
「ToyADMOS:異常音検知」手法比較:CNN と AutoEncoder

はじめに
機械学習(ML)やディープラーニング(DL)の発展が目覚ましいため、この分野に関心を持っておりました。基礎から学ぶためにAidemyプレミアム(データ分析:6か月)を受講しました。
略歴:
半導体前工程データ分析(8年)⇒産業用ロボットの故障予知など(5年)
背景
産業用機器の予兆・異常検知では振動計やモータ電流等を用いた手法が中心です。最近、音を用いた検出技術についても実用化されてきていますが、まだまだ事例が少ないです。従来の異音検査では検査員の勘や経験に頼る部分も多く、エキスパートの育成や検査に時間がかかるなど課題が多いです。常時、計測した音の状態変化を捉える事ができれば、検査時間の大幅な短縮などや人手不足による検査要員の不足を補うことができます。
今回は、Toy ADMOSという公開データセットを用いて、正常/異常の状態を検知する異常検出器を作成・検証してみました。
目的
現場では異常モードのデータを網羅できていないケースが多いため、異常値・正常値の2値分類を教師なし学習と教師あり学習で行い比較しました。教師あり学習ではCNN、教師なし学習ではAutoEncoderを採用しました。評価指標としては、f1-score・Recall(再現率)と学習時間、推論時間に着目します。
結論
f1-score・Recall(再現率)・学習時間・推論時間ともに、CNNがAutoEncoderよりも優れている結果となりました。CNNの方が精度よく分類でき、推論時間も速いため、実用に適していると思われます。
・f1-score : CNN > AutoEncoder
・recall : CNN ≧ AutoEncoder
・学習時間: CNNが約3~4倍速い
・推論時間: CNNが約3倍速い




環境
環境:Google Colaboratory
データセット
データセット: ToyADMOS”異常音検知のためのおもちゃ稼働音データセット”
・ToyADMOSデータセットは、3種類(Car, Conveyor, Train)あります 。
・ダウンロードはこちら。
今回は以下データを利用しました。
【音の対象】
●ToyCar (case1~case4)
●ToyConveyor(case1~case3)
【音の種類】
●Normal sound:正常音(ToyCar:1350個、ToyTrain:1800個)
●Anomalous sound:異常音(ToyCar:53種類/各5個、ToyTrain:80種類/各5個)
【音ファイルの形式】
●IND:スタートとストップがある(先頭と末尾に無音区間アリ)
【音ファイルのチャンネル】
●音声チャンネル:CH1(対象に一番近いマイク)
・機器の配置

・ToyCarの異常モードの説明


・ToyConveyorの異常モードの説明


データ確認・異常値除外
学習に支障をきたすので、正常/異常データから無音データを除外。

検証モデル
教師あり学習(CNN)と教師なし学習(AutoEncoder)を比較します。

モデル構成とコード
●CNN:コード
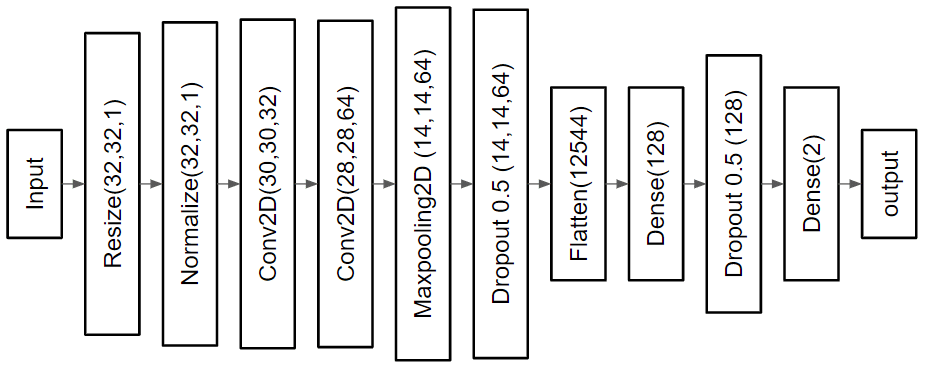
●AutoEncoder: コード

学習シーケンス
1.教師あり学習:CNN
波形(ラベル付き、正常&異常) ⇒ STFT ⇒ CNN

2.教師なし学習:AutoEncoder
・Step1(モデル学習):
波形(ラベルなし、正常のみ) ⇒ FFT ⇒ 正規化 ⇒ AutoEncoder

・Step2(閾値決定):
TrainData ⇒ 学習済みモデル ⇒ 入力データと予測データの平均絶対誤差(MAE)分布確認 ⇒ 閾値決定(再構成誤差の平均+2σ)
※MAE:Mean Absolute Error

予測シーケンス
1.教師あり学習:CNN
波形 ⇒ STFT ⇒ 学習済みモデル ⇒ 予測ラベル(確率)
2.教師なし学習:AutoEncoder
波形 ⇒ FFT ⇒ 学習済みモデル ⇒ 波形再構成 ⇒ 再構成誤差を計算
⇒ 閾値と比較 ⇒ 予測(閾値以下を正常と判別)
評価方法
異常検知という観点では、異常の取りこぼしがあると大変困るため、recall(再現率)を主に見ていきます(FNを最小化したい)。precisioin(適合率)が低いと狼少年となる場合もありますが、、、
Accuracy(精度): どれだけ正確に予測できたか
$${Accuracy(精度)= \frac{TP + TN} {TP+TN+FP+FN}}$$
precisioin(適合率): 正と予測したものがどれだけ正しかったか
全ての正であると予測したデータ(分母)において、実際に正のデータであるもの(分子)
$${precisioin(適合率) = \frac{TP} {TP+FP}}$$
recall(再現率): どれだけ取りこぼしなく予測することができたか
全ての正のデータ(分母)において、正であると予測できたもの(分子)
$${recall(再現率) = \frac{TP} {TP+FN}}$$
f1 score(適合率と再現率の調和平均):$${f1 score = 2×\frac{適合率×再現率} {適合率+再現率}}$$

評価結果
recall(再現率)では7データセットのうち、CNNが6勝1敗。CNNは2D画像を入力として学習するので、AutoEncoderに比べて情報量が多く、より多くの特徴を捉える事ができたと思われれます。
また、データセットによる違いが大きく出てきました。ToyCarは正常データと異常データの差がToyConveyorに比べて小さいため、データセットによる再現率の違いが生まれたと思われます。
ToyCarデータセットでは、AutoEncoderのrecallが0.4~1.0とバラついており、4セット中3セットでCNNに負けています。これは閾値設定と波形の前処理に問題がありそうです。
AutoEncoderの閾値について:
学習時の正常データの入力波形と出力波形とのMAEの分布を確認し、閾値を平均値+2σで設定しました。正常データと異常データのMAEの分布に重なりがあり、car2以外の閾値を最適化できていない可能性が高いです。ROCカーブ等を試しましたが、異常データ数が正常データ数に比べて少ないため、最適な閾値を設定できませんでした。今後の課題です。



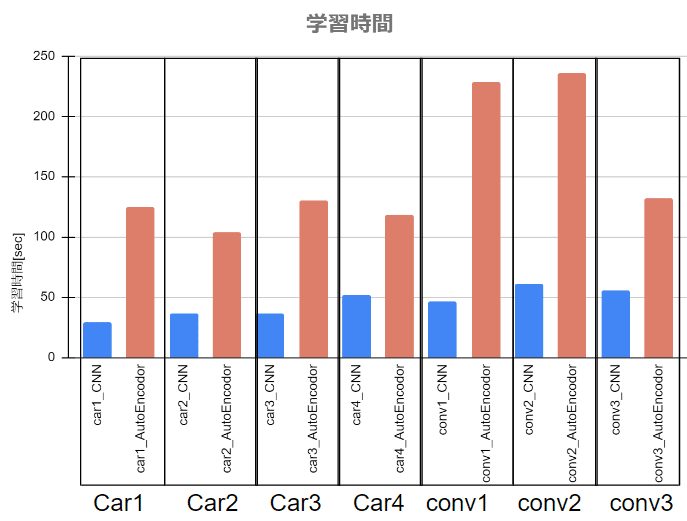
学習時間
学習時間は、CNNがAutoEncoderの約3~4倍になりました。AutoEncoderのパラメータ数がCNNの約200倍なのが原因と思われます。
これは、AutoEncoderでは、入力している正規化周波数波形のデータ点数が多いことに起因すると思われます。

推論時間
推論時間は、CNNで60.7[msec]、AutoEncoderで180[msec]と、CNNの方が約3倍高速です。特にデータセットによる違いは見られません。

今後の活用
実務レベルで使えるようにさらなる機能向上・精度向上に取り組んでいきたいと思います。
CNNの精度が比較的高く、本当に驚きました。今後は、異常状態のモード分類も行えるようにしたいです。異常のモード別データ数が少ないため、データ水増し等の手法を試していきたいと思います。
また、教師なし学習ではAutoEncoderを試してみましたが、GANを利用した異常検出を試してみたいです。
追加検証
・教師なし学習による異常検知~AutoEncoder色々~(2022/11/6)
AutoEncoderについて追加検証しました。
・1D AutoEncoderと2D AutoEncoderの比較
・閾値決定手法の検証(ROCカーブによる決定)
・Audioデータのダウンサンプリング(48kHz ⇒ 16 kHz)
・異常音検知:ノイズに対するロバスト性の検証(CNN・AutoEncoder)(2022/11/11)
CNN/AutoEncoderのノイズ重畳信号に対する性能を比較しました。
・教師なし(AutoEncoder)のロバスト性は低い
・教師あり(CNN)のロバスト性は高い
終わりに
アイデミーの講座は大変分かりやすく、機械学習・ディープラーニングの敷居が下がり、面白さを実感できました。Tensorflowなどの習熟度を高めていきたいと思います。
課題添削やチューターの指導も丁寧で分かりやすかったです。
体調不良のため最後の2カ月ほど学習ができず、とても残念な結果となりました。休学制度(最大一カ月)を利用させていただき大変助かりました。有難うございます。
参考文献
[1] Koizumi, Yuma, et al. “ToyADMOS: A Dataset of Miniature-Machine Operating Sounds for Anomalous Sound Detection.” arXiv preprint arXiv:1908.03299 (2019).
[2] Koizumi, Yuma. “ToyADMOS Dataset” GitHub (2020).
変更履歴
2022/11/6 リンク追加(教師なし学習による異常検知)
2022/11/11 リンク追加(異常音検知:ノイズに対するロバスト性の検証)
2022/11/12 図を追加
・結果 ⇒ スコア・学習時間・パラメータ数
・学習シーケンス ⇒ モデル学習、閾値決定
2022/11/13 推論時間追加