
G検定チートシート(cheat sheet)(2024年第三回G検定 2024.5.11)

せっかく作ったので公開しておきます。Ctrl+Fで検索で利用してください。
私の勉強方法などの経験は「G検定受けてみた」を参照ください。
2024.11月から試験の新しいシラバス対応版はこっち
人工知能とは
学習目標:人工知能や機械学習の定義を理解する
学習項目:人工知能とは何か、人工知能のおおまかな分類、AI 効果、人工知能とロボットの違い
推論 (Inference)
特徴: 推論は、与えられた事実やデータから新しい結論を導き出す過程です。
目的: 未知の情報を既知の事実から導き出し、意思決定や問題解決に役立てること。
説明: 例えば、天気予報で「今日は雲が多い」という情報があれば、「雨が降る可能性が高い」と推論することができます。AIではこの論理的な推論を自動化し、データから新しい知識や結論を生成します。
認識 (Recognition)
特徴: 認識は、センサーやデータからパターンを識別する能力です。
目的: 環境や入力データから有用な情報を識別し、それに適切に反応すること。
説明: 顔認識システムがカメラで捉えた画像から個々の顔を識別するプロセスです。この技術はセキュリティシステムやスマートフォンのロック解除などに利用されます。
判断 (Judgment)
特徴: 判断は、利用可能な情報を基に最善の選択肢を選び出す過程です。
目的: 効率的かつ効果的な意思決定を行うため。
説明: 自動運転車が道路の状況を分析し、停止するか続行するかを判断するプロセスです。車は周囲の状況を評価し、安全を最優先に判断を下します。
エージェント (Agent)
特徴: エージェントは、自身の知覚をもとに行動を決定し、環境に作用するエンティティです。
目的: 環境内で自動的にタスクを実行し、目標を達成すること。
説明: オンラインカスタマーサービスのチャットボットは、ユーザーからの質問を理解し、適切な回答を提供するエージェントの一例です。
古典的な人工知能 (Classical AI)
特徴: 論理的推論やルールベースのシステムに重点を置いたAIのアプローチです。
目的: 明確なルールやアルゴリズムを通じて問題を解決すること。
説明: ショッピングカートの推薦システムなど、あらかじめ設定されたルールに基づき、関連商品を推薦します。
機械学習 (Machine Learning)
特徴: データからパターンを学習し、その学習を基に予測や分類を行うAIのサブフィールドです。
目的: 手作業によるプログラミングを減らし、データ自体から直接学習すること。
説明: メールシステムが受信したメッセージからスパムを自動で識別するフィルタリング機能です。
ディープラーニング (Deep Learning)
特徴: 多層のニューラルネットワークを用いて複雑なパターンを学習する機械学習の手法。
目的: 音声、画像、テキストなどの複雑なデータから高度な特徴を抽出し、より精度の高い予測や分類を行うこと。
説明: 自動写真タギング機能が、写真の中の物体や人物を識別し、タグ付けするプロセスです。
学習目標:ブームと冬の時代を繰り返してきた人工知能研究の歴史を学ぶ 学習項目:世界初の汎用コンピュータ、ダートマス会議、人工知能研究のブームと冬の時代
エニアック (ENIAC)
特徴: 第二次世界大戦中に開発された、世界初の電子式汎用コンピュータ。
目的: 軍事的な計算ニーズ、特に弾道計算表の作成を自動化するため。
説明: ENIACは真空管を数千個使用し、重量は約30トンありました。その計算能力は当時としては画期的で、手作業で行う場合よりもはるかに速く計算を行うことができました。
ダートマス会議
特徴: 1956年に開催された、人工知能分野の創成期に位置づけられる会議。
目的: 人工知能研究の基盤を形成し、学問としての地位を確立するため。
説明: この会議でジョン・マッカーシーが「人工知能」という用語を初めて使い、その後の研究の方向性や分野の定義が議論されました。
ロジック・セオリスト
特徴: アレン・ニューウェルとハーバート・サイモンによって開発された、最初期のAIプログラムの一つ。
目的: 数学的定理を自動で証明すること。
説明: ロジック・セオリストは、人間の問題解決プロセスを模倣しようとする試みであり、初めてコンピュータが数学的な証明を生成した例とされています。
Logic Theorist:AI黎明期の革新者
Logic Theoristは、1955年から1956年にかけてアレン・ニューウェル、ハーバート・サイモン、J・C・ショーによって開発されたコンピュータプログラムです。人工知能の最初の実用的なプログラムと称され、AI研究に大きな影響を与えました。
Logic Theoristの目的と役割
Logic Theoristの目的は、論理学における定理を自動的に証明することでした。当時、コンピュータは主に数値計算に使用されていましたが、Logic Theoristは論理的な推論を行うことを可能にし、AIの可能性を示しました。
Logic Theoristは以下の役割を果たしました。
論理学における定理の自動証明: 論理的な推論規則に基づいて、定理を自動的に証明することができました。
人工知能の可能性の提示: 当時としては画期的な成果であり、人工知能の可能性を広く知らしめました。
問題解決手法の開発: ヒューリスティック法と呼ばれる問題解決手法の開発に貢献しました。
トイ・プロブレム
特徴: 複雑さを制限した簡単な問題で、AI研究でよく使用されます。
目的: 新しいアルゴリズムや理論を試験するための簡易モデルを提供する。
説明: これらは現実の問題よりも単純化されており、新しいアプローチの有効性を評価するのに役立ちます。例えば、チェスの終盤やパズルゲームなどが含まれます。
エキスパートシステム
特徴: 特定の分野の専門家の知識を模倣して設計されたコンピュータプログラム。
目的: 専門家の判断を代替し、その知識を広く提供する。
説明: エキスパートシステムは、医療診断や工学設計など、特定の専門知識を要する分野で利用されました。
第五世代コンピュータ
特徴: 1980年代に日本で開始された、知的なコンピュータシステムを開発するための国家プロジェクト。
目的: AIとコンピュータ科学の進歩を通じて、次世代のコンピュータ技術をリードする。
説明: プロジェクトでは、並列処理やロジックプログラミングを重視し、AIアプリケーションを強化しようとしましたが、商業的には大きな成果を上げることはできませんでした。
ビッグデータ
特徴: 非常に大規模で複雑なデータセット。通常、従来のデータ処理アプリケーションソフトウェアでは扱いきれない規模です。
目的: 大量のデータからパターン、トレンド、関連性を発見し、ビジネスや科学の意思決定を支援する。
説明: ビッグデータは、インターネット検索、金融市場分析、ヘルスケア、科学研究など、多岐にわたる分野で活用されています。
機械学習
特徴: データからパターンを学習し、その学習を基に予測や分類を行う技術。
目的: 手作業によるプログラミングを減らし、データ自体から直接学習することで、自動化と効率化を図る。
説明: 機械学習は、スパムメールのフィルタリングや顔認識、推薦システムなど、日常生活の多くの側面に影響を与えています。
特徴量 (Feature)
特徴: データの入力として使用される、計算可能な属性または特性。
目的: データを効果的に表現し、機械学習モデルの性能を最大化する。
説明: たとえば画像認識では、エッジ、コーナー、色などが特徴量として使われ、画像の内容を数値化します。
ディープラーニング
特徴: 多層のニューラルネットワークを用いて複雑なパターンを学習する機械学習の一分野。
目的: 音声、画像、テキストなどの複雑なデータから高度な特徴を抽出し、より精度の高い予測や分類を行うこと。
説明: ディープラーニングは、自動運転車の視覚システムや、自然言語処理、医療画像分析などに利用されています。
ディープブルー
特徴: IBMによって開発されたチェスプレイングコンピュータ。1997年に世界チェスチャンピオン、ガリー・カスパロフを破ったことで有名です。
これはディーブラーニングを利用していない。
目的: コンピュータの計算能力とAI技術を組み合わせ、人間の専門家を超えるパフォーマンスを実現する。
説明: ディープブルーの勝利は、AIが特定の専門的なタスクにおいて人間を上回る可能性があることを世界に示しました。
ディープブルーは、以下の技術を用いて開発されました。
ミニマックス法: チェス盤上の全ての局面を探索し、最善の手を選択するアルゴリズム
αβ剪定: ミニマックス法の計算量を削減するための技術
評価関数: チェス盤上の局面を評価するための関数
並列処理: 複数のコンピュータを用いて計算を並列化
人工知能をめぐる動向
学習目標:第1次ブームで中心的な役割を果たした推論・探索の研究について学ぶ
学習項目:探索木、ハノイの塔、ロボットの行動計画、ボードゲーム、モンテカルロ法
推論・探索の時代
特徴: AIが論理的な推論や問題解決能力を中心とした時代。主にルールベースのアプローチや探索アルゴリズムが中心でした。
目的: 汎用的な問題解決能力をコンピュータに実装することで、より広範なタスクに対応可能なAIシステムを開発する。
説明: この時代は、AIがチェスやパズル解決などの特定のタスクで人間の能力を模倣または超越することに重点を置いていました。論理的推論やシンボリックAIの進歩が見られ、問題空間を効率的に探索するアルゴリズムが開発されました。
知識の時代
特徴: AI研究が知識表現と知識ベースの推論に焦点を当てた時代。
目的: 特定のドメインに関する専門知識をAIシステムに組み込むことで、より正確かつ効率的な推論を可能にする。
説明: この時期にはエキスパートシステムが広く研究され、開発されました。これらのシステムは特定の領域の専門家の推論プロセスを模倣しようとし、医療診断、金融分析、工学設計などの分野で応用されました。
機械学習と特徴表現学習の時代
特徴: データ駆動型アプローチが主流となり、特徴表現学習が重要視されるようになった時代。
目的: 生データから直接有用な特徴を学習し、より一般化されたAIモデルを構築する。
説明: 機械学習と特にディープラーニングの技術が急速に発展し、画像、音声、テキストなどの複雑なデータから意味のある情報を自動で抽出する能力が向上しました。これにより、AIはより広範囲なタスクとシナリオでの適用が可能となりました。
探索木 (Search Tree)
特徴: 状態空間を階層的に表現したデータ構造。各ノードが状態を、エッジが状態間の遷移を表す。
目的: 可能なすべての状態や行動の系統的な探索を可能にする。
説明: 探索木は、問題の解決策を見つけるための選択肢を段階的に展開し、各段階での選択肢を木の形で視覚化します。これにより、最適な解決策を効率的に探索するための道筋を提供します。
幅優先探索 (Breadth-First Search, BFS)
特徴: 探索木の各レベルを横断的に探索する方法。
目的: 最短経路問題など、最小のステップで目的地に達する解を見つける場合に適用。
説明: 幅優先探索は、探索木のルートから始まり、隣接するすべてのノードを探索し、その後でそれらのノードの隣接ノードへと進みます。これにより、最短経路が保証されます。
深さ優先探索 (Depth-First Search, DFS)
特徴: 探索木をできる限り深く掘り下げる探索手法。
目的: 解が深いレベルに存在する場合に効率的に探索するため。
説明: 深さ優先探索は、一つの枝を可能な限り深く探索し、解を見つけられない場合にバックトラックして別の枝を探します。これはメモリ効率が良いが、最短経路を保証しない。
プランニング (Planning)
特徴: 事前に目標達成のための行動序列を計画するプロセス。
目的: 効率的かつ効果的な行動計画を立てることで、目標を達成する。
説明: プランニングは、与えられた初期状態から目標状態への最適または満足できる経路を生成することに焦点を当てています。これはロボティクスや自動化システム設計で広く用いられます。
STRIPS (Stanford Research Institute Problem Solver)
特徴: アクションの効果を記述する形式言語を使用した初期のプランニングシステム。
目的: 自動プランニングと問題解決能力を機械に提供する。
説明: STRIPSは、特定のアクションが状態にどのように影響を及ぼすかを定義し、これを基にプランを作成します。主に人工知能研究で使用され、その後の多くのプランニングシステムの基盤となりました。
SHRDLU
特徴: テリー・ウィノグラードによって開発された自然言語理解システム。
目的: 自然言語の命令を理解し、仮想世界内で行動を実行する。
説明: SHRDLUは、ユーザーからの単純な英語の命令を解釈し、仮想のブロック世界でブロックを移動するなどのタスクを実行しました。これにより、言語理解と行動計画が組み合わさった初の例となります。
アルファ碁 (AlphaGo)
特徴: DeepMindによって開発された、囲碁のプロプレイヤーに勝利したAIプログラム。
目的: 深層学習とモンテカルロ木探索を組み合わせることで、囲碁という高度に戦略的なゲームで人間を超える。
説明: アルファ碁は、自己対戦による学習と強化学習を用いて囲碁の知識を獲得し、2016年に世界チャンピオンの李セドルを破りました。この成功は、AIが直感とされる領域でも人間を超えうることを示しました。
詳細説明
AlphaGo
AlphaGoは、2016年に世界チャンピオンのイ・セドルに対して勝利し、その名を世界に知らしめました。このモデルは、大量の人間の対局データに基づいて教師あり学習を行い、その後自己対戦による強化学習を通じてさらにスキルを向上させました。モンテカルロ木探索を利用し、実際のゲーム中に最適な手を選択するための複雑な探索アルゴリズムが組み込まれています。
AlphaGo Zero
AlphaGo Zeroは、人間の対局データを一切使用せず、「タブララサ(白紙の状態)」からスタートし、完全に自己対戦のみで学習を進めることで、AlphaGoを超える性能を発揮しました。このアプローチにより、バイアスのない、より創造的で強力なプレイスタイルが生まれ、囲碁の理解に新たな洞察をもたらしました。
AlphaZero
AlphaZeroは、AlphaGo Zeroのアプローチをさらに一般化し、囲碁だけでなくチェスや将棋など他のボードゲームにも適用する能力を持っています。これにより、特定のゲームに依存することなく、一般的なアルゴリズムとして様々なゲームにおいて最高レベルのプレイを実現することが可能になりました。各ゲームでトップクラスの既存のプログラムと比較しても優れた結果を示しました。
ヒューリスティックな知識
特徴: 特定の問題を解決するための経験則や指針。
目的: 探索空間を効率的に絞り込み、計算リソースを節約しながら解を迅速に見つける。
説明: ヒューリスティックな知識は、問題に対する直感的なアプローチや短絡的なルールを利用して、より効果的な探索を実現します。例えば、チェスのプレイで特定の局面で有利な手を優先的に探索します。
Mini-Max 法
特徴: ゼロサムゲームにおいて、最小の損失を最大にする戦略を選択する探索アルゴリズム。
目的: 対戦相手の可能な手を考慮に入れ、最悪のシナリオに対して最適な手を選択する。
説明: ミニマックス法は、特にボードゲームのAIにおいて、自分の手番で最大の利益を、相手の手番では最小の損失を目指す手を選びます。
αβ 法 (Alpha-Beta Pruning)
特徴: ミニマックス法の効率を向上させるために不必要な枝を剪定(プルーニング)する技術。
目的: 探索時間の短縮と効率の向上を図る。
説明: αβ法は、勝敗が確定しているゲームの局面や、他の手より明らかに劣る手は探索から排除します。これにより、処理すべきノードの数が大幅に削減され、より迅速な意思決定が可能になります。
ブルートフォース (Brute Force)
特徴: すべての可能なケースを系統的に試す探索手法。
目的: 確実に最適解を見つけ出すため。
説明: ブルートフォース法は、すべての可能性を一つずつ試すため、計算量が多くなりがちですが、問題のサイズが小さい場合や、他のアルゴリズムが適用困難な場合に有効です。
学習目標:第2次ブームで中心的な役割を果たした知識表現の研究とエキスパートシステムを学ぶ
学習項目:人工無脳、知識ベースの構築とエキスパートシステム、知識獲得のボトルネック(エキスパートシステムの限界)、意味ネットワーク、オントロジー、概念間の関係 (is-a と part-of の関係)、オントロジーの構築、ワトソン、東ロボくん。
イライザ (ELIZA)
特徴: 1960年代に開発された最初のチャットボットの一つで、自然言語処理の技術を使用してユーザーとの会話を模倣します。
目的: コンピュータとの対話が人間の会話と似ているという錯覚(イライザ効果)を利用して、人工知能の対話能力を探究する。
説明: ELIZAは特に「ロジャーシアン心理療法者」としてプログラムされ、ユーザーの質問によっては繰り返しや質問形式で返答し、まるで理解しているかのように振る舞います。
イライザ効果
特徴: 人々が比較的単純なソフトウェアとの対話において、それが実際よりもはるかに高度な理解を持っているかのように感じる心理現象。
目的: この効果を理解することで、人間と機械のインタラクションの設計を改善する。
説明: ELIZAの対話は実際には非常に機械的でありながら、ユーザーが深い感情的な接続を感じることがあります。
マイシン (MYCIN)
特徴: 1970年代に開発された医療診断支援を目的としたエキスパートシステム。
目的: 感染症の診断と抗生物質の選択を支援する。
説明: MYCINは医学的知識ベースを利用して個々の症例に最適な抗生物質療法を推薦し、その推薦の根拠を示すことができます。
DENDRAL
特徴: 化学物質の構造を特定するために開発された最初のエキスパートシステムの一つ。
目的: 科学者が実験データから化合物の構造を導き出す過程を自動化する。
説明: DENDRALは質量分析データを用いて、可能な化学構造の候補を生成し評価します。
インタビューシステム
特徴: ユーザーからの情報を収集し、質問に基づいてさらに情報を導出するシステム。
目的: ユーザーからの情報収集を効率化し、特定の問題に対するソリューションを提供する。
説明: インタビューシステムは、特定の問題に対するユーザーのニーズを明らかにし、適切な情報やサービスを提供します。
オントロジーとは
オントロジーは、特定の領域における概念やエンティティ、それらの間の関係性を形式的に表現するためのフレームワークやモデルです。主に知識表現、情報科学、人工知能などの分野で利用され、複雑なデータ構造を理解しやすく整理するための手段として活用されます。オントロジーを用いることで、データ間の意味的なつながりを明確にし、機械が人間のように情報を理解し処理するのを助けます。
オントロジーの主な特徴
概念の階層構造:
オントロジーは、領域内の概念やエンティティを階層的に整理します。上位概念と下位概念の関係(一般的に「is-a」関係と呼ばれる)を通じて、より具体的な事物から抽象的な事物までカテゴリー分けされます。
関係の定義:
エンティティ間のさまざまな関係を定義することが可能です。これには、所有関係、位置関係、因果関係などが含まれます。
共有可能:
オントロジーは、共通の理解や標準化された知識構造を提供するため、異なるシステムや組織間でのデータ共有と連携を容易にします。
再利用性:
一度作成されたオントロジーは、他のプロジェクトやアプリケーションで再利用することができます。これにより、新たなシステム開発の際の労力と時間を節約することが可能です。
オントロジーとは?
オントロジーは、特定のドメインに関する概念とその間の関係を体系的に記述したものです。具体的には、以下の要素で構成されます。
概念: ドメインにおける基本的な事柄を表します。例えば、「犬」、「猫」、「人間」などの概念が挙げられます。
関係: 概念間の関係を表します。例えば、「犬は哺乳類である」、「猫はペットである」などの関係が挙げられます。
属性: 概念の性質を表します。例えば、「犬は毛皮を持つ」、「猫は夜行性である」などの属性が挙げられます。
オントロジーは、論理学、哲学、計算機科学などの分野で研究されています。
オントロジー研究の目的
オントロジー研究の目的は、以下のとおりです。
知識の共有: オントロジーを使用することで、異なるシステム間で知識を共有することができます。これにより、システム間の連携や協調が可能になります。
推論: オントロジーを使用することで、システムは新しい知識を推論することができます。これにより、システムの知能化が可能になります。
学習: オントロジーを使用することで、システムは新しいデータから学習することができます。これにより、システムの精度向上が可能になります。
オントロジー研究の現状
オントロジー研究は、様々な分野で活発に研究されています。特に、以下の分野で多くの研究が行われています。
人工知能: オントロジーは、AIシステムの知識表現と推論に不可欠な要素です。AIシステムの開発にオントロジーが活用されています。
セマンティックWeb: セマンティックWebは、Web上の情報を意味的に理解できるようにする技術です。オントロジーは、セマンティックWebの基盤となる技術です。
情報検索: オントロジーを使用することで、より高度な情報検索システムを実現することができます。
自然言語処理: オントロジーを使用することで、自然言語処理システムの精度を向上させることができます。
オントロジー研究の展望
オントロジー研究は、今後もますます発展していくことが期待されています。特に、以下の分野での発展が期待されています。
大規模オントロジーの構築: より大規模で複雑なオントロジーを構築することで、より高度な知識表現と推論が可能になります。
マルチドメインオントロジーの構築: 異なるドメインのオントロジーを統合することで、より幅広い知識を扱うことができるようになります。
学習型オントロジーの開発: 新しいデータから自動的に学習できるオントロジーを開発することで、より柔軟で適応性の高い知識表現が可能になります。
オントロジー研究は、AI技術の発展に大きく貢献することが期待されています。今後、オントロジー技術がどのように活用されていくのか、注目されます。
is-a の関係
特徴: オントロジー内で、一つのエンティティ(子)が別のエンテ
ィティ(親)の特殊なインスタンスであるという関係。
目的: 知識の階層構造を構築し、知識の再利用と理解を促進する。
説明: 「カラス is-a 鳥」はカラスが鳥の一種であることを示し、カラスは鳥のすべての特性を継承します。
has-a の関係
特徴: あるオブジェクトが別のオブジェクトを部品や属性として含む関係。
目的: オブジェクト間の組織的関連を表現し、複雑なデータ構造を効率的に管理する。
説明: 「車 has-a エンジン」は車がエンジンを部品として持っていることを表し、車の機能にエンジンが必要であることを示します。
part-of の関係
特徴: オブジェクトが他のオブジェクトの一部であるという関係。
目的: オブジェクト間の物理的または概念的な包含関係を明確にする。
説明: 「指 part-of 手」は、指が手の一部であることを示します。これにより、手の構造や機能に関する知識が整理されます。
Cycプロジェクト
特徴: 広範な一般常識知識を持つエキスパートシステムを構築するためのプロジェクト。
目的: AIが人間のような推論能力を持つために必要な広範な背景知識の提供。
説明: Cycは数百万の事実や規則を含む知識ベースであり、AIが常識的な判断を下すのに役立ちます。
推移律
特徴: 論理的な推論規則で、ある関係が連鎖する場合に適用される。
目的: 推論プロセスにおける正確性と一貫性の確保。
説明: もし「A is-a B」かつ「B is-a C」ならば、「A is-a C」が成立します。これにより、知識の正確な伝播が可能になります。
ウェブマイニング
特徴: ウェブデータから有用な情報を抽出するプロセス。
目的: ウェブ上の膨大なデータからパターンや関連性を発見し、ビジネスインテリジェンスを向上させる。
説明: ウェブマイニングは、ユーザーの行動パターン、リンクの構造、ページの内容などから洞察を得るために用いられます。
データマイニング
特徴: 大量のデータセットからパターンや規則性を発見する技術。
目的: ビッグデータから価値ある情報を抽出し、意思決定を支援する。
説明: データマイニングは、顧客データ、販売履歴、天気データなどから有用な洞察や予測モデルを生成します。
ワトソン
特徴: IBMが開発した質問応答システム。ジェパディ!クイズショーで人間のチャンピオンに勝利しました。
目的: 自然言語処理と機械学習を用いて、複雑な質問に対する正確な回答を生成する。
説明: Watsonは構造化されていないデータから情報を抽出し、特定の問いに対する回答をリアルタイムで提供します。
セマンティック Web
特徴: ウェブデータに意味情報(メタデータ)を追加し、ウェブの読解と利用を自動化するためのフレームワーク。
目的: ウェブ上の情報を機械が解釈可能にし、より効率的な検索、データ連携、知識の再利用を実現する。
説明: セマンティック Webは、リソースに対してRDFやOWLを用いて意味的なタグ付けを行い、情報の検索と統合を改善します。
学習目標:機械学習、ニューラルネットワーク、ディープラーニングの研究と歴史、それぞれの関係について学ぶ
学習項目:データの増加と機械学習、機械学習と統計的自然言語処理、ニューラルネットワーク、ディープラーニング
ビッグデータ
特徴: 非常に大規模で複雑なデータセット。通常、従来のデータベース管理ツールでは処理が困難。
目的: 大量のデータから洞察を得ることで、ビジネスインテリジェンスや科学研究を推進する。
説明: ビッグデータは、ソーシャルメディア、トランザクションレコード、センサーデータなどから集められ、パターン、トレンド、相関関係を分析するのに使用されます。このデータの解析により、より良い意思決定が可能になります。
レコメンデーションエンジン
特徴: ユーザーの過去の行動や好みに基づいて、商品やサービスを推薦するシステム。
目的: 個々のユーザーに合わせたパーソナライズされた体験を提供することで、顧客満足度の向上と販売促進を図る。
説明: レコメンデーションエンジンは、NetflixやAmazonのようなプラットフォームで利用され、ユーザーの視聴履歴や購入履歴から次に楽しむであろう商品や映画を推薦します。
スパムフィルター
特徴: 不要または不適切なメールを自動的に識別し、ユーザーのメールボックスから除外するシステム。
目的: ユーザーのメール体験を向上させ、セキュリティリスクを減らす。
説明: スパムフィルターは、特定のキーワードや送信者の信頼性、過去のユーザーの行動に基づき、スパムメールをフィルタリングします。
統計的自然言語処理
特徴: 言語データから統計的手法を用いて意味を抽出する分野。
目的: テキストや音声データから情報を効率的に理解し、抽出する。
説明: 統計的自然言語処理は、コーパスから学習したモデルを用いて、テキストの意味を解析する。これには、機械翻訳や感情分析などが含まれます。
コーパス
特徴: 特定の言語の使用例を集めたテキスト集。
目的: 言語研究や自然言語処理システムのトレーニングに使用する。
説明: コーパスは、様々な言語の構造や用法を解析するために使われ、言語モデルの構築やテキスト分析の基礎データとして重要です。
コーパスは、大量の言語データの集まりです。このデータは、書籍、論文、ニュース記事、ソーシャルメディア投稿など、様々な形式で存在します。コーパスは、言語学、自然言語処理、人工知能などの分野で広く利用されています。
コーパスの種類
書かれた言語コーパス: 書籍、論文、ニュース記事など、文字で書かれた言語のデータを集めたものです。
音声コーパス: 音声データを集めたものです。会話、講演、インタビューなど、様々な形式の音声データが含まれます。
マルチモーダルコーパス: 音声と映像、または音声とテキストなど、複数の形式のデータを組み合わせたものです。
人間の神経回路
特徴: 人間の脳内で情報を処理するための細胞(ニューロン)のネットワーク。
目的: 人間の学習と思考のプロセスを模倣することで、より自然なAIシステムを開発する。
説明: ニューラルネットワークは、この人間の神経回路に触発されており、多数の接続されたユニット(ニューロンに相当)を用いてデータを処理します。
単純パーセプトロン
特徴: 最も基本的な形のニューラルネットワークで、入力層と出力層のみから構成される。
目的: 単純な分類問題を解くためのモデルを提供する。
説明: パーセプトロンは、入力に重みを掛け、合計がある閾値を超えた場合に1を出力するシンプルなアルゴリズムです。
誤差逆伝播法
特徴: ニューラルネットワークを訓練するためのアルゴリズムで、出力層から入力層へと誤差を逆伝播させて重みを更新します。
目的: ニューラルネットワークの性能を最適化し、正確な予測を可能にする。
説明: 誤差逆伝播法は、ネットワークが予測した結果と実際の結果との差(誤差)を用いて、各層の重みを効率的に調整します。誤差逆伝搬法(Backpropagation)は、ニューラルネットワークを訓練する際に用いられる中心的なアルゴリズムで、ネットワーク内の各重みについて、どのように調整すれば出力層の誤差を最小限に抑えられるかを効率的に計算します。このアルゴリズムは、多層ニューラルネットワークにおいて特に有効で、ディープラーニングの成功には欠かせない技術です。
誤差逆伝搬法のプロセス
フォワードパス
入力データはネットワークの入力層から順に各隠れ層を経由し、最終的に出力層へと伝播されます。
各層でのノード(ニューロン)の出力は、その層の重み、バイアス、活性化関数によって決定されます。
誤差の計算
出力層での予測値と実際の目標値との間に発生する誤差(損失)を計算します。
損失関数(例えば、平均二乗誤差や交差エントロピー損失など)がこの誤差を数値化します。
逆伝搬
誤差を出力層から入力層に向かって逆方向に伝搬させ、各層の重みに対する誤差の影響(勾配)を計算します。
この逆伝搬により、各重みが最終的な誤差にどの程度貢献しているかが明らかになります。
重みの更新
勾配降下法(またはその他の最適化手法)を使用して、計算された勾配に基づいて各重みを更新します。
更新量は学習率と勾配の積で決定され、目的は全体の損失を減少させることです。
誤差逆伝搬法の重要性
効率的な学習: 誤差逆伝搬法は、ネットワーク内の多数のパラメータに対する誤差の効果を効率的に計算し、適切な調整を可能にします。
ディープラーニングの基盤: この手法はディープラーニングモデルの訓練に不可欠であり、画像認識、自然言語処理、強化学習など幅広い応用があります。
進化し続けるアルゴリズム: 誤差逆伝搬法をさらに発展させた最適化手法(例えば、AdamやRMSpropなど)が登場し、より高速かつ効率的な学習が可能になっています。
オートエンコーダ
特徴: 入力を受け取り、それを圧縮してから再構築することを目的としたニューラルネットワーク。
目的: 効果的なデータ圧縮と次元削減を行い、データの重要な特徴を抽出する。
説明: オートエンコーダは、入力データを内部表現にエンコードし、その後で可能な限り元のデータを再構築します。これは、画像や音声データのノイズ除去や異常検出に有用です。
オートエンコーダ (Autoencoder)
特徴: 入力データを再構築することを目的としたニューラルネットワークで、データの圧縮と復元を行う。
目的: データの低次元表現を学習し、データの本質的な特徴を抽出するため。
説明: オートエンコーダはエンコーダ部分でデータを圧縮し、デコーダ部分で元のデータに戻すプロセスを通じて、データの重要な特徴を捉えます。これは次元削減やノイズ除去にも使用されます。
積層オートエンコーダ (Stacked Autoencoder)
特徴: 複数のオートエンコーダを連続して配置し、階層的にデータの抽象的な特徴を学習するニューラルネットワーク。
目的: より複雑なデータ構造を効果的に学習し、ディープラーニングモデルの表現力を高めるため。
説明: 各オートエンコーダの出力が次のオートエンコーダの入力になる構造をしており、階層的に深い特徴を抽出することができます。
積層オートエンコーダとは?
積層オートエンコーダは、オートエンコーダを複数層に重ねたニューラルネットワークアーキテクチャです。
各層のオートエンコーダは、入力データを圧縮し、再構成するタスクを実行します。この過程を通して、モデルはデータの重要な特徴を学習していきます。
積層オートエンコーダの仕組み
積層オートエンコーダは以下の3つの主要な部分から構成されています。エンコーダ: 入力データを圧縮し、潜在表現と呼ばれる低次元の特徴ベクトルに変換します。
潜在層: 潜在表現を保持します。
デコーダ: 潜在表現を入力として、元の入力データを再構成します。
各層のオートエンコーダは、誤差逆伝播法を使用して学習されます。
積層オートエンコーダの利点
積層オートエンコーダには、以下のような利点があります。特徴抽出: 積層オートエンコーダは、データの重要な特徴を自動的に抽出することができます。
次元削減: 積層オートエンコーダは、データを低次元の特徴ベクトルに変換することができます。
ノイズ除去: 積層オートエンコーダは、データからノイズを除去することができます。
前処理: 積層オートエンコーダは、他の深層学習モデルの前処理として使用することができます。
変分オートエンコーダ (Variational Autoencoder, VAE)
特徴: エンコーダとデコーダの2部構造を持ち、入力データから潜在空間へのマッピングとその逆のプロセスを学習する。
目的: 連続的で意味のある潜在空間を構築し、新しいデータを生成する。
説明: VAEはデータの確率分布を学習することで、その分布に従った新しいデータを生成する能力を持ちます。エンコーダはデータから潜在変数へのマッピングを行い、デコーダは潜在変数からデータへの再構築を行います。
VAE: エンコーダーとデコーダーの役割と詳細な説明
VAE(変分オートエンコーダー)は、画像生成や異常検知などに活用される深層生成モデルです。VAEは、エンコーダーとデコーダーという2つのニューラルネットワークで構成されています。
1. エンコーダー
エンコーダーは、入力データ(画像、音声など)を潜在変数と呼ばれる低次元のベクトルに変換する役割を担います。
具体的な動き
入力データを受け取り、畳み込み層や活性化関数などを用いて処理します。
処理を重ねることで、入力データの特徴を抽出し、潜在変数と呼ばれる低次元のベクトルに変換します。
潜在変数は、平均と分散を持つ多変量ガウス分布に従います。
役割
入力データの本質的な特徴を圧縮して表現します。
潜在変数は、入力データを再構成するだけでなく、新たなデータを生成するためにも使用されます。
例
画像の場合:画像の特徴を、色、形状、テクスチャなどの要素に圧縮して表現します。
音声の場合:音声の特徴を、音色、ピッチ、時間情報などの要素に圧縮して表現します。
2. デコーダー
デコーダーは、潜在変数を受け取り、入力データと似たようなデータを復元する役割を担います。
具体的な動き
潜在変数を受け取り、活性化関数などを用いて処理します。
処理を重ねることで、潜在変数から元のデータを再構築します。
出力層では、入力データと同じ形式のデータを出力します。
役割
潜在変数から入力データを忠実に復元します。
復元されたデータは、ノイズが除去されたり、圧縮による劣化が補正されたりします。
例
画像の場合:潜在変数から、色、形状、テクスチャなどの要素を組み合わせて、元の画像を復元します。
音声の場合:潜在変数から、音色、ピッチ、時間情報などを組み合わせて、元の音声を復元します。
3. エンコーダーとデコーダーの関係
エンコーダーとデコーダーは、互いに情報をやり取りしながら学習します。
エンコーダーは、デコーダーが復元しやすい潜在変数を生成することを学習します。
デコーダーは、エンコーダーが生成した潜在変数から、入力データとできるだけ近いデータを再構築することを学習します。
この相互作用を通して、VAEは入力データの本質的な特徴を捉え、新たなデータを生成できるようになります。
4. まとめ
VAEは、エンコーダーとデコーダーの連携によって、データの圧縮と復元だけでなく、新たなデータの生成という強力な機能を実現します。
エンコーダーは、入力データの本質的な特徴を潜在変数に圧縮します。
デコーダーは、潜在変数から入力データと似たようなデータを復元します。
エンコーダーとデコーダーは、互いに情報をやり取りしながら学習し、生成結果の精度を向上させます。
ILSVRC (ImageNet Large Scale Visual Recognition Challenge)
特徴: 大規模な画像データセットを用いた視覚認識コンペティション。
目的: コンピュータビジョンのアルゴリズムの進歩を推進し、画像認識技術の限界を押し広げる。
説明: ILSVRCは、毎年異なるチームが画像認識に関する最新のアプローチを競い合います。特にディープラーニングの進歩がこのコンペティションを通じて大きく進展しました。
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)で注目された代表的なモデルと、それらを開発した大学や企業について、詳細を年代順に以下にまとめます:
AlexNet (2012)
開発元: トロント大学
特徴: AlexNetは、畳み込みニューラルネットワーク(CNN)を用いてILSVRC-2012で優勝し、ディープラーニングのブレイクスルーとされます。ReLU、ドロップアウト、GPUを利用したトレーニングなど、多くの新しい技術を導入しました。
ZFNet (2013)
開発元: ニューヨーク大学
特徴: ZFNetは、AlexNetのアーキテクチャを改良してILSVRC-2013で優勝しました。主に畳み込み層のフィルターサイズとストライドの調整を行い、より詳細なビジュアライゼーションと解析を実現しました。
GoogLeNet (Inception v1) (2014)
開発元: Google
特徴: GoogLeNetは、Inceptionモジュールを用いた革新的なデザインでILSVRC-2014で優勝しました。深さと幅のあるネットワーク設計を採用し、計算効率と精度のバランスを大きく改善しました。
VGGNet (2014)
開発元: オックスフォード大学
特徴: VGGNetは、そのシンプルなアーキテクチャで知られ、ILSVRC-2014で2位に輝きました。最大19層の非常に深いネットワークを使用し、畳み込み層とReLU層を効果的に重ねることで高い認識性能を実現しました。
ResNet (2015)
開発元: マイクロソフト研究所
特徴: ResNetは、152層という当時としては画期的な深さのネットワーク構造を持ち、ILSVRC-2015で優勝しました。残差学習という新しいコンセプトを導入し、深いネットワークでの勾配消失問題を解決しました。
特徴量
特徴: データから抽出された、そのデータの特性や内容を表す数値またはカテゴリー。
目的: データをより扱いやすい形式に変換し、機械学習モデルの学習効率と予測精度を向上させる。
説明: 特徴量は、生のデータを機械学習アルゴリズムが処理しやすい形に変換します。例えば、画像データから色、形、テクスチャなどの属性を抽出します。
次元の呪い
特徴: 高次元データを扱う際に生じる、データポイントが疎になり、各種計算が困難になる現象。
目的: 次元の呪いを理解し、効果的なデータ処理と機械学習モデルの設計を行う。
説明: 高次元空間では、データポイント間の距離が非常に大きくなり、統計的手法が正常に機能しなくなることがあります。これを避けるために次元削減技術が用いられます。
機械学習の定義
特徴: データからパターンを学習し、その学習を通じて新しいデータに対する予測や決定を行う技術。
目的: 人間の介入を最小限に抑え、データから直接知識を抽出することで、自動化と効率化を図る。
説明: 機械学習は、データを分析し、その中の規則性や関連性を見つけ出してモデルを構築し、未見のデータに対して予測や分類を行います。
パターン認識
特徴: データから有意なパターンや構造を識別するプロセス。
目的: 複雑なデータセットから情報を抽出し、意味のある洞察を得る。
説明: パターン認識は、画像、音声、テキストデータなど、さまざまな形式のデータに適用され、特定のパターンや規則性を自動的に認識します。
画像認識
特徴: コンピュータが画像データからオブジェクトやパターンを識別する技術。
目的: 自動化された環境で画像コンテンツを解析し、関連するタスクを実行する。
説明: 画像認識技術は、セキュリティシステムの顔認識から医療画像の分析まで、幅広い応用が可能です。
特徴抽出
特徴: データから最も情報的な属性または特徴を選択または変換するプロセス。
目的: データをより効果的に解析し、処理するために必要な情報を抽出する。
説明: 特徴抽出は、データの次元を減らし、学習アルゴリズムがより効率的に機能するようにします。例えば、画像からエッジやテクスチャを抽出することがこれに該当します。
一般物体認識
特徴: 任意のカテゴリの物体を認識する能力。
目的: 多種多様なオブジェクトを正確に識別し、分類する。
説明: 一般物体認識は、異なる環境や状況下での物体を識別するために重要で、自動運転車やロボット工学で特に重要です。
OCR (Optical Character Recognition)
特徴: 印刷または手書きのテキストをデジタルテキストに変換する技術。
目的: 紙のドキュメントをデジタル形式に変換し、テキストの編集や検索を可能にする。
説明: OCR技術は、スキャンされた書類や写真の中の文字を読み取り、それを編集可能なテキストファイルに変換します。これにより、データ入力の作業が大幅に効率化されます。
学習目標:人工知能の研究で議論されている問題や、人工知能の実現可能性を考察する
学習項目:トイ・プロブレム、フレーム問題、チューリングテスト、強い AI と弱いAI、シンボルグラウンディング問題、身体性、知識獲得のボトルネック、特徴量設計、シンギュラリティ
人工知能分野の問題
学習目標:人工知能の研究で議論されている問題や、人工知能の実現可能性を考察する
学習項目:トイ・プロブレム、フレーム問題、チューリングテスト、強い AI と弱いAI、シンボルグラウンディング問題、身体性、知識獲得のボトルネック、特徴量設計、シンギュラリティ
トイ・プロブレム
特徴: 複雑な問題を単純化したモデル。
目的: 実世界の複雑な問題を理解しやすくするために、単純で解決しやすい問題に変換します。
説明: トイ・プロブレムは、主に研究や学習の文脈で使用され、アルゴリズムや理論をテストしやすくするために設計された単純な問題です。これにより、基本的な原理やアプローチを明確に理解することができます。
フレーム問題
特徴: AIが特定のアクションによる変化のみを識別し、無関係な情報を無視する問題。
目的: AIが環境内でのみ関連する変数を効果的に扱えるようにすること。
説明: フレーム問題は、AIがどの情報がアクションにとって本当に重要かを判断する際の困難さを指します。これは特に、複雑な環境下での意思決定においてAIが直面する課題です。
チューリングテスト
特徴: 人間の判断者が機械と人間との会話を区別できない場合、その機械は知的であると評価される。
目的: AIの知性を評価するための実用的なテストを提供すること。
説明: チューリングテストは、AIが人間と区別がつかないほど自然な会話を行えるかどうかを評価するために、アラン・チューリングによって提案されました。これは、機械が「思考」する能力を持つかどうかを判定する方法として知られています。
強い AI と弱い AI
特徴: 強い AI は人間のような知性を持ち、自我や意識を有する可能性があります。弱い AI は特定のタスクに特化しています。
目的: 強い AI は全般的な問題解決能力を目指し、弱い AI は特定のタスクでの効率化を目指します。
説明: 強い AI は理論上、あらゆる知的活動を人間と同等またはそれ以上にこなすことができるとされています。一方、弱い AI は音声認識や画像認識など、限定されたタスクに優れています。
シンボルグラウンディング問題
特徴: 抽象的なシンボルが具体的な実体や状況とどのように関連づけられるかの問題。
目的: AIがシンボルの背後にある実世界の意味を理解し、適切に行動できるようにすること。
説明: シンボルグラウンディング問題は、AIがただシンボルを処理するだけでなく、それ
らが指し示す実世界の要素を理解する必要があるという課題です。
身体性
特徴: AIやロボットが物理的な体を持つことによる影響。
目的: AIが実世界の物理環境と相互作用し、より効果的に行動すること。
説明: 身体性は、AIが実世界の環境において自身の身体を使ってタスクをこなすことがどのように影響するかを研究する概念です。これは、AIが環境から直接学習し、その身体を通じて世界を「感じる」ことができるという考え方に基づいています。
知識獲得のボトルネック
特徴: AIが新しい知識を獲得する過程で直面する困難。
目的: AIの学習効率を向上させ、より迅速かつ広範囲にわたる知識の獲得を可能にすること。
説明: 知識獲得のボトルネックは、AIが新しい情報を効率的に学習し、既存の知識ベースに統合する際に遭遇する障害を指します。これを克服することが、AIの発展にとって重要です。
特徴量設計
特徴: データから有効な特徴量(特徴ベクトル)を抽出または設計するプロセス。
目的: 機械学習モデルのパフォーマンスを最適化するため。
説明: 特徴量設計は、機械学習においてモデルがデータから学習するための「入力」をどのように準備するかに関わる重要なステップです。適切な特徴量を設計することで、モデルの学習効率と予測精度が向上します。
シンギュラリティ
特徴: 技術的特異点とも呼ばれ、人工知能が人間の知能を超えると予想される未来の時点。
レイ・カーツワイルはシンギュラリティは2045年と主張
2029年は人工知能が人間より賢くなる年目的: この概念は、AI技術の将来的な影響と、それが人類にもたらす可能性のある変革を議論するために用いられます。
説明: シンギュラリティは、AIが自己改善能力を持つようになり、その知能が加速度的に成長する点を指します。この時点を境に、AIは人間の知能を超え、予測不能な変化が起こるとされています。
ローブナーコンテスト
特徴: コンピュータと人間がテキストベースの会話を行うコンペティション。チューリングテストを模倣した形式で実施されます。
目的: プログラムが人間のように会話できるかどうかを評価し、自然言語処理の進歩を推し進める。
説明: ローブナーコンテストでは、ジャッジがコンピュータプログラムと人間との会話を行い、どちらがコンピュータかを識別する試みがなされます。この競技はAIが人間らしい会話能力を持つかどうかを探るための一つの試金石とされています。
中国語の部屋
特徴: ジョン・サールによって提唱された思考実験で、部屋の中の人間が中国語の質問に対して中国語で答えるシステムを示します。
目的: シンボル処理システムが実際に「理解」をしているかどうかについての哲学的問いを投げかける。
説明: 中国語の部屋の実験は、外部から見れば中国語を理解しているように見えるが、実際には単に符号化された指示に従っているだけであるため、真の「理解」は存在しないという問題を提起します。
機械翻訳
特徴: テキストまたは音声を一つの言語から別の言語に自動で翻訳する技術。
目的: 言語の障壁を越えて情報を共有し、国際的なコミュニケーションを容易にする。
説明: 機械翻訳は、グローバル化が進む世界において重要な技術であり、ウェブページや文書、会話などの翻訳に広く用いられています。
ルールベース機械翻訳
特徴: 翻訳のための規則や辞書に依存する翻訳システム。
目的: 正確で文法的に正しい翻訳を生成する。
説明: ルールベースの機械翻訳は、文法や単語の変換規則に基づきテキストを翻訳します。このアプローチは精確さには優れていますが、柔軟性に欠けることがあります。
統計学的機械翻訳
特徴: 大量の二言語テキストコーパスから学習した統計的モデルを使用して翻訳を行うシステム。
目的: コンテキストに基づいた自然で流暢な翻訳を提供する。
説明: 統計学的機械翻訳は、以前の翻訳例から確率的なパターン
を抽出し、これを用いて新たなテキストの翻訳を行います。文脈に強く依存するため、より自然な翻訳が可能ですが、大量の学習データが必要です。
特徴表現学習
特徴: データから自動的に有用な特徴を学習するプロセス。
目的: 手動で特徴を設計する作業を減らし、データの内在する構造をより効果的に捉える。
説明: 特徴表現学習は、特にディープラーニングの文脈で注目され、画像、音声、テキストなどの複雑なデータから、タスクに最適な特徴を自動的に抽出します。これにより、モデルの精度が向上し、より広範なアプリケーションが可能になります。
機械学習の具体的手法
学習目標:教師あり学習に用いられる学習モデルを理解する
学習項目:線形回帰、ロジスティック回帰、ランダムフォレスト、ブースティング、サポートベクターマシン (SVM)、ニューラルネットワーク、自己回帰モデル (AR)
線形回帰
特徴: 連続的な値を予測するために、入力(説明変数)と出力(目的変数)の間の線形関係をモデリングします。
目的: 一つまたは複数の予測変数と目的変数との関係を明らかにし、新しいデータに対する予測を行うこと。
説明: 線形回帰は最も基本的な予測モデルの一つで、データポイント間の直線的な関係を利用して、未知の値を予測します。例えば、家の大きさと価格の関係を予測する際に使われます。
線形回帰における帰無仮説と検定:統計的推論の基礎
線形回帰において、帰無仮説は、説明変数が目的変数に影響を与えていないという仮説です。これは、回帰係数が0であることを意味します。
一方、対立仮説は、説明変数が目的変数に影響を与えているという仮説です。これは、回帰係数が0ではないことを意味します。
第1種の過誤と第2種の過誤: 定義とイメージ
第1種の過誤(α誤差): 帰無仮説が正しいのに、対立仮説を支持してしまう誤り。宝探しで、宝箱が隠されていないのに石ころを宝箱と勘違いしてしまうようなものです。
第2種の過誤(β誤差): 帰無仮説が間違っているのに、帰無仮説を支持してしまう誤り。宝探しで、宝箱が隠されているのに見逃してしまうようなものです。
偽陽性と偽陰性: イメージと関係
偽陽性: 検査結果が陽性なのに、実際には病気ではない状態。宝箱が隠されていないのに、石ころを宝箱と勘違いしてしまう状態と同じです。
偽陰性: 検査結果が陰性なのに、実際には病気にかかっている状態。宝箱が隠されているのに、見逃してしまう状態と同じです。
ロジスティック回帰
特徴: 分類問題に使用され、特に二値分類(はい/いいえの答え)に適しています。
目的: 与えられた入力からカテゴリー出力の確率を予測すること。
説明: ロジスティック回帰は、出力を0と1の間の確率として表現し、特定の閾値(例えば0.5)を超えたら「1」と予測し、下回れば「0」と予測します。このモデルは、メールがスパムかどうかを判断するのに使われることがあります。
対数オッズとは
対数オッズは、イベントが起こる確率と起こらない確率のオッズを対数で表した値です。オッズとは、あるイベントが起こる確率と起こらない確率の比です。
対数オッズは、以下の式で計算されます。
対数オッズ = log(p / (1 - p))
ここで、p: イベントが起こる確率
対数オッズは、以下の特徴があります。
確率が 0 から 1 の範囲にある場合、対数オッズは -∞ から ∞ の範囲にある: 確率が 0 に近いほど、対数オッズは負の値になり、確率が 1 に近いほど、対数オッズは正の値になります。
対数オッズは、確率の変化に対して線形的な関係にある: 確率が 2 倍になると、対数オッズも 2 倍になります。
ランダムフォレスト
特徴: 複数の決定木を組み合わせたアンサンブル学習モデルです。
目的: 個々の決定木の予測を集約することで、全体としての予測精度を向上させること。
説明: ランダムフォレストは、多数の決定木をランダムに生成し、それぞれの木の予測結果を平均化または多数決により最終的な予測を行います。これにより、過学習を防ぎながら精度の高いモデルを作成できます。
ブースティング
特徴: 弱い学習器(単純なモデル)を順番に改善していくアンサンブル技術。
目的: 弱い学習器の予測を改善し、強力な予測モデルを構築すること。
説明: ブースティングは、一連の弱いモデルを徐々に改善していくことで、全体として強い予測力を持つモデルを作成します。各ステップでの誤りを次のモデルの学習に反映させ、徐々に誤差を減らしていきます。
サポートベクターマシン (SVM)
特徴: 高次元空間で最もマージンが大きい境界線を見つけることで、クラスを分割します。
目的: クラス間の明確な境界を確立し、新しいデータ点のクラスを効果的に予測すること。
説明: SVMはデータセットを最適に分割する線や平面(または超平面)を見つけることで、異なるカテゴリーのデータを効果的に分類します。特にマージン(クラス間の距離)が最大となる線を見つけ出すことが特徴です。
ニューラルネットワーク
特徴: 人間の脳のニューロンのネットワークを模倣したモデルで、複数の層から構成されます。
目的: 非常に複雑なパターンを学習し、分類、回帰、特徴抽出など多様なタスクに対応すること。
説明: ニューラルネットワークは、画像認識、音声認識、言語処理など、複雑な問題を解決するために使用されます。深層学習とも呼ばれるこの手法は、多数の隠れ層を通じてデータから高度な特徴を抽出する能力があります。
自己回帰モデル (AR)
特徴: 時系列データにおいて、過去の値を基に未来の値を予渤するモデル。
目的: 過去のデータパターンから未来を予測し、時系列分析における予測精度を向上させること。
説明: 自己回帰モデルは、過去の時点のデータ点(ラグ)に基づいて現在のデータ点を予測します。金融市場の分析や気象予測など、時系列データが豊富な分野で広く使用されています。
分類問題
特徴: カテゴリーに基づいてデータを分類するタイプの問題。
目的: ラベル付きデータを用いてモデルを訓練し、未知のデータに対する正確なカテゴリー予測を行う。
説明: 分類問題では、メールがスパムか非スパムかを判定するなど、データを事前定義されたクラスに分類します。これには、ロジスティック回帰やサポートベクターマシンなどが利用されます。
回帰問題
特徴: 連続値(実数値)を予測するタイプの問題。
目的: ラベル付きデータを基にして、未来の値や連続する数値を予測する。
説明: 回帰問題では、家の価格予測や気温
ラッソ回帰 (Lasso Regression)
特徴: 線形回帰の一種で、L1正則化を使用している。
目的: 重要でない特徴の係数を0に近づけ、モデルの解釈を容易にすること。
説明: ラッソ回帰は、不要な特徴量を削減し、モデルの過学習を防ぐために特に有用です。これにより、よりシンプルで効果的なモデルを作成することができます。
リッジ回帰 (Ridge Regression)
特徴: 線形回帰の一種で、L2正則化を使用している。
目的: 係数の大きさを制限することで過学習を防ぐ。
説明: リッジ回帰は、特に予測変数が多い場合に過学習を防ぐために有効です。これは、係数の大きさにペナルティを課すことで行われます。
決定木 (Decision Tree)
特徴: データを分類または回帰するために、質問を連鎖させるツリー構造のモデル。
目的: 単純明快なルールに基づいてデータを分割し、クラスを予測する。
説明: 決定木は、データをいくつかの質問に基づいて分岐させ、最終的に予測を行います。各質問はノードを形成し、最終的な予測は葉に到達することで行われます。
決定木と情報利得の最大化
決定木は、機械学習における代表的なアルゴリズムの一つであり、分類や回帰などの様々なタスクに利用することができます。
決定木は、データを階層的に分割していくことで、分類や予測を行うモデルです。
決定木を構築する際には、情報利得 を最大化するように分割点を決定することが重要です。
決定木のメリット
決定木は、以下のような多くのメリット を持ちます。
1. わかりやすい解釈性
決定木は、木構造 で表現されるため、論理的な思考過程 を視覚的に理解 しやすいという大きな利点があります。
複雑なモデルでは、なぜそのような結果が出力されるのか を理解するのが難しい場合がありますが、決定木であれば各ノード がどのような条件 でどのように分岐 しているのかを一目瞭然 で確認できます。
2. 高い汎用性
決定木は、分類 や回帰 などの様々なタスクに幅広く適用 できます。
教師あり学習 だけではなく、教師なし学習 にも利用できるため、データの種類 に縛られることなく活用できます。
3. 少ない前処理
決定木は、欠損値 やカテゴリカルデータ などに対しても比較的頑健 であり、データの前処理 に多くの時間を費やす必要がありません。
そのため、データ分析初心者 でも比較的簡単に 導入することができます。
4. 柔軟性の高さ
決定木は、剪定 やアンサンブル などの手法を組み合わせることで、精度 を向上させることができます。
また、新しいデータ が追加された場合にも、容易にモデルを更新 することができます。
5. 頑健性
決定木は、ノイズ や外れ値 に対しても比較的強い という特徴があります。そのため、信頼性の高いモデル を構築することができます。
決定木のデメリット
決定木にも、いくつかのデメリット があります。
1. 過学習
決定木は、データに過剰に適合 してしまう過学習 に陥りやすいという弱点があります。
過学習が発生すると、訓練データ では高い精度を達成できるものの、未知のデータ では精度が低下してしまう可能性があります。
2. 分岐の多さ
決定木は、分岐が多くなるほど モデルが複雑 になり、解釈が難しく なるという問題があります。
また、計算量 も増加するため、学習に時間がかかる というデメリットもあります。
アンサンブル学習 (Ensemble Learning)
特徴: 複数の学習モデルを組み合わせて、一つの最終的な予測モデルを作成する手法。
目的: 個々のモデルよりも優れた予測性能を達成する。
説明: アンサンブル学習は、バギング、ブースティング、スタッキングなどの技法を用いて、複数のモデルからの予測を組み合わせ、より正確な予測を行います。
バギング (Bagging)
特徴: ブートストラップサンプリングを使用して、複数のモデルを訓練し、その結果を平均化するアンサンブル技法。
目的: 分散を減少させ、過学習を防ぐ。
説明: バギングでは、元の訓練データセットからランダムに再サンプリングして複数のサブセットを作成し、それぞれでモデルを訓練します。その後、各モデルの予測を平均化することで最終的な予測を得ます。
勾配ブースティング (Gradient Boosting)
特徴: 弱い予測モデルを順番に改善していくブースティングの一種。
目的: 弱い学習器の予測を反復的に改善し、強い予測モデルを構築する。
説明: 勾配ブースティングは、前のモデルの誤差を次のモデルが修正するように設計されており、各ステップで損失関数の勾配を利用してモデルを更新します。
ブートストラップサンプリング (Bootstrap Sampling)
特徴: 元のデータセットから重複を許してランダムにサンプルを抽出する方法。
目的: データセットのランダムな部分集合を生成し、モデルの堅牢性を評価する。
説明: ブートストラップサンプリングは、特にバギングなどのアンサンブル学習法で用いられ、個々のサンプルが複数回選ばれることがあります。これにより、モデルの一般化能力をテストできます
マージン最大化 (Margin Maximization)
特徴: 分類器が異なるクラス間で最大のマージン(距離)を持つように設計するプロセス。
目的: モデルの汎用性と堅牢性を高め、新しいデータに対しても良好な性能を維持する。
説明: サポートベクターマシン(SVM)はこの原理を使用しており、最も近い訓練データ点(サポートベクター)から最大の距離を持つ決定境界を見つけます。
カーネル (Kernel)
特徴: データの非線形変換を行い、元の特徴空間よりも高次元の特徴空間でデータを表現する関数。
目的: 非線形のパターンを持つデータに対して、より効果的な学習モデルを構築する。
説明: カーネルはSVMなどのアルゴリズムで利用され、複雑なデータ関係をより単純な形で扱うことができるように変換します。
カーネルトリック (Kernel Trick)
特徴: 高次元へのデータの明示的な変換を避けながら、データをより高次元の空間で扱う手法。
目的: 計算の複雑性を増大させることなく、非線形問題を解決する。
説明: カーネルトリックを使用することで、サポートベクターマシンは複雑な非線形分類問題を、元の空間で線形分類問題として扱うことが可能になります。
単純パーセプトロン (Simple Perceptron)
特徴: 最も基本的な形のニューラルネットワークで、一層の前方向のみのフィードを持つ。
目的: 線形分類問題を解くためのモデルを提供する。
説明: 単純パーセプトロンは入力を受け取り、それに重みを掛け、合計値が閾値を超えるかどうかに基づいて出力します。
多層パーセプトロン (Multilayer Perceptron, MLP)
特徴: 複数の層を持ち、少なくとも一つの隠れ層が含まれるニューラルネットワーク。
目的: より複雑なパターンを識別できるようにモデルの能力を向上させる。
説明: MLPは、非線形活性化関数を使用しているため、単純パーセプトロンよりも複雑な問題を解くことが可能です。
活性化関数 (Activation Function)
特徴: ニューラルネットワークの各ノード(ニューロン)で使用される、入力信号の合計を出力信号に変換する関数。
目的: ネットワークに非線形性を導入し、より複雑な関数の近似を可能にする。
説明: 活性化関数には、シグモイド関数、ReLU関数、ソフトマックス関数などがあり、それぞれが異なる特性を持ち、用途に応じて選択されます。
非線形活性化関数
ネットワークに非線形性を導入し、複雑な関数を学習可能にする。非線形活性化関数はさらに以下のように細分化できる。
※非線形な関数を用いられるのは線形ではネットワークを多層にする意味がない
飽和型活性化関数
特性: 出力がある範囲内に限定される(飽和する)。勾配消失問題の原因になることがあるが、出力の正規化に役立つ。
例: Sigmoid, Tanh, Softmax
非飽和型活性化関数
特性: ある条件下で出力が飽和しない。これにより、勾配消失問題を軽減できる。
例: ReLU, Leaky ReLU, Parametric ReLU (PReLU), ELU
適応型活性化関数
特性: パラメータを持ち、学習プロセス中にこれらのパラメータが調整される。
例: Parametric ReLU (PReLU), ELU (ある意味で適応的), GELU
高度な非線形活性化関数
特性: 複雑な計算を行い、モデルの学習能力を向上させることができる。しばしば特定の問題に特化している。
例: Swish, GELU
シグモイド関数 (Sigmoid Function)
特徴: S字型の曲線を描く活性化関数。
目的: 出力を0から1の間に制限し、確率として解釈できるようにする。
説明: シグモイド関数は、特に二値分類問題の出力層で使用され、出力を確率として解釈することができます。
ソフトマックス関数 (Softmax Function)
特徴: 各クラスに対する確率を計算するために使用される活性化関数。
目的: 多クラス分類問題の出力層で、それぞれのクラスに属する確率を出力する。
説明: ソフトマックス関数は、ネットワークの最後の層で使用され、各クラスに対する相対的な確率スコアを提供します。
誤差逆伝播法 (Backpropagation)
特徴: ニューラルネットワークを訓練するためのアルゴリズムで、出力誤差を元に各重みを効率的に調整する。
目的: ネットワークの予測誤差を最小化し、正確なモデルを構築する。
説明: 誤差逆伝播法は、ネットワークの出力と期待される出力との間の誤差を計算し、この誤差をネットワークの層を逆方向に伝播させながら各ニューロンの重みを更新します。これにより、ネットワーク全体のパフォーマンスが向上します。
ベクトル自己回帰モデル (VARモデル)
特徴: 複数の時系列データ間の線形関係をモデリングするための統計モデル。
目的: 複数の変数の動的な関係を捉え、将来の値を予測する。
説明: VARモデルは、各変数が他の変数の過去の値にどのように依存しているかを表し、経済学、金融などの分野で広く使用されています。これにより、システム内の全変数の相互作用を同時に分析することが可能です。
隠れ層 (Hidden Layer)
特徴: 入力層と出力層の間にあるニューラルネットワークの層。
目的: データのより抽象的な特徴を学習し、モデルの表現力を向上させる。
説明: 隠れ層はネットワークが複雑なパターンや非線形の関係を学習するのに不可欠で、その数やサイズはモデルの複雑性や学習能力を決定します。
疑似相関 (Spurious Correlation)
特徴: 統計的には相関が認められるものの、実際には因果関係が存在しない関係。
目的: データ分析の際に誤解を避け、より信頼性の高い結論を導く。
説明: 疑似相関は、たまたまの一致や共通の原因によって生じることがあり、データ科学者はこのような誤った相関に基づく結論を避けるために注意が必要です。
重回帰分析 (Multiple Regression Analysis)
特徴: 複数の説明変数を用いて一つの従属変数を予測する統計手法。
目的: 複数の要因が従属変数にどのように影響を与えるかを同時に評価する。
説明: 重回帰分析は、各説明変数の効果を分離して量定することができ、ビジネス、経済学、生物学など多岐にわたる分野で用いられます。
AdaBoost
特徴: 弱い学習器を順番に改良しながら組み合わせ、強い学習器を作成するブースティングアルゴリズム。
目的: 分類器の性能を段階的に向上させる。
説明: AdaBoostは、誤分類されたインスタンスに次第に重みを加えていくことで、学習過程でこれらにより注目し、分類精度を高めます。
多クラス分類 (Multiclass Classification)
特徴: 二つ以上のクラスにデータを分類する問題。
目的: より複雑な分類問題に対応し、多様なカテゴリーを識別する。
説明: 多クラス分類は、例えば動物の画像を犬、猫、鳥といった複数のカテゴリに分類する際に使用されます。この問題は、ソフトマックス関数を使用して解決することが一般的です。
プルーニング (Pruning)
特徴: 決定木などのモデルの成長を制限し、過学習を防ぐために枝を剪定するプロセス。
目的: モデルの汎用性を向上させる。
説明: プルーニングは、特に決定木で有効で、ノードの追加がモデルの性能向上に寄与しない場合にその部分を削除します。これにより、モデルはより一般化され、新しいデータに対しても強い性能を発揮します。
学習目標:教師なし学習の基本的な理論を理解する
学習項目:k-means 法、ウォード法、主成分分析 (PCA)、協調フィルタリング、トピックモデル
クラスタリング
特徴: データを類似性に基づいてグループに分けるプロセス。
目的: 類似の特性を持つデータポイントを同じグループに分類し、データの構造を明確にする。
説明: クラスタリングは、データを複数のクラスタに自動的に分けることで、データセット内の自然なグルーピングやパターンを発見するのに役立ちます。例えば、顧客データから類似の購買行動を示す顧客グループを識別することができます。
Q1. クラスタリングとは何か簡単に説明してください。 A1. クラスタリングとは、与えられたデータ集合を、そのデータ間の類似性に基づいて複数のグループ(クラスタ)に分割する手法のことです。同じクラスタ内のデータは類似性が高く、異なるクラスタ間ではデータは異なる性質を持つように分割されます。
Q2. クラスタリング手法の代表的なアルゴリズムを2つ挙げてください。 A2. 代表的なクラスタリング手法には、k-means法と階層的クラスタリング法があります。k-means法は事前にクラスタ数kを指定し、それぞれのデータを最も近いクラスタに割り当てていきます。階層的クラスタリングは、デンドログラムと呼ばれる木構造を構築し、任意の高さでクラスタを分割します。
Q3. クラスタリングの目的は何か、2つ挙げてください。 A3. 1つ目はデータの可視化と解釈が容易になることです。大量のデータを少数のクラスタに分割することで、データの背後にある構造をつかみやすくなります。2つ目は、将来のデータに対する予測や分類が容易になることです。学習済みのクラスタリングモデルに新しいデータを入力すれば、そのデータがどのクラスタに属するかを判断できます。
Q4. クラスタリングの評価指標としてよく使われるものを答えてください。 A4. クラスタリングの評価指標としてよく使われるのは、手法内分散(Within-Cluster Sum of Squares)です。これは各クラスタ内のデータ点間の距離の総和を小さくすることで、クラスタ内の凝集度を最大化します。また、手法間分散(Between-Cluster Sum of Squares)は、クラスタ間の距離を最大化するための指標です。
Q5. クラスタリングの利用例を2つ挙げてください。 A5. クラスタリングの利用例としては、マーケティングにおける顧客セグメンテーションがあげられます。顧客データをクラスタリングすることで、類似した嗜好や行動パターンを持つ顧客グループを発見できます。また、金融分野においては、不正検知のためにクレジットカード利用履歴をクラスタリングし、異常なパターンを検出する例があります。
クラスタ分析
特徴: データセットを意味のあるクラスタに分割し、分析するプロセス。
目的: データ内の自然なグループを同定し、データの理解を深める。
説明: クラスタ分析はマーケティング、生物学、社会科学など多岐にわたる分野で利用され、データの特徴や構造を把握するのに役立ちます。
レコメンデーション
特徴: ユーザーの好みや行動に基づいて製品やサービスを提案するプロセス。
目的: ユーザー体験を個人化し、関連性の高いアイテムを推薦する。
説明: レコメンデーションシステムは、オンラインショッピングや映画の推薦などに利用され、ユーザーの以前の行動や評価から新しいアイテムを推薦します。
デンドログラム (樹形図)
特徴: ヒエラルキカルクラスタリングの結果を表す樹形図。
目的: クラスタ間の関係性や距離を視覚的に表現し、データの階層的な構造を理解する。
説明: デンドログラムは、各クラスタがどのように組み合わさり、最終的に単一のクラスタになるかを示します。これにより、データセットの詳細な洞察が可能になります。
デンドログラムが利用されるクラスタリング手法:群平均法
デンドログラムは、階層型クラスタリング手法において、データの類似性に基づいてグループ化していく過程を可視化するために利用されます。
群平均法は、階層型クラスタリング手法の一つであり、以下の手順でクラスタリングを行います。
初期化: 最初に、すべてのデータを個別のクラスタに割り当てます。
クラスタ間の距離計算: 次に、すべてのクラスタ間の距離を計算します。距離計算には、様々な方法がありますが、群平均法ではユークリッド距離を用いるのが一般的です。
最小距離のクラスタ結合: 最も近い2つのクラスタを結合します。このとき、結合される2つのクラスタ間の距離を新しいクラスタの中心距離とします。
2.と3.を繰り返す: 2.と3.の手順を、すべてのデータが一つのクラスタになるまで繰り返します。
デンドログラムは、この群平均法におけるクラスタ結合の過程を図示したものです。デンドログラムには、以下の情報が示されます。
横軸: データのIDまたはクラスタのID
縦軸: クラスタの中心距離
水平線: クラスタ結合のタイミング
図1は、群平均法で生成されたデンドログラムの例です。
[図1: 群平均法によるデンドログラムの例]
このデンドログラムから、以下のことが読み取れます。
データは4つのクラスタに分類されている
クラスタ1とクラスタ2は最も類似しており、最初に結合された
クラスタ3とクラスタ4は次に類似しており、その後結合された
デンドログラムは、以下の目的で使用されます。
クラスタリング結果の可視化: クラスタリング結果を視覚的に確認するために用いられます。
最適なクラスタ数の決定: デンドログラムの形状から、最適なクラスタ数を判断するために用いられます。
異常値の検出: デンドログラムから、異常値とみられるデータ点を検出するために用いられます。
群平均法におけるデンドログラムは、以下の点に注意する必要があります。
距離計算方法: 距離計算方法によって、デンドログラムの形状が変化することがあります。
リンク距離: デンドログラムの横軸に表示される距離は、リンク距離と呼ばれるものであり、クラスタ間の距離とは異なります。
解釈: デンドログラムはあくまでも可視化ツールであり、クラスタリング結果を解釈する際には、他の情報も考慮する必要があります。
まとめ
デンドログラムは、群平均法をはじめとする階層型クラスタリング手法において、クラスタリング結果を理解し、分析するために役立つツールです。デンドログラムを活用することで、データの構造や異常値などをより深く理解することができます。
特異値分解 (SVD)
特徴: マトリックスを特異ベクトルと特異値の積に分解する線形代数の手法。
目的: データの本質的な特性を抽出し、次元削減を行う。
説明: SVDはデータ圧縮、ノイズリダクション、レコメンデーションシステムなどで使用され、効率的なデータ表現を提供します。
多次元尺度構成法 (Multidimensional Scaling, MDS)
特徴: 高次元データを低次元空間に表現し、元の距離関係を保持するように配置する手法。
目的: データ間の相対的な距離を保持しながら視覚化し、データのパターンを理解しやすくする。
説明: MDSは、類似性や距離が重要な分析で利用され、複雑なデータ関係を直感的に解釈するのに役立ちます。
多次元尺度構成法の概要
MDSは、対象間の類似性や相違性のデータから、それらの対象を低次元の空間上に配置する手法です。
対象間の距離が近いほど、それらの対象が類似していると判断できます。
対象を低次元の空間上に配置することで、対象間の関係性を視覚的に把握できるようになります。
MDSの特徴
定量的なデータ(メトリックMDS)や順序データ(ノンメトリックMDS)を扱うことができます。前者を量的データ、後者は質的データとして扱う。
対象間の類似性や相違性を数値化したデータを入力として使用します。
出力される配置図では、類似した対象が近くに、異なる対象が離れて表示されます。
MDSの応用
市場調査: 商品やブランドの位置づけを把握するために使用されます。
心理学: 人の認知構造を分析するのに活用されます。
情報可視化: 高次元データを低次元の空間に表現できるため、データの構造を視覚的に理解できます。
MDSの手順
対象間の類似性や相違性のデータを収集する
MDSアルゴリズムを使って、低次元の空間上に対象を配置する
配置図を分析し、対象間の関係性を解釈する
MDSは、多変量解析の手法の1つで、主成分分析と同様に分類対象物の関係を低次元空間に表現することができます。
多次元尺度構成法
多次元尺度構成法(Multidimensional Scaling、MDS)は、アイテム間の類似性または距離データを基にして、それらアイテムを低次元の空間(通常は2次元または3次元)に配置する統計手法です。この方法は、複雑な類似性関係を視覚的に表現するために使用され、心理学、マーケティング、社会科学、生物学など様々な分野で応用されています。
基本原理
MDSの目的は、アイテム間の距離または類似性を可能な限り忠実に空間に表現することです。具体的には、各アイテムを点として空間に配置し、与えられた距離データと空間内の点同士のユークリッド距離が一致するようにします。このプロセスは、アイテム間の距離の構造を解釈しやすくするために、高次元の関係性を低次元で表現します。
手順
距離行列の作成: 全てのアイテムペアの間の距離または類似性を測定し、それを距離行列としてまとめます。距離は直接測定するか、類似性スコアから変換して導出します。
初期配置: アイテムをランダムまたはある程度の仮定に基づいて空間に初期配置します。
ストレス関数の最小化: 空間内の点同士の距離が、元の距離行列に記載されている距離とできるだけ一致するように、配置を調整します。このために一般的には「ストレス関数」と呼ばれる目的関数を最小化することで、配置を反復的に調整します。
解の解釈: 結果の空間配置を解析し、アイテム間の関係を解釈します。この配置から、アイテム群のクラスタリングやパターンの特定が可能になります。
種類
計量(古典的)MDS(Metric MDS): 元の距離行列が正確な距離を表している場合に使用され、距離の二乗行列に基づく固有値分解を用いて解を求めます。
非計量MDS(Non-metric MDS): 距離行列が厳密な距離ではなく、順序尺度などの類似度のランキング情報のみを含む場合に使用されます。ここでは、距離の順序を保持するように配置を求めるため、距離の正確な値よりもその相対的な大小が重視されます。
メリット
複雑なデータの構造を直感的に可視化できる。
アイテム間の類似性やクラスタを容易に把握できる。
デメリット
計算コストが高い場合がある。
結果の解釈が主観的になる可能性がある。
初期値の選択や解の多様性により、異なる解が得られることがあります。
t-SNE (t-Distributed Stochastic Neighbor Embedding)
特徴: 高次元データを低次元で表現するための統計的手法。
目的: 高次元データのクラスタリングやパターンを低次元で視覚的に表現する。
説明: t-SNEは特にデータサイエンスで人気があり、類似したデータポイントが低次元で密集して表示されるようにデータをマッピングします。
コールドスタート問題
特徴: 新しいユーザーやアイテムに対して十分なデータがないためにレコメンデーションが困難になる問題。
目的: レコメンデーションシステムの効果を初期段階から高める。
説明: コールドスタート問題は、特に新規ユーザーや新商品の場合に顕著であり、過去のデータに基づく推薦ができないために起こります。
コンテンツベースフィルタリング
特徴: ユーザーが過去に好んだアイテムの内容(コンテンツ)を分析し、類似のアイテムを推薦する手法。
目的: ユーザーの個別の好みに合わせたパーソナライズされた推薦を提供する。
説明: コンテンツベースフィルタリングは、アイテム自体の特徴(例えば映画のジャンルやキャスト)を利用して推薦を行い、ユーザーの個々の嗜好に応じたアイテムを提示します。
潜在的ディリクレ配分法 (Latent Dirichlet Allocation, LDA)
特徴: トピックモデルの一種で、文書を複数のトピックの混合としてモデル化する。
目的: 大量のテキストデータから潜在的なトピックを抽出し、文書の構造を理解する。
説明: LDAは文書集合からトピックを学習し、各文書がどのトピックにどれだけ関連しているかを推定します。これにより、文書の主要なテーマを把握できます。
Latent Dirichlet Allocation (LDA) は、自然言語処理およびテキストマイニングにおいて広く使用される統計的なトピックモデルです。LDAは2003年にDavid M. Blei、Andrew Y. Ng、およびMichael I. Jordanによって導入されました。このモデルは文書内に存在する隠れたトピック(テーマ)を発見することを目的としています。以下に、LDAの基本的な仕組み、プロセス、およびその特徴について詳しく説明します。
LDAの基本概念
LDAは、各文書が複数のトピックから生成されるという生成モデルです。文書集合を通じて共通のトピックを識別し、それぞれの文書がどのトピックにどれだけ関連しているかを示します。LDAは以下のような基本的な仮定に基づいています:
トピックは単語の分布:各トピックは特定の単語が出現する確率分布として表されます。
文書はトピックの混合:各文書は一つ以上のトピックの混合であり、それぞれのトピックは文書内の一定の割合を占めます。
LDAのプロセス
LDAの処理プロセスは、以下のステップに大別されます:
パラメータの設定:トピックの数 𝐾K を設定します。これはモデルによって識別されるトピックの総数です。
ディリクレ分布の割り当て:文書におけるトピックの分布と各トピックにおける単語の分布にディリクレ分布を使用します。これにより、文書とトピック、トピックと単語の関係が確率的にモデリングされます。
ランダム初期化:最初に、文書の各単語にランダムにトピックを割り当てます。
反復アルゴリズムの適用:ギブスサンプリングや変分ベイズ推論などのアルゴリズムを用いて、各単語のトピック割り当てを最適化します。この過程で、文書内の他の単語のトピック割り当てや他の文書のトピック分布を考慮し、反復的に更新を行います。
LDAの特徴と応用
トピックの解釈性:LDAはトピックを単語の確率分布としてモデル化するため、生成されたトピックは人間が解釈可能です。
非監視学習:LDAはラベルのないテキストデータからトピックを学習するため、非監視学習の一形態です。
多様な応用:LDAはニュース記事、科学論文、顧客レビューなど、さまざまな種類のテキストデータに適用可能です。文書分類、情報検索、コンテンツ推薦など、多岐にわたる分野で利用されています。
LDAは、文書の隠れたトピック構造を理解するのに強力なツールであり、テキストデータの潜在的な意味構造を解明するために広く使われています。
次元削減
特徴: データセットの特徴量の数を減少させるプロセス。
目的: データの本質的な情報を保持しつつ、計算負担を軽減し、データの可視化を容易にする。
説明: 次元削減は、PCAやt-SNEなどの技術を使用して高次元データの複雑さを低減し、データ解析の効率を向上させます。
次元圧縮
特徴: データの情報をできるだけ保ちながら、データの表現をより少ない量で表す技術。
目的: ストレージ要件の削減と計算効率の向上。
説明: 次元圧縮は、データの重要な特性を保持しながら、不要な情報を取り除くことでデータのサイズを小さくします。特異値分解 (SVD) がこの目的でよく使用されます。
次元圧縮手法の種類と詳細
次元圧縮は、高次元データを低次元空間に射影することで、データ量を削減し、処理速度を向上させる手法です。様々な手法が存在し、それぞれの特徴と利点・欠点があります。以下では、代表的な次元圧縮手法をいくつか詳しく説明します。
1. 主成分分析 (PCA)
主成分分析 (PCA) は、線形変換を用いた次元圧縮手法であり、最も広く用いられている手法の一つです。データの分散を最大化するような方向ベクトルを基底として、低次元空間に射影します。
PCAの利点
計算効率が高い *解釈しやすい
多くの場合、効果的に次元圧縮できる
PCAの欠点
非線形な関係性を考慮できない
すべての情報を保持できない
PCAの適用例
画像圧縮
音声圧縮
テキストマイニング
異常検知
2. 線形判別分析 (LDA)
線形判別分析 (LDA) は、分類問題に特化した線形変換を用いた次元圧縮手法です。複数のクラス間の判別性を最大化するような方向ベクトルを基底として、低次元空間に射影します。
LDAの利点
分類精度を向上させることができる
LDAの欠点
クラス間の分布が正規分布に従っている必要がある
PCAよりも計算コストが高い
LDAの適用例
顔認識
スパムフィルタリング
医療診断
3. 多重スケールエンコーダ・デコーダ (MSAED)
多重スケールエンコーダ・デコーダ (MSAED) は、畳み込みニューラルネットワークを用いた非線形変換による次元圧縮手法です。入力データを複数のスケールでエンコーダに入力し、デコーダで低次元空間に再構成します。
MSAEDの利点
非線形な関係性を考慮できる
PCAよりも高い精度で次元圧縮できる
MSAEDの欠点
PCAよりも計算コストが高い
学習データが必要
MSAEDの適用例
画像圧縮
音声圧縮
自然言語処理
4. t-SNE
t-SNE は、確率的な手法を用いた非線形変換による次元圧縮手法です。高次元空間と低次元空間におけるデータ点間の距離を保ちながら、低次元空間に射影します。
t-SNEの利点
高次元データの可視化に有効
t-SNEの欠点
計算コストが高い
収束に時間がかかる
t-SNEの適用例
高次元データの可視化
異常検知
5. UMAP
UMAP は、t-SNEと同様に、確率的な手法を用いた非線形変換による次元圧縮手法です。t-SNEよりも計算効率が高く、より高精度な次元圧縮が可能であると言われています。
UMAPの利点
t-SNEよりも計算効率が高い
t-SNEよりも高精度な次元圧縮が可能
UMAPの欠点
t-SNEと同様に、収束に時間がかかる
UMAPの適用例
高次元データの可視化
異常検知
その他の次元圧縮手法
上記以外にも、様々な次元圧縮手法が存在します。代表的なものとして、以下のようなものがあります。
独立成分分析 (ICA)
非負値行列因子分解 (NMF)
特異値分解 (SVD)
カーネルPCA (KPCA)
スパースコーディング
それぞれの次元圧縮手法は、異なる特徴と利点・欠点を持っています。最適な手法は、データの種類や目的によって異なります。
次元圧縮手法の選び方
次元圧縮手法を選ぶ際には、以下の点を考慮する必要があります。
データの種類: 画像データ、音声データ、テキストデータなど、データの種類によって適した手法が異なります。
目的: 次元圧縮を行う目的によって、適した手法が異なります。例えば、データ量を削減したい場合はPCAが適していますが、分類精度を向上させたい場合はLDAが適しています。
計算コスト: 計算コストの高い手法は、大規模なデータセットには適していません。
解釈性: 解釈しやすい手法は、結果の理解が容易になります。
学習目標:強化学習の基本的な理論を理解する 学習項目:バンディットアルゴリズム、マルコフ決定過程モデル、価値関数、方策勾配
強化学習の学習:詳細解説
強化学習は、エージェントと呼ばれる主体が、試行錯誤を通じて最適な行動を学習していく機械学習の一種です。従来の教師あり学習とは異なり、正解データを与えられるのではなく、報酬と呼ばれる評価指標のみを与えられ、自律的に学習していく点が特徴です。
強化学習の学習プロセスは、以下の3つのステップで構成されます。
1. 環境とのインタラクション
エージェントは、環境と相互作用することで、状態と報酬の情報を得ます。
環境は、エージェントの行動に応じて、状態を変化させ、報酬を与えます。
例:ロボット掃除機が部屋を掃除する、ゲームでキャラクターを操作する
2. 方策の更新
エージェントは、得られた状態と報酬の情報に基づいて、方策と呼ばれる行動選択確率を更新します。
方策は、状態における各行動を選択する確率を表します。
方策は、経験に基づいて改善されていきます。
例:ロボット掃除機が汚れている場所を掃除する確率を高める、ゲームで勝率の高い行動を選択する確率を高める
3. 繰り返し
エージェントは、1と2を繰り返し行うことで、最適な行動を学習していきます。
経験を積み重ねることで、方策が改善され、より多くの報酬を得られるようになります。
例:ロボット掃除機が部屋を効率的に掃除できるようになる、ゲームでより高いスコアを獲得できるようになる
強化学習の学習アルゴリズム
強化学習には、様々な学習アルゴリズムが存在します。代表的なアルゴリズムは以下の通りです。
Q学習: 現在の状態における各行動の期待報酬を学習し、最大期待報酬に基づいて行動を選択します。
SARSA: 現在の状態と次の状態における行動のペアの期待報酬を学習し、最大期待報酬に基づいて行動を選択します。
Policy Gradient法: 方策のパラメータを直接更新することで、報酬を最大化する方策を学習します。
強化学習: 従来の機械学習との違いを解き明かす
強化学習は、人工知能の一分野であり、試行錯誤を通じて最適な行動を学習する手法です。まるで、ゲームのキャラクターが経験を積み重ねて最強の攻略方法を身につけるように、自律的に学習していくイメージです。
従来の機械学習との主な違いは以下の3点です。
1. 学習方法の違い
従来の機械学習: 大量の教師データ(正解ラベル付きデータ)を与えられ、教師あり学習と呼ばれる方法で学習します。
強化学習: 教師データは不要で、報酬と呼ばれる評価指標のみを与えられ、試行錯誤を通じて最適な行動を学習します。
2. 目標の違い
従来の機械学習: 特定のタスク(画像分類、音声認識など)を高精度に実行することを目標とします。
強化学習: 長期的な報酬を最大化することを目標とします。これは、ゲームで高得点を獲得したり、ロボットが自律的に目標地点に到達したりすることに例えられます。
3. 応用分野の違い
従来の機械学習: 画像認識、音声認識、自然言語処理など、データ分析に適した分野で広く利用されています。
強化学習: ゲーム、ロボット制御、自動運転、電力制御など、複雑な環境で最適な行動を決定することが求められる分野で注目されています。
強化学習は、自律的な学習と長期的な報酬という2つの特徴により、従来の機械学習では対応が難しかった複雑な問題を解決する可能性を秘めています。
マルコフ決定過程 (MDP) の要素:詳細解説
マルコフ決定過程 (MDP)は、強化学習における重要な概念であり、エージェントと環境の相互作用を確率的なモデルで表現します。MDPは、以下の5つの要素で構成されます。
1. 状態 (S)
エージェントが環境に置かれている状況を表します。
時間によって変化し、有限個または無限個の状態が存在します。
例:ロボットの位置、ゲームの盤面、株式市場の状態
2. 行動 (A)
エージェントが環境に対して取ることのできる行動を表します。
有限個または無限個の行動が存在します。
例:ロボットの移動方向、ゲームにおけるアクション、株式の売買
3. 状態遷移確率 (P)
ある状態である行動を取ったとき、次の状態に遷移する確率を表します。
P(s'|s, a) で表され、0 ≦ P(s'|s, a) ≦ 1 を満たします。
例:ロボットが上方向に移動しようとしたとき、実際に上方向に移動する確率
4. 報酬 (R)
エージェントがある状態に遷移したとき、またはある行動を取ったときに得られる報酬を表します。
数値で表され、正の報酬 (好ましい状態) と負の報酬 (好ましくない状態) があります。
例:ロボットが目標地点に到達したとき得られる報酬、ゲームでポイントを獲得したとき得られる報酬
5. 報酬関数 (R)
状態と行動の組み合わせに対して、期待される報酬を定義する関数です。
R(s, a) で表されます。
エージェントの目標を定量的に表現します。
例:ロボットが特定の状態に滞在したとき得られる報酬、ゲームで特定のアクションを取ったとき得られる報酬
MDPの例:ロボット掃除機
ロボット掃除機を例に、MDPの要素を説明します。
状態 (S): ロボット掃除機の現在位置と部屋の状態 (汚れている/綺麗)
行動 (A): 前進、後退、左旋回、右旋回
状態遷移確率 (P): ロボット掃除機の行動と部屋の状態に基づいて、次の状態が決定される確率
報酬 (R): ロボット掃除機が汚れている場所を掃除したとき、正の報酬。ロボット掃除機が壁にぶつかったとき、負の報酬
報酬関数 (R): ロボット掃除機が掃除した場所の割合に基づいて、報酬を計算
MDPの重要性
MDPは、強化学習における基本的なフレームワークであり、以下の理由で重要です。
エージェントと環境の相互作用を確率的にモデル化できる
様々な強化学習アルゴリズムの基礎となる
問題を状態**、行動、報酬というシンプルな要素に分解できる。
バンディットアルゴリズム(Bandit Algorithms)
バンディットアルゴリズムは、強化学習の一形態で、特に「マルチアームドバンディット問題」に対する解決策を提供します。この問題では、複数の選択肢(「アーム」と呼ばれる)から一つを選び、それに応じた報酬を受け取ることができます。各アームがもたらす報酬の分布は未知であり、アルゴリズムの目的は、限られた試行回数の中で最大の報酬を獲得することです。
主な特徴
単純な意思決定: バンディットアルゴリズムは、一連の選択肢の中から最も良い選択を迅速に見つけることに焦点を当てています。各選択は独立しており、前の選択からの複雑な状態遷移は考慮しません。
探索と活用のトレードオフ: バンディット問題の核心は、既知の選択肢から最大の報酬を得る(活用)か、未知の選択肢を試して将来的な報酬を最大化するか(探索)の間のバランスを見つけることです。
主なバンディットアルゴリズム
ε-greedyアルゴリズム
定期的にランダムな選択を行い(探索)、それ以外の時はこれまでに最も高い報酬を与えた選択を行います(活用)。
UCB(Upper Confidence Bound)
各アームの報酬の推定値とその不確実性を考慮し、それに基づいてアームを選択します。不確実性が高いアームは報酬の潜在能力が高いと考えられるため、探索の機会が与えられます。
トンプソン・サンプリング
ベイジアンアプローチを使用して、各アームの報酬分布の確率モデルを更新し、その分布からサンプリングしてアームを選択します。この方法は、確率的に探索と活用のバランスを取ります。
応用例
広告の最適化: ウェブサイトにおいてどの広告が最もクリックされるかを試行錯誤しながら学習し、最終的には最も効果的な広告を表示します。
推薦システム: ユーザーに最適な推薦を行うために、異なる推薦アイテムの中から最も反応が良いものを特定します。
臨床試験: 新しい医薬品の効果を試験する際に、患者に対して最も有効な治療法を探索します。
バンディットアルゴリズムは、その単純さと強力なパフォーマンスにより、多くの実用的な問題解決に有効な手段として広く使用されています。特に、オンラインでの意思決定プロセスに
Rollout POLICY、SL POLICY、RL POLICYの特徴と比較
ロールアウトポリシー、SL スーパーバイストポリシー、RL リインフォースメントラーニングポリシーの比較
ロールアウトポリシー、SLスーパーバイストポリシー、RLリインフォースメントラーニングポリシーは、それぞれ異なる強化学習における方策であり、それぞれ異なる特徴と利点・欠点を持っています。以下では、それぞれの詳細と比較を行います。
1. ロールアウトポリシー
概要:
シミュレーションを用いて未来の報酬を推定し、最適な行動を選択する方策
長期的な利益を考慮できる
探索と活用のバランスを調整できる
計算量が多い
パラメータの設定が重要
利点:
短期的な利益だけでなく、長期的な利益も考慮して行動を選択できる
探索と活用のバランスを調整できるため、未知の環境でも学習しやすい
欠点:
シミュレーションを実行する必要があるため、計算量が多い
パラメータの設定が重要であり、適切な設定が難しい場合がある
局所解に陥る可能性がある
適用例:
ロボット制御
ゲーム
資源管理
金融工学
2. SLスーパーバイストポリシー
概要:
教師あり学習を用いて、正解データから方策を学習する方策
学習効率が高い
計算量が少ない
十分な教師データが必要
環境の変化に対応できない
利点:
教師あり学習を用いるため、学習効率が高い
計算量が少ない
欠点:
十分な教師データが必要であり、データ収集が難しい場合がある
環境の変化に対応できない
適用例:
画像認識
自然言語処理
音声認識
3. RLリインフォースメントラーニングポリシー
概要:
試行錯誤を通じて、報酬を最大化する方策を学習する方策
柔軟性が高い
環境変化に適応できる
学習に時間がかかる
探索と活用のバランスが難しい
利点:
教師データがなくても学習できる
環境変化に適応できる
欠点:
学習に時間がかかる
探索と活用のバランスが難しく、学習がうまくいかない場合がある
適用例:
ロボット制御
ゲーム
資源管理
金融工学
比較表
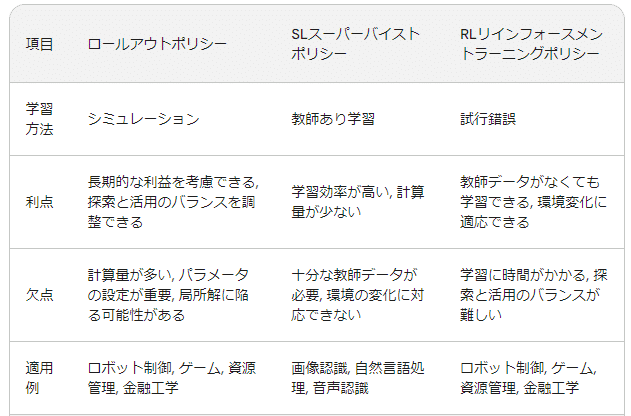
まとめ
ロールアウトポリシー、SLスーパーバイストポリシー、RLリインフォースメントラーニングポリシーは、それぞれ異なる特徴と利点・欠点を持っています。どのポリシーが最適かは、タスクや環境によって異なります。
長期的な利益を考慮する必要がある場合は、ロールアウトポリシーが適しています。
学習効率を重視する場合は、SLスーパーバイストポリシーが適しています。
教師データがない場合は、RLリインフォースメントラーニングポリシーが適しています。
割引率 (Discount Factor)
特徴: 将来の報酬を現在価値に割り引いて評価するためのパラメータ。
目的: 長期的な目標に焦点を合わせつつも、近い将来の報酬を重視するバランスを取る。
説明: 割引率は0から1の間で設定され、値が低いほど即時の報酬を重視し、高いほど将来の報酬を重視します。これにより、エージェントは即時の利益と長期的な利益のトレードオフを管理します。
ε-greedy 方策 (Epsilon-Greedy Policy)
特徴: 一定の確率εでランダムな行動を選択し、残りの1-εの確率で最大の報酬をもたらす行動を選択する方策。
目的: 探索と活用のバランスを取り、局所的最適解に固執することなく多様な行動を試す。
説明: ε-greedy 方策は、初期の学習段階でランダムな行動を多く取り入れることで探索を促進し、学習が進むにつれて最適な行動を活用する比率を高めます。
UCB 方策 (Upper Confidence Bound Policy)
特徴: 行動の選択において、推定された報酬の不確実性も考慮に入れる方策。
目的: 探索と活用のトレードオフを効率的に管理し、不確実性が高い行動を適度に探索する。
説明: UCB方策は、既に試された行動の報酬とその行動が選択された回数に基づいて、次にどの行動を取るかを決定します。これにより、探索が不十分な行動に自動的に重みを置くことができます。(試行数が少ない行動を優先的に選択)
UCB(Upper Confidence Bound)方策は、強化学習における一つの戦略で、報酬が最大となるような行動を選択するためにその行動に関する情報が必要です。UCB方策は、この情報を収集する際に、これまでに選択された回数が少ないものを優先的に選択します。
UCB方策は、期待値の高い選択肢を選ぶ一方で、それまで施行数が少ない選択肢を優先的に選択されるようにする方策です。これにより、探索と利用のバランスを取りながら、最適な行動を見つけ出すことが可能となります。
このような特性から、UCB方策はバンディット問題などの問題解決に広く利用されています。バンディット問題とは、未知の報酬が設定された選択肢が多数存在し、その中から一つを選択するという問題で、選んだ選択肢に対する報酬を得ることができます。この問題では、報酬を最大化するためには、良い選択肢の探索と過去に選んだ選択肢に対する知識の利用のバランスが重要になります。
UCB 方策 vs ε-greedy 方策:探索と利用の戦い
UCB 方策と ε-greedy 方策はどちらも、強化学習における 探索と利用 のバランスをとるアルゴリズムですが、アプローチが異なります。
共通の目的:
未知の行動を試して報酬を最大化するための情報を集める(探索)
学習済みの情報をもとに、現時点で最も報酬の高い行動を選択する(利用)
相違点:
探索の考え方
UCB 方策: 各行動のUCB値を計算し、値が高い(探索ボーナスが大きい)行動を選択。UCB値は、平均報酬と探索度 (選択回数が少ないほど大きくなる) を考慮します。
ε-greedy 方策: 一定の確率 (ε) でランダムに行動を選択し、残りの確率 (1-ε) でこれまでで一番報酬が高かった行動を選択。εは固定値なので、探索の度合いが一定です。
計算量
UCB 方策: 各行動のUCB値を計算する必要があるため、ε-greedy 方策より計算量が多いです。
ε-greedy 方策: 非常にシンプルなアルゴリズムのため、計算量は少ないです。
学習初期の効率
UCB 方策: 探索ボーナスを考慮するため、学習初期はより多くの行動を試すことができ、新しい情報収集に効率的です。
ε-greedy 方策: ε が大きすぎると探索が多くなり、学習が遅れることも。ε が小さすぎると探索が不十分になり、局所解に陥る可能性があります。ε の設定が難しく、学習初期の効率が不安定になりがちです。
学習後期の安定性
UCB 方策: 探索ボーナスが小さくなり、学習後は徐々に利用に寄せていきます。
ε-greedy 方策: ε を下げても、一定の確率でランダムな行動を選択し続けるため、学習後も探索が混ざることがあります。
マルコフ性 (Markov Property)
特徴: 現在の状態が過去の履歴に依存せず、将来の状態とのみ関係がある性質。
目的: 状態の遷移と意思決定を単純化し、計算の複雑性を減少させる。
説明: マルコフ性を持つシステムでは、現在の状態のみが未来の状態を決定するため、過去の状態について考慮する必要がありません。これは特にマルコフ決定過程モデルで重要です。
状態価値関数 (State Value Function)
特徴: ある状態から開始して特定の方策に従った場合の、期待される累積報酬を示す関数。
目的: 状態の価値を評価し、最適な方策決定に役立てる。
説明: 状態価値関数は、その状態がどれだけ「良い」か、つまりその状態から始めてどれだけの報酬を得られるかを示します。これは方策の評価や改善に用いられます。
行動価値関数 (Action Value Function), Q値
特徴: ある状態で特定の行動を取った際の、期待される累積報酬を示す関数。
目的: 各行動の価値を評価し、最適な行動選択に役立てる。
説明: 行動価値関数またはQ値は、特定の状態で取りうる各行動の価値を数値化します。これにより、どの行動が最も有益かを判断できます。
Q学習 (Q-learning)
特徴: オフポリシー学習アルゴリズムの一種で、行動価値関数を更新しながら最適な方策を学習する。
目的: 最適な方策を方策外から学習し、環境に依存しない汎用的な学習を実現する。
説明: Q学習では、エージェントが行動を選択し、その結果として得られる報酬と次の状態に基づいてQ値を更新します。このプロセスは、最適な方策を導き出すために繰り返されます。
DQNとQ学習の比較:詳細
DQNとQ学習は、どちらも強化学習における重要なアルゴリズムですが、それぞれ異なる特徴を持ち、長所と短所があります。
DQNの利点
複雑な状態空間や高次元な問題に対応可能: ニューラルネットワークを用いることで、より複雑な状態空間や高次元な問題にも対応することができます。これは、従来のQ学習では困難だった問題を解くことを可能にします。
学習速度の向上: 経験リプレイを用いることで、学習効率が向上し、より短時間で学習することができます。
柔軟性の高さ: ニューラルネットワークのアーキテクチャを変更することで、様々なタスクに適用することができます。
DQNの課題
計算量の増加: ニューラルネットワークを用いるため、Q学習よりも計算量が多くなります。
ハイパーパラメータの調整: ニューラルネットワークには多くのハイパーパラメータが存在し、適切な値を設定することが重要です。
過学習: 十分なデータがない場合、過学習を起こしやすくなります。
Q学習の利点
シンプルなアルゴリズム: Q学習は、比較的シンプルなアルゴリズムであり、実装しやすいという利点があります。
オフライン学習可能: Q学習は、オンライン学習だけでなくオフライン学習にも適用することができます。これは、シミュレーション環境などで学習できることを意味します。
解釈性: Q値を直接確認することで、エージェントの行動を理解しやすいという利点があります。
Q学習の課題
探索と活用: エージェントは、新しい行動を試す探索と、既知の最適な行動を選択する活用のバランスを取る必要があります。
収束: エージェントが常に最適な行動を選択できるよう、Q値が適切に収束する必要があります。
次元性の呪い: 状態空間の次元が高い場合、Q値を学習することが困難になります。
DQNとQ学習の選び方
DQNとQ学習のどちらを選ぶべきかは、問題の性質によって異なります。
複雑な状態空間や高次元な問題の場合は、DQNの方が適しています。
シンプルな問題や、計算量を制限したい場合は、Q学習の方が適しています。
オフライン学習が必要な場合は、Q学習を選択する必要があります。
REINFORCE (Monte Carlo Policy Gradient)
特徴: 方策ベースの強化学習アルゴリズムで、完全なエピソードの報酬を用いて方策を直接更新する。
目的: 方策のパラメータを最適化し、期待される報酬を最大化する。
説明: REINFORCEは、エピソードが完了するごとに得られる報酬を使用して方策のパラメータを調整し、長期的に最も報酬が大きい行動を選択するように学習します。
方策勾配法 (Policy Gradient Methods)
特徴: 方策を直接パラメータ化し、期待される報酬を最大化する方向に方策パラメータを勾配上昇法で更新する。
目的: より一般的な問題設定での学習を可能にし、連続的な行動空間にも適用可能。
説明: 方策勾配法は、方策の確率的な性質を利用して探索と活用のバランスをとりながら、最適な行動選択戦略を学習します。
方策勾配法:詳細解説
方策勾配法は、強化学習における代表的な学習アルゴリズムの一つであり、エージェントの方策を直接更新することで報酬を最大化する手法です。従来のQ学習やSARSAなどの価値関数ベースのアルゴリズムとは異なり、方策を直接パラメータ化し、勾配法を用いて最適な方策を探索します。
方策勾配法の具体的な手順は以下の通りです。
1. 方策のパラメータ化
まず、エージェントの方策をパラメータで表現します。代表的なパラメータ化方法として、ソフトマックス関数やガウス分布などが用いられます。
2. 勾配の計算
次に、現在の方策における期待報酬の勾度を計算します。勾配は、報酬を最大化する方向を示します。
3. 方策のパラメータ更新
最後に、計算された勾配に基づいて、方策のパラメータを更新します。パラメータ更新には、勾配降下法やAdamなどの最適化アルゴリズムを用います。
4. 繰り返し
1から3までの手順を繰り返し行うことで、方策を改善し、より多くの報酬を得られるようにしていきます。
方策勾配法の特徴
直接的な方策更新: 方策を直接更新することで、探索と活用のバランスを調整しやすくなります。
柔軟な表現: 方策をパラメータで表現することで、様々な種類の行動を表現することができます。
モデルフリー学習: 環境モデルを必要としないモデルフリー学習であり、未知の環境でも学習することができます。
方策勾配法の課題
サンプル効率: 多くの経験が必要となるため、学習に時間がかかる
局所解: 必ずしも最適な解を見つけられない可能性がある
ハイパーパラメータ: 適切なハイパーパラメータを設定することが重要
Actor-Critic
特徴: 方策勾配法と価値関数アプローチを組み合わせた強化学習アルゴリズム。
目的: 方策(Actor)と価値関数(Critic)の双方を同時に学習し、より効率的な学習を実現する。
説明: Actor-Criticアルゴリズムでは、Actorが行動を決定し、Criticがその行動の価値を評価します。このフィードバックにより、Actorはより良い方策を学習し、Criticはより正確な価値予測を行います。
A3C (Asynchronous Advantage Actor-Critic)
特徴: 複数のエージェントが非同期に環境と相互作用しながら学習を進めるActor-Criticの一形態。
目的: 複数のエージェントが異なる経験を同時に学習することで、学習プロセスを加速し効率を向上させる。
説明: A3Cでは各エージェントが独立して行動価値を学習し、定期的にグローバルネットワークにその学習結果を統合します。これにより、学習が安定し、速度も向上します。
学習目標:学習されたモデルの精度の評価方法と評価指標を理解する
学習項目:正解率・適合率・再現率・F 値、ROC 曲線と AUC、モデルの解釈、モデルの選択と情報量
交差検証 (Cross-validation)
特徴: データセットを複数の部分に分割し、一部を訓練データとして、残りをテストデータとして使用するプロセスを繰り返す。
目的: モデルの汎化能力を評価し、過学習を防ぐ。
説明: 交差検証では、データセット全体を効率的に使用し、各サブセットでモデルを試すことで、異なるデータに対するモデルの性能を確認します。交差検証法(Cross-Validation)は、機械学習モデルの性能評価と選定において広く使用される手法です。この方法は、データの一部を訓練用に、別の一部をテスト用に分割することを繰り返し、モデルの学習と評価を複数回実施します。このプロセスを通じて、モデルが未知のデータに対してどの程度うまく一般化できるかを評価することができます。
交差検証の主な特徴
一般化能力の向上:
交差検証は、データセット全体を使用してモデルの一般化能力を評価します。これにより、特定のサンプルに過剰適合するリスクを減少させることができます。
効率的なデータ利用:
全データを訓練と評価に利用するため、データの限られた状況でも効率的にモデルの性能を検証できます。特にデータ量が少ない場合に有効です。
異なるバリエーション:
交差検証にはいくつかの異なる形式があり、代表的なものにk-分割交差検証(k-fold cross-validation)、層化k-分割交差検証(stratified k-fold cross-validation)、そしてリーブ・ワン・アウト(leave-one-out)があります。
交差検証のタイプ
k-分割交差検証:
データセットをk個の部分に分割し、そのうちの一つをテストデータとして使用し、残りの ( k-1 ) 個でモデルを訓練します。このプロセスをk回繰り返し、それぞれ異なる部分をテストデータとして使用します。
層化k-分割交差検証:
分類問題において、各クラスのサンプルが均等に分布するようにデータセットを分割します。これにより、クラス間での偏りを防ぎながらモデルを評価することができます。
リーブ・ワン・アウト:
この方法では、データセットの各サンプルが一度はテストデータとして使用されます。データセットから一つのサンプルを抜き出してテスト用に使用し、残りのデータでモデルを訓練します。データポイントが少ない場合に特に有効ですが、計算コストが非常に高いです。
応用
交差検証は、モデルのパラメータをチューニングする際にも非常に有効です。例えば、異なるハイパーパラメータのセットを試して、最も高い検証スコアを持つパラメータを選択します。これにより、モデルの過剰適合を避け、実際の運用環境でより良いパフォーマンスを発揮するモデルを得ることができます。
ホールドアウト検証 (Holdout Validation)
特徴: データセットを一定の比率で訓練データとテストデータに分割する。
目的: モデルの性能をシンプルに評価する。
説明: ホールドアウト検証は、データの一部を完全に分離してテストに使用することで、訓練中にモデルが見ていないデータに対する性能を評価します。
k-分割交差検証 (k-Fold Cross-validation)
特徴: データセットをk個のサブセットに分割し、交替でテストセットとして使用する。
目的: データのランダムなサブセットに対するモデルの性能を評価し、より信頼性の高い性能評価を提供する。
説明: k-分割交差検証は、データ全体が均等に評価に使用されるため、単一のホールドアウトセットを使用するよりも一般的に信頼性が高いです。
混同行列 (Confusion Matrix)
特徴: 実際のクラスと予測クラスの関係を表す行列。
目的: 分類モデルの性能を詳細に理解し、正解、偽陽性、偽陰性、真陰性を識別する。
説明: 混同行列は、分類問題において、モデルがどのクラスをどれだけ正確に予測できているか、また誤分類の種類を明確にします。
混同行列(Confusion Matrix)は、分類問題においてモデルのパフォーマンスを評価するためのツールです。この行列は、実際のカテゴリーと予測カテゴリーの組み合わせに基づいて、モデルがどのように動作しているかを視覚的に表現します。混合行列は特に二値分類問題において一般的で、以下のような情報を提供します。
混合行列から、以下の指標を算出することができます。
正解率: (TP+TN / 全体) * 100
再現率: (TP / 実際の陽性) * 100
適合率: (TP / 予測の陽性) * 100
F1スコア: (2 * 再現率 * 適合率) / (再現率 + 適合率)
特異度: (真陰性 / 実際の陰性) * 100
混同行列を使用するメリット
モデルの正確性の評価:
正確さ(Accuracy)や感度(Sensitivity / Recall)、特異性(Specificity)、適合率(Precision)など、分類モデルのパフォーマンスを評価するためのさまざまな指標を導出できます。
エラーのタイプの理解:
モデルがどのタイプのエラー(偽陽性または偽陰性)を多く生じているかを明らかにし、特定のアプリケーションにおいてそのバランスを取るための改善策を講じることができます。
クラスの不均衡の影響の評価:
データセットにおいて一部のクラスが過少表現されている場合の影響を評価し、それに対処する戦略を立てるのに役立ちます。
混同行列は、特に医療分野の診断テスト、スパムメールのフィルタリング、金融詐欺の検出など、誤分類のコストが高い場面でその真価を発揮します。モデルの改善点を明確にし、さらに精度の高いモデルへと改良を加えるための基礎データとして非常に有効です。
混同行列(Confusion Matrix)は、分類問題における予測の正確さを評価するための表です。この表は、予測結果と実際のカテゴリーがどのように一致しているか(または一致していないか)を示します。主に二値分類問題において使用されることが多いですが、多クラス分類においても応用されます。
混同行列の要素
混合行列は以下の4つの基本要素から構成されます。
真陽性(True Positive, TP):
実際に「陽性」であるデータを正しく「陽性」と予測した件数です。この値が高いほど、陽性のデータを見逃さずに捉える能力が高いことを示します。
真陰性(True Negative, TN):
実際に「陰性」であるデータを正しく「陰性」と予測した件数です。この値が高いほど、陰性のデータを正確に識別できることを示します。
偽陽性(False Positive, FP):
実際には「陰性」であるデータを誤って「陽性」と予測した件数です。これは「タイプIエラー」とも呼ばれます。
偽陰性(False Negative, FN):
実際には「陽性」であるデータを誤って「陰性」と予測した件数です。これは「タイプIIエラー」とも呼ばれます。
F値(F-scoreまたはF1スコア)
F値(F-scoreまたはF1スコア)は、分類モデルの性能を評価するために用いられる指標です。このスコアは、適合率(Precision)と再現率(Recall)の調和平均として計算されます。適合率はモデルが正と予測したケースの中で実際に正であるケースの割合を示し、再現率は実際に正であるケースの中でモデルが正と予測したケースの割合を示します。F値はこれら二つの指標をバランスよく考慮するために設計されており、一方が高くても他方が低い場合には全体のスコアが低くなるようになっています。
・Precision(適合率) は、正と予測されたデータのうち実際に正である割合を表します。これは正確な予測の重要性を示す指標です。
Recall(再現率) は、実際に正であるデータのうち、モデルが正と予測した割合を表します。これは全ての正のケースを捉える能力を示す指標です。
F値の利点
バランスの取れた評価:
F値は適合率と再現率のバランスを取ることに重点を置いています。そのため、どちらか一方だけが非常に高い値を示しても、もう一方が低い場合はF値全体としては低くなります。これにより、モデルが一方の指標に偏ることなく、全体的にバランスの取れた性能を持つかを評価できます。
異なるモデルの比較:
異なるモデルやアプローチを公平に比較するための一つの指標として利用できます。特に、クラスの不均衡が存在する場合や、誤分類のコストが異なる場合に有効です。
F値の制限
適用状況の選択:
F値は適合率と再現率の調和平均を取るため、どちらかが極端に低い場合には低い評価を受けます。したがって、特定の状況では適合率または再現率のどちらか一方が重要である場合、F値ではそのニュアンスを捉えることができないことがあります。
クラスごとの性能評価の欠如:
F値は二値分類問題においてよく用いられますが、多クラス問題においてはそれぞれのクラスに対して個別にF値を計算し、平均を取るなどの追加の処理が必要になる場合があります。
過学習 (Overfitting)
特徴: モデルが訓練データに対して過度に最適化され、未知のデータに対して性能が低下する現象。
目的: 訓練データのノイズや非代表的な特徴にモデルが適応しないようにする。
説明: 過学習は、モデルが訓練データの詳細を「覚える」ことで起こり、新しいデータに対する予測が不正確になります。これを防ぐためには正則化技術などが用いられます。
過学習が起こった場合の予測値と誤差の変化
過学習が起こると、**モデルは訓練データに対しては高い精度を達成するものの、テストデータ(学習に使用していないデータ)に対しては精度が低くなるという現象が発生します。これは、モデルが訓練データのノイズや個々の特徴を過剰に学習し、一般化能力が低下してしまうためです。
過学習が起こりやすい状況を一覧
モデルが過度に複雑
ニューラルネットワークの層が多すぎる
パラメータ数が多すぎる
特徴量が多すぎる
トレーニングデータが不足している
サンプル数が少ない
データの多様性が乏しい
データにノイズが多い
ラベル付けの誤りがある
外れ値が多い
正則化が不足している
L1/L2正則化の強さが弱い
ドロップアウトが不適切
バッチ正規化を使っていない
学習が過度に進んだ
学習エポック数が多すぎる
早期停止していない
学習率が不適切
初期学習率が高すぎる
減衰スケジュールが適切でない
訓練とテストの分布が異なる
ドメインシフトやデータシフトがある
ハードコーディングしている
特殊なケースを想定している
目的関数がデータに合っていない
損失関数が適切でない
モデルの自由度が高すぎる
カーネルトリック等で高次元化しすぎている
これらの要因が単独または複合して影響することで過学習が引き起こされやすくなります。データとモデルの特性に合わせて適切な対策を行う必要があります。
未学習 (Underfitting)
特徴: モデルが訓練データのパターンを十分に学習しておらず、訓練データおよび新しいデータに対しても性能が低い状態。
目的: モデルの複雑さを増やすことで、データの基本的なパターンを捉える能力を向上させる。
説明: 未学習は、モデルが単純すぎるために発生し、訓練データの特性を適切に表現できていない状態を指します。モデルの複雑度を高めることで解決可能です。
正則化 (Regularization)
特徴: モデルの複雑さにペナルティを与える手法。
目的: 過学習を防ぎ、モデルの汎化性能を向上させる。
説明: 正則化は、モデルの重みに対して制約を加えることで、その複雑さを制限します。例えば、L1、L2正則化は重みを制限することでモデルがデータの本質的な特徴だけを学習するのを助けます。
正則化の概要
正則化は機械学習において過学習を防ぐための重要な手法です。
過学習とは、モデルがトレーニングデータに過度に適合してしまい、一般化性能が低下してしまうことを指します。
正則化は、損失関数に罰則項を追加することで、モデルの複雑さを制限し、過学習を防ぐことができます。
正則化の種類
主な正則化手法には以下のようなものがあります:
L1正則化(ラッソ正則化):
重みパラメータの絶対値の和を損失関数に追加する手法
重みパラメータを0に近づけ、スパース性を高める
L2正則化(リッジ正則化):
重みパラメータの二乗和を損失関数に追加する手法
重みパラメータの大きさを抑制する
Elastic Net正則化:
L1正則化とL2正則化を組み合わせた手法
L1正則化とL2正則化のバランスを調整できる
これらの正則化手法により、過学習を防ぎ、一般化性能の高いモデルを構築することができます。
正則化の効果
正則化を適用することで、モデルの複雑さを制限し、過学習を防ぐことができます。
これにより、トレーニングデータに対する適合性は下がりますが、テストデータに対する一般化性能が向上します。
適切な正則化手法と強さを選択することで、バリアンスとバイアスのバランスを取ることができ、高精度なモデルを構築できます
L0正則化、L1正則化、L2正則化
特徴: L0正則化は非ゼロのパラメータの数を最小化し、L1正則化はパラメータの絶対値の和を最小化し(ラッソ回帰)、L2正則化はパラメータの二乗和を最小化します(リッジ回帰)。
目的: モデルの過学習を防ぐため、特にL1はスパースソリューションを促進し、L2はパラメータ値を小さく抑える。
説明: L1正則化は不要なパラメータをゼロにする効果があるため、特徴選択に役立ちます。L2正則化はパラメータの値を小さくすることでモデルの過学習を防ぎ、より滑らかなモデル予測を促します。
L1正則化とマンハッタン距離の関係
L1正則化とマンハッタン距離は、以下の2つの点で深く関係しています。
幾何的な解釈: L1正則化は、モデルのパラメータ空間におけるL1距離を最小化する問題として解釈することができます。L1距離とは、2つの点間の座標の絶対値の差の和を意味します。つまり、L1正則化は、パラメータ空間における原点に近いほど小さいL1距離を持つモデルを選択することになります。これは、パラメータの値を0に近いほど小さいモデルを選択することと同じ意味です。
特徴量選択: L1正則化は、重要度の低い特徴量のパラメータの値が0になりやすくなります。これは、L1距離の意味から考えると、原点から最も遠い特徴量が排除されることになります。つまり、L1正則化は、距離という概念を利用して、重要度の低い特徴量を自動的に選択することができるのです。
L2正則化とユークリッド距離の関係
L2正則化とユークリッド距離は、以下の2つの点で深く関係しています。
幾何的な解釈: L2正則化は、モデルのパラメータ空間におけるL2距離を最小化する問題として解釈することができます。L2距離とは、2つの点間の座標の2乗の差の和の平方根を意味します。つまり、L2正則化は、パラメータ空間における原点に近いほど小さいL2距離を持つモデルを選択することになります。これは、パラメータの値を全体的に小さくするモデルを選択することと同じ意味です。
過学習の防止: L2正則化は、モデルの複雑さを制御することで、過学習を防ぎます。過学習とは、モデルが訓練データに過剰に適応してしまう現象です。L2正則化によって、パラメータの値が小さくなることで、モデルが訓練データに依存しすぎないように抑制することができます。
LIME (Local Interpretable Model-agnostic Explanations)
特徴: 個々の予測に対して局所的な説明を提供するモデル解釈手法。
個々の予測に対して局所的な説明を提供します。
元のモデルの予測周辺で線形モデル(などの単純なモデル)を学習させ、その予測の解釈を試みます。
モデルに依存しない方法であり、複雑なモデルの予測を近似することで理解を助けます。
目的: 複雑なモデルの予測を理解しやすくする。
説明: LIMEは、特定の予測周辺のデータを使って単純なモデルを訓練し、どの特徴が予測に最も影響を与えたかを示します。これにより、複雑なモデルの決定を人間が解釈しやすくなります。
SHAP (SHapley Additive exPlanations)
特徴: ゲーム理論に基づいたモデル予測の解釈を提供する手法。
ゲーム理論に基づいたアプローチで、各特徴が予測にどのように貢献するかを定量的に評価します。
各特徴の影響度をシャプリー値として算出し、モデルの予測に対する各入力特徴の寄与を明らかにします。
モデルに依存しないため、任意の機械学習モデルに適用可能です。
目的: モデルの予測に対する各特徴の貢献度を定量的に評価する。
説明: SHAP値は、ある特徴がモデルの予測にどのように影響を与えるかを示し、モデルの予測全体に対する各特徴の公平な貢献を計算します。
オッカムの剃刀 (Occam's Razor)
特徴: 等しく予測可能な複数の仮説がある場合、最も単純な仮説を選択すべきであるという原則。
目的: 不必要な複雑さを避け、より単純で理解しやすい解釈を提供する。
説明: オッカムの剃刀は、科学的な仮説形成やモデル選択において、不必要な仮定を排除するための指針として使用されます。より単純なモデルは、しばしばより高い汎化性能を持ちます。
オッカムの剃刀とスパースモデリング手法
オッカムの剃刀は、14世紀の神学者ウィリアム・オブ・オッカムによって提唱された考え方です。これは、「事柄を説明するには必要以上に多くのものを仮定すべきではない」という原則を意味します。
スパースモデリング手法は、このオッカムの剃刀の考え方に基づいています。スパースモデリング手法は、データから最も重要な特徴のみを選び出し、その特徴に基づいてモデルを構築する手法です。これは、モデルをできるだけシンプルにし、複雑な仮定を避けるというオッカムの剃刀の精神に則っています。
スパースモデリング手法を用いることで、以下の利点があります。
モデルの解釈性向上: スパースモデルは、複雑なモデルよりも解釈しやすいという特徴があります。これは、モデルがどのような特徴に基づいて予測を行っているのかを理解しやすいためです。
過学習の抑制: スパースモデルは、過学習を起こしにくいという特徴があります。これは、モデルがデータのノイズではなく、真の特徴を学習するためです。
計算コストの削減: スパースモデルは、複雑なモデルよりも計算コストが低くなります。これは、モデルのパラメータ数が少ないためです。
スパースモデリング手法の例
スパースモデリング手法には、様々な種類があります。代表的な例としては、以下のようなものがあります。
LASSO回帰: LASSO回帰は、L1正則化を用いてモデルのパラメータを制限する手法です。L1正則化は、各パラメータの絶対値の和を最小化するようにモデルを学習します。これにより、多くのパラメータが0になり、スパースなモデルが得られます。
Ridge回帰: Ridge回帰は、L2正則化を用いてモデルのパラメータを制限する手法です。L2正則化は、各パラメータの二乗和を最小化するようにモデルを学習します。これにより、すべてのパラメータが小さくなり、スパースなモデルが得られます。
Elastic Net: Elastic Netは、L1正則化とL2正則化を組み合わせた手法です。Elastic Netは、LASSO回帰よりも多くの特徴を選択することができ、Ridge回帰よりも解釈しやすいモデルを得ることができます。
スパースモデリング手法の応用例
スパースモデリング手法は、様々な分野で応用されています。代表的な例としては、以下のようなものがあります。
画像処理: 画像圧縮、画像認識、画像分類
音声処理: 音声圧縮、音声認識、音声分類
自然言語処理: テキストマイニング、文書分類、情報検索
機械学習: 特徴量抽出、異常検知、回帰分析
まとめ
オッカムの剃刀は、スパースモデリング手法の背景にある重要な考え方です。スパースモデリング手法は、オッカムの剃刀の精神に基づいて、シンプルで解釈しやすいモデルを構築することができます。スパースモデリング手法は、様々な分野で応用されており、今後ますます重要になっていくと考えられます。
赤池情報量基準 (AIC: Akaike Information Criterion)
特徴: モデルの良さを評価するための統計的指標で、モデルの複雑さとデータへの適合度をバランスさせる。
目的: 最も良いモデルを選択する際に、適合度とモデルの複雑さのトレードオフを考慮する。
説明: AICは、モデルの適合度を示す尺度からモデルのパラメータ数に対するペナルティを引いた値です。数値が小さいほど良いモデルと評価されます。
赤池情報量基準(AIC)について
赤池情報量基準(AIC)は、統計モデルの適合度を評価するための指標です。値が小さいほどモデルの当てはまりが良いとされ、モデルの予測性能と複雑さのバランスを考慮しています。
赤池情報量基準(AIC)の概要
定義: AICは、モデルの予測性能を評価するための統計量で、残差を用いて計算されます。値が小さいほど、モデルの当てはまりが良いとされます。
計算方法: AICは、モデルの複雑さ(パラメータの数)とデータへの当てはまりの良さ(尤度)を考慮して計算されます。具体的には、
AIC = -2 (最大対数尤度 - パラメータの数) で表されます。AIC = 2k - 2ln(L)
AICの応用
モデル選択: AICは、複数の統計モデルの中から最適なモデルを選択する際に用いられます。モデルの複雑さとデータへの当てはまりの良さのバランスを考慮することで、過学習を避けつつ、適切なモデルを選択することができます。
赤池情報量基準(AIC)は、統計モデルの適合度を評価し、複数のモデルの中から最適なものを選択するための重要な指標です。モデルの予測性能と複雑さのバランスを考慮することで、より信頼性の高い統計分析を行うことが可能になります。
説明変数選択と AIC
説明変数選択において、AICは以下のように用いられます。
すべての説明変数を用いたモデルを構築する
順次、説明変数を1つずつ削除し、AICを計算する
AICが最小になるまで、説明変数を削除していく
この手順により、過学習と欠学習のバランスが良く、モデルが良いと評価される説明変数の組み合わせを選択することができます。
汎化誤差 (Generalization Error)
特徴: モデルが新しい、未見のデータに対してどの程度うまく機能するかを示す誤差。
目的: モデルの実世界での性能を推定し、その信頼性を評価する。
説明: 汎化誤差は、モデルが訓練データセット以外のデータにどれだけ適応できるかを測る指標であり、低い汎化誤差はモデルが未知のデータにもうまく対応できることを意味します。
学習率 (Learning Rate)
特徴: 機械学習アルゴリズムにおいて、各ステップでモデルのパラメータがどれだけ更新されるかを制御するパラメータ。
目的: 学習プロセスの速度と安定性を調整し、適切な収束を促す。
説明: 学習率が高すぎると学習過程で振動または発散するリスクがあり、低すぎると学習が遅くなり、最適な解に収束しない可能性があります。
学習率が大きい場合と小さい場合の特徴
学習率は、機械学習において、モデルのパラメータを更新する際のステップ幅を表す値です。
学習率が大きすぎると、以下のような問題が発生する可能性があります。
パラメータが最適解を飛び越えてしまう: 学習率が大きすぎると、パラメータの更新幅が大きくなり、最適解を飛び越えてしまう可能性があります。
振動が発生する: 学習率が大きすぎると、パラメータの更新方向が大きく変化し、振動が発生する可能性があります。
訓練が不安定になる: 学習率が大きすぎると、訓練が不安定になり、収束しにくくなる可能性があります。(発散する)
一方、学習率が小さすぎると、以下のような問題が発生する可能性があります。
学習が遅くなる: 学習率が小さすぎると、パラメータの更新幅が小さくなり、学習が遅くなります。
局所解に陥る: 学習率が小さすぎると、局所解に陥る可能性が高くなります。
十分な精度が得られない: 学習率が小さすぎると、十分な精度が得られない可能性があります。
一般的には、学習率を最初は大きめに設定し、訓練が進むにつれて徐々に小さくしていくのが一般的です。
これは、初期段階ではパラメータを素早く更新し、ある程度最適解に近づけた後、より精密な調整を行うためです。
具体的な学習率の設定値は、データセットやモデルによって異なるため、試行錯誤しながら最適な値を見つける必要があります。
学習率を調整する際のヒント
学習曲線を監視する: 学習曲線を監視することで、学習率が適切かどうかを確認することができます。
検証データセットを用いる: 検証データセットを用いることで、学習率が過学習を引き起こしていないかどうかを確認することができます。
異なる学習率を試してみる: 異なる学習率を試してみることで、最適な値を見つけることができます。
学習率スケジューリングを用いる: 学習率スケジューリングを用いることで、訓練が進むにつれて学習率を自動的に調整することができます。
まとめ
学習率は、機械学習において重要なハイパーパラメータの一つです。
学習率を適切に設定することで、より良いモデルを学習することができます
誤差関数 (損失関数)(Error Function)
特徴: モデルの予測が実際の値からどれだけ離れているかを定量化する関数。
目的: モデルの訓練中に最小化を目指すことで、最適なパラメータを見つける。
説明: 誤差関数(または損失関数)は、モデルがどれだけ「間違っている」かを示す指標であり、訓練中にこの値を最小化することでモデルの精度を向上させます。
代表的な誤差関数
機械学習には様々な誤差関数がありますが、代表的なものは以下の3つです。平均二乗誤差 (MSE): 予測値と正解値の二乗差の平均を計算します。最もシンプルな誤差関数の一つであり、回帰タスクによく用いられます。
平均絶対誤差 (MAE): 予測値と正解値の絶対差の平均を計算します。外れ値の影響を受けにくいという特徴があります。
交差エントロピー誤差: 確率的な分類タスクにおいて用いられる誤差関数です。予測された確率分布と正解の確率分布間の情報量に基づいて誤差を計算します。
誤差関数の選び方
誤差関数は、学習タスクやデータによって適切なものが異なります。回帰タスク: 平均二乗誤差 (MSE) や平均絶対誤差 (MAE) がよく用いられます。
分類タスク: 交差エントロピー誤差がよく用いられます。
外れ値の影響が大きい場合: 平均絶対誤差 (MAE) が適しています。
ディープラーニングの概要
学習目標:ディープラーニングを理解する上で押さえておくべき事柄を理解する。
単純パーセプトロン (Simple Perceptron)
特徴: 最も基本的な形のニューラルネットワークで、単一のニューロンから成る。
目的: 線形分離可能なデータセットに対する分類問題を解く。
説明: 単純パーセプトロンは、入力に重みを掛け、合計がある閾値を超えた場合に1を出力し、超えない場合には0を出力します。このモデルは基本的なバイナリ分類タスクに利用され、その学習規則は線形分離可能なパターンを学習するのに適しています。
多層パーセプトロン (Multilayer Perceptron, MLP)
特徴: 複数の層を持ち、少なくとも一つの隠れ層を含むニューラルネットワーク。
目的: 非線形問題を解く能力を持ち、より複雑な関数を近似する。
説明: 多層パーセプトロンは、入力層、一つまたは複数の隠れ層、および出力層から成り立ちます。各層のニューロンは前の層の全ニューロンと接続されており、非線形活性化関数を使用することで複雑なデータパターンを学習できます。
ディープラーニングとは
特徴: 多層のニューラルネットワークを使用して、大量のデータから複雑な特徴を自動で学習する技術。
目的: 画像認識、自然言語処理、音声認識など、多岐にわたるタスクで人間に近い、またはそれを超える性能を達成する。
説明: ディープラーニングは、データから自動的に高度な特徴を抽出する能力を持っており、特に大量のデータが利用できる場合に強力なパフォーマンスを発揮します。これにより、事前に特徴を手動で設計する必要がなくなります。
勾配消失問題 (Vanishing Gradient Problem)
特徴: ネットワークが深くなるにつれて、誤差逆伝播時に勾配が急速に小さくなり、入力層に近い層の学習が進まなくなる問題。
目的: ニューラルネットワークの効果的な訓練を妨げるこの問題を克服する。
説明: 勾配消失は、特に深いネットワークで顕著であり、勾配が非常に小さくなるため、重みの更新がほとんどまたは全く行われなくなります。これを解決するために、ReLU活性化関数や、より効果的な重み初期化方法などが導入されています。
信用割当問題 (Credit Assignment Problem)
特徴: 強化学習において、どの行動が最終的な報酬にどのように貢献したかを判断するのが難しい問題。
目的: エージェントがどの行動が良い結果に貢献したかを正確に理解し、効果的な学習を促進する。
説明: 信用割当問題は、特に長い行動シーケンスが関与する場合に困難となります。エージェントが適切な行動に適切な「信用」を割り当てることができれば、より効果的に学習し、最適な方策を見つけることができます。
信用割当問題の解決手法
誤差逆伝播法の改善:
誤差逆伝播法では、出力層から入力層に向けて誤差を逆伝播させることで、各ノードの重要度を評価します。
しかし、この手法では勾配消失問題などの課題があるため、改善が必要です。
深層残差学習(Deep Residual Learning)などの手法が提案されています。4
自己符号化器の活用:
自己符号化器(Autoencoder)は入力を圧縮・復元するニューラルネットワークで、
潜在変数の学習を通じて、各ノードの重要度を評価することができます。
変分自己符号化器(VAE)やベクトル量子化VAE(VQ-VAE)などの手法が提案されています。4
新しい学習アルゴリズムの開発:
誤差逆伝播法以外の新しい学習アルゴリズムの開発も進められています。
東京大学の松尾ゼミでは、誤差逆伝播法を用いない深層ニューラルネットワークの学習方法について研究が行われています。
誤差逆伝播法 (Backpropagation)
特徴: ニューラルネットワークを訓練するためのアルゴリズムで、出力からの誤差を用いて各層の重みを効率的に調整する。
目的: ネットワークの予測誤差を最小化し、最適な重みを見つける。
説明: 誤差逆伝播法は、出力層から入力層に向かって誤差を逆方向に伝播させることで、各重みを適切に更新します。この方法はディープラーニングで広く用いられ、効果的な学習プロセスを可能にします。
学習目標:ディープラーニングがどういった手法によって実現されたのかを理解する。
事前学習 (Pre-training)
特徴: ニューラルネットワークが特定のタスクの訓練を開始する前に、一般的なデータセットを使って初期の特徴を学習するプロセス。
目的: モデルがより関連性の高い特徴を抽出し、最終タスクの性能を向上させるため。
説明: 事前学習は、ラベルのない大量のデータを利用してネットワークを訓練し、その後具体的なタスクに適用する前にファインチューニングを行います。これにより、データが限られている場合でも効果的に学習が進められます。
事前学習:ディープラーニングにおける重要な手法
事前学習は、ディープラーニングモデルを学習させる前に、大量のデータを用いてモデルを初期化する方法です。これにより、モデルは学習の開始段階からより良い性能を発揮することができ、学習時間を短縮し、過学習を防ぐことができます。
事前学習の種類
事前学習には、大きく分けて以下の2種類があります。
教師あり事前学習: ラベル付きのデータを用いてモデルを初期化します。
教師なし事前学習: ラベルなしのデータを用いてモデルを初期化します。
教師あり事前学習は、画像分類や自然言語処理などのタスクによく用いられます。教師なし事前学習は、画像生成や異常検知などのタスクによく用いられます。
事前学習の代表的な手法
事前学習の代表的な手法は以下の通りです。
ImageNet: ImageNetは、1000万以上の画像と1000種類のクラスを含む大規模な画像データセットです。ImageNetは、画像分類の事前学習によく用いられます。
BERT: BERTは、自然言語処理の事前学習によく用いられるモデルです。BERTは、Transformerと呼ばれるニューラルネットワークアーキテクチャを用いており、文章の全体的な意味を理解することができます。
ELMo: ELMoは、BERTと同様に自然言語処理の事前学習によく用いられるモデルです。ELMoは、双方向LSTMと呼ばれるニューラルネットワークアーキテクチャを用いており、文章中の単語の意味を理解することができます。
事前学習の利点
事前学習には、以下の利点があります。
学習時間の短縮: 事前学習により、モデルは学習の開始段階からより良い性能を発揮することができ、学習時間を短縮することができます。
過学習の防止: 事前学習により、モデルは学習データに過度に依存することを防ぎ、過学習を防ぐことができます。
汎化性能の向上: 事前学習により、モデルは未知のデータに対する汎化性能を向上させることができます。
事前学習の注意点
事前学習には、以下の注意点があります。
データバイアス: 事前学習データにバイアスが含まれている場合、モデルもそのバイアスを反映してしまいます。
計算コスト: 事前学習には、大量の計算コストが必要となります。
転移学習: 事前学習モデルを異なるタスクに適用する際には、転移学習と呼ばれる手法を用いてモデルを微調整する必要があります。
まとめ
事前学習は、ディープラーニングにおける重要な手法であり、学習時間の短縮、過学習の防止、汎化性能の向上などの利点があります。しかし、データバイアス、計算コスト、転移学習などの注意点も理解する必要があります。
ファインチューニング (Fine-tuning)
特徴: 事前学習済みのモデルに対して、特定のタスクのデータを使って追加の訓練を行うプロセス。
目的: 事前学習で獲得した知識を活用しつつ、特定のタスクに最適化することでモデルの性能を最大化するため。
説明: 事前学習済みのネットワークを特定のタスクに再適用する際、ファインチューニングを行うことで、既存の知識を保持しつつ新しいデータに適応させ、より精度の高い予測を実現します。
ファインチューニング:詳細解説
ファインチューニングは、機械学習における重要な手法の一つであり、事前学習済みモデルを特定のタスクに特化させるために微調整を行う手法です。
ファインチューニングの仕組み
ファインチューニングは、以下の手順で行われます。
事前学習済みモデルの選択: 汎用的なタスクで学習済みのモデルを選択します。
モデルの調整: 選択したモデルの最後の層を削除し、新しい層を追加します。
微調整: 新しい層と既存のモデルのパラメータを、特定のタスクのデータを用いて微調整します。
ファインチューニングの利点
ファインチューニングには、以下の利点があります。
学習効率の向上: ゼロからモデルを学習するよりも、事前学習済みモデルをベースにすることで、学習効率を大幅に向上させることができます。
少ないデータでの学習: 少量しかデータがない場合でも、事前学習済みモデルをベースにすることで、モデルを学習することができます。
高い精度: 適切なファインチューニングを行うことで、高い精度を実現することができます。
ファインチューニングの課題
ファインチューニングには、以下の課題があります。
過学習: 訓練データに過度に適応し、訓練データ以外のデータに対して良い精度を出せない状態になる可能性があります。
データ量: ファインチューニングには、ある程度の量のデータが必要です。データ量が少ない場合、十分な精度が得られない可能性があります。
計算量: 複雑なモデルの場合、ファインチューニングに時間がかかることがあります。
ファインチューニングの応用例
ファインチューニングは、画像認識、自然言語処理、音声認識など、様々な分野で応用されています。
画像認識: 画像分類、オブジェクト検出、セマンティックセグメンテーションなど
自然言語処理: 機械翻訳、文書分類、感情分析など
音声認識: 音声認識、音声合成、音声翻訳など
ファインチューニングの注意点
ファインチューニングを行う際には、以下の点に注意する必要があります。
適切な事前学習済みモデルを選択: タスクに適した事前学習済みモデルを選択することが重要です。
過学習を防ぐ: 過学習を防ぐために、検証データを用いてモデルの精度を評価し、必要に応じて正則化などの手法を用いる必要があります。
データ量: ファインチューニングには、ある程度の量のデータが必要です。データ量が少ない場合、十分な精度が得られない可能性があります。
まとめ
ファインチューニングは、機械学習において強力な手法であり、学習効率の向上、少ないデータでの学習、高い精度の達成など、様々な利点があります。しかし、過学習、データ量、計算量などの課題も存在するため、注意して利用する必要があります。
深層信念ネットワーク (Deep Belief Network, DBN)
特徴: 複数の制限付きボルツマンマシン (RBM) またはその他の確率的グラフィカルモデルを積層して構成されるディープラーニングアーキテクチャ。深層信念ネットワーク(Deep Belief Networks, DBNs)は、2006年にジェフリー・ヒントンと彼の同僚たちによって提案されました。これは、多層の生成的確率モデルであり、特にディープラーニングの分野で重要な役割を果たしています。
多層構造: DBNsは複数の層から構成されており、各層は制限付きボルツマンマシン(RBM)またはオートエンコーダで構成されています。
事前学習と微調整: DBNsは、層ごとに事前学習を行い、その後、バックプロパゲーションによる微調整を通じて全体を最適化します。
教師なし学習(事前学習)を行って教師あり学習を行う。
この事前学習は計算コストがかかるため現在はあまり使われない。生成的モデル: DBNsは生成的モデルであり、入力データの生成分布を学習します。
目的: 複数の隠れ層を通じてデータから高度な特徴を効率的に学習し、複雑なデータ表現を実現するため。
特徴抽出: DBNsはデータから抽象的な特徴を効果的に抽出する能力を持ちます。
分類: 抽出された特徴を使用して、画像、音声、テキストなどのデータを分類します。
データ生成: 学習したモデルを使用して、新しいデータインスタンスを生成することが可能です。
説明: DBNは最初の数層を事前学習によって効率的に訓練し、その後の層に対してファインチューニングを適用することで、高度な特徴抽出とデータ表現を可能にします。これは特に画像や音声などの複雑なデータセットに有効です。
提案者 ジェフリー・ヒントン: トロント大学の教授であり、ディープラーニングの先駆者の一人。DBNsの開発に大きく貢献しました。
派生形
畳み込み深層信念ネットワーク(Convolutional Deep Belief Networks): 畳み込み層を取り入れたDBNsで、主に画像データの処理に使用されます。条件付き深層信念ネットワーク(Conditional Deep Belief Networks): 特定の条件やクラスに依存するデータ生成が可能です。
制限付きボルツマンマシン (Restricted Boltzmann Machine, RBM)
特徴: 可視層と隠れ層の二層から構成されるニューラルネットワークで、層間は完全に結合しているが、同じ層内のユニット間には接続がない。
二部グラフ構造: RBMは可視層(入力層)と隠れ層(特徴層)の2つの層から構成されており、層内のユニット間には接続がありませんが、異なる層間には接続が存在します。
エネルギーベースモデル: システムのエネルギーを定義し、低エネルギー状態が高確率で発生するように設計されています。
確率的学習と推論: 学習プロセスは、データからモデルパラメータを推定するために確率的な手法(例:コントラスティブ・ダイバージェンス)を使用します。
目的: 入力データの確率的な特徴を学習し、これをディープラーニングモデルの初期値や特徴抽出器として使用するため。
特徴抽出: 入力データから重要な特徴を学習し、データの理解を深める。
次元削減: 高次元のデータを低次元の表現に変換し、データの本質的な特性を捉えます。
生成モデル: 学習した確率分布に基づいて、新しいデータのサンプル生成を可能にします。
説明: RBMはデータの生成モデルとしても利用され、データの特徴を捉えるための重みを学習します。これらは単独で使用されることも、DBNの構成要素として使用されることもあります。
制限付きボルツマンマシン(Restricted Boltzmann Machine, RBM)は、1986年にジェフリー・ヒントンとテリー・セジノウスキーによって紹介されました。このモデルは、教師なし学習のためのエネルギーベースのニューラルネットワークであり、ディープラーニングや機械学習の分野で広く使われています。
製作者
ジェフリー・ヒントンとテリー・セジノウスキーによって開発されました。ヒントンはディープラーニングとニューラルネットワークの先駆者の一人であり、多くの重要な貢献をしています。
深層生成モデル:詳細解説
深層生成モデルは、ディープラーニングと生成モデルを組み合わせた強力なツールであり、画像、音声、テキストなどのデータを生成することができます。従来の生成モデルとは異なり、複雑なデータや現実的なデータを生成することができ、様々な分野で注目を集めています。
深層生成モデルの仕組み
深層生成モデルは、確率モデルと呼ばれる数学的なモデルを学習することで、データを生成します。確率モデルは、データの生成確率を計算することができます。深層生成モデルは、ニューラルネットワークと呼ばれる複雑な関数を使って、確率モデルを学習します。
深層生成モデルの種類
深層生成モデルには、様々な種類があります。代表的な種類は以下の通りです。
生成敵対ネットワーク (GAN): 2つのニューラルネットワークから構成されるモデルで、生成ネットワークと識別ネットワークと呼ばれる2つのネットワークが競い合いながら学習します。生成ネットワークは、偽のデータを生成し、識別ネットワークは、本物のデータと偽のデータを区別することを学習します。
変分オートエンコーダ (VAE): エンコーダとデコーダと呼ばれる2つのニューラルネットワークから構成されるモデルで、潜在変数と呼ばれる変数を用いてデータを表現します。エンコーダは、入力データを潜在変数に変換し、デコーダは、潜在変数を入力データに戻します。
オートエンコーダ: 入力データを圧縮して再構築するモデルで、特徴抽出や異常検知などに用いられます
学習目標:ディープラーニングを実現するために必要ものは何か、何故ディープラニングが実現できたかを理解する
CPU と GPU
特徴: CPU(Central Processing Unit)は一般的な計算タスクに使用されるプロセッサで、複雑なロジックや制御タスクに適しています。GPU(Graphics Processing Unit)は元々は画像処理用に設計されましたが、大量のデータに対する並列計算が得意です。
目的: ディープラーニングでは、特にGPUが重要で、その強力な並列処理能力によって大規模なニューラルネットワークの訓練が現実的な時間内に可能になります。
説明: ディープラーニングの訓練プロセスには膨大な数の行列計算が含まれるため、GPUの並列処理能力がこれを大幅に加速し、訓練時間を短縮します。CPUと比較して、GPUはこの種の計算においてはるかに効率的です。
GPGPU (General-Purpose computing on Graphics Processing Units)
特徴: GPUをグラフィックス以外の一般的な計算用途に使用する技術。
目的: GPUの計算資源を活用して、科学技術計算やデータ分析、機械学習などの分野で高速な計算を実現する。
説明: GPGPUは、GPUの強力な計算能力を利用して非グラフィックスタスクを処理し、特にディープラーニングのような計算集約的なタスクにおいて顕著な性能向上をもたらします。
ディープラーニングのデータ量
特徴: ディープラーニングモデルの訓練には、通常、大量のデータが必要です。
目的: 大量のデータを使用することで、モデルが現実世界の複雑なパターンを学習し、より正確な予測が可能になります。
説明: ディープラーニングはデータ駆動のアプローチであり、大量のデータからパターンを抽出して学習することで、モデルの汎用性と正確性が向上します。データ量が多いほど、モデルはより多様なシナリオと変動に対処できるようになります。
TPU (Tensor Processing Unit)
特徴: Googleによって開発された、特にテンソル計算と機械学習に特化したプロセッサ。
目的: ディープラーニングのような高度な機械学習タスクにおける計算効率と速度を最大化する。
説明: TPUは、特にディープラーニングモデルの訓練と推論に最適化されており、複数の計算を高速に並列実行することが可能です。TPUはGPUよりも一部のタスクで優れた性能を発揮し、特に大規模なニューラルネットワークの訓練において効果的です。
学習目標:ニューラルネットワークにおいて重要な役割をになう活性化関数を理解する
tanh 関数 (Hyperbolic Tangent Function)
特徴: 双曲線正接関数とも呼ばれ、出力範囲が-1から1の間である。
目的: ニューラルネットワークの中間層で使用され、データの正規化を助けることで学習プロセスを安定化させる。
説明: tanh 関数はシグモイド関数に似ていますが、出力が-1から1の範囲であるため、ゼロ中心であることから勾配消失の問題を緩和しやすいです。これにより、ニューラルネットワークの学習がスムーズに進みます。
ReLU 関数 (Rectified Linear Unit Function)
特徴: 入力が0を超えている場合はその入力をそのまま出力し、0以下の場合は0を出力する。
目的: 非線形性を導入しつつ、計算の単純さを保持し、効率的な学習を促進する。
説明: ReLUは現代のディープラーニングで最も広く使用される活性化関数の一つで、特に深いネットワークでの勾配消失問題を防ぐのに効果的です。そのシンプルさから、学習が早くなります。
シグモイド関数 (Sigmoid Function)
特徴: S字型の曲線を描き、出力範囲が0から1の間である。
目的: ニューラルネットワークの出力層で使用され、確率として解釈できる出力を生成する。
説明: シグモイド関数は特に二値分類問題での出力層に適しており、出力値を0から1の間の確率として解釈できるため、特定のクラスに属する確率をモデル化できます。
ソフトマックス関数 (Softmax Function)
特徴: クラスが複数ある場合に各クラスに属する確率を計算するために使用される。
目的: 多クラス分類問題の出力層で使用され、各クラスへの所属確率を出力する。
説明: ソフトマックス関数は、各クラスの指数関数的なスコアを正規化して、出力和が1になるように変換します。これにより、ニューラルネットワークの出力を直接確率分布として解釈できます。
Leaky ReLU 関数 (Leaky Rectified Linear Unit Function)
特徴: ReLU関数の変種で、入力が0以下の場合にもごく小さい値を出力する。
目的: ReLUの持つ死んだニューロンの問題を緩和し、すべてのニューロンが活動する可能性を保持する。
説明: Leaky ReLUは、入力が負の場合にも非ゼロの小さな勾配を持つことで、ニューラルネットワークがアクティブな状態を維持しやすくなり、学習中にニューロンが完全に無効化されることを防ぎます。
学習目標:ディープラーニングの学習に用いられるアルゴリズムである勾配降下法を理解する。そして勾配降下法にはどのような課題があり、どうやって解決するかを理解する
勾配降下法 (Gradient Descent)
特徴: 誤差関数の勾配(最も急な上昇方向)に基づいて、パラメータを逐次的に更新し、誤差を最小化する最適化手法。
目的: モデルのパラメータを最適化して、誤差を最小限に抑える。
説明: 勾配降下法は、誤差関数の勾配を計算し、その勾配が示す方向の反対へパラメータを少しずつ移動させることで、関数の最小値(最適解)を見つける手法です。
勾配降下法の問題と改善
特徴: 学習率の選択、局所最適解への収束、鞍点、非効率な収束速度などが主な問題点。
目的: 勾配降下法の性能と効率を向上させる。
説明: 問題に対処するため、異なる勾配降下法のバリエーション(モーメンタム、AdaGradなど)や適切な学習率の設定、ハイパーパラメータの調整が用いられます。
勾配降下法と訓練誤差
勾配降下法は、機械学習において最も基本的な最適化アルゴリズムの一つであり、損失関数を最小化することでモデルの学習を行う手法です。訓練誤差は、学習中のモデルが訓練データに対してどれほど良い精度を出せているかを表す指標です。
勾配降下法と訓練誤差の関係
勾配降下法を用いてモデルを学習させると、訓練誤差は一般的に以下のような動きをします。
初期段階: 訓練誤差は大きく、モデルの精度が低くなります。
学習進行: 勾配降下法によってモデルのパラメータが更新され、訓練誤差は徐々に小さくなります。
収束: モデルのパラメータが最適解に近づくと、訓練誤差は一定値に近づきます。
訓練誤差と過学習
訓練誤差が常に小さくなるとは限りません。モデルが訓練データに過度に適応し、訓練データ以外のデータに対して良い精度を出せない状態を過学習といいます。過学習を防ぐためには、検証データと呼ばれる別のデータセットを用いてモデルの精度を評価し、過学習が始まらないように調整する必要があります。
勾配降下法の注意点
勾配降下法は、以下の点に注意する必要があります。
学習率: 勾配降下法における学習率は、モデルのパラメータを更新する際のステップの大きさを決めます。学習率が大きすぎると、最適解を飛び越えてしまう可能性があり、小さすぎると収束が遅くなります。
局所解: 勾配降下法は、必ずしもグローバルな最適解を見つけるとは限りません。局所解に陥ってしまう可能性もあるため、注意が必要です。
まとめ
勾配降下法と訓練誤差は、機械学習において密接な関係にあります。訓練誤差を監視することで、モデルの学習状況を把握することができ、過学習などの問題を防ぐことができます。
学習率 (Learning Rate)
特徴: 勾配降下法でパラメータを更新する際のステップサイズ。
目的: 効率的かつ効果的に最適解に収束させる。
説明: 学習率が高すぎるとオーバーシュートが起こり、低すぎると収束が遅くなる。適切な学習率の設定は最適化の成功に不可欠です。
誤差関数 (Error Function)
特徴: モデルの予測が実際の値からどれだけ離れているかを示す関数。
目的: モデルの性能を評価し、最適化する基準を提供する。
説明: 誤差関数(または損失関数)は、訓練データに対するモデルの誤差を測定し、この値を最小化することでモデルの精度を向上させるための指標となります。
交差エントロピー (Cross-Entropy)
特徴: 分類問題においてよく使用される損失関数で、予測された確率分布と実際の分布との間の差異を計測する。
目的: モデルの予測が実際のカテゴリにどれだけ適合しているかを評価する。
説明: 交差エントロピーは特に多クラス分類問題で有効で、モデルが正しいクラスに高確率を割り当てるように促します。
イテレーションとエポック
特徴: イテレーションはデータセット全体またはサブセットに対する単一の更新ステップを指し、エポックは全データセットが一度完全に処理される周期を指す。
目的: モデルの訓練プロセスを定義し、進捗を監視する。
説明: 通常、複数のエポックを通じて訓練が行われ、各エポックでモデルのパフォーマンスが改善されることを目指します。イテレーションはエポックを細かく分けた単位です。
局所最適解と大域最適解
特徴: 局所最適解はある近傍で最も良い解であり、大域最適解は全域で最も良い解。
目的: 最適なモデルパラメータを見つける。
説明: 勾配降下法は局所最適解に陥りやすいが、適切な初期値設定やアルゴリズムの調整により大域最適解に近づけることが目標です。
鞍点とプラトー
特徴: 鞍点は勾配が0になるが最小値ではない点。プラトーは損失がほとんどまたは全く改善されない平坦な領域。
目的: 最適化プロセスの障害を理解し、克服する。
説明: 鞍点とプラトーは訓練の進行を妨げるが、モーメンタムや学習率の調整によりこれらの問題を緩和できる。
モーメンタム (Momentum)
特徴: 過去の勾配を考慮に入れて現在の更新を調整することで、勾配の更新に「運動量」を加える。
目的: 収束を加速し、局所最適解や鞍点を克服する。
説明: モーメンタムは勾配の更新に一種の慣性を与え、不要な方向への振動を抑えつつ、重要な方向へ効果的に進むことを助けます。
AdaGrad, AdaDelta, MSprop, Adam, AdaBound, AMSBound
特徴: 各々が勾配降下法のバリエーションであり、特に学習率の動的調整に焦点を当てる。
目的: 勾配のスケールに基づいて学習率を適応的に調整し、より効率的な最適化を実現する。
説明: これらのアルゴリズムは、特定の課題やデータセット特性に合わせて最適化プロセスをカスタマイズし、より迅速かつ効果的な収束を可能にします。例えば、Adamはモーメンタムと学習率の適応的調整を組み合わせ、広く使用されています。
AdaGrad
特徴: 個々のパラメータに対して異なるサイズの更新を適用するアダプティブ学習率アルゴリズム。
説明: AdaGradは、よく出現する特徴の学習率を低くし、まれな特徴の学習率を高く保つことで、効率的な学習が可能です。これにより、スパースデータに対する学習が効果的に行われます。
AdaDelta
特徴: AdaGradの拡張で、過去の全ての勾配情報を保持する代わりに、固定サイズのウィンドウに基づく勾配の累積を考慮する。
説明: AdaDeltaは、学習率の調整に勾配の情報を使用するが、勾配の累積が無限に成長することを防ぎます。これにより、長期間のトレーニングでも性能が安定します。
RMSprop
特徴: 勾配の二乗の指数移動平均を使用して学習率を調整するアルゴリズム。
説明: RMSpropはAdaGradの問題を解決するために開発され、各パラメータに対して個別の学習率を設定します。この方法は特に非定常目的関数に対して効果的です。
Adam
特徴: 勾配のモーメンタムとRMSpropの適応型学習率のアイデアを組み合わせたアルゴリズム。
説明: Adamは、勾配の一次モーメンタムと二次モーメンタムの両方を考慮し、非常に効率的な学習が可能です。多くのディープラーニングタスクでデファクトスタンダードとされています。
AdaBound
特徴: Adamの利点を保持しつつ、学習の最終段階でSGDのように振る舞うことを目指したアルゴリズム。
説明: AdaBoundは、学習過程でパラメータの更新が適切な範囲内に収まるように制限を加え、より安定した収束を実現します。(学習率の上限と下限を動的に加えた手法)
AMSBound
特徴: AdaBoundの一種で、より厳格に最適解に収束するように設計されている。
説明: AMSBoundは、特定の条件下での収束性を改善するために、適応的な制約を更に強化したものです。(学習率の上限と下限を動的に加えた手法)
ハイパーパラメータ
特徴: モデルの設計において事前に設定されるパラメータで、学習プロセスに影響を与える。
説明: ハイパーパラメータには学習率、エポック数、バッチサイズなどが含まれ、これらの適切な設定がモデルの性能を大きく左右します。
ランダムサーチ
特徴: ハイパーパラメータの最適値を見つけるためにランダムに値を選択し、評価する方法。
説明: ランダムサーチは、大域的な探索空間を効率的にカバーすることが可能で、多くの場合、より少ない試行で良いハイパーパラメータの組み合わせを見つけることができます。
グリッドサーチ
特徴: 事前に定義された複数のハイパーパラメータの組み合わせを体系적に試して最適なものを探す方法。
説明: グリッドサーチは計算コストは高いが、ハイパーパラメータの各組み合わせを網羅的に試すことができるため、最適な組み合わせを見つけ出す可能性が高いです。
確率的勾配降下法 (Stochastic Gradient Descent, SGD)
特徴: 各イテレーションでランダムに選ばれた一つのデータ点のみを使用して勾配を計算し、パラメータを更新する。
説明: SGDは計算効率が良く、大規模なデータセットに適しています。ランダムなデータ選択により局所最適解を避けやすいが、収束が不安定になることもあります。
SGDは、以下の式で表されるパラメータ更新式を用います。
θ_t+1 = θ_t - α * ∇L(θ_t, x_t, y_t)
ここで、
θ_t: t回目の更新後のパラメータ
α: 学習率
∇L(θ_t, x_t, y_t): t番目のデータ (x_t, y_t) における損失関数の勾配
x_t: t番目の入力データ
y_t: t番目の教師データ
SGDが向いていない状況(不向き)
確率的勾配降下法(SGD)は、機械学習において最も基本的な最適化アルゴリズムの一つですが、いくつかの状況では他のアルゴリズムの方が適している場合があります。以下に、SGDが向いていない状況をいくつか挙げます。
1. 凸関数でない損失関数
SGDは、凸関数の最小化にのみ適用できます。凸関数とは、任意の2点における接線区間がその2点よりも上にあるような関数です。損失関数が凸関数でない場合、SGDは局所解に収束する可能性が高くなります。局所解とは、真の最小値ではない解のことです。
2. 大規模なデータセット
SGDは、各イテレーションで1つのデータポイントのみを使用して更新を行うため、大規模なデータセットの学習には時間がかかる場合があります。大規模なデータセットを扱う場合は、ミニバッチSGDやAdamなどの他のアルゴリズムの方が効率的に学習できます。
3. 複雑なモデル
SGDは、シンプルなモデルの学習には効果的ですが、複雑なモデルの学習には時間がかかる場合があります。複雑なモデルを扱う場合は、L1正則化やL2正則化などの正則化手法と組み合わせて使用することで、過学習を防ぐことができます。
4. ノイズが多いデータ
SGDは、ノイズの影響を受けやすいという欠点があります。ノイズが多いデータを使用する場合、SGDは誤った方向に更新を行う可能性があります。ノイズが多いデータを使用する場合は、モーメンタムSGDやRMSpropなどの他のアルゴリズムの方が効果的に学習できます。
5. 勾配が不安定な場合
SGDは、勾配が不安定な場合にうまく機能しないことがあります。勾配が不安定な場合、SGDはジグザグな動きをする可能性があり、収束が遅くなります。勾配が不安定な場合は、Adamなどの他のアルゴリズムの方が効果的に学習できます。
SGDの代替案
上記のような状況では、SGDの代替となるアルゴリズムをいくつか紹介します。
ミニバッチSGD: ミニバッチSGDは、SGDの改良版であり、各イテレーションで複数のデータポイントを使用して更新を行います。これにより、大規模なデータセットの学習効率が向上します。
Adam: Adamは、勾配降下法とモーメンタム法を組み合わせたアルゴリズムです。Adamは、SGDよりも高速に収束し、局所解に陥る可能性が低くなります。
RMSprop: RMSpropは、勾配の二乗平均平方根に基づいて学習率を調整するアルゴリズムです。RMSpropは、勾配が不安定な場合に効果的です。
L1正則化/L2正則化: L1正則化とL2正則化は、モデルの複雑さを制御するための手法です。これらの手法は、過学習を防ぐのに役立ちます。
確率的勾配降下法 (SGD)のパラメータ更新式
確率的勾配降下法(Stochastic Gradient Descent, SGD)は、損失関数の勾配を用いてパラメータを更新する方法です。SGDは、データセットのすべてのサンプルを一度に使用するのではなく、ランダムに選択されたサンプルのサブセット(通常は1つのサンプル)を使用してパラメータを更新します。これにより、計算効率が向上し、大規模なデータセットでも扱いやすくなります。
SGDのパラメータ更新式
SGDのパラメータ更新式は次の通りです:
$$[\theta_{t+1} = \theta_t - \eta \nabla L(\theta_t, x_i, y_i)]$$
ここで:
$$\theta_t$$:時刻 ( t ) におけるモデルのパラメータです。
$$ \eta $$:学習率(learning rate)、すなわち各ステップでどれだけパラメータを更新するかを決定する正のスカラー値です。
$$( \nabla L(\theta_t, x_i, y_i) )$$:損失関数 ( L ) のパラメータ $$\theta_t$$ に対する勾配です。ここで $$ x_i, y_i $$ はランダムに選択された訓練データのサンプルとそのラベルです。
勾配の計算
損失関数の勾配 $$ \nabla L $$ は、選択されたサンプル $$ (x_i, y_i) $$ に対するモデルの予測誤差に基づいて計算されます。勾配は、損失関数が最も急な上昇方向を示し、パラメータをこの方向の逆に移動させることで損失を減少させることができます。
学習率の役割
学習率 $$ \eta $$ はSGDの重要なハイパーパラメータであり、その値によって学習プロセスの速度と収束の質が大きく影響を受けます。学習率が大きすぎると、最適な解を通り過ぎてしまうリスクがあります。一方で、学習率が小さすぎると、収束までに非常に長い時間がかかったり、局所的な最小値に陥る可能性があります。
SGDの利点と課題
SGDの主な利点は、そのシンプルさと効率の良さにあります。しかし、ノイズが多い勾配推定と学習率の適切な設定が必要という課題も持っています。そのため、実際にはSGDの発展形であるモーメンタムを用いたSGDや、Adamのようなより高度な最適化アルゴリズムがよく使用されます。これらは勾配のノイズを軽減し、より安定した収束を実現するための改良が加えられています。
勾配降下法の各種手法についての一覧
勾配降下法(Gradient Descent)は、最適化問題において広く使用されるアルゴリズムで、損失関数の勾配に基づいてパラメータを反復的に更新することで最小値を求める手法です。以下に、勾配降下法の主要なバリエーションとその派生元および派生先を一覧表にまとめました。
| 手法名 | 派生元 | 派生先 | 説明 |
|-------------------------|-------------------------|------------------------------|------------------------------------------------------------|
| 勾配降下法 (Gradient Descent) | - | 確率的勾配降下法 (SGD) | パラメータを全データの勾配に基づいて更新。 |
| 確率的勾配降下法 (SGD) | 勾配降下法 | ミニバッチ勾配降下法 | ランダムに選んだ1つのデータポイントの勾配に基づいてパラメータを更新。 |
| ミニバッチ勾配降下法 | 確率的勾配降下法 | モーメンタム、Adam | ランダムなサブセット(ミニバッチ)の勾配に基づいてパラメータを更新。 |
| モーメンタム | ミニバッチ勾配降下法 | Nesterov Accelerated Gradient | 前の更新を考慮に入れてパラメータを更新し、振動を減少させ加速する。 |
| Nesterov Accelerated Gradient | モーメンタム | Adam | モーメンタムをさらに改善し、未来の位置を予測して勾配を計算する。 |
| Adam | モーメンタム、RMSprop | - | モーメンタムと適応学習率の技術を組み合わせ、高効率な最適化を実現する。 |
| RMSprop | Adagrad | Adam | 学習率を適応的に調整し、各パラメータごとに異なる学習率を設定する。 |
| Adagrad | - | RMSprop | それぞれのパラメータに対して、その勾配の大きさに応じて学習率を調整する。 |
各手法の特徴
勾配降下法: シンプルで理解しやすいが、大規模データセットでは計算コストが高い。
確率的勾配降下法 (SGD): 高速だがノイジーな更新が問題となることがある。
ミニバッチ勾配降下法: SGDの利点を保ちつつ、ノイズを減らすことができる。
モーメンタム: 収束を加速させるが、適切なパラメータ設定が必要。
Nesterov Accelerated Gradient (NAG): モーメンタムよりも一般に効率的。
Adam: モーメンタムと適応的学習率を組み合わせ、多くの問題に対して効果的。
RMSprop: 勾配のスケールに応じて学習率を調整し、非凸最適化問題に強い。
Adagrad: 稀な特徴に大きな重みを与えることができるが、学習率が徐々に小さくなる問題がある。
これらの手法は、それぞれの問題やデータセットに最適な方法を選択することで、機械学習モデルの訓練効率と性能を最大化できます。
最急降下法 (Gradient Descent)
特徴: すべてのデータを使用して勾配を計算し、パラメータを更新する方法。
説明: 最急降下法はバッチ学習とも呼ばれ、確実な方向での最適化を行いますが、計算コストが高く、非常に大きなデータセットには不向きです。
バッチ学習
特徴: トレーニングデータ全体を使って一度にモデルを訓練する方法。
説明: バッチ学習では、一度の更新で全データの平均勾配を使用するため、安定した学習が可能ですが、メモリ消費が大きく、大規模なデータセットでは不利です。
ミニバッチ学習
特徴: トレーニングデータのサブセット(ミニバッチ)を使ってモデルを段階的に更新する方法。
説明: ミニバッチ学習はSGDとバッチ学習のバランスをとるアプローチで、計算効率と収束の安定性を両立させます。
オンライン学習
特徴: データを一つずつまたは小さなチャンクで順次処理し、逐次的にモデルを更新する学習方式。
説明: オンライン学習はデータが次々に入ってくる環境に適しており、リアルタイムでの学習や適応が可能です。
逐次学習(オンライン学習)の特徴
教師データを一つずつ、またはミニバッチと呼ばれる小さなグループで逐次的に与えて、最適な重みを計算していく手法です。
新しい事実や観測を基に、既に学習した概念や知識を洗練させていく方法です。
大量のデータを一度に処理する必要がなく、メモリ使用量が少なくて済むというメリットがあります。
ミニバッチ学習の特徴
ディープラーニングで頻繁に用いられる手法で、データをグループに分けて損失関数を計算し、学習を進めます。
バッチサイズが小さいほど処理負担が小さくなり、大きいほど負荷が大きくなります。
小さなデータのグループを指定した数だけ計算し、全ての訓練データの読み込みを行います。
計算コストの削減、パラメータ更新頻度の調整、過学習の防止などの効果が期待できます。
逐次学習とミニバッチ学習の比較
逐次学習は新しい事実に基づいて既存の知識を洗練させていく一方、ミニバッチ学習は大量のデータを効率的に処理することに適しています。
逐次学習はメモリ使用量が少なくて済むが、ミニバッチ学習は計算コストの削減や過学習の防止などの利点があります。
用途に応じて、これらの手法を使い分けることが重要です。
データリーケージ
特徴: 訓練データにテストデータの情報が混入すること。
説明: データリーケージはモデルの評価を不正確にし、実際の運用時のパフォーマンスが期待より低くなる原因となります。モデルの訓練とテストの際は、このリーケージを避けるために厳格なデータ管理が必要です。
学習目標:ディープラーニングの精度をさらに高めるべく考えられた数々のテクニックを理解する
ドロップアウト (Dropout)
特徴: 訓練中にランダムにネットワークのニューロンを無効化(ドロップアウト)すること。
目的: 過学習を防ぎ、モデルの汎化能力を向上させる。
説明: ドロップアウトは特に大規模なネットワークで有効で、訓練中に一部のニューロンの出力を0に設定することで、ネットワークがデータの少ない部分に依存しすぎるのを防ぎます。
早期終了 (Early Stopping)
特徴: 検証セットのパフォーマンスが改善されなくなった時点で訓練を停止する。
目的: 過学習を防ぎ、計算資源の無駄遣いを避ける。
説明: 早期終了は、訓練過程でモデルの性能が最も良かった時点を選択し、それ以降性能が低下しないように訓練を終了することで、過学習のリスクを軽減します。検証データに対する誤差が次第に大きくなる。
データの正規化・重みの初期化
特徴: 入力データを正規化し、ネットワークの重みを適切に初期化する。
目的: 訓練プロセスを安定化させ、効率的な学習を促進する。
説明: データの正規化は各特徴量のスケールを揃え、重みの初期化は勾配消失や爆発を防ぎ、最適化アルゴリズムが効率的に動作するようにします。
バッチ正規化 (Batch Normalization)
特徴: 各バッチにおいて、層の入力を正規化する技術。
目的: 訓練を安定化させ、学習速度を速める。
説明: バッチ正規化は内部共変量シフトを減少させ、モデルがより高い学習率で安定して学習できるようにします。
過学習 (Overfitting)
特徴: モデルが訓練データに過剰に適合してしまい、新しいデータに対する汎化能力が低下する現象。
目的: 汎用的で堅牢なモデルを作成するために過学習を避ける。
説明: 過学習を防ぐためには、ドロップアウトやデータ拡張、正則化手法などが用いられます。
アンサンブル学習 (Ensemble Learning)
特徴: 複数のモデルを組み合わせて予測を行う手法。
目的: 個々のモデルよりも優れた予測性能を実現する。
説明: アンサンブル学習は、バギング、ブースティング、スタッキングなどの手法を通じて、異なるモデルの予測を組み合わせることで、より正確な予測が可能になります。
ノーフリーランチの定理 (No Free Lunch Theorem)
特徴: すべての最適化問題に対して一概に優れたアルゴリズムは存在しないとする理論。
目的: アルゴリズム選択時のリアリティチェックとして機能する。
説明: この定理は、特定の問題に特化したアルゴリズムが、その問題に最も効果的である可能性が高いことを意味します。適切なモデルやアルゴリズムの選択が重要です。
二重降下現象 (Double Descent Phenomenon)
特徴: モデルの複雑さが増すにつれて性能が一度低下した後、再び改善する現象。(検証データに対する誤差が降下した後に一度上昇し、再び降下する現象)
目的: モデル選択と複雑さの理解を深める。
説明: この現象は、過学習の概念を再評価させ、特に大きなモデルでは、ある点を超えると再び性能が向上することを示します。
正規化 (Regularization)
特徴: モデルの複雑さにペナルティを加えることで、過学習を抑制する技術。
目的: モデルの汎化性を向上させる。
説明: 正規化にはL1、L2正則化などがあり、これらはモデルの重みを制限することで、よりシンプルで汎用性の高いモデル構築を助けます。
標準化 (Standardization)
特徴: データから平均を引き、標準偏差で割ることにより、平均0、分散1のデータに変換する。
目的: 異なる特徴量間のスケールの違いをなくし、モデルの訓練を容易にする。
説明: 標準化は、特に勾配降下法のような最適化アルゴリズムにおいて、収束速度を速めるのに有効です。
データの平均が0、分散が1となるよう変換する処理
白色化 (Whitening)
特徴: データの各特徴が単位分散を持ち、相互に無相関になるように変換するプロセス。
目的: モデルの学習をより効率的に行うため。
説明: 白色化を行うことで、データの冗長性を減少させ、特徴間の相互依存性を排除します。これにより、深いネットワークの学習がより効率的に進行します。
荷重減衰
重減衰(Weight Decay)は、まるで料理にスパイスを加えるように、深層学習モデルの精度と汎化性能を向上させる魔法のスパイスのようなものです。適切な量を調整することで、モデルをより洗練させ、様々な状況に柔軟に対応できる能力を高めることができます。
荷重減衰には、以下のような利点があります。
過学習の抑制: モデルが訓練データに過学習しすぎるのを防ぎ、汎化性能を向上させることができます。
モデルの簡素化: モデルをシンプルにすることで、計算量を削減し、学習速度を向上させることができます。
ノイズの影響の軽減: 訓練データに含まれるノイズの影響を受けにくくすることができます。
荷重減衰の仕組み
ディープラーニングの手法
学習目標:CNN の構造を理解し、各層の役割と層間のデータの流れについて理解する。
CNN の基本形 (Basic Form of CNN)
特徴: 畳み込み層、プーリング層、全結合層から構成される典型的なニューラルネットワークの一種。
目的: 画像認識や画像分類に特化した構造を持ち、パラメータの共有と局所的な接続により効率的な学習が可能。
説明: CNNは主に視覚的なタスクに用いられ、畳み込み層で特徴を抽出し、プーリング層で特徴を圧縮し、全結合層で分類を行います。
畳み込み層 (Convolutional Layer)
特徴: 画像の局所的な特徴を抽出するためのフィルター(カーネル)を用いて畳み込み演算を行う層。
目的: 入力画像から特徴を抽出し、次の層へのデータ量を圧縮しつつ、重要な情報を保持する。
説明: 畳み込み層はフィルタを画像に適用し、画像の特定の特性(エッジ、形、テクスチャなど)を活性化マップとして出力します。
プーリング層 (Pooling Layer)
特徴: 活性化マップのサイズを減少させるために、特定の領域から最大値または平均値を取り出す。
目的: 特徴の次元を減らし、計算量を削減し、特徴の位置に対する感度を低下させる。
説明: プーリング層は、画像の小さな変形に対しても同じ特徴を捉えられるようにすることで、モデルの汎用性を向上させます。
全結合層 (Fully Connected Layer)
特徴: ネットワークの最後に配置され、畳み込み層やプーリング層で得られた特徴を基に最終的な分類や回帰を行う。
目的: 畳み込み層やプーリング層で抽出された特徴を用いて、具体的なタスク(分類、回帰)のための出力を生成する。
説明: 全結合層は、前層からのすべての活性化を入力として受け取り、それらを重み付けして目的の出力(例えばクラスの確率)を計算します。
データ拡張 (Data Augmentation)
特徴: トレーニングデータを人工的に増やすために、既存のデータに様々な変形を加える技術。
目的: モデルの汎用性を向上させ、過学習を防ぐ。
説明: データ拡張には、画像を回転させる、反転させる、色調を変更するなどの手法があり、これによりデータの多様性が増し、より堅牢なモデルが訓練されます。ただし加工前後で認識結果が変わらない程度にする。
CNN の発展形 (Advanced Forms of CNN)
特徴: 基本的なCNNアーキテクチャを改良し、さまざまな応用に適した形にカスタマイズされたもの。
目的: 特定の課題やデータに合わせた最適なパフォーマンスを達成する。
説明: CNNの発展形には、ResNet、InceptionNet、DenseNetなどがあり、これらは層を深くすることで精度を向上させたり、計算リソースの使用を効率化したりしています。
Deep CNNにおける変形に対して頑強な特徴表現の獲得:詳細解説
Deep CNNは、畳み込みニューラルネットワーク(Convolutional Neural Network)の略称であり、画像認識分野において卓越した性能を誇るディープラーニングモデルです。
本記事では、Deep CNNがどのように変形に対して頑強な特徴表現を獲得するのかについて、詳細に解説します。
1. 変形に対する頑強性の重要性
画像認識において、変形に対する頑強な特徴表現を獲得することは非常に重要です。
というのも、現実世界における画像は、様々な変形を受けやすいからです。
具体的には、以下のような変形が考えられます。
回転: 画像が回転される
拡大縮小: 画像が拡大または縮小される
移動: 画像が移動される
歪み: 画像が歪められる
照明: 画像の照明が変化する
これらの変形によって、画像の見た目は大きく変化しますが、本来持つべき情報は変化しません。
Deep CNNは、これらの変形に対して頑強な特徴表現を獲得することで、変形された画像であっても、正しい認識を行うことができます。
2. Deep CNNによる変形に対して頑強な特徴表現の獲得方法
Deep CNNは、以下の3つの主要なメカニズムによって、変形に対して頑強な特徴表現を獲得します。
2.1 局所的な特徴抽出
Deep CNNは、畳み込み層と呼ばれる独自のパラメータ層を持つことが特徴です。
畳み込み層は、入力画像とフィルタと呼ばれる小さな行列を畳み込み、特徴量マップを生成します。
この特徴量マップは、入力画像の局所的な特徴を抽出します。
局所的な特徴とは、画像の一部領域にのみ存在する特徴です。
例えば、画像中に猫がいる場合、猫の顔、目、耳などの局所的な特徴が抽出されます。
局所的な特徴は、変形に対して比較的頑強です。
というのは、変形によって画像全体が大きく変化しても、局所的な特徴は変化することが少ないからです。
2.2 プーリング層による空間情報の圧縮
Deep CNNは、プーリング層と呼ばれる層を用いることで、空間情報の圧縮を行います。
プーリング層は、特徴量マップを縮小し、計算量を削減します。
具体的には、プーリング層は、特徴量マップ内の各セルに対して、最大値や平均値などの処理を行い、新しいセル値を生成します。
プーリング層による空間情報の圧縮は、変形に対して頑強な特徴表現を獲得する上で重要な役割を果たします。
というのも、プーリング層によって、局所的な特徴が空間的な制約から解放されるからです。
例えば、プーリング層によって、猫の顔の位置が変化しても、猫の顔という局所的な特徴は維持されます。
2.3 非線形活性化関数の導入
Deep CNNは、非線形活性化関数と呼ばれる関数を用いることで、モデルの表現力を向上させます。
代表的な非線形活性化関数として、ReLU関数やSigmoid関数などが挙げられます。
非線形活性化関数は、入力と出力が線形関係ではないことを意味します。
これにより、Deep CNNは、画像中の複雑なパターンを表現することが可能になります。
非線形活性化関数の導入は、変形に対して頑強な特徴表現を獲得する上で重要です。
というのは、変形によって、画像中の複雑なパターンが変化しても、非線形活性化関数によって、そのパターンを抽象化して表現することができるからです。
3. Deep CNNにおける変形に対して頑強な特徴表現の利点
Deep CNNが変形に対して頑強な特徴表現を獲得することで、以下の利点が得られます。
認識精度: 変形された画像であっても、高い認識精度を実現できます。
汎化性能: 様々な変形に耐性を持つため、汎化性能が向上します。
データ効率: 少ない学習データで高精度なモデルを学習できます。
4. まとめ
Deep CNNは、畳み込み層、プーリング層、非線形活性化関数などのメカニズムによって、変形に対して頑強な特徴表現を獲得することができます。
転移学習とファインチューニング (Transfer Learning and Fine-tuning)
特徴: 一つのタスクで学習したモデルの知識を、別の関連するタスクに適用する手法。
目的: 既存の学習済みモデルを新しいタスクに迅速に適用し、少ないデータで高いパフォーマンスを達成する。
説明: 転移学習では、例えば画像認識で広く学習されたモデルを特定の分野の画像に適用し、最後の数層を新しいデータでファインチューニングすることが一般的です。
ネオコグニトロン (Neocognitron)
特徴: 自己組織化により学習するニューラルネットワークで、畳み込みニューラルネットワークの先駆けとされる。
目的: 手書き数字認識などのパターン認識タスクにおいて、ロバストな特徴抽出を実現する。
説明: ネオコグニトロンは複数の層を持ち、各層は特定の特徴を学習するために設計されており、画像からのパターン認識に特化しています。
特徴抽出は、多層回路の各層で、特徴の抽出と統合を繰り返しながら次第に高次の特徴を抽出していきます。この特徴抽出は、「add-if-silent」則と呼ばれる学習法を用いて行われます。
※誤差逆伝搬法は用いない。
ネオコグニトロンは、1982年に福島邦彦氏によって発表された人工ニューラルネットワークモデルの一つです。
畳み込みニューラルネットワーク(CNN)の原型として知られており、画像認識分野において特に重要な役割を果たしてきました。ネオコグニトロンは、生物の視覚皮質の構造と機能にインスパイアされたモデルであり、その後の畳み込みニューラルネットワーク(CNN)の発展にも大きな影響を与えたとされています。
ネオコグニトロンの構造
ネオコグニトロンは、複数の層を持つ階層的なネットワーク構造をしています。主に以下のような層から構成されます:
S層(単純細胞層):畳み込み
S層は、局所的な受容野を持ち、特定の特徴(例えばエッジや角)に対して応答します。この層は特徴抽出の役割を果たし、異なる位置で同じ特徴に対しても反応するように学習されます。
C層(複雑細胞層):プーリング
C層はS層の出力を受け取り、位置のずれに対して頑健な応答をします。つまり、特徴が画像内でわずかに移動しても、同じように反応することができます。この層は特徴の位置不変性を高める役割を担います。
LeNet
特徴: 1990年代に提案された初期の畳み込みニューラルネットワークで、手書き数字認識に成功した。
LeNetの特徴
LeNetは、1998年にYann LeCun氏らによって開発された畳み込みニューラルネットワーク(CNN)のモデルです。手書き文字認識タスクで非常に高い精度を達成し、CNNのパイオニア的なモデルとして広く知られています。
LeNetの特徴は以下の通りです。
1. 畳み込み層とプーリング層の導入
LeNetは、畳み込み層とプーリング層というCNNの基本的な構成要素を初めて導入したモデルです。畳み込み層は、入力データに対して空間的なフィルタを適用することで、特徴抽出を行います。プーリング層は、畳み込み層の出力を縮小することで、計算量を削減し、過学習を防ぎます。
2. 重み共有
LeNetは、畳み込み層のフィルタにおいて重み共有という手法を用いています。重み共有とは、複数のフィルタで同じ重みを使用する方法です。これにより、モデルのパラメータ数を大幅に削減し、学習効率を向上させることができます。
3. 非線形活性化関数の導入
LeNetは、畳み込み層と全結合層の間でシグモイド関数を用いることで、非線形性を導入しています。非線形性を導入することで、モデルがより複雑なパターンを学習することができます。
4. 多層構造
LeNetは、畳み込み層とプーリング層を複数層重ねることで、階層的な特徴抽出を実現しています。これにより、モデルがより高レベルな特徴を学習することができます。
目的: 小規模な画像データから効率的に特徴を抽出し、認識タスクを実行する。
説明: LeNetは畳み込み層とサブサンプリング層を交互に配置し、最終的に全結合層を通じて分類を行う構造です。
サブサンプリング層 (Subsampling Layer)
特徴: 特徴マップの空間サイズを減少させる層で、通常プーリング層として知られる。
目的: 特徴マップの次元を削減し、計算量を減少させる。
説明: サブサンプリング層では、最大値プーリングや平均値プーリングなどが用いられ、画像のローカルな情報を保持しつつデータ量を減らします。
畳み込み (Convolution)
特徴: 入力データに対してフィルタ(またはカーネル)を適用し、局所的な特徴を抽出する操作。
目的: 画像や音声などのデータから重要な特徴を効果的に捉える。
説明: 畳み込み操作は、フィルタをスライドさせながらデータに適用し、フィルタによって強調された特徴のマップを生成します。
フィルタ (Filter)
特徴: 畳み込み層で使用される小さな行列で、特定の特徴を入力データから抽出するために設計されている。
目的: 画像からエッジ、テクスチャなどの特定の視覚的特徴を検出する。
説明: フィルタは畳み込み層を通じてデータを処理し、活性化マップを生成することでデータの有用な特徴を際立たせます。
最大値プーリング (Max Pooling)
特徴: プーリング層の一種で、処理対象領域の最大値を選択する。
目的: データの特徴を圧縮しつつ、最も顕著な特徴を保持する。
説明: 最大値プーリングは特に強いシグナルを持つ特徴を強調し、モデルの過学習を防ぐのに役立ちます。
平均値プーリング (Average Pooling)
特徴: 処理対象領域の平均値を計算して使用するプーリング手法。
目的: 特徴マップを平滑化し、主要な特徴を損なわずに次元を削減する。
説明: 平均値プーリングは特徴の一般的な平均表現を提供し、画像内のバックグラウンドノイズを抑える効果があります。
グローバルアベレージプーリング (GAP)
特徴: 各特徴マップの平均値を計算し、それを特徴として利用する。
目的: 全結合層を置き換え、パラメータ数を削減することでモデルを軽量化し、過学習を防ぐ。
説明: GAPは特にディープラーニングモデルの最終層で利用され、特徴マップの空間的な情報を圧縮し、クラスごとの代表的な特徴を抽出します。
Cutout
特徴: トレーニング画像からランダムに一部を切り取る(マスクする)データ拡張技術。
目的: モデルが画像の局部的な特徴に過度に依存することを防ぎ、ロバストな学習を促進する。
説明: Cutoutは画像の一部をゼロで塗りつぶし、ネットワークが画像の残りの部分から情報を抽出する能力を強化します。
Random Erasing
特徴: 画像のランダムな領域をランダムな値で塗りつぶすデータ拡張技術。
目的: モデルの汎用性を向上させ、過学習を防止する。
説明: Random ErasingはCutoutに似ていますが、塗りつぶす値をランダム化し、さらにデータの多様性を高めます。
Mixup
特徴: 二つの異なる画像とそのラベルを線形に混合するデータ拡張手法。
目的: モデルがより汎用的な特徴を学習し、過学習を防ぐ。
説明: Mixupはトレーニングデータの組み合わせから新しいサンプルを生成し、モデルが異なる特徴間の関連をより良く理解するのに役立ちます。
CutMix
特徴: 一つの画像に別の画像のパッチを挿入するデータ拡張手法。
目的: 複数のコンテキストを同時に学習し、モデルの汎化能力を向上させる。
説明: CutMixは画像の一部を別の画像で置き換えることで、より困難なトレーニングサンプルを作成し、ロバストな特徴学習を促進します。
MobileNet
特徴: 軽量で高効率なニューラルネットワークアーキテクチャ。Depthwise Separable Convolutionを利用。軽量だが小型端末用ではない
目的: モバイルデバイスやエッジデバイスでのリアルタイム画像処理を可能にする。
説明: MobileNetは計算量とパラメータ数を大幅に削減しつつ、高い精度を維持する設計が特徴です。
MobileNET:軽量で高性能なCNNモデル
MobileNETは、Googleが開発した畳み込みニューラルネットワーク(CNN)モデルです。2017年に発表されて以来、スマートフォンなどのモバイル端末上で動作する軽量かつ高性能なCNNモデルとして広く利用されています。
MobileNETの特徴
MobileNETの特徴は以下の通りです。
軽量性: 従来のCNNモデルと比べて、計算量とメモリ使用量を大幅に削減することができます。
高精度: 軽量モデルでありながら、画像分類や物体検出などのタスクにおいて高い精度を維持することができます。
汎用性: 画像分類、物体検出、画像セグメンテーションなど、様々なタスクに適用することができます。
転移学習: ImageNetなどの大規模なデータセットで事前学習されたモデルを転移学習として利用することができます。
MobileNETのアーキテクチャ
MobileNETは、以下の3つの主要なコンポーネントで構成されています。
Depthwise Separable Convolutions: 従来の畳み込み層を、Depthwise ConvolutionとPointwise Convolutionの2つの層に分解することで、計算量を削減します。
Squeeze-and-Excite Blocks: 各畳み込み層の後段に、チャネル間の相互作用を学習するSqueeze-and-Excite Blocksを挿入することで、モデルの表現力を向上させます。
Linear Bottleneck: 各畳み込み層の前段に、入力チャネル数を削減するLinear Bottleneckと呼ばれる構造を挿入することで、モデルの軽量化を図ります。
MobileNETのバージョン
MobileNETには、v1、v2、v3の3つの主要なバージョンがあります。
MobileNET v1: 2017年に発表された最初のMobileNETモデルです。
MobileNET v2: 2018年に発表されたMobileNET v1の後継モデルです。Squeeze-and-Excite Blocksの導入など、様々な改良が加えられています。
MobileNET v3: 2019年に発表されたMobileNET v2の後継モデルです。Linear Bottleneckの導入など、さらなる軽量化と精度向上が図られています。
MobileNETの応用例
MobileNETは、以下の様な様々な応用分野で利用されています。
モバイルアプリ: 顔認証、画像分類、物体検出など
IoT機器: 画像認識、音声認識など
エッジコンピューティング: ローカルでの画像処理、物体認識など
MobileNETは、軽量で高性能なCNNモデルとして、様々な分野で幅広く利用されています。今後も研究開発が進み、さらに性能が向上していくことが期待されています。
Depthwise Separable Convolution
特徴: 畳み込みを深さごとの畳み込みと1x1の畳み込みに分けて効率化する。
目的: 計算コストとパラメータの数を削減する。
説明: この手法はまず入力チャンネルごとに空間的な畳み込みを行い、次に1x1の畳み込みを通じてチャンネル間の特徴を統合します。これにより、効率的なネットワーク設計が可能になります。
NAS (Neural Architecture Search)
特徴: ニューラルネットワークのアーキテクチャを自動で設計する技術。
目的: 最適なネットワーク構造を自動的に発見し、人手による設計プロセスを削減する。
説明: NASは様々なネットワーク設計を試行し、与えられたタスクに最適なアーキテクチャを選択することで、性能を最大化します。
NAS(Neural Architecture Search):詳細な説明
ニューラルアーキテクチャサーチ(NAS)は、機械学習における重要な手法の一つです。従来の機械学習では、人間が手動でニューラルネットワークのアーキテクチャ(層の構成やニューロン数など)を設計していましたが、NASは自動的に最適なアーキテクチャを探索する手法です。
NASの仕組み
NASは、以下の2つの主要な要素で構成されています。
探索アルゴリズム: さまざまなニューラルネットワークのアーキテクチャを生成するアルゴリズムです。
評価アルゴリズム: 生成されたアーキテクチャの性能を評価するアルゴリズムです。
探索アルゴリズムは、ランダムサーチ、強化学習、進化アルゴリズムなど、さまざまな手法を用いることができます。評価アルゴリズムは、通常は精度や計算時間などの指標を用いて、生成されたアーキテクチャの性能を評価します。
NASは、探索アルゴリズムと評価アルゴリズムを繰り返すことで、徐々に最適なアーキテクチャに近づいていきます。
NASの利点
NASには、以下の利点があります。
人間によるバイアスを排除: 人間が手動で設計した場合に比べて、より客観的に最適なアーキテクチャを探索することができます。
複雑なアーキテクチャの探索: 人間が手動で設計するのは難しい、複雑なアーキテクチャを探索することができます。
新しいアーキテクチャの発見: これまでに知られていなかった、新しい高性能なアーキテクチャを発見することができます。
NASの課題
NASには、以下の課題もあります。
計算コスト: 多くのアーキテクチャを探索するため、計算コストが高くなります。
データ量: 多くのデータが必要となるため、データ収集が難しい場合があります。
解釈性: 探索されたアーキテクチャがなぜ高性能なのかを理解するのが難しい場合があります。
NASの応用例
NASは、以下の様な様々な応用分野で利用されています。
画像認識: 画像分類、物体検出、セマンティックセグメンテーションなど
自然言語処理: 機械翻訳、質問応答、要約生成など
音声認識: 音声認識、音声合成、音声翻訳など
ロボット工学: ロボット制御、物体操作、ナビゲーションなど
NASとAutoMLの関係
**NAS(Neural Architecture Search)とAutoML(Automated Machine Learning)**は、どちらも機械学習における重要な手法ですが、それぞれ異なる役割と特徴を持っています。
NASは、ニューラルネットワークのアーキテクチャ(層の構成やニューロン数など)を自動的に探索する手法です。一方、AutoMLは、データ前処理、モデル選択、ハイパーパラメータ調整などの機械学習の作業を自動化するフレームワークです。
関係性
NASとAutoMLは、以下の点で密接に関係しています。
共通の目標: NASとAutoMLは、どちらも高精度な機械学習モデルを自動的に構築するという共通の目標を持っています。
相補的な関係: NASは、AutoMLが選択したモデルのアーキテクチャを最適化するために使用することができます。一方、AutoMLは、NASが探索したアーキテクチャを効率的に評価するために使用することができます。
統合的な利用: NASとAutoMLを組み合わせることで、より効率的かつ効果的に高精度なモデルを構築することができます。
ニューロモーフィクス:生物脳の仕組みを模倣した人工知能
ニューロモーフィクス(Neuromorphic Computing)は、生物の脳の仕組みを模倣した人工知能の研究分野です。従来の人工知能は、論理演算や統計学に基づいて設計されていましたが、ニューロモーフィクスでは、生物脳のニューロンやシナプスの構造と機能を模倣することで、より高性能で省電力な人工知能の開発を目指しています。
ニューロモーフィクス研究の目的
ニューロモーフィクス研究の主な目的は以下の通りです。
生物脳の仕組みを理解する: 生物脳の仕組みを理解することで、より高性能な人工知能を開発することができます。
より高性能な人工知能を開発する: 生物脳の仕組みを模倣することで、従来の人工知能よりも高性能で省電力な人工知能を開発することができます。
新しいコンピューティングアーキテクチャを開発する: 生物脳の仕組みを模倣することで、従来のコンピュータアーキテクチャとは異なる、新しいコンピューティングアーキテクチャを開発することができます。
EfficientNet
特徴: スケーリング法を用いて、深さ、幅、解像度のバランスをとることで効率的にネットワークをスケーリングするアーキテクチャ。
目的: 限られたリソースで最大の効率と精度を達成する。
説明: EfficientNetはベースネットワークをシステマティックにスケーリングすることにより、さまざまなデバイスやアプリケーションに適応可能なモデルを提供します。
EfficientNetは、機械学習の分野で注目されているニューラルネットワークアーキテクチャの一つで、特にそのスケーラビリティと効率性により広く認知されています。2019年にGoogle AIの研究者によって初めて提案され、画像分類タスクにおいて高い精度と効率を実現しています。
EfficientNetの主要な特徴
コンパウンドスケーリング:
EfficientNetの最も重要な特徴は、幅、深さ、解像度の3つの次元にわたってネットワークを均一にスケーリングすることです。この方法は、モデルのサイズが大きくなるにつれて、これらの次元をバランス良く拡張することを可能にし、性能向上を図ります。
基礎モデルとしてのEfficientNet-B0:
B0モデルは、スケーリングの基準となるベースラインモデルであり、他のEfficientNetモデル(B1からB7)は、このB0モデルを基にスケールアップされています。
性能と効率のトレードオフ:
EfficientNetは、少ない計算資源で高い性能を達成するよう設計されています。これにより、モバイルデバイスやリソースが限られた環境でも使用可能です。
AutoMLによる設計:
ネットワークアーキテクチャは、GoogleのAutoML MNASフレームワークを使用して自動的に設計されました。これにより、人間の直感に頼ることなく、最適なネットワーク構造が求められます。
Swish活性化関数:
EfficientNetはReLUの代わりにSwish活性化関数を使用しています。Swishは、特定のタスクにおいてReLUよりも優れた性能を示すことが報告されています。
Mobile Inverted Residual Bottleneck (MBConv):
MBConvブロックは、モバイルネットワークに最適化された反転残差構造を使用しており、軽量で効率的なモデル設計を実現しています。
DropConnect:
DropConnectは、モデルの過学習を防ぐために使用される正則化手法で、トレーニング中にネットワークの重みの一部をランダムに0に設定します。
データ拡張の利用:
トレーニング中にAutoAugmentというデータ拡張技術を利用することで、モデルが多様なデータに対して頑健になるよう助けています。
NASNet、MnasNet
特徴: NASを利用して最適化されたネットワークアーキテクチャ。
目的: 特定の計算予算またはパフォーマンス基準に基づいて、最適なネットワーク構造を自動で設計する。
説明: NASNetとMnasNetは、それぞれ異なるパフォーマンス指標に基づいて設計されており、例えばMnasNetはモバイルデバイスの効率を重視しています。
転移学習 (Transfer Learning)
特徴: 一つのタスクで訓練されたモデルの知識を、別のタスクに適用する手法。
目的: 訓練時間とデータ要件を減らし、新しいタスクでの学習効率と性能を向上させる。
説明: 転移学習は、特にデータが限られている場合に有効で、事前に大量のデータで訓練されたモデルを新しいタスクにファインチューニングして使用します。
局所結合構造 (Locally Connected Structure)
特徴: 各ニューロンが入力の小さな局所的な領域にのみ接続される構造。
目的: 画像などのデータ内の局所的な情報を効果的に捉える。
説明: 局所結合構造は、全結合層よりもパラメータの数を大幅に減少させ、画像内の局所的な特徴をより効果的に抽出します。
ストライド (Stride)
特徴: 畳み込みやプーリング操作を行う際にフィルタが入力データ上を移動する距離。
目的: 特徴マップのサイズを調整し、演算の効率を向上させる。
説明: ストライドは、特に大きな画像を処理する際に、出力の空間的な次元を効果的に縮小し、計算コストを削減します。
カーネル幅 (Kernel Width)
特徴: 畳み込み層で使用されるフィルタの幅(またはサイズ)。
目的: 畳み込みによる特徴抽出の範囲と精度を定義する。
説明: カーネル幅はフィルタが捉える入力データの範囲を決定し、より大きなカーネルはより広い領域から情報を抽出しますが、計算コストも増加します。
プーリング (Pooling)
特徴: 特徴マップのサイズを縮小し、重要な特徴を保持しながら冗長性を減らす操作。
目的: モデルの計算負荷を軽減し、画像の小さな変形に対するロバスト性を向上させる。
説明: プーリングには最大値プーリングや平均値プーリングがあり、それぞれが異なる方法で特徴を圧縮します。
スキップ結合 (Skip Connection)
特徴: 異なる層間で直接的な接続を行い、入力を後の層へ直接渡す構造。
目的: 勾配消失問題を緩和し、深いネットワークの訓練を効果的に行う。
説明: スキップ結合は、例えばResNetで広く用いられ、より深いネットワークでも安定して学習が進行するように支援します。
各種データ拡張 (Various Data Augmentation)
特徴: 画像を回転させる、サイズを変更する、色彩を調整するなど、データセットを人工的に増やす技術。
目的: モデルの過学習を防ぎ、汎用性を高める。
説明: データ拡張はトレーニングデータの多様性を高めることで、モデルが新しい未見のデータに対しても良好な性能を発揮するようにします。
パディング (Padding)
特徴: 入力データの周囲に特定の値(通常はゼロ)を追加すること。
目的: 畳み込み操作でサイズが縮小するのを防ぎ、端の情報を適切に利用する。
説明: パディングは畳み込み層の入力データの各辺にゼロなどの固定値を追加することで、出力サイズの調整と特徴の損失を防ぎます。
Cutout、Random Erasing、Mixup、CutMixの違い
Cutout、Random Erasing、Mixup、CutMixはすべてデータ拡張技術で、ディープラーニングモデルのトレーニング中に使用されますが、それぞれ異なるアプローチを取ります。


Cutoutでは、対象となるマスクの大きさや形状(正方形が一般的)は事前に設定するか、画像の一定比率に基づいて動的に決定されます。この方法はシンプルであり、実装が容易です。
Random Erasingでは、より動的なアプローチが取られます。マスクの大きさ、形状、アスペクト比が各画像ごとにランダムに決定され、これによりモデルが異なる種類のデータ摂動に対して頑健になることが期待されます。
CutMixは、マスク処理ではなくパッチ交換を行いますが、対象となるパッチの大きさやアスペクト比が重要です。この手法では、一つの画像から切り取ったパッチを別の画像に貼り付け、その際に元の画像の内容とのバランスを取ることが求められます。
各データ拡張技術がモデルのトレーニングにどのように影響を与えるかの理解が深まります。CutoutとRandom Erasingは画像内の特定の部分を直接操作することでデータを拡張しますが、MixupとCutMixは二つの異なるデータサンプルを組み合わせることによって新しい学習材料を生成します。これにより、モデルがより汎用的な特徴を学習し、実際の世界での応用において高い柔軟性とロバスト性を発揮することが期待されます。
Cutout、Random Erasing、Mixup、CutMix できた順
ディープラーニングにおいて、データ拡張技術はモデルの汎化性能を向上させる重要な手段の一つです。ここで挙げられた「Cutout」、「Random Erasing」、「Mixup」、「CutMix」は、画像データに対する革新的な拡張技術であり、特に画像認識タスクで効果を発揮します。これらの技術が提案された順番は以下の通りです:
Mixup:
発表年:2017年
説明:Mixupは、異なる画像を線形に重ね合わせることで新しい画像を生成する手法です。このプロセスでは、画像だけでなく、それに対応するラベルも同様に重ね合わされます。これにより、モデルがデータ間の線形補間を学習し、より滑らかな決定境界を形成することが促されます。
Cutout:
発表年:2017年
説明:Cutoutは画像からランダムな領域を切り取る(マスキングする)ことでデータを拡張する手法です。このシンプルなアプローチは、モデルが部分的に隠されたオブジェクトを認識する能力を向上させるのに役立ちます。
Random Erasing:
発表年:2017年後半から2018年にかけての議論
説明:Random Erasingは、Cutoutに似ていますが、ここではランダムに選ばれた矩形領域をランダムなピクセル値で塗りつぶすことにより画像を拡張します。このランダム性はモデルが過度に特定のパターンや位置に依存することなく、よりロバストな特徴を捉えるのに役立ちます。
CutMix:
発表年:2019年
説明:CutMixは、一部の画像領域を他の画像の同じ位置の領域で置き換えることにより新しい画像を生成します。この方法では、置き換えられた領域のラベルも適切に混合されます。CutMixは、局所的な画像情報とラベルの関連性を保ちつつ、モデルの注意を散らすことで、より堅牢な学習を促進します。
これらの手法はいずれも、トレーニングデータの多様性を高め、モデルの過学習を防ぎながら認識精度を向上させることを目的としています。それぞれが異なるアプローチを取ることで、さまざまなシナリオにおいて有効に機能します。
NASNetとMnasNetの違い
NASNetとMnasNetはどちらもニューラルアーキテクチャサーチ(NAS)を利用して開発されたニューラルネットワークモデルですが、それぞれ異なる目的と特性を持っています。以下の表で、これら二つの技術を比較します
この表から、NASNetが一般的に高性能なアーキテクチャを求めるためのモデルであるのに対して、MnasNetは特にモバイルデバイスでの使用を念頭に置いた効率的なモデル設計を目指していることがわかります。MnasNetのアプローチでは、モデルの速度やエネルギー効率などの追加的なパラメータが最適化の対象となり、リアルワールドアプリケーションでの実用性が高まります。NASNetは計算資源を多く消費する環境で最大のパフォーマンスを発揮する設計となっています。
NASNetの特徴
NASNetは、AutoML(自動機械学習)の一種である**ニューラルアーキテクチャサーチ(NAS)**を用いて開発された畳み込みニューラルネットワーク(CNN)アーキテクチャです。
2017年にGoogle AIによって開発され、ImageNet ILSVRC 2017画像分類コンペティションにおいて、当時の最先端モデルを上回る精度を達成しました。
NASNetの概要
NASNetは、Google Brain Teamによって開発された自動機械学習(AutoML)を用いて設計された畳み込みニューラルネットワーク(CNN)です。
NASNetの特徴
自動設計: AutoMLを用いて、Normal Cellとよばれる基本セルと、Reduction Cellと呼ばれる縮小セルを自動的に設計しています。
柔軟な入力サイズ: Normal Cellは入力サイズに合わせて出力サイズを変化させることができるため、様々な入力サイズに対応できます。
ImageNetで事前学習: NASNet-Mobileは、ImageNetデータセットの100万枚以上の画像で事前学習されています。
汎用性の高い特徴学習: ImageNetやCOCOデータセットで学習した特徴は、多くのコンピュービジョンタスクで活用できると考えられています。
NASNetの特徴は以下の通りです。
1. 高精度
ImageNet ILSVRC 2017画像分類コンペティションにおいて、当時の最先端モデルを上回る82.7%のトップ5精度を達成しました。
2. 軽量性
MobileNetよりも少ないパラメータ数で、同等の精度を実現しています。
3. 汎用性
ImageNet以外にも、COCO物体検出、Cityscapesセマンティックセグメンテーションなど、様々なタスクで高い精度を達成しています。
4. 探索アルゴリズム
NASNetは、強化学習を用いた探索アルゴリズムを用いて開発されています。この探索アルゴリズムは、効率的に最適なアーキテクチャを探索することができ、NASNetの高い精度と軽量性を実現する要因の一つとなっています。
5. セル構造
NASNetは、Normal CellとReduction Cellと呼ばれる2種類のセル構造を用いて構成されています。Normal Cellは入力と同じサイズの特徴マップを出力する畳み込みレイヤーで、Reduction Cellは入力よりもサイズが2の倍数で削減された特徴マップを出力する畳み込みレイヤーです。
6. Controller RNN
NASNetは、Controller RNNと呼ばれる再帰ニューラルネットワークを用いて、Normal CellとReduction Cellを組み合わせる方法を決定します。Controller RNNは、過去のアーキテクチャと性能を考慮して、最適なアーキテクチャを決定することができます。
7. 転移学習
NASNetは、ImageNetで事前学習されたモデルをベースとして、転移学習を用いて様々なタスクに適用することができます。
NASNetの応用例
NASNetは、以下の様な様々な応用分野で利用されています。
画像認識: 画像分類、物体検出、セマンティックセグメンテーションなど
自然言語処理: 機械翻訳、質問応答、要約生成など
音声認識: 音声認識、音声合成、音声翻訳など
ロボット工学: ロボット制御、物体操作、ナビゲーションなど
MnasNetの特徴
MnasNetは、AutoML(自動機械学習)の一種である**ニューラルアーキテクチャサーチ(NAS)**を用いて開発された畳み込みニューラルネットワーク(CNN)アーキテクチャです。
2018年にGoogle AIによって開発され、ImageNet ILSVRC 2017画像分類コンペティションにおいて、当時の最先端モデルを上回る精度を達成したNASNetの後継モデルとなります。
MnasNetの特徴は以下の通りです。
1. 高精度
ImageNet ILSVRC 2017画像分類コンペティションにおいて、当時の最先端モデルを上回る75.9%のトップ5精度を達成しました。
2. 軽量性
MobileNet V2よりも少ないパラメータ数で、同等の精度を実現しています。
3. 汎用性
ImageNet以外にも、COCO物体検出、Cityscapesセマンティックセグメンテーションなど、様々なタスクで高い精度を達成しています。
4. 探索アルゴリズム
MnasNetは、**ニューラルアーキテクチャサーチ(NAS)**と呼ばれる手法を用いて開発されています。この手法は、自動的に最適なアーキテクチャを探索することができ、MnasNetの高い精度と軽量性を実現する要因の一つとなっています。
5. セル構造
MnasNetは、Depthwise Separable Convolutionと呼ばれる畳み込みレイヤーとPointwise Group Convolutionと呼ばれる畳み込みレイヤーを組み合わせたセル構造を用いて構成されています。
6. EfficientNet
MnasNetは、EfficientNetと呼ばれる一連のモデルアーキテクチャの基盤となっています。EfficientNetは、様々なタスクに適用できる汎用的なモデルアーキテクチャであり、MnasNetの高い精度と軽量性を継承しています。
7. 転移学習
MnasNetは、ImageNetで事前学習されたモデルをベースとして、転移学習を用いて様々なタスクに適用することができます。
MnasNetの応用例
MnasNetは、以下の様な様々な応用分野で利用されています。
画像認識: 画像分類、物体検出、セマンティックセグメンテーションなど
自然言語処理: 機械翻訳、質問応答、要約生成など
音声認識: 音声認識、音声合成、音声翻訳など
ロボット工学: ロボット制御、物体操作、ナビゲーションなど
NASNetとの比較
MnasNetは、NASNetと比較して以下の点が優れています。
精度: MnasNetは、NASNetよりも高い精度を達成しています。
軽量性: MnasNetは、NASNetよりも少ないパラメータ数で、同等の精度を実現しています。
汎用性: MnasNetは、NASNetよりも汎用性が高く、様々なタスクに適用することができます。
MNASNet: 端的に解説
MNASNetは、モバイル端末で動作する機械学習モデルを自動的に設計する手法です。
従来の手動でのモデル設計と比較して、検出速度と精度を大幅に向上させることができます。
特徴:
AutoMLによる自動設計: 人工知能を用いて、効率的に最適なモデル構造を探索します。
モバイル端末向け: 計算量とメモリ使用量を削減し、モバイル端末での動作を最適化します。
高い精度: ImageNetなどのベンチマークで、従来のモデルを上回る精度を達成しています。
応用例:
画像認識: 物体検出、画像分類、顔認識など
音声認識: 音声コマンド認識、音声翻訳など
自然言語処理: 機械翻訳、テキスト要約など
MNASNetは、モバイル端末での機械学習の発展に大きく貢献しており、様々な分野で活用されています。
補足:
MNASNetは、Google AIによって開発されました。
TensorFlow Liteなどのライブラリで、簡単に利用できます。
より詳細な情報については、MNASNetの論文やドキュメントを参照してください。
MNASNetは、主に以下の3つの手法により、計算量とメモリ使用量を削減しています。
1. 深度と幅の探索:
深さ: ネットワークの層数を調整することで、モデルの複雑さを制御します。
幅: 各層のチャネル数を調整することで、モデルの表現力を制御します。
2. フィルターの分解:
3x3フィルターを複数の1x1フィルターに分解することで、計算量を削減します。
分解されたフィルターをグループ化することで、メモリ使用量を削減します。
3. スキップ接続:
深い層からの情報を浅い層に伝達することで、モデルの精度を維持しながら、計算量を削減します
Dilated Convolution (膨張畳み込み)
概要 Dilated Convolution(膨張畳み込み)は、畳み込み演算を行う際に、フィルタ内の各要素間に空間を挿入することで受容野(畳み込みが捉える入力データの範囲)を拡大する手法です。この方法により、畳み込みフィルタがカバーする範囲を増やしつつ、パラメータの数や計算コストを増加させることなく、より広いコンテキストを考慮することができます。
応用 膨張畳み込みは、特にセグメンテーションや時系列データ解析など、広い範囲のコンテキスト情報が重要となるタスクに有用です。音声合成や画像の詳細な解析など、局所的な特徴だけでなく、より広範囲のパターンを捉える必要がある場合にも使用されます。
メリット
広範囲の受容野を効率的に確保:Dilated Convolutionは、カーネルの走査位置を膨張させることにより、少数の層のみで、効率的に広い受容野を確保できます。これにより、広い範囲で(疎に)畳み込むことができるので、少ない層数で効率的に「広範囲の受容野」から畳み込みを(疎に)行うことができます。
計算量の削減:Dilated Convolutionは、計算量を増やすことなく受容野を拡大できるという大きな利点があります。例えば、3×3=9個のパラメータを使うだけで、5×5のフィルターを使ったのと同じだけの広範なエリアの情報を要約することができます。
大域的な情報の組み込み:この手法では特徴マップに対して入力画像の大域的な情報が組み込まれるといったメリットがあります。そのため、この畳み込みは特に大きな受容野の情報を要約する必要があるタスク、たとえばセマンティックセグメンテーションなどにおいて有用です。
デメリット
低レベル特徴の取りこぼし:Dilated Convolutionは、カーネルの走査位置を膨張させることにより、広範囲の情報を効率的に取り扱うことができますが、その反面、低レベルの特徴を取りこぼす可能性があります。これは、カーネルの間隔が広がることで、細かい特徴を捉える能力が低下するためです。
情報の非連続性:Dilated Convolutionは、カーネルの走査位置を膨張させることで、広範囲の情報を効率的に取り扱うことができますが、その結果、畳み込み後の特徴マップ上で、遠距離の情報間に関連性が生まれにくいという問題があります。これは、カーネルの間隔が広がることで、畳み込みが行われる位置間の情報の連続性が失われるためです。
計算量の増加:Dilated Convolutionは、広範囲の情報を効率的に取り扱うことができますが、その反面、計算量が増加する可能性があります。特に、深い層での畳み込みは、画像比率から見ても計算量が大幅に増えるため、現実的な学習時間内での学習が難しくなる可能性があります
G検定に出そうなDilated Convolutionに関する質問と回答
質問:
Dilated Convolutionとはどのような畳み込み操作ですか?
Dilated Convolutionの利点と欠点は何ですか?
Dilated Convolutionの代表的な用途は何ですか?
Dilated Convolutionを用いた画像認識タスクの例を挙げてください。
Dilated Convolutionの学習率について、どのような点に注意する必要がありますか?
回答:
1. Dilated Convolutionとはどのような畳み込み操作ですか?
Dilated Convolutionは、従来の畳み込み操作に拡張係子(dilation rate)を導入した畳み込み操作です。拡張係子によって、フィルタのカーネル間隔が広くなり、より広い視野で入力特徴を捉えることができます。
2. Dilated Convolutionの利点と欠点は何ですか?
利点:
広い視野で特徴を捉えられる: 拡張係子によってフィルタのカーネル間隔が広くなるため、従来の畳み込み操作よりも広い視野で入力特徴を捉えることができます。これは、画像認識タスクにおいて、遠距離のオブジェクトやコンテキスト情報を捉えるのに有効です。
プーリング層の必要性を減らせる: Dilated Convolutionを用いることで、プーリング層を用いずに広い視野で特徴を抽出することができます。プーリング層を用いると空間解像度が低下するため、Dilated Convolutionを用いることで空間解像度を維持することができます。
欠点:
計算コストが高い: 拡張係子が大きくなるほど、計算コストが高くなります。
メモリ使用量: カーネル間隔が大きくなるほど、メモリ使用量が増加します。
レセプティブフィールド: カーネル間隔が大きくなるほど、レセプティブフィールド(フィルターが影響を与える範囲)が大きくなります。レセプティブフィールドが大きくなりすぎると、モデルが学習しにくくなる場合があります。
3. Dilated Convolutionの代表的な用途は何ですか?
画像認識: 画像認識タスクにおいて、遠距離のオブジェクトやコンテキスト情報を捉えるのに有効です。
セマンティックセグメンテーション: セマンティックセグメンテーションタスクにおいて、各ピクセルのクラスラベルを推定するのに有効です。
物体検出: 物体検出タスクにおいて、物体とその位置を検出するのに有効です。
4. Dilated Convolutionを用いた画像認識タスクの例を挙げてください。
顔認識: 顔認識タスクにおいて、顔の各部位の特徴を捉えるのに有効です。
風景認識: 風景認識タスクにおいて、風景全体の特徴を捉えるのに有効です。
医療画像解析: 医療画像解析タスクにおいて、腫瘍などの病変を検出するのに有効です。
5. Dilated Convolutionの学習率について、どのような点に注意する必要がありますか?
Dilated Convolutionは、従来の畳み込み操作よりもパラメータ数が多い傾向があるため、学習率を小さく設定する必要があります。学習率が大きすぎると、学習が不安定になり、精度が向上しない可能性があります。
Dilated Convolutionの別名
Dilated Convolutionは、主に以下の別名で呼ばれています。
拡張畳み込み
アトロピカル畳み込み (Atrous Convolution)
稀疎畳み込み (Sparse Convolution)
拡張カーネル畳み込み (Dilated Kernel Convolution)
拡張フィルター畳み込み (Dilated Filter Convolution)
これらの別名は、すべてDilated Convolutionの特徴である「カーネル間隔を拡張する」という点に由来しています。
拡張畳み込み: カーネル間隔を拡張することで、より広い視野で特徴を捉えることができるため、「拡張」という表現が使われます。
アトロピカル畳み込み: Atrousは「間隔」という意味のフランス語です。カーネル間隔を拡張することで、従来の畳み込み操作よりも間隔が空くため、「アトロピカル」という表現が使われます。
稀疎畳み込み: 従来の畳み込み操作では、すべてのカーネル要素が重なり合うように配置されていますが、Dilated Convolutionではカーネル要素の間隔が空いているため、「稀疎」という表現が使われます。
拡張カーネル畳み込み: カーネル間隔を拡張することで、カーネルのサイズが拡張されるため、「拡張カーネル」という表現が使われます。
拡張フィルター畳み込み: フィルターはカーネルと同義語であるため、「拡張フィルター」という表現が使われます。
上記以外にも、Dilated Convolutionを指す別名として「拡張コンボリューション」や「稀疎コンボリューション」などがある場合があります。
Depthwise Separable Convolution (深さ方向分離畳み込み)
概要 Depthwise Separable Convolutionは、畳み込み演算を2つの畳み込みステップに分離する手法です。最初のステップでは、各入力チャンネルに対して独立して畳み込み(
)を行い、次に1x1の畳み込み(Pointwise Convolution)を使用してチャンネル間の特徴を組み合わせます。このアプローチにより、従来の畳み込みと比較して計算コストとパラメータの数を大幅に削減しながら、類似またはそれ以上の性能を達成することが可能です。
応用 モバイルデバイスやエッジデバイスなど、計算リソースが限られている環境での画像処理タスクに適しています。GoogleのMobileNetアーキテクチャなど、軽量で高速なモデル設計に積極的に採用されています。
メリット
計算コストとパラメータの数を大幅に削減できる。
リソースが限られた環境でも高い性能を発揮するモデルの構築が可能。
デメリット
分離畳み込み特有のアーキテクチャのため、一部のタスクでは従来の畳み込みに比べて微妙に性能が劣ることがある。
モデルの設計や最適化が従来の畳み込みと異なるため、新たな考慮事項が生じる。
Depthwise Separable Convolution (深さ方向分離畳み込み) は、空間方向の畳み込みとチャンネル方向の畳み込みを分離して行う畳み込み手法です。
従来の畳み込みでは、空間方向とチャンネル方向の畳み込みを同時に実行しますが、Depthwise Separable Convolutionでは、2つのステップに分けて実行することで、計算コストを削減することができます。
2.1 利点
Depthwise Separable Convolutionの主な利点は以下の通りです。
計算コストの削減: 空間方向とチャンネル方向の畳み込みを分離することで、計算コストを大幅に削減することができます。
パラメータ数の削減: カーネルのサイズを小さくすることで、パラメータ数を削減することができます。
2.2 欠点
Depthwise Separable Convolutionの主な欠点は以下の通りです。
精度: 従来の畳み込みと比較して、精度が劣る場合がある。
3. Dilated ConvolutionとDepthwise Separable Convolutionの組み合わせ
Dilated ConvolutionとDepthwise Separable Convolutionを組み合わせることで、レセプティブフィールドを拡大しながら、計算コストを削減することができます。
これは、モバイル端末や組み込みシステムなどのリソースが限られた環境で、畳み込みニューラルネットワークを実行する場合に有効です。
4. まとめ
Dilated ConvolutionとDepthwise Separable Convolutionは、レセプティブフィールドや計算コスト、パラメータ数などの観点から、それぞれ異なる特徴を持つ畳み込み手法です。
それぞれの利点と欠点を理解した上で、適切な手法を選択することが重要です。
Pointwise Convolution
Pointwise Convolutionは、畳み込みニューラルネットワーク(CNN)における1x1のフィルタを用いた畳み込み処理です。従来の畳み込み処理とは異なり、空間的な特徴抽出ではなく、チャンネル間の情報量を調整する役割を果たします。
※チャンネル方向に畳みこむ、画素ごとに畳みこむ
特徴
計算量とパラメータ数が少ない
チャンネル間の情報量を調整できる
Depthwise Convolutionと組み合わせることで効率的な畳み込み処理が可能
利点
軽量なモデルを構築できる
モバイル端末など計算量やメモリに制約がある環境で利用できる
チャンネル間の情報量を調整できる
Depthwise Convolutionと組み合わせることで、より効率的な畳み込み処理が可能
欠点
空間的な特徴抽出能力が低い
従来の畳み込み処理よりも精度が劣る場合がある
学習目標:生成モデルにディープラーニングを取り入れた深層生成モデルについて理解する
生成モデルの考え方 (Concept of Generative Models)
特徴: 観測されたデータを生成するための確率的プロセスをモデル化する方法。
目的: データセットに含まれる潜在的なデータ分布を学習し、新しいデータインスタンスを生成する能力を獲得する。
説明: 生成モデルは、データがどのように生成されるかの理論的なモデルを作成し、そのモデルを基に新たなデータ点を生成する。このアプローチは、画像、音声、テキストなど多様なデータタイプに応用されます。
敵対的生成ネットワーク (Generative Adversarial Network, GAN)
特徴: 生成器(ジェネレータ)と識別器(ディスクリミネータ)の二つのネットワークが敵対的に学習を行う。
目的: 高品質な生成データを作り出し、ディスクリミネータを騙すことができる生成器を訓練する。
説明: GANでは、ジェネレータが新しいデータを生成し、ディスクリミネータが本物のデータと生成データを識別します。両者が競争することで、ジェネレータは本物に近いデータを生成する能力を向上させます。
2014年に イアン=グッドフェロー(Ian Goodfellow)によって提唱
GAN(敵対的生成ネットワーク)の詳細解説
GAN(Generative Adversarial Networks)は、生成モデルと識別器の2つのネットワークから構成される深層学習モデルであり、近年注目を集めているAI技術の一つです。従来の生成モデルとは異なり、教師データを用いることなく、敵対的な学習を通して高品質なデータを生成することができます。
1. 尤度ではなく識別器による生成器の評価
GANでは、生成モデル(Generator)と識別モデル(Discriminator)の2つのネットワークが互いに競い合いながら学習を行います。
生成モデル: ランダムなノイズを入力として、実在するデータに類似したデータを生成します。
識別モデル: 生成されたデータと実在するデータを見分け、どちらが本物か偽物かを判断します。
生成モデルは、識別モデルを騙すように、よりリアルなデータを生成することを学習します。一方、識別モデルは、生成されたデータをより正確に見破れるように学習します。
この過程を通して、生成モデルは識別モデルを騙すことができれば良いという学習目標を与えられるため、尤度ではなく識別器の判断に基づいて生成器の良し悪さを評価することになります。
2. GANが図る距離:JSダイバージェンス
GANにおける生成モデルと実在データの分布間の距離は、JSダイバージェンスと呼ばれる指標を用いて評価されます。JSダイバージェンスは、2つの確率分布間の違いを測る指標であり、値が小さいほど2つの分布が似ていることを意味します。
GANでは、生成モデルが学習を進めるにつれて、生成されたデータの分布が実在データの分布に近づき、JSダイバージェンスの値が小さくなります。
3. GANの課題
GANは、非常に強力な生成モデルですが、以下のような課題も存在します。
収束性: GANの学習は、非常に難しく、安定的に収束しない場合がよくあります。
モードコラプス: 生成モデルが、特定のモードしか生成できなくなる現象です。
勾配消失: 生成モデルと識別モデルの学習過程において、勾配が消失してしまう問題です。
これらの課題は、GANの研究において活発に取り組まれており、様々な解決策が提案されています。
GANの応用例
GANは、画像生成、音声生成、自然言語処理など、様々な分野で応用されています。
画像生成: リアルな顔写真や風景画像を生成することができます。
音声生成: 既存の音声データを元に、新しい音声データを生成することができます。
自然言語処理: 創作的な文章や詩を生成することができます。
ジェネレータ (Generator)
特徴: GANや他の生成モデルにおいて、新しいデータサンプルを生成する部分。
目的: 学習したデータ分布に基づいて新しいデータを生成する。
説明: ジェネレータはランダムノイズからデータを生成することで、データセットの本物の分布を模倣しようと試みます。
ディスクリミネータ (Discriminator)
特徴: GANにおいて、生成されたデータが本物か偽物かを識別する役割を担うネットワーク。
目的: 生成器のトレーニングをガイドするために本物と生成データの区別を行う。
説明: ディスクリミネータは生成されたデータと実データを比較し、その真偽を判断します。このフィードバックにより生成器の性能が向上します。
DCGAN (Deep Convolutional Generative Adversarial Network)
特徴: 畳み込み層を用いたGANの一種で、特に画像データに効果的。
目的: 視覚的リアリズムが高い画像の生成。
説明: DCGANは畳み込みニューラルネットワーク(CNN)を採用しており、画像の特徴をより効果的に捉えることができます。
2015年に提案された。
Pix2Pix
特徴: 画像から画像への変換を学習する条件付きGANモデル。
目的: ある画像から目的の画像へのリアルタイム変換を実現する。
説明: Pix2Pixはペアになった画像間のマッピングを学習し、例えば衛星画像から地図を生成するなど、具体的なタスクに適用されます。
CycleGAN
特徴: 未ペアの画像間でスタイル変換を可能にするGANモデル。
目的: 一方のドメインのスタイルを持つ画像を、別のドメインのスタイルに変換する。
説明: CycleGANは、例えば夏の写真を冬の風景に変換するなど、ペアでないデータ間で相互に学習することが特徴です。
※馬の画像をシマウマに変換
StackGAN:テキストから画像を生成する深層学習モデル
StackGANは、テキストの説明に基づいてリアルな画像を生成する深層学習モデルです。従来の生成モデルと異なり、StackGANは段階的な生成を行うという特徴を持ちます。
StackGANの特徴
段階的な生成: StackGANは、2つのGAN(Generative Adversarial Network)を段階的に用いて画像を生成します。
Stage-I GAN: 低解像度の画像を生成
Stage-II GAN: Stage-I GANで生成された画像を基に、高解像度の画像を生成
テキストと画像のマッチング: 生成された画像と入力テキストの意味的な一致を評価するために、テキストエンコーダと画像エンコーダを用います。
多様な画像生成: 異なるテキストの説明に対して、多様な画像を生成することができます。
学習目標:ディープラーニングの画像認識への応用事例や代表的なネットワーク構成を理解する。
物体識別タスク (Object Classification Task)
特徴: 画像に含まれる主要なオブジェクトを識別し、カテゴリに分類する。
目的: 画像内の物体が何かを認識し、そのカテゴリを特定する。
説明: 物体識別は、画像から単一または複数の物体を識別して分類ラベルを割り当てるプロセスです。基本的な画像分類タスクであり、多くのディープラーニングモデルの基盤です。
物体検出タスク (Object Detection Task)
特徴: 画像内の複数の物体をローカライズし、それぞれの物体についてバウンディングボックスとカテゴリラベルを割り当てる。
目的: 画像内の各物体の位置とカテゴリを同時に特定する。
説明: 物体検出では、画像内の複数のオブジェクトの位置とそのカテゴリ(クラス)を識別します。このタスクは、交通監視、自動運転車、セキュリティシステムなどに応用されます。
セグメンテーションタスク (Segmentation Task)
特徴: 画像をピクセルレベルで分析し、各ピクセルが属するオブジェクトやクラスにラベルを付ける。
目的: 画像内の各ピクセルの属性を理解し、詳細な形状や境界を抽出する。
説明: セグメンテーションは、医療画像分析、衛星画像処理、道路標識の検出など、高度に詳細な画像分析が必要な場面で使用されます。
姿勢推定タスク (Pose Estimation Task)
特徴: 画像内の人物の姿勢を推定し、各関節の位置を特定する。
目的: 人間の動作や活動を理解し、その動きを分析する。
説明: 姿勢推定はスポーツ分析、インタラクティブゲーム、医療リハビリテーションなどで応用され、動的なシナリオでの人間の動作を把握するのに役立ちます。
マルチタスク学習 (Multi-task Learning)
特徴: 複数の学習タスクを同時に解決するために設計されたモデル。
目的: 異なるが関連する複数のタスクから学習することで、各タスクの性能を向上させる。
説明: マルチタスク学習は、タスク間で有用な情報を共有することで、一つのモデルが複数の問題を効果的に解決する能力を持ちます。これにより、学習効率とモデルの汎用性が向上します。
ILSVRC (ImageNet Large Scale Visual Recognition Challenge)
特徴: 大規模な画像データセットを使用した視覚認識の国際コンペティション。
目的: 画像認識技術の進展を促進し、新しいアルゴリズムやモデルを評価する。
説明: ILSVRCはImageNetデータベースを使用し、画像分類、物体検出、物体ローカライゼーションなど複数のタスクで技術の進歩を競います。
AlexNet
特徴: 2012年のILSVRCで優勝した深層畳み込みニューラルネットワーク。
目的: ディープラーニングを用いた画像分類の性能を大幅に向上させる。
説明: AlexNetは畳み込み層と全結合層から構成され、非常に深いアーキテクチャを持ちます。これにより、以前のモデルよりもはるかに高い精度を実現しました。(CNNベース)
AlexNet は、深層学習の歴史において、革新的な畳み込みニューラルネットワーク (CNN) として知られるモデルです。
AlexNet の誕生:
Alex Krizhevsky、Ilya Sutskever、Geoffrey Hinton の 3 人によって開発されました。
当時としては画期的な深さを持つ 8 層の CNN を設計しました。
AlexNet の特徴:
畳み込み層とプーリング層を巧みに組み合わせることで、 画像の特徴を効率的に抽出 するように設計されています。
**ReLU (Rectified Linear Unit)**と呼ばれる活性化関数を採用することで、 勾配消失問題 を緩和しています。
オーバーラッププーリングと呼ばれるプーリング手法を採用し、局所的な特徴の保持を向上させています。
ドロップアウトと呼ばれる手法をニューラルネットワークに導入し、 過学習 を抑制しています。
Inception モジュール
特徴: 異なるサイズのカーネルを持つ複数の畳み込み層とプーリング層を同時に適用し、結果を結合するモジュール。
目的: 多スケールでの特徴抽出を同時に行い、ネットワークの幅と深さを効率的に拡張する。
説明: Inception モジュールは、1x1, 3x3, 5x5 の畳み込み層と3x3 のプーリング層を並列に配置し、これにより異なるスケールの特徴を捉え、計算資源を効率的に使用します。
GoogLeNet
特徴: Inception モジュールを基盤とした深層畳み込みニューラルネットワーク。
目的: 計算コストを抑えつつ、高い認識精度を実現する。
説明: GoogLeNetは多層のInceptionモジュールを組み合わせて深く広いネットワークを構築し、ILSVRC2014で分類部門と検出部門で高い成績(優勝)を収めました。
GoogLeNetの概要
GoogLeNetは、2014年のImageNet Large Scale Visual Recognition Challenge (ILSVRC)で優勝したConvolutional Neural Network (CNN)モデルです。
GoogLeNetは、22層の深い構造を持ち、VGGネットワークよりも高い性能を発揮しました。
GoogLeNetの大きな特徴は、Inception Moduleと呼ばれる独自の構造を採用していることです。
補助的損失(Auxiliary Loss)
GoogLeNetでは、中間層にも損失関数を追加する「補助的損失」という手法が採用されています。
補助的損失とは、ネットワークの中間層の出力に対しても損失関数を定義し、学習を促進する手法です。
これにより、勾配消失問題を緩和し、大規模なネットワークの学習を可能にしています。
補助的損失の効果
勾配消失問題の緩和: 中間層にも損失関数を定義することで、下位層への勾配が維持されるため、勾配消失問題が緩和されます。
一般化性能の向上: 中間層の学習が促進されることで、より良い特徴量が抽出され、一般化性能が向上します。
大規模モデルの学習: 補助的損失により、大規模なネットワークの学習が可能になります。
関連技術
補助的損失は、GoogLeNetのほかにも、ResNetやDenseNetなどの深層学習モデルでも採用されています。
補助的損失は、Inception Moduleと組み合わせることで、より効果的に勾配消失問題に対処できます。
VGG
特徴: 小さい3x3のカーネルを使用する畳み込み層を多層(16~19層)に重ねたシンプルなアーキテクチャ。
目的: 畳み込み層を深く重ねることで、より複雑な特徴を抽出する。
説明: VGGはそのシンプルさから広く使用され、特に転移学習のベースモデルとして優れた性能を発揮します。
オックスフォード大学が提出したモデル。2014年のILSVRCの分類部門で2位を取ったモデル。
スキップ結合 (Skip Connection)
特徴: 入力を畳み込み層の出力に直接加算することで、層を飛び越えた接続を形成。
目的: 深いネットワークでの勾配消失問題を軽減し、効果的な学習を可能にする。
説明: スキップ結合は特にResNetで使用され、層を通じて情報を効率的に伝えることができるため、非常に深いネットワークの訓練が可能になります。
ResNet
特徴: スキップ結合を用いて、層を通じて入力を直接伝播させる構造。
目的: 深いネットワークの訓練を可能にし、より複雑な問題の解決を実現する。
説明: ResNetは勾配消失問題を解決し、100層以上の非常に深いネットワークで高い性能を実現します。
Wide ResNet
特徴: 通常のResNetよりも広いネットワーク、つまり各層により多くのユニットを持たせたバージョン。RESNETと比較して計算速度は上がる
目的: 深さだけでなく幅も増やすことで、さらなる性能向上を図る。
説明: Wide ResNetは計算コストを大幅に増やすことなく、深いネットワークの性能を向上させます。
Wide ResNet: ResNetの構造を基に、チャンネル数を増やしたモデルです。フィルターの数を増やすことで、表現力を向上させます。
各ブロックの畳み込み層のチャンネル数は、ResNetよりも2倍または4倍に増えています。
深さは、ResNetと同じです。
ResNet: 残差接続と呼ばれるショートカット接続を用いた構造が特徴です。深層化による勾配消失問題を軽減し、学習効率を向上させます。
各ブロックに、ショートカット接続と呼ばれる恒等関数と残差関数の和を計算する層が含まれています。
深さは、34層、50層、101層、152層など、様々なバリエーションがあります。

DenseNet
特徴: 各層が前のすべての層と直接接続される密結合ネットワーク。
目的: 特徴伝達を最大化し、効率的な学習を実現する。
説明: DenseNetは、特徴が次の層に再利用されるため、より少ないパラメータで高い性能を維持します。
SENet (Squeeze-and-Excitation Network)
特徴: 各畳み込みブロックにチャネル間の依存関係をモデル化する機構を導入。
目的: 畳み込み層の特徴の再調整を行い、重要な特徴が強調されるようにする。
説明: SENetは特定のタスクにおいて重要なチャネルに焦点を当てることで、ネットワークの注意を向上させ、パフォーマンスを向上させます。
概要
SE ネットワークは、従来のCNNモデルに追加することで性能を向上させるモジュールです。
チャンネル間の相関関係を明示的にモデル化し、チャンネル重要度を動的に再調整することで、特徴表現の性能を高めます。
2017年のILSVRC (ImageNet Large Scale Visual Recognition Challenge) コンテストで、SENetが1%の精度向上を達成し、新しい最高記録を更新しました。
SEブロックの仕組み
Squeeze: 空間情報を圧縮し、チャンネル単位の特徴ベクトルを生成します。
Excitation: 生成したチャンネル特徴ベクトルを使って、チャンネル間の相関関係を学習し、チャンネル重要度を推定します。
Re-scale: 推定したチャンネル重要度に基づいて、入力特徴マップを再スケーリングします。
これにより、CNNモデルがチャンネル間の相互作用を学習できるようになり、より強力な特徴表現が得られます。
SEネットワークの特徴
既存のCNNモデル(ResNet、Inception等)にSEブロックを組み込むことで、パラメータ数を増やすことなく性能を向上できます。
画像分類、物体検出、セグメンテーションなど、様々なコンピュータビジョンタスクで効果を発揮します。
計算コストが低く、実用的な適用が可能です。
応用例
SEブロックはResNetやInceptionなどの既存CNNモデルに組み込まれ、ImageNetなどの大規模データセットで高い精度を達成しています。
物体検出、セグメンテーション、画像生成などの分野でも、SEブロックの導入により性能が向上しています。
医療画像解析、自然言語処理など、様々な分野での応用が期待されています。
R-CNN (Regions with CNN features)
特徴: 候補領域にCNNを適用し、物体のバウンディングボックスとラベルを予測する。
目的: 高精度な物体検出を実現する。
説明: R-CNNは選択的検索を用いて候補領域を生成し、それぞれの領域に対してCNNを適用して分類します。この手法は精度は高いが、計算コストが大きいという欠点があります。
選択的検索(Selective Search)は、物体検出における効率的な領域提案手法の一つです。従来の領域提案手法と異なり、選択的検索は画像全体のグリッド構造と色やテクスチャなどの特徴量に基づいて、候補となる領域を段階的に絞り込む
FPN (Feature Pyramid Networks)
特徴: 異なるスケールで特徴を抽出し、それらを統合して物体検出を行うネットワーク。
目的: スケールの異なる物体を効果的に検出する。
説明: FPNは複数の解像度の特徴マップを生成し、それらを上下に統合して物体の検出精度を向上させます。
YOLO (You Only Look Once)
特徴: 画像全体を単一の畳み込みネットワークを通じて一度に処理し、バウンディングボックスとクラス確率を予測する。
目的: 高速かつリアルタイムの物体検出を実現する。
説明: YOLOはその名の通り、画像を一度だけ見ることで全ての予測を行うため、非常に高速である一方で、小さな物体の検出には苦手とする部分があります。
矩形領域 (Rectangular Regions)
特徴: 画像内の物体を囲む四角形の領域。
目的: 物体の位置を定義し、検出や分類を行う際の基準とする。
説明: 物体検出タスクでは、矩形領域を用いて物体の位置と大きさを特定します。この領域は物体の周囲に密着する形で定義されることが多いです。
SSD (Single Shot MultiBox Detector)
特徴: 単一の畳み込みネットワークを使用して物体の位置とクラスを同時に予測する。
目的: 高速かつ効率的な物体検出を実現する。
説明: SSDは複数のスケールの特徴マップを利用して物体を検出し、それぞれの特徴マップから異なるサイズの物体に対する予測を行います。速度と精度のバランスが取れています。
Fast R-CNN
特徴: R-CNNを改良し、特徴抽出を一度だけ行い、ROIプーリングを通じて各候補領域の特徴を抽出する。
最大プーリングとROIプーリングを利用目的: 計算効率を向上させ、より高速なトレーニングと推論を実現する。
説明: Fast R-CNNは全画像の特徴マップを一度計算し、その後各領域に対して独立して分類とバウンディングボックスの回帰を行います。これにより、R-CNNよりも処理速度が大幅に向上します。
Faster R-CNN
特徴: Fast R-CNNにリージョン提案ネットワーク (RPN) を追加し、候補領域の生成も学習ベースで行う。
最大プーリングとROIプーリングを利用目的: エンドツーエンドで物体検出の精度と速度をさらに向上させる。
説明: Faster R-CNNはリアルタイムでの物体検出に適しており、リージョン提案から分類までの全プロセスを単一のネットワークで行います。
セマンティックセグメンテーション (Semantic Segmentation)
特徴: 画像内のすべてのピクセルをクラスラベルにマッピングし、ピクセル単位で物体を区分する。
目的: 画像内の各物体を正確に理解し、より詳細な画像解析を行う。
説明: セマンティックセグメンテーションは、道路、建物、人、車など、画像内の異なるオブジェクトを正確に区別し、各ピクセルに対応するカテゴリーラベルを割り当てます。
インスタンスセグメンテーション (Instance Segmentation)
特徴: セマンティックセグメンテーションに加えて、同一クラスの異なるインスタンスを個別に区分する。
目的: 画像内の個々のオブジェクトを独立したエンティティとして識別し、より精密な画像理解を実現する。
説明: インスタンスセグメンテーションは、たとえば複数の人が写っている場面で、それぞれの人を個別に識別し、それぞれの境界を明確にする技術です。
パノプティックセグメンテーション (Panoptic Segmentation)
特徴: セマンティックセグメンテーションとインスタンスセグメンテーションを組み合わせたアプローチ。
目的: シーン内のすべての物体を、そのクラスとインスタンスレベルで同時に理解する。
説明: パノプティックセグメンテーションは、背景を含むすべてのオブジェクトを一度に処理し、画像全体の包括的な理解を提供します。
FCN (Fully Convolutional Network)
特徴: 従来の全結合層を畳み込み層に置き換え、任意サイズの画像を入力として受け入れられるネットワーク。
畳み込み層のみ: FCNは全結合層を排除し、フル畳み込み層を採用しています。これにより、任意のサイズの画像に対応可能であり、セマンティックセグメンテーションのための出力マップが直接生成されます。
アップサンプリングと特徴融合: 異なる解像度で得られる特徴マップをアップサンプリング(逆畳み込み)し、詳細な予測を行います。低解像度で得た情報と高解像度で得た情報を組み合わせることで、より精密なセグメンテーションが可能になります。目的: 効率的な学習と柔軟な入力サイズでセグメンテーションタスクを達成する。
説明: FCNは画像全体を一度に処理し、各ピクセルに対してラベルを予測します。これにより、特に大きな画像でのセグメンテーションが効率的に行えます。
類似モデルとの比較
U-Net: FCNの基本的なアイデアにスキップ接続を追加し、さらに詳細なセグメンテーションが可能になります。特に医療画像セグメンテーションに有効です。
SegNet: プーリングインデックスを活用することで、デコード時の空間情報の精度を高めています。これにより、細かいエッジや境界をより正確に再構築できます。
DeepLab: 膨張畳み込みを用いることで、異なるスケールのオブジェクトに対する適応性が向上し、より柔軟なセグメンテーションが可能です。
SegNet
特徴: エンコーダデコーダアーキテクチャを採用し、エンコーダでダウンサンプリングした後、デコーダでアップサンプリングを行う。
目的: 交通監視や衛星画像解析など、具体的なアプリケーションでの精確なピクセルレベルのセグメンテーションを提供する。
説明: SegNetは特にエッジの精度を高めるために、エンコーダのプーリングインデックスをデコーダで再利用します。
U-Net
特徴: 対称的なエンコーダデコーダ構造を持ち、スキップ結合を用いて詳細情報を保持する。
目的: 医療画像セグメンテーションなど、詳細が重要なアプリケーションで高い精度を達成する。
説明: U-Netは、細かい構造が重要な医療画像などで高い性能を発揮し、少ないトレーニング画像からも良好な結果を得ることができます。
PSPNet (Pyramid Scene Parsing Network)
特徴: 異なる領域からのグローバルなコンテキスト情報を集約するためにピラミッドプーリングを利用する。
目的: シーン解析タスクで詳細な画像理解を実現する。
説明: PSPNetは、異なるスケールでのコンテキスト情報を効果的に統合し、より正確なセグメンテーションを提供します。
Dilation convolution / Atrous convolution
特徴: 通常の畳み込みよりも広い受容野を持つように設計された畳み込み演算。
目的: より広範囲のコンテキスト情報を捉え、セグメンテーションの精度を向上させる。
説明: Dilation / Atrous convolutionはフィルタ内のスペースを広げることで、受容野を拡大し、細かいディテールと広範囲のコンテキストの両方を捉えます。
DeepLab
特徴: Atrous convolutionを使用し、さらにアトラス空間ピラミッドプーリングを組み込んで、異なるスケールでのコンテキストを捉える。
膨張畳み込み (Dilated Convolution): 膨張畳み込みは、通常の畳み込み層よりも走査する画素範囲を膨張させて「疎に広く」畳み込むことができます。これにより、効率的に少数回で広範囲の情報を畳み込んでいくことで、各出力座標からみた「広範囲の周辺コンテキスト」を特徴マップへと収集することができます。
膨張空間ピラミッドプーリング (Atrous Spatial Pyramid Pooling, ASPP): ASPPは、4つの異なるサイズの膨張カーネルを用いることで、4段階の各スケールの特徴から並列にプーリングを行ったのち、それらの結果を1つに合成します。これにより、広範囲のコンテキスト特徴を、多重解像度かつ密に集約できます。
End-to-End学習: DeepLab v3以降では、後処理としてのCRF (Conditional Random Field)を廃止し、Deep Neural Networkのみでセグメンテーションを最後まで行うEnd-to-End学習が可能になりました。
深さ単位分解可能畳み込み: DeepLab v3+では、深さ単位分解可能畳み込みが導入され、モデルの軽量化が図られました。
目的: 高度に正確なセグメンテーション性能を提供する。
説明: DeepLabは特に困難なセグメンテーションタスクで高い性能を示し、細かなエッジや複雑なオブジェクトの形状を正確に予測します。
Open Pose
特徴: リアルタイムでのマルチパーソン姿勢推定を行うオープンソースのライブラリ。
目的: 姿勢推定の精度と速度を向上させ、実用的なアプリケーションでの使用を可能にする。
説明: Open Poseは複数の人物の姿勢を同時に推定でき、ビデオストリームに対してリアルタイムで処理を行います。
Parts Affinity Fields (PAF)
特徴: 姿勢推定において、個々の人間の部位間の関連性をエンコードするためのフィールド。
目的: 複数人が写るシーンで個々の人間の関節とそのつながりを正確に識別する。
説明: PAFは人間の各部位を検出し、それらの部位がどのようにつながっているかの確率ベクトルフィールドを生成します。これにより、複数人の姿勢推定が可能になります。
Mask R-CNN
特徴: Faster R-CNNに基づき、さらに各検出されたオブジェクトインスタンスに対してセグメンテーションマスクを生成する。
目的: インスタンスセグメンテーションタスクにおいて、物体検出とピクセルレベルのセグメンテーションを同時に行う。
説明: Mask R-CNNは、高速かつ正確なインスタンスセグメンテーションを実現し、さまざまなシーンで個々のオブジェクトを詳細に理解します。
Mask R-CNNの特徴
インスタンスセグメンテーション:各検出されたオブジェクトに対してバウンディングボックスを生成し、それぞれのオブジェクトの正確なピクセルレベルのマスクを生成する。
ROI Align:従来のROI Poolingの精度問題を解決するために導入された技術で、ピクセルレベルでの細かな特徴を保持する。
柔軟性:オブジェクト検出、セグメンテーション、ポーズ推定など、複数のタスクに対応可能。
PSPNetの特徴
空間ピラミッドプーリング:異なるリージョンからのコンテキスト情報を集約し、よりリッチな特徴表現を可能にする。
効果的なシーンパーシング:大規模なシーンの理解に特化しており、道路や風景など広範囲の環境での詳細なセグメンテーションに優れている。
DeepLabの進化形:DeepLabシリーズと同様に、複数のスケールでの情報を扱うことができ、それによってセグメンテーションの精度を向上させる。
学習目標:音声と言語の時系列データをモデルで取り扱うためのニューラルネットワークモデルと最新の研究成果などを理解する
データの扱い方
特徴: 時系列データや言語データの処理には、適切な前処理と表現が必要です。
目的: モデルがデータから効果的に学習するために、データを適切な形式に変換する。
説明: 音声データは波形データをスペクトログラムやMFCCといった特徴量に変換し、言語データはトークン化、正規化、ベクトル化を行います。
リカレントニューラルネットワーク (RNN)
特徴: 過去の情報を隠れ状態に蓄積し、その状態を更新しながら次々とデータを処理するネットワーク。
目的: 時系列データの内部依存関係をモデル化し、シーケンスの予測や生成を行う。
説明: RNNは自然言語処理や音声認識に有効で、過去の情報を考慮しながら入力を処理します。
Transformer
特徴: 自己注意機構を利用して全トークン間の関係を一度に捉えることができるアーキテクチャ。
Transformerのメカニズム:詳細解説
Transformerは、2017年にGoogle AIによって発表された革新的なニューラルネットワークアーキテクチャです。従来のRNN(再帰型ニューラルネットワーク)とは異なり、自己アテンションと呼ばれるメカニズムを用いることで、長距離依存関係を効率的に処理することができます。Transformerの利点
Transformerには、以下の利点があります。
長距離依存関係の処理: 自己アテンションメカニズムにより、長距離依存関係を効率的に処理することができます。
並列処理: Transformerは、並列処理に適しており、計算効率が高いです。
解釈性: Transformerは、RNNよりも解釈性が高く、モデルの動作を理解しやすくなっています。
目的: 効率的な学習と優れた並列化能力を実現し、長距離依存関係を効果的に捉える。
説明: Transformerは特に自然言語処理において、従来のRNNやLSTMよりも優れた性能を示し、大規模な言語モデルの訓練に広く使われています。
自然言語処理における Pre-trained Models
特徴: 大規模データセットで事前に訓練されたモデルを、特定のタスクにファインチューニングする。
目的: ベースラインとなる言語理解を提供し、限られたデータでの学習を効率的にする。
説明: BERTやGPTのようなモデルは、事前に豊富なコーパスで訓練され、特定のタスクにおいて追加学習を少なくすることで高いパフォーマンスを発揮します。
LSTM (Long Short-Term Memory)
特徴: RNNの一種で、長期依存関係を学習する能力に優れる。
目的: シーケンスデータの長距離依存関係を捉え、勾配消失問題を解決する。
説明: LSTMはゲート制御機構を持ち、不要な情報を忘れ、必要な情報を長期間記憶することができます。LSTM(Long Short-Term Memory)
LSTM(Long Short-Term Memory)は、再帰的ニューラルネットワーク(RNN)の一種であり、特に時系列データやシーケンスデータの処理に適しています。1997年にSepp HochreiterとJürgen Schmidhuberによって提案され、長期間にわたる依存関係を学習する能力があります。
LSTMの構造と特徴
LSTMは、通常のRNNが持つ短期記憶の問題を解決するために設計されました。具体的には、勾配消失問題や勾配爆発問題を克服する機能を備えています。LSTMの主要な特徴は、以下の三つのゲートと一つのセル状態から成り立っています:
忘却ゲート(Forget Gate)
このゲートは、セル状態から不要な情報を削除する役割を果たします。入力と前の隠れ層からの情報に基づき、どの情報を忘れるかを決定します。
入力ゲート(Input Gate)
新しい情報をセル状態にどの程度加えるかを決定します。新しい入力データと前の隠れ層の出力に基づいて、更新する情報の量を制御します。
出力ゲート(Output Gate)
セル状態のどの部分を次の隠れ層の出力として送るかを決定します。この出力が次の時点での隠れ層の入力として使用されます。
セル状態(Cell State)
LSTMの核となる部分で、ネットワークを通じて情報を長期間にわたって運搬する役割を果たします。ゲートによって情報の更新や削除が行われます。
LSTMの用途
LSTMは特に以下のようなアプリケーションに有効です:
自然言語処理(機械翻訳、テキスト生成、感情分析など)
音声認識
時系列予測(株価予測、気象予測など)
G検定におけるLSTM
G検定(ジェネラリスト検定)では、LSTMの基本的な構造や特性、及びそれがどのようにして長期依存関係を扱うのかについて問われる可能性があります。具体的には、以下のような内容が問題として出されるかもしれません:
LSTMの各ゲートの機能と役割
通常のRNNとLSTMの違い
LSTMが解決する主な問題(勾配消失問題など)
LSTMを使用する典型的なアプリケーション
LSTMについての理解は、深層学習がどのようにして複雑なシーケンスデータを扱うかの理解を深めるのに役立ちます。また、AI技術の進歩における重要なマイルストーンの一つとして、その知識は広範な分野での応用が期待されています。
CEC (Constant Error Carousel)
特徴: LSTMにおいて、エラーが時間を通じて一定であることを保証する部分。
目的: 情報を長期間ネットワーク内に保持し、勾配消失を防ぐ。
説明: CECは情報が長期間モデルに留まり続けることを可能にし、シーケンス学習の精度を向上させます。
GRU (Gated Recurrent Unit)
特徴: LSTMを単純化したモデルで、リセットゲートと更新ゲートの二つのゲートを使用する。
目的: 計算効率を向上させつつ、長期依存関係をモデル化する。
説明: GRUはパラメータが少ないため学習が速く、多くの場合LSTMと同等またはそれ以上の性能を発揮します。
双方向 RNN (Bidirectional RNN)
特徴: 通常のRNNとは異なり、入力データを前から後ろへ、後ろから前への両方向から処理する。
目的: 文脈の全体的な理解を深め、より正確な予測を行う。
説明: 双方向RNNは特に自然言語処理において有効で、文中の前後の情報を利用して各単語の意味をより正確に捉えます。
RNNEncoder-Decoder
特徴: エンコーダ部で入力シーケンスを固定長のベクトルに変換し、デコーダ部でこのベクトルから目的のシーケンスを生成する。
目的: 翻訳や要約など、一つのシーケンスから別のシーケンスへの変換を学習する。
説明: このアーキテクチャはシーケンス間の複雑な関係をモデル化する能力に優れ、機械翻訳やテキスト要約に適しています。
BPTT (Backpropagation Through Time)
特徴: 時間を遡って誤差逆伝播を行うことで、RNNの学習を可能にする技術。
目的: RNNにおける時間依存関係のあるデータの学習を効率的に行う。
説明: BPTTはシーケンス全体の損失を計算し、それを基に各時点でのパラメータ更新を行います。この方法は勾配消失や勾配爆発を引き起こすことがあります。
BPTT (Backpropagation Through Time) の要約説明
BPTT (Backpropagation Through Time) は、**リカーレントニューラルネットワーク(RNN)**などの時系列データ処理を行うニューラルネットワークにおいて、時間軸に沿って誤差を伝播させる手法です。
従来のニューラルネットワークでは、入力データと出力データのみを用いて誤差を計算していましたが、BPTTでは過去のデータも考慮することで、より精度が高い誤差計算が可能になります。
BPTTの仕組みは、以下の3つのステップで実行されます。
順方向計算: 入力データから出力データまでの計算を順方向に行います。
誤差計算: 出力データと教師データの誤差を計算します。
逆方向計算: 誤差を各パラメータに沿って伝播させます。
BPTTの利点は、以下の2点です。
高い精度: 過去のデータも考慮することで、より精度が高い誤差計算が可能になります。
時系列データ処理: 時間軸に沿って誤差を伝播させるため、時系列データ処理を行うRNNなどのニューラルネットワークに適しています。
BPTTの課題は、以下の2点です。
計算コスト: 時間軸 t に沿って誤差を伝播させるため、計算コストが高くなります。
勾配消失問題: 時間軸が長くなると、過去のデータの影響が弱くなり、勾配消失問題が発生する可能性があります。
BPTTの応用例は、以下の3つです。
自然言語処理: 機械翻訳、質問応答、要約生成など
音声認識: 音声認識、音声合成、音声翻訳など
時系列予測: 株価予測、需要予測、天気予報など
Truncated BPTT
Truncated BPTT は、誤差信号が遡って伝播される時間ステップの数を制限することで、この問題に対処します。以下が動作の流れです。
RNN はデータのシーケンス全体を処理します。
ネットワークの出力と目的の出力との誤差を計算します。
誤差信号を、事前に定義された時間ステップ数 (切断長) だけ時間軸に遡って伝播します。
ネットワークの重みは、これらの時間ステップにおける累積誤差信号に基づいて更新されます。
Truncated BPTT の利点
計算コストの削減: バックプロパゲーションのステップ数を制限することで、Truncated BPTT は特に長いシーケンスの場合、BPTT と比較して計算効率が向上します。
消失勾配問題の軽減: 誤差信号をシーケンス全体で伝播しないことで、Truncated BPTT は消失勾配問題を軽減し、ネットワークがある程度の長期依存関係を学習できるようにします。
Attention
特徴: シーケンスの各部分に対して異なる重みをつけることで、重要な情報に焦点を当てる。
目的: モデルが重要な情報に注目し、不要な情報を無視することで性能を向上させる。
説明: Attention機構は特に翻訳タスクにおいて効果を発揮し、入力の一部に対して出力がどの程度影響を受けるかをモデル化します。これにより、長距離の依存関係をより効果的に捉えることができます。
Attention の要約説明
Attentionは、ニューラルネットワークの一種の手法であり、入力データの中で最も重要な部分に焦点を当てることで、より精度の高い処理を行うことができます。
従来のニューラルネットワークでは、すべての入力データに対して同じ重みを適用していましたが、Attentionでは入力データの各要素に対して異なる重みを適用することで、重要な部分にのみ焦点を当てることができます。
Attentionの仕組み
Attentionは以下の3つのステップで実行されます。
エンコーダー: 入力データを処理し、各要素の重要度を表す Query、Key、Value を生成します。
スコアリング: QueryとKeyを内積することで、各要素間の関連度を表す Attentionスコア を計算します。
ウェイト付け: Attentionスコアに基づいて、Valueにウェイトを付け、Attention出力 を生成します。
Attentionの利点
Attentionには、以下の利点があります。
精度向上: 重要な部分にのみ焦点を当てることで、より精度の高い処理を行うことができます。
解釈性: Attentionスコアを分析することで、ニューラルネットワークがどのように入力データを解釈しているのかを理解することができます。
長距離依存関係の処理: 入力データの離れた要素間の関係性を考慮することができます。
Attentionの課題
Attentionには、以下の課題があります。
計算コスト: Attentionスコアを計算するために、計算コストが高くなります。
ハイパーパラメータの調整: Attentionの性能を調整するために、多くのハイパーパラメータを調整する必要があります。
Attentionの応用例
Attentionは、以下の様な様々な応用分野で利用されています。
機械翻訳: 入力文の中で最も重要な単語に焦点を当てることで、より精度の高い翻訳を行うことができます。
画像認識: 画像の中で最も重要な部分に焦点を当てることで、より精度の高い物体検出やセマンティックセグメンテーションを行うことができます。
音声認識: 音声の中で最も重要な部分に焦点を当てることで、より精度の高い音声認識を行うことができます。
A-D 変換 (Analog-to-Digital Conversion)
特徴: アナログ信号をデジタル信号に変換するプロセス。
目的: 音声などのアナログデータをデジタル化し、コンピュータで処理可能にする。
説明: A-D変換により、音声データはデジタル化され、その後の処理、分析、保存が容易になります。
パルス符号変調器 (PCM)
特徴: アナログ信号をサンプルし、各サンプルをデジタル値に変換する最も一般的なデジタル音声フォーマット。
目的: 音声信号をデジタル形式に変換し、デジタル通信や記録を可能にする。
説明: PCMは音声通信やオーディオ記録に広く使用され、アナログ音声を高精度にデジタルデータに変換します。
高速フーリエ変換 (FFT)
特徴: 離散フーリエ変換を高速に計算するアルゴリズム。
目的: 時間領域の信号を周波数領域に変換し、信号の周波数成分を解析する。
説明: FFTは音声信号の分析や画像処理に不可欠で、信号の周波数特性を迅速に把握することができます。
スペクトル包絡 (Spectral Envelope)
特徴: 音声信号のスペクトル(周波数成分の強度分布)の滑らかな包絡線を表す。
目的: 音声の音響特性を把握し、音声合成や音声認識に利用する。(音韻の識別)
説明: スペクトル包絡は、音声の音色や発声機構の特性を反映し、話者の特定や音声の性質を理解するのに役立ちます。
メル周波数ケプストラム係数 (MFCC)
特徴: 音声信号から抽出される特徴量で、人間の聴覚特性を模倣した周波数スケーリングを使用。
目的: 音声認識や話者識別など、音声処理タスクにおける効果的な特徴量として使用する。
説明: MFCCは音声信号のメルスケール周波数領域における短時間パワースペクトルのログを取り、そのケプストラムを求めることで得られます。これにより、音声のティンバーやピッチなどの重要な属性が捉えられます。
メル周波数ケプストラム係数 (MFCC) の要約説明
**メル周波数ケプストラム係数 (MFCC)**は、音声信号の特徴量を抽出する際に用いられる手法です。音声認識、音声合成、音声分類など、様々な音声処理タスクにおいて広く利用されています。
MFCCの特徴
MFCCは以下の3つの特徴を持ちます。
聴覚に基づいた特徴量: 人間の聴覚特性を考慮したメル尺度を用いることで、人間の聴覚にとって重要な音響情報を抽出することができます。
周波数情報の圧縮: 離散コサイン変換を用いることで、周波数情報を圧縮し、低次元のベクトルで表現することができます。
頑健性: ノイズや環境変化の影響を受けにくい特徴量であるため、様々な環境で安定した性能を発揮することができます。
MFCCの利点
MFCCには、以下の利点があります。
高い精度: 音声認識、音声合成、音声分類など、様々な音声処理タスクにおいて高い精度を実現することができます。
計算効率: 処理の計算コストが比較的低いため、リアルタイム処理にも適しています。
頑健性: ノイズや環境変化の影響を受けにくい特徴量であるため、様々な環境で安定した性能を発揮することができます。
フォルマント (Formant)
特徴: 音声のスペクトル中で顕著なピークを示す周波数帯域。
目的: 音声の特定の母音品質を識別し、話者の声の特徴を分析する。
説明: フォルマントは母音の特性を決定し、言語学者や音声科学者が話者の声や発音の特徴を理解するのに重要な指標です。
フォルマント (Formant) の要約説明
フォルマントは、音声における共鳴周波数(共振周波数)のことであり、人間の声道形状によって決まります。
人の声は、声帯の振動によって基本的な音波 (基音) が発生しますが、この基音が声道を通過する際に、声道形状によって共鳴が起こり、フォルマントと呼ばれる特定の周波数が強調されます。
フォルマントの種類
フォルマントは、共鳴する場所によってF1、F2、F3のように番号で区別されます。
F1: 口腔の前部で共鳴するフォルマントで、母音の種類を区別する際に重要な役割を果たします。
F2: 舌の高さによって共鳴するフォルマントで、母音の高低を区別する際に重要な役割を果たします。
F3: 口腔の奥で共鳴するフォルマントで、母音の明暗を区別する際に重要な役割を果たします。
フォルマントの特徴
フォルマントは以下の特徴を持ちます。
母音の特徴: フォルマントは、母音の種類、高低、明暗を区別する重要な役割を果たします。
話者の特徴: フォルマントは、話者の性別、年齢、体格などの特徴を反映します。
音声認識: フォルマントは、音声認識において重要な特徴量として利用されます。
フォルマント周波数 (Formant Frequency)
特徴: 音声のフォルマントにおける中心周波数。
目的: 音声信号の特徴的な母音特性を定量的に分析する。
説明: フォルマント周波数は、音声の特定の母音がどのように発音されるかを示し、言語間や個人間の発音の違いを分析するのに利用されます。
音韻 (Phoneme)
特徴: 言語において意味を区別する最小の音声単位。
目的: 音声言語の基本的な構造を理解し、音声認識や合成を行う。
説明: 音韻は言語の音声を分類する基本的な要素であり、音声認識システムではこれを正確に識別することが重要です。
音韻とは、言語の音声体系における最小単位であり、意味を持つ音素を構成する要素です。日本語の音韻は、子音と母音の組み合わせによって構成されます。
音韻の特徴
抽象的な概念: 音韻は、具体的な音声ではなく、言語における抽象的な概念です。例えば、「か」と「き」の音声は異なりますが、音韻としては同じ「/k/」と分析されます。
機能的な役割: 音韻は、単語の意味を区別する役割を果たします。例えば、「か」と「き」は音韻が異なるため、「かご」と「きご」は意味が異なります。
言語体系の一部: 音韻は、他の音韻と組み合わせて、単語や文を構成します。
音素 (Phonetic)
特徴: 音声の発音を表す記号、通常は国際音声記号(IPA)を使用。
目的: 音声の正確な発音を文書化し、言語学的な分析を行う。
説明: 音素は、音声の具体的な発音方法を示し、言語の音響的特性を詳細に記録します。
音素は、言語における最小の音声単位であり、意味を持つ音韻を構成する要素です。日本語の音素は、子音と母音の組み合わせによって構成されます。
音素の特徴
抽象的な概念: 音素は、具体的な音声ではなく、言語における抽象的な概念です。例えば、「か」と「き」の音声は異なりますが、音素としては同じ「/k/」と分析されます。
機能的な役割: 音素は、単語の意味を区別する役割を果たします。例えば、「か」と「き」は音素が異なるため、「かご」と「きご」は意味が異なります。
言語体系の一部: 音素は、他の音素と組み合わせて、単語や文を構成します。
音声認識エンジン (Speech Recognition Engine)
特徴: 音声データをテキストデータに変換するためのソフトウェアまたはシステム。
目的: 自然言語処理を通じて音声データから情報を抽出し、対話型サービスや文書化を自動化する。
説明: 音声認識エンジンは、ユーザーの話す言葉をテキストに変換し、さまざまなアプリケーションでの使用が可能になります。例えば、音声操作システムや音声対話型アシスタントなどがあります。
音声認識エンジンの仕組み
音声認識エンジンは、大きく分けて以下の4つのステップで処理されます。
前処理: 音声信号をノイズ除去や音声特徴量抽出などの処理を行います。
音響モデル: 音声特徴量から音素の並びを推定します。
言語モデル: 音素の並びから単語の並びを推定します。
デコーダ: 単語の並びを文脈に応じて修正し、最終的な認識結果を出力します。
隠れマルコフモデル (Hidden Markov Model, HMM)
特徴: 非観測の状態がマルコフプロセスに従い、観測データがこれらの状態に依存して生成される統計モデル。
目的: 時系列データや音声データのようなシーケンスのモデリングを行う。
説明: HMMは特に早期の音声認識システムで広く使用され、音声や言語の時間依存性をモデル化するのに適しています。
隠れマルコフモデル(Hidden Markov Model、HMM)は、特に時系列データやシーケンスデータの解析に適用される統計的モデルの一種です。HMMは、観測されない隠れ状態が存在し、それがマルコフ過程(つまり、次の状態が現在の状態のみに依存する過程)に従うと仮定しています。以下に、HMMの主要な特徴と、G検定に出そうな内容を詳しく説明します。
HMMの基本的な特徴
隠れ状態と観測状態:
HMMでは、システムの状態が直接観測できない「隠れ状態」によって表されます。これらの隠れ状態は観測データに間接的に影響を与えます。
各隠れ状態は、一連の観測可能な出力(観測状態)を生成する確率分布に関連付けられています。
マルコフ性質:
HMMの核心的な特性はマルコフ性です。これは、任意の時点での隠れ状態が直前の状態のみに依存し、それ以前の歴史からは独立しているという性質です。
遷移確率:
隠れ状態間の遷移は確率的に決まり、この遷移確率はモデルのパラメータとして定義されます。
出力確率:
各隠れ状態において特定の観測が生成される確率です。これもまたモデルの重要なパラメータの一部です。
HMMの用途
音声認識:
HMMは音声信号をテキストに変換する際に用いられます。音声の各フレームが観測状態として扱われ、発話された単語や音素のシーケンスが隠れ状態に対応します。
自然言語処理:
品詞タグ付けや文法解析など、テキストのシーケンスデータを処理するために使用されます。
バイオインフォマティクス:
DNA配列やタンパク質の配列解析において、生物学的機能や構造を予測する際に利用されます。
HMMの学習と推定
学習:
Baum-Welchアルゴリズム(期待値最大化アルゴリズムの一種)を使用して、観測データからHMMのパラメータ(遷移確率と出力確率)を推定します。
推定:
Viterbiアルゴリズムを用いて、与えられた観測データに対して最も可能性の高い隠れ状態のシーケンスを推定します。
確率計算:
前向きアルゴリズムを使用して、観測されたデータシーケンスが生成される確率を計算します。
HMMを利用する際に定義するべき要素
隠れ状態のセット:
モデルの隠れ状態(Hidden States)を定義します。これらは観測されない内部状態であり、モデルの主要な要素です。隠れ状態が何を表すのか(例: 音声認識では音素、テキスト解析では品詞など)、それらの状態がどのように遷移するかを明確にする必要があります。
観測のセット:
各隠れ状態からどのような観測(Observations)が生成され得るかを定義します。観測は隠れ状態に依存し、観測データの具体的な形式を決定します。
遷移確率:
各隠れ状態から他の隠れ状態への遷移確率(Transition Probabilities)を定義します。これにより、状態間のダイナミクスがモデル化されます。
出力確率(観測確率):
各隠れ状態において、特定の観測が生成される確率(Emission Probabilities)を定義します。この確率分布は、隠れ状態に基づいて観測がどのように発生するかを示します。
初期状態の確率分布:
モデルが最初にどの隠れ状態にあるかの確率分布を定義します。これは特にシーケンスの開始時の状態推定に重要です。
HMMを利用する際の注意点
適切なモデルサイズの選択:
隠れ状態の数を過大または過小に設定すると、モデルのパフォーマンスに悪影響を与える可能性があります。状態数が多すぎると過学習に陥りやすく、少なすぎると未学習になりがちです。
データへの適用性の検討:
HMMは一定のマルコフ性(過去の状態の影響がないこと)を前提としています。この仮定が現実のデータに合致しない場合、モデルの効果が低下することがあります。
学習データの量:
十分な学習データがないと、遷移確率や出力確率を正確に推定することが困難です。データが少ない場合は、パラメータの過学習に注意が必要です。
アルゴリズムの選択:
HMMのパラメータ推定には通常、Baum-Welchアルゴリズムが使用されますが、計算コストが高いことが問題になることがあります。また、最適な状態系列の推定にはViterbiアルゴリズムが使用されますが、これも計算資源を要求します。
隠れマルコフモデルとニューラルネットワークの組み合わせ
隠れマルコフモデルとニューラルネットワークを組み合わせることで、それぞれの利点を活かしたモデルを構築することができます。
HMM-RNN: 隠れマルコフモデルの状態遷移確率や出力確率を、ニューラルネットワークで学習させる手法。
ニューラルHMM: ニューラルネットワークのアーキテクチャに、隠れマルコフモデルの概念を取り入れたモデル。
これらのモデルは、以下の利点を持っています。
従来のHMMよりも高い精度: ニューラルネットワークを用いることで、より精度の高い状態推定や出力予測を行うことができる。
従来のNNよりも解釈性が高い: 隠れマルコフモデルの概念を取り入れることで、モデルの動作をより解釈しやすくなる。
隠れマルコフモデルとニューラルネットワークの例
音声認識: 音声信号を隠れ状態と観測出力と捉え、HMM-RNNを用いて音声認識を行う。
機械翻訳: 文章を単語の列と隠れ状態と捉え、ニューラルHMMを用いて機械翻訳を行う。
異常検知: センサーデータから異常な状態を検出するために、HMM-RNNを用いる。
Juliusと隠れマルコフモデル (HMM) の関係
Juliusは、音声認識エンジンであり、隠れマルコフモデル (HMM) を基盤とした音声認識技術を採用しています。HMMは、音声認識をはじめ、音声合成、音声処理など、様々な音声関連タスクで広く利用されている統計的なモデルです。
隠れマルコフモデルと音声合成タスクにおける役割
隠れマルコフモデル (HMM) は、音声合成タスクにおいて重要な役割を果たす統計的モデルです。音声合成とは、テキストデータを音声に変換する技術であり、様々な分野で広く利用されています。
WaveNet
特徴: 深層学習に基づく音声生成モデルで、畳み込みニューラルネットワークを使用して音声波形を直接モデリングする。
目的: 高品質な音声合成を実現する。
説明: WaveNetは音声の生波形を生成することで、自然で流暢な音声合成を行い、特にテキストから音声へのアプリケーションにおいて革新をもたらしました。
WaveNet
WaveNetは、DeepMindによって開発された深層学習ベースの音声合成モデルです。2016年に公開され、テキストから自然な音声を生成することができる点で注目されました。特に、従来のテキスト音声変換(TTS)システムと比較して、非常にリアルな人間の声を模倣する能力があります。
特徴
オートリグレッシブモデル:
WaveNetは、オートリグレッシブ(自己回帰)モデルを使用しており、過去のオーディオサンプルを条件として、新しいオーディオサンプルを一つずつ生成します。
畳み込みニューラルネットワーク:
音声サンプルの生成には、畳み込み層が使用されています。これにより、局所的な音声パターンを学習し、それを利用して次の音声波形を生成します。
ダイレーテッド畳み込み:
過去の情報を効率的に処理するために、拡張畳み込み(ダイレーテッド畳み込み)が用いられます。これにより、長期の時間依存性を捉えることが可能です。
高品質な音声生成:
WaveNetは、従来のパラメトリックまたは連結型音声合成システムよりも自然でリアルな音声を生成することができます。生成される音声は滑らかで、息継ぎや発声時の微妙なニュアンスも再現可能です。
多言語対応と多声種対応:
このモデルは、さまざまな言語や声のタイプに対応しており、一つのモデルで複数の声やアクセントを生成することができます
メル尺度 (Mel Scale)
特徴: 人間の耳の感じる音の高さの知覚に基づいた周波数尺度。
目的: 音声信号の処理と分析を人間の聴覚に近づける。
説明: メル尺度は、特に音声信号処理で使用され、音の知覚的な特性に合わせて周波数成分を変換します。
N-gram
特徴: テキストデータにおいて、隣接するN個のアイテム(通常は単語や文字)の連続。
目的: 言語モデルやテキストの確率的な特性を把握する。
説明: N-gramモデルは特にテキストの統計的な特性を捉えるのに有効で、言語の自然な流れや文脈をモデル化します。N-gramは、言葉のパターンを分析するための統計的な方法です。連続するN個の単語の組み合わせを調べ、その出現頻度を分析することで、文章の構造や意味を理解しやすくなります。
BoW (Bag-of-Words)
特徴: テキストを単語の出現回数のみを考慮したベクトルで表現する方法。
目的: 文書のトピックや内容を簡潔に表現する。
説明: BoWモデルは文書分類や情報検索において基本的なテキスト表現方法として利用されますが、単語の順序や文脈は考慮されません。
BOWと形態素解析の組み合わせ
BOWと形態素解析を組み合わせることで、以下の利点が得られます。精度向上: 形態素解析により、単語の意味や役割をより詳細に理解することができるため、BOWよりも精度の高い文書理解が可能になります。
情報量増加: 形態素解析により、単語以外にも品詞や活用形などの情報を取り込むことができるため、BOWよりも情報量が増加します
多言語対応: 形態素解析は言語ごとに異なる処理が必要となりますが、BOWは言語に依存しないため、多言語対応が容易になります。
ワンホットベクトル (One-Hot Vector)
特徴: カテゴリ変数をビットベクトルとして表現し、該当するインデックスのみ1で他は0のベクトル。
目的: カテゴリ変数を数値化し、機械学習アルゴリズムで扱いやすくする。
説明: ワンホットベクトルは、特にカテゴリデータの処理に使用され、各カテゴリを明確に区別します。
TF-IDF (Term Frequency-Inverse Document Frequency)
特徴: 単語の重要性を評価するために、その単語の出現頻度と文書頻度の逆数を用いた重み付けスキーム。
目的: 文書内の単語の重要性と希少性を数値化し、文書検索や情報検索の効率を向上させる。
説明: TF-IDFは単語がどの程度情報を持っているかを評価し、特定のクエリに対する文書の関連度を判断するのに役立ちます。
単語埋め込み (Word Embedding)
特徴: 単語を密なベクトル空間に埋め込み、単語の意味的な関係をベクトルの距離で表現する。
目的: 単語の意味的な類似性を捉え、自然言語処理タスクの性能を向上させる。
説明: 単語埋め込みモデル如何にGloVeやWord2Vecがあり、これらは単語間の意味的な類似性を捉えることができ、言語モデルやテキスト分析に広く利用されます。
局所表現 (Local Representation)
特徴: 各単語やアイテムが独立したエンティティとしてベクトル空間上に表現される方法(例:ワンホットエンコーディング)。
目的: 単語やアイテムを明確に区別し、計算モデルで簡単に扱う。
説明: 局所表現では、各エンティティは独立した次元を持ち、他のエンティティとの直接的な関連は表現されません。これにより、計算処理が簡潔になりますが、意味的な関係は捉えられません。
局所表現:詳細解説
局所表現(Local Representation)は、自然言語処理(NLP)において、個々の単語を独立したベクトルで表現する手法です。各単語は、他の単語との関係性や文脈を考慮せずに、単独でベクトル化されます。
局所表現は、主に以下の2つの方法で実現されます。
1. ワンホットエンコーディング (One-Hot Encoding)
ワンホットエンコーディングは、単語を固定長のバイナリベクトルとして表現する最もシンプルな方法です。このベクトルは、単語に対応する要素が1となり、他の要素はすべて0となります。
例:
単語 "猫" は、[1, 0, 0, 0, 0] というベクトルで表現されます。
単語 "犬" は、[0, 1, 0, 0, 0] というベクトルで表現されます。
単語 "鳥" は、[0, 0, 1, 0, 0] というベクトルで表現されます。
ワンホットエンコーディングは、実装が非常にシンプルで、計算コストも低いという利点があります。しかし、以下の欠点もあります。
情報量: ワンホットエンコーディングは、単語間の意味的な類似性を表現することができません。
次元数: ワンホットエンコーディングは、語彙数と同じ次元数のベクトルが必要となるため、語彙数が多い場合は次元数が非常に高くなります。
2. Bag-of-Words (BoW)
Bag-of-Wordsは、文書を構成する単語の集合とその出現頻度をベクトルとして表現する手法です。各単語は、出現頻度に応じてベクトル要素に重み付けされます。
例:
文書 "猫が犬を追いかけた" は、[猫: 1, 犬: 1, 追いかけた: 1] というベクトルで表現されます。
文書 "犬が鳥を食べた" は、[犬: 1, 鳥: 1, 食べた: 1] というベクトルで表現されます。
Bag-of-Wordsは、文書の主題をある程度捉えることができますが、以下の欠点があります。
文脈: Bag-of-Wordsは、単語間の順序や文脈を考慮しません。
意味: Bag-of-Wordsは、単語の意味的な類似性を表現することができません。
局所表現の利点
シンプル: 局所表現は、実装が非常にシンプルで、計算コストも低い。
解釈: 局所表現は、各要素が何を表しているのかが明確であるため、解釈しやすい。
局所表現の欠点
意味: 局所表現は、単語間の意味的な類似性を表現することができない。
文脈: 局所表現は、単語間の順序や文脈を考慮しない。
局所表現の用途
局所表現は、以下の用途に適しています。
テキスト分類: テキストをカテゴリに分類するタスクにおいて、局所表現を用いることができます。
特徴量エンジニアリング: 機械学習モデルの入力データとして使用する特徴量を作成する際に、局所表現を用いることができます。
分散表現との比較
分散表現は、局所表現とは対照的に、単語をベクトル空間上で点として表現する手法です。分散表現は、単語間の意味的な類似性を表現することができ、局所表現よりも多くの情報を含むことができます。
近年では、分散表現が主流となり、局所表現は補助的な役割で使用されることが多くなっています。
まとめ
局所表現は、単語を独立したベクトルで表現するシンプルな方法です。ワンホットエンコーディングとBag-of-Wordsが代表的な局所表現の手法です。局所表現は、実装がシンプルで解釈しやすいという利点がありますが、単語間の意味的な類似性や文脈を表現することができません。近年では、分散表現が主流となり、局所表現は補助的な役割で使用されることが多くなっています。
分散表現 (Distributed Representation)
特徴: エンティティを複数の特徴が組み合わさった形で表現し、それぞれの特徴が多くのエンティティに対して何らかの情報を共有する。
目的: より豊かな情報表現を実現し、エンティティ間の類似性を効果的にモデル化する。
説明: 分散表現は、エンティティの意味的な側面を多次元空間上で捉えることで、類似のエンティティが空間上で近くに位置するようにします。これにより、単語や画像などの複雑なデータの関連性をより詳細に分析できます。
自然言語処理における単語とベクトルの1対1表現:詳細解説
自然言語処理 (NLP) において、単語とベクトルを1対1で対応付ける方法は、大きく2つのカテゴリに分類されます。それぞれの特徴、利点、欠点、そして代表的なアルゴリズムを以下に詳しく説明します。
1. 分散表現 (Distributed Representation)
分散表現は、単語を固定長のベクトルとして表現する手法です。このベクトルは、単なるIDではなく、単語の意味や文脈における役割を捉えるように学習されます。分散表現の主な利点は以下の通りです。
意味の捉え: 分散表現は、単語の意味や文脈における役割を捉えるように学習されるため、単なるIDとしてのベクトルよりも、単語間の意味的な類似性を表現することができます。
柔軟性: 分散表現は、単語だけでなく、文、文章、さらには文書全体をベクトルとして表現することができます。
汎用性: 分散表現は、様々なNLPタスクに応用することができます。
一方、分散表現には以下の欠点もあります。
計算量: 分散表現を学習するには、大量の計算量が必要となります。
解釈: 分散表現は、学習データに基づいて生成されるため、その解釈が難しい場合があります。
分散表現の代表的なアルゴリズムは以下の通りです。
Word2Vec: Googleが開発した分散表現アルゴリズムで、単語の共起関係に基づいてベクトルを学習します。
GloVe: スタンフォード大学が開発した分散表現アルゴリズムで、確率共起統計に基づいてベクトルを学習します。
fastText: Facebookが開発した分散表現アルゴリズムで、単語の一部や接頭辞・接尾辞などを考慮してベクトルを学習します。
2. ワンホットエンコーディング (One-Hot Encoding)
ワンホットエンコーディングは、単語を固定長のバイナリベクトルとして表現する手法です。このベクトルは、単語に対応する要素が1となり、他の要素はすべて0となります。ワンホットエンコーディングの主な利点は以下の通りです。
シンプル: ワンホットエンコーディングは、非常にシンプルで実装しやすい手法です。
解釈: ワンホットエンコーディングは、各要素が何を表しているのかが明確であるため、解釈しやすい手法です。
一方、ワンホットエンコーディングには以下の欠点もあります。
情報量: ワンホットエンコーディングは、単語間の意味的な類似性を表現することができません。
次元数: ワンホットエンコーディングは、語彙数と同じ次元数のベクトルが必要となるため、語彙数が多い場合は次元数が非常に高くなります。
ワンホットエンコーディングは、分散表現ほど汎用性はありませんが、以下の用途に適しています。
特徴量エンジニアリング: 機械学習モデルの入力データとして使用する特徴量を作成する際に、ワンホットエンコーディングを用いることができます。
テキスト分類: テキストをカテゴリに分類するタスクにおいて、ワンホットエンコーディングを用いることができます。
まとめ
自然言語処理における単語とベクトルの1対1表現には、分散表現とワンホットエンコーディングの2種類があります。それぞれの方法には、利点と欠点があり、適切な方法はタスクやデータによって異なります。分散表現は、より高度なNLPタスクに適していますが、計算量や解釈が難しい場合があります。一方、ワンホットエンコーディングは、シンプルで解釈しやすいですが、情報量や次元数の問題があります。
分散表現学習:詳細解説
分散表現学習(Distributed Representation Learning)は、単語やフレーズをベクトルとして表現する手法です。
従来のone-hot表現では、単語を高次元のベクトルで表現していましたが、各要素が0である要素が多く、情報量が少ないという問題がありました。
分散表現学習では、単語を低次元のベクトルで表現することで、情報量を削減しつつ、意味的な関係性を保持することができます。
本記事では、分散表現学習について、以下の内容を詳細に解説します。
分散表現学習の仕組み
代表的な分散表現学習手法
分散表現学習の利点
分散表現学習の課題
分散表現学習の応用例
1. 分散表現学習の仕組み
分散表現学習は、主に以下の2つの手順で実行されます。
コーパスデータの準備: コーパスデータとは、大量の文書や文章データのことです。分散表現学習には、大量のコーパスデータが必要となります。
モデルの学習: コーパスデータをモデルに入力し、学習を行います。モデルは、単語やフレーズと、それらの周辺単語の関係性などを学習します。
学習が完了すると、各単語やフレーズに対して、固有のベクトルが割り当てられます。
このベクトルは、分散表現と呼ばれ、その単語やフレーズの意味的な情報を表します。
2. 代表的な分散表現学習手法
代表的な分散表現学習手法は以下の通りです。
Word2Vec: 単語をベクトル化する手法です。Skip-gram法とCBOW法という2つの方法があります。
GloVe: 単語とフレーズを同時にベクトル化する手法です。
FastText: 構文情報を考慮した単語ベクトル化手法です。
ELMo: 文脈情報を考慮した単語ベクトル化手法です。
これらの手法はそれぞれ、異なる特徴と利点・欠点を持っています。
具体的な状況に合わせて、適切な手法を選択することが重要です。
3. 分散表現学習の利点
分散表現学習には、以下の利点があります。
情報量の削減: 単語を低次元のベクトルで表現することで、情報量を削減することができます。
意味的な関係性の保持: 単語間の意味的な関係性をベクトル空間上で表現することができます。
データ効率の向上: 少ない学習データで高精度なモデルを学習することができます。
多様な応用: 自然言語処理の様々なタスクに応用することができます。
4. 分散表現学習の課題
分散表現学習には、以下の課題があります。
パラメータの調整: 分散表現学習には、多くのパラメータが存在するため、適切なパラメータを設定することが重要です。
計算量: 分散表現学習は、計算量が多いという課題があります。
解釈可能性: 分散表現学習は、複雑なモデルであるため、その動作を理解することが難しい場合があります。
word2vec
特徴: 単語を密なベクトル空間に埋め込むためのフレームワークで、特に「スキップグラム」と「連続バッグ・オブ・ワード(CBOW)」の2つのモデルがある。
目的: 大規模なテキストコーパスから単語の意味的な特徴を学習し、単語間の意味的な類似性をベクトルの距離で表現する。
説明: word2vecのモデルは単語を周囲の単語の文脈に基づいてベクトル空間に埋め込みます。これにより、単語の意味的な類似性が反映されたベクトルを生成し、これが自然言語処理の多くのタスクでの基礎となります。
Word2Vecの特徴
コンテキストに基づく学習:Word2Vecは、ある単語の周囲にある単語(コンテキスト)からその単語の意味を学習します。このプロセスは、ニューラルネットワークを通じて行われ、単語を予測するための「推論」に基づいています。
ニューラルネットワークモデル:Word2Vecは、浅いニューラルネットワーク(通常は1つの隠れ層を持つ)を使用しています。このネットワークは、特定のタスク(CBOWやSkip-gram)を解決するように訓練されます。
CBOW (Continuous Bag of Words):このアプローチでは、コンテキスト内の複数の単語からターゲット単語を予測します。
Skip-gram:このモデルは、ターゲット単語からその周囲の単語を予測することを目的としています。
セマンティック&シンタクティックパターンの学習:Word2Vecは、単語の類似性だけでなく、より複雑なパターン(例えば、「男性」と「女性」、「都市」と「国」などの関係性)も学習します。
推論ベース vs カウントベース
推論ベース:Word2Vecのようなモデルは、大量のテキストデータから直接単語のベクトルを学習します。これにより、実際の使用例に基づいて単語の意味を捉えることができます。また、大規模なコーパスに適しており、学習過程で単語間の微妙なニュアンスを捉えることができます。
カウントベース:LSAなどのカウントベースの手法は、単語とそのコンテキストの共起行列を作成し、次に次元削減技術(例えば、特異値分解)を適用して単語のベクトル表現を得ます。これは単語の共起情報に基づいており、推論ベースのアプローチに比べて直感的で数学的な処理が多く含まれます。
Word2Vecの推論ベースのアプローチは、特に大規模なテキストデータで効果を発揮し、単語間の複雑な関係やパターンを効果的にモデル化することができます。
トマス・ミコロフ(Tomas Mikolov)は、自然言語処理の分野で広く知られている研究者で、特に単語の分散表現を生成するための手法である「Word2Vec」の開発者として知られています。彼はGoogleの研究者として、Word2Vecの開発に携わりました。
Word2Vecは、単語の言語コンテキストを再構築するように訓練された浅い2層ニューラルネットワークであり、大きなコーパスを受け取って一つのベクトル空間を生成します。このベクトル空間は典型的には数百次元からなり、コーパスの個々の単語はベクトル空間内の個々のベクトルに割り当てられます。コーパス内で同じコンテキストを共有する単語ベクトルは、ベクトル空間内の近くに配置されます。
Word2Vecは、その名前の表す通り、単語をベクトル化して表現するする定量化手法であり、例えば日本人が日常的に使う語彙数は数万から数十万といわれるが、Word2Vecでは各単語を200次元くらいの空間内におけるベクトルとして表現します。その結果、今まで分からなかったり精度を向上するのが難しかった単語同士の類似度や、単語間での加算・減算などができるようになり、単語の「意味」を捉えられるようになりました。
スキップグラム (Skip-gram)
特徴: word2vecの一部で、ターゲット単語からその文脈内の単語を予測するモデル。
目的: 大規模なテキストデータから効率的に高品質な単語ベクトルを学習する。
説明: スキップグラムモデルは、特に大量のデータが利用可能な場合に高い性能を発揮し、単語の少ない出現にも強いモデルです。
CBOW (Continuous Bag of Words)
特徴: 文脈内の単語からターゲット単語を予測する、word2vecのモデルの一つ。
目的: 文脈に基づいて単語の意味を捉え、効率的な単語ベクトルを生成する。
説明: CBOWはスキップグラムよりも速く学習できる反面、少ないデータでは性能が低下することがあります。それでも、一般的な文脈での単語の使用を効果的にモデル化できます。
fastText
特徴: word2vecに似ていますが、単語をさらに細かいn-gramの集合として扱います。
目的: 単語内の部分的な情報を利用して、形態素の類似性も考慮した単語ベクトルを生成する。
説明: fastTextは特に形態素が豊かな言語(例えばトルコ語やフィンランド語など)で効果を発揮し、新しい単語やレアな単語に対しても強いモデルです。
FastTextについての概要
FastTextは、テキスト表現と分類器の学習のためのオープンソースで無料の軽量ライブラリです。Facebookによって2016年にリリースされた自然言語処理ライブラリであり、日常の人間のコミュニケーションで使用される言語を処理するための一連の技術を含んでいます。Word2Vecなどの以前のモデルでは考慮されなかった「go」や「goes」のような活用形も扱うことができるモデルです。
FastTextの特徴と応用
オープンソース: FastTextはオープンソースであり、誰でも無料で利用することができます。1
自然言語処理: Facebookによって開発され、日常の人間のコミュニケーションで使用される言語を処理するための技術を提供します。2
活用形の処理: Word2Vecなどのモデルでは考慮されなかった活用形も扱うことができます。3
多クラス分類: livedoorニュースコーパスにおける多クラス分類に使用されました。
ELMo (Embeddings from Language Models)
特徴: 文脈に依存する単語の表現を生成するために、双方向LSTMベースの言語モデルを使用。
LMoは以下の特徴を持っています。文脈依存性: 単語の意味を文脈に応じて動的に変化するベクトルで表現するため、従来の単語表現学習手法よりも高い精度で単語の意味を捉えることができます。
双方向処理: 文脈を考慮するために、文章を両方向から処理する双方向LSTM (Long Short-Term Memory) を用いています。
事前学習: 大規模なコーパスを用いて事前学習を行うことで、汎用性の高い単語表現を学習することができます。
汎用性: 文書分類、情報検索、機械翻訳など、様々な自然言語処理タスクに適用することができます。
目的: 単語の使用状況に基づいてその意味を動的に変化させ、より豊かな単語埋め込みを提供する。
説明: ELMoは固定された単語ベクトルではなく、単語が使われる文脈に応じてその表現が変わるため、特定のタスクに対して細かく調整が可能です。
言語モデル (Language Model)
特徴: 単語のシーケンスに確率を割り当てるモデルで、次に来る単語の予測や文の生成に使用される。
目的: 自然言語の統計的特性を学習し、テキスト生成や音声認識、機械翻訳などのタスクを改善する。
説明: 言語モデルは、テキストデータの大規模なコーパスから言語の統計的パターンを学習し、これを基にテキスト生成やその他の言語処理タスクが行われます。
言語モデル:確率モデルに基づく詳細解説
言語モデル は、過去の入力系列に基づいて次回の出力単語の分布を求める確率モデルです。
このモデルは、機械翻訳、音声認識、チャットボットなど、様々な自然言語処理タスクにおいて重要な役割を果たします。
本記事では、言語モデルについて、以下の内容を確率モデルの観点から詳細に解説します。
確率モデルとしての言語モデル
統計的言語モデルとニューラルネットワーク言語モデル
代表的な言語モデル
言語モデルの評価指標
言語モデルの応用例
言語モデルの課題と展望
1. 確率モデルとしての言語モデル
言語モデルを確率モデルとして捉えると、以下の2つの要素で構成されます。
事象空間: すべての可能な単語列の集合
確率分布: 事象空間上の各単語列に対する確率
事象空間 は、言語モデルが生成できるすべての可能な単語列を網羅します。
例えば、3単語からなる単語列の場合、事象空間は「私は」、「あなたは」、「彼は」など、すべての3単語の組み合わせを含みます。
確率分布 は、事象空間上の各単語列に対する確率を定義します。
例えば、「私は本を読んでいる」という単語列の確率が0.8であれば、この単語列が出現する可能性が80%であることを意味します。
言語モデルは、この確率分布を用いて、与えられた文章の続きを予測します。
具体的には、以下の手順で実行されます。
部分的な文章を入力: 例えば、「私は」という部分的な文章を入力します。
確率分布に基づいて続きを予測: 言語モデルは、確率分布に基づいて、「本を読んでいる」、「ご飯を食べている」、「テレビを見ている」などの候補を提案します。
最も確率の高い候補を選択: 言語モデルは、最も確率の高い候補を選択します。
2. 統計的言語モデルとニューラルネットワーク言語モデル
言語モデルには、主に以下の2つのアプローチがあります。
統計的言語モデル は、過去の統計情報に基づいて、次の単語を予測します。
具体的には、n-gramモデルや言語規則などを用いて、単語間の出現頻度や文法規則などを学習します。
ニューラルネットワーク言語モデル は、ニューラルネットワークを用いて、過去の単語と次の単語の関係性を学習します。
具体的には、RNNやTransformerなどのニューラルネットワークアーキテクチャを用いて、文脈情報を考慮した単語表現を学習します。
統計的言語モデル は、計算量が少ないという利点がありますが、文脈依存性を考慮することができず、精度が低いという欠点があります。
ニューラルネットワーク言語モデル は、統計的言語モデルよりも精度が高いという利点がありますが、計算量が多いという欠点があります。
3. 代表的な言語モデル
代表的な言語モデルは以下の通りです。
n-gramモデル: 最も単純な言語モデルの一つです。前のn個の単語に基づいて、次の単語を予測します。
RNN (Recurrent Neural Network): 過去のすべての入力単語を考慮して、次の単語を予測します。
Transformer: 近年注目を集めている言語モデルです。自己アテンションと呼ばれるメカニズムを用いて、長距離の依存関係を捉えることができます。
GPT-3: OpenAIが開発した大規模言語モデルです。人間が書いた文章と区別がつかないほどの文章を生成することができます。
4. 言語モデルの評価指標
言語モデルの性能を評価するには、以下の指標が用いられます。
Perplexity: 予測が難しいほど値が低くなります。
BLEU: 機械翻訳の精度を評価するための指標です。
ROUGE: 要約の精度を評価するための指標です。
CIDEr: 画像キャプションの精度を評価するための指標です。
CTC (Connectionist Temporal Classification)
特徴: アライメントの問題なくシーケンスデータのラベル付けを行うための学習方法。
目的: 音声や手書きテキストなど、入力と出力の長さが異なる場合の学習を効果的に行う。
説明: CTCは特に音声認識で有効で、入力された音声データから直接テキストを生成する際に使用され、正確なタイミングでのラベル付けを必要としません。
Seq2Seq (Sequence to Sequence)
特徴: 一つのシーケンスを入力として別のシーケンスを出力するモデル。通常、エンコーダとデコーダの二部構成で構成される。(RNNモデル)
目的: 機械翻訳や自動要約など、一連のデータを別の形式や言語に変換すること。
説明: Seq2Seqモデルは、入力シーケンスを固定長のベクトルにエンコードし、そのベクトルを使用して目的のシーケンスをデコードします。このプロセスは、特に機械翻訳で効果的です。
Seq2Seqモデルは、自然言語処理(NLP)におけるシーケンスからシーケンスへの変換を行うニューラルネットワークモデルです。入力シーケンス(単語列など)を処理し、別のシーケンス(翻訳文、要約文など)を生成するタスクに特化しています。
Seq2Seqモデルの構成
Seq2Seqモデルは、主に以下の2つのコンポーネントで構成されます。
エンコーダ: 入力シーケンスを処理し、固定長のベクトル表現に変換するコンポーネントです。
デコーダ: エンコーダが出力したベクトル表現に基づいて、出力シーケンスを生成するコンポーネントです。
エンコーダとデコーダは、それぞれLSTMやGRUなどの**再帰ニューラルネットワーク(RNN)**によって構成されることが多いです。RNNは、シーケンスデータの処理に適したニューラルネットワークアーキテクチャです。
Seq2Seqモデルの動作
エンコーダ: 入力シーケンスを単語ごとに処理し、それぞれの単語に対応するベクトル表現を生成します。
コンテキストベクトル: エンコーダが出力したベクトル表現を基に、コンテキストベクトルと呼ばれる固定長のベクトル表現を生成します。コンテキストベクトルは、入力シーケンス全体の情報を要約したベクトル表現です。
デコーダ: コンテキストベクトルを初期入力として、出力シーケンスを単語ごとに生成します。デコーダは、生成した単語を次の入力として使用し、シーケンスを逐次的に生成します。
Seq2Seqモデルの学習
Seq2Seqモデルは、教師あり学習によって学習されます。学習データは、入力シーケンスとそれに対応する出力シーケンスのペアで構成されます。モデルは、入力シーケンスに対して正しい出力シーケンスを生成できるように、パラメータを更新していきます。
Seq2Seqモデルの応用例
Seq2Seqモデルは、様々なNLPタスクに適用することができます。代表的な応用例は以下の通りです。
機械翻訳: ある言語の文章を別の言語に翻訳するタスク。
テキスト要約: 長文をより短い文章に要約するタスク。
チャットボット: 人間との自然な会話を行うチャットボットを開発するタスク。
音声認識: 音声をテキストに変換するタスク。
テキスト生成: 詩、小説、コードなど、様々な種類のテキストを生成するタスク。
Seq2Seqモデルの利点
柔軟性: Seq2Seqモデルは、様々な種類の入力シーケンスと出力シーケンスに対応することができます。
表現力: Seq2Seqモデルは、入力シーケンスの文脈を考慮した出力シーケンスを生成することができます。
汎用性: Seq2Seqモデルは、様々なNLPタスクに適用することができます。
Seq2Seqモデルの課題
学習データ: Seq2Seqモデルを学習するには、大量の教師あり学習データが必要です。
計算量: Seq2Seqモデルの学習には、多くの計算量が必要となります。
解釈: Seq2Seqモデルは、複雑なニューラルネットワークモデルであるため、その動作を解釈することが難しい場合があります。
Source-Target Attention
特徴: 翻訳タスクにおいて、ソース(入力)テキストとターゲット(出力)テキストの間で関連性の高い部分に焦点を当てるアテンションメカニズム。
目的: 翻訳の精度を向上させ、文脈に基づいた適切な翻訳を生成する。
説明: Source-Target Attentionは、翻訳を生成する際にソーステキストの関連する部分に注意を払いながら、より自然で正確なターゲットテキストを生成します。
Source-Target Attention:わかりやすく要約
Source-Target Attentionは、Seq2Seqモデルにおいて、デコーダが出力する単語を生成する際に、エンコーダが出力したベクトル表現をどのように参照するかを制御するメカニズムです。従来のSeq2Seqモデルでは、デコーダはエンコーダが出力したすべてのベクトル表現を等しく参照していました。しかし、Source-Target Attentionを用いることで、デコーダは生成する単語に関連するエンコーダのベクトル表現を重点的に参照することができます。
Source-Target Attentionの利点
精度向上: Source-Target Attentionを用いることで、デコーダは生成する単語に関連する情報に重点的に注目することができ、翻訳精度や要約精度を向上させることができます。
解釈性向上: Source-Target Attentionを用いることで、デコーダが出力する単語がどのエンコーダベクトル表現に基づいて生成されたのかを可視化することができ、モデルの動作を理解しやすくなります。
Encoder-Decoder Attention
特徴: エンコーダからの情報をデコーダが活用するためのアテンションメカニズム。
目的: エンコーダの全情報を効果的にデコーダに伝え、より関連性の高い出力を生成する。
説明: このアテンション機構は、エンコーダからの出力をデコーダが各ステップで利用することで、入力データの全体的な文脈を反映した出力が可能になります。
Encoder-Decoder Attention:わかりやすく要約
Encoder-Decoder Attentionは、Seq2Seqモデルにおいて、エンコーダとデコーダ間の情報の流れを制御するメカニズムです。従来のSeq2Seqモデルでは、デコーダはエンコーダが出力したすべてのベクトル表現を等しく参照していました。しかし、Encoder-Decoder Attentionを用いることで、デコーダは生成する単語に関連するエンコーダのベクトル表現を重点的に参照することができます。
Encoder-Decoder Attentionの利点
精度向上: Encoder-Decoder Attentionを用いることで、デコーダは生成する単語に関連する情報に重点的に注目することができ、翻訳精度や要約精度を向上させることができます。
解釈性向上: Encoder-Decoder Attentionを用いることで、デコーダが出力する単語がどのエンコーダベクトル表現に基づいて生成されたのかを可視化することができ、モデルの動作を理解しやすくなります。
Self-Attention
特徴: シーケンス内の各要素が他の全要素とどのように関連しているかをモデル化するアテンションメカニズム。
目的: シーケンスデータの内部構造をより深く理解し、効果的な表現を学習する。
説明: Self-Attentionは特にTransformerモデルで使用され、シーケンス内の長距離依存関係を捉えることができます。これにより、全体的な文脈が保持され、より一貫性のある出力が得られます。
Self-Attentionは、自然言語処理(NLP)におけるTransformerモデルで使用されるメカニズムです。Transformerモデルは、Seq2Seqモデルの代表的なアーキテクチャの一つであり、機械翻訳やテキスト要約などのタスクに高い精度を発揮します。
Self-Attentionは、入力シーケンス内の単語間の関係性を学習することで、より意味的な処理を行うことができます。従来のSeq2Seqモデルでは、単語を順番に処理していましたが、Self-Attentionを用いることで、文脈全体を考慮した処理が可能になります。
Self-Attentionの利点
精度向上: Self-Attentionを用いることで、文脈全体を考慮した処理が可能になり、機械翻訳精度やテキスト要約精度を向上させることができます。
解釈性向上: Self-Attentionを用いることで、どの単語が他の単語に影響を与えているのかを可視化することができ、モデルの動作を理解しやすくなります。
位置エンコーディング (Positional Encoding)
特徴: Transformerモデルにおいて、シーケンスの各要素の位置情報を注入するためのエンコーディング。
目的: モデルが単語の順序情報を利用して正確な文脈を把握する。
説明: 位置エンコーディングは、シーケンスの各位置に一意のエンコーディングを追加することで、モデルが単語の相対的な位置を理解し、より効果的な言語理解を行うのを助けます。
GPT (Generative Pre-trained Transformer)
特徴: 事前に大量のテキストデータで訓練された後、特定のタスクにファインチューニングされる自己注意ベースの言語生成モデル。
目的: 広範囲の言語タスクに対応可能な強力なモデルの提供。
説明: GPTは多様な言語生成タスクにおいて高い柔軟性と性能を示し、テキスト生成、要約、翻訳など幅広い応用が可能です。
GPT-2
特徴: GPTの拡張版で、さらに多くのレイヤーとパラメータを持つ。
目的: より複雑な文脈と長いシーケンスの処理能力を向上させる。
説明: GPT-2は特にテキスト生成の品質において顕著な改善を見せ、より自然で詳細なテキストを生成する能力を持ちます。
GPT-3
特徴: GPTシリーズの最新モデルで、数十億のパラメータを持つ極めて大規模なモデル。
目的: 事前学習だけで高い一般化能力を持ち、ほとんどのNLPタスクでファインチューニングなしで使用可能。
説明: GPT-3はその巨大なサイズと一般化能力により、自然言語処理の限界を押し広げ、多くのタスクで人間に近いパフォーマンスを示しています。
BERT (Bidirectional Encoder Representations from Transformers)
特徴: 双方向のTransformerを使用して文脈を捉え、テキストの深い理解を可能にする。
目的: 言語理解タスク全般にわたって強力な基盤を提供し、細かい文脈のニュアンスを把握する。
説明: BERTは特に言語理解タスクで顕著な成果を上げ、質問応答や感情分析など多岐にわたるNLPタスクで新たな基準を設けました。
BERTの事前学習方法:Transformerと教師なし学習による革新
BERT(Bidirectional Encoder Representations from Transformers)の事前学習は、Transformerアーキテクチャと教師なし学習という2つの革新的な技術を組み合わせることで、従来のモデルを大きく凌駕する自然言語処理(NLP)モデルを実現しました。
1. Transformerアーキテクチャ:双方向処理による文脈理解の飛躍
BERTは、Transformerと呼ばれるニューラルネットワークアーキテクチャを採用しています。Transformerは、従来のRNN(Recurrent Neural Network)と異なり、エンコーダとデコーダという2つのモジュールから構成されています。
エンコーダ: 入力文を処理し、単語間の関係性を表現するベクトルを生成します。
デコーダ: エンコーダが出力したベクトルに基づいて、出力文を生成します。
Transformerの大きな特徴は、エンコーダとデコーダが相互に情報を共有できることです。従来のRNNでは、単語を順番に処理していたため、文全体の文脈を理解することが困難でした。一方、Transformerはエンコーダとデコーダが相互に情報を共有することで、文全体の文脈を考慮しながら処理することができます。
2. 教師なし学習:大量データからの効率的な汎用表現学習
BERTの事前学習は、教師あり学習ではなく、教師なし学習と呼ばれる手法を用いて行われます。教師なし学習では、正解ラベルを与えずに、大量のテキストデータからモデルを学習します。BERTでは、以下の2つの主要な教師なし学習タスクを組み合わせることで、汎用的な言語表現を学習します。
1. マスク付き言語モデル (MLM)
MLMでは、入力文の一部をランダムにマスクし、マスクされた単語を推測するタスクを行います。BERTは、文全体の構造や単語間の関係を考慮しながら、マスクされた単語を予測することで、単語の意味を学習します。
2. 次文予測 (NSP)
NSPでは、2つの文が連続する文章の一部であるかどうかを判断するタスクを行います。BERTは、文脈を理解し、文同士の関係性を学習することで、文の論理的な流れを把握することができます。
GLUE (General Language Understanding Evaluation)
特徴: 自然言語理解システムの性能を評価するためのベンチマークスイート。
目的: 異なるNLPタスクでモデルの一般化能力と性能を標準化された方法で評価する。
説明: GLUEは、モデルがどれだけ幅広い言語理解タスクに対応できるかを測定し、研究の進展を促進するための重要なツールです。
Vision Transformer
特徴: 画像処理にTransformerアーキテクチャを適用し、画像をパッチに分割してそれぞれをトークンとして処理する。
目的: 高度な画像認識タスクでの性能向上と、モデルの視覚タスクへの適応を探る。
説明: Vision Transformerは、従来のCNNモデルに比べて、特に大規模な画像データセットで顕著な性能を示し、画像認識の新たな可能性を開いています。Vision Transformer(ViT)は、従来の畳み込みニューラルネットワーク(CNN)を使用せず、自然言語処理(NLP)で成功を収めたトランスフォーマー構造を画像認識タスクに適用することで、画像処理の新しいアプローチを提供します。このモデルは、CNNが広く利用されている従来の方法とは異なる以下の点で新しいモデルと言えます
Vision Transformer(ViT)は、もともと自然言語処理(NLP)で成功を収めたトランスフォーマーアーキテクチャをコンピュータビジョンタスクに適用したものです。2020年にGoogle Researchによって紹介されたこのモデルは、画像認識タスクにおいて従来の畳み込みニューラルネットワーク(CNN)と比較して卓越した性能を示しました。以下に、Vision Transformerの主な特徴とその動作原理を詳細に説明します。
Vision Transformerの特徴
トランスフォーマーベースのアーキテクチャ:
ViTは自己注意機構(Self-Attention)を核としています。これにより、画像の全領域から情報を同時に処理し、局所的な特徴だけでなく、画像全体の文脈を捉えることができます。
画像をパッチに分割:
ViTは入力画像を固定サイズのパッチ(例えば16x16ピクセル)に分割し、各パッチをトランスフォーマーの入力として使用します。これらのパッチは、自然言語処理における「単語」に相当し、それぞれが独立したトークンとして処理されます。
位置エンコーディング:
各パッチには位置エンコーディングが追加され、パッチの位置情報をモデルに提供します。これにより、モデルはパッチの空間的な関係を理解し、より効果的な特徴抽出が可能になります。
クラストークン:
ViTは、入力パッチのシーケンスに「クラストークン」と呼ばれる特別なトークンを追加します。このトークンは、最終的な画像分類のために全てのパッチから情報を集約する役割を果たします。
事前学習と転移学習:
ViTは大規模なデータセットで事前学習され、様々な画像認識タスクに転移学習することができます。大量のデータで学習されたViTは、小規模なデータセットでも優れた性能を発揮します。
構文解析 (Syntactic Parsing)
特徴: テキストの文法的構造を分析し、その統語構造を明らかにするプロセス。
目的: 文の構造を理解し、言語の文法的関係を明確にする。
説明: 構文解析は、文の各単語がどのように組み合わさって意味を形成するかを解析し、言語の深い理解に寄与します。
構文解析は、自然言語処理(NLP)における重要なタスクの一つであり、文章の構造を分析するものです。具体的には、文章を構成する単語や文節、構文関係などを特定し、文法的に正しい構造かどうかを判定します。
構文解析の目的
構文解析を行う主な目的は以下の通りです。
機械翻訳: ある言語の文章を別の言語に翻訳する際に、文章の構造を理解することが重要です。構文解析を用いることで、翻訳元の文章の構造を正しく分析し、翻訳文に反映することができます。
情報検索: 文章中の特定の情報を見つけ出す際に、文章の構造を理解することが役立ちます。構文解析を用いることで、文章の主語、述語、目的語などを特定し、情報検索の精度を向上させることができます。
質問応答: ユーザーの質問に対して適切な回答を生成する際に、文章の構造を理解することが重要です。構文解析を用いることで、質問の意図を正しく理解し、適切な回答を生成することができます。
言語学習: 構文解析を用いることで、言語の構造を分析し、理解を深めることができます。特に、第二言語学習においては、構文解析は非常に効果的な学習方法の一つです。
構文解析の手法
構文解析には、主に以下の2つの手法があります。
規則ベース法: 言語の文法規則に基づいて、文章の構造を分析する手法です。
統計的解析法: 過去の学習データから、文章の構造を統計的に推論する手法です。
近年では、統計的解析法の中でも、ニューラルネットワークを用いた手法が主流となっています。ニューラルネットワークを用いた構文解析は、規則ベース法よりも高い精度を達成することができ、様々な種類の文章に対応することができます。
形態要素解析 (Morphological Analysis)
特徴: 単語を更に細かい意味を持つ部分(形態素)に分解し、その構造と意味を解析する。
目的: 単語の内部構造を理解し、言語の形態学的特性を明らかにする。
説明: 形態要素解析は、単語がどのように形成されるかを明らかにし、特に複合語や派生語の解析に有効です。これにより、言語のルールを詳細に理解し、より効果的なテキスト処理が可能になります。
形態素解析 (Morphological Analysis)
目的: 形態素解析の目的は、テキストを単語やその他の意味を持つ最小単位(形態素)に分割し、それらの形態学的特性を識別することです。
主な特徴:
最小意味単位の識別:
文やフレーズを構成する最小の意味を持つ単位(形態素)に分割します。
品詞の識別:
各形態素に対して名詞、動詞、形容詞などの品詞をタグ付けします。
語幹と語尾の分離:
単語を語幹と接尾辞や接頭辞に分割し、変化形から基本形を導き出します。
複合語の分解:
複合語を構成する個々の単語や形態素に分解します。
多言語対応:
異なる言語特有の形態学的特性を理解し、適切な解析を行います。
処理方法:
テキストトークン化:
テキストを個々の単位(通常は単語)に分割する。これは言語によって異なり、スペースで区切られていない言語(例:日本語、中国語)では特に複雑。
品詞タグ付け:
トークン化された各単語に対して品詞(名詞、動詞など)を割り当てる。これは機械学習モデルやルールベースのアルゴリズムを使用して自動的に行われる。
語幹抽出と形態素分析:
単語をさらに細かく分析し、接頭辞や接尾辞を除去して語幹を抽出する。これにより、文書内の異なる単語形の関連付けや、より一貫したテキスト分析が可能になる。
形態素解析における辞書の役割
単語の識別と品詞の割り当て:
形態素解析プロセスにおいて、テキストを単語に分割する際、辞書を参照して各単語の意味や品詞を特定します。この情報は、文の構造を理解するために不可欠です。
単語の基本形の特定:
辞書は、単語の基本形(語幹)や変形形(例えば、動詞の過去形や現在進行形)を識別するのに使用されます。これにより、テキスト内の異なる単語形が同一の概念を指していることを認識することができます。
未知語の処理:
辞書には登録されていない新しい単語や専門用語がテキストに含まれることがあります。多くの形態素解析器は、辞書外の単語を識別し、適切に処理する機能も備えていますが、辞書の更新と拡張が重要です。
多言語対応:
複数言語に対応するためには、それぞれの言語の辞書が必要です。各言語の形態学的特性を反映した辞書が形態素解析の正確性を大きく左右します。
プロセス:
単語分割: テキストを単語に分割します。特にスペースで区切られていない言語(例: 日本語、中国語)ではこのステップが重要です。
品詞タグ付け: 各単語に品詞(名詞、動詞、形容詞など)を割り当てます。
語幹抽出: 単語から接頭辞や接尾辞を除去し、基本形を抽出します。例えば、「running」から「run」を得る。
応用例: 検索エンジン、テキスト編集ツール、情報抽出など。
構文解析 (Syntactic Analysis)
目的: 構文解析の目的は、文の文法的構造を解析し、その文の単語がどのように組み合わさって意味を形成しているかを理解することです。
主な特徴:
構文木の生成:
文の文法的構造を示す構文木(パースツリー)を生成し、単語間の階層的関係を明確にします。
依存関係のマッピング:
単語間の依存関係を明らかにし、どの単語が他の単語に文法的に依存しているかを示します。
文法エラーの検出:
文法的に不正な構造を識別し、修正提案を行うことができます。
句構造の識別:
名詞句や動詞句など、より大きな文法的単位を識別します。
処理方法:
依存構文解析:
単語間の「支配」や「従属」の関係を特定し、どの単語が文の他の部分に構文的に依存しているかを示す。
これには通常、機械学習アルゴリズムが用いられ、大量の注釈付きデータ(ツリーバンク)に基づいて訓練される。
構文木構築:
単語とその構文的関係を用いて、文全体の構造を表す構文木(パースツリー)を生成する。
ツリーでは、各ノードが単語や句を表し、エッジがそれらの構文的関係を表す。
プロセス:
依存関係解析: 文中の各単語間の依存関係を識別し、どの単語が他の単語に「依存」しているかを示します。
構文木構築: 単語をノードとして、それらの関係を枝で示したツリー(構文木)を生成します。これにより、文の階層的な文法構造が明らかになります。
応用例: 翻訳システム、文書要約、質問応答システム。
意味解析 (Semantic Analysis)
目的: 意味解析の目的は、単語や文が持つ意味を理解し、それらが文脈上どのように機能するかを解析することです。
主な特徴:
意味役割の割り当て:
文中の各単語に対して、その意味的役割(例: 行為者、対象、道具)を割り当てます。
多義性の解消:
単語が複数の意味を持つ場合、文脈に基づいて最も適切な意味を選択します。
意味ネットワークの構築:
単語や表現の意味的関連をつなぐネットワークを形成し、より複雑な意味の構造を理解します。
意味の一貫性の検証:
提供された情報が意味的に一貫しているかを確認します。
処理方法:
意味役割ラベリング:
文中の動詞とその関連引数(主語、目的語など)にラベルを付け、各要素の意味的役割を識別する。
意味ネットワークの構築:
意味のある単位(単語や句)間の関連を定義し、これらの関係に基づいて意味ネットワークを構築する。これには、知識ベースやオントロジーが利用されることが多い。
多義性の解消:
文脈に基づいて単語の意味を特定する。このプロセスでは、周辺のテキストや外部知識が参照されることが一般的。
プロセス:
意味役割ラベリング: 文中の各単語が果たす意味的な役割(例: 主体、目的語、道具など)を識別します。
意味ネットワーク構築: 単語やフレーズの意味的関連をつなぐネットワークを形成します。
多義性の解消: 単語が複数の意味を持つ場合、文脈に基づいて最も適切な意味を選択します。
応用例: 感情分析、テキストベースの情報検索、対話システム。
文脈解析 (Discourse Analysis)
目的: 文脈解析の目的は、複数の文または会話全体がどのようにつながっているかを理解し、テキスト全体の意味や構造を解析することです。
主な特徴:
照応解析:
文書内での代名詞や指示詞の参照先を特定し、テキスト全体の意味的な連続性を保ちます。
文間の論理関係の識別:
文と文の間の因果関係、対比関係などを識別し、テキスト全体の論理的な流れを明らかにします。
話題の把握と維持:
テキスト全体の話題を特定し、どのように話題が展開または転換しているかを追跡します。
文脈に基づいた意味の推定:
複数の文をまたがる文脈に基づき、言及されていない情報や暗黙の前提を推測します。
照応解析:
文書内での代名詞や指示詞が指す先を特定し、参照解決を行う。
プロセス:
照応解析: 文や段落を跨いで参照されている要素(代名詞が何を指しているかなど)を識別します。
話題の維持と転換: テキストや会話がどのように話題を展開または転換しているかを追跡します。
文の関係性分析: 文同士の論理的なつながりや因果関係を解析します。
応用例: ドキュメント自動生成、チャットボット、教育ツール。
学習目標:強化学習にディープラーニングを組み込んだ深層強化学習の基本的な手法とその応用分野について理解する。
深層強化学習の基本的な手法と発展
特徴: 強化学習にディープラーニングを組み込んだアプローチで、エージェントが環境からのフィードバックを基に最適な行動を学習する。
目的: 高次元の入力空間でも効率的に最適なポリシーを学習できるようにする。
説明: 深層強化学習では、ディープニューラルネットワークが状態や行動の複雑な表現を捉え、より効果的な意思決定を支援します。これにより、ビデオゲームやロボット制御など、複雑な問題に対しても適用可能です。
深層強化学習とゲーム AI
特徴: ゲームのプレイを通じて最適な戦略や行動を学習する。
目的: ゲームの環境内で高度な戦略とタクティクスを自動で生成し、人間のプレイヤーや他のAIと競争する。
説明: 深層強化学習は、チェス、囲碁、ビデオゲームなど、さまざまなゲームで人間以上の性能を示しており、ゲーム戦略の開発に革命をもたらしています。
実システム制御への応用
特徴: 実世界の物理システムを制御するための深層強化学習の応用。
目的: ロボットアームの動作や自動運転車の制御など、現実世界の複雑なタスクを自動化する。
説明: 実システム制御では、深層強化学習を用いてセンサーデータから直接制御ポリシーを学習し、現実の動的環境に対応する能力を実現します。
DQN (Deep Q-Network)
特徴: Q学習にディープラーニングを組み合わせ、大規模な状態空間を持つ問題に対応。
関数近似器としてのニューラルネットワーク: DQNはQ関数(行動価値関数)を近似するためにディープニューラルネットワークを使用します。これにより、従来のQ学習が扱うことのできなかった大規模かつ高次元の状態空間を効果的に学習することが可能になります。
経験リプレイ (Experience Replay): DQNはエージェントの経験をメモリに保存し、学習中にランダムにこれらの経験をサンプリングして再利用します。これにより、学習プロセスがより安定し、効率的になります。
固定Qターゲット (Fixed Q-Targets): 学習の安定性を高めるために、目標値を計算するために使用するネットワークのパラメータを定期的に更新しますが、頻繁な更新は行わずに一定間隔で行います。これにより、学習プロセス中の目標値の変動を抑え、収束を早めます。
目的: エージェントが与えられた環境で最大の報酬を獲得するための行動を学習する。
説明: DQNはビデオゲームなどの複雑なタスクにおいて顕著な成功を収めており、安定した学習と優れた汎用性を提供します。
DQN(Deep Q-Network)は、ディープラーニングと強化学習を組み合わせたアプローチで、特にディープラーニング技術を使用してQ学習の価値関数を近似する手法です。この技術は、DeepMindによって開発され、2013年に発表された論文で、Atari 2600のビデオゲームをプレイするAIが人間以上のパフォーマンスを達成することが示されました。以下にDQNの特徴、仕組みについて詳しく説明します。
仕組み
DQNは、状態を入力として受け取り、各行動に対する価値(Q値)を出力するニューラルネットワーク(Qネットワーク)を使用します。エージェントはこのQネットワークを使用して、各状態で最も価値の高い行動を選択します。このプロセスは以下のように進行します初期化: ランダムに初期化されたパラメータを持つニューラルネットワークを用意します。
ポリシー実行: 現在のQネットワークに基づいて行動を選択し、環境と対話します。ε-greedy法などの探索戦略を使用して、探索と利用のバランスを取ります。
経験の蓄積: エージェントの経験(状態、行動、報酬、次の状態)をメモリに保存します。
経験リプレイ: メモリからランダムにミニバッチをサンプリングし、これらの経験を使用してネットワークを訓練します。
Q値の更新: 最適な行動価値関数を近似するようにネットワークの重みを更新します。損失関数は、予測されたQ値と目標Q値との間の誤差(たとえば二乗誤差)を最小化するように設計されます。
DQNを端的にいうと
DQNは、Deep Q-Networkの略称で、強化学習における方策の一種です。エージェントが環境と相互作用しながら、報酬を最大化する行動を学習します。DQNの特徴
経験リプレイを用いて、過去の経験を学習に活用する
ニューラルネットワークを用いて、価値関数を近似する
オフライン学習が可能
DQNの利点
複雑な環境でも学習できる
高い性能を達成できる
DQNの欠点
学習に時間がかかる
探索と活用のバランスを調整する必要がある
DQNの動作を端的にいうと
DQN(Deep Q-Network)は、エージェントが環境と相互作用しながら、報酬を最大化する行動を学習する強化学習アルゴリズムです。環境と相互作用
エージェントは、状態を観測し、行動を選択します。
行動を選択すると、環境から報酬と次の状態を受け取ります。
価値関数を学習
価値関数は、各状態における将来的な累積報酬を推定します
DQNは、経験リプレイと呼ばれる記憶装置に、過去の経験を保存します。
経験リプレイからランダムにサンプリングされた経験を用いて、ニューラルネットワークを用いて価値関数を学習します。
3行動を選択
エージェントは、現在の状態における最大価値を持つ行動を選択します。
探索と活用のバランスを調整するために、ε-greedy法などの手法を用います。
4繰り返し
1から3までの手順を繰り返すことで、エージェントは報酬を最大化する行動を学習します。
DQNの動きを一言で表すと、「経験から学び、最適な行動を選択する」となります。
補足
DQNは、オフライン学習が可能であり、シミュレーション環境などで学習させることができます。
DQNは、探索と活用のバランスを調整することが重要です。探索が多すぎると学習が遅くなり、活用が多すぎると局所解に陥る可能性があります。

DQN (Deep Q-Network) が出力する行動は、環境の状態を表現する低次元ベクトルです。このベクトルは、離散的な行動空間に対応しており、各要素が特定の行動の確率を表します。(離散値)
具体的には、DQNは以下のような処理を行います。
現在の状態を観察:エージェントは、現在の環境の状態を観察します。この状態は、環境の様々な要素 (位置、速度、敵の位置など) を表す数値ベクトルとして表現されます。
Q値を推定:DQNは、ニューラルネットワークを用いて、各行動における Q値 を推定します。Q値は、その行動を選択したときの 将来的な報酬の期待値 を表します。
行動を選択:DQNは、推定されたQ値に基づいて、 ε-greedy 法 などの手法を用いて行動を選択します。ε-greedy 法では、通常は 最も高いQ値を持つ行動 を選択しますが、確率 ε で ランダムな行動 を選択します。これは、探索と収束のバランスを保つために重要です。
行動を実行:エージェントは、選択した行動を実行します。
報酬を受け取る:エージェントは、行動の結果として 報酬 を受け取ります。
経験を記憶:エージェントは、現在の状態、選択した行動、受け取った報酬を 経験リプレイ に記憶します。
ニューラルネットワークを更新:経験リプレイからランダムにサンプリングされた経験を用いて、DQNのニューラルネットワークを更新します。
SARSAとDQNの関係は?
SARSA(State-Action-Reward-State-Action)とDQN(Deep Q-Network)は共に強化学習のアルゴリズムであり、それぞれ異なるアプローチを用いて学習を進めます。これら二つのアルゴリズムは共にQ学習(Q-learning)の枠組みに基づいていますが、行動の選択と学習の更新ルールにおいて異なる特徴を持っています。
SARSA
SARSAはオンポリシー(on-policy)学習アルゴリズムです。これは、学習中に採用されるポリシー(方針)と、将来の行動選択に使用されるポリシーが同一であることを意味します。つまり、学習プロセス自体が行動選択のポリシーに影響を受けます。
DQN
DQNはオフポリシー(off-policy)学習アルゴリズムであり、Q学習の原理に基づいています。オフポリシー学習では、行動選択と学習更新が異なるポリシーに基づくことができます。これは、学習中に異なるポリシーを探索することが可能であり、最終的な方策が探索方策とは独立して最適化されることを意味します。
DQNはニューラルネットワークを使用してQ関数を近似し、経験リプレイと固定Qターゲットを用いて学習の安定性を向上させます。また、最適な行動は現在学習中のQ値に基づいて決定されますが、ε-greedyアルゴリズムなどによる探索が行動選択に用いられることが多いです。
SARSAとDQNの関係
SARSAとDQNはどちらも環境からの相互作用を通じて価値関数を学習しますが、SARSAがオンポリシーのアプローチを取るのに対して、DQNはオフポリシーのアプローチを取ります。この違いは、特に探索の安全性やポリシーの発散に関して影響を与えることがあります。SARSAは探索中に得られる情報に基づいて学習するため、安全な探索に適している場合がありますが、DQNは最適な行動に重点を置いているため、より高い報酬を目指す可能性があります。
ダブル DQN
特徴: DQNを改善し、オーバーエスティメーションを抑制する。
目的: Q値の過大評価を防ぎ、より安定した学習結果を得る。
説明: ダブルDQNは、選択と評価のために異なるネットワークを用いることで、Q値の過大評価問題を解決します。
デュエリングネットワーク
特徴: 状態価値とアクションアドバンテージを別々に学習し、組み合わせて行動価値を評価。
目的: 状態評価と行動選択の区別を明確にし、より効果的な学習を行う。
説明: デュエリングネットワークは、状態が与えられた際の各アクションの相対的な価値をより正確に推定することができます。
デュエリングネットワークについて
デュエリングネットワークは、従来のDQN(Deep Q-Network)のネットワーク構造を改良した手法で、状態価値関数(V(s))とアドバンテージ関数(A(a))を分離して学習することが特徴です。この構造により、行動に関係なく状態価値を学習することが可能になります。
デュエリングネットワークの特徴
状態価値関数とアドバンテージ関数の分離: デュエリングネットワークは、状態価値関数(V(s))とアドバンテージ関数(A(a))を分離して学習します。これにより、状態価値を行動から独立して学習することができます。
DQNやDDQNとの組み合わせ: デュエリングネットワークは、DQNやDDQNなどのモデルフリーのアルゴリズムと組み合わせて使用することができます。これにより、より高度なタスクに対応する能力が向上します3。
デュエリングネットワークの応用
高度なタスクへの対応: デュエリングネットワークは、従来のDeep Q-Learning手法を強化するユニークなアーキテクチャを持っており、より高度なタスクに対応するために注目されています
ノイジーネットワーク
特徴: ネットワークのパラメータに意図的にノイズを加えることで探索を促進。
目的: より多様な状態を探索し、局所最適解に陥るのを防ぐ。
探索の効率を向上させ、最適なポリシーをより早く見つけ出すことができます。
説明: ノイジーネットワークは探索プロセスにランダム性を導入することで、未知の状態やアクションを試す確率を高め、学習の効率を向上させます。
概要: ノイジーネットワークは、探索を促進するためにネットワークの重みにノイズを加える手法です。これにより、より多様な行動を試すことが可能になります。
ノイジーネットワーク:わかりやすく要約
ノイジーネットワークは、ニューラルネットワークの一種であり、意図的にノイズを導入することで、学習性能や汎化性能を向上させる手法です。ノイズを導入することで、ネットワークが特定の入力パターンに依存しすぎるのを防ぎ、より汎用的なモデルを学習することができます。
ノイジーネットワークの仕組み
ノイジーネットワークでは、以下の2つの方法でノイズを導入することができます。
トレーニングデータにノイズを追加する: トレーニングデータにランダムなノイズを追加することで、ネットワークがノイズに頑健になるように学習させることができます。
ネットワークの重みにノイズを追加する: ネットワークの重みにランダムなノイズを追加することで、ネットワークが特定の重みに依存しすぎるのを防ぐことができます。
ノイジーネットワークの利点
ノイジーネットワークを用いることで、以下の利点があります。
学習性能の向上: ノイズを導入することで、ネットワークがトレーニングデータに過学習しすぎるのを防ぎ、学習性能を向上させることができます。
汎化性能の向上: ノイズを導入することで、ネットワークが特定の入力パターンに依存しすぎるのを防ぎ、汎化性能を向上させることができます。
過学習の抑制: ノイズを導入することで、ネットワークが特定の入力パターンに過学習しすぎるのを抑制することができます。
Rainbow
特徴: 複数の改善技術を組み合わせたDQNの拡張版。
目的: 深層強化学習の性能をさらに向上させる。
説明: Rainbowは、ダブルDQN、優先順位付きリプレイ、デュエリングネットワークなど、複数の手法を統合して最適化し、多くの環境において最先端の性能を示します。
RAINBOW (RainbowDQN) は、強化学習におけるDQN (Deep Q-Network) の派生アルゴリズムであり、複数のDQNエージェントを組み合わせることで、より高い性能を実現することを目的としています。
特徴:複数DQNエージェント: 異なるアーキテクチャやハイパーパラメータを持つ複数のDQNエージェントを組み合わせる
アンサンブル学習: 各エージェントの予測結果を統合することで、より正確な行動を選択する
経験リプレイ: 過去の経験をリプレイメモリに蓄積し、ランダムにサンプリングして学習に利用する
ニューラルネットワーク: Q関数を表現するために、ニューラルネットワークを用いる
目的: 複雑な環境や高次元状態空間における強化学習において、より高い性能を実現する
わかりやすい説明:
RAINBOWは、複数のDQNエージェントを組み合わせることで、それぞれのエージェントの強みを活かした学習を行うことができます。
具体的には、異なるアーキテクチャやハイパーパラメータを持つ複数のDQNエージェントを学習させ、各エージェントの予測結果を統合することで、より正確な行動を選択することができます。
また、RAINBOWは経験リプレイと呼ばれる手法を用いて、過去の経験を効率的に学習に活用することができます。
RAINBOWの利点:
高い性能: 複雑な環境や高次元状態空間における強化学習において、従来のDQNよりも高い性能を実現できる
安定性: 複数のエージェントを組み合わせることで、学習の安定性を向上させることができる
汎用性: 異なるアーキテクチャやハイパーパラメータを持つエージェントを組み合わせることで、様々な環境に適用できる
RAINBOWの欠点:
計算量: 複数のエージェントを学習させるため、計算量が多くなる
ハイパーパラメータ: 複数のエージェントのハイパーパラメータを調整する必要がある
RAINBOWの応用例:
ゲーム: Atariゲームなど、複雑な環境における強化学習
ロボット制御: ロボットアームなどの制御
レコメンデーションシステム: 商品やサービスのレコメンデーション
RAINBOWとDQNの関係:
RAINBOWはDQNの派生アルゴリズムであり、DQNよりも高い性能を実現することを目的としています。
DQNは単一のエージェントを用いて学習を行うのに対し、RAINBOWは複数のエージェントを組み合わせることで、より複雑な環境や高次元状態空間における学習を可能にします。
まとめ:
RAINBOWは、強化学習におけるDQNの派生アルゴリズムであり、複数のDQNエージェントを組み合わせることで、より高い性能を実現することができます。
RAINBOWは複雑な環境や高次元状態空間における強化学習において、有望なアルゴリズムの一つです。
Rainbowで用いられる手法
Rainbowは、機械学習における強化学習アルゴリズムの一つで、特にDQN(Deep Q-Network)の複数の拡張を組み合わせたものです。Rainbowは、各種技術の利点を活用して、元のDQNが抱えるいくつかの問題を解決し、全体的な性能と安定性を向上させます。ここで使われる主要な技術は以下の通りです。
1. Double DQN (DDQN)
目的: Q値の過大評価を防ぐ。
仕組み: Q値の更新で最大化を行う行動の選択と、Q値の評価を別のネットワーク(または同じネットワークの異なるパラメータセット)を使用して行うことで、過大評価を抑制します。
2. Prioritized Experience Replay
目的: 重要な過去の経験を効率的に再利用する。
仕組み: 経験(トランジション)の重要性をTD誤差(Temporal Difference error、予測値と目標値との差)の大きさに基づいて測定し、重要な経験を優先的に学習に使用します。
3. Dueling Network Architecture
目的: 状態価値と行動価値の学習を分離することで学習効率を向上させる。
仕組み: ネットワークアーキテクチャを、状態価値(V(s))とアドバンテージ(A(s, a))の計算に特化した二つのストリームに分け、これにより状態のみに依存する価値と行動の選択に依存する価値を別々に評価できます。
4. Noisy Nets
目的: 探索のためのノイズをネットワークパラメータに直接注入し、探索効率を向上させる。
仕組み: ネットワークの重みに確率的なノイズを加えることで、エージェントが新たな行動を探索する機会を増やし、より多様な状況での学習を促進します。
5. Multi-step Learning
目的: 報酬の予測を短期間ではなく長期間で行い、報酬予測の精度を高める。
仕組み: 単一ステップの報酬ではなく、複数ステップにわたる累積報酬を用いて更新することで、遅延報酬を効果的に取り入れます。
6. Distributional Q-Learning
目的: 報酬の分布を学習し、報酬予測の不確実性を考慮に入れる。
仕組み: 単一の報酬値ではなく、報酬の確率分布をモデル化することで、異なる可能性を含めた意思決定をサポートします。
7. Categorical DQN (C51)
目的: 報酬の分布をより細かく予測し、報酬の変動に対応する。
仕組み: 報酬を特定の区間に分割し、各区間に属する確率を予測することで、より詳細な報酬の分布を学習します。
Rainbowはこれらの技術を統合することで、DQNのさまざまな限界に対処し、特に複雑で不確実性の高い環境でのパフォーマンスを大幅に向上させています。このアプローチは、強化学習におけるエージェントの汎用性とロバスト性を大きく改善する一歩とされています。
モンテカルロ木探索 (MCTS)
特徴: 確率的な試行を用いて最適な決定を探索する手法。
目的: 特に計算量が大きい問題に対して、効率的な探索を行う。
説明: MCTSは囲碁やチェスなどの複雑なボードゲームにおいて用いられ、各局面で最も有望な手を逐次的に選択します。
モンテカルロ木探索(MCTS)は、ゲームAIなどで用いられる探索アルゴリズムです。
特徴
ランダムシミュレーションと評価関数を使って、効率的に最良の手を選択
将棋、囲碁、オセロなどのボードゲームや、コンピューターゲームでよく使われる
利点: 効率的、柔軟、学習可能
欠点: 計算量が多い、精度と計算量の関係、探索バイアス
イメージ
ゲームの展開を木構造で表現
ランダムシミュレーションで木を探索
評価関数で枝を評価
最も高い評価を持つ枝に対応する手を選択
一言で表すと
「ランダムシミュレーションと評価関数で、ゲームの最善の手を見つける」
木構造でゲームの展開を表現
MCTSは、ゲームの進行状況を木構造で表現します。
根ノード: ゲームの開始状態を表します。
子ノード: 各ノードは、それぞれのプレイヤーが選択できる行動を表します。
枝: ノード間のつながりを表し、ゲームの進行を表します。
葉ノード: ゲームの終了状態を表します。
ランダムシミュレーションで探索
MCTSは、ランダムシミュレーションを用いて、木の枝を探索していきます。
選択: 現在の手番のプレイヤーが、まだ探索されていない最も有望な枝を選択します。
展開: 選択された枝から、可能な全ての子枝を生成します。
シミュレーション: ランダムな行動を選択しながら、各子枝から終局までプレイします。
バックアップ: シミュレーションで得られた勝敗を、親枝から子枝へ伝播させます。
この過程を繰り返し、より多くの枝を探索することで、より良い手を見つけ出すことができます。
アルファ碁 (AlphaGo)
特徴: ディープラーニングとMCTSを組み合わせて設計された、囲碁プログラム。
目的: 人間のトッププロプレイヤーに匹敵または勝る囲碁プレイを実現する。
説明: アルファ碁は2016年に世界チャンピオンに勝利し、深層強化学習が複雑な知的タスクにおいて人間の能力を超える可能性を示しました。
アルファ碁ゼロ (AlphaGo Zero)
特徴: 人間のプレイデータに依存せず、ゼロから自己対戦を通じて学習する囲碁プログラム。
目的: 純粋な強化学習のみで最高水準の囲碁プレイを実現する。
説明: アルファ碁ゼロは既存のアルファ碁を超える強さを短期間で達成し、深層学習と自己対戦による学習が非常に効果的であることを証明しました。
アルファゼロ (Alpha Zero)
特徴: 囲碁、将棋、チェスなど複数のゲームにおいてトップレベルのプレイを実現する多目的AI。
目的: 異なる種類のボードゲームにおいて最高水準のプレイを一つのアルゴリズムで実現する。
説明: アルファゼロは一般化された学習アルゴリズムを使用しており、各種ゲームの基本ルールのみから自己対戦を通じて学習を進めます。
マルチエージェント強化学習
特徴: 複数のエージェントが同時に学習し、協力や競争を通じてそれぞれの目標を達成する学習プロセス。
目的: 複雑な環境内での複数エージェントの相互作用をモデル化し、効果的な戦略を学習する。
説明: マルチエージェント強化学習は、交通制御、経済モデル、ロボットの協調作業など、実世界の多くのシナリオで応用されます。
マルチエージェント強化学習(MARL)は、複数のエージェントが相互作用しながら学習を進める強化学習の分野です。このアプローチは、各エージェントが自己の報酬を最大化するように行動する中で、他のエージェントの存在や行動による影響を考慮に入れなければならない状況に適用されます。マルチエージェント環境は、協力、競争、あるいはその両方が含まれる場合があり、それによって学習の複雑さが大幅に増します。
特徴
エージェントの相互作用:
マルチエージェントシステムでは、エージェント間の相互作用が中心的な役割を果たします。これには協力的なタスク(チームで目標を達成する)、競争的なタスク(他のエージェントと競争する)、またはその両方が含まれます。非定常環境:
他のエージェントも同時に学習しているため、環境が非定常になります。つまり、一つのエージェントのポリシーが変わると、それが他のエージェントの経験に影響を与え、全体の環境が変化します。複雑な報酬構造:
マルチエージェント環境では、個々のエージェントの行動が集合的な結果に寄与し、その影響が各エージェントの報酬に反映されるため、報酬構造が非常に複雑になります。
仕組み
マルチエージェント強化学習の基本的な仕組みは、個々のエージェントが環境からのフィードバック(報酬)を基に自身のポリシーを更新し続ける点にあります。ただし、他のエージェントのポリシーも同時に更新されるため、それぞれの学習プロセスは他のエージェントの行動に強く依存します。
主な手法
独立Q学習(Independent Q-Learning, IQL):
各エージェントが独立にQ学習を行うアプローチです。エージェントは他のエージェントの存在を無視して学習を進めますが、これにより非定常問題が発生する可能性があります。共同行動学習(Joint Action Learning, JAL):
すべてのエージェントの行動を組み合わせた共同行動空間で学習を行います。このアプローチは理論的には最適な解を導く可能性がありますが、行動空間の大きさが指数関数的に増加するため、実際にはスケールが非常に難しいです。ポリシー勾配法:
各エージェントがニューラルネットワークなどの関数近似器を用いてポリシーを直接学習する手法です。マルチエージェント環境では、エージェント間の協調や情報の共有を取り入れる
ことで、効率的な学習が可能になります。
マルチエージェントアクタークリティック(Multi-Agent Actor-Critic):
アクタークリティックアーキテクチャをマルチエージェント設定に拡張したもので、各エージェントがアクター(ポリシー関数)とクリティック(価値関数)を持ちます。この手法はエージェント間の通信や協力をモデル化することが可能です。
応用
マルチエージェント強化学習は、ロボット工学、自動運転車、リソース共有問題、経済学、社会科学など、多様な分野での応用が考えられています。特に、複数のエージェントが共存する環境において、協調や競争を効果的に扱う必要がある問題に適しています。
OpenAI Five
特徴: マルチプレイヤーオンラインバトルアリーナゲーム「Dota 2」で使用される、OpenAIによるマルチエージェント強化学習システム。
目的: チームとして協力し、高度な戦略とタクティクスを学習する。
説明: OpenAI Fiveはプロの人間プレイヤーに匹敵する性能を示し、AIのチーム協力と複雑な戦略学習の可能性を広げました。
OpenAI Fiveにおける強化学習の特徴
分散型強化学習: 5つのエージェントそれぞれが個別に強化学習を行い、チーム全体としての最適な行動を学習します。
報酬設計: チームの勝利だけでなく、個々のエージェントの貢献度も考慮した報酬設計を行うことで、チームワークを促進します。
経験リプレイ: 過去の経験を蓄積し、学習に活用することで、学習効率を向上させます。
適応型探索: 状況に応じて探索と収束のバランスを調整することで、より効率的に学習を進めます。
アルファスター (AlphaStar)
特徴: リアルタイムストラテジーゲーム「StarCraft II」のために開発された深層強化学習ベースのAI。
目的: 高度な戦略ゲームのプレイを通じて、リアルタイムでの複雑な意思決定を学習する。
説明: アルファスターはプロのプレイヤーと競争し、ゲーム内での複数のユニットを効率的に管理する戦略を学習しました。
AlphaStar:ゲームAIの頂点を目指すDeepMindの研究
AlphaStarは、Google傘下のAI研究会社DeepMindが開発した、リアルタイムストラテジーゲーム「StarCraft II」をプレイするAIです。
2019年、AlphaStarはプロゲーマーを相手に勝利し、AIがeスポーツのトップレベルに到達できることを証明しました。
特徴:
人間を超える戦略: AlphaStarは、高度な戦略と戦術を駆使して、人間プレイヤーを圧倒します。
マルチエージェント学習: AlphaStarは、複数のAIエージェントを同時に学習させることで、複雑なチームワークを必要とするStarCraft IIのようなゲームでも高いパフォーマンスを発揮することができます。
強化学習: AlphaStarは、膨大な量のゲームプレイデータを用いて強化学習を行い、不断に戦略と戦術を磨き続けています。
開発の経緯:
2016年、DeepMindはStarCraft IIの開発元であるBlizzard Entertainmentと提携し、AlphaStarの開発を開始しました。
開発チームは、StarCraft IIのゲームプレイデータとプロゲーマーの試合データを収集し、AlphaStarに学習させました。
AlphaStarは、強化学習と呼ばれる手法を用いて、膨大な量のデータから戦略と戦術を学び、人間プレイヤーを超える能力を獲得しました。
2019年のマイルストーン:
2019年、AlphaStarはプロゲーマーを相手に勝利し、AIがeスポーツのトップレベルに到達できることを証明しました。
AlphaStarは、以下の3つの異なる種族(Terran、Zerg、Protoss)を使用して、プロゲーマーと対戦しました。
Terran: AlphaStarは、Terranを使用して、プロゲーマーのDario "TLO" Wünschを5対0で破りました。
Zerg: AlphaStarは、Zergを使用して、プロゲーマーのGrubbyを5対0で破りました。
Protoss: AlphaStarは、Protossを使用して、プロゲーマーのマナ "Mana" Vodaを4対2で破りました。
これらの勝利は、AIが人間を超える知性を獲得し、複雑なゲームにおいても人間を打ち負かすことができることを示しました。
AlphaStarの意義:
AlphaStarは、AI研究における大きな飛躍であり、以下のような重要な意味を持っています。
AIの進化: AlphaStarは、AIが人間を超える知性を獲得し、複雑なゲームにおいても人間を打ち負かすことができることを示しました。
eスポーツへの影響: AlphaStarは、eスポーツの世界に大きな影響を与え、AIが今後どのようにeスポーツに参入していくのか、注目が集まっています。
人工知能倫理: AlphaStarのような強力なAIの開発は、人工知能倫理に関する議論を活発化させています。
AlphaStarの今後の展望:
AlphaStarは、まだ開発段階であり、今後も進化を続けることが予想されます。
今後、AlphaStarはさらに高度な戦略と戦術を身につけるだけでなく、他のゲームや競技にも挑戦していく可能性があります。
AlphaStarの進化は、AIの未来を大きく変える可能性を秘めています。
状態表現学習
特徴: エージェントが環境の状態を効果的に表現する方法を学習するプロセス。
目的: より少ないデータで高速に学習を進めるため、環境の状態を効率的にエンコードする。
説明: 状態表現学習は、エージェントが観測から本質的な特徴を抽出し、状態の良い表現を形成することを目指します。これは、特に視覚データを扱うタスクで重要です。
状態表現学習:端的に言うと
状態表現学習は、強化学習において、世界モデルと呼ばれる内部モデルを学習することで、学習効率を高める手法です。
従来の強化学習では、エージェントは環境と直接やり取りしながら学習を進めていました。しかし、この方法では、複雑な環境や高次元な状態空間の場合、学習に時間がかかったり、効率が悪かったりする問題がありました。
そこで、状態表現学習では、事前に環境を学習し、状態をより低次元で表現する方法を学習することで、学習効率を向上させることができます。
具体的には、以下のような利点があります。
次元削減: 高次元な状態空間を低次元で表現することで、計算量を削減することができます。
探索の効率化: 状態表現を用いることで、エージェントはより効率的に探索を行うことができます。
転移学習: 学習した状態表現を他のタスクに転移することができます。
状態表現学習は、近年注目を集めている強化学習の手法の一つであり、様々なタスクに適用されています。
連続値制御
特徴: エージェントが連続的なアクションスペース内で最適なアクションを選択することを学習するプロセス。
目的: ロボットの動きや車のステアリングといった、連続的な値を要求するタスクの制御を行う。
説明: 連続値制御は特にロボティクスや自動運転車など、精密な操作が求められるアプリケーションでの使用が進んでいます。
報酬成形
特徴: 学習を促進または特定の方向に導くために、報酬信号に追加的なフィードバックを加える技術。
目的: エージェントが望ましい行動を学習しやすくするため、報酬信号を調整する。
説明: 報酬成形は学習過程を加速させることができ、エージェントがより迅速に有効なポリシーを学習するのを助けます。
報酬成形:詳細な説明
報酬成形(Reward Shaping)は、強化学習において、エージェントが学習する報酬関数を設計することで、学習効率を高める手法です。
従来の強化学習では、エージェントは環境と直接やり取りしながら学習を進めていました。しかし、この方法では、複雑な環境や高次元な状態空間の場合、学習に時間がかかったり、効率が悪かったりする問題がありました。
そこで、報酬成形では、最終的に達成したい目標に基づいて、中間的な状態や行動に対しても報酬を与えるようにすることで、エージェントが効率的に目標を学習できるようにします。
具体的には、以下の効果が期待できます。
探索の促進: 中間的な状態や行動に対しても報酬を与えることで、エージェントが積極的に探索を行い、最適な解を見つけやすくなります。
学習の安定化: 最終的な報酬のみを与える場合、エージェントが局所解に陥ってしまう可能性があります。報酬成形を用いることで、学習の安定化を図ることができます。
学習時間の短縮: エージェントが効率的に学習できるようになるため、学習時間が短縮されます。
オフライン強化学習
特徴: 予め収集されたデータセットから学習を行う強化学習の形式。
目的: 実環境での探索リスクを回避し、既存のデータを最大限に活用する。
説明: オフライン強化学習は、特に探索が危険またはコストがかかる環境において有効で、事前に収集された大量のデータからポリシーを学習します。
sim2real
特徴: シミュレーションで学習したモデルを現実世界に適用する技術。
目的: シミュレーションの利点を活かしつつ、現実のタスクでの適用を可能にする。
説明: sim2realは特にロボティクスで重要で、シミュレーションでの安全かつ低コストな学習環境を活用して、実世界の複雑なタスクへの適応を図ります。従来の強化学習では、ロボットなどのエージェントを現実世界で直接学習させることが一般的でした。しかし、現実世界での学習は、時間とコストがかかり、危険を伴う場合もあります。
そこで、Sim2Realでは、シミュレーション環境を用いて効率的に学習を行い、その後、現実世界で微調整を行うことで、より安全かつ迅速に高性能なモデルを開発することができます。
Sim2Realの利点:効率性: シミュレーション環境では、現実世界よりも高速かつ低コストで学習を行うことができます。
安全性: シミュレーション環境では、現実世界での学習に伴う危険性を回避することができます。
再現性: シミュレーション環境では、学習条件を厳密に制御することができ、再現性の高いモデルを開発することができます。
Sim2Realの課題:
現実とシミュレーションのギャップ: シミュレーション環境と現実世界の間には、物理特性や環境特性などのギャップが存在し、このギャップをどのように克服するかが課題となります。
ドメイン知識: シミュレーション環境を構築するためには、対象となるドメインに関する深い知識が必要となります。
計算量: 高度なシミュレーション環境を用いる場合、計算量が多くなり、学習に時間がかかる場合があります。
Sim2Realの応用例:
ロボット制御: ロボットアームなどの制御
自動運転: 自動運転車の制御
ゲーム: ゲームAIの開発
医療: 医療ロボットの開発
Sim2Realの将来展望:
Sim2Realは、強化学習の発展において重要な役割を果たすことが期待されています。
シミュレーション環境と現実世界の間のギャップを克服するための研究が進み、計算量も削減されることで、Sim2Realはより幅広い分野で活用されるようになるでしょう。
Sim2Realと関連する用語:
強化学習: エージェントが環境と相互作用しながら、最適な行動を選択することを学習するアルゴリズム
シミュレーション環境: 現実世界を模倣した仮想環境
ドメイン知識: 対象となる分野に関する専門知識
現実ギャップ: シミュレーション環境と現実世界の間のギャップ
転移学習: シミュレーション環境で学習した知識を現実世界に適用する手法
ドメインランダマイゼーション
ドメインランダマイゼーション:端的に言うと
ドメインランダマイゼーションは、シミュレーション環境において、様々なパラメータをランダムに設定することで、現実世界に近い環境を作り出し、学習の汎化能力を向上させる手法です。
従来のシミュレーション環境では、現実世界とは異なるパラメータ設定で作られているため、エージェントがシミュレーション環境で学習した知識が、現実世界でうまく適用できないという問題がありました。
そこで、ドメインランダマイゼーションでは、シミュレーション環境のパラメータをランダムに設定することで、様々な環境に適応できるエージェントを育成することができます。
簡単に言えば、シミュレーション環境で様々な状況を想定して学習することで、現実世界でも対応できるエージェントを育成するというイメージです。
ドメインランダマイゼーションは、強化学習において、シミュレーション環境と現実世界の間のギャップを克服するために用いられる手法です。
シミュレーション環境で学習したモデルを現実世界に適用する場合、シミュレーション環境と現実世界の間には、物理特性や環境特性などの違いが存在します。
この違いを 「リアリティギャップ」 と呼び、このギャップが原因で、シミュレーション環境でうまく動作していたモデルが、現実世界ではうまく動作しないことがあります。
ドメインランダマイゼーションは、このリアリティギャップを克服するために、シミュレーション環境のパラメータをランダムに変化させて、様々な環境条件でモデルを学習させることで、より汎用性の高いモデルを開発することを目的としています。
具体的には、以下の手順でドメインランダマイゼーションを実行します。
シミュレーション環境のパラメータをランダムに設定します。
設定された環境でエージェントを学習させます。
と 2. を繰り返します。
学習されたモデルを現実世界で評価します。
ドメインランダマイゼーションの利点:
リアリティギャップの克服: シミュレーション環境のパラメータをランダムに変化させることで、様々な環境条件でモデルを学習させ、リアリティギャップを克服することができます。
汎用性の高いモデルの開発: リアリティギャップを克服することで、より汎用性の高いモデルを開発することができます。
学習効率の向上: シミュレーション環境のパラメータをランダムに変化させることで、モデルが様々な環境条件に適応しやすくなり、学習効率が向上します。
ドメインランダマイゼーションの課題:
計算量の増加: シミュレーション環境のパラメータをランダムに変化させるため、計算量が増加します。
適切なパラメータの設定: シミュレーション環境のパラメータを適切に設定しないと、学習効率が低下したり、モデルが現実世界でうまく動作しない場合があります。
ドメインランダマイゼーションの応用例:
ロボット制御: ロボットアームなどの制御
自動運転: 自動運転車の制御
ゲーム: ゲームAIの開発
医療: 医療ロボットの開発
ドメインランダマイゼーションと関連する用語:
強化学習: エージェントが環境と相互作用しながら、最適な行動を選択することを学習するアルゴリズム
シミュレーション環境: 現実世界を模倣した仮想環境
リアリティギャップ: シミュレーション環境と現実世界の間のギャップ
汎用性: 異なる環境条件でもうまく動作する能力
学習効率: 学習に必要な時間と計算量
特徴: シミュレーション内の環境要素をランダムに変更することで、モデルの汎用性を向上させる手法。
定義: シミュレーション環境のパラメータをランダムに変更し、多様な環境を生成することで、モデルが実世界のデータに対してより一般化できるようにする手法。
目的:
シミュレーションと実世界のギャップを縮小し、sim2realの課題を克服する。
シミュレーションで学習したモデルが現実世界の未知の変数に対しても頑健であるようにする。
説明: ドメインランダマイゼーションは、モデルがシミュレーションの限界を超え、現実の多様なシナリオに対応できるよう訓練するために使用されます。ドメインランダマイゼーションは、特にシミュレーション環境から実世界への知識の転移を容易にするために用いられる技術です。この手法では、シミュレーション環境内での入力データの特徴(例えば、テクスチャ、照明、背景など)をランダムに変化させることにより、モデルが多様なシナリオに対応できるよう訓練されます。しかし、このアプローチにはいくつかの弱点が存在します。
ドメインランダマイゼーションの主な弱点
現実世界の多様性の完全なカバレッジが難しい
どれだけ多くのバリエーションをシミュレーションに導入しても、現実世界のすべての変動を網羅することは非常に困難です。これにより、訓練されたモデルが未知のシナリオに遭遇したときにパフォーマンスが落ちる可能性があります。
計算コストが高い
シミュレーション環境をランダムに多様化させるためには、多くのリソースを必要とします。これは計算コストの増加を意味し、特にリソースが限られている場合には実行が困難になることがあります。
ランダマイゼーションの範囲選定の困難
適切なランダマイゼーションの範囲や程度を設定することは難しく、不適切な設定はモデルの学習に悪影響を及ぼす可能性があります。過剰にランダマイズすると、現実から離れた不自然なデータになり得ます。
過学習のリスク
モデルがランダマイズされたシミュレーション環境に過剰に適応することで、実際の環境での一般化能力が低下する可能性があります。これは、現実世界での有効性を損なう結果を招くことがあります。
バイアスの導入
ランダマイゼーションプロセス自体が意図しないバイアスを導入する可能性があります。例えば、特定のシナリオや環境が過剰に表現されることで、モデルの決定に偏りが生じる可能性があります。
これらの弱点にもかかわらず、ドメインランダマイゼーションはトレーニングデータの多様性を向上させ、シミュレーションから実世界への転移学習を促進する有効な手法であると考えられています。それでも、これらの弱点を認識し、適切な対策を講じることが重要です。
ドメインアダプテーション(Domain Adaptation)
ドメインアダプテーション(Domain Adaptation)は、異なるが関連するデータソース(ドメイン)間で機械学習モデルのパフォーマンスを一般化させることを目的とした技術です。特に、訓練データ(ソースドメイン)と異なる特性を持つデータ(ターゲットドメイン)でモデルを適用する際に重要です。ここでは、G検定(AIに関する基礎知識を問う試験)で問われるかもしれないドメインアダプテーションに関する質問とその説明を示します。
ドメインアダプテーションとは何か?
異なるドメイン間での知識の転移を目指し、ソースドメインで学習したモデルがターゲットドメインでもうまく機能するようにする技術。
ドメインシフトとは何か?
ソースドメインとターゲットドメイン間でデータの分布が異なる状態を指し、この違いがモデルのパフォーマンス低下の原因となる。
ドメインアダプテーションの主な課題は何か?
ソースドメインとターゲットドメイン間の統計的な差異(ドメインシフト)に対処し、モデルの一般化能力を高めること。
教師ありドメインアダプテーションとは何か?
ターゲットドメインからのラベル付きデータを使用してモデルを調整するドメインアダプテーションの手法。
教師なしドメインアダプテーションとは何か?
ターゲットドメインからのラベルなしデータを利用し、ドメイン間の分布のギャップを埋めるための技術。
セミ教師ありドメインアダプテーションとは何か?
ターゲットドメインの少量のラベル付きデータと大量のラベルなしデータを共に使用するドメインアダプテーションの形式。
ドメイン不変表現学習とは何か?
モデルがドメインの影響を受けずに一般的な特徴を抽出できるように学習すること。
逆学習を用いたドメインアダプテーションとは?
逆学習(Adversarial Learning)を利用して、ドメイン識別器がソースとターゲットのデータを区別できないような特徴表現を学習させる手法。
ピボットベースドメインアダプテーションとは何か?
ピボット(共通の特徴)を基にソースとターゲットドメインのデータをマッピングし、ドメインシフトを低減する手法。
ドメインアダプテーションの応用例を挙げよ。
自然言語処理における感情分析で、製品レビューから得たモデルをTwitter投稿の感情分析に適用する。また、医療画像解析で、ある病院での画像データを別の病院の画像解析に適用する場合など。
残差強化学習
特徴: 既存の制御システムやポリシーに小さな改善を加えることを目的とした強化学習のアプローチ。
目的: 既に効率的なシステムをさらに改善し、性能を微調整する。
説明: 残差強化学習は、完全なポリシーを一から学習する代わりに、既存のポリシーを基に少しずつ改善を加えることで、より精密な制御を可能にします。
Residual blockとDense net
Residual Block(残差ブロック)
概要 残差ブロックは、主にResNet(Residual Network)アーキテクチャにおいて使用されるコンポーネントです。このブロックの主な目的は、非常に深いネットワークを効果的に訓練することを可能にすることです。残差ブロックのキーアイデアは、入力をブロックの出力に直接追加(スキップ接続またはショートカット接続とも呼ばれる)することです。
動作原理 残差ブロックでは、入力 𝑥x に対して一連の畳み込み(およびその他の)操作を適用し、その結果を元の入力 𝑥x と加算します。これにより、ネットワークは入力 𝑥x からの残差関数(入力と出力の差)を学習します。この設計により、勾配が消失する問題を効果的に防ぐことができ、非常に深いネットワークを安定して訓練することが可能になります。
式 Output=𝐹(𝑥,{𝑊𝑖})+𝑥Output=F(x,{Wi})+x ここで、𝐹(𝑥,{𝑊𝑖})F(x,{Wi}) は畳み込み層を含むネットワーク操作、𝑥x は入力、𝑊𝑖Wi は学習可能なパラメータです。
DenseNet(Densely Connected Convolutional Networks)
概要 DenseNetは、各層が以前のすべての層と直接的に接続されるという特徴を持つCNNアーキテクチャです。この設計により、各層が前のすべての層からの特徴マップにアクセスできるため、特徴の再利用が可能となり、非常に効率的な特徴伝達とパラメータの使用が実現します。
動作原理 DenseNetでは、各層からの出力が後続のすべての層の入力として連結されます。つまり、第 𝑙l 層の出力は、第1層から第 𝑙−1l−1 層までのすべての層の出力の連結となります。この「密結合」設計により、層間での情報の流れが最大化され、勾配の消失を防ぎながら効率的に学習することが可能です。
式 𝑥𝑙=𝐻𝑙([𝑥0,𝑥1,…,𝑥𝑙−1])xl=Hl([x0,x1,…,xl−1]) ここで、𝑥0,𝑥1,…,𝑥𝑙−1x0,x1,…,xl−1 は0から 𝑙−1l−1 までの層の出力の連結を表し、𝐻𝑙Hl は層 𝑙l の操作(通常は畳み込み)、𝑥𝑙xl は層 𝑙l の出力です。
共通点と相違点
共通点: 両方とも深いネットワークの訓練を容易にし、勾配の消失問題を解決する設計を持っています。
相違点: 残差ブロックでは入力を出力に加算するのに対し、DenseNetでは入力を後続のすべての層に連結します。この違いにより、DenseNetは特徴の再利用を最大化し、ResNetはより深いネットワークの効率的な訓練に焦点を当てています。
学習目標:ディープラニングのモデルの解釈性の手法について理解する。
ディープラーニングのモデルの解釈性問題
特徴: ディープラーニングモデルはしばしば「ブラックボックス」と見なされるため、その決定プロセスの理解が困難であること。
目的: モデルの予測や決定の根拠を明らかにし、ユーザーの信頼と理解を向上させる。
説明: ディープラーニングモデル、特に深いニューラルネットワークは、複数の隠れ層と複雑な接続から成り立っており、どのようにして特定の出力が得られたかを解析するのが難しい。この解釈性問題に対処するために、さまざまな可視化技術や説明可能なAI(Explainable AI, XAI)が開発されています。
Grad-CAM (Gradient-weighted Class Activation Mapping)
特徴: 畳み込み層の特徴マップに基づいて、モデルの予測に寄与した領域を可視化する手法。
畳み込みニューラルネットワークにおける最後の畳み込み層の勾配情報を利用して、どの領域が予測に最も影響を与えたかを視覚化します。
特定のクラスの予測に対する「重要な領域」をヒートマップ形式で示すことができる。
主に画像認識タスク(画像分類以外も可能)に用いられ、どの部分がクラスの識別に重要であったかを明示します。
CAMよりも精度が高い: Grad-CAMは、CAMよりも精度が高いと言われています。これは、Grad-CAMが勾配情報に基づいて重み付けを行っているためです。
より詳細な可視化: Grad-CAMは、CAMよりもより詳細な可視化を提供します。これは、Grad-CAMが各ピクセルの勾配情報に基づいて重み付けを行っているためです。
解釈しやすい: Grad-CAMは、CAMよりも解釈しやすいと言われています。これは、Grad-CAMが勾配情報に基づいて重み付けを行っているためです。
目的: 画像内でモデルが注目している部分をハイライトし、モデルの判断根拠を視覚的に理解する。
CNNの動作理解: CNNがどのように画像を認識し、分類しているのかを理解するのに役立ちます。
モデルの改善: Grad-CAMを用いることで、CNNの誤認識の原因を特定し、モデルを改善することができます。
説明責任の向上: Grad-CAMを用いることで、AIシステムの意思決定過程を説明し、説明責任を向上させることができます。
説明: Grad-CAMは、特定の出力クラスに対する畳み込み層の勾配を利用して、入力画像のどの領域がそのクラスの予測に重要であったかを示します。これにより、モデルが「なぜその予測をしたのか」をユーザーが理解するのに役立ちます。
Grad-CAM(Gradient-weighted Class Activation Mapping)は、畳み込みニューラルネットワーク(CNN)における特定のクラスに対する寄与度を可視化する手法であり、CAM(Class Activation Mapping)の改良版です。CAMと同様に、画像分類タスクにおいて、CNNがどのように画像を認識し、分類しているのかを理解するのに役立ちます。
Grad-CAMヒートマップ:画像解析の可視化ツール
Grad-CAM(Gradient-weighted Class Activation Mapping)ヒートマップは、画像認識におけるAIの思考過程を可視化するツールです。画像中のどの領域が特定のクラスの認識に重要なのかを、熱さで示します。
具体的には、熱い領域ほど、そのクラスの認識に重要
青い領域ほど、そのクラスの認識に重要でない
Grad-CAMヒートマップの例:

この例では、猫を認識するCNNにおけるGrad-CAMヒートマップを示しています。画像の左側は入力画像、右側はGrad-CAMヒートマップです。ヒートマップを見ると、猫の顔や耳などの領域が赤く表示されており、これらの領域が猫の認識に最も重要であることがわかります。
Guided Grad-CAM
・説明
Guided Grad-CAM(Guided Gradient-weighted Class Activation Mapping)は、畳み込みニューラルネットワーク(CNN)における特定のクラスに対する寄与度を可視化する手法であり、Grad-CAM(Gradient-weighted Class Activation Mapping)の改良版です。Grad-CAMと同様に、画像分類タスクにおいて、CNNがどのように画像を認識し、分類しているのかを理解するのに役立ちます。
Guided Grad-CAMの特徴
Grad-CAMよりも高解像度の可視化: Guided Grad-CAMは、Grad-CAMよりも高解像度の可視化を提供します。これは、Guided Grad-CAMがGuided Backpropagationと呼ばれる手法を用いているためです。
より精度の高い可視化: Guided Grad-CAMは、Grad-CAMよりも精度の高い可視化を提供します。これは、Guided Grad-CAMが勾配情報とGuided Backpropagationの結果を組み合わせて重み付けを行っているためです。
より意味のある可視化: Guided Grad-CAMは、Grad-CAMよりもより意味のある可視化を提供します。これは、Guided Grad-CAMがCNNが実際に見ているものに基づいて重み付けを行っているためです。
Guided Grad-CAMの目的
Guided Grad-CAMの主な目的は以下のとおりです。
CNNの動作理解: CNNがどのように画像を認識し、分類しているのかをより深く理解するのに役立ちます。
モデルの改善: Guided Grad-CAMを用いることで、CNNの誤認識の原因をより詳細に特定し、モデルを改善することができます。
説明責任の向上: Guided Grad-CAMを用いることで、AIシステムの意思決定過程をより詳細に説明し、説明責任を向上させることができます。
モデルの解釈
特徴: モデルが出力した結果の背後にある理由や因果関係を理解するプロセス。
目的: モデルの動作を透明にし、その予測がどのように導かれたかを明らかにする。
説明: モデルの解釈は、データサイエンティストやドメイン専門家がモデルの予測を評価し、必要に応じて調整を加えることを可能にします。これにより、モデルの適用範囲、制限、および信頼性が改善されます。
CAM (Class Activation Mapping)
特徴: モデルの畳み込み層を活用して、クラス固有の空間的な重要度を画像上にマッピングする手法。
Grad-CAMの基となる技術で、特定の層の出力に基づきヒートマップを生成します。
特定のクラスの予測に対する画像内の影響力のある領域を可視化します。
Grad-CAMよりも先に開発され、特定のアーキテクチャの変更を必要とする場合がある。
視覚的な説明: CAMは、画像上のどの領域が特定のクラスの認識に最も貢献しているのかを視覚的に示します。
モデルの理解: CAMを用いることで、CNNがどのような特徴を重要視しているのかを理解することができます。
デバッグ: CAMを用いることで、CNNの誤認識の原因を特定することができます。
目的: モデルが画像のどの部分を重視して判断を下したのかを示し、モデルの視覚的な説明を提供する。
CNNの動作理解: CNNがどのように画像を認識し、分類しているのかを理解するのに役立ちます。
モデルの改善: CAMを用いることで、CNNの誤認識の原因を特定し、モデルを改善することができます。
説明責任の向上: CAMを用いることで、AIシステムの意思決定過程を説明し、説明責任を向上させることができます。
説明: CAMは特定の出力クラスに対して、畳み込み層の出力の平均プーリングを行い、その後の全結合層の重みと組み合わせて、入力画像に対するヒートマップを生成します。これにより、モデルの「見ている」場所が明確になり、診断、監視、その他多くのアプリケーションにおいて有用です。
CAM(Class Activation Mapping)は、畳み込みニューラルネットワーク(CNN)における特定のクラスに対する寄与度を可視化する手法です。画像分類タスクにおいて、CNNがどのように画像を認識し、分類しているのかを理解するのに役立ちます。
XAIとSHAPやLIME、Grad-CAMやCAMの関係
これらの手法は、XAIの具体的な実現手段として機能します。SHAPやLIMEはデータの特徴がモデル予測にどのように影響するかを数値的または視覚的に示し、ユーザーがモデルの動作を理解するのを助けます。一方、Grad-CAMやCAMは主に画像データに対して使用され、予測に寄与する画像領域を強調することで、モデルの「見ている」部分を明らかにします。これらの技術を通じて、モデルの判断根拠が透明になり、ユーザーはAIの判断をより信頼できるようになります。
補足説明
SHAPは、個々の予測に対する全ての特徴の貢献度を理解するのに非常に有効です。SHAP値は、特徴の正または負の影響を数値で提供し、それぞれの特徴がどのように予測を形成しているかを明確にします。
LIMEは、特定の予測に対する説明を生成することに特化しており、非常に複雑なモデルでも、局所的な解釈が可能です。代理モデル(通常は線形モデル)を使用して、元のモデルの予測の近くでデータをサンプリングし、その予測を説明します。
Grad-CAMおよびCAMは、特に畳み込みニューラルネットワークの分析に有効で、どの画像領域がクラスの予測に最も寄与したかを視覚的に示します。これは特に医療画像診断、オブジェクト検出、画像分類タスクで有用です。
学習目標:計算リソースが十分ではないエッジデバイス等で学習モデルを活用する方法を理解する
エッジ AI
特徴: デバイス自体でデータを処理し、意思決定を行う技術。クラウドとの連携を最小限に抑え、エッジデバイスの能力を最大限に活用する。
目的: 通信の遅延を減らし、プライバシーを強化し、リアルタイム処理を可能にする。
説明: エッジ AIは、データをその発生源であるデバイス上で直接処理することで、通信コストと遅延を削減します。これにより、自動運転車、スマートファクトリー、IoTデバイスなどのアプリケーションで効率的な運用が可能になります。
モデル圧縮の手法
特徴: ディープラーニングモデルのサイズを削減し、計算要求を減らす一連の技術。
目的: 計算資源が限られたデバイスでのモデルのデプロイを可能にし、パフォーマンスを維持しつつ効率を向上させる。
説明: モデル圧縮は、プルーニング、量子化、蒸留などの技術を通じてモデルの複雑さを減らし、メモリ使用量と計算負荷を削減します。これにより、エッジデバイスでのスムーズな運用が支援されます。
蒸留
特徴: 大きく複雑なモデル(教師モデル)から、小さく効率的なモデル(生徒モデル)へ知識を移転するプロセス。
(ネットワーク構造は変わらない)目的: 小型モデルでも教師モデルと同等のパフォーマンスを実現すること。
説明: 蒸留では、教師モデルの出力(ソフトターゲット)を使用して生徒モデルを訓練します。これにより、生徒モデルは教師モデルが持つ微妙な情報を捉え、より効率的ながら効果的なモデルになります。
モデル圧縮
特徴: ディープラーニングモデルのサイズを物理的に削減し、実行時の効率を向上させる技術。
目的: モデルの推論速度を高速化し、エッジデバイスでのリアルタイム性能を向上させる。
説明: モデル圧縮には、不要なパラメータの削除、重要でない情報の圧縮、ネットワーク構造の最適化などが含まれます。これにより、エッジデバイスでも高度なモデルが扱えるようになります。
量子化
特徴: モデルの重みを低ビット表現に変換するプロセス。
目的: モデルのメモリ使用量を減少させ、計算効率を向上させる。
説明: 量子化により、浮動小数点数を整数に変換することで、モデルの計算要求が大幅に削減されます。これはエッジデバイスでのデプロイにおいて特に有用で、消費電力の削減にも寄与します。
プルーニング
特徴: ネットワークから重要度の低い接続やニューロンを削除すること。
目的: モデルのサイズを削減し、推論速度を向上させる。
説明: プルーニングは、モデルの冗長な部分を削除することで、必要な計算資源を削減します。これにより、モデルの効率が向上し、エッジデバイスでの応答性が高まります。
ディープラーニングの社会実装に向けて
学習目標:AI を利活用するための、考えるべき論点や基本となる概念を国内外の議論や事例を参照に理解する。
AI のビジネス活用と法・倫理
特徴: AI技術をビジネスプロセスに組み込むことで、意思決定の自動化、顧客サービスの向上、運用コストの削減などが可能になる。
目的: ビジネスの効率化とイノベーションを推進する一方で、法規制や倫理的な問題に適切に対応する。
説明: AIのビジネス活用は、顧客データの分析、製品のパーソナライゼーション、市場予測などに利用されますが、プライバシー保護、透明性、アカウンタビリティを確保する必要があります。例えば、EUの一般データ保護規則(GDPR)は、AIを用いたデータ処理が個人の権利を尊重することを要求しています。
AI による経営課題の解決と利益の創出
特徴: AIを用いて経営上の課題を解決し、新たなビジネスチャンスを見出す。
目的: AIの分析能力と予測能力を活用して、未解決の課題に対処し、競争優位を築く。
説明: AIはサプライチェーンの最適化、顧客行動の予測、新製品の開発など、多岐にわたる経営課題に対応可能です。例えば、IBMのWatsonなどのAIシステムは、大量のデータからインサイトを抽出し、より効果的な意思決定を支援しています。
法の順守
特徴: 法律や規制に従いながらAI技術を適用すること。
目的: 法的なリスクを回避し、社会的な信頼を維持する。
説明: AI導入にあたっては、個人情報保護法、不正アクセス禁止法、著作権法など、関連する法律を遵守する必要があります。これにより、企業は法的な問題から保護されるとともに、顧客との信頼関係を維持することができます。
ビッグデータ
特徴: 膨大な量のデータセットを分析・処理する技術。
目的: データから有益な情報を抽出し、ビジネスの意思決定を支援する。
説明: ビッグデータ技術は、顧客の行動パターン、市場のトレンド、リスク管理などに利用され、企業がよりデータ駆動型のアプローチを取るのに役立ちます。ビッグデータは、AIと組み合わせることでそのポテンシャルが最大化されます。
IoT(Internet of Things)
特徴: 様々なデバイスがインターネットを通じて相互接続されること。
目的: データの収集と分析を自動化し、効率的な運用を実現する。
説明: IoTデバイスは、工場の機械から家庭用アプライアンスまで幅広く、これらから収集されるデータはAIによって分析され、エネルギー管理、メンテナンス予測、ユーザーエクスペリエンスの向上などに利用されます。
RPA(Robotic Process Automation)
特徴: ルーチンタスクや繰り返しタスクを自動化するソフトウェアロボット。
目的: 作業の自動化により、効率を向上させ、人間の労働をより価値の高い活動にシフトさせる。
説明: RPAは、請求書処理、データエントリー、顧客サービスなど、定型的な作業を自動化することで、エラーを減少させ、コストを削減します。また、従業員は創造的な仕事に集中できるようになります。
ブロックチェーン
特徴: 分散型台帳技術であり、改ざんが困難なデータの連鎖を作ることができる。
目的: 取引の透明性を高め、セキュリティを強化する。
説明: ブロックチェーンは、金融取引だけでなく、サプライチェーンの管理、契約の自動実行(スマートコントラクト)、健康記録の管理など、多岐にわたる分野で利用されています。データの完全性と透明性を保ちながら、効率的な運用が可能です。
強化学習においてロボット制御の方策獲得では何が望まれている?
強化学習をロボット制御に応用する際、いくつかの重要なアプローチや概念が望まれています。ここで言及された「pix2pix」、「seq2seq」、「sim2real」、「end2end」はそれぞれ異なるコンテキストで使用されますが、ロボット制御の文脈では以下のように解釈できます。
End-to-End Learning (end2end):
望まれている点: ロボット制御における強化学習で望まれるのは、センサー入力(例えば画像)から直接制御アクション(例えばモーターの動作)までを直結するエンドツーエンドの学習です。これにより、中間の手作業による特徴抽出やプログラミングが不要になり、システム全体としての最適化が可能になります。
利点: システムの自動化と効率化が進むため、設計からデプロイメントまでがスムーズになります。
Simulation to Reality Transfer (sim2real):
望まれている点: シミュレーション環境で学習した方策を現実世界のロボットに適用することです。シミュレーションでは無限に近いデータを生成でき、コストも抑えられますが、現実の物理環境への適応が課題です。
利点: 安全かつ経済的に大量のトレーニングを行えるため、より複雑で現実的なタスクに対応可能になります。
pix2pix and seq2seq:
これらは通常、画像から画像への変換や時系列データの処理に使われる用語であり、直接的にはロボット制御とは関連しませんが、ロボットビジョンや動作生成に関連したタスクで応用することが考えられます。
Pix2Pix: ある画像から別のスタイルの画像を生成すること。例えば、センサーデータから環境マップを生成する場合などに応用される可能性があります。
Seq2Seq: 一連の入力(例えば時系列データ)から一連の出力を生成するモデル。ロボットの動作計画や行動予測に利用されることがあります。
まとめ:
ロボット制御における強化学習のアプローチでは、特にエンドツーエンドの学習とシミュレーションから現実への転移(Sim2Real)が重要視されています。これにより、ロボットがより自律的に、かつ効果的に現実世界でのタスクを遂行できるようになることが期待されます。
世界モデルの性質
高次元データの次元削減:
世界モデルは、観測から得られる高次元データを圧縮し、より扱いやすい低次元の潜在空間にマッピングします。これにより、データの本質的な特徴が抽出され、処理が容易になります。
データの予測可能性の向上:
学習された内部モデルを利用して、未来の状態や可能な結果を予測します。これにより、エージェントは計画を立てやすくなり、意思決定の精度が向上します。
一般化能力の向上:
内部表現を通じて、訓練データに含まれない新しい状況や変動にも対応できるようになります。これは、モデルが基本的な環境のダイナミクスを捉えているためです。
学習効率の向上:
実際の環境との相互作用に依存せずに、内部モデル上でシミュレーションを行うことで、学習プロセスが加速します。特に、計算資源や時間が制限されている場合に有効です。
報酬予測:
エージェントは、内部モデルを使用して特定の行動から得られる報酬を予測できるようになります。これにより、報酬を最大化する行動選択が可能になります。
ロバスト性の向上:
世界モデルは、観測データに含まれるノイズや不完全な情報に対してもロバストな表現を提供します。これは、モデルが観測データの背後にある基本的な因果関係や構造を学習しているためです。
応用例
自動運転: 車両が周囲の環境を正確に理解し、安全に行動をとるために使用されます。
ロボティクス: ロボットが不確実な環境で効果的にタスクを遂行するための意思決定支援に利用されます。
ゲーム: 仮想環境内での戦略計画やシミュレーションに使用されます。
世界モデルは、エージェントが複雑な環境を理解し、適応する能力を大幅に向上させるための強力なツールです。これにより、実世界のアプリケーションでの強化学習の実用性が高まります。
状態表現学習(State Representation Learning)
状態表現学習(State Representation Learning)は、環境からの生のセンサデータや高次元の観測を低次元で意味のある特徴へと変換するプロセスです。この種の学習を通じて得られる表現は、その後の学習タスクにおいて非常に有用であり、転移学習においても効果的です。以下に、状態表現学習が転移学習に適している理由をいくつか挙げます。
状態表現学習の転移学習への利点
一般化能力の向上:
状態表現学習によって得られる特徴は、環境の根本的な特性を捉えるものであり、より一般化された形で情報を表現します。これにより、一つのタスクで学習した知識を他の類似タスクへ容易に適用できるようになります。
データの効率的な使用:
効果的な状態表現は、学習に必要なデータ量を減少させることができます。新しいタスクにおいても、基本的な特性が既に捉えられているため、少ないデータから学習が可能になります。
学習速度の向上:
一度良好な状態表現が学習されると、新しいタスクに対する学習プロセスが加速されます。これは、新しい環境においても、重要な特徴が迅速に抽出されるからです。
ドメイン間の適用性:
より抽象的な状態表現は、異なるドメイン間での適用性を持ちます。例えば、自動運転車のシミュレーションから実世界への知識の転移が、状態表現を通じて容易になります。
堅牢性の向上:
状態表現は、観測データのノイズや変動に対しても堅牢な特徴を提供します。これにより、新しい環境や条件の変化に対しても、モデルの性能が安定します。
考慮すべき点
表現の適切性:
転移学習の効果は、状態表現がタスク間で共有可能な、適切な抽象度であるかどうかに大きく依存します。不適切な表現は転移を困難にします。
タスク間の類似性:
状態表現の転移は、元のタスクと新しいタスク間に十分な類似性がある場合に最も効果的です。タスク間での差異が大きい場合、表現を調整する追加の学習が必要になること
学習目標:AI を利活用するための、考えるべき論点や基本となる概念を国内外の議論や事例を参照に理解する。AI プロジェクトをどのように進めるか、全体像と各フェーズで注意すべき点などを理解する。
1. AI プロジェクト進行の全体像
AI プロジェクトの全体像は、プロジェクトの目的設定から始まり、データの収集・整理、モデルの開発、テスト、デプロイメント、そして運用・監視に至るまでのプロセスを含みます。これらのフェーズは互いに連携しており、一つのフェーズが次のフェーズへの効果的な移行を可能にするためには、各段階での詳細な計画と管理が求められます。
2. AI プロジェクトの進め方
AI プロジェクトを進める方法には、プロジェクトの規模、関連するステークホルダー、利用する技術に応じて異なります。しかし一般的には、初期の要件定義、データ収集、モデル訓練、モデル評価、本番環境でのデプロイ、そして継続的なモニタリングと改善が含まれます。
3. AI を運営すべきかの検討
AI を運営するかどうかの決定は、そのAIが解決しようとする問題、プロジェクトのコスト、予想されるリターン、技術的な実現可能性、組織のAI導入に対する準備度など、多くの要因を考慮する必要があります。
4. AI を運用した場合のプロセスの再設計
AIを実際に運用する際には、既存のビジネスプロセスや業務フローを再設計する必要がしばしばあります。これにより、AIの導入がもたらす効率化や自動化の利点を最大限に活用することができます。
5. AI システムの提供方法
AIシステムを提供する方法には、オンプレミス(自社サーバーでの運用)、クラウドベース(インターネット経由でアクセスするサービス)、またはハイブリッド(両方の組み合わせ)のアプローチがあります。選択は、コスト、セキュリティ、スケーラビリティ、およびアクセシビリティの要件に基づいて行われます。
6. 開発計画の策定
AIプロジェクトにおける開発計画の策定は、プロジェクトのスコープ、目標、期間、リソース、リスク評価、およびマイルストーンを明確にすることを含みます。この計画はプロジェクトの進行を監督し、調整するための基盤を提供します。
7. プロジェクト体制の構築
AIプロジェクトを成功させるためには、適切なチーム構成が重要です。データサイエンティスト、データエンジニア、プロジェクトマネージャー、ビジネスアナリストなど、多様なスキルを持ったメンバーが必要です。
8. CRISP-DM
CRISP-DM (Cross Industry Standard Process for Data Mining) は、データマイニングプロジェクトの標準的なモデルであり、ビジネス理解、データ理解、データ準備、モデリング、評価、デプロイメントの6つのフェーズからなります。(わかりやすい言葉でデータ分析を行う標準手法)
1996年に発足したEUのESPRITプロジェクトの一環として開発され、異なる業界でデータマイニングプロジェクトを効果的に実施するためのフレームワークとして設計されました。CRISP-DMは、データマイニングプロジェクトにおける一連のタスクを包括的に記述し、これを6つの主要なフェーズに分類しています。各フェーズは具体的なタスクとアウトプットで構成されており、プロジェクトの進行に従って反復的に実施されます。
CRISP-DMの6つのフェーズ
ビジネス理解(Business Understanding)
プロジェクトの目的と要件を明確にし、ビジネス問題をデータマイニングの課題に変換します。
データ理解(Data Understanding)
利用可能なデータを収集し、データの品質を評価し、データの初歩的な探索や発見を行うフェーズです。
データ準備(Data Preparation)
分析に適したデータセットを構築します。これにはデータのクリーニング、変換、整形が含まれます。
モデリング(Modeling)
データマイニングの手法とツールを選択し、適用します。必要に応じてモデルのパラメータを調整します。
評価(Evaluation)
モデルがビジネス目標を達成しているかどうかを評価し、モデルの結果をビジネス問題に適用する前に問題点を洗い出します。
展開(Deployment)
モデルをビジネスプロセスに組み込み、結果をビジネス運営に活用します。この段階でのアウトプットはレポート、プレゼンテーション、実運用プロセスなどがあります。
CRISP-DMは、その汎用性と構造的なアプローチにより、多くの組織や業界で広く採用されています。データサイエンスプロジェクトを計画的に進める際のガイドラインとして、非常に有用です。
9. MLOps
MLOps(Machine Learning Operations)は、機械学習モデルの開発と運用を効率的に管理するためのプラクティスです。開発からデプロイメント、モニタリング、保守に至るまで、機械学習のライフサイクル全体をカバーします。
MLopsのメリット
MLOps(Machine Learning Operations)は、機械学習システムの開発、導入、運用の効率化を目指すプラクティスです。このアプローチは、DevOpsの概念を機械学習プロジェクトに適用したものであり、以下にその主なメリットを列挙します。
1. 高速化されたモデル開発とデプロイメント
MLOpsを採用することで、モデルの開発からデプロイメントまでのプロセスが自動化され、迅速化されます。これにより、ビジネスのニーズに応じた柔軟な対応が可能になります。
2. 改善されたコラボレーション
データサイエンティスト、データエンジニア、運用チーム、開発チーム間のコラボレーションが強化されます。これにより、各チーム間の情報の透明性が向上し、エラーの削減や効率的な問題解決が可能になります。
3. モデルのパフォーマンスの持続的な監視と最適化
デプロイされたモデルの性能を継続的に監視し、必要に応じて自動で再トレーニングすることができます。これにより、変化するデータや環境条件に迅速に適応し、モデルの精度を維持します。
4. 再現性とコンプライアンスの確保
MLOpsはプロジェクトのバージョニング、モデルのバージョン管理、データのトラッキングを促進します。これにより、プロジェクトの透明性が向上し、監査やコンプライアンス要件を満たしやすくなります。
5. スケーラビリティの向上
MLOpsフレームワークはスケーラビリティを考慮して設計されているため、小規模なプロトタイプから大規模なプロダクション環境まで効率的にスケールアップすることが可能です。
6. リスクの軽減
開発から運用までのプロセスが標準化されることで、モデル導入時のリスクが低減されます。エラーやバグが発生した場合でも、迅速に対処できる体制が整います。
7. 持続可能な運用
MLOpsの実践は、機械学習モデルの運用を継続的にサポートし、メンテナンスの負担を減らすことを目指します。これにより、長期的にモデルを健全に保つことが可能になります。
10. BPR (Business Process Reengineering)
BPRは、企業の業務プロセスを根本から見直し、効率的で効果的な新しい方法へと再設計することを目的とします。AIの導入にあたっては、この手法がプロセスの最適化に役立ちます。
11. クラウド
クラウド技術は、インターネットを介してサーバー、ストレージ、データベース、ネットワーキング、ソフトウェアなどのコンピューティングリソースへのアクセスを提供します。AIプロジェクトにおいては、スケーラビリティとコスト効率の向上に貢献します。
12. Web API
Web APIは、異なるソフトウェア間での情報交換や機能の利用を可能にするインターフェースです。AIシステムにおいては、モデルの機能を外部アプリケーションに組み込むために使われます。
13. データサイエンティスト
データサイエンティストは、データ解析、機械学習のモデル構築、データ駆動型の意思決定支援を行う専門家です。AIプロジェクトでは、彼らのスキルが中心的な役割を果たします。
14. プライバシー・バイ・デザイン
プライバシー・バイ・デザインは、製品やサービスの設計段階からプライバシー保護の原則を組み込むアプローチです。AIプロジェクトにおいて重要であり、ユーザーの信頼を獲得するための基本方針とされています。
特徴: プライバシー保護を最初から考慮した設計
目的: 個人情報の漏洩や悪用を防ぎ、プライバシー保護を向上させる
わかりやすい説明:
プライバシー・バイ・デザイン(Privacy by Design)は、製品やサービスの設計段階からプライバシー保護を考慮する考え方です。
具体的には、以下の原則に基づいて、製品やサービスを設計します。
データ最小化: 収集する個人情報を最小限に抑える
目的限定: 収集した個人情報は、あらかじめ定められた目的にのみ利用する
使用制限: 個人情報は、関係者以外に閲覧・利用させない
セキュリティ: 個人情報は、不正アクセス、漏洩、改ざんから保護する
プライバシー・バイ・デザインを実践することで、個人情報の漏洩や悪用を防ぎ、プライバシー保護を向上させることができます。
国内外の議論と事例:
政府のプライバシー・バイ・デザイン関連ガイドラインと事例
国内: 政府は、プライバシー・バイ・デザインの重要性を認識し、関連するガイドラインや制度を整備しています。
ガイドライン:
総務省「プライバシー・バイ・デザインガイドライン」:官公庁におけるプライバシー・バイ・デザインの推進に向けたガイドライン
経済産業省「IoTセキュリティガイドライン」:IoT製品におけるプライバシー・バイ・デザインの重要性を提唱
制度:
個人情報保護法:個人情報の取り扱いに関する基本的なルールを定めた法律
マイナンバー法:マイナンバーの取り扱いに関する法律
事例:
民間企業:
LINE Corporation: LINEアプリにおけるプライバシー保護対策として、プライバシー・バイ・デザインの考え方を導入
楽天株式会社: 楽天市場における個人情報保護対策として、プライバシー・バイ・デザインの考え方を導入
行政機関:
総務省: マイナンバー制度における個人情報保護対策として、プライバシー・バイ・デザインの考え方を導入
厚生労働省: 健康医療情報における個人情報保護対策として、プライバシー・バイ・デザインの考え方を導入
学習目標:AI の学習対象となるデータを取得・利用するときに注意すべきことや、データを共有しながら共同開発を進める場合の留意点を理解する。
1. オープンデータセット
オープンデータセットは、一般に公開され、誰もが自由にアクセスし利用できるデータの集合です。これらは主に研究や教育目的で利用され、AIモデルのトレーニングにも広く用いられます。利用する際はデータセットのライセンス条件を確認し、適切な使用が求められます。
2. 個人情報保護法
個人情報保護法は、個人のプライバシーを保護し、個人情報の適正な取り扱いを義務付ける法律です。AIプロジェクトにおいて個人情報を扱う場合、この法律の規定に従うことが必須であり、違反すると法的責任を問われる可能性があります。
3. 不正競争防止法
不正競争防止法は、ビジネス上の公正な競争を保護することを目的としています。この法律は、企業が他社の営業秘密を不正に使用することを禁じており、AIデータやアルゴリズムの保護にも適用されることがあります。
4. 著作権法
著作権法は、作品の創造者がその作品に対して有する権利を保護します。AIプロジェクトで使用されるデータセットやソフトウェアコードが他者の著作物を含む場合、著作権違反にならないよう注意が必要です。
5. 特許法
特許法は、新しい技術や発明を保護する法律です。AI技術を開発する際には、既存の特許を侵害していないか、または自身の発明を特許で保護する必要があるかどうかを検討する必要があります。
6. 個別の契約
個別の契約は、データの使用やAIプロジェクトにおける特定の条件を定める法的文書です。これにより、プロジェクトの各参加者の権利と義務が明確にされ、トラブルの防止に役立ちます。
7. データの網羅性
データの網羅性は、利用するデータセットが対象とする現象や集団を適切に表現しているかどうかを指します。不十分な網羅性は、AIモデルの偏りや誤った予測を引き起こす原因となるため、注意が必要です。
8. 転移学習
転移学習は、あるタスクで学習した知識を、異なるが関連する別のタスクへ適用する学習方法です。これにより、データが少ない状況でも効果的なモデルを構築できるため、AI開発において広く利用されています。
9. サンプリング・バイアス
サンプリング・バイアスは、データセットが生成される過程で偏りが生じることです。これは、データが特定の集団や現象を不公正に表現することを意味し、AIモデルの公平性や正確性に悪影響を与えます。
10. 他企業や他業種との連携
他企業や他業種との連携は、リソース、知識、技術の共有を通じて、より革新的なAIソリューションを開発する手法です。これには相互の信頼と共有される目的の明確化が必要です。
11. 産学連携
産学連携は、企業と学術機関が協力して研究開発を進めることです。この協力関係は、理論的な知見と実践的な応用のギャップを埋め、技術革新を加速させる効果があります。
12. オープン・イノベーション
オープン・イノベーションは、外部のアイデアや技術を積極的に取り入れることで、新しい製品やサービスを生み出すプロセスです。AI分野では、異なる業種や分野からの知識を組み合わせることが多く、創造性を高めます。
13. AI・データの利用に関する契約ガイドライン
AI・データの利用に関する契約ガイドラインは、データの使用、知的財産権の管理、プライバシー保護など、AIプロジェクトにおける法的問題を扱うための枠組みを提供します。これに従うことで、法的リスクを管理し、プロジェクトの透明性を確保できます。
1. アノテーション
特徴: アノテーションはデータに追加情報やラベルを付けるプロセスです。
目的: 機械学習モデルのトレーニングに必要な正確なデータセットを作成するため。
説明: アノテーションは、画像、テキスト、音声などの生データに、カテゴリーや特徴を示すタグを付けることです。これにより、AIは特定のデータを認識し、学習する際の基準点を持つことができます。
2. 匿名加工情報
特徴: 個人を特定できないように加工された情報。
目的: プライバシー保護を保ちながらデータを利用するため。
説明: 匿名加工情報は、元の個人情報から特定の個人を識別できないように加工されたデータです。この加工により、データの利用範囲が広がり、プライバシーのリスクを最小限に抑えることができます。
3. カメラ画像利活用ガイドブック
特徴: カメラ画像の収集と利用に関するガイドライン。
目的: 倫理的かつ法的に適切な画像データの利用を促進するため。
説明: このガイドブックは、カメラ画像の収集、保管、処理、利用の際に考慮すべき法的、倫理的要件を説明しています。プライバシー保護やデータ保護の観点から重要な指針を提供します。
4. ELSI
特徴: Ethical, Legal and Social Implications(倫理的、法的および社会的影響)の略。
目的: 科学技術の進展が社会に与える影響を考慮し、適切な対策を講じるため。
説明: ELSIは、特にバイオテクノロジーや情報技術の分野で、研究や技術開発が社会に与える可能性のある影響を評価し、対応策を検討する枠組みです。
5. ライブラリ
特徴: 特定のプログラミング言語で使える再利用可能なコードの集まり。
目的: 効率的なソフトウェア開発を支援するため。
説明: ライブラリはプログラム開発時に共通のタスクを効率よく処理するためのコード集です。たとえば、データ分析でよく使われるPython言語のNumPyやPandasなどがあります。
6. Python
特徴: 高レベルで解読しやすい構文を持つプログラミング言語。
目的: 汎用性の高いプログラミングを可能にし、特にデータサイエンスとAIに
適しています。
説明: Pythonは初心者から専門家まで幅広く使われており、そのライブラリの豊富さがデータ分析、ウェブ開発、自動化など多岐にわたる分野での使用を促進しています。
7. Docker
特徴: アプリケーションをコンテナ化することで、一貫した環境で動作させる技術。
目的: アプリケーションのデプロイメントを簡素化し、環境依存の問題を解消するため。
説明: Dockerはソフトウェアをコンテナと呼ばれる隔離された環境にパッケージ化することで、開発からテスト、本番環境まで一貫して動作させることができます。
Docker は、OS レベルの仮想化技術を使ってソフトウェアをパッケージングし配布する方法です。コンテナと呼ばれる単位でアプリケーションを実行することで、 実行環境を依存関係ごとまるごと配布 できるようになります。これにより、異なる環境でも同じように動作するアプリケーション を開発・配布・実行することが容易になります。
Dockerの仕組み
Docker は、コンテナ、コンテナイメージ、Dockerエンジンの 3 つの主要コンポーネントで構成されます。
コンテナ: アプリケーションの実行に必要なコード、ライブラリ、設定ファイルなどすべてがまとめられた実行環境です。軽量で、起動が速いです。
コンテナイメージ: コンテナのテンプレートのようなもので、コンテナを生成するためのレシピが記述されています。イメージは Docker Hubと呼ばれるレジストリに公開されており、そこからダウンロードすることができます。
Dockerエンジン (Dockerデーモン): Docker コマンドを実行し、コンテナの作成や実行、管理を行うソフトウェアです。Dockerエンジンは、ホストマシンの OS 上で動作します。
Dockerを使うメリット
Docker を使うことで得られる主なメリットは以下です。
移植性が高い: Dockerアプリケーションは、コンテナとしてパッケージングされているため、実行環境に依存しません。異なる OS 上でも同じように動作します。
軽量で起動が速い: コンテナは仮想マシンよりも軽量で、起動が速いです。
開発・テスト・本番環境での一貫性: 開発環境、テスト環境、本番環境で同じ Docker イメージを使うことで、環境差による問題を回避できます。
リソースの効率化: コンテナはホストマシンの OS カーネルを共有するため、仮想マシンよりもリソース効率に優れています。
マイクロサービスアーキテクチャの実現: Docker はマイクロサービスアーキテクチャを実装するのに適しており、アプリケーションを小さなサービスに分割し、それぞれをコンテナで実行することができます。
Dockerのデメリット
Docker を使うことでのデメリットとしては以下が挙げられます。
ホストマシンの OS に依存する: コンテナは、ホストマシンの OS カーネルを共有して動作するため、完全に独立した実行環境ではありません。
セキュリティ: コンテナ同士やホストマシンとの間のセキュリティ対策が必要です。
複雑性: 大規模なシステムでは、コンテナを大量に管理することが必要になり、複雑になる可能性があります。
8. Jupyter Notebook
特徴: ウェブベースのインタラクティブなコンピューティング環境。
目的: コードの実行と文書化を同時に行うことで、データサイエンスプロジェクトの進行を効率化するため。
説明: Jupyter Notebookではコードの実行結果をリアルタイムで確認しながら、解析の手順や結果を文書化することができます。これにより、研究や報告書の作成が容易になります。
Jupyter Notebook とは、ウェブブラウザ上で動作する対話型の文書作成環境です。主に、Python でのプログラミングやデータ分析に用いられます。
Jupyter Notebook は以下の特徴を備えています。
コード、テキスト、グラフなどを一つの文書にまとめられる
コードの実行結果をリアルタイムで確認できる
マークダウン記法による文書作成がサポートされている
様々なライブラリや拡張機能を利用できる
9. 説明可能AI (XAI)
特徴: AIモデルの意思決定プロセスを人間が理解できる形で説明する技術。
目的: AIの透明性と信頼性を高めるため。
説明: XAIは、AIの決定に至るロジックや根拠を明確にすることで、ユーザーがAIの判断を信頼しやすくなります。特に重要な意思決定において必要とされます。
**説明可能AI(XAI)**は、AIシステムがどのように意思決定を行うのかを人間が理解できるようにするための手法や技術の総称です。近年、AIシステムが社会の中で広く利用されるようになり、その影響力も大きくなっていく中で、AIシステムの透明性や説明責任が求められています。XAIは、こうした課題に対処するために重要となる技術です。
XAIの重要性
XAIが重要な理由は、以下のとおりです。
AIシステムの信頼性向上: AIシステムがどのように意思決定を行うのかを理解することで、その信頼性を高めることができます。
AIシステムのデバッグ: AIシステムが誤った判断をした場合、XAIを用いることでその原因を特定しやすくなります。
AIシステムの倫理的な利用: AIシステムが偏見や差別などの問題を引き起こしていないことを確認するために、XAIを用いることができます。
AIシステムに対する理解: XAIを用いることで、AIシステムの内部構造や動作原理を理解することができます。
XAIの手法
XAIには、様々な手法があります。代表的な手法としては、以下のものが挙げられます。
特徴重要度分析: 各特徴がモデルの予測にどのように影響を与えているのかを分析する手法です。
部分依存度プロット: 入力値の変化がモデルの予測にどのように影響を与えているのかを可視化する手法です。
LIME: 入力データの局所的な近似モデルを用いて、モデルの予測を説明する手法です。
SHAP: 各特徴がモデルの予測にどのように貢献しているのかを数値で表す手法です。
XAIの課題
XAIには、以下のような課題があります。
説明の複雑性: XAIによって生成される説明が、人間にとって理解しにくい場合がある。
説明の妥当性: XAIによって生成される説明が、必ずしもモデルの実際の動作を正確に反映しているとは限らない。
計算量: XAI手法によっては、計算量が多くなり、処理時間が長くなる場合がある。
10. フィルターバブル
特徴: ユーザーの過去の行動に基づいて情報をフィルタリングし、類似の情報のみを提供する環境。
目的: ユーザー体験のパーソナライズを強化するため。
説明: フィルターバブルは、ソーシャルメディアや検索エンジンなどで見られる現象で、ユーザーが多様な視点や情報に触れる機会を失う可能性があります。
11. FAT (Fairness, Accountability, Transparency)
特徴: AIシステムの公平性、説明責任、透明性を確保するための原則。
目的: AIの倫理的な利用と社会的受容を促進するため。
説明: FATは、AI技術が個人や社会に与える影響を正しく評価し、それに対する責任を明確にすることを目指します。
12. PoC (Proof of Concept)
特徴: 新しいアイデアや技術が実現可能であることを示す初期段階の実証。
目的: 投資前に技術の有効性や実用性を評価するため。
説明: PoCは、プロジェクトや製品が期待通りに機能するかを小規模でテストすることで、リスクを管理し、開発の方向性を定めるのに役立ちます。
1. 著作物
特徴: 創作の成果物で、独創的な表現を持つもの。
目的: 創作者の権利を保護し、創作活動を促進する。
説明: 著作物には文学、音楽、美術作品などが含まれ、著作権法により保護されています。これにより創作者は自分の作品から経済的利益を得ることができ、創作活動の動機付けになります。
2. データベースの著作物
特徴: 系統的に構成されたデータの集まり。
目的: データベースの創作者に対する投資の回収と保護。
説明: データベースはその選択や配置に創造性が認められる場合、著作物として保護されます。これはデータベースを作成するための労力とコストを保護するために重要です。
3. 営業秘密
特徴: 公開されていない業務上の情報で、経済的価値を持ち、秘密として管理されているもの。
目的: 競争上の優位性を保持する。
説明: 営業秘密は、製造方法、販売戦略、顧客リストなどが含まれます。これらは企業が競争力を維持するために重要であり、不正競争防止法により保護されています。
4. 限定利用データ
特徴: 利用が特定の条件下でのみ許可されるデータ。
目的: プライバシー保護や契約上の約束を守るため。
説明: このようなデータは、利用者が特定の契約に同意した場合のみアクセス可能で、条件違反時には法的措置が取られる可能性があります。
5. オープンデータに関する運用除外
特徴: 特定のデータがオープンデータ政策の対象外である場合。
目的: セキュリティやプライバシーの保護。
説明: このような除外は通常、国家安全保障、個人情報の保護、企業の機密情報などの理由で行われます。
6. 秘密管理
特徴: 情報を秘密として適切に保護するためのプロセス。
目的: 情報の不正利用や漏洩を防ぐ。
説明: 秘密管理には物理的、技術的、管理的な対策が含まれ、これにより情報が保護され、信頼性の高いビジネス環境が維持されます。
7. 個人情報
特徴: 個人を識別できる情報。
目的: 個人のプライバシーとデータの安全を保護する。
説明: 個人情報は、氏名、住所、メールアドレスなどが含まれます。データ保護法(例えばGDPR)により、これらの情報の収集、使用、保存が厳格に規制されています。
8. GDPR
特徴: ヨーロッパ連合のデータ保護法規。
目的: EU内のすべての個人のデータ保護を強化し、企業によるデータの取り扱いを規制する。
説明: GDPRは、個人の同意なしに個人データを処理することを制限し、データ漏洩時には厳格な報告義務を課します。
9. 十分性制定
特徴: 特定の国がGDPRに基づいて個人データの保護に関して十分な措置を講じているとEUが認定すること。
目的: EU外の国とのデータ流通を容易にする。
説明: 十分性認定を受けた国は、EUとデータを自由にやり取りできるようになり、国際ビジネスの効率化が図れます。
10. 敵対的な攻撃(Adversarial attacks)
特徴: AIシステムを欺くためにデータ入力を意図的に操作する。
目的: AIシステムの脆弱性を発見または悪用する。
説明: 敵対的攻撃は、AIが誤った判断を下すように誤解させるデータを生成することで、システムのセキュリティを試験します。
敵対性バッチとは、モデルの判断を誤らせるように設計されたデータの集合です。具体的には、モデルが誤分類しやすいように、特定のパターンやノイズを含むデータを作成します。これらのデータを含むバッチをモデルに学習させると、モデルは誤ったパターンを学習し、本来の判断能力が低下してしまう可能性があります。
敵対性サンプルとは、個々のデータポイントに対して、モデルの判断を誤らせるように設計された改ざんデータです。具体的には、データにわずかなノイズを加えたり、特定のパターンを挿入したりすることで、モデルが誤分類しやすいようにします。敵対性サンプルは、モデルの入力データに対する感度を利用して作成されます。
メンバーシップ推論とは、機械学習モデルに対して、入力されたデータがモデルの学習データに含まれているかどうかを推測する攻撃手法です。この攻撃が成功すると、攻撃者は以下の情報を入手することができます。
モデルの学習データに含まれるデータの種類
特定の個人データがモデルの学習データに含まれているかどうか
機密情報を含むデータがモデルの学習データに含まれているかどうか
代表的な方法として以下の2つが挙げられます。
信頼スコア分析: 多くの機械学習モデルは、予測結果の信頼度を示す信頼スコアを出力します。攻撃者は、この信頼スコアを分析することで、入力されたデータがモデルの学習データに含まれているかどうかを推測することができます。
データサンプリング: 攻撃者は、モデルの学習データと類似したデータのサンプリングを行い、モデルの応答を分析することで、入力されたデータがモデルの学習データに含まれているかどうかを推測することができます。
データセットへの攻撃対策
データセットは、機械学習モデルの学習に不可欠な要素です。しかし、データセットは様々な攻撃に対して脆弱であり、攻撃によってモデルの精度が低下したり、誤った結果を導き出されたりする可能性があります。
データセットへの攻撃には、以下のような種類があります。
データポイズニング攻撃: 攻撃者は、意図的に誤ったデータやノイズを含むデータをデータセットに混入させ、モデルを誤学習させようとします。
バックドア挿入攻撃: 攻撃者は、モデルが特定の入力に対して特定の出力を出すように仕向けるバックドアをデータセットに挿入しようとします。
データ改ざん攻撃: 攻撃者は、データセットのデータを改ざんすることで、モデルの精度を低下させようとします。
データ漏洩攻撃: 攻撃者は、データセットを盗み出すことで、機密情報を入手しようとします。
データセットへの攻撃を防ぐためには、以下の対策を講じることが重要です。
データソースの信頼性を確保する: データセットは、信頼できるソースから取得する必要があります。
データの異常を検知する: データセットに異常なデータが含まれていないかどうかを検知する必要があります。
データのアクセス権を制限する: データセットへのアクセス権は、必要な人だけに制限する必要があります。
データの暗号化: データセットは、暗号化して保存する必要があります。
モデルの検証を行う: モデルは、データセットに攻撃が含まれていないかどうかを検証する必要があります。
11. ディープフェイク
特徴: AI技術を使用して作成された、現実のものと見分けがつかない偽のビデオや音声。
目的: エンターテインメント、教育、または悪意のある偽情報の拡散。
説明: ディープフェイクは、特に社会的な混乱を引き起こすために使用されることがあります。これにより、情報の真偽を判断することが難しくなります。
12. フェイクニュース
特徴: 誤情報または捏造情報を含むニュース。
目的: 公共の意見形成を誤らせること。
説明: フェイクニュースは、政治的アジェンダを推進するためや、社会的な混乱を引き起こすために意図的に拡散されることが多いです。
13. アルゴリズムバイアス
特徴: AIシステムにおける偏りまたは不公正な結果。
目的: アルゴリズムによる判断が公平であることを確保する。
説明: アルゴリズムバイアスは、トレーニングデータの偏りや設計の欠陥によって発生します。この問題を認識し、対策を講じることがAI倫理において重要です。
14. ステークホルダーのニーズ
特徴: プロジェクトや企業に関わる個人やグループの要求や期待。
目的: ステークホルダーの満足とプロジェクトの成功を確保する。
説明: ステークホルダーのニーズを理解し、それに応じてサービスや製品を設計することは、プロジェクトの成果に直接影響します。これには顧客、従業員、投資家などが含まれます。
1. コーポレートガバナンス
特徴: 企業の経営と監督の枠組みやプロセス。
目的: 効果的な経営、利害関係者への説明責任、及び企業倫理の遵守を確保する。
説明: コーポレートガバナンスは、企業の取締役会が如何に企業を適正に管理し、株主やその他のステークホルダーの利益を保護するかに焦点を当てます。適切なガバナンスは、企業の透明性を高め、投資家の信頼を確保することができます。
2. 内部統制の更新
特徴: 企業内部での監査やプロセスの改善。
目的: 企業の運営効率の向上とリスクの管理。
説明: 内部統制の更新は、財務報告の正確性を保証し、詐欺やミスを防ぐために重要です。これには、情報システムのセキュリティ強化や、運営プロセスの見直しが含まれます。
3. シリアス・ゲーム
特徴: 教育や訓練、健康管理を目的としたビデオゲーム。
目的: 楽しみながら学習やスキルの向上を促す。
説明: シリアス・ゲームは、従来の教育手法に比べて参加者のモチベーションを高め、より効果的な学習が期待できます。例えば、医療訓練や災害対応訓練などに用いられます。
4. 炎上対策とダイバーシティ
特徴: ソーシャルメディアでの批判的な状況への対応策と多様性の促進。
目的: 企業の評判保護と社会的責任の充足。
説明: 炎上対策は企業がオンラインでの否定的な反響を管理するための戦略です。一方、ダイバーシティの推進は、異なるバックグラウンドを持つ人々を尊重し、積極的に取り入れることで、より豊かな企業文化を築きます。
5. AI と安全保障・軍事技術
特徴: 人工知能の軍事および安全保障への応用。
目的: 国防の強化と軍事作戦の効率化。
説明: AI技術は、無人戦闘機の運用や諜報活動の自動化など、軍事操作の多くの面で利用されています。しかし、これらの技術の使用は倫理的な議論を引き起こすこともあります。
6. 実施状況の公開
特徴: 企業活動やプロジェクトの進行状況を透明にする行
為。
目的: ステークホルダーへの説明責任と信頼の構築。
説明: 実施状況の公開は、企業が進めているプロジェクトやイニシアティブの進行具合を外部に報告することです。これにより、透明性が保たれ、利害関係者との良好な関係が維持されます。
7. 透明性レポート
特徴: 企業が定期的に発行する、その活動や影響に関する詳細な報告書。
目的: 企業の活動の透明性を向上させ、公共の信頼を確保する。
説明: 透明性レポートは、プライバシー、セキュリティ、法律への準拠など、さまざまな側面についての情報を公開し、企業がどのように社会的責任を果たしているかを示します。
8. よりどころとする原則や指針
特徴: 企業や組織が遵守するべき倫理的、法的な基準。
目的: 一貫性のある意思決定と行動の基盤を提供する。
説明: 原則や指針は、企業が直面する倫理的なジレンマや選択に対して指導的な役割を果たします。これにより、企業はその価値観を反映した行動を取ることができ、外部からの信頼を維持することが可能です。
1. Partnership on AI
特徴: 人工知能の研究と実践に関する多様なステークホルダーが参加する非営利団体。
目的: 人工知能の開発と利用が人間社会にとって益となるように促進し、ガイドする。
説明: Partnership on AIは、テクノロジー企業、学術機関、非営利団体などから構成されており、AIの倫理的な使用、透明性、公正性を推進することを目指しています。この組織は、AI技術の社会的影響についての研究を支援し、ポリシー作成に影響を与える情報を提供します。
2. 運用の改善やシステムの改修
特徴: 現行システムの効率化や機能強化を目的としたプロセス。
目的: 組織の運用効率を向上させ、技術的問題を解消する。
説明: 運用の改善やシステムの改修は、既存のビジネスプロセスやITシステムに対して、新たな技術を導入することや、プロセスを再構築することを含みます。これにより、作業の自動化が進む、エラーの減少、作業効率の向上などの利点が期待できます。
3. 次への開発と循環
特徴: 既存のプロダクトやサービスから得られた知見を次のイテレーションに活かすアプローチ。
目的: 継続的な改善と革新を促進する。
説明: 次への開発と循環は、プロダクト開発サイクルの一環として、フィードバックやパフォーマンスデータを収集し、それを基に製品やサービスのアップデートを行うプロセスです。このアプローチにより、企業は市場の変化に迅速に対応し、競争優位を保持することが可能になります。この循環的なプロセスは、アジャイル開発やリーンスタートアップの手法にも通じるものがあり、継続的な学習と改善を重視します。
統計検定3級は、統計学の基本的な知識と技能を測る試験です。ここでは、そのレベルに適した基礎的なキーワードとその説明、さらに基本的な計算問題をいくつか取り上げます。
1. 平均 (Mean)
特徴: データセットの中心的な傾向を示す尺度。
目的: データの集中値を表す。
説明: 平均は、すべてのデータ点の合計をデータ点の数で割ったものです。計算式は (\frac{\sum_{i=1}^n x_i}{n}) です。
2. 中央値 (Median)
特徴: データセットを小さい順に並べたときに、ちょうど中央に位置する値。
目的: データの中心値を外れ値の影響を受けずに示す。
説明: データの数が奇数の場合は中央の値、偶数の場合は中央の二つの値の平均が中央値です。
3. 分散 (Variance)
特徴: データの散らばり具合を数値化する尺度。
目的: データが平均からどの程度離れているかを量る。
説明: 分散は各データ点と平均との差の二乗の平均です。計算式は (\frac{\sum_{i=1}^n (x_i - \mu)^2}{n}) です。
4. 標準偏差 (Standard Deviation)
特徴: 分散の平方根として定義される、データの散らばりを示す尺度。
目的: 分散よりも直感的にデータの散らばりを理解する。
説明: 標準偏差は (\sqrt{\text{Variance}}) で計算され、データの単位と一致します。
5. 確率分布 (Probability Distribution)
特徴: ランダムな事象の各結果に対する確率を記述する関数。
目的: 事象の発生確率を理解する。
説明: 代表的な確率分布には正規分布、二項分布、ポアソン分布などがあります。
6. 正規分布 (Normal Distribution)
特徴: 自然界や人間活動に頻繁に現れる、ベル形の確率分布。
目的: 実際のデータ分布をモデル化し、予測する。
説明: 正規分布は平均 (\mu) と標準偏差 (\sigma) の二つのパラメータで定義されます。
基本的な計算問題
問題 1: 平均の計算
データセット: (3, 5, 8, 10, 2)
平均は?
問題 2: 標準偏差の計算
データセット: (4, 6, 6, 7, 11, 13)
標準偏差は?
これらの問題を解くことで、統計の基本的な概念がより明確に理解できます。それぞれの計算方法は、数学的な公式に基づいており、データの特性を定量的に評価するための重要な手段です。
統計検定3級の範囲に適した基本的な統計学のキーワード
1. 母集団
特徴: 調査対象となる全体の集まり。
目的: 調査や研究の対象となる全データの基。
説明: 母集団は、特定の研究問題に関連するすべての要素や個体を含む集合です。例えば、ある国の全成人が母集団となる場合があります。
2. 標本
特徴: 母集団から抽出された一部のデータ。
目的: 母集団を代表するデータを得る。
説明: 標本は、コストや時間の制約から母集団全体を調査できない時に用いられる、小さな代表集団です。
3. 統計量
特徴: 標本データに基づいて計算される数値。
目的: 標本データを要約し、解析する。
説明: 統計量には平均、分散、標準偏差などがあり、これらは標本データを要約するために用いられます。
4. 母数
特徴: 母集団全体に基づいて計算されるパラメータ。
目的: 母集団の特性を理解する。
説明: 母数には母平均や母分散などがあり、これらは母集団全体の特性を表します。
5. 変数
特徴: 数値で表現される特徴。
目的: データの特性を数値化して分析する。
説明: 変数には、身長、体重、年齢など、測定または計算で得られる数値があります。
6. 定性変数
特徴: カテゴリーに基づく変数。
目的: データを分類する。
説明: 定性変数は性別や血液型など、数値化されないカテゴリーに基づいてデータを分類します。
7. 量的変数
特徴: 数値で表される変数。
目的: 量的な分析を可能にする。
説明: 量的変数には身長や収入など、数値で表現されるデータが含まれます。
8. 度数
特徴: データが発生する回数。
目的: データの分布を把握する。
説明: 度数は特定のデータ値がどれだけ頻繁に発生するかを示します。
9. 度数分布表
特徴: 度数を表形式で表示したもの。
目的: データの分布を視覚的に理解しやすくする。
説明: 度数分布表は、データの値とそれが発生した回数を表にまとめたものです。
10. ヒストグラム
特徴: 度数分布を棒グラフで表した図。
目的: データの分布を視覚的に示す。
説明: ヒストグラムはデータの度数分布を棒グラフで表し、データの分布状態を直感的に理解するのに役立ちます。
11. 平均値
特徴: データの合計をデータ数で割った値。
目的: データセットの中心傾向を示す。
説明: 平均値はデータセットの一般的な値を示し、データの中心を理解するために使用されます。
12. 中央値
特徴: データを昇順に並べたときに中央に位置する値。
目的: 外れ値の影響を受けにくい中心値を提供する。
説明: 中央値は、データセットの中央に位置する値であり、外れ値の影響を受けにくいため、データの中心傾向をより正確に反映します。
13. 最頻値
特徴: データセットで最も頻繁に出現する値。
目的: データセットの最も一般的な特性を把握する。
説明: 最頻値は、データセット内で最も多く発生する値を指し、特定のデータ値の一般的な発生を示します。
14. 分散
特徴: データがその平均値からどれだけ散らばっているかを示す尺度。
目的: データのばらつきを量的に評価する。
説明: 分散は、各データ点と平均値との差の二乗の平均であり、データの散布具合を示します。
15. 標準偏差
特徴: 分散の平方根で、データの散布度を示す。
目的: 分散よりも直感的にデータの散布を理解する。
説明: 標準偏差はデータの散らばり具合を、元のデータと同じ単位で表します。これにより、データの分布状態を直接比較できます。
16. 正規分布
特徴: 平均値を中心とした対称的な鐘型曲線を持つ確率分布。
目的: 多くの自然現象や社会科学のデータ分布をモデル化する。
説明: 正規分布は、多くの実際のデータセットがこの分布に従うと考えられており、標準化や確率計算に広く利用されます。
ATARI 2600
ATARI 2600は、1977年に発売されたビデオゲームコンソールで、ビデオゲーム産業における重要な地位を占めています。このコンソールは、カートリッジ交換式のシステムを採用し、ユーザーが多様なゲームを楽しむことができました。ATARI 2600は、そのシンプルで直感的なデザインと、プレイしやすいゲームで広く受け入れられ、ビデオゲームの黎明期において家庭用ゲーム機市場を開拓しました。代表的なゲームには『スペースインベーダー』『パックマン』『アステロイド』などがあります。
このATARI 2600は、近年の研究である強化学習の分野においても重要な役割を果たしています。DeepMindのDQNやその後継のアルゴリズムが開発される際に、様々なATARI 2600のゲームがベンチマークとして用いられ、これらのアルゴリズムの性能を評価するための標準的なテスト環境とされています。
AGENT57
AGENT57は、DeepMindによって開発された最新の強化学習エージェントで、ATARI 2600の57種類のゲームすべてで人間のプロのプレイヤーよりも高いスコアを達成した初めてのAIです。これにより、AGENT57はこれまでのどの強化学習アルゴリズムよりも優れた一般化能力と適応能力を持つことが示されました。
特徴と技術的進歩
探索と搾取のバランス:
AGENT57は、探索(新しい情報を得る行動)と搾取(既知の情報を基に最適な行動を選択する)の間のバランスを動的に調整する能力を持っています。これは、内部報酬システムを用いて達成され、異なる探索戦略を適応的に切り替えることができます。長期的な報酬への焦点:
AGENT57は、短期的な報酬だけでなく、長期的な報酬を最大化するように設計されています。これは、学習プロセスを通じて報酬の遅延を考慮に入れることで実現されています。ニューラルネットワークアーキテクチャの改善:
従来のDQNやその派生形よりも進んだニューラルネットワークアーキテクチャを採用しており、より複雑な環境やシナリオでの学習が可能です。
AGENT57の開発は、特に多様なタイプのゲームにおいて、一つのアルゴリズムで全てのゲームで高い性能を発揮することの可能性を示しています。これにより、AIがさらに複雑な実世界のタスクに適応するための道が開かれることになります。
リアリティギャップ
リアリティギャップ(Reality Gap)は、特にロボティクスやシミュレーションベースの機械学習などの分野で使われる用語で、シミュレーション環境で開発・訓練されたモデルやアルゴリズムが、現実世界の環境に適用された際に見られる性能の差異を指します。シミュレーションでは理想化された条件や近似された物理法則が用いられるため、完璧に現実の複雑さや不確実性を模倣することは難しく、その結果として生じる性能の低下がリアリティギャップと呼ばれます。
リアリティギャップの主な要因
物理的な違い: シミュレーションでは物理法則が簡略化されるため、実際の物理的な相互作用(摩擦、風、温度変動など)が異なる場合が多い。
センサーの精度: シミュレーションでは理想的なセンサーが使用されるが、現実世界のセンサーはノイズや誤差を含むことが一般的。
計算能力の制限: 実世界では計算資源に制約がある場合があり、シミュレーションで用いられる複雑なモデルが実時間での応答に適さないことがある。
環境の複雑性: 現実世界は予測不能な要素が多く、これをすべてシミュレーションで再現することは非常に困難。
対策
リアリティギャップを克服するための主要なアプローチは以下の通りです:
シミュレーションの向上: シミュレーション環境の物理モデルを改善し、より現実に近いモデリングを試みる。
ドメインランダム化: シミュレーション中にランダムな変数(光の条件、物体の配置、センサーノイズなど)を導入し、モデルがさまざまな条件に対応できるように訓練する。
シミュレーションと現実データの統合: 実世界のデータをシミュレーションデータに組み合わせて使用し、より現実的なトレーニングを行う。
転移学習: シミュレーションで学んだ知識をベースにして、実世界データでの微調整を行う。
リアリティギャップは、特に自動運転車や無人航空機など、安全性が極めて重要なアプリケーションにおいて大きな課題です。このギャップを狭めることで、シミュレーションで得られた成果を実世界でより効果的に活用できるようになります。
勾配ブースティング木 Gradient Boosting Decision Tree(GBDT)
Gradient Boosting Decision Tree(GBDT)は、強力な機械学習アルゴリズムの一つで、多くの実世界の問題に対して高い性能を発揮します。以下は、GBDTを実装している代表的なライブラリの一覧表です。これらのライブラリはそれぞれ独自の特徴と利点があり、多様なニーズに対応しています。
ブースティング は、複数の弱い学習モデルを組み合わせることで、より精度が高い 強力なモデルを構築する手法です。 勾配ブースティング木は、このブースティング手法の一つであり、決定木 を弱い学習モデルとして利用しています。
各ライブラリの詳細と選択のポイント
XGBoost:
強化された正則化が特徴で、オーバーフィットを防ぐのに役立ちます。
分散型コンピューティングをサポートし、非常に大きなデータセットでのトレーニングが可能。
クロスバリデーション、欠損値処理など、高度な機能を提供。
LightGBM:
Leaf-wise(葉単位)の成長戦略により、計算効率が向上し、より高速に学習が可能。
少ないメモリで高速に動作し、同等の学習精度を維持。
GPU学習のサポートもあり、さらに高速な学習が可能。
CatBoost:
特にカテゴリカルデータの扱いに特化しており、プリプロセッシングが不要。
独自のアルゴリズムにより、情報漏れを防ぎつつ効率的にカテゴリカル特徴を変換。
ユーザーフレンドリーなデフォルト設定で初心者でも容易に使用可能。
H2O:
オープンソースの分散機械学習フレームワーク。
Javaで実装されており、H2OのWeb GUIまたはR、Pythonからアクセス可能。
自動機械学習機能(AutoML)があり、最適なモデルを自動で選択。
scikit-learn:
Pythonでの機械学習プロジェクトにおいて広く採用されているライブラリ。
Gradient Boosting Classifierなど、シンプルで効果的なGBDTモデルを提供。
簡潔なAPIと豊富なドキュメントが利用を容易にしますが、大規模データや分散処理はサポート外。
バギング のサンプリング方法
バギング(Bootstrap Aggregatingの略)は、機械学習におけるアンサンブル学習の一種で、特にランダムフォレストなどの決定木ベースのモデルにおいて広く用いられる手法です。バギングの目的は、モデルのバリアンスを減少させることで、過学習を防ぎながらモデルの汎化能力を向上させることにあります。
バギングのサンプリング方法
バギングのサンプリング方法は、「ブートストラップ」という統計学の手法を用います。ブートストラップサンプリングは以下のように行われます。
元のデータセットのサイズを保持:
元の訓練データセットから、同じサイズのサンプルをランダムに選択します。この過程では、一つのデータが複数回選ばれることがあります(置き換えを伴うサンプリング)。置き換えを伴うランダムサンプリング:
各バギングのイテレーションで、訓練データセットからランダムにデータを選択し(抽出されたデータを元に戻して再度選択可能)、新たなサブセット(ブートストラップサンプル)を生成します。このサンプルは元のデータセットと同じサイズですが、一部のデータが複数回現れ、一部は含まれない場合があります。モデルの訓練:
生成された各ブートストラップサンプルに対して独立してモデル(通常は決定木)を訓練します。これにより、データの異なる側面を捉えた複数のモデルが得られます。予測の集約:
分類問題の場合は多数決(各モデルの予測の中で最も多いクラスが最終的な予測結果となる)、回帰問題の場合は平均(各モデルの予測の平均値が最終的な予測結果となる)により、全モデルの予測を集約します。
バギングの利点
バリアンスの削減:
複数のモデルが異なるサブセットで訓練されるため、個々のモデルの過学習が互いに打ち消し合い、全体としてのモデルのバリアンスが減少します。堅牢なモデル:
バギングはデータのランダムな側面を捉えるため、外れ値やノイズに対してより堅牢です。並列計算:
各モデルの訓練は独立しているため、バギングは並列処理に適しており、計算資源を効率的に活用できます。
バギングは、単一モデルに比べてより安定した予測を提供するため、特に決定木のように高バリアンスなモデルに有効です。
ブースティング
ブースティングは、弱い学習アルゴリズムを複数組み合わせて、強い学習アルゴリズムを作り出すアンサンブル手法の一つです。この手法は、一連の予測モデル(通常は決定木)を逐次的に訓練し、前のモデルが間違えた部分に重点を置いて次のモデルを改善していきます。
特徴
逐次的なプロセス:
ブースティングはモデルを並列ではなく逐次的に訓練します。各ステップで新しいモデルは前のモデルの誤りを修正することに焦点を当てます。誤分類への焦点:
誤って分類されたデータポイントに次第に重みを加え、それらを正しく分類することに重点を置いてモデルを調整します。低バリアンスと高バイアス:
ブースティングは低バリアンスで高バイアスのモデルを生成し、過学習のリスクが比較的低いですが、適切な停止条件やパラメータ調整が求められます。
目的
性能向上:
個々の弱い予測モデルよりもはるかに高い精度を持つ強力な予測モデルを生成すること。誤りの修正:
連続する学習プロセスを通じて、前のモデルが誤分類したデータに対して次のモデルが改善を試みること。
メリット
高い精度:
ブースティングは一般的に高い分類精度を達成します。特に、AdaBoostやGradient Boostingのようなアルゴリズムは多くの標準データセットで非常に効果的です。過学習のリスク低減:
逐次的な学習と重み付けの適応により、過学習への耐性が増します。柔軟性:
分類だけでなく回帰問題にも適用可能で、異なる種類のデータと損失関数に対応することができます。
デメリット
計算コスト:
逐次的な学習プロセスは計算資源を多く消費し、特にデータセットが大きい場合やモデル数が多い場合は時間がかかることがあります。パラメータの調整:
ブースティングアルゴリズムには複数の重要なパラメータ(学習率、モデルの数など)があり、これらのパラメータのバランスを適切に調整する必要があります。ノイズと外れ値の影響:
ブースティングは誤って分類されたデータに重みを加えるため、ノイズが多いデータや外れ値に弱い場合があります。
ブースティングは、適切に適用されれば、多くの予測タスクにおいて卓越した
パフォーマンスを発揮する強力なツールですが、その複雑性と計算コストも考慮する必要があります。
アンサンブル手法の比較
ンサンブル手法は、複数の学習アルゴリズムを組み合わせることで、単一のモデルよりも優れた予測性能を達成する方法です。以下は、代表的なアンサンブル手法であるバギング、ブースティング、スタッキングの比較一覧表です。
詳細な解説
バギング(Bootstrap Aggregating)
バギングは、訓練データセットからランダムに複数のサブセットを生成し、各サブセットで個別のモデルを訓練します。最終的な予測は、これらのモデルの予測結果を平均化(回帰)または多数決(分類)によって決定します。ランダムフォレストはバギングの一例で、多数の決定木を組み合わせたものです。
ブースティング
ブースティングは、複数の弱い学習モデルを組み合わせて強い学習モデルを作成します。最初のモデルが学習した後、そのモデルの誤りに基づいて次のモデルの学習が行われます。このプロセスを繰り返すことで、全体としてのモデルの誤差を小さくしていきます。各モデルは重み付けされ、これによりより重要なモデルに大きな影響力を与えます。
スタッキング
スタッキングは、異なるモデルからの予測結果を新たな「メタモデル」の入力として使用します。このメタモデルが、元のモデルの予測を踏まえて最終的な予測を行います。
ベイズの定理の式
ベイズの定理は以下の式で表されます:
P(A | B) = (P(B | A) * P(A)) / P(B)
ここで、
P(A∣B) は事象 B が与えられた条件下での事象 A の条件付き確率です(事後確率)。
P(B∣A) は事象 A が与えられた条件下での事象 B の条件付き確率です。(尤度)
P(A) は事象 A の事前確率です。
P(B) は事象 B の周辺確率(全確率)で、すべての可能な方法で B が発生する確率です。
式の解説
この式は、事象 B が発生したことが観測された後に、事象 A の確率がどのように変化するかを示します。この更新された確率(事後確率)は、事象 A が事象 B を引き起こす「尤もらしさ」(P(B∣A)と、事象 A の事前の発生確率(P(A)の積に比例します。分母の P(B)は、全ての可能な A の事象にわたる P(B∣A)×P(A)の合計(全確率の法則による)で、この値で正規化することで、確率の総和が1になるようにします。
尤度:確率論における事象の起こりやすさを表す指標
尤度(ゆうど、 likelihood)は、確率論における概念で、ある仮説が真であると仮定したときに、観測されたデータが起こる確率を表します。別の言い方をすれば、尤度とは、あるデータが観測されたときに、そのデータを説明できる仮説の妥当性を表す指標と言えます。
代表的なモデル解釈手法
機械学習モデル、特にディープラーニングや複雑なアンサンブルモデルはしばしば「ブラックボックス」と見なされます。これらのモデルの予測や決定を解釈するために、いくつかの手法が開発されています。以下は、代表的なモデル解釈手法とそれらが発表された年の一覧表です。
各手法の詳細
LIME:
非常に複雑なモデルでも、個別の予測に対して「なぜこの予測結果になったのか」という質問に答えることができます。個々のインスタンスに対して単純な局所的なモデルを生成し、解釈可能な結果を提供します。
SHAP:
SHAP値は、ある特徴がモデルの予測に与える平均的な寄与を測定します。これにより、モデル全体を通じて特徴の影響を理解するのに役立ちます。
Integrated Gradients:
個々の予測に対して、各入力特徴がどの程度影響を与えたかを数値で示します。特にディープニューラルネットワークで有効です。
Partial Dependence Plots (PDP):
特定の一つまたは二つの特徴に着目し、他の特徴を平均化することで、その特徴が目的変数に与える影響を視覚的に示します。
Counterfactual Explanations:
「もしXがYだったら、予測はZになる」という形式で、予測結果を変更するための最小限の変更点を提示します。
Feature Importance:
これは多くのモデルに組み込まれている標準的な機能で、特徴の重要性をランク付けすることで、どの入力が最も予測に貢献しているかを示します。
これらの手法は、モデルの予測を理解しやすくするために重要であり、特に法規制遵守や倫理的な観点からモデルの判断基準を説明する必要がある場合には不可欠です。
主成分分析:詳細解説
1. 主成分分析の定義と目的
主成分分析(PCA)は、相関のある多数の変数から、相関のない少数で全体のばらつきを最もよく表す主成分と呼ばれる変数を合成する多変量解析の一手法です。 データの次元を削減するために用いられます。
簡単に言うと、たくさんの変数を持っているデータを、より少ない数の変数で表現する方法です。 例えば、身長、体重、体脂肪率などの体格に関する変数がたくさんある場合、主成分分析を使って、これらの変数を「体格の大きさ」と「体脂肪の割合」という2つの変数にまとめることができます。
主成分分析の目的は、以下の通りです。
データの理解を容易にする: 多数の変数から主要な情報を抽出し、データの本質を把握しやすくする
データの可視化を容易にする: 次元削減により、データを低次元に投影し、グラフなどで可視化しやすくする
ノイズの除去: 主要な情報以外のノイズを除去し、データの精度を向上させる
次元削減による計算量の削減: 機械学習などのアルゴリズムにおいて、データの次元が高いと計算量が多くなります。主成分分析によって、データの次元を削減することで、計算量を削減することができます。
2. 主成分分析の手順
主成分分析の手順は以下の通りです。
データの前処理: データの欠損値や異常値を処理し、標準化を行います。
共分散行列または相関行列の計算: データの分散と共分散、または相関関係を表す行列を計算します。
固有値と固有ベクトルの計算: 共分散行列または相関行列の固有値と固有ベクトルを計算します。
主成分の選択: 固有値の大きい順に固有ベクトルを選び出し、主成分とします。
主成分得点の計算: 各データ点について、主成分に対する投影値を計算します。
3. 主成分分析の利点と欠点
利点
データの理解を容易にする
データの可視化を容易にする
ノイズの除去
次元削減による計算量の削減
欠点
情報の損失:主成分分析によって、データの一部情報が失われてしまいます。
解釈の困難さ:主成分が何を意味しているのか、解釈が難しい場合があります。
4. 主成分分析の具体的な応用例
主成分分析は、様々な分野で応用されています。 以下に、いくつかの例を挙げます。
マーケティング: 顧客の属性や購買行動に関するデータを分析し、顧客のセグメント化やターゲティングを行うことができます。
金融: 株価などの金融データの分析を行い、リスク管理やポートフォリオの構築を行うことができます。
医学: 遺伝子発現データなどの医療データを分析し、病気の原因や治療法の開発を行うことができます。
工学: 画像認識や音声認識などの分野で、特徴量抽出に使用することができます。
主成分分析における主成分の相関はどうなるか?
主成分分析(PCA)における主成分同士の相関について説明します。主成分分析の目的の一つは、多次元データセットの次元を削減し、データの構造をよりシンプルな形で表現することです。このプロセスでは、データの分散が最大となる方向を見つけ出し、それらの方向(主成分)にデータを射影します。
主成分の相関
主成分分析における主成分は、それぞれがデータセットの異なる分散の方向を捉えています。PCAの基本的な性質として、主成分同士は相互に無相関になります。これは、主成分がデータの共分散行列の固有ベクトルに基づいて計算されるためです。共分散行列の固有ベクトルは直交する性質を持っており、これによって主成分は互いに直交し、無相関となります。
相関が0になる理由
直交性と無相関性:数学的に、固有ベクトル同士は直交します。直交するベクトルに基づいて導出される主成分は、それぞれが直交座標軸の役割を果たすため、相互に無相関になります。
分散の最大化:PCAでは、最初の主成分がデータの分散を最大にする方向を捉え、次の主成分はそれに直交する方向の中で分散を最大にする方向を捉えるというプロセスを繰り返します。この方法により、各主成分は他の成分と無相関の状態で分散を捉えることができます。
応用上の意味
主成分間の無相関性は、データの分析や解釈において重要な意味を持ちます。主成分同士が無相関であることにより、それぞれの成分が独立した情報を持つと考えることができ、多次元データセットの理解や次元削減を行いやすくなります。また、この性質により、データの可視化や、特定の方向の分散を無視することでノイズを減らすことも可能になります。
まとめ
主成分分析において、主成分同士は互いに無相関となります。これは、各主成分がデータの異なる独立した情報を捉えているためであり、PCAが効果的な次元削減ツールである理由の一つです。この性質は、PCAを使用する際の重要な利点となります。
深層学習をわかりやすく
深層学習(Deep Learning)は、機械学習の一分野であり、特に複雑なデータ構造をモデル化する能力で知られています。この技術は、人間の脳の動作にヒントを得た人工ニューラルネットワーク(Artificial Neural Networks)を使用して、大量のデータから学習することが特徴です。
基本概念
ニューラルネットワークの構造:
入力層(Input Layer):データを受け取る層です。
隠れ層(Hidden Layers):一つ以上存在し、データの複雑な特徴を抽出します。層が深いほど(多いほど)、ネットワークはより高度な特徴を学習できます。
出力層(Output Layer):最終的な予測や分類結果を出力します。
活性化関数(Activation Function):
ニューロンの出力を決定するための非線形関数。例えば、ReLU(Rectified Linear Unit)、シグモイド(Sigmoid)、ソフトマックス(Softmax)などがあります。
損失関数(Loss Function):
モデルの予測が実際のデータからどれだけ離れているかを測定する関数。例えば、二乗誤差、交差エントロピーなどがあります。
最適化アルゴリズム(Optimizer):
損失関数を最小化するためにモデルの重みを更新する方法。例えば、SGD(Stochastic Gradient Descent)、Adam(Adaptive Moment Estimation)などがあります。
深層学習の特徴
特徴抽出の自動化:
深層学習モデルは、生データから自動的に有用な特徴を抽出し、これを利用して学習します。これにより、手作業による特徴エンジニアリングの必要性が減少します。柔軟性と汎用性:
画像認識、自然言語処理、音声認識など、多岐にわたる問題に適用可能です。大量のデータと計算資源を要求:
深層学習は、大規模なデータセットと高い計算リソースを必要とすることが多いです。
応用例
画像認識:
畳み込みニューラルネットワーク(CNN)を使用して、画像内のオブジェクトを認識します。自然言語処理(NLP):
リカレントニューラルネットワーク(RNN)やトランスフォーマーモデル(例:BERT、GPT)を使用して、テキストデータの意味を解析します。強化学習:
エージェントが環境からのフィードバックを基に最適な行動を学習します。例えば、AlphaGoが有名です。
結論
深層学習は非常に強力な技術であり、複雑な問題を解決するための強い能力を持っていますが、適切なデータと計算資源の確保が成功の鍵です。継続的な研究と技術の進化により、その応用範囲と効率性はさらに向上しています。
積層オートエンコーダで利用する活性化関数
積層オートエンコーダ(Stacked Autoencoder)は、入力データを効率的に圧縮・再構成するために使用される深層学習モデルの一種です。このモデルは、複数の隠れ層を持つオートエンコーダを積み重ねることで構成され、データの重要な特徴を抽出することが目的です。積層オートエンコーダで利用される活性化関数は、各層のニューロンの出力を決定し、非線形性を導入する重要な役割を果たします。以下は、一般的に使用される活性化関数の一覧とその特徴を比較した表です。
| シグモイド(Sigmoid)
特徴 | 出力が0から1の範囲。シグナルを平滑に変換します。
利点 | 勾配消失問題に直面しがちだが、出力が確率として解釈可能。
制限事項 | 勾配消失問題が発生しやすく、学習が遅くなることがある。 |
| 双曲線正接(Tanh)
特徴 | 出力が-1から1の範囲。シグモイドよりも広範囲の出力を提供します。
利点| ゼロ中心化(出力が正負に分布)であるため、学習が効率的。
制限事項 | シグモイドと同様に勾配消失問題を引き起こす可能性がある。 |
| ReLU(Rectified Linear Unit)
特徴 | 正の入力に対してはそのまま出力し、負の入力に対しては0を出力します。
利点 | 勾配消失問題が少なく、計算効率が良い。
制限事項 | 負の入力で勾配が0になるため、ニューロンが「死ぬ」可能性がある。 |
| Leaky ReLU
特徴 | ReLUと似ていますが、負の入力に対しても非常に小さい正の勾配を許可します。
利点 | ReLUの「死んだニューロン」問題を部分的に解決。
制限事項| ReLUに比べて計算コストがわずかに高い。 |
| ELU(Exponential Linear Unit)
特徴 | 負の入力に対して飽和しない小さな正の値を出力し、正の入力に対してはReLUと同様に動作します。
利点 | 勾配消失問題を軽減し、出力の平均がゼロに近くなり学習が安定。
制限事項 | 計算コストがReLUやLeaky ReLUより高い。 |
| Swish
特徴 | ( f(x) = x \cdot \text{sigmoid}(\beta x) ) の形式で、より柔軟な非線形関数。
利点 | ReLUよりも性能が良い場合がある。
制限事項 | 研究が進行中であり、すべてのケースでの効果が確立されていない。 |
活性化関数の選択
積層オートエンコーダにおける活性化関数の選択は、特定のタスクやデータの性質に応じて行う必要があります。例えば、勾配消失問題を避けたい場合はReLU系の関数が推奨されますが、出力が確率として解釈される必要がある場合はシグモイドやソフトマックスを選択することが適切です。また、ネットワークの学習率や他のハイパーパラメータとの相互作用も考慮する必要があります。
活性化関数が分類問題や回帰問題にどのように適しているかを評価する際、その関数が出力する値の範囲と特性を考慮することが重要です。以下は、主要な活性化関数が分類問題や回帰問題にどのように適しているかについての概要です。
1. シグモイド(Sigmoid)
分類問題に適している: シグモイド関数は、出力が0から1の範囲にあるため、二値分類問題において特に有効です。出力を確率として解釈できるため、例えばロジスティック回帰モデルなどで使用されます。
回帰問題には適していない: 出力が限定された範囲に制限されるため、連続値を扱う一般的な回帰問題には適していません。
2. 双曲線正接(Tanh)
分類問題に適している: 出力が-1から1の範囲で、特にマルチクラス分類問題で有効です。また、出力がゼロ中心化されているため、学習プロセスが安定することがあります。
回帰問題に適している: 出力が連続的であるため、特に出力値が-1から1の範囲にある回帰問題に適しています。
3. ReLU(Rectified Linear Unit)
分類問題に適している: 非線形性を提供しつつ計算効率が良いため、ディープニューラルネットワークの隠れ層で広く使用されています。
回帰問題に適している: ReLUは正の無限大に向かう非飽和性を持つため、連続値を出力する一般的な回帰問題で良く使われます。
4. Leaky ReLU
分類問題に適している: ReLUと同様に、分類問題で効果的に機能します。
回帰問題に適している: 負の入力に対しても小さい勾配を保持することができるため、ReLUよりも回帰問題での「死んだニューロン」の問題を減少させます。
5. ELU(Exponential Linear Unit)
分類問題に適している: ReLUやLeaky ReLUと同じく、分類問題に広く用いられます。
回帰問題に適している: 負の値に対しても飽和しない特性があり、より柔軟な回帰モデルの構築が可能です。
6. Swish
分類問題に適している: ReLUに比べて性能が向上することが報告されており、様々なディープラーニングアーキテクチャで利用されています。
回帰問題に適している: ReLUの代替として利用可能で、より複雑な非線形パターンを捉える能力があります。
これらの活性化関数はそれぞれ独自の利点と制限があるため、特定のアプリケーションや問題に応じて適切なものを選択することが重要です。一般に、多くのモデルでは隠れ層でReLU系の関数が使われることが多く、出力層では問題の種類(分類か回帰か)に応じてシグモイドやソフトマックス、恒等関数などが選択されます。
分類問題において積層オートエンコーダー(Stacked Autoencoder)を使用してラベル出力を行うためには、最終的な出力層に特定の活性化関数を持つ層を追加する必要があります。この出力層は、クラスラベルに対応する確率を出力するように設計されます。
出力層の設計
出力層のニューロン数:
出力層のニューロンの数は、分類したいクラスの数に等しく設定します。たとえば、10クラス分類問題の場合、出力層には10個のニューロンを持つことになります。
活性化関数:
多クラス分類の場合: ソフトマックス(Softmax) 活性化関数を使用します。これにより、各クラスに対する予測確率を出力し、全クラスの確率の合計が1になるようにします。
二値分類の場合: 出力層には1つのニューロンを使用し、シグモイド(Sigmoid) 活性化関数を用いて、そのニューロンの出力を0から1の間の値(クラス1に属する確率)として扱います。
積層オートエンコーダーの改造
積層オートエンコーダーは本来、データの圧縮と再構成に用いられる非監督学習モデルですが、分類タスクに適用するためには次のような改造が必要です。
特徴抽出器としての使用: オートエンコーダーのエンコーダ部分を用いて入力データから有用な特徴を抽出し、その特徴を分類器の入力として利用します。
分類層の追加: 抽出された特徴を入力とする分類層(出力層)をネットワークに追加します。この層は上述したように設計され、最終的なクラス予測を行います。
学習プロセス
事前学習: オートエンコーダーの各層を個別に訓練して、効率的な特徴抽出器を形成します。
微調整: 全体のネットワーク(エンコーダ部分と新たに追加した分類層)をエンドツーエンドで再学習し、分類精度を最大化します。
このように設計と学習を行うことで、積層オートエンコーダーは分類問題にも適用可能となり、深層学習における強力なツールとして機能します。
CUDAの説明
CUDA(Compute Unified Device Architecture)は、NVIDIAが開発したプログラミングモデルおよび計算プラットフォームです。CUDAを使用することで、開発者はNVIDIAのGPU(Graphics Processing Unit)上で高度な計算処理を効率的に実行することができます。これにより、特に大規模な数値計算、データ処理、機械学習などの分野で顕著なパフォーマンス向上が見られます。
CUDAは、C、C++、およびFortranなどの一般的なプログラミング言語に対応したAPIを提供し、GPUの強力な並列処理能力を利用するための直感的な手段を提供します。開発者は通常のCコードに少しの修正を加えることで、数千のスレッドを持つGPU上での並列処理を実現できます。
CUDAと類似の技術
以下はCUDAと機能が類似している代表的な技術やプラットフォームの一覧とその比較です。
| 技術名 | 開発者/提供者 | 説明 | CUDAとの主な違い |
|---------------------|---------------------|--------------------------------------------------------------------|---------------------------------------------------------------|
| OpenCL | Khronos Group | オープンスタンダードで、多種多様なプロセッサ(GPU、CPUなど)上での並列計算を可能にするプログラミングフレームワーク。 | ハードウェア非依存で、より広範なデバイスで使用可能。CUDAより汎用性が高いが、特定のNVIDIA GPUでの最適化は劣る可能性がある。 |
| DirectCompute | Microsoft | Windows向けのGPUコンピューティングAPI。DirectXの一部。 | Windowsプラットフォーム専用。CUDAよりも一般のPCユーザーに向けたAPI。 |
| Metal for Compute | Apple | Appleのデバイス用の低レベル・高性能のグラフィックスおよび計算API。 | Appleのデバイス限定。CUDAはNVIDIA GPU専用のため、プラットフォームが異なる。 |
| SYCL | Khronos Group | C++ベースのシングルソースプログラミング標準で、OpenCLの抽象レイヤーを提供。 | クロスプラットフォーム対応で、より高レベルの抽象化を提供。CUDAはNVIDIA専用の低レベルAPI。 |
CUDAの利点と制限
利点:
高度なNVIDIA GPUでの計算処理の最適化が可能。
リアルタイムでの大規模計算が可能になり、科学計算やAI、ビッグデータ分析などの分野での応用が広がる。
GPUリソースを最大限に活用し、パフォーマンスを向上させるための豊富なツールとライブラリが提供される。
制限:
NVIDIAのGPUに限定されるため、他のハードウェアベンダーのデバイスでは使用できない。
高度なプログラミングスキルとGPUアーキテクチャへの理解が求められる。
CUDAは、NVIDIA GPUを使用する開発者にとって強力な
ツールですが、その使用は特定のハードウェアに依存するため、プロジェクトのニーズに応じて適切な技術を選択することが重要です。
機械学習モデルのパラメータを最適化するための一般的な手法
機械学習モデルのパラメータを最適化する手法は多岐にわたり、それぞれの手法はモデルの学習プロセスにおいて特定の側面を改善するために設計されています。以下は、機械学習モデルのパラメータを最適化するための一般的な手法の一覧です。
1. 勾配降下法(Gradient Descent)
説明: モデルの損失関数の勾配を計算し、その勾配が示す方向にパラメータを更新することで、損失を最小化します。
適用: 幅広いモデルに使用可能で、特に線形回帰やロジスティック回帰などのシンプルなモデルに効果的。
2. 確率的勾配降下法(Stochastic Gradient Descent, SGD)
説明: 勾配降下法の一種で、訓練データの一部のみを使用して勾配を計算し、より高速にパラメータを更新します。
適用: ニューラルネットワークや、大規模なデータセットを扱う場合に有効。
3. ミニバッチ勾配降下法(Mini-batch Gradient Descent)
説明: SGDと勾配降下法の中間に位置し、ミニバッチと呼ばれる小さなデータのグループを使用して勾配を計算します。
適用: バッチ処理とリアルタイム処理のバランスが求められる状況で便利。
4. モーメンタム(Momentum)
説明: 勾配の更新に前回の更新を加味することで、勾配の方向が安定し、より速く最適な解に収束します。
適用: 深層学習モデルでよく使用され、特に平坦な損失曲線を持つ問題で効果的。
5. アダム(Adam)
説明: モーメンタムと適応学習率を組み合わせたアプローチで、各パラメータに対して個別の学習率を調整します。
適用: 広範囲の問題で効果的で、特にディープラーニングモデルで広く使用されています。
6. RMSprop(Root Mean Square Propagation)
説明: 学習率を適応的に調整し、過去の勾配の二乗平均を使用して各ステップの学習率を更新します。
適用: ニューラルネットワークの訓練で効果的で、特に不規則なデータ分布に対応する場合に有用。
7. 学習率スケジューリング
説明: 学習の進行に合わせて学習率を段階的に減少させることで、より細かいパラメータ調整を可能にします。
適用: ほぼすべての最適化アルゴリズムに適用可能で、特に収束に時間がかかる大規模なモデルに効果的。
これらの最適化手法は、機械学習モデルの訓練を効率化し、より高い性能を達成するために重要です。各手法は特定のシナリオやモデルの要件によって選ばれ、時には複数の手法を組み合わせて使用されることもあります。
ランダムサーチとグリッドサーチの手法
モデルのハイパーパラメータを選択する際によく使われる二つの方法、ランダムサーチ(Random Search)とグリッドサーチ(Grid Search)は、どちらもパラメータの最適な組み合わせを見つけ出すための探索手法ですが、アプローチには大きな違いがあります。
グリッドサーチ(Grid Search)
グリッドサーチは、ハイパーパラメータの各組み合わせを徹底的に試す方法です。具体的には、各パラメータに対して試したい値のリストを設定し、これらのリストから生成されるすべての可能な組み合わせについてモデルを訓練して評価します。
特徴
徹底性: 全てのパラメータ組み合わせを試すため、最適な組み合わせを見逃すことがありません。
計算コスト: パラメータの数と値のリストが大きくなると、試すべき組み合わせの数が指数関数的に増加し、計算に多大な時間が必要となります。
使いやすさ: 設定が直感的で、特にパラメータの候補が少ない場合に適しています。
ランダムサーチ(Random Search)
ランダムサーチは、パラメータ空間内のランダムな組み合わせを選択してモデルを評価する方法です。グリッドサーチと異なり、すべての可能な組み合わせを試すのではなく、設定された試行回数に基づいてランダムに選ばれた組み合わせで評価を行います。
特徴
効率性: 高次元のパラメータ空間でも効率的に探索でき、計算資源を節約できます。
カバレッジ: パラメータ空間の広範囲を探索できるため、予期しない良い組み合わせを見つける可能性があります。
柔軟性: 連続的なパラメータに対しても、均一に探索することができます。
比較
効率: ランダムサーチは、同じ計算時間でより多くの異なる組み合わせを試せるため、特にパラメータ空間が広い場合には効率的です。
最適性: グリッドサーチは、与えられた値の中で最適な組み合わせを見つけ出す可能性が高いですが、計算コストが非常に高いです。
適用性: 小規模なパラメータ空間ではグリッドサーチが有効ですが、パラメータが多く、その範囲が広い場合はランダムサーチが有効です。
どちらの手法も一長一短があり、使用する際は問題の性質、パラメータの数と範囲、計算リソースなどを考慮に入れて選択することが重要です。
XavierとHEについて
Xavier(グロロット)初期化とHe初期化は、ニューラルネットワークの重みを初期化するための手法です。これらの初期化手法は、特にディープニューラルネットワークを訓練する際に重要で、勾配消失や勾配爆発の問題を軽減するのに役立ちます。
Xavier初期化
概要: Xavier初期化(またはGlorot初期化とも呼ばれる)は、重みを一様分布または正規分布からランダムに初期化し、バイアスは0に初期化します。この手法は、特に活性化関数がtanhやシグモイドの場合に適しています。
目的: Xavier初期化は、層間での入力の分散を保持し、勾配消失や勾配爆発を防ぐことを目的としています。
Xavier初期化
Xavier初期化(またはグロロット初期化)は、2010年にXavier GlorotとYoshua Bengioによって提案されました。この初期化方法は、各層の入力と出力ユニットの数に基づいて、重みを適切にスケーリングすることにより、活性化関数を通じての情報の流れを最適化します。
特徴
均一または正規分布: 重みは中心が0で、分散が ( \frac{1}{n_{\text{in}}} ) (均一分布の場合)または ( \frac{2}{n_{\text{in}} + n_{\text{out}}} ) (正規分布の場合)の分布からランダムに抽出されます。ここで、( n_{\text{in}} ) は入力ユニットの数、( n_{\text{out}} ) は出力ユニットの数です。
適用性: シグモイドやハイパボリックタンジェントなどのS字型活性化関数に特に適しています。
He初期化
He初期化は、2015年にKaiming Heらによって提案されました。これはReLU(Rectified Linear Unit)活性化関数のために特別に設計された初期化方法で、Xavier初期化の考え方を拡張し、ReLUの特性を考慮に入れています。
He初期化
概要: He初期化(またはKaiming初期化とも呼ばれる)は、Xavier初期化の改良版で、ReLU活性化関数を使用する場合に適しています。この手法では、Xavier初期化で使用される分散の2倍の分散を持つ重みを初期化します。
目的: He初期化は、ReLUを使用する際の勾配消失問題を軽減し、深いネットワークの効率的な学習を可能にすることを目的としています
特徴
正規分布: 重みは平均0、標準偏差が ( \sqrt{\frac{2}{n_{\text{in}}}} ) の正規分布から抽出されます。
適用性: ReLU及びその変種(Leaky ReLUなど)に適しており、これらの活性化関数を使用する層で勾配消失の問題を軽減します。
比較と選択
活性化関数の選択: Xavier初期化はS字型活性化関数に適しており、He初期化はReLUを用いるネットワークで理想的です。
問題の回避: 両方の手法は、勾配消失や爆発の問題を緩和するために設計されていますが、He初期化はReLUでの学習を始める際に特に有効です。
これらの初期化手法は、ネットワークの深さが増すにつれて特に重要となり、訓練の安定性と収束速度を大きく向上させることができます。
バッチ正規化について
バッチ正規化(Batch Normalization)は、ディープニューラルネットワークの訓練を安定化し、加速するために用いられる手法です。2015年に Sergey Ioffe と Christian Szegedy によって提案されました。この手法は、内部共変量シフト(内部のデータ分布が学習の各ステップで変動する問題)を減少させることを目的としています。
基本的な概念
バッチ正規化は、ネットワークの各層における入力を正規化することで、層間でのデータ分布の変動を抑制します。具体的には、ミニバッチごとに層の入力を平均0、分散1に正規化し、その後、スケールとシフトのパラメータを用いて再スケーリングとシフトを行います。これにより、活性化関数への入力の分布が安定し、学習過程がより効率的かつ安定的になります。
バッチ正規化の利点
学習率の向上:
バッチ正規化により、より高い学習率を使用してもネットワークが収束しやすくなります。これは、各層の入力が安定することで勾配の消失や爆発が抑制されるためです。過学習の抑制:
バッチ正規化は軽度の正則化効果ももたらし、特に小さいデータセットでの過学習を減少させる効果があります。初期化への依存度の低減:
パラメータの初期値に対するモデルの依存度が低下します。
まとめ
バッチ正規化は、モデルの訓練を加速し、より堅牢にするために広く使われている重要な技術です。これにより、ディープラーニングモデルのパフォーマンスが大きく向上し、多くの最先端技術に不可欠なコンポーネントとなっています。
全結合層 (Fully Connected Layer)の目的、手法、役割、説明
全結合層(Fully Connected Layer、FC層)は、ディープラーニング、特にニューラルネットワークの構造において重要な役割を果たします。この層は、ネットワークの各層の出力を次の層の入力として完全に接続し、すべての入力がすべての出力に影響を与えるように設計されています。
目的
全結合層の主な目的は、入力特徴から複雑な関係やパターンを学習し、それらを利用して特定のタスク(分類、回帰、その他の予測タスク)に適した出力を生成することです。
手法
全結合層では、以下のような数学的手法が用いられます:
線形変換:
$$[
\mathbf{y} = \mathbf{Wx} + \mathbf{b}
]$$
ここで、$$(\mathbf{x})$$は入力ベクトル、$$(\mathbf{W})$$は重み行列、$$(\mathbf{b})$$はバイアスベクトル、$$(\mathbf{y})$$は層の出力ベクトルです。活性化関数:
全結合層の出力には通常、非線形活性化関数が適用されます。これにより、ネットワークは非線形の複雑なパターンを学習する能力を持ちます。よく使われる活性化関数にはReLU(Rectified Linear Unit)、シグモイド、tanh(双曲線正接)などがあります。
役割
全結合層の役割は多岐にわたりますが、主なものは以下の通りです:
特徴の統合:
全結合層は、畳み込み層(CNN)や再帰的層(RNN)などの前の層からの特徴を集約し、それらを組み合わせて新しい特徴を生成します。決定関数としての役割:
分類問題では、最終的な全結合層の後にソフトマックス関数が適用されることが多く、これによりクラス確率が算出されます。回帰問題の場合は、出力層が直接的な予測値を生成します。パターン認識:
訓練中に全結合層は入力データのパターンや関連性を把握し、これを基にして重要な特徴を学習します。
まとめ
全結合層はニューラルネットワークの非常に重要な部分であり、入力データの全体的な特徴を捉え、目的のタスクに適した出力を生成するための中核的な機能を担います。これにより、ニューラルネットワークは画像認識、音声認識、自然言語処理など、多くの分野で高い性能を発揮することができます。
全結合層 (Fully Connected Layer)の構造
全結合層(Fully Connected Layer、またはDense Layer)は、ニューラルネットワークの基本的な構造の一つであり、特にディープラーニングモデルにおいて重要な役割を果たします。この層は、すべての入力がすべての出力と完全に接続されていることが特徴です。
構造の詳細
全結合層の構造は比較的シンプルですが、非常に効果的な計算を行います。以下はその基本的な構成要素です:
入力ユニット:
全結合層には一つ以上の入力があります。これらは通常、前の層からの出力か、入力データ自体です。
入力は、特徴ベクトルや前の層の活性化ユニットからの出力として表されます。
重み(Weights):
すべての入力ユニットは、それぞれ出力ユニットへの独立した重みを持ちます。
これらの重みはモデルの訓練過程で調整され、データからパターンを学習します。
バイアス(Biases):
各出力ユニットには独自のバイアス値が加えられます。
バイアスはモデルの出力に定数項を追加し、活性化関数の動作範囲を調整します。
活性化関数:
各出力ユニットの線形結合(重み付き入力の合計にバイアスを加えたもの)は、活性化関数を通して非線形変換されます。
活性化関数にはReLU(Rectified Linear Unit)、シグモイド(Sigmoid)、双曲線正接(Tanh)などがあります。
出力ユニット:
全結合層の各ユニットは、すべての入力とその重みの線形結合を計算し、活性化関数を適用した後の値を出力として提供します。
処理フロー
具体的な処理ステップは次の通りです:
各入力ユニットに対して、それぞれ対応する重みを乗じる。
重み付けされたすべての入力の合計を計算し、それにバイアスを加える。
得られた合計値を活性化関数に通して、非線形の変換を行う。
変換された値が出力として次の層へ送られる、またはネットワークの最終出力となる。
全結合層はその単純な構造にも関わらず、複雑なデータの特徴を捉える能力を持っています。これにより、画像認識、自然言語処理、音声認識など、多様な応用が可能となっています。
全結合層 (Fully Connected Layer) の概要
全結合層は、ニューラルネットワークの中で、前後の層と密に全てのニューロンが接続されている層です。この層は、特に畳み込みニューラルネットワーク(CNN)の出力層でよく使用され、特徴マップを組み合わせて一次元の出力を生成する役割を持っています。
全結合層の目的と役割
高次元特徴の統合: 全結合層は、畳み込み層やプーリング層で抽出された高次元の特徴を統合し、最終的な出力(例えば、分類問題のクラスラベル)に変換します。
決定関数の実装: ネットワークの最終段階で、入力されたデータに対する決定(分類や回帰)を行います。この層は、学習可能な重みとバイアスを用いて入力を変換し、特定のタスクに対する予測を行います。
全結合層の手法
全結合層では、入力ベクトルに重み行列を乗算し、バイアスベクトルを加算することで、次の層への入力を生成します。このプロセスは、以下の式で表されます。
[ \text{出力} = (\text{入力} \times \text{重み}) + \text{バイアス} ]
この手法により、ネットワークは複雑な関数を学習し、様々なタスクに対応することが可能になります。
全結合層は、ニューラルネットワークにおいて非常に重要な役割を果たします。高次元の特徴を統合し、最終的な予測を行うことで、画像認識、自然言語処理、その他多くの分野での応用が可能になります。
CNNモデルの登場歴史
畳み込みニューラルネットワーク(CNN)は、主に画像認識と分析において広く使用される深層学習モデルの一種です。時間を経るにつれて、多くの画期的なCNNモデルが開発され、それぞれが異なるアーキテクチャの革新や特定の問題への適応を示しています。以下は、重要なCNNモデルの登場歴史を時系列順に示した表です。
| 年 | モデル名 | 主な特徴や貢献 |
|----|-----------------|-------------------------------------------------------|
| 1998 | LeNet-5 | 最初の実用的な畳み込みニューラルネットワーク。手書き数字認識に利用。 |
| 2012 | AlexNet | ImageNetコンペティションで高い性能を達成。深層学習の可能性を広く認識させた。 |
| 2014 | VGGNet | 畳み込み層とプーリング層を深く積み重ねたモデル。精度の向上に貢献。 |
| 2014 | GoogLeNet (Inception v1) | 「インセプションモジュール」の導入。計算資源の効率的な利用を実現。 |
| 2015 | ResNet | 「残差ブロック」の導入により、非常に深いネットワークの訓練を可能に。 |
| 2016 | Inception-v4 | Inceptionアーキテクチャの改良とResNetの概念の組み合わせ。 |
| 2017 | DenseNet | 各層から全ての後続層への接続を特徴とする。パラメータ効率と特徴再利用を改善。 |
| 2017 | MobileNet | モバイルやエッジデバイス向けに最適化。深度分離畳み込みを採用。 |
| 2018 | EfficientNet | スケーリング手法を用いて、効率的にモデルサイズを調整。性能と効率のバランスを最適化。 |
これらのモデルは、畳み込みニューラルネットワークがどのように進化してきたかの良い例です。各モデルは特定の課題を解決するために設計され、それぞれがコンピュータビジョン分野における新たな標準を設けました。例えば、ResNetは非常に深いネットワークの訓練を可能にし、EfficientNetはモデルの効率性を極限まで追求しました。これらの革新は、後続の研究や応用に大きな影響を与えています。
全結合層の構造と多層パーセプトロンの構造の類似点
全結合層(Fully Connected Layer)と多層パーセプトロン(Multilayer Perceptron, MLP)は、ニューラルネットワークの中で密接に関連しており、多くの構造的類似点を持っています。以下にその主な類似点を挙げます。
構造的類似点
層の接続性:
両者ともに、層内の各ニューロンが前の層のすべてのニューロンと接続されています(全結合)。この全結合の特性により、入力のすべての特徴が各層で処理されることになります。
線形変換と活性化関数:
全結合層と多層パーセプトロンの各層は、線形変換(重みとバイアスを使用)の後に非線形の活性化関数を適用します。この組み合わせによって、ネットワークは非線形なデータのパターンを学習する能力を持ちます。
学習可能なパラメータ:
両者は重み(Weights)とバイアス(Biases)を持ち、これらのパラメータは学習プロセス中に最適化されます。これにより、モデルはトレーニングデータに基づいてパターンを抽出し、学習します。
用途の多様性:
全結合層と多層パーセプトロンは、分類、回帰、特徴抽出など、多岐にわたるタスクに適用可能です。これは、層を通じて複雑な関数を近似できる能力に起因します。
主な違い
用語とコンテキスト:
「全結合層」は、一般に個々の層を指す用語で、特に畳み込みニューラルネットワーク(CNN)などで、最終的な出力前に特徴を集約するために使われます。
「多層パーセプトロン」は、複数の全結合層から構成されるネットワーク全体を指す用語で、特に単純な前進型(feedforward)ニューラルネットワークの一種です。
全結合層は、多層パーセプトロンを形成する基本的な構成要素の一つです。したがって、全結合層の連続した積み重ねが多層パーセプトロンを構成し、その強力な表現能力を生み出します。この構造的な類似性が、様々なデータ駆動タスクにおいて両者を非常に有用にしています。
Transformerの詳細説明
Transformerは、自然言語処理(NLP)の分野で革命的な影響を与えたアーキテクチャで、2017年にGoogleの研究者たちによって提案されました。その論文「Attention is All You Need」によって導入されたこのモデルは、従来のRNN(Recurrent Neural Network)やLSTM(Long Short-Term Memory)に代わるものとして登場しました。Transformerの最大の特徴は、シーケンスを処理する際にリカレンス(繰り返し)や畳み込みを使わず、全てをアテンション機構に依存する点です。
Transformerの主要コンポーネント
自己注意機構(Self-Attention):
自己注意機構は、シーケンス内の各要素が他のすべての要素とどのように関連しているかを学習します。このプロセスにより、モデルはデータの重要な部分に「注意」を集中させることができます。具体的には、入力された各単語(またはトークン)に対して、それが他の単語とどれだけ関連しているかを示す重みを計算します。
マルチヘッドアテンション:
自己注意機構を複数の「ヘッド」で並行して行います。これにより、モデルは異なる表現のサブスペースにおいて情報を捉えることができ、各ヘッドが異なる種類の関連性を捉えることが可能になります。
位置エンコーディング:
Transformerはリカレンスを使用しないため、単語の順序情報を別途提供する必要があります。位置エンコーディングは各入力トークンの位置情報を数学的にエンコードし、その情報をトークンの埋め込みに追加することでこの問題を解決します。
フィードフォワードニューラルネットワーク:
各アテンション層の後には、ポイントワイズのフィードフォワードニューラルネットワークが配置されます。これは、各位置の隠れ層表現に対して独立して適用される単純なニューラルネットワークです。
正規化と残差接続:
各サブ層(自己注意層やフィードフォワード層)の出力には残差接続が追加され、その後にレイヤー正規化が行われます。これにより、深いネットワークの訓練中に生じる可能性のある勾配の消失や爆発を防ぎます。
モデルのアーキテクチャ
Transformerモデルは、エンコーダとデコーダの二つの主要部分から構成されています。エンコーダは入力トークンの表現を生成し、デコーダはこの表現を使用して出力シーケンスを生成します。各エンコーダとデコーダは複数の同一の層で構成されており、それぞれがマルチヘッドアテンションとフィードフォワードニューラルネットワークを含んでいます。
用途
TransformerはNLPの幅広い応用に利用されており、機械翻訳、テキスト要約、感情分析など、多くのタスクで最先端の性能を発揮しています。また、GPTやBERTなどの事前訓練されたモデルは、Transformerを基にしており、多くの下流タスクで有効です。
Transformerの登場によって、NLPの分野におけるアプローチと性能が劇的に向上しました。このアーキテクチャは、高い並列化能力と効果的な長距離依存関係の捉え方が特徴です。
セグメンテーション技術の開発順
以下は、指定されたセグメンテーション技術を開発された順序に従って特徴をまとめた一覧表です。
Faster R-CNN (2015)
目的: オブジェクト検出
特徴: 地域提案ネットワーク(RPN)を導入し、高速なオブジェクト検出を実現。最大プーリングとROIプーリングを利用
適用: リアルタイムオブジェクト検出。
U-Net (2015)
目的: 医療画像セグメンテーション
特徴: エンコーダとデコーダの間にスキップ接続を持つ対称的な構造。少量のデータでも高い精度のセグメンテーションが可能。
適用: 生物医学的画像セグメンテーション。
SegNet (2015)
目的: 道路や建物などのセグメンテーション
特徴: エンコーダでのプーリングインデックスをデコーダで利用し、精度の高いアップサンプリングを実現。
適用: 都市景観のセグメンテーション。
DeepLab (2016)
目的: セマンティックセグメンテーション
特徴: Atrous ConvolutionとAtrous Spatial Pyramid Pooling (ASPP)を使用し、異なるスケールでの情報を捉える。
適用: 複雑なシーンのセグメンテーション。
PSPNet (2017)
目的: セマンティックセグメンテーション
特徴: ピラミッド型プーリングを利用し、異なるスケールのコンテキスト情報を集約。
適用: 道路標識、風景、医療画像などの詳細なセグメンテーション。
Mask R-CNN (2017)
目的: インスタンスセグメンテーション
特徴: Faster R-CNNに基づき、各検出されたオブジェクトに対してセグメンテーションマスクを生成。
適用: 高度なオブジェクト検出とピクセルレベルのセグメンテーション。
これらの技術は、それぞれ特定のタスクや要件に合わせて開発され、セグメンテーションの分野において重要な進歩をもたらしました。各技術の特徴を理解し、適用することで、多様なシナリオにおける精度の高いセグメンテーションが可能になります。
FastTextの派生元と派生先
fastTextは、自然言語処理の分野で広く用いられるテキスト分類と単語埋め込みのためのライブラリであり、FacebookのAI Research (FAIR) ラボによって開発されました。以下は、fastTextの派生元と考えられる技術および派生先の概要です。
派生元
Word2Vec
概要: Googleによって開発された、単語をベクトル空間に埋め込む技術。文脈に基づいた単語の類似性を捉えることができる。
関連性: fastTextはWord2Vecのアイデアを基にしており、Word2Vecが単語を単一のベクトルとして扱うのに対し、fastTextは単語をサブワード(n-gram)の集合として扱います。
GloVe (Global Vectors for Word Representation)
概要: スタンフォード大学によって開発された、単語の共起行列を利用した単語ベクトルの学習方法。
関連性: GloVeも単語埋め込みの先行技術の一つで、fastTextの開発に影響を与えた可能性があります。
派生先
fastText自体が非常に効果的な単語埋め込み手法として確立しており、その核となるアイデアはその後の多くの研究やアプリケーションに影響を与えていますが、特定の「派生先」技術というものは少ないです。しかし、以下のような分野での応用や改良が進んでいます。
言語モデルの改良
fastTextのサブワード情報を活用するアプローチは、新しい言語モデルや他の単語埋め込み手法にインスピレーションを与えています。
多言語および低リソース言語への応用
fastTextの技術は、多言語対応やリソースが限られた言語での自然言語処理タスクに適用され、言語間での単語埋め込みの転移学習に利用されています。
特定ドメインへの適用
fastTextのモデルは、特定のドメインやニッチな用途にカスタマイズされ、より専門的な用語やジャンルに適した単語埋め込みの生成に使われています。
fastTextの開発は、テキスト分類と単語のベクトル表現の分野における重要な進歩を代表しており、その効果的なアプローチは今後も広範な影響を与え続けるでしょう。
Tensorflowとは?
TensorFlowは、Googleによって開発されたオープンソースの機械学習ライブラリです。ディープラーニングや機械学習のための柔軟で強力なツールとして広く使用されており、数値計算をグラフベースで行うことができます。特に、データフローグラフを使用して複雑なネットワークを構築し、トレーニングし、デプロイすることが特徴です。
TensorFlowの主な特徴
データフローグラフ:
TensorFlowプログラムは、演算をノードとし、データ配列(テンソル)をエッジとするデータフローグラフを構築することにより表現されます。これにより、複雑な演算の依存関係と実行を効率的に管理できます。
柔軟性:
Python、C++、Javaなど複数の言語でAPIが提供されており、デスクトップ、サーバー、またはモバイルデバイスでの使用が可能です。さらに、多様なハードウェア(CPU、GPU、TPU)での実行をサポートしています。
スケーラビリティ:
小規模な研究から大規模な産業用アプリケーションまで、プロジェクトの規模に関わらず使用することができます。分散コンピューティングをサポートしているため、必要に応じて計算リソースを拡張できます。
自動微分機能:
機械学習モデルの訓練に必須の勾配計算を自動化できるため、開発者はモデルの設計に集中でき、複雑な微分演算を手動で行う必要がありません。
広範なライブラリとコミュニティ:
多くの標準的なニューラルネットワークが実装されているほか、画像認識、音声認識、自然言語処理など、多岐にわたるアプリケーションのための高水準API(例:TFX、TF-Lite、TensorFlow Hubなど)が提供されています。
エコシステムとサポート:
TensorFlowには、TensorBoardでの可視化ツールやTensorFlow Servingでのモデルのデプロイメント支援ツールなど、開発から運用までをサポートする豊富なツールが用意されています。
TensorFlowは、機械学習とディープラーニングの研究者や開発者にとって非常に価値のあるリソースであり、その用途は教育、医療、産業など多岐にわたります。オープンソースであるため、誰でも自由に使用し、必要に応じてカスタマイズすることが可能です。
numpy、pandas、pytorchの特徴
Numpy
Numpy(Numerical Pythonの略)は、Pythonで数値計算を効率的に行うための基本的なライブラリです。特に大規模な数値計算を行う際に必須とされる機能を提供しています。
主な特徴
多次元配列オブジェクト:
Numpyの中心的なデータ構造はndarray(n-dimensional array)で、同一タイプのデータを多次元配列として効率的に扱います。
放送機能(Broadcasting):
異なる形状の配列間で算術演算を行うことが可能です。これにより、異なるサイズのデータ構造間の操作が簡潔に記述できます。
包括的な数学関数ライブラリ:
線形代数、統計、フーリエ変換など、高度な数学演算をサポートしています。
C API:
CやC++など他の言語からNumpy機能を利用することができます。
パフォーマンス:
内部的にはCで実装されており、Pythonのリストよりも計算が高速です。
Pandas
Pandasは、Pythonでデータ分析を行うための高機能で柔軟なライブラリです。特にデータの操作や処理、分析を容易にするツールを提供しています。
主な特徴
データ構造:
主に二つのデータ構造を使用します: 1Dの「Series」と2Dの「DataFrame」。これらは多様なデータ型をサポートし、複雑なデータ操作と分析を可能にします。
データ操作のための広範なツール:
データの読み込み、書き出し、クリーニング、変換、リダクション、再形成、ピボット、スライシング、インデクシング、結合、マージ、グループ化などが行えます。
時間系列分析:
時系列データの生成、変換、操作、可視化を行う豊富な機能を持ちます。
欠損データの扱い:
自動的に欠損データを処理し、置換や削除を容易に行うことができます。
高度な分析機能:
統計分析や回帰分析などの複雑な分析をサポートしています。
PyTorch
PyTorchは、Facebookによって開発されたオープンソースの機械学習ライブラリで、特にディープラーニングアプリケーションに適しています。
主な特徴
動的計算グラフ:
PyTorchは「define-by-run」アプローチを採用しており、計算グラフが実行時に動的に構築されます。これにより、条件分岐やループなど複雑なアーキテクチャが容易に実装できます。
自動微分:
モデルを通じて自動で微分を計算する「Autograd」システムを提供し、ニューラルネットワークのバックプロパゲーションを簡
素化します。
Pythonicな設計:
PyTorchはPythonの機能をフルに活用し、直感的で使いやすいAPIを提供しています。
拡張性とモジュラリティ:
カスタム層や新しいモデルのタイプを簡単に作成でき、高度にモジュール化されています。
強力なGPU加速:
CUDAを通じてGPUを利用することで、計算を大幅に加速できます。
XAI、FAT、ELSI、RRIの意味
以下に、XAI、FAT、ELSI、RRIの各用語の意味と重要性について説明します。
XAI(Explainable Artificial Intelligence)
XAI(Explainable Artificial Intelligence)は、「説明可能な人工知能」を指します。これは、AIの決定や予測のプロセスを人間が理解できる形で説明する技術や手法のことを言います。XAIの目的は、AIシステムの透明性を高め、ユーザーがその動作を信頼しやすくすることです。特に、医療、金融、法執行などの重要な意思決定を伴う分野での利用が注目されています。
FAT(Fairness, Accountability, and Transparency)
FAT(Fairness, Accountability, and Transparency)は、「公平性、説明責任、透明性」を意味し、AIシステムの倫理的な設計と運用に関連する原則を指します。公平性は偏見や差別を排除すること、説明責任はAIの行動に対する責任の所在を明確にすること、透明性はAIのプロセスを開示し理解しやすくすることを目指しています。これらの原則は、信頼性の高いAIシステムを開発するために重要です。
ELSI(Ethical, Legal, and Social Implications)
ELSI(Ethical, Legal, and Social Implications)は、「倫理的、法的、社会的含意」と訳され、科学技術が社会に及ぼす影響を考慮する研究アプローチです。特に遺伝子研究やバイオテクノロジーの分野で始まりましたが、AIやデータ科学にも適用されています。このアプローチは、技術の進歩が個人や社会に及ぼす潜在的な影響を事前に評価し、適切なガイドラインやポリシーの策定を支援します。
RRI(Responsible Research and Innovation)
RRI(Responsible Research and Innovation)は、「責任ある研究とイノベーション」を意味し、研究やイノベーションが社会にとって望ましい結果をもたらすように設計、実施されるべきであるという考え方です。この枠組みは、研究活動が持続可能で包摂的で社会に受け入れられるものであることを目指しています。公共の利益を最大化し、不利益を最小化するための取り組みが含まれます。
これらの概念は、AI技術の開発と実装における倫理的、法的、社会的な課題に対処するために重要であり、より公正で透明で責任ある技術の利用を目指しています。
信用割当問題を解決する手法は?
信用割当問題(Credit Allocation Problem)に対処する手法としては、金融業界で広く用いられるいくつかのアプローチがあります。この問題の核心は、個人や企業が適切な信用枠を得られるように、適切な方法で信用リスクを評価し、信用枠を割り当てることです。以下はその主要な手法です。
1. ロジスティック回帰
概要: 伝統的な統計的手法で、信用スコアリングに広く使用されています。個々の借入者の特性に基づいて返済能力を予測するモデルを構築します。
利点: 理解しやすく、実装が容易で、結果の解釈が直感的です。
制限: 線形の境界しか扱えないため、より複雑な関係を捉えるのには限界があります。
ロジスティック回帰の学習
ロジスティック回帰のモデルを学習するには、与えられたデータからモデルのパラメータ(β0 と βi )を推定する必要があります。
ロジスティック回帰と最尤推定の関係
ロジスティック回帰と最尤推定は、密接な関係にあります。
ロジスティック回帰 は、二値分類 のための統計モデルです。二値分類とは、データを観測結果が2つのカテゴリーのいずれかに属するかどうかを分類するタスクです。
最尤推定 は、統計学における点推定方法の一つであり、与えられたデータからそれが従う確率分布の母数を推定する方法です。
最尤推定と呼ばれる方法を用いて、パラメータの値が与えられたデータを生成する確率が最大になるように、パラメータの値を推定します。
最尤推定のメリット:
理論的な根拠がある: 最尤推定は、確率論に基づいた理論的な根拠のある推定方法です。
計算しやすい: 最尤推定は、計算機を用いて比較的簡単に計算することができます。
最尤推定のデメリット:
非線形なモデルには適用できない: 最尤推定は、線形なモデルにしか適用できません。
局所解に陥る可能性がある: 最尤推定は、局所解に陥る可能性があります
2. 決定木とランダムフォレスト
概要: 決定木はデータを分割する一連の質問に基づいて構築され、ランダムフォレストは多数の決定木を組み合わせたアンサンブル学習です。
利点: 非線形なデータパターンにも対応可能で、特徴の重要性を把握しやすい。
制限: 過学習(特に決定木)のリスクがあり、パラメータのチューニングが必要です。
3. サポートベクターマシン(SVM)
概要: データクラス間の最大マージンを見つけることに焦点を当てた教師あり学習アルゴリズムです。
利点: 強力な分類能力を持ち、高次元のデータセットにも効果的です。
制限: パラメータの選択と計算コストが高いことが挑戦となります。
SVMにおけるスラック変数、カーネル法、カーネルトリックの働きについて詳しく説明します。
スラック変数の働き
スラック変数は、データがマージンや線形識別境界に対してどの位置にあるかを示す変数です。
スラック変数を導入することで、誤分類無しの条件を緩和することができます。
これにより、ある程度の誤分類を許容しつつ、より良い分類器を学習できるようになります。
スラック変数の値が大きいほど、その訓練データは分類境界から離れていることを意味します。
カーネル法の働き
カーネル法は、データを高次元の特徴空間に写像することで、非線形分離問題を線形分離問題に変換する手法です。
これにより、SVMの非線形分離能力が大幅に向上します。
カーネル関数を定義することで、陽な特徴マッピングを行う必要がなくなり、計算コストも大幅に削減できます。
カーネルトリックの働き
カーネルトリックは、カーネル関数を使って高次元特徴空間での内積計算を効率的に行う手法です。
これにより、SVMの非線形分離能力がさらに向上します。
代表的なカーネル関数には、線形カーネル、多項式カーネル、RBFカーネル、シグモイドカーネルなどがあります。
これらのカーネル関数を使うことで、SVMの非線形分離能力を高めることができます。
4. 人工ニューラルネットワーク
概要: 複数の層を持つネットワーク構造を通じて、複雑なパターンや非線形の関係を学習します。
利点: 大量のデータから複雑な特徴を学習でき、高い予測精度が期待できます。
制限: モデルの透明性が低く(ブラックボックス)、過学習に注意が必要です。
5. アンサンブルメソッド
概要: 複数の学習アルゴリズムを組み合わせて、より優れた予測モデルを構築します。例えば、ブースティングやバギングがあります。
利点: 個別のモデルよりもバイアスやバリアンスを低減でき、一般により堅牢な予測が可能です。
制限: 複雑で、計算コストが高くなる可能性があります。
これらの手法は、信用リスクを評価し、個々の借入者に適切な信用枠を割り当てるために使用されます。選
択する手法は、具体的なビジネス要件、データの種類、利用可能な計算リソースによって異なります。また、倫理的な考慮も重要であり、不公平な偏見が結果に影響を与えないように注意が必要です。
信用割当問題を解決する手法
信用割当問題は、ニューラルネットワークにおいて、各ノードのパラメータがどのように予測に役立っており、またどのパラメータをどう修正すれば精度が上昇するのかが分からないという問題です。これは従来の手法に比べニューラルネットワークのパラメータ数が多すぎることにより発生しましたが、誤差逆伝播法の登場により解決されました。
誤差逆伝播法は、ニューラルネットワークのパラメータを更新するためのアルゴリズムです。このアルゴリズムは、以下のステップで実行されます。
順伝播: 入力から出力までのネットワークを計算します。
誤差計算: 出力と正解ラベルとの誤差を計算します。
逆伝播: 誤差を各パラメータに伝搬します。
パラメータ更新: 各パラメータを誤差に基づいて更新します。
これらのステップを繰り返すことで、ネットワークのパラメータを最適化することができます。
誤差逆伝播法は、信用割当問題を解決する効果的な手法です。この手法を用いることで、各ノードのパラメータがどのように予測に役立っており、またどのパラメータをどう修正すれば精度が上昇するのかを明らかにすることができます。
誤差逆伝播法以外にも、信用割当問題を解決する手法はいくつかあります。
層別誤差逆伝播法: 各層の誤差を別々に計算し、各層のパラメータを更新する方法です。
逐次誤差逆伝播法: 1つのノードのパラメータを更新してから、次のノードのパラメータを更新する方法です。
注意機構: 各ノードが出力にどれだけ注意を払うかを制御する方法です。
これらの手法は、誤差逆伝播法と組み合わせて使用されることもあります。
まとめ
信用割当問題は、ニューラルネットワークの学習において重要な問題です。誤差逆伝播法などの手法を用いることで、この問題を解決することができます。
モデルフリー強化学習とモデルベース強化学習の手法を比較一覧
強化学習(RL)には、主に「モデルフリー」強化学習と「モデルベース」強化学習の二つのアプローチがあります。それぞれのアプローチは異なる特性を持ち、特定のシナリオやタスクにより適したものが異なります。以下の一覧表は、これら二つのアプローチの特徴とそれぞれの代表的な手法を比較しています。
特徴/手法
モデルフリー強化学習
モデルベース強化学習
定義
環境のモデルを明示的に学習せず、経験から直接最適なポリシーを学習します。
環境の動作を模倣するモデルを学習し、そのモデルを用いて最適なポリシーを学習します。
計算効率
通常、計算効率が高いが、最適なポリシーを見つけるために多くの試行錯誤が必要です。
モデルを用いることで効率的な学習が可能ですが、正確なモデルを構築するための計算コストが発生します。
サンプル効率
サンプル効率が低い傾向にあり、多くのインタラクションを必要とすることがあります。
サンプル効率が高く、少ないインタラクションで学習が進むことが多いです。
一般化能力
学習したポリシーは直接的な経験に基づくため、見たことのない状況への適応が難しい場合があります。
モデルを用いてシミュレーションを行うことができるため、新しい状況への適応が容易な場合があります。
代表的な手法
Q-learning, Sarsa, Deep Q-Networks (DQN)
Dyna-Q, モンテカルロツリー検索 (MCTS), PILCO
実用例
Atariゲーム、ロボットナビゲーション
自動運転車のシミュレーション、AIによる戦略ゲーム
長所
実装が比較的簡単で、具体的な環境モデルが不明な場合でも使用できます。
環境についての予測モデルを構築することで、効果的な計画が可能となり、事前のシミュレーションでの試行が可能です。
短所
学習に時間がかかり、エージェントが環境と多くのインタラクションを必要とするため、リアルタイムアプリケーションには不向きな場合があります。
環境モデルが不正確な場合、学習したポリシーの性能が大幅に低下する可能性があります。また、複雑な環境ではモデルの構築が困難です。
モデルフリーとモデルベースの強化学習の選択は、利用可能なデータ、必要とされる反応時間、タスクの複雑性、そして必要とされる一般化能力など、プロジェクトの具体的な要件に基づいて行うべきです。それぞれのアプローチにはメリットとデメリットがあり、目的に最も適したものを選ぶことが重要です。
モデルベース学習:詳細解説
モデルベース学習は、強化学習の一種であり、エージェントが環境と相互作用しながら最適な行動を学習する方法です。モデルベース学習では、まず環境モデルを学習し、そのモデルに基づいて行動計画を立て、計画に基づいて行動を実行します。
モデルベース学習の仕組み
モデルベース学習の仕組みは以下の通りです。
エージェントは、環境と相互作用しながら経験を収集します。
エージェントは、収集した経験に基づいて環境モデルを学習します。
エージェントは、環境モデルを用いて行動計画を立てます。
エージェントは、行動計画に基づいて行動を実行します。
エージェントは、行動の結果に基づいて環境モデルを更新します。
これらのステップを繰り返すことで、エージェントは環境モデルの精度を向上させ、より良い行動計画を立て、より良い行動を実行することができます。
モデルベース学習の特徴
モデルベース学習の特徴は以下の通りです。
モデルフリー学習に比べて効率的な学習: モデルベース学習では、環境モデルを用いて行動計画を立てるため、モデルフリー学習に比べて効率的に学習することができます。
複雑な環境への適応: モデルベース学習では、環境モデルを学習することで、複雑な環境にも適応することができます。
長期的な計画: モデルベース学習では、環境モデルを用いて長期的な計画を立てることができます。
モデルベース学習の課題
モデルベース学習には、以下の課題があります。
環境モデルの学習: 環境モデルの学習には、多くのデータと計算コストが必要となります。
環境モデルの精度: 環境モデルの精度が低い場合、行動計画も精度が低くなります。
不確実性への対応: モデルベース学習は、環境の不確実性に弱いという弱点があります。
モデルベース学習の拡張
モデルベース学習は、様々な方法で拡張されています。
ダイナミックプログラミング: ダイナミックプログラミングは、最適な行動計画を効率的に求めるための手法です。
モンテカルロ木探索: モンテカルロ木探索は、不確実な環境における行動計画を立てるための手法です。
階層型強化学習: 階層型強化学習は、複雑な環境における行動計画を立てるための手法です。
モデルベース学習の応用例
モデルベース学習は、様々なタスクに適用されています。
ロボット制御: ロボットの歩行、アーム制御
ゲーム: ゲームのエージェントの行動計画
自律走行: 自律走行車の経路計画
製造業: 製造工程の最適化
まとめ
モデルベース学習は、強化学習の一種であり、エージェントが環境と相互作用しながら最適な行動を学習する方法です。モデルベース学習は、モデルフリー学習に比べて効率的な学習、複雑な環境への適応、長期的な計画といった特徴を持ちますが、環境モデルの学習、環境モデルの精度、不確実性への対応といった課題もあります。モデルベース学習は、様々な方法で拡張されており、ロボット制御、ゲーム、自律走行、製造業など、様々なタスクに適用されています。
モデルフリー強化学習:詳細解説
モデルフリー強化学習は、強化学習の一種であり、エージェントが環境と直接的に相互作用しながら最適な行動を学習する方法です。モデルフリー強化学習では、環境モデルを学習せず、経験から直接的に行動と価値を学習します。
モデルフリー強化学習の仕組み
モデルフリー強化学習の仕組みは以下の通りです。
エージェントは、環境と相互作用しながら経験を収集します。
エージェントは、収集した経験に基づいて行動と価値を学習します。
エージェントは、学習した行動と価値に基づいて行動を選択します。
エージェントは、行動の結果に基づいて行動と価値を更新します。
これらのステップを繰り返すことで、エージェントはより良い行動を選択できるようになります。
モデルフリー強化学習の特徴
モデルフリー強化学習の特徴は以下の通りです。
モデルベース学習に比べてシンプルな学習: モデルフリー強化学習では、環境モデルを学習する必要がないため、モデルベース学習に比べてシンプルな学習が可能です。
少ないデータで学習可能: モデルフリー強化学習は、少ないデータで学習することができます。
オンライン学習: モデルフリー強化学習は、オンライン学習が可能であり、学習しながら行動することができます。
モデルフリー強化学習の課題
モデルフリー強化学習には、以下の課題があります。
探索と活用: モデルフリー強化学習では、探索と活用をバランスよく行うことが重要です。
収束: すべての状態を十分に探索する必要があるため、収束に時間がかかる場合があります。
次元性の呪い: 状態空間が大きくなると、学習が困難になる場合があります。
モデルフリー強化学習の拡張
モデルフリー強化学習は、様々な方法で拡張されています。
ε-greedy法: ε-greedy法は、探索と活用をバランスよく行うための手法です。
SARSA: SARSAは、時間差学習を用いた行動価値関数学習法です。
Q-learning: Q-learningは、経験リプレイを用いた行動価値関数学習法です。
モデルフリー強化学習の応用例
モデルフリー強化学習は、様々なタスクに適用されています。
ロボット制御: ロボットの歩行、アーム制御
ゲーム: ゲームのエージェントの行動学習
自律走行: 自律走行車の経路学習
レコメンデーションシステム: ユーザーに最適な商品やサービスを推薦
まとめ
モデルフリー強化学習は、強化学習の一種であり、エージェントが環境と直接的に相互作用しながら最適な行動を学習する方法です。モデルフリー強化学習は、モデルベース学習に比べてシンプルな学習、少ないデータで学習可能、オンライン学習といった特徴を持ちますが、探索と活用、収束、次元性の呪いといった課題もあります。モデルフリー強化学習は、様々な方法で拡張されており、ロボット制御、ゲーム、自律走行、レコメンデーションシステムなど、様々なタスクに適用されています。
Adversarial attackの特徴
Adversarial Attack(敵対的攻撃)の特徴
敵対的攻撃とは、機械学習モデル、特にディープラーニングに基づくモデルに対して意図的に誤動作を引き起こすよう設計された入力を作成することです。この攻撃は、モデルの出力を意図的に操作するため、セキュリティ上重要なリスクをもたらすことがあります。
主な特徴
微妙な変更: 攻撃者は、人間の目にはほとんど見えないが、モデルが誤分類を引き起こすような微妙な変更を入力データに加えます。
脆弱性の露呈: 敵対的攻撃は、ニューラルネットワークなどのAIモデルの脆弱性を露呈し、それに対する防御策の開発を促進します。
高度にカスタマイズ可能: 攻撃は特定のモデル、タスク、またはデータセットに対してカスタマイズ可能で、非常に多様な方法で実施されます。
攻撃の例
画像分類の誤誘導:
最も一般的な例は、画像分類器に対する攻撃です。たとえば、パンダの画像に微妙なノイズを加えることで、分類器がその画像をギブンと誤認識するようにします。
自然言語処理(NLP)の攻撃:
テキストベースのモデルに対して、文の意味を変えないように一部の単語を変更することで、感情分析モデルを誤分類させる攻撃があります。
自動運転車への攻撃:
交通標識にステッカーやペイントを施すことで、自動運転システムが標識を誤認識し、不適切な運転判断を引き起こすような攻撃です。
防御方法
敵対的トレーニング: 敵対的例をトレーニングデータに組み込むことで、モデルの堅牢性を高める。
入力の検証と修正: 入力データに異常なパターンやノイズが含まれていないか検証し、必要に応じて修正する。
モデルの正則化: モデルが入力データの微小な変化に対して過敏に反応しないように正則化を強化します。
敵対的攻撃は、AIシステムの安全性と信頼性を試す重要なテストであり、これに対処することは、AI技術の実用化を進める上で不可欠です。
「ヒューリスティックな知識」とは?
ヒューリスティックな知識の定義
ヒューリスティックな知識とは、経験則や実務上の知見から得られる、システマティックではないが実用的な解決策やガイドラインを指します。これは、特定の問題を効率的に解決するための「指針」や「ルール」として機能し、通常、正確な証明や科学的根拠がないものの、実際の問題解決には役立つ知識です。
特徴
実用性: ヒューリスティックな知識は、特定の状況や問題に対して素早く効果的な解決策を提供することに焦点を当てています。
非体系的: 伝統的な科学的方法や論理的導出に基づかず、個々の経験や直感によって形成されます。
適用性の限定性: ある状況で有効なヒューリスティックが別の状況では機能しない場合があります。その有効性は文脈に依存します。
単純化と省略: 複雑な理論やデータよりも簡潔なガイドラインやルールを提供することで、意思決定プロセスを速めることができます。
例
プログラミング:
「コードは他の誰かが三時の朝に見ても理解できるように書け」: これは、コードがクリアでシンプルであるべきだというヒューリスティックなアドバイスです。複雑なロジックや冗長なコードは避けるべきです。
ビジネスマネジメント:
「80/20の法則(パレート原則)」: この原則は、結果の大部分(80%)は原因の一部(20%)によって生じるというヒューリスティックです。資源の配分、時間管理、販売戦略など、多くのビジネスプロセスで応用されています。
ユーザーインターフェースデザイン:
「ユーザーは3クリック以内に目的の情報を見つけるべきだ」: このヒューリスティックは、ウェブサイトやアプリのナビゲーション設計において、ユーザビリティを向上させるための指針として使われます。
自動車運転:
「二秒ルール」: 他の車との安全な距離を保つための指針です。前の車が通過した地点を基点にしてから2秒後にその地点を通過するのが安全距離です。
ヒューリスティックな知識は、特定の分野での経験や観察から導かれるため、実務者には非常に価値があるものです。しかし、その効果は状況やコンテキストによって大きく異なるため、柔軟な適用と経験に基づく判断が重要です。
バリアンスとバイアスの関係
バリアンスとバイアスは、機械学習におけるモデルの一般化性能を理解するための重要な概念です。これらはしばしばトレードオフの関係にあり、どちらか一方を減少させることが他方を増加させる可能性があります。このトレードオフは「バイアス-バリアンストレードオフ」と呼ばれ、モデルの過学習と過少適合のバランスを取ることに中心的な役割を果たします。
バイアスとバリアンス:機械学習モデルにおける二つのジレンマ
バイアスとバリアンスは、機械学習モデルにおける重要な概念であり、モデルの性能を大きく左右する要素です。それぞれ、以下の通り定義されます。
バイアス: モデルが真の値からどれだけ離れているかを表す指標です。バイアスが大きい場合、モデルは常に一定方向に誤差を生み出すことになります。
バリアンス: モデルが学習データに対してどれだけ過剰に適合しているかを表す指標です。バリアンスが大きい場合、モデルは訓練データに酷似したデータに対しては良い結果を出すものの、訓練データ外の新規データに対しては良い結果を出さない可能性があります。
一般的に、バイアスとバリアンスはトレードオフの関係にあります。つまり、一方を低減しようとすると、もう一方が高くなる傾向があります。
バイアスが高い場合の条件
バイアスが高い場合、以下の条件が当てはまります。
モデルが単純すぎる: モデルが単純すぎると、データの複雑な構造を捉えることができず、真の値から大きく離れた予測をしてしまう可能性があります。
学習データが少ない: 学習データが少ない場合、モデルはデータの真の分布を十分に学習することができず、偏った予測をしてしまう可能性があります。
ノイズが多い: 学習データにノイズが多い場合、モデルはノイズに過剰に適合し、真の値から離れた予測をしてしまう可能性があります。
バリアンスが高い場合の条件
バリアンスが高い場合、以下の条件が当てはまります。
モデルが複雑すぎる: モデルが複雑すぎると、訓練データのノイズや個々の特徴に過剰に適合し、訓練データ外の新規データに対して良い結果を出さない可能性があります。
過学習: モデルが過学習している場合、訓練データに酷似したデータに対しては良い結果を出すものの、訓練データ外の新規データに対しては良い結果を出さない可能性があります。
非線形な関係: データ間の関係が非線形な場合、線形モデルでは十分に関係を捉えることができず、バリアンスが高くなる可能性があります。
バイアスとバリアンスの対策
バイアスとバリアンスの対策としては、以下の方法があります。モデルの複雑さを調整する: モデルが単純すぎるとバイアスが高くなり、複雑すぎるとバリアンスが高くなります。そのため、モデルの複雑さを調整して、適切なバランスを見つけることが重要です。
学習データを増やす: 学習データが多いほど、モデルはデータの真の分布をより良く学習することができます。そのため、学習データを増やすことで、バイアスを低減することができます。
正則化: 正則化は、モデルの複雑さを制御し、過学習を防ぐ手法です。L1正則化、L2正則化、ドロップアウトなど、様々な正則化手法があります。
ノイズ除去: 学習データからノイズを除去することで、モデルがノイズに過剰に適合することを防ぐことができます。
RL Policyについて
RL Policy(Reinforcement Learning Policy)は、自己対局による強化学習を通じて、ポリシーネットワークをさらに強化するプロセスを指します。このプロセスでは、プログラムが自らの行動に対するフィードバック(報酬やペナルティ)をトレーニングデータとして使用し、最適な行動戦略を学習します。
RL Policyの特徴
自己対局による学習: RL Policyは、自己対局を通じて、勝利に導く戦略を学習します。これにより、ポリシーネットワークは人間の知識を超えた戦略を発見することが可能になります。
フィードバックを利用した学習: 強化学習では、プログラムの行動に対するフィードバック(報酬やペナルティ)をトレーニングデータとして使用し、最適な行動戦略を学習します。
RL Policyの役割
高度な戦略の発見: RL Policyを通じて訓練されたポリシーネットワークは、人間のプレイヤーが考えつかないような高度な戦略や手法を発見することがあります。
自律的な学習能力の向上: 強化学習により、ポリシーネットワークは自律的に学習し、継続的に自己改善する能力を持つようになります。
ロールアウト(Rollout)Policyについて
ロールアウトPolicyは、特にコンピュータ囲碁プログラムにおいて使用される概念で、シミュレーションを通じて最適な手を選択するための手法です。このプロセスでは、特定のロジックに基づいて手を展開(ロールアウト)し、その結果を評価して最良の手を決定します。
ロールアウトPolicyの特徴
特定のロジックに基づく: 現代のコンピュータ囲碁プログラムにおいて、ロールアウトはランダムではなく、特定のロジックに基づいて行われます。
最適な手の選択: このニューラルネットワークは、商用の囲碁プログラムの検索アプローチにおいて、シミュレーションを通じて最良の手を選択するために使用されます。
ロールアウトPolicyの役割
シミュレーションによる評価: ロールアウトPolicyは、複数の手をシミュレーションし、それぞれの結果を評価することで、最適な手を選択します。
戦略的な意思決定のサポート: 特定のロジックに基づいて手を展開することで、より戦略的な意思決定をサポートし、ゲームの勝率を向上させることができます。
深層強化学習におけるバリューネットワーク
深層強化学習では、バリューネットワークはエージェントがどのように行動すべきかを学習するための重要な要素です。特に、AlphaZeroのようなアルゴリズムでは、ポリシーネットワークとバリューネットワークを組み合わせることで、ターン制戦略ゲームにおける高度な学習と意思決定が可能になります。
バリューネットワークの基本
バリューネットワークの役割: バリューネットワークは、特定の盤面や状態がどれだけ有利かを評価することで、エージェントが勝利に向けて最適な行動を選択できるようにします4。
深層強化学習における応用
AlphaZeroのアプローチ: AlphaZeroはポリシーネットワークとバリューネットワークを併用し、探索と学習の方法を組み合わせることで、ターン制戦略ゲームにおいて顕著な成果を上げました13。
深層強化学習におけるバリューネットワークは、エージェントがより賢く、効率的に学習し、意思決定を行うための鍵となります。AlphaZeroのようなアルゴリズムが示すように、ポリシーネットワークとの組み合わせにより、複雑な問題解決においても高い性能を発揮します。
深層強化学習の基本的な用語解説
深層強化学習は、エージェントが環境と相互作用しながら最適な行動を学習するプロセスです。この分野を理解するためには、いくつかの基本的な用語を知っておく必要があります。
基本的な用語
エージェント(Agent): 学習者や行動を決定する主体。環境に対して行動を起こし、その結果を受け取り、学習を進めます。
環境(Environment): エージェントが行動を起こす場所。エージェントの行動に対して状態と報酬を提供します。
状態(State): エージェントが現在の環境の状態を表します。エージェントは状態を考慮して行動を選択します。
行動(Action): エージェントが環境に対して起こす具体的な行為です。エージェントは状態に応じて行動を選択します。
報酬(Reward): エージェントが環境に対して起こす行動に対する評価です。報酬はエージェントの学習を促進します。
ステップ(Step): エージェントが環境に対して行動を起こすために必要な最小の単位です。エピソードは複数のステップから構成されます。
エピソード(Episode): エージェントが環境に対して行動を起こす一連のプロセス。複数のステップから成り立ちます。
マルコフ決定過程(Markov Decision Process, MDP): エージェントと環境の相互作用を記述する数理モデル。次の状態が現在の状態と行動から確定的に決まる特性を持ちます。
方策(Policy): エージェントが環境に対して行動を起こすために使用するルール。最適な方策を見つけることが強化学習の目的です。
収益(Revenue): エージェントが環境に対して起こす行動に対する長期的な報酬を表します。収益は方策の評価指標として用いられます。
価値(Value): エージェントが環境に対して起こす行動に対する長期的な報酬の期待値です。状態価値や行動価値として用いられます。
深層学習の主要モデル年表
深層学習は、様々な分野で革新をもたらしてきました。ここでは、特に自然言語処理(NLP)における主要な深層学習モデルを年代順に一覧化してみましょう。
自然言語処理における主要モデル
1986年: RNN (Recurrent Neural Network) - 時系列データやシーケンスデータを扱うためのネットワーク
2014年: Seq2Seq (Sequence to Sequence) - 一つのシーケンスから別のシーケンスへの変換を学習するモデル
2014年: Attention Mechanism - シーケンス内の重要な情報に焦点を当てる技術
2015年: ResNet (Residual Network)
開発者: Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun
概要: 画像認識において、深いネットワークを効率的に学習させるための技術
2016年: LSTM (Long Short-Term Memory)
開発者: Sepp Hochreiter, Jürgen Schmidhuber
概要: RNNの一種で、長期的な依存関係を学習する能力がある
2017年: Transformer - Attention Mechanismを基礎とし、並列処理が可能で高速な学習を実現するモデル
2018年: BERT (Bidirectional Encoder Representations from Transformers) - 双方向のTransformerを用いて、文脈を理解するモデル
2018年: GPT-2 (Generative Pre-trained Transformer 2) - 大規模なデータセットで事前学習された後、特定のタスクに微調整されるモデル
SENet (Squeeze-and-Excitation Networks)についての詳細
SENetは、画像認識の精度を向上させるために開発されたニューラルネットワークアーキテクチャです。ここでは、その特徴と重要性について、わかりやすく箇条書きで説明します🌟。
SENetの基本概念
一般的なネットワークとの組み合わせ: SENetは、単独で存在するネットワークではなく、「SE」ブロックをResNetやInceptionなどの既存のネットワークアーキテクチャと組み合わせることで構成されます。
SENetの特徴
Squeeze-and-Excitation (SE) ブロック: SENetの核となるのは、SEブロックです。このブロックは、チャネル間の関係性をモデル化し、重要な情報を強調することで、ネットワークの表現力を高めます。
性能の向上: SENetは、2017年のILSVRC (ImageNet Large Scale Visual Recognition Competition) で第1位を獲得しました。これは、SEブロックがネットワークの性能を大幅に向上させることができることを示しています。
SENetの主な特徴
チャネル間の依存関係のモデリング: SENetは、畳み込みニューラルネットワーク(CNN)内の各チャネルの機能応答を、チャネル間の依存関係を明示的にモデリングすることにより、適応的に再調整することに焦点を当てています3。
SEブロックの利用: SEブロックは、CNN内のチャネル間相互作用を処理し、チャネル間の相互作用を表現します。これらのブロックを積み重ねることで、SENetアーキテクチャが形成され、追加の計算コストを最小限に抑えつつ、既存の最先端CNNの性能を大幅に向上させることができます
SENetの重要性
引用数の多さ: Google Scholarでの引用数が10,000を超えるなど、SENetは画像認識分野において大きな影響を与えています。
SENetの応用
画像認識の精度向上: SENetを組み込むことで、さまざまな画像認識タスクにおいて精度の向上が期待できます。特に、複雑なシーンや細かい特徴を捉える必要がある場合に有効です。
Mask R-CNNについてのわかりやすい説明
Mask R-CNNは、画像内のオブジェクトを検出し、それぞれのオブジェクトに対してピクセルレベルでのセグメンテーション(インスタンスセグメンテーション)を行うことができる強力なフレームワークです。
ここでは、Mask R-CNNの基本的な特徴と重要性について、簡潔に説明します。
Mask R-CNNの基本概念
オブジェクト検出とセグメンテーション: Mask R-CNNは、画像内のオブジェクトを検出するだけでなく、それぞれのオブジェクトの正確な形状をピクセルレベルで識別することができます。
Mask R-CNNの特徴
Faster R-CNNの拡張: Mask R-CNNは、Faster R-CNNをベースにしており、オブジェクト検出と高品質なセグメンテーションを同時に実現します。
roiAlignLayerの採用: Faster R-CNNのROI最大プーリング層をroiAlignLayerに置き換えることで、より正確なサブピクセルレベルのROIプーリングを実現しています。
Mask R-CNNの重要性
ICCV 2017のベストペーパー: Mask R-CNNは、2017年のICCV(International Conference on Computer Vision)でベストペーパーに選ばれました。これは、オブジェクト検出とセグメンテーションの分野において、その革新性と有効性が高く評価されたことを意味します。
Mask R-CNNの応用
幅広い応用: Mask R-CNNは、医療画像分析、自動運転車の認識システム、ビデオ解析など、さまざまな分野での応用が期待されています。
画像セグメンテーション技術の概要:Mask R-CNN、DeepLab、SegNet
画像セグメンテーションは、画像内の各ピクセルを特定のクラスに分類するプロセスです。この技術は、自動運転、医療画像解析、画像編集など、多岐にわたる分野で応用されています。ここでは、Mask R-CNN、DeepLab、SegNetという3つの代表的なセグメンテーション技術についてわかりやすく説明します。
Mask R-CNN
概要: Mask R-CNNは、オブジェクトの検出とピクセルレベルでのセグメンテーションを同時に行う深層学習ベースのインスタンスセグメンテーション手法です。複数クラスのオブジェクトを検出し、重なり合うオブジェクトに対しても、それぞれのオブジェクトインスタンスに対するセグメンテーションマップを生成します。
DeepLab
概要: DeepLabシリーズは、Google AIリサーチチームによって設計された、広範なコンテキストのセマンティック情報を効率的に収集するためのセグメンテーションモデルです。DeepLab v3+モデルは、エンコーダモジュールから豊富なセマンティック情報を含み、詳細なオブジェクト境界を生成するためのシンプルかつ効果的なデコーダを持っています5。
SegNet
概要: ケンブリッジ大学によって提案されたSegNetは、深層学習を使用したオープンソースの画像セグメンテーション手法で、特に交通シーンの画像をピクセルレベルでセグメント化します。SegNetは、エンコーダ・デコーダ型の完全畳み込みネットワーク(FCN)であり、U-Net、PSPNet、DeepLab v3などの他のモデルと類似点があります。
FCN、U-Net、PSPNetについての解説
画像セグメンテーションは、画像内の各ピクセルを特定のクラスに分類する技術で、医療画像解析、自動運転車、衛星画像解析など、多岐にわたる分野で応用されています。ここでは、FCN、U-Net、PSPNetという3つの代表的なセグメンテーションモデルについてわかりやすく説明します。
FCN (Fully Convolutional Network)
概要: FCNは、画像セグメンテーションのための深層学習モデルで、全ての層が畳み込み層で構成されています。従来の畳み込みネットワークと異なり、全結合層を畳み込み層に置き換えることで、任意サイズの画像を入力として受け入れ、対応するサイズのセグメンテーションマップを出力することができます。
U-Net
概要: U-Netは、特に医療画像セグメンテーションにおいて高い性能を発揮するモデルです。エンコーダーとデコーダーの構造を持ち、エンコーダーで特徴を抽出し、デコーダーでセグメンテーションマップを生成します。U-Netの特徴は、エンコーダーとデコーダー間のスキップ接続にあり、これにより詳細な情報が保持され、より精度の高いセグメンテーションが可能になります。
PSPNet (Pyramid Scene Parsing Network)
概要: PSPNetは、シーン解析のために設計されたセグメンテーションモデルで、特に大規模なシーンの理解に優れています。PSPNetの核となるのは、ピラミッド型のシーン解析モジュールで、異なるスケールでのグローバルなコンテキスト情報を集約し、より正確なセグメンテーションを実現します
ドメインアダプテーションについての解説
ドメインアダプテーション(Domain Adaptation、DA)は、異なるが関連するデータセット間での知識の転移を可能にする技術です。具体的には、あるドメイン(ソースドメイン)で学習したモデルを、別のドメイン(ターゲットドメイン)に適用し、その性能を向上させることを目指します。このプロセスは、転移学習の一種と見なされます。
ドメインアダプテーションのシナリオとタイプ
ソースドメインとターゲットドメイン: ソースドメインは、ラベル付きデータが豊富に存在するドメインです。一方、ターゲットドメインは、ラベル付きデータが少ないか全くないドメインで、モデルの性能を向上させたい対象です1。
ドメインアダプテーションの手法
知識の転送: ドメインアダプテーションは、ソースドメインからターゲットドメインへの知識転送を行う学習手法です。このプロセスにより、ターゲットドメインでのモデルの性能が向上します2。
ドメインアダプテーションの応用例
AIとビッグデータ: 転移学習とドメインアダプテーションは、AIとビッグデータの分野で実用的な例と将来の展望を提供します。これにより、限られたデータでの学習や、異なるドメイン間での知識の活用が可能になります
ドメインランダマイゼーションの目的について
ドメインランダマイゼーションは、AIやロボティクスの分野で、シミュレーション環境から実世界(sim2real)への適応を助けるために用いられる技術です。この技術の主な目的は、シミュレータ内でのパラメータをランダムに変更することにより、モデルが多様な環境に対応できるようにすることです。
ドメインランダマイゼーションの概要
sim2realの課題: シミュレーションで学習したモデルを実世界に適用する際、シミュレーションと実世界の間には「リアリティギャップ」と呼ばれる差異が存在します。ドメインランダマイゼーションは、このギャップを埋めるための手法の一つです1。
ドメインランダマイゼーションの目的と効果
多様な環境での学習: パラメータをランダムに変更することで、モデルは様々な環境下での学習が可能になります。これにより、モデルは実世界の多様なシナリオに対応できるようになることが期待されます
強化学習の手法一覧
強化学習は、エージェントが環境と相互作用しながら最適な行動を学習するAIの一分野です。ここでは、強化学習の代表的な手法をいくつか紹介します。
代表的な強化学習の手法
Q学習 (Q-Learning): 環境の状態と行動からなるQ値(行動価値)を学習し、最適な行動選択を目指します。Q学習は、オフポリシー学習の一種で、最も基本的な強化学習アルゴリズムの一つです。
SARSA: 状態、行動、報酬、次の状態、次の行動(S,A,R,S',A')の5つの要素を用いて学習を行います。SARSAは、オンポリシー学習の一種で、行動方針に従って次の行動を選択します。
モンテカルロ法: エピソードが完了するまでの報酬を用いて価値を推定する方法です。各エピソードの経験を通じて学習を進めます3。
ポリシー勾配法 (Policy Gradient Methods): 行動方針自体を直接学習する手法で、報酬を最大化する行動方針を求めます。Actor-Criticアルゴリズムなどがこのカテゴリに含まれます。
Actor-Critic: エージェントが行動を選択する「Actor」と、選択した行動の価値を評価する「Critic」の二つの部分で構成されています。ActorとCriticが協力しながら学習を進めます
深層強化学習 (Deep Reinforcement Learning): 強化学習に深層学習(ディープラーニング)を組み合わせた手法です。複雑な環境や高次元のデータに対応可能で、AlphaGoなどの応用例が有名です。
逆強化学習 (Inverse Reinforcement Learning): エージェントが観察した行動から報酬関数を学習する手法です。エキスパートの行動を模倣することで、最適な行動方針を導き出します。
マルチエージェント強化学習 (Multi-Agent Reinforcement Learning): 複数のエージェントが同時に学習を進める環境での強化学習です。エージェント間の協力や競争を考慮しながら、最適な行動を学習します
二値分類と多値分類に利用される活性化関数
二値分類と多値分類の問題において、ニューラルネットワークの出力層で利用される活性化関数は異なります。それぞれの分類問題に適した活性化関数を選択することが重要です。
二値分類に利用される活性化関数
シグモイド関数: 二値分類問題において、シグモイド関数は出力層でよく使用されます。この関数は、出力を0から1の間の値に制限し、ある入力が特定のクラスに属する確率を表すことができます。二値分類問題では、しばしばBinaryCrossentropyを損失関数として使用します。
多値分類に利用される活性化関数
ソフトマックス関数: 多値分類問題では、ソフトマックス関数が出力層で一般的に使用されます。この関数は、各クラスに属する確率を出力し、その総和が1になるようにします。多値分類問題では、CategoricalCrossentropyを損失関数としてよく使用します
勾配降下法以外の類似する最適化手法
勾配降下法は、機械学習モデルのパラメータを最適化するための一般的な手法ですが、これ以外にも類似する手法が存在します。これらの手法は、特定の問題やデータセットによって、勾配降下法よりも効率的な場合があります。
確率的勾配降下法 (SGD)
概要: 確率的勾配降下法は、ランダムに選んだ1つのデータのみを使用して学習を進める方法です。これにより、計算コストを大幅に削減しながら、オンライン学習に適した手法となっています。
ミニバッチ勾配降下法
概要: ミニバッチ勾配降下法は、バッチサイズに基づいて少量のデータを集計し、各バッチの更新を行う最適化手法です。この手法は、確率的勾配降下法とバッチ勾配降下法の中間に位置づけられ、効率と精度のバランスを取ります。
その他の手法
概要: 勾配ブースティング法は、損失関数を最小化するために使用される手法で、特異値分解(SVD)や多次元尺度法(MDS)などの類似技術も利用されます。これらの手法は、特定の種類の問題やデータセットに対して、より適した解を提供することがあります。
モーメンタムを物理法則に例えて説明
モーメンタム(運動量)は、物体の運動の状態を表す物理量で、質量と速度の積として定義されます。この概念を機械学習の最適化問題に例えると、以下のようなイメージになります。
物理法則とモーメンタム法の関係
物理学におけるモーメンタム(運動量)は、物体の質量と速度の積で表されます。この物理法則を最適化問題に適用した場合、以下のように考えることができます。
物理学のモーメンタム: 物体が持つ運動の勢い。質量が大きいほど、または速度が速いほど、その物体の運動量は大きくなります。1
最適化問題におけるモーメンタム: 前回のパラメータ更新量(過去の勾配の影響)を考慮して、現在の更新量を決定します。これにより、パラメータの更新が滑らかになり、最適解に向かって効率的に進むことができます。
物理法則に例えたモーメンタム法のイメージ
モーメンタム法を物理法則に例えると、滑らかな平面上を転がるボールの動きに似ています。ボールが勾配(斜面)を下るとき、重力によって加速されますが、モーメンタム法では、この「加速」を過去の勾配(運動量)が影響を与えることで表現します。つまり、ボールが勢いよく転がり続けるように、パラメータの更新も過去の更新の「勢い」を利用して、よりスムーズかつ迅速に最適解に近づけるわけです。
バッチ正規化について
バッチ正規化は、モデルの訓練過程をより効率的にするために使用される技術です。この手法は、ミニバッチごとにデータを正規化して、平均が0、標準偏差が1になるようにします。これにより、学習プロセスが安定し、学習速度が向上します。
バッチ正規化の主な特徴
学習の安定化: 各チャネルをミニバッチごとに平均0、分散1に正規化することで、学習が安定します。
学習速度の向上: 学習プロセス全体が安定し、学習速度が増加します。
勾配消失/爆発の防止: 勾配消失や勾配爆発といった問題を防ぎます。これにより、深いネットワークの訓練が容易になります。
内部共変量シフトの軽減: 訓練とテスト環境間で入力データの分布が変化する「内部共変量シフト」現象を軽減します。これにより、モデルの性能が向上します。
バッチ正規化のメカニズム
バッチ正規化は、各ミニバッチのデータを正規化することで、ニューラルネットワークの各層が受け取る入力の分布を安定させます。具体的には、各層の入力を平均0、分散1に正規化し、さらに学習可能なパラメータを用いてスケールとシフトを行います。これにより、モデルの訓練が容易になり、より深いネットワークの訓練が可能になります
エンコーダでは、Self-Attention、デコーダではSelf-AttentionとAttentionを使う構造
Transformerのエンコーダ部分ではSelf-Attentionメカニズムが使用され、デコーダ部分ではSelf-Attentionとさらにエンコーダからの出力に対するAttention(エンコーダ-デコーダAttention)が使用されます。
エンコーダのSelf-Attention: エンコーダ内のSelf-Attentionは、入力シーケンス内の各要素が他の全ての要素とどの程度関連しているかを計算します。これにより、文脈全体を考慮したトークン間の関係をモデル化できます。
デコーダのSelf-Attention: デコーダ内のSelf-Attentionも同様に、出力シーケンス内の各要素が、既に生成された要素とどの程度関連しているかを計算します。ただし、将来の位置にあるトークンからの情報はマスクされ、予測が現在と過去のトークンのみに基づくようにします。
デコーダのエンコーダ-デコーダAttention: これは、デコーダがエンコーダの出力全体に対してAttentionを行う部分です。デコーダの各ステップで、エンコーダの出力に対してAttentionを計算することで、入力シーケンスのどの部分が現在の出力トークンの生成に最も関連しているかをモデルが判断できるようにします。
この構造により、Transformerは入力シーケンスの各要素間の複雑な関係を捉え、それを基にして出力シーケンスを生成することができます。
FATの原則について
FATの原則は、AIの設計と運用において非常に重要な概念であり、公平性(Fairness)、説明責任(Accountability)、透明性(Transparency)の3つのキーポイントに焦点を当てています。
公平性(Fairness)
概要: 公平性は、AIシステムが人種、性別、国籍、年齢、政治的信念、宗教などの多様な背景に基づいて不公平な差別を行わないようにすることを目指しています。
説明責任(Accountability)
概要: AIシステムの決定や行動に対する説明責任は、開発者や運用者がその結果に責任を持ち、必要に応じて説明や是正措置を提供することを意味します。
透明性(Transparency)
概要: 透明性は、AIシステムの動作原理や決定プロセスが明確であり、利用者や関係者が理解しやすいことを指します。これにより、信頼性の向上と不公平な差別の防止が期待されます。
FATの原則は、AI技術の倫理的な使用を確保し、社会全体にとって公正で透明性のある技術開発を促進するために重要です。これらの原則を遵守することで、AIのポジティブな影響を最大化し、潜在的なリスクを最小限に抑えることができます。
隠れ層の活性化関数について
隠れ層では、線形層の出力値を活性化関数を通して非線形変換します。これにより、ニューラルネットワークは複雑な関数を学習する能力を持ちます。
活性化関数の種類
tanh: 入力値を-1から1の範囲に圧縮します。[2]
シグモイド: 入力値を0から1の範囲に圧縮します。主に二値分類問題で使用されます。[2]
ReLU (Rectified Linear Unit): 負の入力を0に、正の入力はそのまま出力します。勾配消失問題を軽減し、計算効率が良いため、多くのネットワークで使用されます。
ソフトマックス: 主に出力層で使用されますが、隠れ層での使用も考えられます。多クラス分類問題での確率分布を出力します。[3]
活性化関数の役割
非線形性の導入: 活性化関数により、ニューラルネットワークは非線形な関数を学習できるようになります。これにより、より複雑なデータパターンを捉えることが可能になります。
勾配消失問題の軽減: 特定の活性化関数(例:ReLU)は、勾配消失問題を軽減する効果があります。これにより、深いネットワークの学習が容易になります。
ニューラルネットワークの設計において、隠れ層の活性化関数の選択は非常に重要です。問題の種類やネットワークの構造に応じて、最適な活性化関数を選択することが、モデルの性能向上につながります。
PReLU-netの特徴
PReLU-net(Parametric Rectified Linear Unit network)は、深層学習のための活性化関数の一種です。以下に主な特徴をまとめました。
PReLUの特徴
非線形性の導入: PReLUは、ReLUと同様に非線形性を導入することで、深層ニューラルネットワークの最適化を助けます。
負の領域の勾配: PReLUは、負の入力に対して小さな勾配を持つことで、勾配の消失問題を緩和します。
パラメータ化された負の勾配: PReLUでは、負の領域の勾配がパラメータ化されており、学習の過程で最適化されます。
PReLU-netの性能
画像分類精度の向上: PReLU-netを使用することで、画像分類の精度が4.9%向上したという報告があります。
計算コストの増加: PReLUはパラメータ化された活性化関数であるため、ReLUに比べて計算コストが若干増加します。
PReLU-netは、深層学習における活性化関数の一つとして注目されています。非線形性の導入と負の領域の勾配の最適化により、モデルの性能向上に寄与しています。ただし、計算コストの増加にも注意が必要です
特異値分解の概要
特異値分解(Singular Value Decomposition, SVD)は、m x n の行列Aを3つの行列に分解する手法です。
行列Aを、直交行列U、対角行列Σ、直交行列Vの積として表すことができます。
この分解により、行列Aの性質を詳しく分析することができます。1
特異値分解の数式表現
特異値分解の数式表現は以下の通りです:
A = UΣV^T
ここで:
A: m x n の入力行列
U: m x m の直交行列
Σ: m x n の対角行列
V: n x n の直交行列
V^T: n x n の転置行列
特異値分解の特徴
行列Aの列ベクトルを、Uの列ベクトルで表現できる
行列Aの行ベクトルを、Vの列ベクトルで表現できる
対角行列Σの対角成分は、行列Aの特異値と呼ばれる重要な値
特異値分解は、行列の次元削減や、データの圧縮などに利用される 3
特異値分解の応用
機械学習: 主成分分析やサポートベクトルマシンなどで使用される
信号処理: 画像圧縮やノイズ除去に利用される
自然言語処理: 潜在意味解析などで活用される
順伝搬型ニューラルネットワーク:詳細解説
順伝搬型ニューラルネットワーク(Feedforward Neural Network)は、機械学習において広く用いられるニューラルネットワークの一種です。ニューロンを層状に接続し、入力層から出力層まで情報を伝搬させることで、複雑な非線形な関数を学習することができます。
順伝搬型ニューラルネットワークの構造
順伝搬型ニューラルネットワークは、以下の3つの層で構成されています。
入力層: 入力データを受け取る層です。入力データは、ニューロンの数と同じ数の要素を持つベクトルで表されます。
中間層: 入力層と出力層の間に存在する層です。中間層は、1つ以上の層で構成されることもあります。
出力層: 最終的な出力を生成する層です。出力層のニューロンの数は、出力データの次元数と同じになります。
各ニューロンは、以下の要素で構成されています。
重み: 入力からの信号を重み付けする値です。
バイアス: ニューロンの出力にオフセットを加える値です。
活性化関数: ニューロンの入力を非線形に変換する関数です。
順伝搬型ニューラルネットワークの動作
順伝搬型ニューラルネットワークの動作は以下の通りです。
入力: 入力データを入力層のニューロンに与えます。
計算: 各ニューロンは、入力信号を重みで重み付けし、バイアスを加えます。その後、活性化関数を通して非線形に変換します。
伝搬: 各ニューロンの出力は、次の層のニューロンに入力されます。この処理を、出力層まで繰り返します。
出力: 出力層のニューロンの出力が出力データとなります。
順伝搬型ニューラルネットワークの学習
順伝搬型ニューラルネットワークは、誤差逆伝搬法と呼ばれるアルゴリズムを用いて学習を行います。誤差逆伝搬法では、以下の手順でモデルのパラメータ(重みとバイアス)を更新します。
順伝搬: 入力データを入力し、出力データを出力します。
誤差計算: 出力データと教師データとの誤差を計算します。
逆伝搬: 誤差を各ニューロンに伝搬し、各ニューロンのパラメータが誤差にどのように影響を与えたかを計算します。
パラメータ更新: 各ニューロンのパラメータを、誤差を減少させる方向に更新します。
この処理を繰り返し行うことで、モデルは教師データとの誤差を最小化するように学習していきます。
順伝搬型ニューラルネットワークの利点
順伝搬型ニューラルネットワークは、以下の利点があります。
汎用性: さまざまな種類のデータに対して学習することができます。
非線形性の表現: 活性化関数を用いることで、複雑な非線形な関数を学習することができます。
学習能力: 誤差逆伝搬法を用いることで、効率的に学習することができます。
順伝搬型ニューラルネットワークの課題
順伝搬型ニューラルネットワークは、以下の課題があります。
過学習: 訓練データに過度に適応し、訓練データ以外のデータに対して良い精度を出せない状態になる可能性があります。
局所解: 誤差逆伝搬法では、必ずしもグローバルな最適解を見つけるとは限りません。局所解に陥ってしまう可能性もあります。
計算量: 複雑なモデルの場合、学習に時間がかかることがあります。
順伝搬型ニューラルネットワークの応用例
順伝搬型ニューラルネットワークは、画像認識、音声認識、自然言語処理など、様々な分野で応用されています。
画像認識: 画像分類、オブジェクト検出、セマンティックセグメンテーションなど
音声認識: 音声認識、音声合成、音声翻訳など
自然言語処理: 機械翻訳、文書分類、感情分析など
まとめ
順伝搬型ニューラルネットワークは、機械学習において広く用いられる強力なツールです。利点と課題を理解した上で、適切な問題に適用することで、優れた結果を得ることができます。
ディープニューラルネットワーク(DNN)の概要
DNNは深層学習の一手法で、4層以上の多層のニューラルネットワークを使用するタイプの機械学習モデルです。
従来の機械学習手法と比べ、DNNは入力データから特徴量を自動的に抽出できるため、人手による特徴量設計が不要です。
DNNは深層構造により、複雑な非線形関数を表現できるため、画像認識や自然言語処理などの高度な問題に適しています。
DNNの特徴
多層のニューラルネットワークを持つことで、複雑な特徴を自動的に抽出できる
大量のデータを使って学習することで、高い精度を実現できる
従来の機械学習手法と比べ、人手による特徴量設計が不要
画像認識、自然言語処理、音声認識など、さまざまな分野で高い性能を発揮
DNNの応用例
画像認識: 物体検出、画像分類、セグメンテーションなどに活用
自然言語処理: 機械翻訳、テキスト生成、感情分析などに活用
音声認識: 音声合成、音声命令認識などに活用
医療分野: 医療画像の診断支援、遺伝子解析などに活用
ディープニューラルネットワークの特徴
階層的特徴抽出:
ディープニューラルネットワークは、入力層から出力層に向かうにつれて、低レベルから高レベルへと段階的に抽象化された特徴を自動的に学習します。例えば、画像処理においては、初期層がエッジやテクスチャを、深い層がオブジェクトの部品や全体像を認識するようになります。
表現学習の強力さ:
隠れ層が多いため、非常に複雑な関数を近似することができ、画像認識、音声認識、自然言語処理など、多様なタスクで高い性能を発揮します。
大量のデータと計算リソースを必要とする:
高度な学習能力を持つ反面、十分な量の訓練データと計算リソース(GPUなど)が必要とされます。
過学習のリスク:
パラメータの数が非常に多いため、過学習(訓練データには良いが、未知のデータに対しては弱い)するリスクがあります。これを防ぐために、正則化技術やドロップアウトが一般的に使用されます。
パラメータ更新手法
ディープニューラルネットワークの訓練には、様々な最適化アルゴリズムが使われています。これらは、ネットワークの重みやバイアスを効果的に更新し、損失関数を最小化するために設計されています。
確率的勾配降下法(SGD):
基本的なアプローチで、訓練データの一部を使って勾配を計算し、パラメータを更新します。バッチサイズや学習率がパフォーマンスに大きな影響を与えます。最も古くからある。
モーメンタムを用いたSGD:
勾配の更新に前回の更新を「モーメンタム」として加算し、より滑らかな収束を実現します。
AdaGrad:
各パラメータの学習率を適応的に調整します。パラメータごとに異なるスケールで勾配を調整するため、特にスパースなデータで効果的です。
RMSprop:
AdaGradの拡張で、最近の勾配の情報だけを使って学習率を調整するため、長期間の訓練での性能低下を防ぎます。
Adam:
モーメンタムとRMSpropのアイデアを組み合わせた手法で、多くの問題で高い性能を発揮します。特にディープラーニングの分野で広く使われています。
パラメータ更新手法の一覧(古い順)
パラメータ更新手法は、機械学習においてモデルのパラメータを更新するために用いられる手法です。
様々なパラメータ更新手法が提案されており、それぞれ異なる特徴と利点・欠点を持っています。
以下では、代表的なパラメータ更新手法を古い順に一覧化し、それぞれの概要と特徴、利点・欠点について説明します。
1. 確率的勾配降下法 (Stochastic Gradient Descent, SGD)
1959年にRosenblattによって提案された、最も基本的なパラメータ更新手法の一つです。
SGDは、勾配方向に小さなステップでパラメータを更新していく手法です。
利点
シンプルで実装しやすい
計算量が少ない
凸関数であれば収束が保証される
欠点
収束速度が遅い
局所解に陥りやすい
ハイパーパラメータの調整が難しい
2. 勾配降下法 (Gradient Descent, GD)
1964年にLinによって提案された手法です。
GDは、バッチデータ全体を用いて勾配方向にパラメータを更新していく手法です。
利点
SGDよりも収束速度が速い
局所解に陥りにくい
欠点
SGDよりも計算量が多い
メモリ使用量が多くなる
3. モメンタム (Momentum)
1986年にRumelhart, Hinton, Williamsによって提案された手法です。
モメンタムは、過去の勾配情報を考慮してパラメータを更新していく手法です。
利点
SGDよりも収束速度が速い
局所解に陥りにくい
欠点
ハイパーパラメータの調整が難しい
4. AdaGrad (Adaptive Gradient Descent)
2011年にDuchi, Hazan, Jordanによって提案された手法です。
AdaGradは、パラメータごとの学習率を調整していく手法です。
利点
過去に大きく更新されたパラメータの影響を減らすことができる
凸関数であれば収束が保証される
欠点
収束速度が遅い
稀なパラメータ更新に対して学習が進まない
5. RMSProp (Root Mean Squared Propagation)
2011年にTieleman, Hintonによって提案された手法です。
RMSPropは、AdaGradと同様にパラメータごとの学習率を調整していく手法ですが、AdaGradよりも安定した収束を実現します。
利点
AdaGradよりも収束速度が速い
AdaGradよりも安定した収束を実現できる
欠点
ハイパーパラメータの調整が難しい
6. Adam (Adaptive Moment Estimation)
2014年にKingma, Baによって提案された手法です。
Adamは、モメンタムとRMSPropを組み合わせた手法で、高い収束速度と安定性を実現します。
利点
SGD、モメンタム、AdaGrad、RMSPropよりも収束速度が速い
SGD、モメンタム、AdaGrad、RMSPropよりも安定した収束を実現できる
ハイパーパラメータの調整が比較的容易
欠点
収束速度が遅い場合がある
7. その他のパラメータ更新手法
上記以外にも、様々なパラメータ更新手法が提案されています。
代表的なものとしては、以下のような手法があります。
Nesterov Accelerated Gradient (NAG)
AdagradAM
AdamW
RMSPropTF
LARS-SGD
これらの手法は、それぞれ異なる特徴と利点・欠点を持っています。
具体的な状況に合わせて、適切なパラメータ更新手法を選択することが重要です。
ニューラルネットワークにおける勾配消失問題に対する対応策
ニューラルネットワークにおける勾配消失問題は、深層学習においてよく発生する問題であり、誤差逆伝搬法を用いて学習を行う際に、中間層の重みの更新がうまく進まなくなるという現象です。
勾配消失問題の原因
勾配消失問題は、以下の要因によって発生します。
活性化関数の選択: シグモイド関数やtanh関数などの活性化関数は、入力値が大きくなると出力値が飽和しやすいため、勾配が小さくなりやすくなります。
ネットワークの深さ: ネットワークが深くなると、誤差が中間層を伝搬していく過程で何度も指数関数的に小さくなっていくため、勾配が消失しやすくなります。
勾配消失問題への対応策
勾配消失問題への対応策として、以下の方法が挙げられます。
活性化関数の変更: ReLU関数やリーキーReLU関数などの活性化関数は、入力値が大きくなっても飽和しにくいため、勾配消失問題を軽減することができます。
バッチ正規化: バッチ正規化は、各層の入力データの分布を正規化することで、勾配消失問題を軽減することができます。
ショートカット接続: ショートカット接続は、スキップ層と呼ばれる中間層を直接出力層に接続することで、誤差が中間層を伝搬していく過程で消失することを防ぎます。
残差ネットワーク: 残差ネットワークは、各層の出力にスキップ層の出力を足すことで、勾配消失問題を軽減することができます。
はい、クラス分類について詳しく説明させていただきます。 🤖
クラス分類の概要
クラス分類とは、入力データを事前に定義されたクラスに分類する機械学習の手法です。
例えば、画像の中にある物体が犬、猫、人間のいずれに属するかを判別するなどが典型的なクラス分類の事例です。
クラス分類の手順
ラベル付きデータの収集:
クラス分類を行うには、事前にラベル付きのデータセットが必要です。
例えば、犬、猫、人間の画像にそれぞれのラベルを付与します。
モデルの学習:
ラベル付きデータを使ってクラス分類モデルを学習させます。
代表的なアルゴリズムにはロジスティック回帰、SVMなどがあります。
新しい入力データの分類:
学習済みのモデルを使って、新しい入力データを各クラスに分類します。
入力データがどのクラスに属するかを出力します。
クラス分類の応用
クラス分類は画像認識、自然言語処理、医療診断など、さまざまな分野で活用されています。
例えば、医療画像診断では、X線画像からがんの有無を判別するのにクラス分類が使われます。
また、メール分類では、受信メールがスパムかどうかを判別するのにクラス分類が用いられます。
クラス分類の利点
自動化: 人手で行うよりも効率的に分類できる
高精度: 機械学習アルゴリズムの進化により、高精度な分類が可能
汎用性: さまざまな分野で応用できる
ResNetがクラス分類に適している理由
ResNetがクラス分類に適している理由は、以下の3つが挙げられます。
1. 高い表現力
ResNetは、非常に深いモデルを構築することが可能であり、高い表現力を持っています。そのため、複雑な画像の特徴を捉えることができ、クラス分類において高い精度を達成することができます。
2. 優れた汎化性能
ResNetは、過学習と呼ばれる問題に比較的強いため、優れた汎化性能を持っています。過学習とは、訓練データに対しては高い精度を達成できるが、未知のデータに対しては精度が低くなるという問題です。
3. 効率的な学習
ResNetは、ショートカット接続によって勾配消失問題を克服しているため、効率的に学習することができます。そのため、他の深層学習モデルよりも短い時間で学習を完了させることができます。
水増しテクニックでロバスト性を向上させる事例:詳細解説
水増しテクニックは、機械学習モデルのロバスト性を向上させるために用いられる手法の一つです。この手法では、教師データセットに人工的にノイズを加えることで、モデルがノイズに対する耐性を獲得できるようにします。
水増しテクニックの種類
水増しテクニックには、以下の種類があります。
回転: 画像をランダムな角度で回転させます。
反転: 画像をランダムに左右反転させます。
切り抜き: 画像の一部を切り抜きます。
拡大縮小: 画像をランダムに拡大縮小します。
色相変化: 画像の色相をランダムに変更します。
輝度変化: 画像の輝度をランダムに変更します。
ガウスノイズ: 画像にガウスノイズを追加します。
ドロップアウト: ニューラルネットワークのトレーニング時に、ランダムにニューロンを非活性化します。
水増しテクニックの利点
水増しテクニックには、以下の利点があります。
ロバスト性の向上: モデルがノイズに対する耐性を獲得するため、ノイズを含むデータに対して精度が向上します。
過学習の防止: 水増しされたデータは、元のデータセットと異なるため、モデルが元のデータセットに過学習するのを防ぐことができます。
汎化性能の向上: モデルがノイズに対する耐性を獲得するため、未知のデータに対する精度が向上します。
水増しテクニックの課題
水増しテクニックには、以下の課題があります。
データ量の増加: 水増しされたデータを作成することで、データ量が大幅に増加します。
計算量の増加: 水増しされたデータを用いてモデルを学習するため、計算量が大幅に増加します。
効果の不確実性: 水増しテクニックの効果は、データセットやモデルによって異なるため、必ずしも効果があるとは限りません。
水増しテクニックの事例
水増しテクニックは、様々な分野で利用されています。以下に、具体的な事例をいくつか紹介します。
画像認識: 画像認識タスクにおいて、水増しテクニックを用いることで、照明条件や角度の変化に対するロバスト性を向上させることができます。
音声認識: 音声認識タスクにおいて、水増しテクニックを用いることで、背景ノイズや話し手のアクセントに対するロバスト性を向上させることができます。
自然言語処理: 自然言語処理タスクにおいて、水増しテクニックを用いることで、文法ミスや誤字脱字に対するロバスト性を向上させることができます。
東京大学 松尾豊教授の人工知能の定義
東京大学 松尾豊教授は、人工知能を以下のように定義しています。
「人工知能とは、人間が行う知的活動を模倣し、代替するシステムである。」
松尾教授は、人工知能の研究において、特に以下の分野に力を入れています。
機械学習: コンピューターに明示的にプログラムすることなく、データから学習する技術
自然言語処理: コンピューターと人間の間の自然な言語でのやり取りを実現する技術
ロボット工学: 人間と同じように行動し、周囲と協調できるロボットを開発する技術
松尾教授は、人工知能は単に人間が行う知的活動を模倣するだけでなく、人間を超える知性を獲得する可能性を秘めていると考えています。そのため、人工知能の研究において、倫理的な問題にも積極的に取り組んでいます。
アーサー・サミュエルの人工知能の定義
アーサー・サミュエルは、計算機ゲームと人工知能の分野で主に知られているアメリカの計算機科学者です。彼は世界初の学習型プログラムである「Samuel Checkers-playing Program」を開発し、人工知能(AI)の基本的概念を世界に示しました。
このプログラムは、明示的なプログラムや指示なしに、コンピュータが学習できることを示すものであり、AIの先駆的な研究となりました。
人工知能の定義:
人工知能とは、コンピューターが明示的なプログラミングなしに学習し、問題を解決できるようにする技術のこと。4
具体的には、機械学習によって、コンピューターが自動的に経験から学習し、より良い性能を発揮できるようになることが人工知能の目的です。2
人工知能の特徴:
明示的なプログラミングなしにコンピューターが学習し、問題を解決できるようにする
機械学習によって、経験から自動的に学習し、性能を向上させる
様々な分野で応用されており、チャットボットや推薦システムなどに活用されている
Chainer
Chainerは、Pythonで書かれたオープンソースのディープラーニングフレームワークで、主に株式会社Preferred Networksによって開発されました。Chainerの特徴は、動的計算グラフ(Define-by-Runスキーム)を採用している点にあります。これは、ニューラルネットワークのモデルが実行時に動的に定義されることを意味し、柔軟性が非常に高いことが特徴です。
Chainerの主な特徴
Define-by-Runアプローチ:
Chainerの最大の特徴は、計算グラフが動的に構築されることです。これにより、プログラムが実行されるたびに異なる計算グラフが生成される可能性があり、ループや条件分岐などのPythonのネイティブな機能を使って直感的にモデルを書くことができます。
柔軟性と拡張性:
ユーザーは独自のカスタム層や最適化アルゴリズムを簡単に追加でき、既存のコードもPythonの標準的な記述で直接変更が可能です。これにより、研究目的での新しいアイディアのテストが容易になります。
GPUサポート:
ChainerはNVIDIA CUDAをサポートしており、GPU上での高速な数値計算を実現します。これにより、大規模なニューラルネットワークモデルのトレーニングが迅速に行えます。
多様なネットワークサポート:
畳み込みニューラルネットワーク(CNN)、再帰的ニューラルネットワーク(RNN)、長・短期記憶ネットワーク(LSTM)など、多様なモデルをサポートしています。
豊富なツールと拡張ライブラリ:
Chainerは、画像処理を効率化するためのCuPyライブラリや、より大規模なデータの効率的な処理を可能にするChainerMN(マルチノード拡張)など、様々な拡張ライブラリが用意されています。
開発の終了と後継
2020年にChainerの開発は正式に終了し、その機能やコンセプトはPyTorchという別のディープラーニングフレームワークに引き継がれました。Preferred NetworksはChainerからPyTorchへの移行をサポートするためのツールやドキュメントを提供しています。PyTorchもまたDefine-by-Runのアプローチを採用しており、Chainerのユーザーが移行しやすい環境が整っています。
Chainerは、動的な計算グラフの先駆者としてディープラーニングフレームワークの発展に大きく寄与し、現在のフレームワークの設計に多くの影響を与えました。
Define-by-Run は、ディープラーニングにおけるプログラミングパラダイムの一つで、計算グラフが動的に定義されるアプローチを指します。この方式では、プログラムの実行フローがそのままネットワークの構造を定義するため、グラフの構築と実行が同時に行われます。この手法は特に柔軟性が高く、動的な変更が頻繁に発生するモデルや条件に依存するモデルの設計に適しています。
Define-by-Runの特徴
動的な計算グラフ:
モデルの実行中に計算グラフが構築されるため、ループや条件分岐などのプログラムの動的な構造を直接モデルに反映させることができます。これにより、各実行時に異なる計算パスを取ることが可能です。
直感的なデバッグと開発:
通常のPythonのデバッグ手法を用いて、ニューラルネットワークのモデルをデバッグすることができます。エラーが発生した時には、その時点の具体的なコードラインや変数の状態を即座に確認できます。
柔軟なネットワーク設計:
可変長の入力データや、実行時に変更が必要なネットワーク構造に対して柔軟に対応できます。例えば、自然言語処理で文の長さに応じてRNNのステップ数を変更する場合などに有効です。
Define-by-RunとDefine-and-Runの比較
Define-and-Run は、計算グラフが事前に定義され、その後でデータが流れる静的なパラダイムです。TensorFlowの初期バージョンがこの方式を採用していました。この方式では、計算グラフが一度構築されると、実行フェーズで何度も再利用されるため、一定の効率があります。しかし、モデルの構造が固定されてしまうため、動的な変更には対応しにくいです。
一方、Define-by-Run は、実行時にモデルの構造が定義されるため、より動的で柔軟なモデル構築が可能です。ChainerやPyTorchがこの方式を採用しており、特に研究開発やプロトタイピングの段階での生産性が高いとされています。
結論
Define-by-Runは、その高い柔軟性と直感的な操作感から、多くの研究者や開発者に支持されています。特に複雑な条件や動的なモデル構造を扱う際に、その真価を発揮します。このパラダイムを採用しているモダンなフレームワークの進化により、ニューラルネットワークの開発がよりアクセスしやすく、実験的なアプローチが容易になっています。
知能の全体像
知能の全体像は、一般的には階層的な構造を持つとされています。
以下に、その階層構造を説明します:
第一の階層「パターン処理」:環境からの情報のセンシングとそれに応じた行動というループが基本とされます。これは、我々が周囲の環境から情報を収集し、それに基づいて行動を決定するという基本的な知能の働きを指します。
第二の階層「記号の処理」:人間はこれを通じて物事を抽象的に認識できるようになり、チェスなどのゲームを楽しむようになったとされています。これは、具体的な事象や現象を記号として表現し、それによって抽象的な思考や複雑な問題解決を可能にするという知能の働きを指します。
第三の階層「他者とのインタラクション」:我々が知識を獲得していく上で不可欠な営みであるとされています。これは、他者とのコミュニケーションや協調行動を通じて新たな知識や情報を獲得し、それを自己の知識体系に組み込んでいくという知能の働きを指します。
ディープラーニングにおける文脈解析と常識推論の課題
近年、ディープラーニングは自然言語処理分野において飛躍的な進歩を遂げてきました。
しかし、文脈解析や常識推論といった高度な自然言語処理タスクにおいては、依然として多くの課題が残されています。
本記事では、ディープラーニングにおける文脈解析と常識推論の課題について、詳細に解説していきます。
1. 文脈解析の課題
文脈解析とは、文章全体の意味を理解し、個々の単語や文節の意味を文脈に基づいて解釈するタスクです。
しかし、ディープラーニングモデルは、文脈情報を十分に考慮することができず、以下のような課題が発生します。
誤解: 文脈を無視して単語の意味を解釈するため、誤解が生じる可能性があります。
曖昧性: 文脈によって単語の意味が異なる場合、正しい解釈が難しい場合があります。
複雑な文脈: 長文や複雑な文脈の場合、文脈情報を全て把握することができず、誤った解釈をしてしまう可能性があります。
2. 常識推論の課題
常識推論とは、文脈に明示的に記述されていない情報を、自身の知識や常識に基づいて推論するタスクです。
しかし、ディープラーニングモデルは、常識的な知識や推論能力を備えておらず、以下のような課題が発生します。
非明示的な情報: 文脈に明示的に記述されていない情報を読み取ることができず、推論が難しい場合があります。
常識の獲得: 常識的な知識を学習するには、膨大なデータが必要となり、学習が困難です。
論理的な推論: 論理的な推論を行うには、複雑な推論能力が必要となり、実現が難しいです。
3. 課題克服に向けた取り組み
文脈解析と常識推論の課題克服に向け、様々な研究が進められています。
代表的な取り組みは以下の通りです。
知識ベースの利用: 知識ベースを用いることで、常識的な知識をモデルに学習させることができます。
注意機構の導入: 注意機構を用いることで、モデルが文脈の中で最も重要な情報に注目できるようにすることができます。
多段階学習: 多段階学習を用いることで、モデルを段階的に学習させることができます。
画像キャプション生成とは
画像キャプション生成は、画像の内容を自然言語で説明するタスクです。具体的には、画像を分析し、その内容を理解した上で、簡潔で分かりやすい文章を生成します。
画像キャプション生成は、近年注目を集めている自然言語処理の分野の一つです。画像検索やソーシャルメディア、教育など、様々な分野での応用が期待されています。
End-to-End 音声認識とは?
End-to-End(E2E)音声認識は、近年注目を集めている音声認識の新しい手法です。従来の音声認識とは異なり、音声特徴量抽出、音素認識、言語モデルという複数のモジュールを別々に扱うのではなく、単一のニューラルネットワークで音声から直接テキストを出力します。
E2E 音声認識の特徴
E2E 音声認識は、以下の特徴を持っています。
シンプルなアーキテクチャ: 単一のニューラルネットワークで構成されるため、従来の音声認識システムよりもシンプルで分かりやすいアーキテクチャとなっています。
高い精度: 従来の音声認識システムと同等の、あるいはそれ以上の精度を達成することが可能です。
学習効率が高い: 音声特徴量抽出や音素認識などのモジュールを個別に学習する必要がないため、学習効率が高いという特徴があります。
柔軟性が高い: ニューラルネットワークの構造を変更することで、様々な音声認識タスクに適用することができます。
E2E 音声認識の課題
E2E 音声認識は、非常に有望な技術ですが、以下の課題も存在します。
学習データ量が多い: 従来の音声認識システムよりも多くの学習データが必要となります。
計算コストが高い: 単一のニューラルネットワークで音声から直接テキストを出力するため、従来の音声認識システムよりも計算コストが高くなります。
解釈可能性が低い: ニューラルネットワークの内部構造が複雑なため、その動作を理解することが難しいという課題があります。
E2E 音声認識の応用例
E2E 音声認識は、様々な分野で応用されています。代表的な応用例としては、以下のようなものがあります。
音声認識システム: スマートフォンやスマートスピーカーなどの音声認識システムに利用されています。
音声翻訳: 音声をリアルタイムで翻訳する音声翻訳システムに利用されています。
音声アシスタント: 音声で操作できる音声アシスタントに利用されています。
CNTK(Microsoft Cognitive Toolkit)
CNTK(Microsoft Cognitive Toolkit)は、Microsoftが開発したディープラーニングフレームワークで、以前はCNTKと呼ばれていました12。このフレームワークは、ディープニューラルネットワークの学習と評価を行うためのライブラリで、GPUやネットワークの利用による並列処理により実行効率を向上させる機能が実装されています12。
CNTKの主な特徴は以下の通りです1:
パフォーマンス:CNTKは、サーバ・GPUのパラレル学習に最適化することを念頭に設計されています1。その結果、他のディープラーニングフレームワークと比較して高速な学習・実行が可能です。
スケーラビリティ:CNTKは、単一マシンに搭載されたGPUの数に縛られることなくモデルを学習させることができます。これにより、大規模なデータセットに対しても効率的な学習が可能となります。
1-bit SGD:CNTKには、1-bit SGDという機能があります。これは、勾配を1bitにまで量子化することで通信コストを削減し、ニューラルネットワークの訓練時の学習速度を大幅に向上させる機能です。
多様なインターフェース:CNTKは、C++・Python・.NET・BrainScriptをサポートしており、様々なプログラミング言語から利用することができます。
これらの特性により、CNTKは、ディープラーニングの研究や実用的なアプリケーション開発に広く利用されています。また、CNTKはオープンソースであり、GitHub上で公開されているため、誰でも無償で利用することが可能です。
Choice Of Plausible Alternatives (COPA)
Choice Of Plausible Alternatives (COPA) は、自然言語処理 (NLP) の分野で使用されるデータセットと評価指標であり、システムの常識的因果推論を実行する能力を評価します。
COPA の概要
データセット: COPA は、状況を説明する前提文と、2 つの代替フォローアップ文 (オプション) で構成される質問のコレクションで構成されています。 1 つのオプションは、常識的な推論に基づいてよりありそうな続行であり、もう 1 つはそうではありません。
評価指標: 評価対象のシステムは、各質問のよりありそうな代替案を選択するよう指示されます。 そのパフォーマンスは精度によって測定され、因果関係を推論するために常識知識をどれだけ活用できるかを示します。
Choice Of Plausible Alternatives (COPA) は、人間と同じように常識を使って、自然言語を理解し、処理する能力を評価するために使用される知能テストの一種です。
このテストでは、以下の2つの要素を評価します。
常識知識: 物理法則、人間関係、社会規範など、世界に関する一般常識的な知識
推論能力: 常識知識に基づいて、新しい情報や状況から論理的に導き出す能力
COPA テストの形式
COPA テストは、通常、以下のような形式で構成されます。
前提: 状況を説明する文
オプション: 2 つの代替フォローアップ文
テスト参加者は、前提に基づいて、よりありそうな代替案を選択する必要があります。
WSC
WSC は、Within Sentence Coreference の略称です。これは、文内照応 とも呼ばれ、同一の文の中で、異なる言語表現を使って同じものを指し示す関係 を指します。
例えば、以下の文を考えてみましょう。
この文では、2番目の「本」は、1番目の「本」と同じものを指し示しています。これは、照応関係 と呼ばれます。
WSC は、この照応関係を自動的に解析する手法の一つです。 WSC は、文法規則や統計的な手法などを用いて、文中のどの言語表現が同じものを指し示しているのかを特定します。
WSC は、以下のような様々な自然言語処理タスクに役立ちます。
機械翻訳: 翻訳システムは、WSC を使って、原文中の名詞や代名詞が翻訳文の中でどのように表現されるべきかを判断することができます。
情報抽出: 情報抽出システムは、WSC を使って、文書中の重要なエンティティ (人名、地名、組織名など) を識別し、それらのエンティティ間の関係を抽出することができます。
質問応答: 質問応答システムは、WSC を使って、質問中の名詞や代名詞が文書中のどのエンティティに関連しているのかを判断することができます。
WSC の種類
WSC には、様々な種類があります。代表的な種類としては、以下のものがあります。
言及型照応: 名詞や代名詞などの言語表現が、文中のどのエンティティに言及しているのかを特定します。
属性型照応: 文中の形容詞や副詞などの言語表現が、どのエンティティの属性を説明しているのかを特定します。
イベント型照応: 文中の動詞や副詞などの言語表現が、どのイベントを表現しているのかを特定します。
WSC の課題
WSC は、様々な自然言語処理タスクに役立つ強力な手法ですが、以下のような課題も存在します。
曖昧性の問題: 文中の言語表現が複数通りに解釈できる場合、WSC は正しい照応関係を特定できないことがあります。
談話文脈の考慮: WSC は、文中の言語表現だけでなく、談話文脈も考慮して照応関係を特定する必要があります。
言語依存性: WSC は、言語によって異なる文法規則や統計的な手法を用いる必要があります。
WSC の研究
WSC は、自然言語処理の分野で活発に研究されているテーマです。近年では、様々な手法を用いて、WSC の精度を向上させる研究が進められています。
GNMT: Google Neural Machine Translation
GNMT (Google's Neural Machine Translation) とは、2016 年 11月に Google が導入したニューラル機械翻訳システムです。従来の統計的機械翻訳 (SMT) システムに代わるもので、より流暢で正確な翻訳を実現することを目指しています。
GNMT の仕組み
GNMT は、エンコーダ - デコーダ アーキテクチャ を採用しています。
エンコーダ: 入力言語の文を処理し、その意味をベクトル表現に変換します。
デコーダ: エンコーダから出力されたベクトル表現に基づいて、出力言語の単語を生成していきます。
GNMT は、従来の SMT システムと比較して以下の特徴を持っています。
長期依存関係の学習: ニューラルネットワークの特性を利用して、文中の単語間の長期的な依存関係をより効果的に学習することができます。
文脈の考慮: 翻訳を行う際に、文脈をより適切に考慮することができるため、より自然な表現の翻訳が可能になります。
ゼロショット翻訳: 訓練に使用していない言語ペア間でも翻訳を行うことができます。(実用レベルの精度はまだの場合が多いです)
GNMT の利点
翻訳精度向上: 従来の SMT システムと比較して、より正確で流暢な翻訳を実現することができます。
汎化性向上: 訓練に使用しなかった言語ペアに対しても、ある程度の翻訳を行うことができます。
学習効率向上: ニューラルネットワークの特性により、大量のデータから効率的に学習を行うことができます。
GNMT の課題
計算コスト: ニューラルネットワークの計算量が多いため、SMT システムよりも計算コストが高くなります。
学習データ: 高性能な翻訳モデルを構築するためには、大量の学習データが必要となります。
解釈可能性: ニューラルネットワークはブラックボックスと呼ばれることが多く、翻訳結果に対する解釈が難しい場合があります。
RNNLM型デコーダにおける過生成と生成不足:主要な課題と解決策
RNNLM型デコーダは、機械翻訳や要約生成など、様々な自然言語処理タスクにおいて広く使用されています。しかし、RNNLM型デコーダには、過生成と生成不足という2つの主要な課題があります。
1. 過生成
過生成とは、必要以上の単語やフレーズを生成してしまう問題です。これは、RNNLM型デコーダが文脈を誤解釈したり、学習データに含まれていない冗長な表現を生成したりすることが原因で起こります。
過生成の例
機械翻訳:入力文が「I went to the store.」の場合、出力文が「I went to the store to buy groceries.」のように、不要な情報を含んでしまう。
要約生成:長い文書の要約を生成する場合、重要な情報が省略されてしまう。
過生成への対策
ビームサーチ: 生成過程において、最も確率の高い部分列のみを保持することで、過剰な生成を抑制する。
長さ制限: 生成する単語数に制限を設けることで、冗長な表現を抑制する。
教師あり学習: 正しい出力例を用いてモデルを学習することで、過剰な生成を抑制する。
2. 生成不足
生成不足とは、十分な単語やフレーズを生成できない問題です。これは、RNNLM型デコーダが文脈を正しく理解できなかったり、学習データに含まれていない新しい表現を生成できなかったりすることが原因で起こります。
生成不足の例
機械翻訳:入力文が「I love my cat.」の場合、出力文が「I cat.」のように、文法的に誤った文を生成してしまう。
要約生成:長い文書の要約を生成する場合、重要な情報がすべて含まれていない。
生成不足への対策
多様な学習データ: さまざまな表現を含む学習データを用いることで、モデルの表現力を向上させる。
教師あり学習: 正しい出力例を用いてモデルを学習することで、生成不足を抑制する。
注意機構: 生成過程において、文脈に最も関連性の高い部分にのみ焦点を当てることで、生成不足を抑制する。
まとめ
RNNLM型デコーダは、自然言語処理における強力なツールですが、過生成と生成不足という課題があります。これらの課題を克服するためには、様々な手法を用いてモデルを改善することが重要です。
マルチエージェントシミュレーション
マルチエージェントシミュレーションは、複数の「エージェント」(個々の行動主体)が相互に影響を及ぼしながら行動する様子をシミュレーションする手法です
マルチエージェントシミュレーションの主な特徴
自律性: 各エージェントは、独自の目標やルールに基づいて自律的に行動します。エージェントはそれぞれ環境からの情報を受け取り、自分の判断で最適な行動を選択します。
局所的な視点: 各エージェントは、全体のシステムや他のエージェントの状態を完全には把握していません。通常、エージェントは限られた情報のみを基に行動し、その行動が全体のシステムにどのような影響を与えるかは局所的な視点からのみ推測されます。
複雑な相互作用: エージェント間の相互作用は非常に複雑で、それによって予測困難なダイナミクスや現象が発生することがあります。エージェントが協力したり競争したりすることで、新たなパターンや秩序が生まれることがあります。
適応性: 環境の変化に応じて、エージェントは自身の戦略を変更したり、新しい行動規則を学習したりすることができます。これにより、システム全体としても進化し続けることができます。
マルチエージェントシミュレーションの応用例
交通システム: 自動運転車や一般車両をエージェントとしてモデル化し、交通流のシミュレーションや交通管理の最適化を行います。
経済モデル: 経済市場をエージェントベースでモデル化し、消費者、企業、規制機関などの相互作用を通じて市場ダイナミクスを分析します。
社会科学: 社会的相互作用や文化の進化をエージェントベースモデリングで研究し、集団行動や意思決定のメカニズムを解析します。
エコロジー: 動植物の集団や生態系をエージェントとしてシミュレーションし、種間の相互作用や環境への適応戦略を研究します。
重回帰分析と決定係数:わかりやすい解説
重回帰分析は、目的変数と複数の説明変数の関係を分析する統計手法です。
例: ある会社の売上高を分析する場合、広告費、顧客数、経済指標などを説明変数として、売上高を目的変数として重回帰分析を行うことができます。
重回帰分析では、各説明変数が売上高にどの程度影響を与えているかを数値で表します。
式:
売上高 = 定数項 + 説明変数1係数 * 説明変数1 + 説明変数2係数 * 説明変数2 + ... + 誤差項
決定係数 (R^2) は、モデルの説明力を表す指標です。
0から1までの値をとり、1に近いほど、モデルが売上高の変動を説明できていることを示します。
例:
R^2 = 0.8: 説明変数1、説明変数2、... が、売上高の変動の80%を説明している
R^2 = 0.5: 説明変数1、説明変数2、... が、売上高の変動の**50%**を説明している
注意点:
決定係数は、説明変数の数を増やすと単純に大きくなる傾向があります。
決定係数だけでモデルの良し悪しを判断するのは避けるべきです。
重回帰分析と決定係数の活用例:
マーケティング: 広告効果を分析し、効果的な広告戦略を立案
経済分析: 経済指標と株価の関係を分析し、投資判断の参考に
教育: 生徒の学習成績と学習時間、家庭環境などの関係を分析し、効果的な教育方法を検討
まとめ:
重回帰分析と決定係数は、様々な現象を分析し、因果関係を推測するのに役立つツールです。
RMSE: 二乗平均平方根誤差
RMSE (Root Mean Squared Error) は、予測値と実際の値の誤差の大きさを表す指標です。日本語では、二乗平均平方根誤差と呼ばれます。
主に何に使われる?
RMSE は、回帰分析や機械学習などの分野で、モデルの予測精度を評価するのに広く使われます
k近傍法:詳細解説
k近傍法(k-Nearest Neighbors, kNN)は、教師あり学習における分類と回帰問題でよく使用される非パラメトリックな機械学習アルゴリズムです。 kNNは、新しいデータ点のラベルを、そのデータ点に最も近いk個の訓練データ点のラベルに基づいて予測します。
1. k近傍法の仕組み
k近傍法の仕組みは以下の通りです。
訓練データとテストデータの準備: 訓練データは、すでにラベル付けされたデータのセットです。 テストデータは、ラベルが未知のデータのセットです。
距離の計算: テストデータ点と各訓練データ点間の距離を計算します。 一般的に、ユークリッド距離やマンハッタン距離などの距離指標が使用されます。
k近傍の選択: テストデータ点に最も近いk個の訓練データ点を選択します。 これらの訓練データ点をk近傍と呼びます。
ラベルの予測: k近傍の多数決に基づいて、テストデータ点のラベルを予測します。 分類問題の場合は、k近傍の中で最も頻繁に出現するラベルをテストデータ点のラベルとします。 回帰問題の場合は、k近傍の平均値をテストデータ点の値とします。
2. k近傍法の利点と欠点
利点
シンプルで理解しやすい: アルゴリズムがシンプルで、実装が比較的簡単です。
非パラメトリック: データ分布を仮定する必要がないため、柔軟性に優れています。
外れ値に強い: 外れ値の影響を受けにくいという特徴があります。
欠点
計算量が多い: データ数が多くなると、計算量が多くなります。
距離指標の選択に依存する: 距離指標の選択によって、結果が大きく変化する可能性があります。
高次元データへの適用が難しい: 高次元データの場合、適切なk近傍を見つけることが難しくなります。
3. k近傍法のパラメータ
k近傍法には、kというパラメータがあります。 kは、k近傍の数を表します。 kの値は、経験則や交差検証などの方法で決定されます。 一般的に、kは奇数に設定されます。
kの値が小さい場合、モデルは過学習しやすくなります。 過学習とは、訓練データに対しては高い精度で予測できるものの、未知のデータに対しては精度が低くなる現象です。
kの値が大きい場合、モデルは欠学習しやすくなります。 欠学習とは、訓練データに対してさえも精度が低くなる現象です。
4. k近傍法の応用例
k近傍法は、様々な分野で応用されています。 以下に、いくつかの例を挙げます。
画像認識: 画像内のオブジェクトを分類したり、画像内のオブジェクトの位置を検出したりするのに用いられます。
情報検索: ウェブページの関連性を評価したり、ユーザーの検索意図を推測したりするのに用いられます。
推薦システム: ユーザーに合った商品やサービスを推薦するのに用いられます
異常検知:外れ値を検出
音声認識技術の評価尺度:WERの詳細解説
WER(Word Error Rate)は、音声認識技術の最も一般的な評価尺度です。 これは、音声認識システムが出力した単語列と、真の単語列との誤差率をパーセンテージで表したものです。
WERの利点と欠点
利点
シンプルで理解しやすい: WERは、計算式がシンプルで理解しやすい指標です。
汎用性が高い: WERは、様々な音声認識システムに適用することができます。
欠点
すべての誤りを等しく扱う: WERは、すべての誤りを等しく扱い、文法誤りや意味誤りを考慮しません。
発音誤りや聞き取り間違いを考慮しない: WERは、発音誤りや聞き取り間違いを考慮しません。
WER以外の評価尺度
WER以外にも、以下のような評価尺度があります。
CER(Character Error Rate): 文字レベルの誤差率
PER(Phoneme Error Rate): 音素レベルの誤差率
MERT(Minimum Error Rate Training): 訓練データにおける誤差率を最小化する手法
BLEU(BiLingual Evaluation Understudy): 機械翻訳の評価尺度
まとめ
WERは、音声認識技術の代表的な評価尺度ですが、すべての誤りを等しく扱うという欠点があります。 音声認識システムの精度を評価する際には、WER以外にも、CER、PER、MERT、BLEUなどの評価尺度を組み合わせて検討することが重要です。
waymo(ウェイモ):自動運転技術の先駆者
ウェイモは、カリフォルニア州マウンテンビューに本社を置く、アメリカの自動運転技術会社です。 2009年にGoogle自動運転車プロジェクトとして設立され、2016年にAlphabet Inc.の子会社となりました。 ウェイモは自動運転車の開発において世界をリードする存在であり、その技術は世界中の都市でテストされています。
アンドリュー・ン:人工知能研究の第一人者
アンドリュー・ン(Andrew Ng)は、中国系アメリカ人の計算機科学者、人工知能研究者、投資家、起業家です。
経歴
1976年4月18日、イギリス ロンドン生まれ
カリフォルニア大学バークレー校で電気工学士号と修士号を取得
スタンフォード大学でコンピュータサイエンス博士号を取得
2006年、Googleに入社し、Google Brainプロジェクトの立ち上げに貢献
2011年、Courseraを共同設立し、世界最大級のオンライン教育プラットフォームを立ち上げる
2014年、Landing AIを設立し、人工知能スタートアップ企業を育成
2018年、Baiduの最高技術責任者に就任
2021年、Landing AIをAI Fundに売却
2022年、Landing AIのCEOに再任
MOOCs: 大規模公開オンライン講座
MOOCs は、 Massive Open Online Courses の略で、日本語では 大規模公開オンライン講座 と呼ばれます。
特徴
大規模: 多くの受講生が同時に受講できるよう設計されています。
公開: インターネットを介して誰でも無料で (もしくは低額で) 受講できます。
オンライン: インターネットを通じて受講でき、時間や場所にとらわれずに学習できます。
講座: 大学教授や専門家による講義ビデオ、教材、課題などで構成されています。
メリット
世界中の質の高い講義を受講できる
無料で (もしくは低額で) 学べる
自分のペースで学習できる
世界中の人々と交流できる機会がある (場合によっては)
デメリット
自己学習能力が求められる (締切や強制力がない)
受講生同士の交流が限定的 (講座によっては)
信頼できる機関が運営している講座を選ぶ必要がある
有名な MOOCs プラットフォーム
Coursera (https://www.coursera.org/)
edX (https://www.edx.org/)
Udacity (https://www.udacity.com/)
FutureLearn (https://www.futurelearn.com/)
日本: JMooc (https://www.jmooc.jp/en/) など
各国の経済成長戦略
日本: 新産業構造ビジョン
英国: RAS2020戦略
ドイツ: デジタル戦略2025
中国: インターネットプラスAI3年行動実施法案
1. 日本:新産業構造ビジョン
正式名称は「第6次産業構造ビジョン」です。
2021年3月に閣議決定されました。
人工知能、ロボット、データなどの先端技術を活用した新たな産業の育成を重点項目としています。
2. 英国:RAS2020戦略
正式名称は「Robotics and Autonomous Systems Strategy 2020」です。
2020年1月に発表されました。
ロボットや自律システムの開発・利用を促進し、経済成長と社会課題の解決を目指す戦略です。
3. ドイツ:デジタル戦略2025
正式名称は「デジタル戦略2025」です。
2020年11月に発表されました。
デジタル技術を活用した社会の変革を推進し、ドイツをデジタル化の先駆者にすることを目指しています。
4. 中国:インターネットプラスAI3年行動実施法案
正式名称は「インターネットプラス人工知能三年行動計画実施方案」です。
2017年7月に国務院によって発表されました。
2020年までに中国を世界をリードするAI強国にすることを目指した計画です。
補足情報
上記の政策は、いずれも人工知能やロボットなどの先端技術を活用した新たな産業の育成を目的としています。
各国は、それぞれの課題や強みを活かした政策を展開しています。
今後、これらの政策がどのように実行され、どのような成果が得られるのか注目されます。
AIの社会実装に関連するリスク
1. プライバシーとデータ保護のリスク
AIシステムは大量の個人データを処理することが多く、これによりプライバシー侵害やデータ漏洩のリスクが生じます。データの収集、保管、そして利用の各段階で厳格なデータ保護策を講じる必要があります。
2. 倫理的および社会的リスク
AIの判断が倫理的な基準や公正性に則っているか、また、AIが社会に悪影響を及ぼす可能性がないかどうかは、重要な検討事項です。特に、バイアスの問題はAIシステムが公平であることを確保する上で重要です。
3. 安全性および信頼性のリスク
AIシステムが誤動作を起こしたり、操作ミスによって不正確な結果を生じさせるリスクも考慮する必要があります。これは、自動運転車の安全性の問題や、医療分野での診断支援システムの信頼性など、多岐にわたります。
4. 経済的および雇用に関するリスク
AI技術の導入により、労働市場に変革がもたらされ、特定の職種が不要になる可能性があります。また、AIによる自動化が進むことで、新たなスキルギャップが生じる可能性も考慮しなければなりません。
G検定対策:AIに関する時事問題50選
1. 倫理・法規制
1.1.EUにおけるAI規制「AI法」の概要と主要な内容を説明してください。
EUにおけるAI規制「AI法」の概要と主要な内容
2021年4月に欧州委員会が提案した「AI法」は、世界で初めてAIに関する包括的な規制となるものです。
主要な内容
高リスクAI(人命や健康、安全、環境などに重大な影響を与えるAI)の使用を禁止
中リスクAI(人命や健康、安全などに影響を与えるAI)に対して、透明性、説明責任、人権尊重などを義務化
低リスクAI(日常生活に影響を与えるAI)に対して、安全要件などを設定
目的
AIによる倫理的な問題を解決し、社会に安心と安全をもたらす
欧州におけるAI開発と利用を促進し、欧州をAIのグローバルリーダーに位置づける
1.2.AIによる倫理的な問題と、それを解決するための取り組みについて論じてください。
AIによる倫理的な問題と、それを解決するための取り組み
AIの発展に伴い、倫理的な問題が次々と浮き彫りになっています。
主な倫理的な問題
公平性・差別: AIシステムにおけるデータバイアスが、特定の人種や性別を差別する結果につながる可能性
説明責任: AIシステムの判断プロセスが不透明で、責任の所在が不明確になる可能性
プライバシー: AIシステムによる個人情報の収集・利用が、プライバシー侵害につながる可能性
安全保障: AI兵器の開発・使用が、国際的な安全保障に悪影響を与える可能性
解決に向けた取り組み
倫理ガイドラインの策定: AI開発・利用における倫理的な原則を定める
AI倫理委員会の設置: AI倫理に関する議論を促進し、倫理的な問題を解決するための指針を策定
AI教育の推進: AI倫理に関する知識や理解を深めるための教育を推進
国際的な協力: AI倫理に関する国際的なルール作りを推進
1.3.AI開発におけるデータバイアスと、その影響について説明してください。
AIシステムは、学習に使用したデータに含まれるバイアスを反映してしまう可能性があります。
データバイアスの種類
属性バイアス: 性別、人種、年齢、出身地など、属性に基づいたバイアス
選択バイアス: データ収集方法の偏りによるバイアス
確認バイアス: 既存の偏見を強化するような情報のみを収集するバイアス
影響
差別: 特定の人種や性別を不当に扱ったり、不利益を与えたりする可能性
誤判断: 偏ったデータに基づいて、誤った判断を下す可能性
社会不安: AIシステムへの不信感や不安感を生じさせる可能性
対策
多様なデータの収集: 偏りのないデータセットを用いる
データバイアスの検出・修正: 機械学習モデルにおいて、データバイアスを検出して修正する
説明責任の確保: AIシステムの判断プロセスを透明化し、説明責任を確保
1.4.AI兵器の禁止に向けた国際的な動きと、今後の課題について論じてください。
AI兵器の禁止に向けた国際的な動きと、今後の課題
国際的な動き
EU: AI兵器の開発・使用を禁止する条約の策定を検討
国連: AI兵器に関する専門家グループを設置
民間団体: AI兵器の禁止を求めるキャンペーンを実施
今後の課題
国際的な合意形成: すべての国がAI兵器の禁止に合意する必要がある
技術的な検証: AI兵器を明確に定義し、識別できる技術を開発する必要がある
法執行: AI兵器の開発・使用を禁止する法制度を整備する必要がある
1.5.AIと著作権の関係性と、著作権侵害の防止策について説明してください。
AIと著作権の関係性と、著作権侵害の防止策
AIによる創作活動が活発化する中、AIと著作権の関係性について議論が活発になっています。
問題点
AIが生成した作品が、著作権法上の著作物と認められるか
AIが既存の作品を学習・利用することで、著作権侵害が発生するか
対策
著作権法の改正: AIと著作権の関係性を明確にする
AIによる創作活動に関するガイドライン: 著作権侵害のリスクを回避するための指針を策定
技術的な対策: AIによる著作権侵害を検知・防止する技術の開発
2. 技術・開発
2.1ディープラーニングの仕組みと、近年における主な進歩について説明してください。
仕組み
ディープラーニングは、ニューラルネットワークと呼ばれる人工知能モデルを用いて学習を行う手法です。
ニューラルネットワークは、人間の脳神経細胞を模倣した構造を持つ
大量のデータを学習することで、複雑なパターンを認識し、予測や判断を行うことができる
近年における主な進歩
大規模なデータセットと高性能な計算機技術の登場により、学習精度が大幅に向上
画像認識、音声認識、自然言語処理などの分野で、人間レベルの成果を達成
自動運転、医療診断、金融サービスなど、様々な分野で実用化
2.2自然言語処理技術の最新動向と、具体的な応用例を3つ挙げてください。
最新動向
Transformerと呼ばれるニューラルネットワークアーキテクチャの登場により、自然言語処理の精度が大幅に向上
大規模言語モデル(LLM)の開発により、人間レベルの自然言語生成が可能に
多言語翻訳、質問応答、要約生成など、様々なタスクで成果を上げている
具体的な応用例
チャットボット: 顧客との対話や情報提供
翻訳サービス: 言語間の翻訳
要約生成: 長文を短文に要約
文章校正: 文法やスペルミスを修正
テキストマイニング: 大量テキストから意味のある情報を取り出す
セマンティックウェブ: 情報間の意味的な関係を表現
2.3コンピュータビジョン技術の最新動向と、具体的な応用例を3つ挙げてください。
最新動向
ディープラーニング技術の進歩により、コンピュータビジョンの精度が大幅に向上
画像認識、物体検出、動画分析など、様々なタスクで成果を上げている
自動運転、顔認証、医療画像診断など、様々な分野で実用化
具体的な応用例
自動運転: 道路上の物体や障害物を認識し、安全運転を支援
顔認証: 個人を特定し、セキュリティを強化
医療画像診断: 病変を検出し、診断を支援
監視カメラ: 不審者を検知し、犯罪防止
2.4AIチップの開発状況と、その市場動向について説明してください。
開発状況
CPUやGPUよりもAI処理に特化したAIチップが開発されている
代表的なAIチップとしては、NVIDIAのGPU、GoogleのTPU、IntelのMovidius Myriad Xなどがある
AIチップの性能は年々向上しており、より高性能なAI処理が可能になっている
市場動向
AIチップの市場は急速に拡大しており、2025年には数千億ドル規模に達すると予測されている
主要なAIチップメーカーは、データセンター、エッジデバイス、スマートフォンなど、様々な市場に向けてAIチップを開発・販売している
2.5量子コンピュータとAIの融合による可能性と、課題について論じてください。
可能性
量子コンピュータの並列処理能力により、従来のコンピュータでは解けない複雑な問題を解くことができる
AIアルゴリズムと組み合わせることで、AIの性能を大幅に向上させることができる
医薬開発、材料科学、金融工学など、様々な分野での革新をもたらす可能性
課題
量子コンピュータの実用化には、技術的な課題やコスト面での課題がある
量子コンピュータのプログラミングは非常に複雑で、専門知識が必要
量子コンピュータのセキュリティ対策も課題
3. 社会・経済
3.1AIによる自動運転技術の現状と、今後の展望について説明してください。
現状
レベル3と呼ばれる条件付き自動運転が一部の国で実現
レベル4と呼ばれる高度自動運転の開発が進み、実用化に向けた試験が行われている
レベル5と呼ばれる完全自動運転の実現には、技術的な課題や法制度の整備が必要
今後の展望
自動運転技術の進歩により、交通事故の減少や渋滞緩和などが期待されている
自動運転車の普及により、物流業やタクシー業などのビジネスモデルが大きく変化する可能性
自動運転車の倫理的な問題や、サイバーセキュリティ対策なども課題
3.2AIによる医療診断の精度と、医療現場における課題について論じてください。
精度
AIは、画像診断や病理診断などにおいて、医師と同等以上の精度で診断できる場合がある
AIは、大量のデータを学習することで、人間の経験や知識では見逃してしまうような微細な病変を検出できる
AIは、診断結果を客観的に評価することができる
課題
AIによる診断結果を医師が理解し、説明できる必要がある
AIによる診断結果の信頼性を検証する必要がある
AIによる診断結果に基づいて、適切な治療を行うための医療体制を整備する必要がある
3.3AIによる教育への活用と、その効果と課題について説明してください。
効果
個々の生徒に合わせた学習を提供することができる
生徒の理解度をリアルタイムで把握し、指導を調整することができる
教員の負担を軽減し、より質の高い教育を提供することができる
課題
AIによる教育が、画一的な教育につながる可能性
AIによる教育が、教員の役割を低下させる可能性
AIによる教育が、倫理的な問題を引き起こす可能性
3.4AIによる金融サービスへの活用と、金融システムへの影響について論じてください。
活用
ローン審査や投資判断などの自動化
顧客情報の分析に基づいたマーケティング
詐欺検知やマネー laundering 対策
影響
金融機関の業務効率化
新たな金融商品・サービスの開発
金融システムの脆弱性増加
金融格差の拡大
課題
AIによる金融サービスの倫理的な問題
AIによる金融サービスの透明性の確保
AIによる金融サービスの安全性確保
3.5AIによる労働市場への影響と、雇用問題への対策について論じてください。
影響
単純作業や事務作業がAIによって自動化され、雇用が失われる可能性
新たな職種が創出される可能性
労働者のスキルや知識のアップデートが必要
対策
職業訓練や教育プログラムの充実
社会保障制度の改革
労働市場の流動化
4. 企業・事例
4.1GoogleのAI戦略と、具体的な取り組みを3つ挙げてください。
AI戦略
AIを「全ての人に役立つ技術」と位置づけ、様々な分野での活用を目指している
AI技術の研究開発に積極的に投資している
オープンソースのAIツールやフレームワークを公開している
具体的な取り組み
Google Search: AIを活用して、検索結果の精度と関連性を向上
Google Translate: AIを活用して、翻訳精度を向上
Google Assistant: AIを活用した音声アシスタント
4.2AmazonのAI戦略と、具体的な取り組みを3つ挙げてください。
AI戦略
AIを「顧客体験の向上」と「事業効率化」に活用することを目指している
クラウドサービス「Amazon Web Services」上で、AIサービスを提供している
オープンソースのAIツールやフレームワークを公開している
具体的な取り組み
Amazon Rekognition: 画像認識・分析サービス
Amazon Polly: テキスト読み上げサービス
Amazon Lex: 音声認識・分析サービス
4.3MicrosoftのAI戦略と、具体的な取り組みを3つ挙げてください。
AI戦略
AIを「全ての人に役立つ技術」と位置づけ、様々な分野での活用を目指している
AI技術の研究開発に積極的に投資している
オープンソースのAIツールやフレームワークを公開している
具体的な取り組み
Microsoft Azure: クラウドサービス上で、AIサービスを提供
Microsoft Cognitive Services: 画像認識、音声認識、自然言語処理などのAIサービス
Microsoft Cortana: AIを活用した音声アシスタント
4.4中国におけるAI企業の台頭と、中国政府のAI政策について説明してください。
AI企業の台頭
近年、中国では多くのAI企業が台頭しており、世界的な競争力を備えている
代表的なAI企業としては、Baidu、Alibaba、Tencentなどがある
中国のAI企業は、政府からの支援を受けている
中国政府のAI政策
中国政府は、AIを国家戦略として位置づけ、積極的な投資と支援を行っている
2017年に発表された「新世代人工知能発展計画」では、2030年までにAI分野で世界をリードすることを目標としている
中国政府は、AI倫理に関するガイドラインも策定している
4.5日本のAI企業の現状と、今後の課題について論じてください。
現状
日本には、多くのAI企業が存在するが、世界的な競争力を持つ企業はまだ少ない
日本のAI企業は、研究開発に強みを持つ企業が多いが、事業化に課題がある
日本政府は、AI分野の投資と支援を強化している
課題
人材不足
データ不足
規制緩和
官民連携
人間中心のAI社会原則とは
人間中心のAI社会原則は、2019年3月に策定された日本の基本方針です。この原則は、AIの社会実装により実現すべきAI-Readyな社会の基本理念として、「人間の尊厳」、「多様性・包摂性」、「持続可能性」の3つの価値を尊重すべきとしています。
具体的には、以下の10の原則が定められています。
1. 人間の尊厳の尊重
AIは、人間の尊厳を尊重し、人権を侵害してはならない。
AIは、人間の判断や意思決定を代替するものではなく、人間の能力を補完するものと認識する。
2. 多様性・包摂性の尊重
AIは、あらゆる人々が平等に利用できるよう、多様性や包摂性を考慮した設計・開発を行う。
AIによる偏見や差別を防止するために、必要な措置を講じる。
3. 人間の安全・安心の確保
AIは、人間の安全・安心を確保するために、必要な安全対策を講じる。
AIによる事故や災害のリスクを評価し、適切な対策を講じる。
4. 説明責任と透明性の確保
AIの開発・運用過程における説明責任と透明性を確保するために、必要な措置を講じる。
AIの意思決定プロセスを説明できるようにし、説明責任を果たす。
5. 倫理規範の遵守
AIの開発・運用において、倫理規範を遵守し、倫理的な問題を事前に検討・評価する。
AI倫理に関する議論を促進し、社会的な合意形成を図る。
6. プライバシーの保護
AIの利用において、個人のプライバシーを保護するために、必要な措置を講じる。
個人情報保護に関する法令を遵守し、適切なデータ管理を行う。
7. 安全保障の確保
AIの悪用による安全保障上のリスクを評価し、適切な対策を講じる。
国際的な協力を通じて、AIの安全な開発・利用を促進する。
8. 消費者保護
AIの利用による消費者被害を防止するために、必要な措置を講じる。
消費者向けの情報提供や啓発活動を行う。
9. 社会基盤の強化
AIの社会実装に向けた社会基盤を整備し、人材育成や研究開発を推進する。
AIに関する国際的な連携を強化し、情報共有や協力体制を構築する。
10. 国際社会との連携
AIに関する国際的な規範形成やルール作りに積極的に貢献し、国際社会との連携を強化する。
AIに関する国際的な議論を促進し、共通の理解を醸成する。
人間中心のAI社会原則の重要性
人間中心のAI社会原則は、AIが社会に与える影響を考慮し、人間にとってより良い社会を実現するために策定されました。この原則は、AIの開発・運用に関わる全ての人々が共有すべき基本的な考え方であり、AI社会の健全な発展に不可欠なものです。
今後の課題
人間中心のAI社会原則を実現するためには、以下のような課題があります。
技術的な課題: AI技術の安全性や信頼性を向上させるための技術開発が必要。
倫理的な課題: AI倫理に関する議論を深め、社会的な合意形成を図る必要がある。
法的な課題: AIの開発・運用に関わる法制度を整備する必要がある。
社会的な課題: AIに対する理解や認識を高め、社会全体で取り組む必要がある。
これらの課題を克服するためには、政府、企業、研究機関、市民社会など、様々な主体が連携して取り組むことが重要です。
人間中心のAI社会原則の基本理念
人間中心のAI社会原則は、AIの利活用において、以下の3つの基本的な価値観を尊重し、実現することを目指しています。
人間の尊厳の尊重
AIの利活用は、人間の尊厳を損なうことがあってはならない。人間の基本的人権を尊重し、差別や偏見のない社会の実現を目指す。
人類の利益のための活用
AIは人類の利益のために活用されるべきであり、人類の幸福と持続可能な社会の実現に貢献する。
多様性と包摂性の推進
AIの利活用においては、性別、年齢、障がいの有無、国籍など、あらゆる人々の多様性を尊重し、誰一人取り残されることのない包摂的な社会の実現を目指す。
人間中心のAI社会原則の重要性
これらの基本理念は、AIの利活用において、人間の尊厳を損なわず、人類全体の利益につながるよう、多様性と包摂性を確保することの重要性を示しています。
具体的には、AIの利用が人権侵害につながらないよう、教育・リテラシーの向上、プライバシー保護、セキュリティ確保などが重要な原則として掲げられています。
企業や組織がAIを導入する際は、これらの基本理念を踏まえ、人間中心のAI社会の実現に向けて取り組むことが求められます。
Soft Actor-Critic(SAC)
Soft Actor-Critic(SAC)は、強化学習のアルゴリズムの一つで、最大エントロピー強化学習フレームワークに基づいています。SACは、オフポリシー(経験から学習する)アクタークリティック(行動者-評価者)型の深層強化学習アルゴリズムで、確率的な方策(行動戦略)を最適化します。
SACの主な特徴は、期待報酬の最大化と方策のエントロピー(ランダム性)の最大化のトレードオフを最大化することを目指す点です。これは探索と利用のトレードオフに密接に関連しています。エントロピーを増やすことで、より多様な探索が可能となり、後の学習を加速することができます。また、方策が早期に不良な局所最適解に収束するのを防ぐこともできます。
SACは、DDPG(Deep Deterministic Policy Gradient)やTD3(Twin Delayed Deep Deterministic policy gradient)のような手法と橋渡しをする形で、確率的な方策最適化とDDPGスタイルのアプローチを組み合わせています。SACでは、方策のエントロピー正則化(ランダム性を制御するための手法)が中心的な役割を果たしています。
具体的には、SACは以下のような特性を持っています:
SACはオフポリシーのアルゴリズムです。
SACは連続的な行動空間に対してのみ使用できます。
SACは並列化をサポートしていません。
Soft Actor-Critic(SAC) の応用
SAC は強化学習の分野で広く使われており、特に連続制御問題に適しています。ロボット制御やゲームエージェントの開発などで活用されています。
DEEP Residual Learning:詳細な説明
DEEP Residual Learning(ディープ残差学習)は、残差接続と呼ばれる手法を用いて、深層ニューラルネットワークの学習効率を高める手法です。従来の深層ニューラルネットワークでは、層が深くなるにつれて、勾配消失問題や過学習問題が発生しやすくなるという問題がありました。
DEEP Residual Learningでは、各層の入力と出力を直接足すことで、勾配消失問題を緩和し、学習効率を向上させます。
具体的には、以下の効果が期待できます。
学習効率の向上: 勾配消失問題を緩和することで、深層ニューラルネットワークでも効率的に学習することができます。
精度向上: 過学習問題を抑制することで、モデルの精度を向上させることができます。
汎化能力向上: 過学習問題を抑制することで、モデルの汎化能力を向上させることができます。
DEEP Residual Learningの仕組み
DEEP Residual Learningでは、各層にショートカット接続と呼ばれる接続を追加します。ショートカット接続は、各層の入力と出力を直接足す接続です。
このショートカット接続によって、各層の出力は前層の入力に影響を受けないようになります。
つまり、各層は前層の入力に加えて、残差のみを学習することになります。
この仕組みによって、勾配消失問題を緩和し、学習効率を向上させることができます。
DEEP Residual Learningの代表的なモデル
DEEP Residual Learningの代表的なモデルとして、以下のモデルがあります。
ResNet: 2015年に発表された、DEEP Residual Learningの代表的なモデルです。ImageNet ILSVRC 2015で優勝し、一躍脚光を浴びました。
Wide ResNet: ResNetの改良版です。ResNetよりもチャンネル数を増やすことで、精度を向上させています。
DenseNet: 2016年に発表された、DEEP Residual Learningのもう一つの代表的なモデルです。ResNetとは異なり、各層をすべて接続することで、学習効率を向上させています。
官民データ活用推進基本法の概要
官民データ活用推進基本法は、2016年12月に公布、2017年5月に施行された法律です。
この法律は、官公庁が保有するデータと民間企業が保有するデータを連携・活用することで、国民生活の利便性向上や経済社会の発展を図ることを目的としています。
具体的には、以下の施策を推進することを定めています。
官民データの標準化・共通化: 官公庁と民間企業が共通のフォーマットでデータを管理できるように、データの標準化・共通化を推進します。
官民データの安全管理: データ漏洩などのリスクを防止するために、官民データの安全管理を徹底します。
官民データの利活用環境の整備: データの利活用を促進するために、官民データの利活用環境を整備します。
官民データの倫理的利用: データの利活用において、倫理的な配慮を徹底します。
官民データ活用推進基本法におけるオープンデータ
官民データ活用推進基本法(平成28年法律第103号)では、オープンデータの推進について以下のように定められています。
1. オープンデータの定義
官民データ活用推進基本法では、オープンデータは以下のよう定義されています。
2. オープンデータの公開
官民データ活用推進基本法では、国及び地方公共団体は、原則として、自らが保有する官民データをオープンデータとして公開することを義務付けています。
ただし、以下の場合は、公開することが適当でないものとされています。
国民の生命、身体又は財産を保護するため
国の安全、公安又は秩序を維持するため
外交上の利益を保護するため
個人情報その他の権利利益を保護するため
公正な競争を確保するため
試験、検査その他の評価制度の適正な運用を確保するため
著作権その他の知的財産権を保護するため
その他、公益上の必要があると認められる場合
3. オープンデータの利用
オープンデータは、営利目的、非営利目的を問わず、誰でも自由に利用することができます。
利用にあたっては、以下の点に注意する必要があります。
著作権その他の知的財産権: オープンデータには、著作権その他の知的財産権が保護されている場合があります。利用にあたっては、著作権法などの法令を遵守する必要があります。
個人情報: オープンデータには、個人情報が含まれている場合があります。個人情報の取り扱いには、個人情報保護法などの法令を遵守する必要があります。
その他の注意事項: オープンデータの利用にあたっては、利用規約等に定められている注意事項を遵守する必要があります。
4. オープンデータの標準化
官民データ活用推進基本法では、オープンデータの標準化を推進することを定めています。
オープンデータの標準化を推進することで、官民データの利活用を促進することが目的です。
具体的には、以下の事項について標準化を推進しています。
メタデータ: オープンデータに関する情報(作成者、作成日時、データ形式など)
データ形式: オープンデータの形式(CSV、JSONなど)
API: オープンデータへのアクセス方法
5. オープンデータに関する情報の提供
官民データ活用推進基本法では、国及び地方公共団体は、オープンデータに関する情報を提供することを義務付けています。
具体的には、以下の情報を提供する必要があります。
公開しているオープンデータの一覧
各オープンデータの説明
オープンデータの利用方法
オープンデータに関する問い合わせ先
6. オープンデータに関する情報の検索
匿名化技術とは?
匿名化技術とは、個人を特定できないようにデータを加工する技術の総称です。具体的には、名前、住所、電話番号などの個人情報だけでなく、性別、年齢、職業、購買履歴などの属性情報も対象となります。
匿名化技術を用いることで、個人を特定するリスクを低減し、プライバシーを保護することができます。近年では、ビッグデータの利活用が進む中、匿名化技術の重要性も高まっています。
匿名化技術の種類
削除: 名前、住所、電話番号などの個人情報を直接削除する方法です。最もシンプルな方法ですが、情報量が大きく減ってしまうという欠点があります。
置換: 個人情報を他の情報に置き換える方法です。例えば、名前をランダムな文字列に置き換える、年齢を年齢層に置き換えるなどが考えられます。
一般化: 個人情報をより一般的な情報に置き換える方法です。例えば、住所を市区町村レベルに置き換える、年齢を5歳刻みに置き換えるなどが考えられます。
k-匿名化: データをk分割し、各分割内の個人がk人以上いるようにする方法です。kが大きければ大きいほど、匿名性のレベルは高くなりますが、情報量も減ってしまいます。
l-多様性: データをl分割し、各分割内の個人がl種類の属性を持つようにする方法です。k-匿名化よりも情報量を保ちながら匿名化することができます。
差分プライバシー: データにランダムなノイズを加える方法です。統計的な分析には影響を与えない程度にノイズを加えることで、個人のプライバシーを保護することができます。
匿名化技術の課題
匿名化技術を用いる際には、以下の点に注意する必要があります。
再特定リスク: 匿名化技術を用いても、他の情報と組み合わせることで個人が再特定される可能性があります。
情報量の減少: 匿名化技術を用いると、情報量が減少してしまうことがあります。
データの品質: 匿名化技術を用いると、データの品質が低下してしまうことがあります。
コスト: 匿名化技術を用いるには、コストがかかります。
限定提供データと営業秘密
限定提供データと営業秘密は、どちらも重要な情報保護制度ですが、それぞれ異なる概念と要件、保護対象、保護方法があります。以下、それぞれの概要と比較表、よくある質問にて詳細を説明します。
1. 概要
1.1 限定提供データ
限定提供データとは、業として特定の者に提供する情報として電磁的方法により相当量蓄積され、及び管理されている技術上又は営業上の情報(営業秘密を除く。)を指します。
要件
限定提供性: 特定の者にのみ提供されること
相当蓄積性: 電磁的方法により相当量蓄積されていること
電磁的管理性: アクセス制限等により管理されていること
保護対象: 技術情報、顧客リスト、市場調査データなど
保護方法: 契約による保護、技術的な保護措置、組織的な保護措置など
法令: 不正競争防止法に基づく
1.2 営業秘密
営業秘密とは、技術上又は営業上の秘密であって、当該事業者において採取された秘密の情報(公知のもの、公知になることが確実なもの、又は当該事業者以外の者が正当に知ることとなったものを除く。)を指します。
要件
秘密性: 一般に知られていないこと
技術性・営業性: 技術上又は営業上の価値を有すること
採取: 当該事業者において採取されたこと
保護対象: 製造方法、設計図、顧客リスト、ノウハウなど
保護方法: 契約による保護、技術的な保護措置、組織的な保護措置、刑事罰による保護など
法令: 不正競争防止法に基づく
日本のAI生成創作物の知財制度:詳細解説
**AI(人工知能)**が生成した創作物(以下「AI創作物」)の知財(知的財産)に関する制度は、日本においても近年注目を集めており、活発な議論がされています。
本記事では、日本のAI創作物の知財制度について、以下の内容を詳細に解説します。
1. AI創作物の著作権
2022年1月1日に施行された改正著作権法により、AI創作物は著作権法上の著作物として保護されるようになりました。
ただし、AI創作物の著作権は、AIが創作活動において実質的に人間と同等の役割を果たした場合にのみ認められます。
具体的には、AIが単に指示に従って創作活動を行うのではなく、独自の発想や判断に基づいて創作活動を行うことが必要です。
2. AI創作物の特許
AIが生成した発明は、特許法上の特許として保護される可能性があります。
ただし、特許保護を受けるためには、発明が新規性、進歩性、産業上の利用可能性を満たす必要があります。
具体的には、AIが生成した発明が従来の発明とは異なるものであり、技術的に進歩していること、そして、産業上利用できる可能性があることを証明する必要があります。
3. AI創作物の商標
AIが生成したロゴや商標は、商標法上の商標として保護される可能性があります。
商標保護を受けるためには、商標が識別力を有し、かつ公序良俗に反しないものである必要があります。
具体的には、AIが生成した商標が他の商標と区別することができ、かつ、公序良俗に反しない内容であることを証明する必要があります。
4. AI創作物の不正競争
AIが生成した創作物が、他人の著作権、特許、商標などを侵害している場合は、不正競争防止法に基づいて責任を問われる可能性があります。
不正競争防止法では、他人の知的財産を不正に利用することを禁止しており、AI創作物についても同様に適用されます。
5. AI創作物に関する法改正
AI創作物の知財制度は、今後さらに発展していくことが予想されます。
2024年以降には、AI創作物に関する新たな法改正が検討される可能性があります。
法改正の内容については、現時点では明らかになっていませんが、AI創作物の権利者と利用者にとってより明確で使いやすい制度となることが期待されています。
6. AI創作物に関する裁判例
AI創作物に関する裁判例は、まだ数多くありません。
しかし、今後AI創作物の利用が増加していくにつれて、AI創作物に関する裁判例も増えていくことが予想されます。
裁判例は、AI創作物の知財制度の解釈や適用を明確化していく上で重要な役割を果たします。
7. AI創作物に関する今後の課題
AI創作物の知財制度は、今後さらに発展していく必要があります。
主な課題としては、以下のものがあります。
AI創作物の権利帰属
AI創作物の利用許諾
AI創作物の責任分配
AI創作物のデータベース
AI創作物に関する国際的な協調
これらの課題を解決するためには、政府、企業、学術機関などが協力して取り組んでいくことが重要です。
AI生成創作物の知財制度:詳細解説と最新情報
**AI(人工知能)**が生成した創作物(以下「AI創作物」)の知財(知的財産)に関する制度は、近年急速に進化しており、世界各国で活発な議論がされています。
1. AI創作物の著作権
AI創作物が著作権法上の著作物として保護されるかどうかは、各国によって判断が分かれています。
**欧州連合(EU)**では、2023年9月に施行された「AI指令」において、AI創作物が著作権法上の著作物として保護される可能性を明示的に認めています。
一方、米国では、現時点ではAI創作物が著作権法上の著作物として保護されるという明確な判例は存在しません。
しかし、2022年には米国著作権局(US Copyright Office)が、AI生成画像の著作権保護に関するガイドラインを発表しており、AI創作物の著作権保護の可能性について議論が活発化しています。
2. AI創作物の特許
AIが生成した発明は、特許法上の特許として保護される可能性があります。
ただし、特許保護を受けるためには、発明が新規性、進歩性、産業上の利用可能性を満たす必要があります。
具体的には、AIが生成した発明が従来の発明とは異なるものであり、技術的に進歩していること、そして、産業上利用できる可能性があることを証明する必要があります。
3. AI創作物の商標
AIが生成したロゴや商標は、商標法上の商標として保護される可能性があります。
商標保護を受けるためには、商標が識別力を有し、かつ公序良俗に反しないものである必要があります。
具体的には、AIが生成した商標が他の商標と区別することができ、かつ、公序良俗に反しない内容であることを証明する必要があります。
4. AI創作物の不正競争
AIが生成した創作物が、他人の著作権、特許、商標などを侵害している場合は、不正競争防止法に基づいて責任を問われる可能性があります。
不正競争防止法では、他人の知的財産を不正に利用することを禁止しており、AI創作物についても同様に適用されます。
5. AI創作物のデータベース
AI創作物は、著作権法上の著作物、特許、商標などの知的財産として保護される可能性があります。
これらの知的財産を保護するために、AI創作物のデータベースを構築することが重要です。
AI創作物のデータベースは、AI創作物の権利者と利用者を結びつける役割を果たし、AI創作物の円滑な流通を促進することができます。
6. AI創作物に関する契約
AI創作物の制作、利用、販売などに関する契約は、民法に基づいて締結することができます。
AI創作物に関する契約には、著作権、特許、商標などの知的財産権に関する条項を明記することが重要です。
また、AI創作物の利用範囲、責任分担などについても明確に定めておく必要があります。
7. AI創作物に関する国際的な議論
AI創作物の知財制度は、世界各国で活発な議論がされています。
2023年5月には、世界知的所有権機関(WIPO)において、AI創作物の知財制度に関する国際的な協議が開催されました。
この協議では、AI創作物の著作権、特許、商標などの知的財産権に関する課題について議論され、今後の国際的なルール作りに向けた方向性が模索されました。
AAAI (Association for the Advancement of Artificial Intelligence)
AAAI (Association for the Advancement of Artificial Intelligence) は、人工知能 (AI) の分野における国際的な非営利学術団体です。 1979 年に設立され、AI の研究、開発、および応用を促進することを目的としています。 AAAI は、世界で最も権威のある AI 学会であり、AI 研究者が最新の成果を発表し、アイデアを共有する場となっています。
AAAI は、次のようなさまざまな活動を展開しています。
会議の開催: AAAI は毎年、AI に関する主要な国際会議である AAAI Conference を開催しています。この会議には、世界中から何千人もの研究者が参加します。
ジャーナルの発行: AAAI は、AI に関する主要な学術誌である AI Magazine を発行しています。この雑誌には、AI 研究の最新進歩に関する査読付き論文が掲載されています。
賞の授与: AAAI は、AI 研究に大きな貢献をした個人や組織に、さまざまな賞を授与しています。これらの賞には、AAAI フェローシップ、AAAI 優秀論文賞、AAAI インフラストラクチャ賞などがあります。
会員サービスの提供: AAAI は、AI 研究者にさまざまな会員サービスを提供しています。これらのサービスには、ニュースレター、割引、および会議への参加の機会が含まれます。
AAAI は、AI コミュニティにおける重要な組織であり、AI の分野における研究、開発、および応用を促進する上で重要な役割を果たしています。
OpenAI
OpenAI は、人工知能 (AI) 研究を行う非営利団体と営利会社からなる組織です。
設立: 2015年12月11日
代表者:
CEO: Sam Altman (2023年11月29日就任)
CTO: Mira Murati
President: Greg Brockman
OpenAI のしくみ
OpenAI は、主に以下の2つの組織で構成されています。
OpenAI Inc. (非営利団体): 人工知能の安全性と利益を確保することに重点を置いています。
OpenAI LP (営利会社): OpenAI Inc. の研究開発成果を商用化し、OpenAI Inc. の活動を資金面で支援しています。利益の分配上限額が設定されており、上限を超えた利益は OpenAI Inc. に還元されます。
OpenAI の活動内容
OpenAI は、以下の様な活動を行っています。
安全な人工知能の研究開発: 人工知能の安全性と倫理に重点を置いており、強力な人工知能が人類にとって脅威にならないように研究開発を進めています。
オープンソースでの研究成果の公開: 研究成果の一部をオープンソースで公開し、透明性とコミュニティの参加を促しています。
人工知能ツールの開発: 自然言語処理、コード生成、画像生成など、幅広い分野で人工知能ツールを開発しています。
大規模言語モデルの開発: GPT-3と呼ばれる大規模言語モデルを開発し、その能力を公開しています。GPT-3 は、人間が書いた文章と区別がつかないほどの文章を生成したり、コードを書いたりすることができる強力な言語モデルです。
ビジネスへの展開: OpenAI LP を通じて、開発した人工知能ツールを企業に提供するなど、ビジネス展開も行っています。
AI開発原則:概要と詳細解説
人工知能(AI)の開発は、社会に大きな影響を与える可能性を秘めています。しかし、倫理や安全性を無視したAI開発は、社会に悪影響を及ぼす可能性もあります。
1. AI開発原則の必要性
AI開発における倫理的なガイドラインや原則が策定される理由は、主に以下の3つです。
AIによる偏見・差別を防ぐ: AIは、学習データに含まれる偏見を反映してしまう可能性があります。そのため、AI開発においては、偏見・差別を助長するようなAIシステムを開発しないようにする必要があります。
AIによるプライバシー侵害を防ぐ: AIは、個人情報を収集・分析するのに利用される可能性があります。そのため、AI開発においては、個人のプライバシーを保護するようなAIシステムを開発する必要があります。
AIによる安全性を確保する: AIは、自動運転や医療診断など、安全性が求められる分野で利用される可能性があります。そのため、AI開発においては、安全性を確保したAIシステムを開発する必要があります。
2. 主要なAI開発原則
AI開発における倫理的なガイドラインや原則は、様々な団体によって策定されています。代表的な例として、以下のものがあります。
EU倫理AI原則: 2019年に欧州委員会が策定したAI開発原則です。人間尊厳、プライバシー、安全性を中心とした7つの原則で構成されています。
OECD AI原則: 2019年に経済協力開発機構(OECD)が策定したAI開発原則です。人間中心性、包摂性、説明責任、堅牢性、透明性、安全性を中心とした5つの原則で構成されています。「人工知能に関するOECD原則」
史上初めて複数国で合意されたAI原則IT業界倫理宣言: 2020年に日本IT団体連合会が策定したAI開発原則です。人権尊重、安全・安心、社会貢献、説明責任、透明性を中心とした5つの原則で構成されています。
3. 各AI開発原則の詳細
主要なAI開発原則について、それぞれ詳細に解説します。
3.1 人間尊厳
すべての人間は、尊厳と価値を持ち、差別や偏見を受けることなく尊重されるべきです。AI開発においては、人種、性別、宗教、民族、性的指向など、いかなる理由でも人々を差別したり、偏見を持ったりするようなAIシステムを開発してはなりません。
3.2 プライバシー
個人のプライバシーは尊重されるべきであり、個人の同意なしに個人情報を収集・分析してはなりません。AI開発においては、個人のプライバシーを保護するようなセキュリティ対策を講じ、個人の同意を得た上でのみ個人情報を収集・分析する必要があります。
3.3 安全性
AIシステムは、安全かつ責任を持って開発・運用されるべきです。AIシステムが誤動作したり、悪用されたりした場合に、人や社会に危害を加えないようにする必要があります。
3.4 包摂性
AIシステムは、あらゆる人にとって利用可能で、偏見や差別を助長しないように設計されるべきです。AIシステムは、特定のグループの人々だけを優遇したり、排除したりするようなものであってはなりません。
3.5 説明責任
AIシステムの開発者および運用者は、AIシステムの動作について説明責任を負うべきです。AIシステムがどのような結果を生み出すのか、どのようなデータに基づいて判断しているのかを、ユーザーが理解できるようにする必要があります。
3.6 透明性
AIシステムのアルゴリズムやデータ処理方法は、透明性を持って公開されるべきです。ユーザーがAIシステムの仕組みを理解できるようにすることで、AIシステムへの信頼性を高めることができます。
4. AI開発における課題
AI開発における倫理的なガイドラインや原則を策定することは重要ですが、実際に実現することは容易ではありません。
主な課題としては、以下のものがあります。
AI開発における倫理的な判断基準の明確化: 倫理的なガイドラインや原則は抽象的な概念であり、具体的な判断基準が明確化されていない場合があります。
AI開発における多様な価値観の尊重: 倫理的なガイドラインや原則は、特定の文化や価値観に基づいて策定される場合が多く、多様な価値観を尊重できていない場合があります。
AI開発における技術的な制約: AIシステムの仕組みを完全に透明化することは、技術的に困難な場合があります。
AI開発における法制度の整備: AI開発に関する法制度が未整備であり、倫理的なガイドラインや原則を強制力のある形で実現することが難しい場合があります。
AI社会原則
AI社会原則は、「AI-Ready な社会」において、国や自治体をはじめとする我が国社会 全体、さらには多国間の枠組みで実現されるべき社会的枠組みに関する原則である。
(1) 人間中心の原則
AI の利用は、憲法及び国際的な規範の保障する基本的人権を侵すものであって はならない。 AI は、人々の能力を拡張し、多様な人々の多様な幸せの追求を可能とするために 開発され、社会に展開され、活用されるべきである。AI が活用される社会において、 人々が AI に過度に依存したり、AI を悪用して人の意思決定を操作したりすることのな いよう、我々は、リテラシー教育や適正な利用の促進などのための適切な仕組みを導 入することが望ましい。
AI は、人間の労働の一部を代替するのみならず、高度な道具として人間を補助 することにより、人間の能力や創造性を拡大することができる。
AIの利用にあたっては、人が自らどのように利用するかの判断と決定を行うこと が求められる。AI の利用がもたらす結果については、問題の特性に応じて、AI の開発・提供・利用に関わった種々のステークホルダーが適切に分担して責任 を負うべきである。
各ステークホルダーは、AI の普及の過程で、いわゆる「情報弱者」や「技術弱 者」を生じさせず、AI の恩恵をすべての人が享受できるよう、使いやすいシステ ムの実現に配慮すべきである。
(2) 教育・リテラシーの原則
AI を前提とした社会において、我々は、人々の間に格差や分断が生じたり、弱者 が生まれたりすることは望まない。したがって、AI に関わる政策決定者や経営者 は、AI の複雑性や、意図的な悪用もありえることを勘案して、AI の正確な理解と、 社会的に正しい利用ができる知識と倫理を持っていなければならない。AI の利用者 側は、AI が従来のツールよりはるかに複雑な動きをするため、その概要を理解し、 正しく利用できる素養を身につけていることが望まれる。一方、AI の開発者側は、AI 技術の基礎を習得していることが当然必要であるが、それに加えて、社会で役立つ AI の開発の観点から、AI が社会においてどのように使われるかに関するビジネス モデル及び規範意識を含む社会科学や倫理等、人文科学に関する素養を習得して いることが重要になる。 このような観点から、我々は、以下のような原則に沿う教育・リテラシーを育む教 育環境が全ての人に平等に提供されなければならないと考える。
人々の格差や弱者を生み出さないために、幼児教育や初等中等教育において 幅広くリテラシー等の教育の機会が提供されるほか、社会人や高齢者の学び 直しの機会の提供が求められる。
AI を活用するためのリテラシー教育やスキルとしては、誰でも AI、数理、データ サイエンスの素養を身につけられる教育システムとなっているべきであり、全て の人が文理の境界を超えて学ぶ必要がある。リテラシー教育には、データにバ イアスが含まれることや使い方によってはバイアスを生じさせる可能性があるこ となどの AI・データの特性があること、AI・データの持つ公平性・公正性、プライ バシー保護に関わる課題があることを認識できるような、セキュリティや AI 技術 の限界に関する内容を備えることも必要である。
AI が広く浸透した社会において、教育環境は、一方的かつ均一的に教える教育 の在り方から、個々人の持つ関心や力を活かす在り方へと変化すると考えられ る。そのため、社会は、これまでの教育環境における成功体験に拘ることなく、 常に最適な形へと柔軟に変化し続ける意識を全体として共有する。教育におい て、落伍者を出さないためのインタラクティブな教育環境や学ぶもの同士が連 携できる環境が AI を活用して構築されることが望ましい。
このような教育環境の整備に向けて、行政や学校(教員)に負担を押し付けるの ではなく、民間企業や市民も主体性をもって取り組んでいくことが望ましい。
(3) プライバシー確保の原則
全てのAIが、パーソナルデータ利用に関するリスクを高めるわけではないが、AI を前提とした社会においては、個人の行動などに関するデータから、政治的立場、 経済状況、趣味・嗜好等が高精度で推定できることがある。これは、重要性・要配慮 性に応じて、単なる個人情報を扱う以上の慎重さが求められる場合があることを意 味する。パーソナルデータが本人の望まない形で流通したり、利用されたりすること によって、個人が不利益を受けることのないよう、各ステークホルダーは、以下の考え方に基づいて、パーソナルデータを扱わなければならない。
パーソナルデータを利用した AI 及びその AI を活用したサービス・ソリューション においては、政府における利用を含め、個人の自由、尊厳、平等が侵害されな いようにすべきである。
AI の使用が個人に害を及ぼすリスクを高める可能性がある場合には、そのよう な状況に対処するための技術的仕組みや非技術的枠組みを整備すべきであ る。特に、パーソナルデータを利用する AI は、当該データのプライバシーにかか わる部分については、正確性・正当性の確保及び本人が実質的な関与ができ る仕組みを持つべきである。これによって、AI の利用に際し、人々が安心してパ ーソナルデータを提供し、提供したデータから有効に便益を得られることにな る。
パーソナルデータは、その重要性・要配慮性に応じて適切な保護がなされなけ ればならない。パーソナルデータには、それが不当に利用されることによって、 個人の権利・利益が大きく影響を受ける可能性が高いもの(典型的には思想信 条・病歴・犯歴等)から、社会生活のなかで半ば公知となっているものまで多様 なものが含まれていることから、その利活用と保護のバランスについては、文化的背景や社会の共通理解をもとにきめ細やかに検討される必要がある。
(4) セキュリティ確保の原則
AI を積極的に利用することで多くの社会システムが自動化され、安全性が向上す る。一方、少なくとも現在想定できる技術の範囲では、希少事象や意図的な攻撃に 対して AI が常に適切に対応することは不可能であり、セキュリティに対する新たなリ スクも生じる。社会は、常にベネフィットとリスクのバランスに留意し、全体として社会 の安全性及び持続可能性が向上するように務めなければならない。
社会は、AI の利用におけるリスクの正しい評価やそのリスクを低減するための 研究等、AI に関わる層の厚い研究開発(当面の対策から、深い本質的な理解 まで)を推進し、サイバーセキュリティの確保を含むリスク管理のための取組を 進めなければならない。
社会は、常に AI の利用における持続可能性に留意すべきである。社会は、特に、単一あるいは少数の特定 AI に一義的に依存してはならない。
(5) 公正競争確保の原則
新たなビジネス、サービスを創出し、持続的な経済成長の維持と社会課題の解決 策が提示されるよう、公正な競争環境が維持されなければならない。
特定の国に AI に関する資源が集中した場合においても、その支配的な地位を利用した不当なデータの収集や主権の侵害が行われる社会であってはならな い。
特定の企業に AI に関する資源が集中した場合においても、その支配的な地位 を利用した不当なデータの収集や不公正な競争が行われる社会であってはな らない。
AI の利用によって、富や社会に対する影響力が一部のステークホルダーに不当過剰に偏る社会であってはならない。
(6) 公平性、説明責任及び透明性の原則
「AI-Ready な社会」においては、AI の利用によって、人々が、その人の持つ背景に よって不当な差別を受けたり、人間の尊厳に照らして不当な扱いを受けたりすること がないように、公平性及び透明性のある意思決定とその結果に対する説明責任(アカ ウンタビリティ)が適切に確保されると共に、技術に対する信頼性(Trust)が担保され る必要がある。
AI の設計思想の下において、人々がその人種、性別、国籍、年齢、政治的信 念、宗教等の多様なバックグラウンドを理由に不当な差別をされることなく、全 ての人々が公平に扱われなければならない。
AI を利用しているという事実、AI に利用されるデータの取得方法や使用方法、 AI の動作結果の適切性を担保する仕組みなど、用途や状況に応じた適切な説 明が得られなければならない。
人々が AI の提案を理解して判断するために、AI の利用・採用・運用について、 必要に応じて開かれた対話の場が適切に持たれなければならない。
上記の観点を担保し、AI を安心して社会で利活用するため、AI とそれを支える データないしアルゴリズムの信頼性(Trust)を確保する仕組みが構築されなけ ればならない。
(7) イノベーションの原則
Society 5.0 を実現し、AI の発展によって、人も併せて進化していくような継続的な イノベーションを目指すため、国境や産学官民、人種、性別、国籍、年齢、政治的 信念、宗教等の垣根を越えて、幅広い知識、視点、発想等に基づき、人材・研究 の両面から、徹底的な国際化・多様化と産学官民連携を推進するべきである。
大学・研究機関・企業の間の対等な協業・連携や柔軟な人材の移動を促さなけ ればならない。
AI を効率的かつ安心して社会実装するため、AI に係る品質や信頼性の確認に係 12 る手法、AI で活用されるデータの効率的な収集・整備手法、AI の開発・テスト・運 用の方法論等の AI 工学を確立するとともに、倫理的側面、経済的側面など幅広 い学問の確立及び発展が推進されなければならない。
AI 技術の健全な発展のため、プライバシーやセキュリティの確保を前提としつ つ、あらゆる分野のデータが独占されることなく、国境を越えて有効利用できる環境が整備される必要がある。また、AI の研究促進のため、国際的な連携を促進し AI を加速するコンピュータ資源や高速ネットワークが共有して活用されるような研 究開発環境が整備されるべきである。
政府は、AI 技術の社会実装を促進するため、あらゆる分野で阻害要因となって いる規制の改革等を進めなければならない。
AI利活用ガイドライン
AI利活用ガイドラインは、経済産業省と総務省が策定した、AIの利活用における倫理的な指針です。2021年3月に策定され、2024年4月に改訂されました。
基本理念
本ガイドラインの目的に鑑み、次に掲げる理念を一体的なものとして後に述 べる AI 利活用原則の基本理念とする。
• 人間が AI ネットワークと共生することにより、その恵沢がすべての人に よってあまねく享受され、人間の尊厳と個人の自律が尊重される人間中心の社会を実現すること
• AIの利活用において利用者の多様性を尊重し、多様な背景と価値観、考 え方を持つ人々を包摂すること
• AIネットワーク化により個人、地域社会、各国、国際社会が抱える様々 な課題の解決を図り、持続可能な社会を実現すること
• AI ネットワーク化による便益を増進するとともに、民主主義社会の価値 を最大限尊重しつつ、権利利益が侵害されるリスクを抑制するため、便益とリスクの適正なバランスを確保すること
• AI に関して有していると期待される能力や知識等に応じ、ステークホル ダ間における適切な役割分担を実現すること
• AI の利活用の在り方について、非拘束的なソフトローたる指針やベストプラクティスを国際的に共有すること
• AI ネットワーク化の進展等を踏まえ、国際的な議論を通じて、本ガイド ラインを不断に見直し、必要に応じて柔軟に改定すること
AI 利活用原則
AI の利用者が留意すべき事項を以下 のとおり 10 の原則に整理する。
① 適正利用の原則 利用者は、人間と AI システムとの間及び利用者間における適切な役割分担 のもと、適正な範囲及び方法で AI システム又は AI サービスを利用するよう 努める。
② 適正学習の原則 利用者及びデータ提供者は、AI システムの学習等に用いるデータの質に留 意する。
③ 連携の原則 AI サービスプロバイダ、ビジネス利用者及びデータ提供者は、AI システム 又は AI サービス相互間の連携に留意する。また、利用者は、AI システムがネ ットワーク化することによってリスクが惹起・増幅される可能性があること に留意する。
④ 安全の原則 利用者は、AI システム又は AI サービスの利活用により、アクチュエータ 等を通じて、利用者及び第三者の生命・身体・財産に危害を及ぼすことがな いよう配慮する。
⑤ セキュリティの原則 利用者及びデータ提供者は、AI システム又は AI サービスのセキュリティ に留意する。
⑥ プライバシーの原則 利用者及びデータ提供者は、AI システム又は AI サービスの利活用におい て、他者又は自己のプライバシーが侵害されないよう配慮する。
⑦ 尊厳・自律の原則 利用者は、AI システム又は AI サービスの利活用において、人間の尊厳と 個人の自律を尊重する。
⑧ 公平性の原則 AI サービスプロバイダ、ビジネス利用者及びデータ提供者は、AI システム 又は AI サービスの判断にバイアスが含まれる可能性があることに留意し、ま た、AI システム又は AI サービスの判断によって個人及び集団が不当に差別 されないよう配慮する。
⑨ 透明性の原則 AI サービスプロバイダ及びビジネス利用者は、AI システム又は AI サービ スの入出力等の検証可能性及び判断結果の説明可能性に留意する。
⑩ アカウンタビリティの原則 利用者は、ステークホルダに対しアカウンタビリティを果たすよう努める。
特許法における「自然人の創作」: 発明の権利獲得に向けた三つの関門
特許法において、発明の権利を得るためには、自然人 が創作したものでなければなりません。そして、その創作が特許要件を満たしている必要があります。
特許要件には、新規性、進歩性、産業上の利用可能性の3つがあります。
このうち、自然人の創作 については、特許法施行規則第3条第3項で以下の3つのステップが定められています。
1.課題設定 2.解決手段候補選択 3.実効性評価
1. 課題設定
まず、解決すべき課題 を設定する必要があります。課題とは、技術的な問題や社会的なニーズなどであり、従来の技術では解決できない、または十分に解決できていない問題であることが求められます。
2. 解決手段候補選択
次に、課題を解決するための解決手段候補 を選択します。解決手段候補とは、課題を解決するためのアイデアや方法であり、複数存在する可能性があります。
3. 実効性評価
最後に、選択した解決手段候補について、実効性 を評価します。実効性とは、課題を確実にかつ効率的に解決できるかどうかを意味します。
Cortanaは2014年にCNNとLSTMを組み合わせて音声認識の性能を向上させました。
具体的な内容は以下の通りです:
2014年、MicrosoftのデジタルアシスタントであるCortanaは、CNNとLSTMを組み合わせることで、音声認識の精度を向上させました。
CNNは画像認識に強みがあり、LSTMは時系列データの処理に優れています。Cortanaはこの2つのニューラルネットワークを組み合わせることで、音声データの特徴抽出と時系列処理を効果的に行えるようになりました。
この取り組みにより、Cortanaの音声認識精度が大幅に向上し、より自然な会話が可能になりました。
同様の手法は、その後のAIシステムの開発にも応用されています。例えば、2015年にDeepMindが開発したAlphaGoでも、CNNとLSTMを組み合わせた手法が採用されています。
ご利用にあたって
本G検定チートシートに記載されている情報は、参考として提供されるものであり、その内容の正確性や完全性を保証するものではありません。本G検定チートシートを利用することにより発生するいかなる結果についても、閲覧者ご自身の責任において運用してください。各自の判断で情報の信頼性を確認し、適切にご利用ください。