絵を作るためにAIに「使われた」話

(約 6,600文字の記事です。)
今日は実際にInvokeAIを使ってStable Diffusionを楽しんでみた。
InvokeAIはAI絵を作成させるための統合環境ソフトだと思っていい。
その使い方の中にStable Diffusionを使って絵を生成させたり、別のモデル(デフォルトではInpainting Ver.1.5 というモデル)に切替えて、少しアルゴリズムの異なるエンジンで絵を再度生成させることができる。

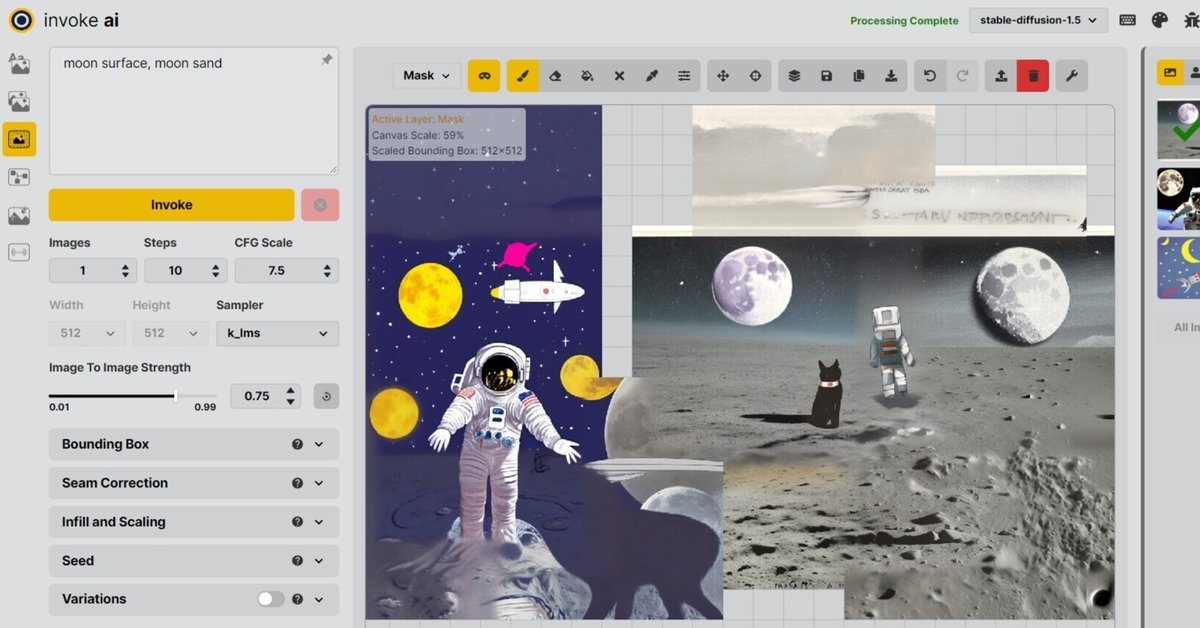
InvokeAIはグラフィックボードのVRAM容量が4GB以上ある人はすぐにでも試すことができます。Windowsユーザー向けインストールマニュアルを作成いたしました。
まずは公式動画をじっくり理解しよう
以前、Windows環境のexeファイルでStable Diffusionでtext2imgを試したときと比べてInvokeAIでの実際の運用方法は違った。具体的には公式YouTube動画を見ればよく分かる。
この動画にはとても重要な情報がたくさん含まれている。オススメは0.75倍速にして「自動生成で日本語字幕」を表示させることだ。そうすればゆっくりなので英単語も聞き取れるし、自動翻訳であってもそこそこ精度のいい、理解できる日本語が字幕になるので理解を助ける。スロー再生だと自動生成の日本語訳も何とか追いついてきてくれる。
Stable Diffusionのみ使う場合との決定的な違い
もし512ピクセル四方の絵で完結させるならば、とにかくプロンプトという呪文の探求が重要になる。だがInvokeAIで絵を外側に向けてどんどん拡張していくことができるので、このやり方だけでは上手く行かない。
動画のように、描画領域に応じて微妙にプロンプトを修正し、画像を追加し、次の追加領域に枠を移動させて、これまたプロンプトを微調整し、この繰り返し。
また、InvokeAIを導入する前の当時は当然ながらStable Diffusionという1つのモデルしか使えなかったわけだが、InvokeAIでは複数のモデルを切替えながら利用可能だ。動画の中では、
四角い領域全体を新規生成させる場合(アウトペインティング)にはStable Diffusion
既存の絵の多くを上書きする場合(インペインティング、大)にはInpainting
既存の絵の小さな一部の領域を上書きする場合(インペインティング、小)にはStable Diffusion
という使い分けまで紹介されている。そしてそれを理解してから自分でも試したが、確かにそうだった。何だか上手く生成できないときにはStable DiffusionとInpaintingとを交互に試して上手くいった。
今回はプリインストールされたStable DiffusionとInpaintingの2つだけを試したが、これで何となくStable Diffusionとそうではない別モデルとの使い分けが見えてきたし、同時にStable Diffusionそのものも相対的にその特徴が分かるようになった気がする。
マスクの意味
最初、これの使い方が分からなかった。
何に対して何をマスクするのか?
何に対してどんな情報を隠すのか?
このマスクブラシでマスクする意味は「既存の描画済みの絵を隠して(マスクして)、Stable Diffusionさんから見て『無色透明の未描画領域だよ』と教える作業」なのだ。つまり既存の描画領域をマスクして、あたかも無色透明な領域に見せる作業。
そしてStable Diffusionや他のモデルは基本的に「無色透明の領域」に絵を生成する。なのでキャンバスの外側に向かって拡張させていくときにはアウトペインティング(アウトペイント)と呼び、既存の絵の一部を修正する場合にはマスク+その内側領域を描画させるのでそれをインペインティング(インペイント)と呼ぶ。
そしてインペインティングの領域の大きさによって、Stable Diffusionのほうがいい結果になったり、Inpaintingのほうがいい結果になったりする。
これが分かってしまえばかなり自由にどんどんと絵を拡張したり、気に入らない部分を修正したり、絵の一部に何かを追加することが簡単にできるようになる。
絵の生成、合成、一部書き換えの違い
Stable Diffusionのみ触っていた頃は512ピクセル四方が一気に書き換わるので「領域内の一部の絵だけを書き換える」という発想がなかった。ところがInvokeAIでは簡単にそれができる。指定領域のみAIに絵を再生成させることができる。
それを何回か試していて気がついた事がある。
絵の生成についてはStable Diffusionがまず基本となって絵柄を生み出す。これはStable Diffusionを指定しているから当たり前だ。キャンバスの透明領域に絵を拡張していく場合も基本的にはStable Diffusionの画像生成機能が透明部分を埋めていく形になる。
512ピクセル四方全部だったり、アウトペインティングの時には基本的にはStable Diffusionでどんどん絵を作らせる。あるいはごく小さな領域のインペインティングの場合も同様。ちょっと広い領域のインペインティングの場合はInpaintingがいい。
でも基本的にアウトペインティング以外は、つまりインペインティングの結果はほぼ例外なく滑らかに「ぼかし」によって外側の絵と内側の絵をつなぎ合わせているに過ぎない。

だいたいいい感じでつながってくれる所もあれば、よくよく見るとインペインティングの境界を機械的にぼかしてブレンドしているだけ、という部分もある。
確かに狭い領域ならばそれが効果的だ。だが512ピクセル四方の4分の1程度という、割と広いエリアを再合成すると、色味の違いや光源の位置の違い・影位置の違い、そういうものが明らかに周りと矛盾する。
結果、絵のキャンバス全体で見ると、まるでパッチワークのような「つぎはぎ」だらけの絵になる。1枚絵としては破綻する。
この辺がAI絵の限界かな、と感じた。
またピクセル数やドキュメントの大きさに対してAIが生成できる情報密度の違いもある。広い領域全体について光源の破綻などなく大きく描くことが、今はかなり難しい。(将来的に基本領域が512ピクセル四方よりも数倍大きくなったときにはそれが実現可能だろうが)
なので現状、以下のような問題点がある。
1枚絵として破綻させないためには512ピクセル四方内で実現させる
破綻の少ない絵が生成されるが1ピクセル未満の情報量を与えられない
なのでアップスケールソフトを使っても基本的に「無い情報は増えない」
無い情報を生成してくれるのがStable Diffusionなわけだから、Stable Diffusionで絵をアウトペインティングするしかない
例えばFull HD(1920x1080ピクセル)相当の絵を作る場合、8つのエリアに分けて絵を拡張する手がある
8つのエリアの継ぎ目を上手く処理する必要がある
8つのエリア全てにおいて光源や陰影の統一化ができるのか謎
色味程度ならばPhotoshopなどのレタッチで手間をかければ何とかなる。だが光源位置と陰影の関係の修正は、完全に絵の描き直しと同じだ。これを果たしてStable Diffusionに正確に指示できるのか?そしてStable Diffusionはそれに対して正確に応答してくれるのか?
マシンパワーがものを言うAI絵

GPUの性能が全てという気がする。というのも1枚の生成時間がGPUの性能次第だからだ。時間は有限だ。なので1枚の生成時間が10倍違うと、試行錯誤できる量が10倍以上の差につながる。
AI絵は基本的にガチャなので、とにかく1つのプロンプトで複数枚の絵を生成させて、その中から最もいい感じの絵を選ぶ、という作業の連続になる。公式動画でも4枚の絵を生成させている。これを30万円台のGPUであるRTX-4090を使って5秒以内に生成させるのか、5万円以内のGTX-10xx系で40秒待つのかでは、試行錯誤の回数が全然違う。結果、当たりのガチャを引ける確率がかなり変わる。
AI絵の生成ではマシンパワーが全て。これは間違いない。
高性能マシンがあってサクサクとガチャを回せるようになってようやく、プロンプトの探求に入っていけると思う。逆はまぁ、難しいだろう。やっていることはガチャを回しているわけだから、その回数の多さが色んな弱点をカバーできる。つまりはAI絵の生成ではマシンパワーが全てなわけだ。
人がAIに使われているだけでは?🤔
だんだんと、私がStable Diffusionにこき使われているだけでは?と思えるようになってきた。
Stable Diffusionのポテンシャルをガチャで引き出そうとする人間。
ガチャをたくさん試さなければならない人間。
どっちが「主」でどっちが「従」なの?と思うように。
ガチャの待ち時間
私にとっては無駄な待ち時間は、短い方がいい。これは間違いない。ドキドキワクワク?そんなの10分で慣れるよ。後は単なる待ち時間でしかない。これを高性能GPUでその待ち時間を数秒に短縮できるならば、その方がいいに決まっている。
どんないい絵が「出たか(過去形)」に意味があるので、これから「どんな絵が出てくるのか(未来形)までの待ち時間」に意味はない。現在から未来までの待ち時間は、自分の貴重な人生そのものなわけだから、その待ち時間は短い方がいい。そのほうがたくさんガチャを回せる。
くどいが、AI絵ではマシンパワーが全てなのだ。そう気が付いた。私のショボいグラボではとってもスローリーなのだ。できないよりはマシだが、ガチャを回しまくるという作戦は使えない。ステップ数を減らすなどして演算量そのものを減らして「画像化までの時間を短時間化」するしかない。
だがそれを高性能GPUを使えば1秒程度で絵が出てくるわけだから、やはりマシンパワーが全て、という点は否定できない。
達成感が感じられない?
いい絵が出ても、なぜか達成感が感じられない。私が描いたわけではなくて、私がガチャを回して気に入る絵を求め続けて、作業し続けただけなのであって、絵を描いてはいないのだ。だから当然ながら、作品の完成までのプロセスもないし、仕上がりまであと一歩、というシーンもない。「画竜点睛(がりょうてんせい)」の、最終仕上げというクライマックスもまた、ない。
だから創作する側、クリエーター側として、作り上げた・成し遂げたという実感も、創作の過程を振り返ってみての達成感というものが感じられない。
淡々と「おっ、いい絵が出たな。」これくらいだ。
まさにガチャで当たりが出た、という感想しか出てこない。そしてそれは自分で生み出したものではないから、次も同じような絵を生み出せる自信が全くない。同じような絵が出るまで延々とガチャを回し続けるだけなのだ。
この感想が「私がAI(Stable Diffusion)に使われているだけでは?」と思った根拠だ。マスターがStable Diffusionというデータで、スレーブがガチャを回し続ける私だ。高額GPUと電気を消費しながら。
(来年3月から電気代が全国一斉に3割以上値上げ予定ですね😭)
そんなわけで、今後しばらくは、というかまだまだ「広い領域、高画素でキャンバス全体が統一感を持った1枚の絵」というものは、まだ人が作ったほうが「効率的」なのだろうと思う。なのでまだまだ絵師という仕事は人の手にあり続ける気がする。
だが、逆の発想もある。
ぼかし前提の、ラフでいい絵はAIに任せよう
例えばアニメの背景などで、雰囲気だけ欲しくて、被写界深度を活かした「多少ぼけた背景」でいいならばAI絵が使える。また企画段階の雰囲気を伝えるためのラフな絵でも同様。
「1枚絵としての、統一感のある精度の高い絵」以外でも、絵が欲しいというシーンはたくさんある。そういう絵を生成させるためにAI絵を活用した方がいい。それならば私のショボいGPUでも、そこそこの絵がそこそこの時間で作れる。
また広いキャンバスのブロックごとに多少色味が違っても「こまけぇこたぁいいんだよ!」的な判断が許される場面で絵を用意したい場合にも有効だ。
例えば「山のてっぺんに少女がたたずんでいる」にしても、日本の山?富士山?その辺の小さな山?あるいはアルプス?エアーズロック?季節は?時間帯は?これの答えを絵が教えてくれるわけで。(少女は棒人形であっても構わないわけで。)そういう情報のある絵をAIに描かせることは割と簡単だろう。
新キャラのデザインの案出しにはいいかも?
と思ったのだが、これ、プロンプトで指示している段階で、ある程度キャラデに慣れている人ならばラフ絵が描けちゃうのでは?とも思ってみたり。あるいは絵師さんが描いた無数の絵を眺めている内に大体のアイディアが出てきそうな気もするし、そもそも顔だけに限って言えば4年前からAI生成の仕組みがあるので、それらを使えばプロンプト探しせずとも簡単なアンケートに答えるだけで無数に新キャラ(女性のみ)が生み出されるわけで。
うん、何のためにAIに絵を描かせるのですか?の答えが分からなくなってきた。
【結論】どんなAI生成画像が欲しいのか?
多分、これの答えによって、人それぞれのStable Diffusionの使い方がある。Stable Diffusionに限らず色んなモデルの使いこなしに関わる。
1枚絵で陰影に破綻のない絵?人物画?日本風の可愛いアニメ少女?セクシーな絵?風景画?ロボット?などなど。
またそのピクセル数とキャンバスの大きさ、これによってガチャを回す回数も全然違ってくるし、それとは別に「人物の特徴、ポーズ、光源の位置、表情」など、本当に無限の組み合わせの中から自分の好みの絵をガチャで引き当てることになる。
その作業効率はマシンパワーに依存する。だがお目当てを引き当てたからといって、次も同じような絵を引き当てられる保証はない。これが「絵師(ペインター)」と「AI絵師(プロンプトセッター)」の決定的な違いになる。両者では成果物が同じだったとしても、その過程の活動内容が全く異なるわけだから。
絵を描くことで絵を作るペインター、絵をAIに生成させるプロンプトを作成する(ガチャで探し求める)ことで絵を生成するAI絵師。
個人的なInvokeAIの使い方
趣味クリエーターとしては、私はペインターの方がいいな、と思った。達成感や満足感を考えるならば。
ただ、遠景の山々の絵を描きたいわけではなくて、そこのワンシーンの絵をラフに作りたい場合など、その場合にはキャラクターの状態にフォーカスしてエネルギーを使いたいわけで、遠景は何でもいいという場合もある。そういう使い方に絞ってAI絵、InvokeAIを使っていこうと思っている。
どちらかというと背景画の自動生成ツールとして考えている。雰囲気の演出としての手段かな。「ここに山、ここに川、ここに草原」などのラフな絵からimg2imgでそこそこの絵が出るならばそれで満足できる。
私は多分、AI絵でキャラクター絵を求めることはないと思う。人が描いた絵を眺めていたほうが楽しい気がするのだ。それはpixivにたくさんあるし。
というわけで少しInvokeAIを触ってみて、AI絵の可能性を感じてみて、そこから今後どう使おうか考えてみた日記でした。
今回の創作活動は約2時間(累積 約3,046時間)
(820回目のnote更新)
筆者はAmazonアソシエイト・プログラムに参加しています。(AmazonアソシエイトとはAmazon.co.jpの商品を宣伝し所定の条件を満たすことで紹介料をAmazon様から頂けるという大変ありがたい仕組みのこと。)
以下のリンクを経由してAmazonでお買物をするとその購入額の1~3%ほどのお小遣いが私に寄付されます(笑)以下のリンクを経由して頂ければ紹介商品以外のご購入でもOKですよ~。
いいなと思ったら応援しよう!
