
Webスクレイピング勉強②~WEB情報取得&CSV出力~

前回と同様に以下動画で勉強。
1.ページ内の情報を取得する
①一つずつ取得
ページ内の「今西航平」という情報はid = 'name'で定義されている
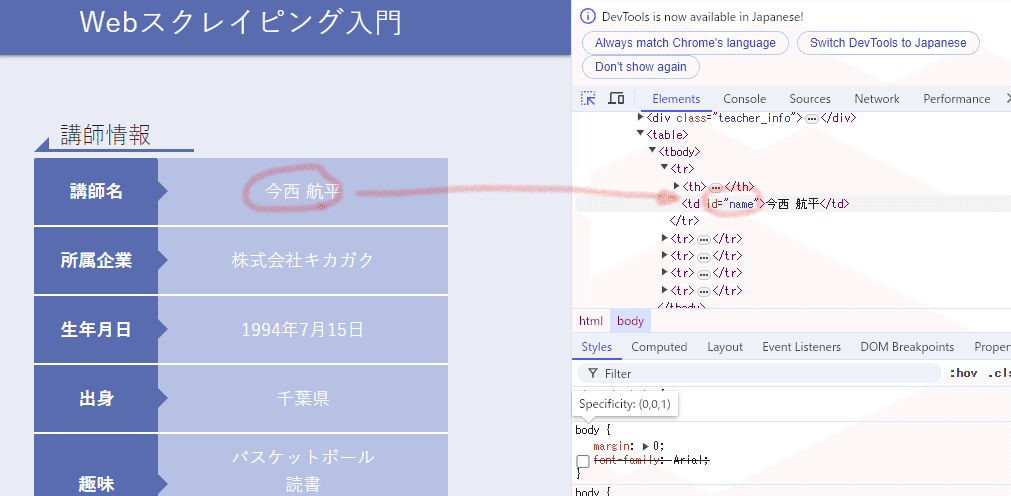
IDがnameの情報を取り出し、その中のテキストデータを出力する。
element = browser.find_element(By.ID, 'name')
element.text取得できた

他の要素も同じ要領で取得可能
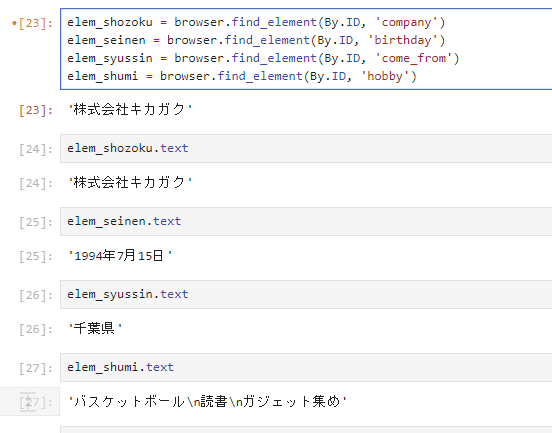
趣味は\nで区切られているが、repralce関数で別記号に置き換え可能

②リストとして取得
表の構造としては、こんな感じ

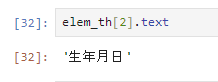
見出し部分は「th」で定義されているため、タグがthの物を取得する
elem_th = browser.find_elements(By.TAG_NAME,'th')そうするとthの文字がリストとして格納される。
※HTMLおさらい
elem_th = browser.find_elements(By.TAG_NAME,'th') #thタグの要素を取得
keys = [] #格納用のリストを初期化
for elem_th in elem_th: #取得したthタグの要素分ループ
key = elem_th.text #テキストを抽出
keys.append(key) #要素をリストへ格納する出力してみるとリストに格納されたことがわかる

同様にtdの要素も抽出する
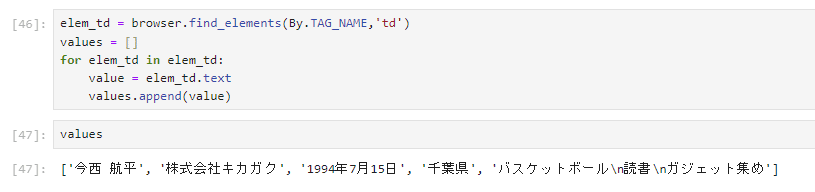
2.CSV出力する
①pandasのデータフレームへ項目と値を格納
import pandas as pd
df = pd.DataFrame()
df['項目'] = keys
df['値'] = valuesdataframeについてはこちらに詳しく記載されていました。
②CSV出力
下記コマンドでCSV出力。indexが不要であればFalseを指定
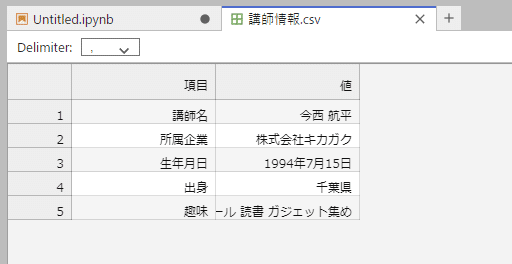
df.to_csv('講師情報.csv', index=False)ファイルが出来ているので中身を確認する。
Python、簡単に色んな事ができてすごいけど、簡単すぎるが故になかなか記憶に定着していない感があるな。