
AI育成講座【day6】


ChatGPTを用いた試行錯誤の流れ。
小さく動かして、サイクルを回して、試行錯誤を繰り返すことに意味がある。試行錯誤の過程でも、ぶつかった問題に対して、知識を補完すると言う考え方。知識を得てから問題にぶつかるのは、学びの途中で挫折する可能性があるし、その知識が必ずしも問題に使えるかの確証がない。

123123123のような単一の要素感なる規則性を読み取るのは、人間でも可能。しかし、多数の要素から絡み合う複雑な系統/傾向を読み取くのは、AI が得意とする領域。

やはりAIを使うべき場所は、専門家や職人が感覚的に理解している法則や仕組みを言語化してモデル化することにあるはず。
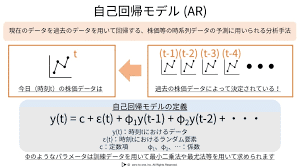
ARモデルを用いて、過去データから現在予測する。

こんな感じのデータからARモデルを使ってデータ分析する。


依然としてデータの名前が文字化けするのはなかなか治らない。ここは日本語フォントよりも英語として統一した方が良いのかもしれない。

95%、信頼区間が過去でも適用されてしまったので、未来のデータのみに直したい。


思い描いたものが、割とスムーズに出せるようなってきた。これは何がおかしいのかを理解する最低限の知識とディープシークへの指示出しがうまくなってきたことが関係しているのか。
これ以上の信頼区間の精度を上げることがなかなか難しいので、ここで一旦終わりにする。
あと、カラム名を日本語にするとバグが生じやすいから、英語の方が望ましいらしいならば、データの段階で絡む名を全部英語にするのがいいか。それは人の手でCSVファイルを事前に直す必要がある。
バグのループがが繰り返される時は、ディープシークの思考過程のわからないところをその都度調べていく必要がありそう。