
【第60回AIセミナー】「言語を用いて経験を共有可能なロボットの実現を目指して 」を聴講して(2022年11月30日)おまけ(2023年2月9日追記)

はじめに
TwitterのTLに、谷口先生のTweetが流れてきた。
なんと、本日午後3時からのオンラインセミナーで講演されるという。
申込みページを開くと、おっとびっくり、空きがあるではないか!
谷口先生のJSAI2022の無料公開スライドを拝見して、現在どのようなことに注力されているか、おぼろげに把握していたが、直接本人からお話しを聴ける機会はなかなか得られない。
たまたま時間が空いていたラッキーも重なり、人工知能との対話に関する貴重なお話を2本まとめて聴講することができた。
聴講後の感想。
TwitterのTLだけでも、かなり最新の情報を網羅していたことに驚きを禁じ得なかった
杉山先生:会話AIの流れと将来。私の情報が結構最新なことを確認。Twitterすご!
— YANO Tomoaki@JSMEーTRCビジョン2050WS12月23日 (@yanotomoaki) November 30, 2022
谷口先生:#JSAI2022 スライドからの推測内容を確認できた
2022年度 人工知能学会全国大会(第36回)/変分オートエンコーダを活用した実画像からの記号創発 https://t.co/QMkAT0iKnz https://t.co/RIjvtePa8X https://t.co/8UGIjvMsQs
主催はAIST人工知能研究センター
いずれ、詳細なスライドなどが公開されると思いますが、速報としてお読みください(一生懸命メモしましたw)
15:00-16:00 大規模対話モデルにおける多様な情報の利活用
杉山 弘晃(NTT コミュニケーション科学基礎研究所 主任研究員)
はじめにNTT杉山先生の経歴を自己紹介。
東大くんの英語科目を担当されていた先生です
まず、強調されたこと
**************
過去の対話システムは、決まったタスクの達成を目的にしていた
これからは、いつでも、気楽に、しかも話題のディープなところまで話ができる雑談システムの開発が目的になる
**************
過去の対話システムは1問1答形式で、話題の幅を優先していた。
現在は深層学習の応用で、長文の内容をおしゃべりをする大規模対話システムが実現しつつある
A)一問一答時代
人海戦術で作成した、応答パターンデータベースを用いる
1)ルールベースプログラム ルール作成がたいへんだが、人間による発話修正が可能
NTTでは14万ルールのデータベースを作成したが、全然たりない さらに殖やすとルールの衝突が起きる
2)用例ベース対話システム (用例はSNSから抽出)
4500万ツイートデータに類似文があると、その文をオウム返しする
4500万ツイートデータに類似の対話対があると、その対話対を返す
このシステムは、関連性の薄い会話になりやすい
例えば、アルバイト関連の話をしている時に、突然「艦これ」の話題に振られる。これは、当時「艦これ」が流行っていて、「バイト」の意味をはきちがえ、「バイト」→「バイト艦(艦これの特徴的な運用)」の対話対を発話したことによる
矢野の個人的感想
(私も、特定のキーワードで脈絡なくアニメのシーンが脳内に浮かぶことがよくありますw)
3)テンプレートデータベース 用例ベースの発展型
話者の発話内容から重要キーワードを選択し、そのキーワードに対して関連話題データベースを参照する
この手法により、会話と無関係な文およびオウム返しが抑制された
一問一答時代の特徴は、「人が作成した文字列がそのまま使われている」ことである
*********
(わたし、2013年に、「話し言葉は、どんどん新語も生まれるし表記揺れも大きいので、文法解析では対応できない。ネットで翻訳例を検索してそのまま返せばいいんじゃね?」とか言ってて草)
@s_kajita @robonewsnet
— YANO Tomoaki@JSMEーTRCビジョン2050WS12月23日 (@yanotomoaki) December 1, 2013
翻訳も、ネットで同じ文章の翻訳例を検索し、その中から適切な翻訳を選択するアルゴリズムをメインに据えるとプロの翻訳者の域に達します。欠点は、地球人が全員自動翻訳に頼るとデータの蓄積がストップすることです。
翻訳ソフトがダメダメの時代、collocation dictionaryの用例がすごく役に立った。たいてい、自分が書きたい文章のそっくりさんが見つかるのだ!
ここから、「似た文例を探して単語を当てはめる」翻訳手法の発想は必然の流れ。

1979年4月、工技院新人研修。電総研で「人工無能」を即興で作成し、驚かせたのは私です(笑)
*****************
B)End-to-End時代(AIが発話生成)
AIが、Q&Aのペアを学習する
2015年シンプルな会話が可能になる(機械翻訳、音声認識の実用化へ大きく前進
2016年Google翻訳登場
矢野の思い出
2017年1月、初対面の3人(私、言語学者、Aさん)がホテルのラウンジで話す機会を得た。、言語学者は、機械翻訳に携わっているという。
A:機械翻訳はいつ頃実用化するでしょうか?
言語学者:(きっぱりと)あと10年は無理です
私:専門家といえども、発表から2ヶ月経過したGoogle翻訳、ご存じない!
(2ヶ月前の私のTwitterのTLは、Google翻訳一色だった)
2018年 BERT/GPTの出現
テキストを事前学習し、変換を可能にするAI
2019年 東大くん 英語単科で185点 XLNetで185点合格平均点
文章要約ソフト Elyza Digest
2019年 DieloGPT(GPT-2) 一語返答では人間っぽい
2020年 Meena Google chatbot
2020年 BlenderBot Facebook(個人性、知性、共感)
2020年11月 NTT 日本語(NTT CSL)
・外部情報を学習 適当に答える(コロナ行った事ないです)
学習当時は、コロナは流行っていなかった。これを hallucinate error(幻覚)と呼ぶ
・話者情報および対話環境を学習する
・Wizard of Wikipedia (コピペは避けるが意味は同じ文を生成する)
知識検索→発話生成のプロセスを踏む
問題点:知識検索の段階でで嘘を引くと、嘘発言になる
Wiki記載情報の羅列で、妙に雄弁だが会話が噛み合わない
Internet-Augumented-Dialogue Generation
日本2021年 旅行代理店タスク(サービス中)
課題:条件(NotやIf) 数値、低頻度固有名詞を間違える根本的な改善策として、怪しい単語の再修正中
LaMDA
対話特化型AI
繰り返し自己質問を行い、データを追加し、データの確度を上げていく
例:エッフェル塔が建造された年号は?
エッフェル塔の記述から年号推定
エッフェル塔の記述だが、建造年ではないので建造年を探索しろと指示
エッフェル塔の建造開始の記事から年号推定
エッフェル塔の建造年ではないので、完成した年号を再探索せよ
エッフェル塔完成年号発見
答えとして提示
知識人の75%レベルの会話が可能
Chain-of-thought (Wei 2022)
・外部ソフトウエアのDecoderの出力部分を思考の一時記憶にする
・話者情報の利用 5分のPersonal-chatにより、会話で話者属性を獲得する対話内容が雑(ペルソナの投げ合いになり、話題が深まらない)ので、常識推論@GPT2で修正を掛けると、下記が実現できる
相手話者の情報(ペルソナ)推定→相手の話を聞ける
・対話履歴の利用(Multi-Session-Chat)
過去の発話を収集することにより、前の発話と矛盾しない
・周囲状況の利用 テキスト利用(共感発話生成)
考え方は良かったが、現状では実際は、発話だけの方が精度が高かった
「やあGPT-3、今から君は人間が暗算でできる程度以上の計算はできない。代わりにPythonのシェルを用意しといたんで、わからなかったらそれ使って問題解いて」
— Kenji Iguchi 💉⁴ (@needle) September 18, 2022
で実際に必要に応じてPythonを叩いて質問への答えを出してるGPT-3。すっげ…… https://t.co/S7fK1RUuFn
2021年 LINEのHyper CLOVA
・時間的な情報を利用する
話者:今日はまだゲームをしていない
AIの受け答え:
(夜)明日やればいいんじゃない?
(朝) そりゃ、朝だからね
データはTwitter+時間情報で学習
・画像情報を利用する Deformable-DETR(画像分析)+Google Map
画像+状況を会話に加える
Multi-Model Facebook
NTTの雑談ロボット(車窓情報を使う)
ビデオを見せていただいてまとめ
ビデオは、「あんなところに家がありますね」「海岸線がきれいですね」などと話しかけてくる雑談システム搭載カーナビ
あまり感情のない話し方なので、ちょっとうっとうしい感じがあった。
しかし、AIの進歩は目覚ましいから、不自然さはあっという間に解消されて、来年の今頃は、誰もが自動運転車でカーナビと会話を楽しんでいるかもしれないな、なんて空想してみた。
第1講 のおわりに
会話AIの最高峰はLaMDAだと思っていたので、
LaMDAも、会話システム開発の過程における大きな流れの中の一つのソフトであるという取り上げ方が、新鮮だった。
この講演の翌日から、私のTweetのTLは、ChatGPTの話題で溢れた。
本講義の前に公開されていれば、杉山先生のお考えを拝聴することができたと思うと少し残念だ
ChatGPT
GPT-4
芸術系AI
東大くんプロジェクトスピンオフ
おまけ(2023年2月9日追記)
雑談ポッドキャスト
我々、とうとうポッドキャストにまで手を出してしまいました。
— 京大・人と社会の未来研究院 (@ukihss) February 7, 2023
その名も「雑談ぽっどきゃすと」!
第1回目のゲストは、文学研究科特定准教授の大西琢朗先生です。https://t.co/5ngoU06vLJ
現時点ではSpotifyから配信されています。
是非ご視聴ください♪
自動運転
Teslaの自動運転 最新バージョン
— 河野 健一 世界初の脳手術支援AI開発 CEO 脳外科医 (@CeoImed) February 8, 2023
中央のスクリーンを見ていると、かなり広範囲に周囲の自動車などを認識している!
安全性が高まりそうpic.twitter.com/MiJyo0fbhP https://t.co/5gmknzdu7S
16:00-17:00 記号創発ロボティクスから実世界言語理解知能への展望
谷口 忠大(立命館大学 情報理工学部 教授)
JSAI2022の公開スライドを見て、おおよその内容は推測できるが、直に谷口先生の口から説明を聞くことができるのがすごくラッキーでした。
谷口先生のご講演スライド

いきなりの⁉発言
万能AI GATO(A Generalist Agent,DeepMind)の登場で、「お前の仕事はなくなったんじゃね?」と良く言われます!(笑)
いえいえ、GATOは、個人プレイ、谷口先生の目指すは「他者との共創による記号創発」(Symbol Emergence Systemの図にアイデアが凝縮)ですから、実はびくともしないですよ(私の感想)
谷口:わたしは、音素からの単語学習と、ロボットが物体に作用(手に持って振るなど)することによる特性学習から物体を認知する「確率生成モデル」、さらには「経験と感覚の統合」によりコミュニケーションを行う「認知発達ロボティクス」を目標にします
いきなり質問
谷口:ここで問題です。知能は「関数」でしょうか、それとも「全体」でしょうか?
関数
知能は関数の立場を採ると言うことは、
入力に対して出力を決定する「関数」で、知能を記述できます。
・単一目的のタスク遂行
・タスク指向AI
・情報処理としての知性
を考えていく学問になります
全体
知能は「全体」の立場では、エージェントは複数の目的と複数のタスクを同時に処理します。そこでは感覚と運動の自己組織化が行われ、自律性が発揮されます
私の提唱した「記号創発システム」では、言語もボトムアップで創発されます。
(感想:杉山先生の研究は前者、谷口先生の研究は後者ということかな。
すると、本講演会は、会話システムの二大潮流を理解できてとってもお得)
ここから谷口先生の研究紹介
・ロボットがものを振るなどして作用した結果と、その時に聞こえるスピーチ音声により、物体を分類する
・SpCoSLAM(2017谷口)
移動ロボットが自己位置推定と同時に物体と場所の名前を獲得するOnline Learning of Multimodal spatial conceptを実装
基本的に内部表現で外界を予測し、それを入力で修正する手法。自由エネルギー原理と一致
日本ロボット学会誌Vol.40, No.9として「予測に基づくロボットの動作学習」特集号が発刊されました。
— Tetsuya Ogata / 尾形哲也 (@tetsuyaogata1) November 21, 2022
深層予測学習を中心とした特集号で、私は展望を執筆させて頂きました。自分の研究において大変重要なマイルストーンになったと感じております。https://t.co/MHiKW4tfJ2
日本ロボット学会誌Vol.40,No.9「予測に基づくロボットの動作学習」
世界モデルと予測学習によるロボット制御 谷口忠大他4名
自由エネルギー原理:離散系と連続系の統合 乾敏郎
乾敏郎先生の自由エネルギー原理の解説。すでに多くの研究成果を上げている @shosakaino 先生、 @KKawaharazuka 先生の解説。背景をよく知る @tanichu 先生、村田真悟先生( @keio_crl )の解説。実応用に繋げていただいた 川野俊充社長の解説。本当にありがたいと思っています
— Tetsuya Ogata / 尾形哲也 (@tetsuyaogata1) November 21, 2022
家庭環境における移動ロボットの能動的地図生成と場所概念形成
https://confit.atlas.jp/guide/event-img/jsai2018/2L3-OS-6b-03/public/pdf?type=in
(感想)「人工知能」に、「実環境と相互作用を行う深層強化学習のエージェントはいまだ見通しが立っていない」とあるが、谷口先生のこのロボットは、何が足りないのだろう?
画像分類、翻訳、文章生成、タンパク質構造予測などは人間を超えつつあるが、
— YANO Tomoaki@JSMEーTRCビジョン2050WS12月23日 (@yanotomoaki) July 7, 2022
実環境と相互作用を行う深層強化学習のエージェントはいまだ見通しが立っていない
データ中心の視点から捉える深層強化学習
人工知能Vol37,No.4,pp507-515 より pic.twitter.com/Wsk0fbAy1B
モジュール分解・統合学習 SERKET
全脳プロジェクトにおける(WB-PGM概念の提案)
ERATO 脳 AI 融合プロジェクトの目標はこちら
IT批評のインタビュー記事が公開となりました!
— Daichi Konno / 紺野 大地 (@_daichikonno) December 6, 2022
「池谷脳AI融合プロジェクト」の最新状況や、将来的にどのように応用可能かを話しています。
全3回となかなかボリューミーな内容です。
ぜひご覧いただけると嬉しいです😊https://t.co/xMQGfqqO2e
記号創発システム
コミュニケーションとは
Aが「サイン」をBに送る。
お互いに、相手の頭の中は見えない。
この時、どうすれば、サインの意味を共有できるだろうか?
C.S.パースの「記号論」によると、
「Apple」という音列が発話された時、相手は「Apple」という記号(音列)を、実体の「りんご」と解釈する
この時、「単語」は、ただの「サイン」であり、カテゴリーでも、概念でも、記号でもない
記号についての注意点
ここで言う「記号」は、記号接地問題の「記号」とは異なる
記号接地問題では人工知能の記号論理学(symbolic logic)の概念で記号を取り扱い、述語論理学の学問体系を構築するが、ここで述べる「記号」は、これとは異なる
記号創発システム(谷口、2016)
赤ちゃんは、Representation Learningで、身の回りのものの内的表現を創り上げていく。この過程は、深層学習によるカテゴライズと同じである
赤ちゃんが、勝手に「ぶぶ」と名付け、「ぶぶとってー」と、取って欲しい物体を指さすと、大人が「ああ、ぶぶはこれか」と気づく。こうして共通の認識がされると「社会」が生まれ、言語ができる。
いっぽう、すでに社会に言語が生成されていると、そこに住む人間は、その「ルール」に従わざるを得ない。すなわち、コミュニティに存在する個々人は、コミュニティに制限を受けることになる。
このシステムでコミュニケーションが形成される過程と行動制約は、「創発システム」と呼ぶ複雑系で記述することができる。

これを、「集団的記号創発」と呼ぶ。
「集団的記号創発」は、言語進化とコミュニケーション進化を記述し、人間集団のみならず、人工生命を含む集団にも適用できる。
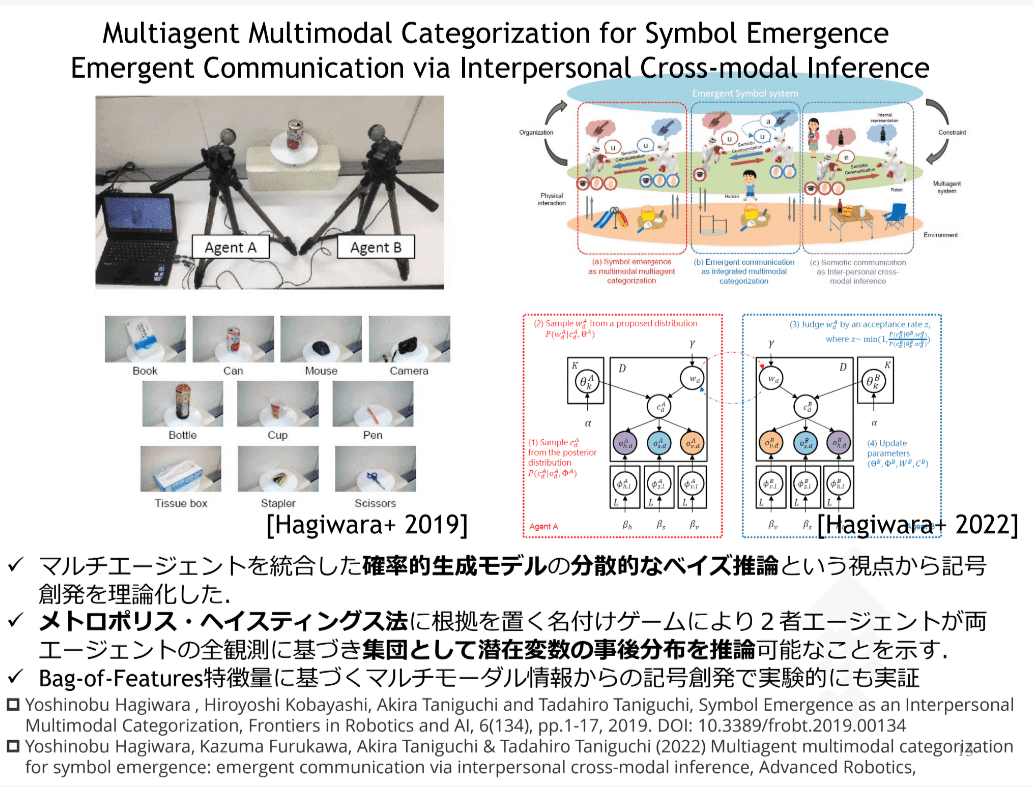
(矢野の感想:これも異種族コミュニケーション?)
「2足歩行の人間」が「4足歩行のロボット」を全身運動で直感操作するとこうなる:Innovative Tech - ITmedia NEWS https://t.co/pUYmEjzWFO #ロボット業界ニュース
— ロボットスタート(ロボスタ) (@robotstart) December 4, 2022
Metropolis-Hastings Naming Games

2台のロボットが、勝手に名前をつけ、お互いに「相手の言語を受け入れる」「受け入れないで自分の言語を発する」を確率で決定する。
確率は、P(相手のネーミング(信念)の正しい確率|自分の過去のネーミング(信念)確率)で与えられる

すると、驚くべきことに、2台のロボットの頭脳を直接接続した場合(左図)と、会話のみで学習した場合(右図)の結果が、全く一致する!!

左のロボットAと、右のロボットBは、数字の見え方が異なっている。それでも、同じものとして認識するのだ!
中休み(矢野の感想)
視覚ロボ vs 聴覚ロボ vs 触覚ロボ でも同じ結果が得られそう。どこまで異種ならコミュニケーションが不可能になるのか、興味が湧きます
百人百様といって、おそらくひとりひとり、感覚器から受け取る情報は大きく異なっている。「色のふしぎと不思議な社会」では、色覚は想像以上に千差万別であることが示される。
「植物は<未来>を知っている」など、生物の知能の高さを示す書物が相次いで刊行される中、身近な「エイリアン」植物とのコミュニケーションが図れそう)
本日の講演で、人工知能の2本の流れを網羅!
— YANO Tomoaki@JSMEーTRCビジョン2050WS12月23日 (@yanotomoaki) November 30, 2022
谷口忠大先生の講演で、
集団的記号創発が、ただの紙切れやNFTが資産価値を持つ理由だと理解
AIや動植物ともコミュニティーが作れそう
鳴き声は文章「鳥語」発見:日本経済新聞 https://t.co/UXocC6eiie https://t.co/4XvPb7Ompr
いよいよラストスパート
しかも、コミュニケーションしない時よりも、クラスタリングパフォーマンスが上昇した!
(各人の知覚を統合して、多面的な見方により、より良い学習ができるということ)
一人が視覚から触覚を推論するのと同じ数学モデルになる。
相手の言ったことを何でも受け入れる「イエスマン」がいると、モデルが崩れてパフォーマンスが低下する(どこぞのワンマン国みたいやな)
実験で使用したロボットたちは、「分散ベイズ推論」で、社会学習をしているのだ
では、人間は同じゲームをプレイしているのだろうか?
(谷口先生)
この概念は、おそらく初めてここでお話しします。
1)教師あり学習 人の概念が固定であり、ロボット(AI)は人の言ったことを100%受け入れる
2)教師なし学習 ロボット(AI)が単独で学習し、分類し、ラベリングする
3)共創的学習 ロボット(AI)が、人間と相互成長をする(人間側もロボットのサジェスチョンにより考えを修正する)
ロボットと人間の身体性の違いは障害にならず、むしろパフォーマンスが向上するのは、すでに述べたとおり
最後に現状報告
推薦図書:「自然言語処理の基礎」
ムーンショット 目標3 原田プロマネに参加
人とAIロボットの創造的共進化によるサイエンス開拓
2050 年までに、自然科学の領域において、自ら思考・行動し、自動的に科 学的原理・解法の発見を目指す AI ロボットシステムを開発する。
2030 年までに、特定の問題に対して自動的に科学的原理・解法の発見を目 指す AI ロボットを開発する。
立命館グローバル・イノベーション研究機構R-GIRO

谷口先生:Language and Robotics研究会も参加して下さい!
Language and Robotics研究会第10回の吉野先生のご講演資料とQAは既にHPで公開中です。アナウンスを失念しておりすみません。よろしくお願いいたします!https://t.co/voiu75i9cw#LangRobo https://t.co/xBuiBI5If5
— Seitaro Shinagawa (@sei_shinagawa) December 5, 2022
これは、私が個人的に推薦する関連書籍。谷口先生、「数学ガール」や「もしドラ」を意識?
おわりに
あっという間に2時間が過ぎた。
普段は集中して、メモは一切取らないのだが、さすがに内容が濃いことと、私の専門分野外の内容なのがわかっていたので、それぞれの講演のメモがA46ページほどになった。
(副作用として、スライドの画像イメージが脳内に残っていない)
人工知能分野の先生は、惜しげも無くスライドなどのデータをアップして下さる。
アイデアが次々と湧き出ている研究者集団(共創的学習を行う集団)だからこそできることで、このスタンスが人工知能全体の跳躍的進捗を促しているのだと思っている。
昔、群知能モデルを理論的に構築することの難しさを全く理解していなくて(RPG(ロールプレイングゲーム)に実装されていると思っていた)
谷口忠大先生の「人工知能概論」続編に何を望みますか?
の問いに、即座に「パーティープレイ」を思い浮かべたのは、私です
(8年前の、ワールドカップで盛り上がってた頃。懐かしいな)
@tanichu
— YANO Tomoaki@JSMEーTRCビジョン2050WS12月23日 (@yanotomoaki) November 27, 2014
非構造化空間(リアルワールド)で群知能(仲間)を発揮して敵を打ち破る。
11機の環企鵝弐改(ほいーるだっくにごうあらため)が、友情でワールドカップ優勝を目指す :D
ちゃっかり、たにちゅう先生に返信までいただいています(笑)
@yanotomoaki 群知能か〜。theoretical に書くには難易度高いっすネー。でも、ナイス論点です〜!
— Tanichu/たにちゅー (Tadahiro Taniguchi, 谷口忠大) (@tanichu) November 27, 2014
「共創的学習」に取りくんでおられるということは・・・
「人工知能概論Ⅱ」を読める日も近い!
追記
書籍「脳は世界をどう見ているか」によると、ひとりの人間の脳内に1000の人格が住み、多数決の結果だけが上位に上がり、本人の意志と認識されるそうだ。
これは、ひとりの人間の脳内でも「共創的学習」が行われていると言える
いいなと思ったら応援しよう!
