した動画を今回も使用します。動画は以下からダウンロードしてください。
https://www.pexels.com/ja-jp/video/4919748/
前項と同様に、Load Video (Upload)の「choose video to upload」から動画をアップロードします。
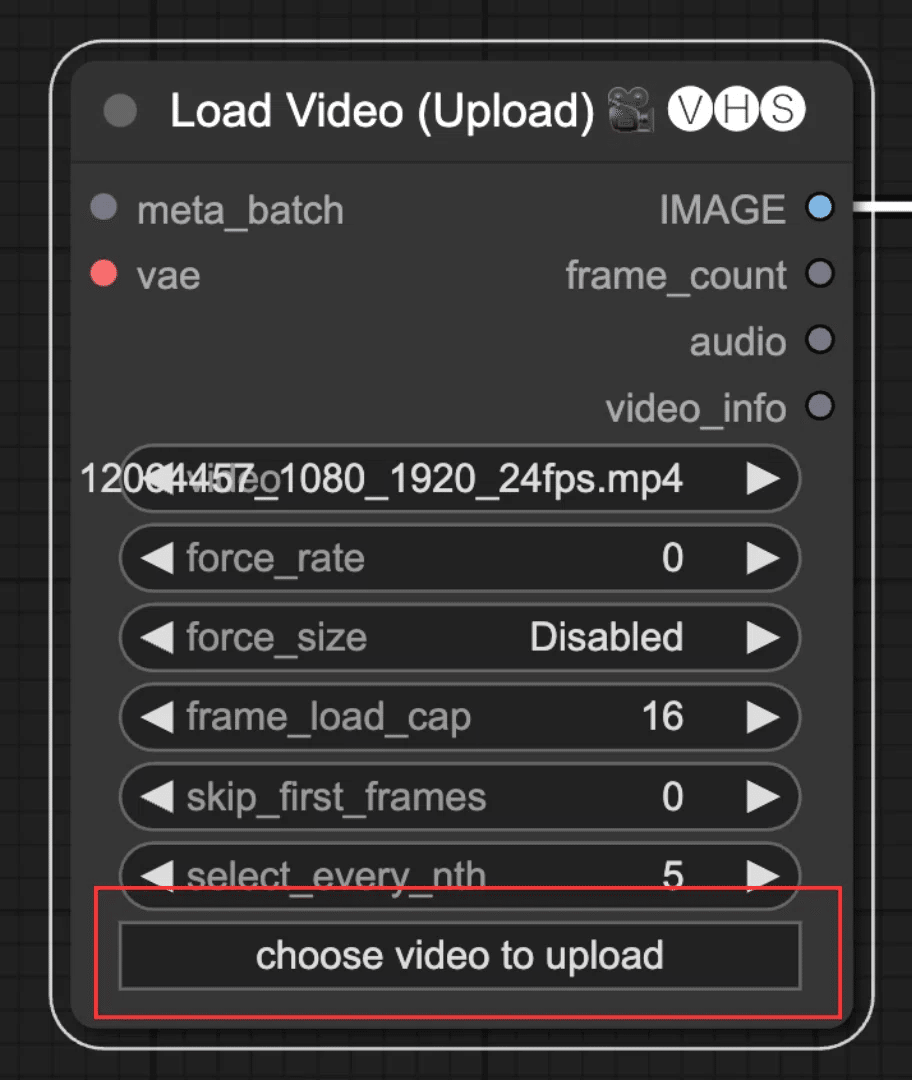
次にセグメンテーションする箇所を指定します。オブジェクトの指定は、Points Editorで行います。ワークフローの初期状態では、Points Editorにバレエの女性の写真が表示されています。

まずは、オブジェクト検出箇所を指定するために、この写真を現在の動画の1フレーム目の画像にする必要があります。それには2つの方法があります。1つは、動画の1フレーム目の画像を用意し、Points Editorに写真の箇所を右クリックして表示されるコンテキストメニューの「Load Image」で画像を差し替える方法です。2つ目は、ワークフローを実行すると、Points Editorに写真の箇所が自動でアップロードした動画の1フレーム目に切り替わる性質を利用して、一先ずワークフローを実行し、オブジェクト検出箇所指定に使う画像を差し替える方法です。後者の方が楽なので、一先ずワークフローを実行し、画像を差し替えます。

一度ワークフローを実行すると、以下のように動画の1フレーム目の画像が表示されます。Points Editorにバグがあるようで、左上に赤丸が残った状態になってしまいます。こちらは利用せずに、画像上に緑色の丸が表示されている場合は、女性の上に緑色の丸を配置してください。緑色の丸が表示されていない場合は、女性をクリックすると、新たに緑色の丸を追加できます。
これで生成を実行(Queue Prompt)します。以下が最終的な実行結果です。女性が綺麗にマスクされています。

7. まとめ: ComfyUIとSAM 2でセグメンテーションがより身近な存在に
本記事では、画像や動画のセグメンテーションにおいて革新的な進化を遂げた「Segment Anything Model 2 (SAM 2)」について解説し、ComfyUIを用いた具体的な使用方法を紹介しました。
SAM 2は、従来のSAMと比較して、動画への対応、リアルタイム処理、高精度なセグメンテーションを実現しており、その応用範囲は多岐に渡ります。
ComfyUIのワークフローを活用することで、オブジェクトの自動検出によるセグメンテーションや、指定箇所のセグメンテーションを容易に行うことができます。
SAM 2はまだ発展途上の技術ですが、今後の進化によって、映像制作、医療画像解析、自動運転など、様々な分野で大きな影響を与える可能性を秘めていると言えるでしょう。

この記事でご紹介したAI技術の応用方法について、もっと詳しく知りたい方や、実際に自社のビジネスにAIを導入したいとお考えの方、私たちは、企業のAI導入をサポートするAIコンサルティングサービスを提供しています。以下のようなニーズにお応えします。
AIを使った業務効率化の実現
データ分析に基づくビジネス戦略の立案
AI技術の導入から運用までの全面サポート
専門家によるカスタマイズされたAIソリューションの提案
初回相談無料ですので、お気軽にご相談ください。以下のリンクからお問い合わせください。
この記事が気に入ったらサポートをしてみませんか?