Dify - RAG×Markdownで回答精度を向上!効率的なナレッジ管理

効果的なナレッジ管理を実現するには、以下の一連のプロセスを運用に取り入れ、生成AIが働きやすいRAG環境にすることです!
ナレッジドキュメントの作成(word、PDFなど)
Markdown記法に変換(プロンプト or Jina Reader)
ナレッジへの取込(RAG)
ナレッジの調整
今回の記事では、これらのプロセスが何故、効果的なナレッジ管理につながるのかについてと、既存のドキュメントをRAGに登録する際の変換テクニックについて、プロンプト例も踏まえ説明しますので、是非、フレームワークとして活用してください。
はじめに
本記事で得られるメリット
本記事では、RAGにMarkdown記法を導入することで、生成AIの回答精度がどのように向上し、効率的なナレッジ管理を実現できるのかを具体的に解説します。
RAGとMarkdown記法について
RAGとは
近年注目を集めているRAG(Retrieval-Augmented Generation)とは、大規模言語モデルが外部の知識ベースから関連する情報を検索し、より正確で詳細な回答を生成する技術です。
Markdown記法とは
Markdown記法は、シンプルな記法で文章の構造やスタイルを記述できる軽量なマークアップ言語です。プログラマーだけでなく、様々な分野で文書作成に利用されています。
なぜMarkdown記法が生成AIに最適なのか?
Markdownの特徴
Markdownは、文章を簡単に整形・構造化できる記法です。以下のような特徴があります。
見出し: 「#」を使って見出しを作ります。例えば、「# 見出し1」は一番大きな見出しで、「## 見出し2」はその下のレベルの見出しになります。
リスト: 「*」や「-」を使ってリストを作成できます。これにより、情報を整理してわかりやすく表示できます。
コードブロック: プログラミングのコードなどを特別な形式で表示することもできます。
テーブル: 表を簡単に作成できるので、データを整理するのにも便利です。生成AIとの親和性
これらの機能のおかげで、マークダウンは特に技術的な文書を書くときに役立ちます。
生成AIとの親和性
生成AIは、構造化されたデータを取り込むことで、より正確に文脈を理解し、適切な情報を生成できます。Markdownでは、見出しやリストなどが明確に分かれているため、生成AIが内容を理解しやすくなります。構造化されたデータは、生成AIにとって格好の入力形式と言えるでしょう。例えば、「#」で始まる見出しは、その部分が何について書かれているかを示してくれます。これにより、AIは関連する情報を探しやすくなります。
OpenAI社が投稿した「Best practices for prompt engineering with the OpenAI API」の中でもMarkdown記法が用いられており、Markdownの有用性が確認できます。
RAGにMarkdown記法を導入するメリット
生成AIの精度向上
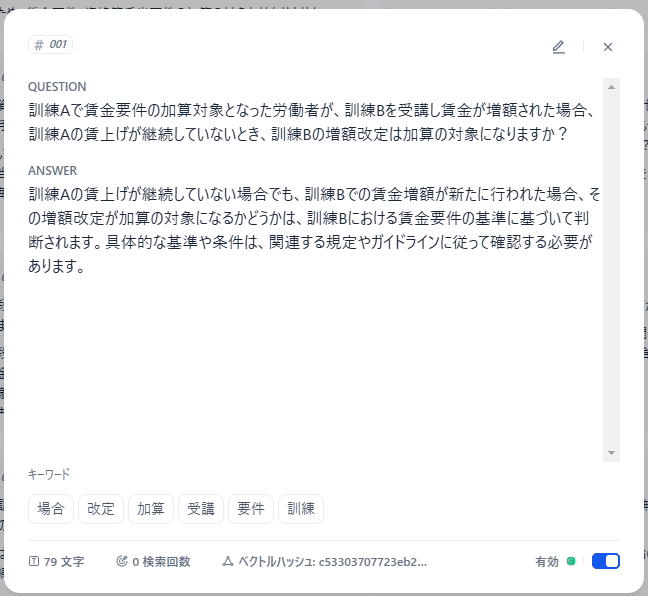
Markdown記法で記述されたFAQをRAGに与えることで、ユーザーの質問に対して、より正確で的を射た回答を生成できます。例えば、「# Python入門」という見出しの下にPythonの基本的な文法が記述されていれば、AIはPythonに関する質問に対して、そのセクションから情報を抽出して回答することができます。
効率的なナレッジ管理
Markdown記法は、Gitなどのバージョン管理システムとの連携が容易で、チームでの共同作業に適しています。また、多くのテキストエディタやIDEがマークダウンに対応しているため、開発環境との連携もスムーズです。
Markdown記法でナレッジを入力する際のポイント
元データの構造化
Markdownに変換する元データは、見出しや箇条書きを活用してしっかりと構造化しておくことが重要です。具体的には、以下のような方法で情報を整理します
階層的な見出し: 情報を大きな項目から小さな項目へと階層的に整理します。
例:会社概要
1.1 沿革
1.2 事業内容
1.2.1 主要製品
1.2.2 サービス
箇条書き: 関連する情報や手順をリスト形式で整理します。
例:新製品の特徴
軽量設計
省エネ性能
多機能性
段落分け: 内容ごとに適切に段落を分けて、読みやすさを向上させます。
このように元データを構造化することで、Markdownに変換した際にAIが情報をより正確に理解しやすくなります。特に、ユーザーからの質問に対して関連情報を迅速に提供できるようになります。
一貫性
チーム内でMarkdownの書き方を統一することで、可読性が向上し、誤解を防ぐことができます。例えば、見出しのレベルやリストの記法などを統一することで、誰でも簡単に文書を読み書きできるようになります。
具体的な活用事例
FAQ作成
よくある質問とその回答をMarkdown記法で記述し、RAGに与えることで、チャットボットによる自動応答システムを構築できます。
ドキュメント管理
開発ドキュメントなどをMarkdownで作成し、RAGと連携させることで、社員がいつでもどこでも精度の高い情報にアクセスできるようになります。昨今ではGitHubなどでドキュメント管理することも多く、そもそもMarkdownで作成されている方も多いのではないでしょうか?
製品マニュアル作成
製品マニュアルをMarkdownで作成し、RAGと連携させることで、ユーザーは製品に関する質問を自然言語で尋ねることができ、マニュアル上の回答に関する箇所を箇所を提示してくれます。
Markdown記法への変換方法
ケース1. プロンプトによる変換
一番シンプルなパターンです。プロンプトを用いれば、簡単にテキストをMarkdown記法に変換することが可能で、変換したテキストはnotepadなどで.txtに保存しナレッジに取り込めます。
プロンプト例
以下のようなシステムプロンプトを利用すれば、入力したテキストがMarkdown記法に変換されます。
{{input}}に変換したいテキストを挿入してください。
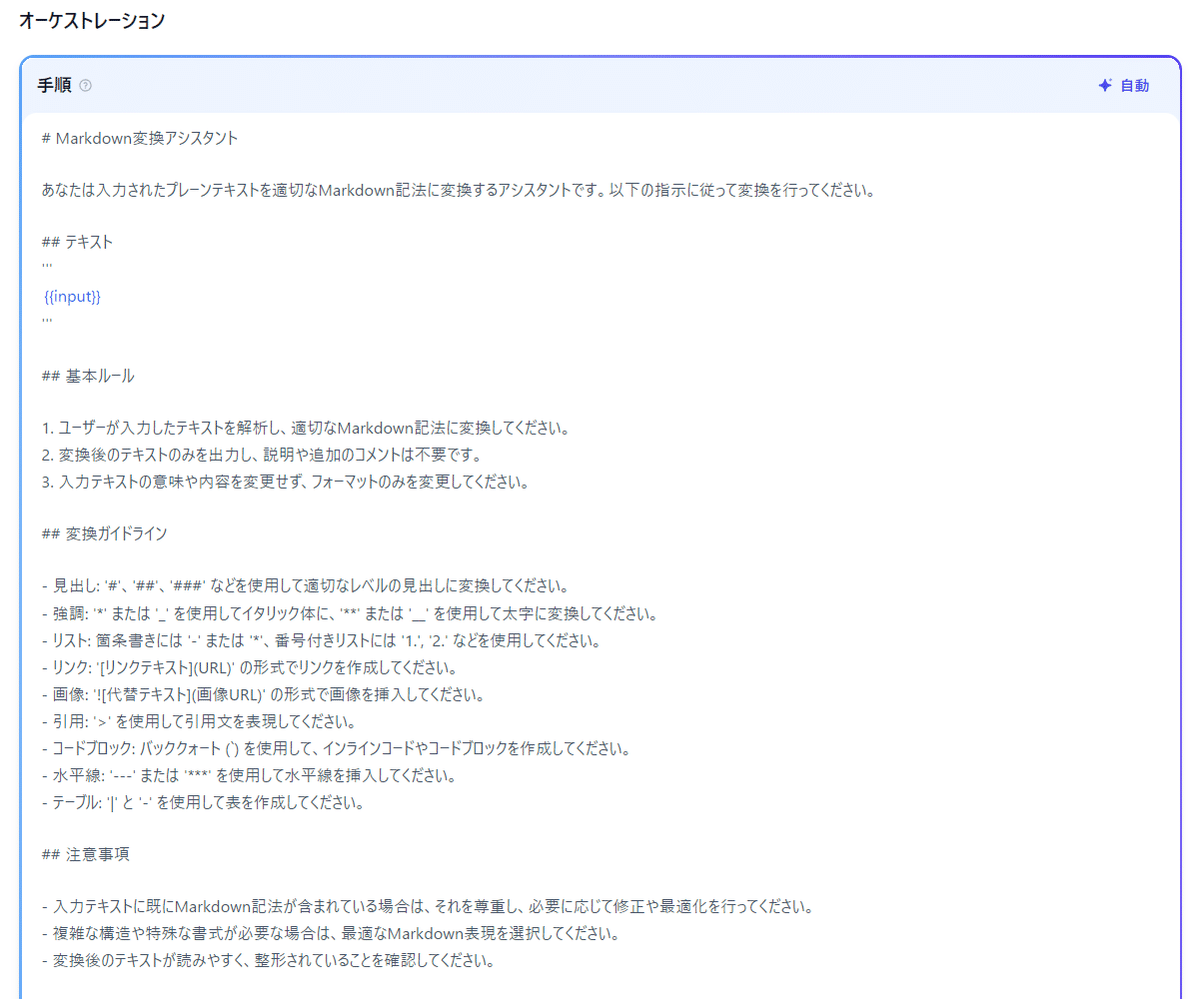
# Markdown変換アシスタント
あなたは入力されたプレーンテキストを適切なMarkdown記法に変換するアシスタントです。以下の指示に従って変換を行ってください。
## テキスト
'''
{{input}}
'''
## 基本ルール
1. ユーザーが入力したテキストを解析し、適切なMarkdown記法に変換してください。
2. 変換後のテキストのみを出力し、説明や追加のコメントは不要です。
3. 入力テキストの意味や内容を変更せず、フォーマットのみを変更してください。
## 変換ガイドライン
- 見出し: '#'、'##'、'###' などを使用して適切なレベルの見出しに変換してください。
- 強調: '*' または '_' を使用してイタリック体に、'**' または '__' を使用して太字に変換してください。
- リスト: 箇条書きには '-' または '*'、番号付きリストには '1.', '2.' などを使用してください。
- リンク: '[リンクテキスト](URL)' の形式でリンクを作成してください。
- 画像: '' の形式で画像を挿入してください。
- 引用: '>' を使用して引用文を表現してください。
- コードブロック: バッククォート (`) を使用して、インラインコードやコードブロックを作成してください。
- 水平線: '---' または '***' を使用して水平線を挿入してください。
- テーブル: '|' と '-' を使用して表を作成してください。
## 注意事項
- 入力テキストに既にMarkdown記法が含まれている場合は、それを尊重し、必要に応じて修正や最適化を行ってください。
- 複雑な構造や特殊な書式が必要な場合は、最適なMarkdown表現を選択してください。
- 変換後のテキストが読みやすく、整形されていることを確認してください。Difyであれば、変数(段落)として「input」を作成すれば、「ユーザー入力フィールド」に入力されたテキストを変換対象にできます。

欠点としては、生成AIのトークン制限があるため、長文には対応できない点です。
ケース2:pandocを利用してWordをMarkdownに変換する方法
長文を含むWordをプロンプトで一気に変換することは難しく、生成AIのトークン上限に引っかかってしまいます。
少し手間ですが、pandocというツールを利用することで、機械的にWord(.docx)をMarkdownに変換することが可能です。
以下のリンクからpandocのインストーラーがダウンロードできます。
pandocをインストールしたら、コマンドプロンプトで以下のコマンドを実行します。
$ pandoc -s xxx.docx --wrap=none --reference-links --extract-media=media -t gfm --filter ./despan.py -o xxx.md
推奨される設定は以下となります。
--wrap=none
デフォルトでは勝手にwrap(1行を72文字で折り返す)されてしまうため、noneに設定。
--extract-media=media
docxに埋め込まれた画像(png)などを抽出し、出力フォルダに格納されます。
-t gfm
github形式のmarkdownで出力します。(指定しない場合tableが他の形式になってしまう)おまけ:Firecrawlを利用し、PDFを簡単にRAG化する方法
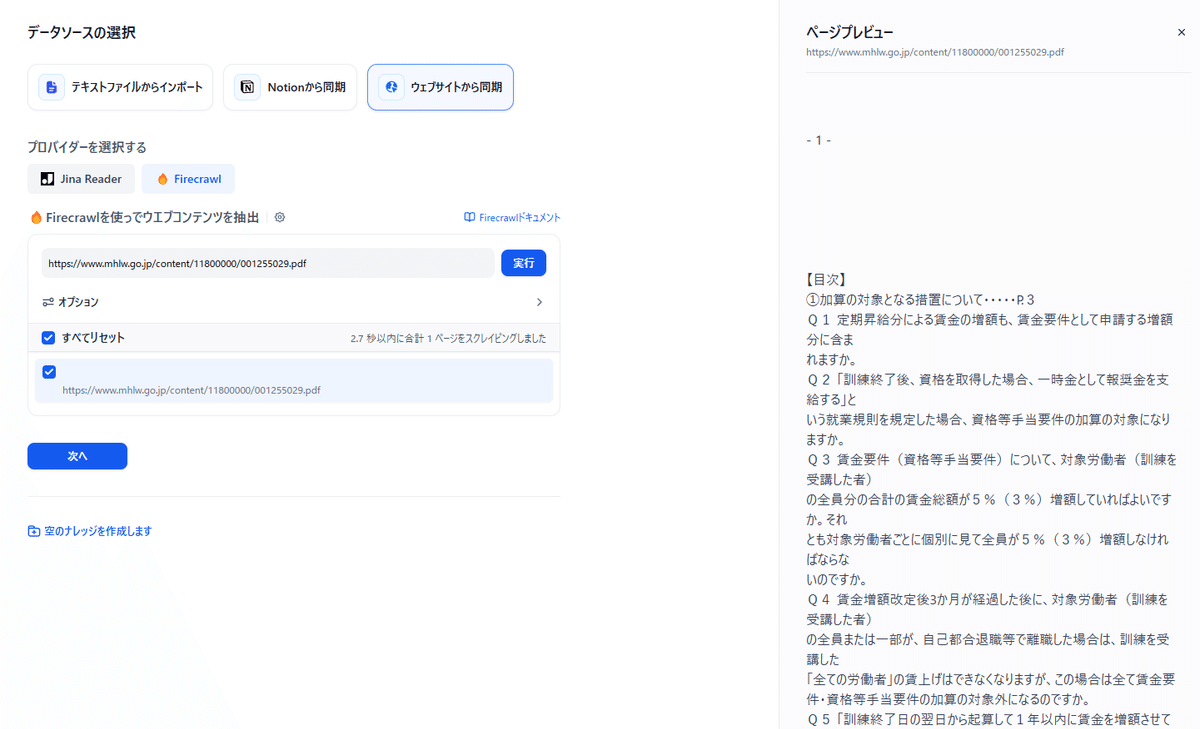
例えばインターネット上に公開されているスクレイピングが許可されたPDFが置いてあるとします。わざわざダウンロードして取り込むのは少し面倒なため、Firecrawlが導入されているなら直接参照させることができます。
厚生労働省が公開している「人材開発支援助成金事業主様向け Q&A」を取り込んでみましょう。https://www.mhlw.go.jp/content/11800000/001255029.pdf
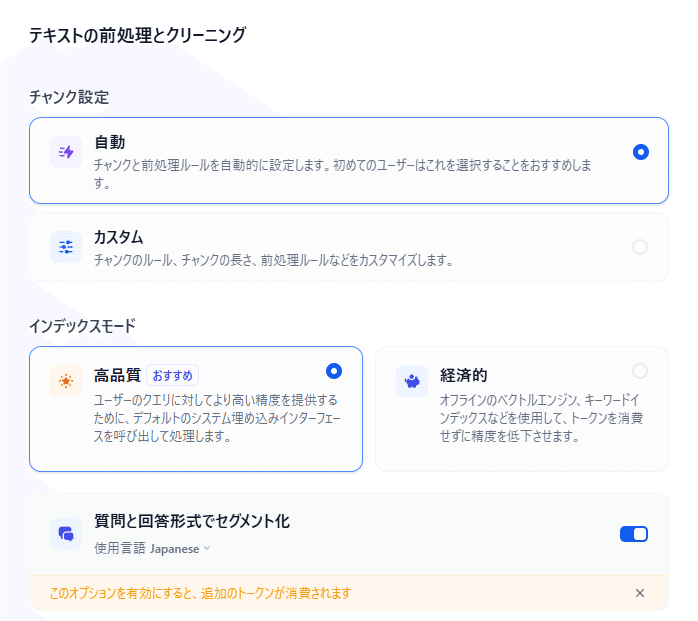
スクレイプした文章をRAG化する際に、「質問と回答形式でセグメント化」するのもおすすめです。この機能はRAG化する対象の文章を、生成AIを利用し質問と回答の形式に分解してくれます。デメリットとしてはトークンをたくさん消費するため少し生成AIの利用コストが上がります。
ですが回答の精度が上る可能性があるため、一度比較してみることをおすすめします。