
DrawThings(画面説明-LoRA)

いつの間にかLoRA学習をする事ができるようになっている。
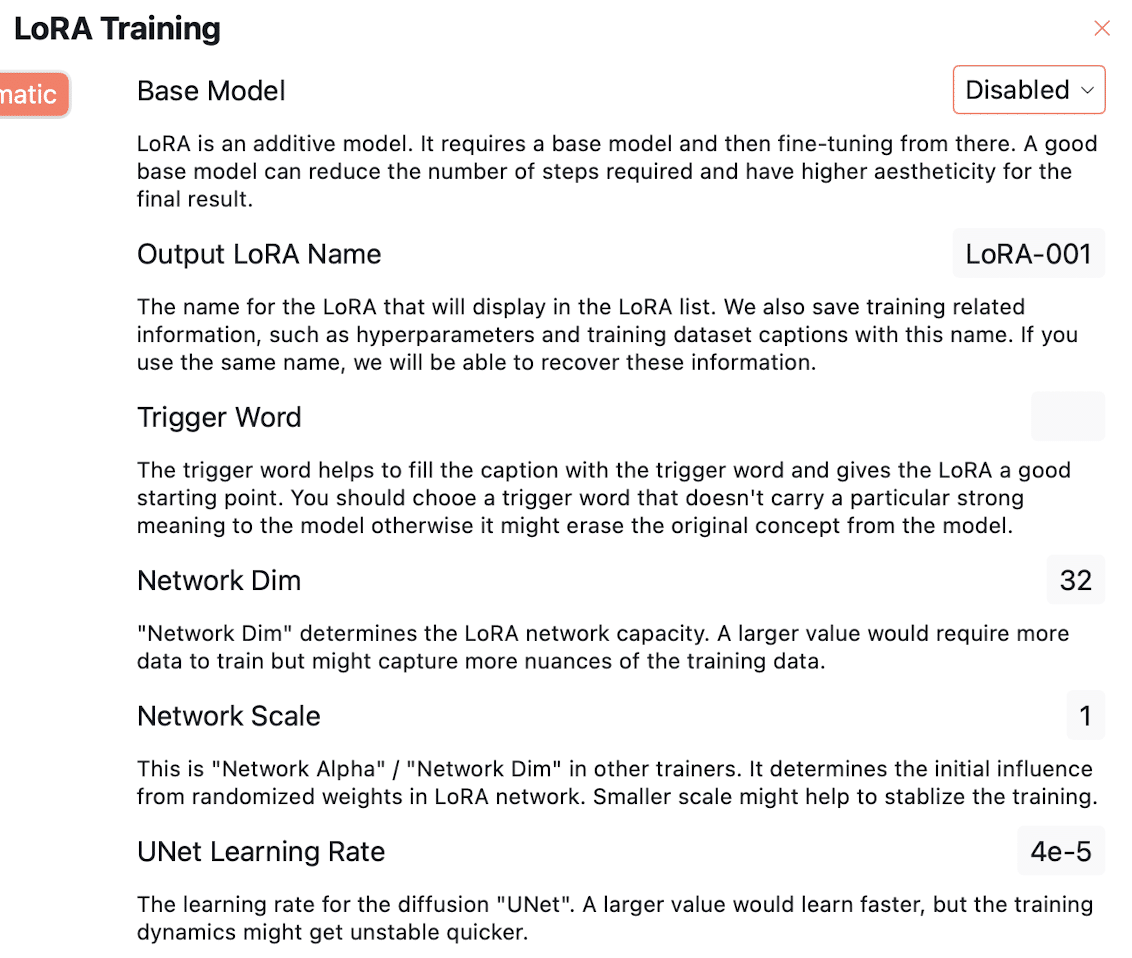
LORA トレーニング
ベースモデル
LoRA は加算モデルです。 基本モデルが必要で、そこから微調整する必要があります。 優れたベースモデルは、必要な手順の数を減らし、最終結果の美しさを高めることができます。
出力 LoRA 名
LoRA リストに表示される LoRA の名前。 また、ハイパーパラメータやトレーニング データセットのキャプションなどのトレーニング関連情報もこの名前で保存されます。 同じ名前を使用すると、これらの情報を復元できます。
トリガーワード
トリガー ワードは、キャプションをトリガー ワードで埋めるのに役立ち、LoRA に適切な開始点を与えます。 モデルに対して特定の強い意味を持たないトリガー ワードを選択する必要があります。そうしないと、モデルから元の概念が消去される可能性があります。
ネットワークディム
「Network Dim」は LoRA ネットワーク容量を決定します。 値が大きいほど、トレーニングにはより多くのデータが必要になりますが、トレーニング データのニュアンスをより多くキャプチャできる可能性があります。
ネットワーク規模
他のトレーナーで言うところの「ネットワークアルファ」/「ネットワークディム」です。 LoRA ネットワークのランダム化された重みから初期の影響を決定します。 規模が小さいとトレーニングが安定する可能性があります。
UNet 学習率
普及「UNet」の学習率。 値が大きいほど学習は速くなりますが、トレーニング ダイナミクスがより早く不安定になる可能性があります。
画像サイズ
ネットワークをトレーニングするときの解像度。 この解像度を提供するために、中心を切り取って拡大縮小します。 ネットワークがアップスケーリング アーティファクトを学習しないように、トレーニング データがこの解像度以上であることを確認してください。
トレーニングのステップ
実行するトレーニング ステップの数。 適切なモデルを作成するには、これをレートと合わせて変更する必要があります。 学習率が低いほど、より多くの学習能力が必要となり、より多くのトレーニングが必要になります
N ステップごとに保存
これにより、n ステップごとに LoRA を保存できるため、オーバークックを避けることができます。
ウォームアップステップ
これは、どのステップでトレーニングに完全な学習率を使用するかを制御します。 初期の例に重点を置きすぎないようにすることで、トレーニングのダイナミクスを早期に安定させるためのウォームアップ
勾配累積ステップ
これは、ネットワーク更新をいつ実行するかを制御します。 さらに勾配を蓄積する
アップデートは、ネットワークがどこに行くかに関するより多くの統計を取得するのに役立ちます。

画像サイズ
ネットワークをトレーニングするときの解像度。 提供された画像をこの解像度に合わせて中央で切り抜き、拡大縮小します。 トレーニング データがこの解像度以上であることを確認してください。そうしないと、ネットワークがアップスケーリング アーティファクトを学習する可能性があります。
トレーニングのステップ
実行するトレーニング ステップの数。 良いモデルを作成するには、学習率に合わせてこれを変更する必要があります。 学習率が低いほど、より多くのトレーニングステップが必要な能力が高まります。
N ステップごとに保存
これにより、n ステップごとに LoRA を保存できるため、モデルのオーバークックを回避できます。
ウォームアップステップ
これは、どのステップでトレーニングに完全な学習率を使用するかを制御します。 ウォームアップ ステップは、初期のサンプルに重点を置きすぎないようにすることで、トレーニング ダイナミクスを早期に安定させるのに役立ちます。
勾配累積ステップ
これは、ネットワーク更新をいつ実行するかを制御します。 更新前にさらに多くの勾配を蓄積すると、ネットワークがどこに行くべきかについてより多くの統計を取得できるようになります。 この値に合わせて学習率をスケールする必要があります (つまり、2 倍の蓄積ステップ、2 倍の学習率)。
テキストモデルを共同トレーニングする
テキストエンコーダーを微調整するかどうか。 SD v1/v2 モデルの場合、テキスト エンコーダーを微調整すると、コンセプトをより早くモデルに浸透させることができます。 SDXL を微調整する場合、これは多くの場合必要ありません。
テキストモデルの学習率
テキスト エンコーダーを微調整するための学習率。

クリップスキップ
「CLIP Skip」は、テキストエンコーダーの最後のレイヤーから何レイヤーをスキップするかを制御します。 テキスト エンコーダーは、テキストをコンピューターが理解できるベクトルに変換します。 テキスト エンコーダーでさらに多くのレイヤーをスキップすると、コンピューターは単語の組み合わせた意味よりも個々の単語に重点を置くようになります。 これは、タグのようなテキスト入力で微調整されるモデルに役立つ可能性があります。
カスタム埋め込みを共同トレーニングする
カスタム T.I. トリガーワードとしてレアワードトークンを使用するよりも、埋め込みの方が本質を捉えるのに優れています。 一方、TI を使用する必要があります。 トレーニングされた LoRA と組み合わせて埋め込むと、トレーニングされた LoRA が適切に動作しません。
カスタム埋め込み学習率
T.I. を共同トレーニングする場合の学習率。 埋め込み。
カスタム埋め込み長さ
埋め込みの長さを長くすると、トレーニング データのニュアンスをより多く捉えることができますが、埋め込みごとに占有するトークンも多くなります。
ステップでトレーニングの埋め込みを停止する
指定されたステップ数の後に埋め込みの更新を停止します。 これは、埋め込みを学習した後のトレーニングを安定させるのに役立ちます。
ノイズオフセット
「オフセット ノイズ」は、ノイズ分布に余分なオフセットを加えます。 これは、常に中程度の露出に陥るのではなく、暗い/明るいシナリオをより適切に表現するためにモデルを微調整するのに役立ちます。
ノイズ除去スケジュール
これは、ノイズ除去プロセスのどの段階で微調整に重点を置くかを制御します。 たとえば、70% から 100% の間のノイズ除去スケジュールに焦点を当てるだけで、画像を「洗練」するのに役立つ LoRA をトレーニングできます。 または、0% ~ 50% の間でスケジュールどおりに適切な構成を取得するのに役立つ LoRA。
いいなと思ったら応援しよう!
