
Twitter利用者のIQは高いのか? ―Rを使ってツイートされたIQ診断結果を分析した―

●はじめに
Twitterで令和初IQテスト2020年度版というものを見つけました。
もし興味がありましたら下記リンクから診断してから記事を読むと面白いかもしれません。
自分でもやってみましたが、結果が高いのか低いのか、全体のうちでどれくらいなのか分かりません。
結果はタグ付きでツイートできるようになっているため、Twitterで#令和初IQテスト2020年版 で検索すると様々な結果がツイートされています。
見てみれば分かりますが、ツイートされているIQは結構高めな方が多いです。IQって普通100前後じゃなかったっけ? やはりTwitter民は頭が良い?
そこで今回はツイートされているIQテスト結果を収集し、ツイートしている人達がどれくらいのIQなのか、自分のIQがどれくらいの位置なのかを知るために分析してみました。
データ収集と分析はRを用いました。使ったコードは最後に記載いたします。
Rは趣味でやってるだけのド初心者なので他にもっと良い方法はあるかも。
Pythonは音楽性の違いでちょっと苦手で...。
●方法
R version 4.0.2 + RStudioを用いました。
実行環境はWindows。
使用したパッケージはrtweet、tidyverseです。
rweetパッケージで用いるTwitter API keyの取得方法はネット上に分かりやすい記事がございますので、そちらをご参照ください。
●ツイートデータの収集
rtweetを用いて「#令和初IQテスト2020年版」を検索し、データを収集しました。
集計範囲は2020-08-22 ~ 2020-08-30。
収集されたツイート数は1279でした。今回の分析には十分な数でしょう。
●ツイートのテキストデータから点数を抽出
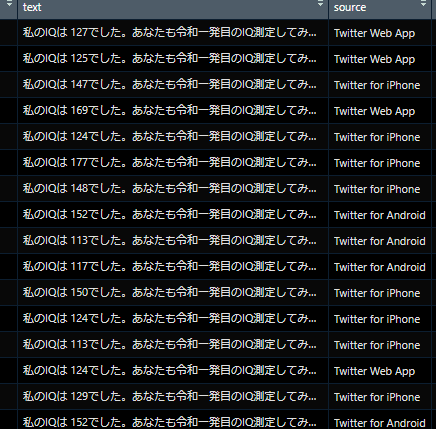
上のように収集されたツイートの投稿テキストデータから。
dplyrとstringrパッケージで頑張って点数が書かれた位置を抽出して。
Wasshoi!
点数データを抽出できました。
●結果 ―Twitter民はIQが高い!?
データ分析に用いたツイートは重複ユーザーと無効なデータを除き1243ツイートでした。
得られた点数分布をヒストグラムにしてみました。
階級幅は1つあたり10点です。

115から125点の人が一番多く、その前後が多く分布しているようです。
105点以下の人はあまりいないようです。
170前後のすげー奴らもそこそこいるようです。
確かIQは平均が大体100で、130以上の人は5%もいないはず。
やはりTwitter民は高IQな人たちがばかりで頭が良かった!!!?
さすがだぜTwitter民!!!!!!!
●ちょっと待て ―標準的な分布との比較
知能指数(IQ)は平均値100の標準偏差15の分布のはずです。
(Wikipedia 知能指数)
IQは正規分布します。正規分布の性質から平均±標準偏差を考えると、理想的には85~115点(±1σ)に100人中68人、70~130(±2σ)に100人中95人が収まるはずで、145以上(±3σ)は1人いるかどうかのはずです。
しかし今回Twitterから集計された1243ツイートの点数は以下のような結果となりました。
平均:129.0
(95%信頼区間 127.8 < x̄ < 130.2)
標準偏差:21.9
仮に理想的なIQの分布 (N=1243) を考えると
平均:100
(95%信頼区間 99.2< x̄ < 100.8)
標準偏差:15
となるはずですので、Twitterから集計されたIQ点数の分布は、理想的なIQ分布と比べても高すぎていて、明らかに大きな有意差があります。
というかそもそも山が二つありますし正規分布してないっぽいです。
そこで平均100 標準偏差15の正規分布乱数をn=1243 発生させて標準IQ分布とし、その分布をTwitterから得られた点数分布と比較しました。

赤が乱数発生させた標準IQ分布、青がツイートされたIQ点数の分布です。
明らかにTwitterのIQ分布の方が点数が高いですね。
本来であればIQ150以上の人はほとんどいないはずなのに、Twitterではかなりの人数がいるようです。
なぜこのようなことになってしまっているのでしょうか。
Twitterユーザーは高IQの持ち主の集まりなのでしょうか?
●考察
仮説1:問題が簡単
診断テストの問題が簡単なために正答率が高く、平均値が高く出るのかもしれません。
しかしIQ診断テストを作るような人が「知能指数(IQ)は平均値100の標準偏差15の分布」ということを知らないことは考えにくいです。
実際に何度か同じ回答で診断してみると点数が変わるようであり、回答者の分布によってIQが変化している可能性があります。
このため恐らく問題が簡単すぎるということはないのではないかと思います。
仮説2:高い点数だけツイートされている。
集計に使用されたデータは「ツイートされた点数」です。
このため、
・どこかで回答を見た上で診断しツイートした
・何度かチャレンジして高い点数を選んでツイートした
・低い点数をツイートしていない
・そもそもツイッターをやっていて診断する人、最後まで診断する人は教育水準が高い、自信があって正答率が高いなどで平均点が高い
(わからない人はそもそもやらないか、途中で脱落する。)
等の理由によって高いIQに偏ったツイートがなされているのではないでしょうか。
分布の山が二つに分かれているのもこれが原因な気がします。
要するに高い点数でツイートしている人は世間一般と比較して実際にIQが高いか、見栄っ張り、あるいはズルをしていると言うことです。
本当に賢い人もいるでしょうし、見栄っ張りな事は別に悪いことではなく仕方のないことではありますが。...ズルはダメ。
仮説3:集計・分析者(僕)がヘボくて偏った集計・分析がなされた。
><
●まとめ
いかがでしたでしょうか。暇つぶしにやってみましたが意外と面白い結果になったのでnote記事にしてみました。
Twitterの分析をする際には偏りに気を付けなければいけないという一つの例でもあります。
Twitterからのサンプリングがこのような偏った結果にならないためには以下のような対策が考えられます。
・優劣のつかない数値データやカテゴリカルデータを分析して「見栄」などの心理的バイアスの入る余地を無くす。高い低いの無い性格診断結果などなら適切に集計できるかもしれません。
・なるべく色々な人がチャレンジしている診断リリース直後に分析し、前情報を持った診断や再チャレンジなど診断者の偏りによる影響を除く。
・Twitter以外の他媒体のデータが入手可能であればしっかり比較を行う。
皆さんは分布の中でどれくらいのIQだったでしょうか?
Twitterの分布と比べて低い位置にあっても気にしてはいけません。
68%の人は100±15に収まるのです!
そもそもこういった診断は、パターンを見つける能力を評価しているだけであって、本当の頭の良さを評価している訳ではありません。
今回は数値データを抽出しましたが、テキストマイニング等と組み合わせたり、価格データを抜き出したりなどでTwitterから有用なデータを得られるかもしれませんね。
Twitterからのデータ収集の良い勉強になりました。
診断を作る際にも診断結果のツイートの出力方法を工夫することで有用な集計結果が得られそうです。
何か興味のある分析がございましたらご相談いただけましたらやってみるかもしれません。
ご意見、改善点もいただけますととっても喜びます。
●で、筆者のIQはいくつだったんだ?
僕のIQはヒミツです。
なぜなら僕は見栄っ張りではないので。
...という気持ち悪い冗談でオチをつけて終わりにしたいと思います。
見てくださった方はありがとうございました!
●使用したコード
初心者なので冗長です。
ご意見、改善点をいただけますと喜びます。
数値の抽出方法は改善の余地がありそう。
# library
if(!require("rtweet")){
install.packages("rtweet", dependencies=TRUE)
}
if(!require("tidyverse")){
install.packages("tidyverse", dependencies=TRUE)
}
# token setting
twitter_token <- create_token(app = "****",
consumer_key = "****",
consumer_secret = "****",
access_token = "****",
access_secret = "****")
# Tweet data collecting
x= "#令和初iqテスト2020年版"
rt <- search_tweets(x, n = 240000, retryonratelimit = TRUE, include_rts = FALSE)
# 念のため重複ツイートを除く
rt <- rt %>% distinct(created_at, screen_name, .keep_all=TRUE)
# ツイートの集計範囲 data collecting range
as.POSIXlt(as.POSIXct(range(rt$created_at), tz="Eulope/London"),tz="Japan")
# tweets count
length(rt$text)
# unique users count
length(unique(rt$screen_name))
# IQ score extracting
rt2 <- rt %>% select(created_at, screen_name, text) %>% distinct(screen_name, .keep_all=TRUE) %>% filter(grepl(pattern = "私のIQは ", x= text))
# str_locateで私のIQは 〇〇でした。の〇〇点数の前後の位置を検出。
rtnumf <- str_locate(rt2$text, pattern = "私のIQは ") %>% as.data.frame()
rtnumb <- str_locate(rt2$text, pattern = "でした。") %>% as.data.frame()
# 特定した位置を使用して〇〇部分だけを抜き出し数値データにする。点数の文章内の位置によってはnaが出てしまうので除く。naは数個しかなかったので見なかったことにしてそのまま分析しました...
rtnum <- cbind(rtnumf[,2]+1,rtnumb[,1]-1) # これいらないんですがまとまった位置データが欲しかったので。診断そのままツイートする人や、コメントする場合どこの位置にする人が多いかが分かります。
rt3 <- str_sub(rt2$text, rtnum[,1], rtnum[,2]) %>% as.numeric() %>% as.data.frame() %>% drop_na()
# two-sided 95% confidence interval for mean
N <- nrow(rt3)
mean <- mean(rt3[,1])
sd <- sd(rt3[,1])
t <- abs(qt(0.05/2, N-1))
SE <- sd/sqrt(N)
(lower <- mean - t * SE)
(upper <- mean + t * SE)
# ggplotで使うフォント設定。https://launchpad.net/takao-fonts Takaoフォントをお借りしました。
windowsFonts("TPG"=windowsFont("Takao Pゴシック"))
# histgram 1
ggplot(rt3) +
aes(x = .) +
geom_histogram(binwidth = 10, fill="skyblue", colour="black") +
labs(x = "点数の分布", y = "数量(度数)", title = "#令和初iqテスト2020年版 点数の分布", subtitle = "2020-08-22 ~ 2020-08-30 n = 1243") +
theme_minimal(base_size = 16, base_family = "TPM")
# 標準的IQの平均値100の標準偏差15の正規分布乱数を1243個発生させて標準的IQ分布データを仮に作る
std.IQ <- as.integer(rnorm(1243, 100, 15)) %>% transform(label="Standard IQ")
# ggplot用にTwitterIQデータと標準IQデータを結合してデータフレームを作る
rt3 <- transform(rt3,label="Twitter IQ")
colnames(rt3) <- c("X_data", "label")
IQ.data = rbind(rt3,std.IQ)
# histgram 2
ggplot(IQ.data) +
aes(x = X_data, fill = label) +
geom_histogram(binwidth = 10, position = "dodge") +
scale_fill_hue() +
labs(x = "点数の分布", y = "数量(度数)", title = "#令和初iqテスト2020年版 点数の分布と標準的なIQの分布", subtitle = "2020-08-22 ~ 2020-08-30 n = 1243") +
theme_minimal(base_size = 16, base_family = "TPM")
いいなと思ったら応援しよう!
