
polarsのいろんなGROUP BY

こんにちは。
これはPolarsのAdvent Calendar 2023 16日目の記事です。
すみません、公開が遅れました。
Polarsは高速で効率的なデータ操作を可能にするRust言語で実装されたライブラリです。Pandasに似た機能を持ちながらも大規模なデータセットを高速に処理できます。
今回は、Pythonでこのpolarsの機能のひとつgroupbyを使用して、最近世界を賑わせている大谷さんの今季の成績を見ていきたいと思います。
大谷さんの今季データの取得
MLBのデータはかなり細かく公開されていて、ダウンロードも可能になっています。今回はこのリンク先にある検索機能を使って大谷さんのデータを取得します。
Battersの欄にShohei Ohtaniを入力して、searchボタンを押下してください。

結果が表示されたら一番右上のボタンを押下してデータをダウンロードしてください。今回はこのデータを使用します。

データの読み込み
import polars as pl
_dat = pl.read_csv("savant_data.csv")
_dat.head()
大谷さんの打席が1球ごとに細かく載っています。
試合日、ピッチャー、バッター、結果、カウント、リリースポイントなど分析には十分なほどデータが取得できています。
前処理
カラムを必要なものにしぼる
game_dateがちゃんと日付型になってないので、変換しておく
データが1球ごとになってるので打席結果の行に絞る
dat = (
_dat
.select(["game_date", "events"])
.with_columns(pl.col("game_date").str.to_date())
.filter(~pl.col("events").is_null())
)打席結果の種類を確認
dat.group_by("events").count().sort("count", descending=True)
安打系の数値は合ってるけど四球数が少ない。ちゃんとwalkって記載されてなさそう。
今回は打数にカウントされる打席結果だけに絞って、
打率、長打率についてGROUP BYを使って移動平均を見ていきます。
dat = dat.filter(pl.col("events").is_in(["single", "double", "triple", "home_run",
"field_out", "strikeout", "force_out", "grounded_into_double_play",
"fielders_choice_out", "field_error"]))塁打のカラムを追加する
dat = dat.with_columns(
pl.when(pl.col('events') == "single").then(pl.lit(1))
.when(pl.col('events') == "double").then(pl.lit(2))
.when(pl.col('events') == "triple").then(pl.lit(3))
.when(pl.col('events') == "home_run").then(pl.lit(4))
.otherwise(pl.lit(0))
.alias("ruida")
)
dat.group_by("events", "ruida").count().sort("ruida", descending=True)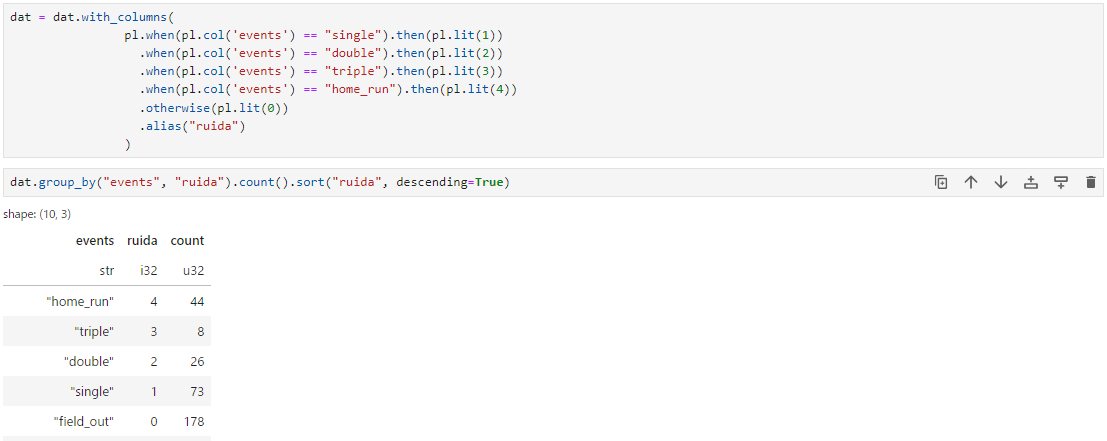
改めて44HR、すごすぎる。
移動平均
polarsにはgroup byが3つあります。
group_by
group_by_dynamic
group_by_rolling
違いを見ていきましょう。
group_by
これは多くの方がご存知の通り、引数で指定した組み合わせごとに何かの処理を使いたいときに使います。
dat = dat.sort("game_date")
dat_gr = (
dat
.group_by("game_date")
.agg(
pl.sum("ruida").alias("ruida")
,pl.count("ruida").alias("AB")
,pl.mean("ruida").alias("SLG")
)
)
dat_gr
試合日ごとの長打率(SLG)を算出したい場合はこちらです。
group_by_dynamic
ほとんど書き方は変わらないですが、引数としてeveryとperiodが出現しました。
これは{every}ごとに{period}分の計算が行われます。
2023-03-31の結果のように当該日に試合がなかった場合は、歯抜けにして計算されます。
dat_gr_d = (
dat_gr
.group_by_dynamic("game_date", every="1d", period="3d")
.agg(
pl.col("game_date").alias("game_date_group")
,pl.sum("ruida").alias("ruida")
,pl.count("ruida").alias("AB")
,pl.mean("ruida").alias("SLG")
)
)
dat_gr_d
つまり、当該日から3日間の数値で計算されていて、当該日に出場しているか(試合があるか)は関係ありません。
group_by_rolling
dat_gr_r = (
dat_gr
.group_by_rolling("game_date", period="3d")
.agg(
pl.col("game_date").alias("game_date_group")
,pl.sum("ruida").alias("ruida")
,pl.count("ruida").alias("AB")
,pl.mean("ruida").alias("SLG")
)
)
dat_gr_r
こちらはdynamicのときとは違い、打席があった日だけがgame_dateに現れていて、当該日までの3日間の値で計算されています。
おそらくよく使われる移動平均はrollingの方かなと思います。
最後に
作成した移動平均の値を可視化してみます。
※最終的に10日ごとの移動平均を採用しました
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 5))
plt.plot(dat_gr_r['game_date'], dat_gr_r['SLG'], marker='o', linestyle='-')
plt.xlabel('Date')
plt.ylabel('SLG')
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
6,7月の長打率が高く、調子が良かったことが見てわかります。
実際6月だけで15本のHRを打っていました。
実際、今回polarsを使って簡単な前処理を書いてみましたが、直感的でpandasよりもカラム指定が楽で、もっと慣れていけば自分が慣れてるRのtidyverseの書き方と遜色なく前処理できるなと感じてます。
ついついpl.to_pandasをして慣れてる書き方をしないように縛って書いていこうと思います笑
良いお年を!