
データサイエンスをアウトプットしながら20分で学ぶ①~タイタニック編~

こんにちは、ワピアです😊
今回は、「データサイエンスのアウトプットの機会がない!」とお悩みの方に向けたものです。
データサイエンスは性質上、実際に会社に就職、仕事をもらわないとデータがないため、実務経験に相当するようなポートフォリオを用意しにくいです。
それは会社側も承知していて、実務経験がない場合、何で判断するかそれぞれ基準を設けています。
その中でも、多くの会社で支持されている(個人的体感ですが)のはデータ分析コンペでのアウトプットです。
実務で使う工程がいくつも含まれていて、実際のデータ分析に近いのが理由でしょう!
そこで、今回はkaggle(データ分析コンペ)の登竜門であるタイタニックのデータ分析をやっていきたいと思います!
いやkaggleってなんだよって思った方も大丈夫です。すべて説明します!
kaggleって?
kaggleとは与えられたデータをもとに、予測を行いその精度を競うデータコンペティションを運営している会社のことです。
kaggleでは様々なコンペが行われており、世界中のデータサイエンティストが参戦しています!
さっそくkaggleをやってみよう!
まずはkaggleのサイトにアクセスして、登録を済ませちゃいましょう!
そしたら、Competitionに移動して、タイタニックのコンペを見つけます。

ここまで来たらあとは右のJoin Competitionをクリックするだけ!
これで参加できました!
あとはdataのダウンロードをしておけばOK
それではここからタイタニックのデータで実際に分析していきます!
ここから先の手順
・jupyter notebookを開く
・コードを出てきた順に理解しながらコピペ
(理解は完全でなくても大丈夫!、どんどん先に進もう!!)
(飛ばしていいところは"""~"""で囲います、、、😄)
前提の確認
最初にするのは、前提確認です。
・どういった問題なのか(タイタニック号の生存したかどうかの判定)
・データの内容(テーブル,、表の形をしているデータ)
・評価指標(正解率)
モジュールのインポートも先にやってしまいます
# data processing and visualization
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
# algorithm
import xgboost as xgb
# training
from sklearn.model_selection import train_test_splitなんやそれ!という方も大丈夫。
これから学べばOK
”””飛ばして~
・numpy(np)(行列計算などの科学技術計算を行う)
・pandas(pd)(データの操作を行う、列の削除とか表の結合とか!)
・matplotlib(plt)・seaborn(sns)(グラフを描く!、seabornはmatplotlibのお手軽版、お手軽でやりたければseabornで複雑なグラフとかはmatplotlib!)
・xgboostは後で!、モデルの一つです
・sklearn (scikit-learn) (機械学習の便利道具がまとまっているもの、今回はその中の訓練データとテストデータを分ける道具をもってきました)
"""
データも読み込みます!
pandasポイント:
データの読み込み:pd.read_csv("パス")
#pandasでデータを読み込む
#pd.read_csv("パス")で読み込める
train = pd.read_csv("train.csv")
test = pd.read_csv("test.csv")パスに注意してください!
同じフォルダ内にある場合は上のコードをコピペで大丈夫です。
データをみる
データの可視化、データへの理解を深める作業です。
EDA(Exploralatory Data Analysis)と呼ばれたりもします。
テーブルデータのEDAに取り組んでいきます!
代表的なEDAで概要をつかむ
今回は、代表的なものの紹介にとどめます。
20分で終わらなくなってしまう、、、
・どんなデータかとりあえず見る
目的:どんなカラム(列)があるかみる。
#()内は表示する行数を指定できる!、デフォルトは5
train.head(3)
上から3行のデータをとっています。
データの説明を軽くします
Survived(生存したかどうか 0なら死亡、1なら生存)
Pclass (客室のグレード)
Embarked(どの港からタイタニック号に乗車したか)
・テーブルの形ってどうなってる?
目的:すべてのデータを出力することはできないので、データの行数はチェックしておきたい!
train.shape
#出力
#(891,12)
#(行数,列数)891行のデータでカラムは12個!
・テータ型、欠損の把握
train.info()はデータの型と欠損値を把握できます。
train.info()
データの総数は891(先ほど確認)なので、それよりも小さければ欠損しているのです!
つまり、Age,Cabin,Embarkedが欠損しているとわかります。
また、NameやSex,Ticket,Embarkedはobject型なので前処理で数値に変更する必要があると分かります。
・基本統計量の確認
train.describe()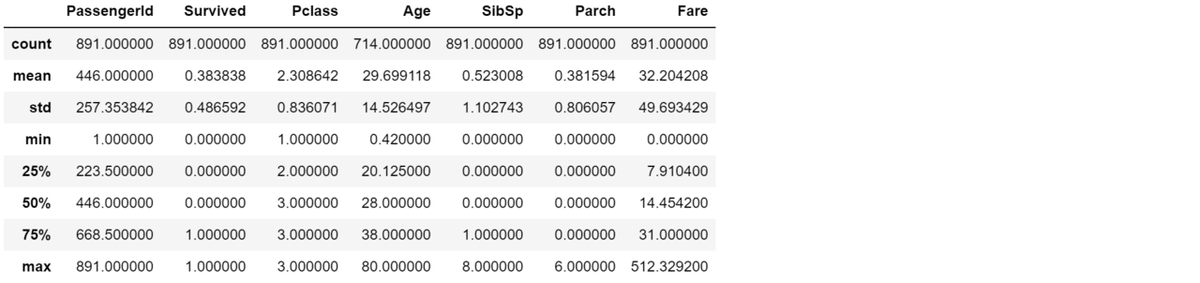
数値型のデータにしか適用されないことに注意!
”””飛ばして~
count 件数
mean 平均
std 標準偏差
min 最小値
25% 第一四分位
50% 中央値
75% 第三四分位
max 最大値
”””
グラフ系(seabornでグラフを描く!)
・相関係数のヒートマップを見る
目的:特徴量同士の相関をみる(目的変数(生存したかどうか)に相関がある特徴量はより重要!)
sns.heatmap(train.corr(),annot=True,center=0,square=True,cmap="Greens")
・カウントグラフ
目的:欠損しているEmbarkedの様子をみてみる
sns.countplot(x="Embarked",data=train)
Sが最頻値であると分かりました。
前処理・特徴量生成
さっきのEDAと同時進行で行っていきます。
機械学習ではモデルによっては、数値しか受け付けなかったり、欠損値があるとエラーになったりするものもあります。
前処理を行って回避していきます!
トレーニングデータとテストデータをくっつける
目的:訓練データとテストデータは両方同じ前処理を行うのだが、2度同じことをやるのは面倒なので、連結して一度にやってしまう。
#トレーニングデータとテストデータをくっつけるにあたり、区別がつくようにカラムを追加しておくtrain['is_train'] = 1
test['is_train'] = 0
#df1,df2を結合する→pd.concat([df1,df2],axis=0)
#train.drop(["カラム名"],axis=1)でカラムを削除!!
df = pd.concat([train.drop(['Survived'], axis=1),test],axis=0)
df.shapeaxisは縦方向か横方向かの指定です。axis=0は水平方向。
これをすることでまとめて前処理できるようになります!!
代表的な前処理
・欠損値を埋める
目的:欠損しているとモデルによっては学習ができないため
pandasポイント:df["カラム名"].fillna(値)で欠損値を埋める
#平均と最頻値で埋めてみた
df["Age"] = df["Age"].fillna(df["Age"].median())
df["Embarked"] = df["Embarked"].fillna("S")欠損の扱い方はいろいろありますが、今回は代表値で埋める手法を採用!
Ageは中央値、Embarkedは最頻値で埋めます
・相関のない、余計なカラムの削除
目的:相関の薄いカラムや欠損が多く情報にかけるカラムは削除しておく
df = df.drop("PassengerId",axis=1)
df = df.drop(["Name","Ticket","Cabin"],axis=1)さきほどのheatmapでPassengerIdは相関がなかったため削除
また、Name,Ticketは文字列データで、前処理が高度であるため今回は扱いません。
Cabinは欠損がとても多いため削除
・文字列データを数値に変換
df['Sex'] = df['Sex'].map( {'female': 1, 'male': 0} ).astype(int)
df["Embarked"] = df["Embarked"].map({"S":0, "Q":1,"C":2}).astype(int)
モデル作成の準備
いよいよモデル作成を行います!
少し準備です。
・さっき結合したものをもう一度わける
# 「is_train」で訓練データとテストデータをわける
df_test = df.loc[df['is_train'] == 0]
df_train = df.loc[df['is_train'] == 1]
# 「is_train」を削除
df_test = df_test.drop(['is_train'], axis=1)
df_train = df_train.drop(['is_train'], axis=1)
df_test.shape, df_train.shape・目的変数を用意する
train_y = train["Survived"]
train_X = df_train・トレーニングデータをトレーニングデータとバリデーションデータに分ける
X_train,X_test,y_train,y_test = train_test_split(train_X,train_y,test_size=0.7,random_state=0)モデルの作成
今回使うモデルはXGBoostというモデルなのですが、説明が長くなるので、
とりあえずコードのみ書いておきます。
詳しい説明は別記事にあるのでそちらもご参考下さい!
・作成(パラメータチューニングは別記事をご覧下さい)
model = xgb.XGBClassifier(max_depth=3)
・実際にトレーニングさせる
model.fit(X_train,y_train)・精度をチェック!!
print(model.score(X_train,y_train))
print(model.score(X_test,y_test))
最後に
いかがだったでしょうか。長くてうんざりしたかもしれません😂
ですが、この記事で一通りのデータ分析の工程を消化できました!
これでもうデータサイエンティストとしてのアウトプットが完成しています。
もしご不明な点がございましたらコメントをお願いします。
ご覧いただきありがとうございました!
この記事が気に入ったらサポートをしてみませんか?