
スクレイピング入門 第2回~スクレイピングを実践してみよう!~

みなさんこんにちは!
「スクレイピング入門~Webサイトの情報を自由自在に手に入れよう~」では、スクレイピングとは何か、やスクレイピングをするときの注意点についてお伝えしました。
今回の「スクレイピング入門 第2回」では、プログラミング言語のPythonを使用してWebページから情報を取得する方法を解説します!
※今回HTMLに関する用語解説は省略します
スクレイピング対象ページ
今回は、前回のスクレイピングの記事ページから記事の文章のみを取得したいと思います。
URL:https://note.com/wid_dataminds/n/n7dbe191760a8
実行環境
・Windows 11 Pro
・IDLE(Python 3.12)
ライブラリ
・requests 2.31.0
・beautifulsoup4 4.12.3
スクレイピング時の注意事項
スクレイピングを始める前に、前回の記事でご紹介したスクレイピングをするときの注意事項を覚えていますか?
注意事項は以下の3つでした。
①利用規約
②サーバー負荷
③著作権
それではまず、①の利用規約から見ていきましょう。
以下がnoteの禁止事項ですが、スクレイピングについての記載はありません(2024年10月24日時点)。

note利用規約:https://note.com/terms
スクレイピングが禁止されていないかの確認には、利用規約を確認するほかに「robots.txt」を確認する方法もあります。
「robots.txt」とはサイトの管理者がサイトを自動で見て回るプログラムに対してどのページやファイルにアクセスできるか、またはアクセスしてほしくないかを指示するためのファイルです。
サイトURLの末尾に「/robots.txt」と記載することで確認することができます。
今回の場合は、アドレスバーに「https://note.com/robots.txt」と記載することでnoteの「robots.txt」を確認することができます。
以下はnoteが自動回覧を制限しているページの記載ですが、こちらでもクリエイターの記事ページについて制限する記載はありません(2024年10月24日時点)。

note_robots.txt:https://note.com/robots.txt
②のサーバー負荷については、今回は1ページのみを対象にスクレイピングをするので問題はないでしょう。
③の著作権については、今回はスクレイピングの対象とするページが自分で作成した記事ページであり、noteの利用規約には「著作権はクリエイターに帰属する」と記載されているので、こちらも問題ないでしょう(2024年10月24日時点)。

note利用規約:https://note.com/terms
スクレイピング時の注意事項は確認しましたので、ここからは実際に使用するソースコードとその解説をします!
解説が難しいと感じた方も、以下のコードをコピペして実行するだけでスクレイピングができるので、ぜひ実践してみてください!
HTMLを取得
まずは情報が欲しいページのHTMLを取得していきます!
# ①ライブラリのインポート
import requests
from bs4 import BeautifulSoup
# ②取得したいページのURLを変数に格納
url = 'https://note.com/wid_dataminds/n/n7dbe191760a8'
# ③取得したいページの情報(requestsオブジェクト)を取得
response = requests.get(url)
# ④取得した情報の確認
print(response.text)
①ライブラリのインポート
今回使用するライブラリは以下の2つです。
・requests
・BeautifulSoup
「requests」はHTTP通信を行うライブラリです。
こちらを使用することで、Webページの情報を取得することができます。
「BeautifulSoup」は取得したHTMLの情報を解析し、特定の要素を抽出することができます。
これら2つはPythonの標準ライブラリに搭載されていないため、インストールしていない方は事前にコマンド プロンプトやWindows PowerShellでインストールしてください。
②取得したいページのURLを変数に格納
今回は、取得するURLを変数「url」に格納しています。
変数名は自分のわかりやすいものにしてください!
③取得したいページの情報(requestsオブジェクト)を取得
「requests.get()」を使用すると( )内のURL(第一引数)のresponseオブジェクト(サーバー情報やHTMLテキストなど)を取得することができます。
今回は、この情報を変数「response」に格納しています。
④取得した情報の確認
「print(response.text)」によって取得したURLのresponseオブジェクトの中から、HTMLを文字列で表示することができます。
今回取得した情報は以下です。

「requests」を使用して目標のページのHTMLを取得できました!
しかし、今の段階ではタグなども含めてページ全体の情報を取得しているので、ここから必要な情報に絞る必要があります。
記事の文章を取得
そこでここからは、「BeautifulSoup」を使用して今回目標とした記事の文章のみを抽出していきます!
# ⑤取得したHTMLをBeautifulSoupで使える形に変換し変数に格納
soup = BeautifulSoup(response.text, 'html.parser')
# ⑥記事の文章を抽出
p_tags = [tag for tag in soup.find_all('p', attrs={'name': True}) if not tag.has_attr('style')]
# ⑦抽出した文章を表示
for tags in p_tags:
print(f"{tags.get_text()}")
⑤取得したHTMLをBeautifulSoupで使える形に変換し変数に格納
「requests」で取得したHTMLを「BeautifulSoup」が扱える形にして変数に格納します。
第二引数で指定している「'html.parser'」はプログラムがHTMLを理解しやすい形式に変換するために使用されます。
⑥記事の文章を抽出
記事の文章はname属性が設定されている<p>タグに格納されています。
ページ全体から上記の該当の部分のみ抽出し、リストに格納しています。
「soup.find_all」は指定したタグや属性に一致するすべてのタグを検索しリストとして返します。
指定したタグや属性は「'p', attrs={'name': True}) if not tag.has_attr('style')」の部分でname属性の<p>タグのみを抽出するよう指定しています。
「attrs」引数はタグの属性に基づいてフィルタリングを行う引数です。
※タグや属性などの要素がどこに格納されているかは「取得対象の探し方」を参考にしてください。
⑦抽出した文章を表示
最後に抽出文章を表示します。

上記が表示結果です。
記事の文章部分のみを抽出できています。
取得対象の探し方
ページ内の取得したいデータの探し方についてですが、Google Chromeの場合取得したいページ内で右クリックをすると検証というダイアログが表示されますのでそこをクリックしてください。
これにより開発者ツールを開くことができます。
※F12キーでも開くことができます。
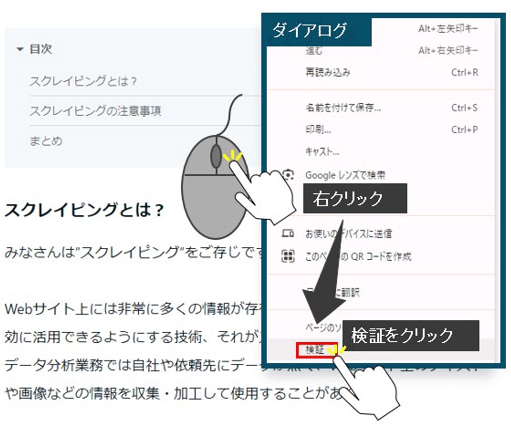
開発者ツールを開いたら、下図のようにセレクトモードをクリックしてください。
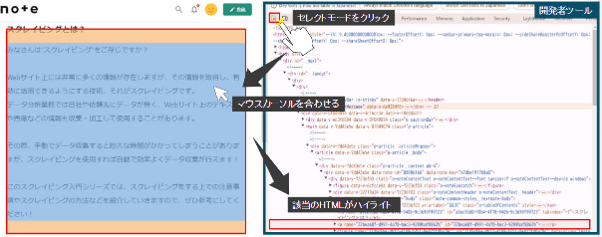
次に、今回取得した文章のような、取得したい情報の場所にマウスカーソルを合わせてください。
すると開発者ツールにカーソルが指す情報が格納されているHTMLがハイライトされます。
あとは、今回のコードの⑥を参考にタブや属性などの要素を指定すれば抽出できます。
まとめ
今回は記事の文章をスクレイピングしましたが、こういった文章を取得し分析などに活用する事例はいくつかあります。
例えば、ニュース記事やレビューから文章を取得すれば、内容から世間的な評価を分析する「感情分析」ができたり、文章内から隠れた特徴を見つけ出し分類する「トピックモデル」を作成したりすることもできます。
文章のほかにも表や画像、動画なども取得できるので、上記以外の活用方法も多岐にわたります。
分析業務では大量のデータを必要とするので、スクレイピングを活用してオープンデータを取得し、利用することは非常に有用です。
ぜひ、みなさんも今回の記事を参考にコードを書いて、スクレイピングをマスターしてください!
【ワークスアイディのホームページはこちら】