
Rへのデータ読み込み(実践)

東京大学医学部老年病科の矢可部です。
Rを用いた統計解析について、noteに記事を書いています。
Noteでは匿名で発信する人が多い印象ですが、私はあえて本名で発信をしたいと思います。
理由の1つはこのnoteを、学生や初期研修医に統計解析を指導する際の教材にしたいからです。
自習してもらうことで指導が効率的になりますし、インターネット上に記事を残せば後から見返してもらうこともできます。
日本中の人に見ていただける可能性があるのも魅力です。
無理のない範囲で記事を作成していきたいと思います。
今回は、データをRに貼り付ける方法の続きです。
サンプルデータ
私が作成した架空の患者20名分のデータです。
以下のリンクからExcelファイル"Rdata.xlsx"をダウンロードして下さい。
開くと1枚目のデータシートに、以下のようなデータがあります。

これから、このデータを解析していきたいと思います。
なお私はMacのPCを使っています。特に断りのない限り、画面はMacに対応したものです。
データの表示
Rへのデータの読み込みについては前回の記事をご覧ください。
readxlパッケージを用いた方法と直接コピペする方法を紹介していますが、ここでは後者の方法で行います。
1枚目のデータ全体をコピーして、以下のようにRに入力します。
dat <- read.table(pipe("pbpaste"), sep="\t", header=T) # Macの場合
dat<-read.table("clipboard", sep="\t", header=T) # Windowsの場合
attach(dat)
dat
以下のような画面になるはずです。

dat全体が表示されたことをご確認ください。
(ただし、データ数が多い時は一部しか表示されません。)
項目の絞り方(応用)
データフレームのうち必要な項目のみを保存することも可能です。
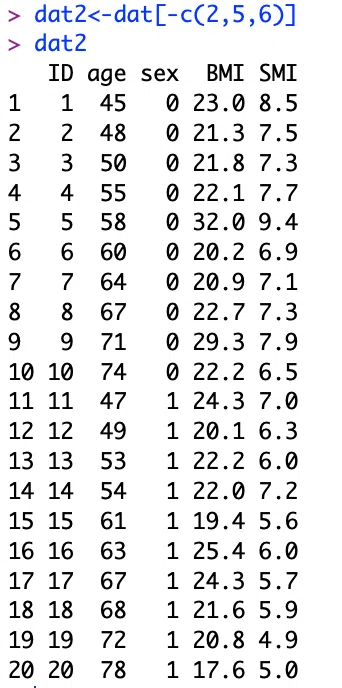
たとえばデータのうち、患者名と身長と体重は不要とします。つまり、2, 5, 6列目が不要ということになります。
datからそれらの列を削ったデータをdat2という名前で保存する場合には、以下のようなコマンドになります。
# datの2, 5, 6列目を消したものを、dat2として保存
dat2<-dat[-c(2, 5, 6)]
# dat2を表示
dat2
実行すると、以下のように不要な列が消えます。
あるいは、必要な列だけを抽出するというやり方もあります。
datのうち、1, 3, 4, 7, 8列を抽出するコマンドは以下のようになります。
# 1, 3, 4, 7, 8列を抽出したものを、dat3として保存
dat3<-dat[c(1,3,4,7,8)]
# dat3を表示
dat3
1つ前の画像と同じデータが表示されるはずので、やってみて下さい。
さらに、連続するいくつかの列を除去したり抽出したりすることもできます。
# 5列目から8列目までを消したものを、dat4として保存
dat4<-dat[-c(5:8)]
# 1列目から4列目までを抽出したものを、dat5として保存
dat5<-dat[c(1:4)]
このように、半角の:(コロン)を用いて"X:Y"と書くことで、「X以上Y以下の数字」を表すことができます。
dat4とdat5が同じになることを確認して下さい。
次回は、このデータを用いて基本的な統計量を計算することにします。
Noteがお役に立てば幸いです。