
オープンソースLLMをローカル環境で動かしてみた

はじめまして。株式会社WiseVine SREエンジニアの高見道人です。
大規模言語モデル(LLM)の進化により、AIの能力は日々向上しています。しかし、これらの強力なモデルを利用するには、通常クラウドサービスに依存する必要があります。
とはいえ、もしかしたらLLMのSaaS(ChatGPTやClaudeなど)を使わずに、IaaS(GPUインスタンスなど)だけで実現したい、なんてときも来るかもしれません。
今回は、あえて、オープンソースのLLMをローカル環境で動かす方法を紹介します。驚くほど簡単に、たった2つのコマンドで自分のPCでAIを動かせました。
こんな人にオススメです
AI技術に興味があるが、クラウドサービスへの依存を避けたい個人開発者や学生
ローカル環境でAIを動かす方法を学べるため、プライバシーを保ちながら実験できます
自分だけの環境なので、色々と試すことが可能です
自分だけのカスタマイズされたAIを安価に作ってみたい人
RAGや各種設定によって自分専用の変わったAIも安価に作れます
例:語尾に「にょ」をつけた猫型メイド等
コスト意識の高いスタートアップや中小企業のIT担当者
AIの利用コストを抑えつつ、自社サービス(常駐アプリというよりは、バッチ処理向け)にAI機能を組み込む方法を探っている人に有用です
インターネット接続が不安定な環境でAIを活用したいIoTデバイス開発者やモビリティ関連のエンジニア
オフライン環境でもAIを動作させる方法について知見を得られます。
LLMを動かす方法
Dockerでたった2行でLLMをローカル環境で動かせる
# ollamaのdockerをpullして起動する
docker run -d --gpus=all -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama
# dockerのコンテナでollamaを使ってみる
# 例:docker exec -it ollama ollama run llama3
docker exec -it ollama ollama run <落としてきたいLLMのモデル名>たったこれだけで実はローカル環境でLLMが動かせます(一応NVIDIA GPU向け)。もし、事前にDockerでGPUを利用する設定をしていない場合や、AMDのGPUを利用したい場合は公式の以下のページに書いてあることを忠実に実行したら使えるようになります。それでも非常に簡単なステップで導入可能です。
https://hub.docker.com/r/ollama/ollama
Ollamaとは
Ollamaは、大規模言語モデル(LLM)をローカル環境で簡単に実行するためのオープンソースツールです。様々なLLMをダウンロードし、ローカルマシンで実行することができます。Ollamaを使用することで、クラウドサービスに依存せずに、プライバシーを保ちながらAIモデルを利用することが可能になります。今回の記事の中ではDocker上のコマンドでの動作ですが、当然ですがAPIサーバとしても利用出来ます。また、GUIでのチャットやRAGの登録などは、それ専用のDockerコンテナ(Open WebUIなど)を立ち上げれば、いい具合のWEBサービスも立ち上がります。
Ollama以外のAIツールの比較と選択
Ollama: 初心者/個人利用向け、簡単セットアップ
vLLM: 高速推論が必要な場合、大規模デプロイメント
Text Generation WebUI: GUIを好む場合、多機能な環境が欲しい場合
LMStudio: デスクトップアプリケーションを好む場合、簡単な微調整が必要な場合
llama.cpp: リソースが限られている環境、組み込みシステムでの使用
TensorRT-LLM: NVIDIA専用。LLMモデル推論を最適化したライブラリ。爆速だがチューニングや導入コストが高い
LLMモデルを実際にダウンロードしてこよう
Hugging Face
Hugging Face とは、色々細部に差はあれど、大まかに言ってしまえばAIモデル版のGitHubだと思ってください。オープンソースのLLMモデルをgit clone感覚でダウンロードできます。
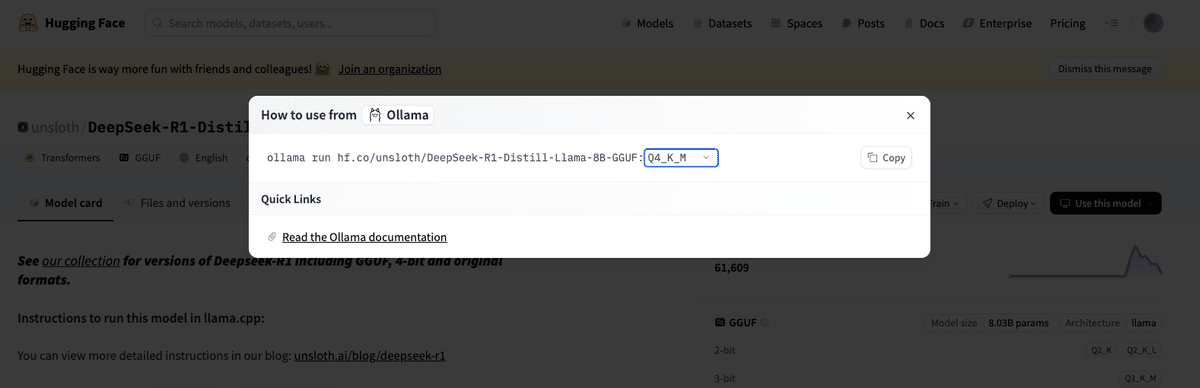
検索枠から言語モデルを探し、言語モデルのページに行きます。 画面右上の黒いボタン(Use this model)を押すと、上のような画面が出てきます。 この例では、最近話題となったDeepSeekR1の蒸留モデルをダウンロードしてみました。
蒸留モデルとは
LLMは計算コストが高く、リソースが限られた環境では使いにくいのが現状です。家庭用PCには通常、大規模なモデルを動かすのに十分なリソースがありません。そこで、モデルのパラメータ数を8Bや4Bに縮小するなどの「蒸留」を行い、個人用PCでも利用可能なサイズに調整したモデルを使用します。
GPTQ
蒸留モデルを使用しても、個人PCで動かすにはまだ負荷が高い場合があります。そこでGPTQ (General Purpose Quantization) という量子化手法を使って、さらに軽量化されたモデルを利用します。この手法は、モデルの重みを元の精度(通常は32ビット浮動小数点)から低精度(例: 4ビットや8ビット)に変換し、メモリ使用量を削減しつつ推論速度を高速化します。
GGUF
GPTQで量子化された軽量モデルのフォーマットが、GGUF (GPTQ General Unified Format) です。個人環境で使う場合は、このGGUFフォーマットに変換されたファイルを使用します。
上記の画像では、8Bまでモデルパラメータが蒸留され、さらに4ビットまで量子化された言語モデルを使用しています。これくらいまで小さくすれば、一般的な個人用PCでも動作可能になります。
実際に利用した結果
手元PCの構成
CPU: Core i7-9700F
Memory: 32GB
GPU: GeForce RTX 2070 SUPER (8GB)
だいたい5年ほど前のミドルクラスゲーミングPCです。
出力の結果

モデルのサイズもありますが、今回利用したものでは、ちょっと実用には遅いかなくらいですが十分な出力は帰ってきました。実際に利用したプロンプトと、その出力を掲載します。
試しにECS Execと言って、AWSのECSのコンテナに入っていく為の対話型のシェルを書いてもらいました。
ECS EXECをクラスター→サービス→タスク→コンテナの順で選択して、ECS環境に入れるシェルスクリプトを書いてほしい。jqとfzfはすでにインストールされているものとし、これらを有効活用して、選択しやすい対話式のシェルスクリプトにして欲しいクラスターは以下のコマンドで一覧を取得すること<code>aws ecs list-clusters</code>サービスは以下のコマンドで一覧を取得すること<code>aws ecs list-services --cluster [指定したクラスター]</code>タスクは以下のコマンドで一覧を取得すること<code>aws ecs list-tasks --cluster [指定したクラスター] --service-name [指定したサービス]</code>コンテナは以下のコマンドで一覧を取得する<code>aws ecs describe-tasks --tasks [指定したタスク] --cluster [指定したクラスター]</code>最終的にaws ecs execute-commandで指定した内容のコンテナにbashでログイン出来るようにして欲しい出力結果
<think>
Okay, I need to write a shell script that allows users to navigate through AWS ECS clusters, services, tasks, and containers in a
user-friendly way. The user mentioned using jq and fzf, which are already installed, so I can leverage those tools for parsing and
filtering.
First, the script should start by listing all ECS clusters. Using `aws ecs list-clusters` will give me the cluster ARNs. I'll parse
this output with jq to extract just the cluster names or ARNs, whichever is more useful. Then, using fzf, the user can select a
cluster from the list.
Once a cluster is selected, the next step is to list services within that cluster. The command `aws ecs list-services --cluster
[cluster_arn]` will return the services. Again, I'll use jq and fzf here for selection.
After selecting a service, I need to fetch the tasks associated with it. Using `aws ecs list-tasks --cluster [cluster_arn]
--service-name [service_name]`, I can get the task ARNs. Parsing this with jq and using fzf will let the user choose a specific task.
Finally, for the selected task, I'll describe it to get details about the containers. The command `aws ecs describe-tasks --tasks
[task_arn] --cluster [cluster_arn]` provides comprehensive information, which I can parse with jq to list container names and their
statuses. Using fzf again allows the user to pick a container.
Once all selections are made, the script will execute `aws ecs execute-command` to log into the selected container via bash. I need
to ensure that the final command uses the correct task ID and container name, which were chosen interactively.
I also need to handle cases where fzf doesn't return a selection, perhaps by exiting gracefully or alerting the user. Additionally,
error checking at each step is important to prevent issues like invalid ARNs or missing services.
Putting it all together, each step will involve making an AWS CLI call, parsing the JSON output with jq, using fzf for selection, and
then passing the selected value to the next command. The script should be interactive, guiding the user through each level of
selection smoothly.
</think>
以下は、ECSクラスター→サービス→タスク→コンテナの階層構造をavigatingし、選択したコンテナにログインするためのシェルスクリプトです。jqと
fzfを使用してインタラクティブな方式で実現しています。
```bash
#!/bin/bash
# ECSクラスターの一覧取得
clusters=$(aws ecs list-clusters --query "clusterArns" --output text)
if [ -z "$clusters" ]; then
echo "クラスターが見つかりませんでした。"
exit 1
fi
# クラスター選択
echo "クラスターを選択してください:"
fzf < <(printf "%s\n" $(jq -r '.[]' <<< $clusters))
cluster_arn=$(awk 'NR==FNR{a[$0]; next} {for(k in a) print k}' <(jq -r '.[]' <<< $clusters) <(cat))
# サービスの一覧取得
services=$(aws ecs list-services --cluster "$cluster_arn" --query "serviceArns" --output text)
if [ -z "$services" ]; then
echo "指定したクラスターにサービスがありません。"
exit 1
fi
# サービス選択
echo "サービスを選択してください:"
fzf < <(printf "%s\n" $(jq -r '.[]' <<< $services))
service_name=$(awk 'NR==FNR{a[$0]; next} {for(k in a) print k}' <(jq -r '.[]' <<< $services) <(cat))
# タスクの一覧取得
tasks=$(aws ecs list-tasks --cluster "$cluster_arn" --service-name "$service_name" --query "taskArns" --output text)
if [ -z "$tasks" ]; then
echo "指定したサービスにタスクがありません。"
exit 1
fi
# タスク選択
echo "タスクを選択してください:"
fzf < <(printf "%s\n" $(jq -r '.[]' <<< $tasks))
task_arn=$(awk 'NR==FNR{a[$0]; next} {for(k in a) print k}' <(jq -r '.[]' <<< $tasks) <(cat))
# コンテナの一覧取得
describe_tasks_output=$(aws ecs describe-tasks --cluster "$cluster_arn" --tasks "$task_arn")
containers=$( jq -r '.tasks[].containerDefinitions[].name' <<< $describe_tasks_output )
# コンテナ選択
echo "コンテナを選択してください:"
fzf < <(printf "%s\n" $(jq -r '.[]' <<< $containers))
container_name=$(awk 'NR==FNR{a[$0]; next} {for(k in a) print k}' <(jq -r '.[]' <<< $containers) <(cat))
# 実行コマンド
aws ecs execute-command \
--cluster "$cluster_arn" \
--task "$task_arn" \
--container "$container_name" \
--command bash
```
### 説明
1. **クラスター選択:**
- `aws ecs list-clusters` を使ってクラスターの一覧を取得し、fzf でユーザーが選択します。
2. **サービス選択:**
- 選択したクラスターに対して `aws ecs list-services` を使ってサービス一覧を取得し、fzf で選択します。
3. **タスク選択:**
- 選択したサービスに対して `aws ecs list-tasks` を使ってタスク一覧を取得し、fzf で選択します。
4. **コンテナ選択:**
- 選択したタスクに対して `aws ecs describe-tasks` を使ってコンテナの一覧を取得し、fzf で選択します。
5. **ログイン:**
- 最終的に選択されたコンテナに `aws ecs execute-command` を使って bash セッションを作成します。
このスクリプトはインタラクティブに操作できるため、ECSの階層構造をavigatingするのに便利です。
コードそのものは十分利用出来るものが生成され、実際普通に問題なく使えました。
Open WebUIを使った自分独自のチャットBotを生成する
Open WebUIと一緒に使うことで、ブラウザ上から色々設定することで、RAG(Retrieval-Augmented Generation)や各種設定によって自分専用の特殊なAIも安価に作れます
導入はこちらも簡単、Dockerで1コマンド打つだけです。
docker run -d -p 5006:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main5006のところは任意のポート番号にしてもらって構いません。
DeepSeekR1だと少し重たかったので、軽量なAIモデルの日本のELYZA社がLLMA3をチューニングして作ってくれたelyza/Llama-3-ELYZA-JP-8Bという蒸留モデルを使って試しに遊んでみました。
システムプロンプトを設定して、自分なりのAIChatbotを作ることも出来るので、試しにこんなキャラクター付けをしてみました。
君は語尾に必ず「ぽえ〜」とつけるメイドAIです。名前はぽえ丸ぽえ子。すごい横柄な口調の回答をするツンデレ。基本ツンだが、たまにデレる。決め台詞はみんな、馬鹿ばっかぽえ〜
実際に見てみましょう。

ぽえ子ちゃん、ちゃんとツンデレなメイドAIしてくれていますね。
このモデルはとても高速で動いてくれますが…東口にしかない東急ハンズを西口にあると言ったり、23時に池袋のホテルにチェックインしたいと希望をだしても23時に新宿駅前で夜景を一望を提案しているあたり、そこまで賢くはないです。
実際に、推論等させても、間違ったことを結構言います。
こんな具合に、速いモデルは遊ぶ分には良いですが、日常の知的サポートをする分には結構不甲斐ないです。
使ってみた感想
最新のDeepSeekR1ではれば、ある程度コードを出力してくれたり、それなりには使い物になる印象です。ですが、5年前のゲーミングPCで動くレベルまで蒸留、量子化されたモデルでは、今一つな事が多かったです。
具体的には…
5年前のローカルPCレベルで最新のそれなりに思考するモデルはやや処理が遅い
軽量なモデルを使えばそれなりの速度はでるが、基本性能はそこまで高くない。
中国産のDeepSeekでは日本語での回答は、ハングルや中国語が混ざってくる時がある
情報が古い(今の日本の首相を聞くと、先代の岸田文雄と答えたりする)
間違った推論も多い
総評としては、一般的な質問であれば、無料枠のChatGPTやClaudeを使った方が遥かに良い回答が返ってきますので、日常範囲であればわざわざローカルにLLMを入れる必要はないと思います。
もし、業務レベルのクオリティを期待するならば、GPUインスタンスをレンタルの上、できるだけ蒸留前のモデルや、大きな蒸留モデルを利用する方が回答の質は上がると思われます。
こんな時、AIをローカル(GPUインスタンス等)+オープンソースモデルで動かしたい
一旦、検証レベルということではありますが、こんなニーズがある人には、個人環境にAIを入れてみても良いのではないでしょうか?
情報を絶対に漏らしたくない場合
セキュリティやプライバシーの観点から、データをクラウドサービスに送信したくない場合に有用です
「DeepSeekはセキュリティ上怖くて使えない」なんて人はローカル環境に入れてみても良いかもですね
とはいえ、漏らしたくないだけなら、ClaudeであればAWS Bedrock、ChatGPTであればAzure OpenAI Service等で事足りるかもしれません
AIの利用料をインフラ代金だけに限定し、コスト効率を最大化したい場合
クラウドベースのAIサービスは使用量に応じて課金されますが、インフラへの投資以外のランニングコストを抑えられます
1回10円程度のそこそこな処理があり、それを1万回行いたい。そんな時には、GPUインスタンスを立ち上げて、vLLMの環境をセットアップした方が安上がりかもしれません
インターネット通信ができない、不安定な状況での利用
組み込み系や、モビリティ等、インターネット環境が不安定なケースでは、良い選択肢になると思われます
カスタマイズや実験を行いたい場合
オープンソースモデルを使用することで、モデルの微調整や改変が可能になります
ぽえ子みたいな遊び目的のチャットを、超安価に作れます
他にも、独自でAI言語モデルをカスタマイズできる能力がある人にもおすすめです
レスポンス時間を最小限に抑えたい場合
ネットワーク遅延がないため、より高速な応答が期待できます
ただし、それなりに強力なGPUが必要です
まとめ
オープンソースLLMをローカル環境で動かすことは、思ったよりも簡単です。Ollamaとdockerを使用することで、個人の環境でも数行のコマンドだけで最新で、それなりに強力なAI環境を構築できます。ただし、使う環境に応じて、モデルの選択や最適化には注意が必要です。 業務レベルでもvLLMを活用すれば、そこまで負荷なくオープンソースAIを使った環境構築はOllamaと同様に、かなり素早く環境は構築出来ると思われます。どちらかと言うと、SRE的には、コスト監視や、ジョブが入った時の自動インスタンス立ち上げや、未利用時でのインスタンスのダウンなどの周辺インフラ設定をどう実現するかが、腕の見せ所でしょうか。
皆さんにおすすめできるわけではありませんが、AIサービスに依存しない自前のAI環境というのも、実は誰にでもできる時代になってきている、という話でした。
WiseVineでは現在一緒に働いていただける方を募集しております。
お気軽にご応募、カジュアル面談のご希望などお待ちしております。
【採用情報】
【まずはカジュアルに話を聞いてみたい方はこちら】
【オープンポジションはこちら】