
米株Python [4-1] スクリーニング

こんにちわ!トミィ(@toushi_tommy)です!3章ではスクリーニングを行いましたが、今回の4章からはスクリーニングの為に作ったデータベースをより、使いやすいものに変更して、簡単に自分好みの銘柄をスクリーニングする方法を説明していきます。いろいろやってみた結果、Finvizのスクリーナー機能は非常に優秀ですので、まずはそれを使い、今後カスタマイズや機能追加を行っていきます。(注意:スクリーニングを使って、Finvizサイトから全銘柄のデータを取ってきますので、サーバーへ負荷がかかります。できるだけ時間を空けて実行するようにお願いします。また、スクレイピングを禁止している場合もございますので、自己責任にて実行をお願いします。)
サークルは無料で運営しております。記事内容も無料です。トミィにジュースでもおごってあげようと思った方は投げ銭いただけると、今後の運営の励みになります。
スクレイピング用データーベース作成
まずは、スクレイピング用のデータベース作成を行います。前回[3-6]と同様にFinvizからデータを取得します。前回と違って追加した項目は
1.決算日順に並び替えができる
2.楽天証券で購入できる個別株に絞れる(日本語での表記も取得可能)
という点です。まずは下記のコードを実行してみてください。
module_dir = '/content/drive/MyDrive/module'
data_dir = '/content/drive/MyDrive/input/'
import os
import sys
sys.path.append(module_dir)
import pytz
import datetime as datetime
import numpy as np
import pandas as pd
from bs4 import BeautifulSoup
import re
import requests
import time
from datetime import datetime as dt
import glob
start = time.time()
base_url = 'https://finviz.com/screener.ashx?v=152&c='+','.join(map(str, range(71)))
df = pd.DataFrame()
cnt = 1
while 1:
url = base_url+'&r='+str(cnt)
time.sleep(0.1)
site = requests.get(url, headers={'User-Agent': 'Custom'}, timeout=3.5)
data = BeautifulSoup(site.text,'html.parser')
da = data.find_all("tr", align="center")
tables = re.findall('<td class="table-top.*</td>', str(da[0]))
#names = [re.sub('.*>(.+)</td>.*', r'\1', s) for s in tables]
names=['No.', 'Ticker','Company', 'Sector', 'Industry', 'Country', 'Market Cap', 'P/E', 'Fwd P/E', 'PEG', 'P/S', 'P/B', 'P/C', 'P/FCF', 'Dividend', 'Payout Ratio', 'EPS', 'EPS this Y', 'EPS next Y', 'EPS past 5Y', 'EPS next 5Y', 'Sales past 5Y', 'EPS Q/Q', 'Sales Q/Q', 'Outstanding', 'Float', 'Insider Own', 'Insider Trans', 'Inst Own', 'Inst Trans', 'Float Short', 'Short Ratio', 'ROA', 'ROE', 'ROI', 'Curr R', 'Quick R', 'LTDebt/Eq', 'Debt/Eq', 'Gross M', 'Oper M', 'Profit M', 'Perf Week', 'Perf Month', 'Perf Quart', 'Perf Half', 'Perf Year', 'Perf YTD', 'Beta', 'ATR', 'Volatility W', 'Volatility M', 'SMA20', 'SMA50', 'SMA200', '50D High', '50D Low', '52W High', '52W Low', 'RSI', 'from Open', 'Gap', 'Recom', 'Avg Volume', 'Rel Volume', 'Price', 'Change', 'Volume', 'Earnings', 'Target Price', 'IPO Date']
cntns = re.findall('<a class="screener-link.*</a>', str(da[0]))
contents = [[re.sub('<a .*">(.+)</a>.*', r'\1', s).replace('</span>','').replace('&','&') for s in re.findall('<a .*?</a>', i)] for i in cntns]
df1 = pd.DataFrame(contents, columns = names)
print("\r now reading -->> " +df1['Ticker'][0]+'('+str(cnt)+") ---" ,end="")
if(len(df1)==1):
if (df1['Ticker'][0] in df['Ticker'].to_list()): break
df = pd.concat([df, df1], axis=0)
if(len(df1)<20): break
cnt+=20
# 元データの保存
df = df.set_index('Ticker')
# 楽天証券情報追加
url = "https://www.trkd-asia.com/rakutensec/exportcsvus?all=on&var1=on&var3=on&r1=on"
df_ticker = pd.read_csv(url, index_col=0)
df = pd.concat([df, df_ticker], axis=1)
out_file = data_dir+'stock_base_'+datetime.datetime.now(pytz.timezone('US/Eastern')).date().strftime("%Y%m%d")+'.csv'
df.to_csv(out_file, encoding='utf_8_sig')
print("Save:",out_file)
df_base = df.copy()
df = df.replace('-', np.nan)
conv_nums = ['Market Cap','Outstanding','Float','Avg Volume']
conv_float = ['P/E','Fwd P/E','PEG','P/S','P/B','P/C','P/FCF','EPS','Short Ratio','Curr R','Quick R','LTDebt/Eq',
'Debt/Eq','Beta','ATR','RSI','Recom','Rel Volume','Price','Target Price']
conv_pct = ['Dividend','Payout Ratio','EPS this Y','EPS next Y','EPS past 5Y','EPS next 5Y','Sales past 5Y','EPS Q/Q','Sales Q/Q',
'Insider Own','Inst Own','Inst Trans','Float Short','ROA','ROE','ROI','Gross M','Oper M','Profit M',
'Perf Week','Perf Month','Perf Quart','Perf Half','Perf Year','Perf YTD',
'Volatility W','Volatility M','SMA20','SMA50','SMA200','50D High','50D Low','52W High','52W Low',
'from Open','Gap','Change']
conv_earndate = ['Earnings']
conv_date = ['IPO Date']
for c in df.columns.to_list():
if (c in conv_nums):
df[c] = [float(str(s).translate(str.maketrans({'K':'E3','M':'E6','B':'E9','T':'E12'}))) for s in df[c]]
elif (c in conv_float):
df[c] = [float(s) for s in df[c]]
elif (c in conv_pct):
df[c] = [float(str(s).replace('%',''))/100 for s in df[c]]
elif (c in conv_date):
df[c] = [dt.strptime(str(s), '%m/%d/%Y') if re.match(r'\d+/\d+/\d+', str(s)) else s for s in df[c]]
elif (c in conv_earndate):
df['Earnings Date'] = [dt.strptime(re.sub('(.+)\/.*', r'\1', s)+' '+datetime.datetime.now().strftime("%Y"), '%b %d %Y') if s is not np.nan else s for s in df[c] ]
df['Earnings BA'] = [re.sub('.*\/(.+)', r'\1', s) if re.match(r'.*\/.*', str(s)) else np.nan for s in df[c] ]
df['prvPrice'] = df['Price'] / (1+df['Change'])
#############################################################################
def set_param(df_i, name_ta, param_ta, cat_name='', splt=''):
if(cat_name!=''):
df_i[cat_name] = ''
for i in range(len(param_ta)):
base_url = 'https://finviz.com/screener.ashx?v=521&'+param_ta[i]
df_p = pd.DataFrame()
cnt = 1
print("\r now reading -->> " +name_ta[i]+" ---" ,end="")
while 1:
url = base_url+'&r='+str(cnt)
time.sleep(0.1)
site = requests.get(url, headers={'User-Agent': 'Custom'})
num = site.text.find('<td data-boxover=\"cssbody=[hoverchart]')
ary_val=re.findall('.*&ty=c&p=d&b=1\" class=\"tab-link\"(.*)/small></td></tr>.*', site.text[num:])
ary_data = [re.findall('>(.+)</a>.+ (.+)</td>.+nowrap"> (.+)</td><td ali.+> (.+)</td>.+ <small>(.+)<', s.replace('</span>','').replace('<span class="is-red">','').replace('<span class="is-green">','')) for s in ary_val]
names = [ s[0][0] for s in ary_data]
num_list = list(range(0,len(names),4)) + list(range(1,len(names),4)) + list(range(2,len(names),4)) + list(range(3,len(names),4))
df1 = pd.DataFrame({ "idx": num_list, "Ticker" : names })
if(len(df1)>0):
print("\r now reading -->> " +name_ta[i]+' : ' +df1['Ticker'][0]+'('+str(cnt)+") ---" ,end="")
df_p = pd.concat([df_p, df1], axis=0)
if(len(df1)<500): break
cnt+=500
if(cat_name!=''):
if(splt!=''):
df_i.loc[df_p['Ticker'].to_list(),cat_name] = [s+splt+name_ta[i]+splt for s in df_i.loc[df_p['Ticker'].to_list(),cat_name].to_list()]
else:
df_i.loc[df_p['Ticker'].to_list(),cat_name] = [s+' '+name_ta[i] if s!='' else name_ta[i] for s in df_i.loc[df_p['Ticker'].to_list(),cat_name].to_list()]
else:
df_i[name_ta[i]] = 0
df_i.loc[df_p['Ticker'].to_list(),name_ta[i]] = df_p['idx'].to_list()
# df_i.loc[df_p['Ticker'].to_list(),name_ta[i]] = 1
return
#############################################################################
# 追加パラメータ
url = 'https://finviz.com/screener.ashx?v=111&ft=4'
site = requests.get(url, headers={'User-Agent': 'Custom'}, timeout=3.5)
data = BeautifulSoup(site.text,'html.parser')
value_list = [[s['value'] for s in dat.find_all('option') if 'value' in str(s)] for dat in data.find_all("select")]
name_list = [[s.text.strip() for s in dat.find_all('option') if 'value' in str(s)] for dat in data.find_all("select")]
#############################################################################
def get_param(df, num, pre_str, first_cut, last_cut ,cat_name='', splt=''):
if first_cut:
value_list[num].pop(0)
name_list[num].pop(0)
if last_cut:
value_list[num].pop(-1)
name_list[num].pop(-1)
ret_param = [pre_str+s.replace('v=111','').replace('ft=4','').replace('screener.ashx?','').replace('&','') for s in value_list[num]]
ret_name = name_list[num]
set_param(df, ret_name, ret_param, cat_name, splt)
return
#############################################################################
get_param(df, 3, '', True, False) # Signal
get_param(df, 4, 'f=exch_', True, True, 'Exchange') # Exchange
get_param(df, 5, 'f=idx_', True, False, 'Index') # Index
get_param(df, 42, 'f=sh_opt_', True, True) # Option/Short
get_param(df, 57, 'f=ta_pattern_', True, True, 'Pattern',':') # Pattern
get_param(df, 58, 'f=ta_candlestick_', True, True, 'Candlestick') # Candlestick
#############################################################################
# RS CALC
no_etf = False # RS計算のETFを外したい場合 True
df_rs = df.copy()
df_rs = df_rs.fillna({'Perf Week': 0, 'Perf Month': 0, 'Perf Quart': 0, 'Perf Half': 0, 'Perf Year': 0})
if no_etf: df_rs = df_rs[df_rs['Industry']!='Exchange Traded Fund']
df_rs['price_mid'] = df_rs['Perf Quart']
df_rs.loc[(df_rs['price_mid'] == 0), 'price_mid'] = df_rs['Perf Month']
df_rs.loc[(df_rs['price_mid'] == 0), 'price_mid'] = df_rs['Perf Week']
df_rs['price_last'] = df_rs['Perf Year']
df_rs.loc[(df_rs['price_last'] == 0), 'price_last'] = df_rs['Perf Half']
df_rs.loc[(df_rs['price_last'] == 0), 'price_last'] = df_rs['Perf Quart']
df_rs.loc[(df_rs['price_last'] == 0), 'price_last'] = df_rs['Perf Month']
df_rs.loc[(df_rs['price_last'] == 0), 'price_last'] = df_rs['Perf Week']
df_rs['POS_NOW'] = 100*(1+df_rs['price_last'])
df_rs['POS_MID'] = df_rs['POS_NOW'] / (1+df_rs['price_mid'])
df_rs['RS_Sort'] = df_rs['POS_MID']+(df_rs['POS_NOW']-df_rs['POS_MID'])*2
df_rs.sort_values('RS_Sort', ascending=True, inplace=True)
df_rs['RS']=[s/(len(df_rs)+1)*100 for s in range(1,len(df_rs)+1)]
df['RS'] = 0
df.loc[df_rs.index, 'RS'] = df_rs['RS']
#############################################################################
# 楽天証券銘のみの銘柄を削除
df = df.dropna(subset=['Company'])
out_file = data_dir+'stock_data_'+datetime.datetime.now(pytz.timezone('US/Eastern')).date().strftime("%Y%m%d")+'.csv'
df.to_csv(out_file, encoding='utf_8_sig')
elapsed_time = time.time() - start
print("\nelapsed_time: {0}".format(elapsed_time) + "[sec]")
print("Save:",out_file)実行に5~10分程かかります。(アクセスが混雑して、エラーになる場合があります。その際は時間をおいて再度実行してください。)実行が終わりましたら、Googleドライブ上にファイルができます。直接中身を確認できますが、ダウンロードして、Excelなどで確認も可能です。ファイルは二つできております。
マイドライブ>input
stock_data_20211024.csv
stock_base_20211024.csv
です。数字は日付ですが、stock_baseはfinvizのデータを加工なしで取ってきており、stock_dataはスクリーニングの為に数値に置き換えたデータになります。Googleドライブへのアクセスはこちら
データベースの説明
データベースの中身はこのような形になります。
基本情報部分
Index : インデックス採用名
Company、銘柄名(English):英語会社名
銘柄名:日本語会社名
Sector:セクター名
Industry、業種:業種名
Exchange、市場:市場名
Country:国名
取扱:楽天証券での取り扱いがあるかどうか
IPO Date:上場日
バリュエーション(株価評価)
Market Cap:時価総額
P/E:株価収益率(PER) (TTM)
Fwd P/E:予想PER
PEG:PEGレシオ(成長率レシオ1以下割安、2以上割高)
P/S:株価売上高倍率(PSR) (TTM)
P/C:
P/FCF:フリーキャッシュフロー倍率
EPS:1株当たり利益 (TTM)
EPS this Y:今年のEPS成長率
EPS next Y:来年のEPS成長率予想
EPS past 5Y:過去5年のEPS成長率
EPS next 5Y:次の5年のEPS成長率予想
Sales past 5Y:過去5年の売上成長率
EPS Q/Q:EPS四半期YoY
Sales Q/Q:売上四半期YoY
Payout Ratio:配当性向 (TTM)
ファイナンシャル(財務)
Dividend:年間配当金
ROA:総資産利益率 (TTM)
ROE:自己資本利益率 (TTM)
ROI:投資利益率 (TTM)
Curr R:流動比率 (Times) 高い方が良い
Quick R:当座比率 (Times)
Debt/Eq:負債比率
LTDebt/Eq:固定負債比率
Gross M:売上総利益率
Oper M:営業利益率
Profit M:当期純利益率
Earnings:決算日(str型)
Earnings Date:決算日(datetime型)
Earnings BA:決算日のBefore/After
テクニカル
Beta:ベータ値(S&P500に対する感応度)
ATR:Average True Range (14日移動平均)
SMA20:20日移動平均線乖離
SMA50:50日移動平均線乖離
SMA200:200日移動平均線乖離
50D High:50日最高値からの乖離率
50D Low:50日最低値からの乖離率
52W High:52週最高値からの乖離率
52W Low:52週最低値からの乖離率
RSI:相対力指数(14日移動平均)
RS:オニール使用のRS値
from Open:当日始値からの変動率
Gap:前日終値から当日始値のギャップ率
株主
Outstanding:発行済株式数
Float:浮動株式数
Insider Own:インサイダー所有率
Insider Trans:過去6か月のインサイダー所有率の動き
Inst Own:機関投資家所有率
Inst Trans:過去3ヵ月の機関投資家所有率の動き
Float Short:空売り比率
Short Ratio:
パフォーマンス
Perf Week:1週間のパフォーマンス
Perf Month:1ヵ月のパフォーマンス
Perf Quart:3ヵ月のパフォーマンス
Perf Half:6ヵ月のパフォーマンス
Perf Year:1年のパフォーマンス
Perf YTD:年初来のパフォーマンス
Volatility W:週のボラティリティー(株価変動率)
Volatility M:月のボラティリティー
Recom:アナリストの推奨(1:買い、5:売り)
Avg Volume:3ヵ月の平均出来高
Rel Volume:出来高と3ヵ月平均出来高の割合 (倍率)
その他
Price:株価
Change:前日比
Volume:出来高
Target Price:アナリストターゲット株価の平均
prvPrice:前日の株価(計算値の為正確ではない)
Optionable:オプション取引可能か
Shortable:空売り可能か
Candlestick:ローソク足種類(後述)
テクニカルシグナル(0:該当なし、1以上:該当順)Horizontal S/R:水平支持線・抵抗線
TL Resistance:上値抵抗線
TL Support:下値支持線
Wedge:ウェッジ
Wedge Up:上昇ウェッジ
Wedge Down:下降ウェッジ
Triangle Ascending:上昇型三角もちあい
Triangle Descending:下降型三角もちあい
Channel:チャネル
Channel Up:チャネル・アップ
Channel Down:チャネル・ダウン
Double Top:ダブルトップ
Double Bottom:ダブルボトム
Multiple Top:マルチトップ
Multiple Bottom:マルチボトム
Head & Shoulders:ヘッド・アンド・ショルダー・トップ
Head & Shoulders Inverse:ヘッド・アンド・ショルダー・ボトム
その他フラグ(0:該当なし、1以上:該当順)(MAX200)
Top Gainers:前日比5%以上上昇銘柄
Top Losers:前日比-5%以下下落銘柄
New High:新高値更新銘柄(場中も含む)
New Low:新低値更新銘柄(場中も含む)
Most Volatile:日中の値動きが激しい銘柄
Most Active:日中のアクティブ銘柄
Unusual Volume:異常出来高銘柄
Overbought:買われ過ぎ銘柄
Oversold:売られ過ぎ銘柄
Downgrades:ダウングレード銘柄
Upgrades:アップグレード銘柄
Earnings Before:当日市場前決算銘柄
Earnings After:当日市場後決算銘柄
Recent Insider Buying:インサイダー購入銘柄
Recent Insider Selling:インサイダー売却銘柄
Major News:ニュース銘柄
Candlestick(以下図参照)
Long Lower Shadow:下影陽線
Long Upper Shadow:上影陰線
Hammer:下影陽線・カラカサ(売り一巡、株価反転)
Inverted Hammer:上影陰線・トンカチ(買い一巡・下落サイン)
Spinning Top White:小陽線・コマ(様子見)
Spinning Top Black:小陰線・コマ(様子見)
Doji:十字線(様子見姿勢、転換を示唆)
Dragonfly Doji:トンボ(買戻しが入った形)
Gravestone Doji:塔婆(売り圧力に押し戻された形)
Marubozu White:大陽線・丸坊主(上昇一辺倒、強気サイン)
Marubozu Black:大陰線・丸坊主(下落一辺倒、弱気サイン)

フラグを使ったスクリーニング
Finvizが最初から持っているフラグを使ったスクリーニングを行います。データベースに既にスクリーニングを行った結果を保存しているので、その結果を使って出力を出します。詳細は上記の「その他フラグ」をご覧ください。現状、使えるフラグは以下の通りです。
'Top Gainers', 'Top Losers', 'New High', 'New Low', 'Most Volatile', 'Most Active', 'Unusual Volume', 'Overbought', 'Oversold', 'Downgrades', 'Upgrades', 'Earnings Before', 'Earnings After', 'Recent Insider Buying', 'Recent Insider Selling', 'Major News'
サンプルとして、以下に 'Top Gainers' を使ったスクリーニングをいたします。前日の値上がりランキング上位銘柄で、楽天証券で買える銘柄を出力します。コードは以下の通りです。
data_dir = '/content/drive/MyDrive/input/'
import os
import pandas as pd
import glob
import plotly.graph_objects as go
# データベースの読み込み
df_data = pd.read_csv(sorted(glob.glob(data_dir+'stock_data*.csv'), key=lambda f: os.stat(f).st_mtime, reverse=True)[0], index_col=0)
df_base = pd.read_csv(sorted(glob.glob(data_dir+'stock_base*.csv'), key=lambda f: os.stat(f).st_mtime, reverse=True)[0], index_col=0)
# 日本で購入できる銘柄に絞る
df_data = df_data.dropna(subset=['銘柄名'])
############################################################################
# スクリーニング可能検索項目
############################################################################
# 基本情報
# 'Index','Company','銘柄名(English)','銘柄名','Sector','Industry','業種','Exchange','市場','Country','取扱','IPO Date'
# バリュエーション(株価評価)
# 'Market Cap','P/E','Fwd P/E','PEG','P/S','P/B','P/C','P/FCF','EPS','EPS this Y','EPS next Y','EPS past 5Y','EPS next 5Y'
# 'Sales past 5Y','EPS Q/Q','Sales Q/Q','Payout Ratio'
# ファイナンシャル(財務)
# 'Dividend','ROA','ROE','ROI','Curr R','Quick R','Debt/Eq','LTDebt/Eq','Gross M','Oper M','Profit M','Earnings','Earnings Date','Earnings BA'
# テクニカル
# 'Beta','ATR','SMA20','SMA50','SMA200','50D High','50D Low','52W High','52W Low','RSI','RS','from Open','Gap',
# 株主
# 'Outstanding','Float','Insider Own','Inst Own','Inst Trans','Float Short','Short Ratio'
# パフォーマンス
# 'Perf Week','Perf Month','Perf Quart','Perf Half','Perf Year','Perf YTD','Volatility W','Volatility M'
# 'Recom','Avg Volume','Rel Volume'
# その他
# 'Price','Change','Volume',Target Price','prvPrice','Optionable','Shortable','Candlestick'
############################################################################
# テクニカル
# 'Horizontal S/R','TL Resistance','TL Support','Wedge Up','Wedge Down','Triangle Ascending','Triangle Descending',
# 'Wedge','Channel Up','Channel Down','Channel','Double Top','Double Bottom','Multiple Top','Multiple Bottom',
# 'Head & Shoulders','Head & Shoulders Inverse'
############################################################################
# CandleStick
# 'Long Lower Shadow','Long Upper Shadow','Hammer','Inverted Hammer','Spinning Top White','Spinning Top Black','Doji',
# 'Dragonfly Doji','Gravestone Doji','Marubozu White','Marubozu Black'
############################################################################
# フラグ
# 'Top Gainers','Top Losers','New High','New Low','Most Volatile','Most Active','Unusual Volume'
# 'Overbought','Oversold','Downgrades','Upgrades','Earnings Before','Earnings After'
# 'Recent Insider Buying','Recent Insider Selling','Major News'
# スクリーニング
title = '値上がりトップ銘柄'
df_screening = df_data.copy()
df_screening = df_screening[ df_screening['Top Gainers']>0 ]
# 並び替え
df_screening.sort_values('Top Gainers', ascending = True, inplace = True)
df_disp = df_base.loc[df_screening.index,]
import plotly.graph_objects as go
fig = go.Figure(data=[go.Table(
header=dict(values=['Ticker','銘柄名','業種','前日比'], line_color='black', fill_color='rgb(247,203,77)',
align='center', font_color='black',font_size=16, height=30),
cells=dict(values=[df_disp.index, df_disp['銘柄名'], df_disp['業種'], df_disp['Change']],
line_color='black',
fill_color=[['rgb(254,248,227)','rgb(255,255,255)']*(int(len(df_disp)/2)+1)],
align=['center'],
font_size=16, height=30)
)],
)
title = title +' ('+str(len(df_screening))+'銘柄)'
fig.update_layout(
title={'text': title, 'y': 0.9, 'x': 0.5},
font={ 'family': 'Noto Sans CJK JP', 'size': 16},
width=1100
)
fig.show()出力は以下の通りです。

特にスクリーニングを書かなくても簡単に出せました。
複数条件でのスクリーニング
次にカスタマイズしたスクリーニングを行ってみます。試しに、CAN-SLIM(オニール投資)の条件である、以下を使ってスクリーニングしてみます。RS70以上、YoY25%以上、新高値、ROE17%以上、インサイダー持ち株比率 1%以上、出来高上昇銘柄。コードは以下の通りです。
data_dir = '/content/drive/MyDrive/input/'
import os
import pandas as pd
import glob
import plotly.graph_objects as go
df_data = pd.read_csv(sorted(glob.glob(data_dir+'stock_data*.csv'), key=lambda f: os.stat(f).st_mtime, reverse=True)[0], index_col=0)
df_base = pd.read_csv(sorted(glob.glob(data_dir+'stock_base*.csv'), key=lambda f: os.stat(f).st_mtime, reverse=True)[0], index_col=0)
# 日本で購入できる銘柄に絞る
df_data = df_data.dropna(subset=['銘柄名'])
title = 'スクリーニング銘柄'
df_screening = df_data.copy()
df_screening = df_screening[
(df_screening['RS']>70)& # RS 70以上
(df_screening['EPS Q/Q']>0.25)& # EPS YoY 25%以上
(df_screening['Sales Q/Q']>0.25)& # 売上 YoY 25%以上
(df_screening['New High']>0)& # 新高値更新
(df_screening['ROE']>0.17)& # ROE 17%以上
(df_screening['Inst Own']>0.01)& # インサイダー持ち株比率 1%以上
(df_screening['Rel Volume']>=1) # 出来高上昇
]
# 並び替え(時価総額順)
df_screening.sort_values('Market Cap', ascending = False, inplace = True)
df_disp = df_base.loc[df_screening.index,]
##### 表示 #####
fig = go.Figure(data=[go.Table(
header=dict(values=['No','Ticker','銘柄名','業種','時価総額','RS', 'ROE','EPS YoY','Salse YoY','前日比'], line_color='black', fill_color='rgb(247,203,77)',
align='center', font_color='black',font_size=16, height=30),
cells=dict(values=[list(range(1,len(df_disp)+1)),df_disp.index, df_disp['銘柄名'], df_disp['業種'], df_disp['Market Cap'],
['{:.0f}'.format(s) for s in df_screening['RS']],
df_disp['ROE'], df_disp['EPS Q/Q'], df_disp['Sales Q/Q'],df_disp['Change']],
line_color='black',
fill_color=[['rgb(254,248,227)','rgb(255,255,255)']*(int(len(df_disp)/2)+1)],
align=['center'],
font_size=16, height=30)
)],
)
title = title +' ('+str(len(df_screening))+'銘柄)'
fig.update_layout(
title={'text': title, 'y': 0.9, 'x': 0.5},
font={ 'family': 'Noto Sans CJK JP', 'size': 16},
width=1100
)
fig.show()出力結果は以下の通りです。
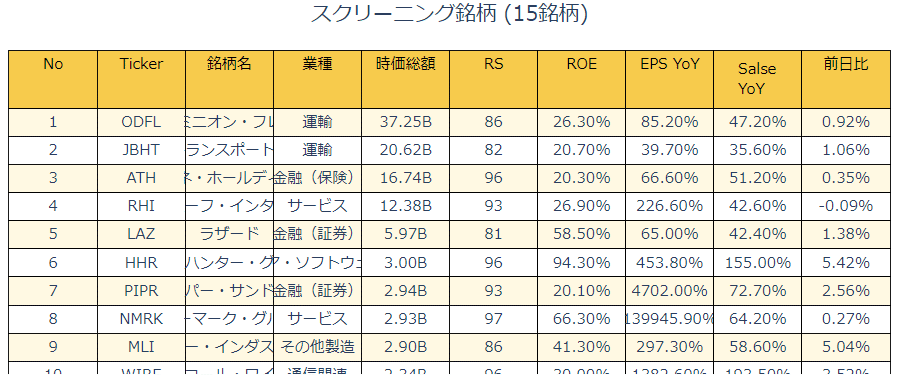
課題:
上記のコードを参考にして、自分が好きな銘柄を探してみましょう。また、チャートのパターンで検索してみましょう。
次回からさらに色んなスクリーニング条件でスクリーニングを行う方法を増やしていきます。
ここから先は
¥ 150
サポートいただけますと、うれしいです。より良い記事を書く励みになります!