【Aidemy X MIT】MITのチュートリアルの教材を利用して、ワインの特性データの分類(classification)を深めてみる!


MITのEric Maさんが数年前にBroad Instituteで行った機械学習のチュートリアルを利用して、Aidemyの教師なし学習のコースででてくるワインの特性データーを分類してみる!なお機械学習のチュートリアルについては、前のnoteの記事
【Aidemy X MIT】MITのチュートリアルの教材を利用して、ワインの特性データのクラスタリングを深めてみる!
を参考にしていただくと良いだろう。
機械学習の概要
機械学習は簡単なものは日常的に使われ、
教師あり学習:分類(classification)、回帰(regression)など
教師なし学習: クラスタリング、Manifold learningなど
があり、今回は教師あり学習の分類を行う。
Eric Maさんのチュートリアル

Eric Maさんは自身のウィルス研究に用いたデータを利用して、インフルエンザウィルスの宿主の種類の分類を行うチュートリアルをGithubで公開されている。宿主(ヒト、トリなど)の文字データをLabelBinarizerをつかって数値化したりしていろいろヒントとなることが多いのだが、今回は分類が主目的なので、キモのところだけ利用させていただく。
前にも述べたように、このワインの特性データはもともとscikit-learnについているもので、3つのグループに分けられた178種類のワインについて、以下の13個の属性について数値データが載せられているものである。
1) Alcohol
2) Malic acid
3) Ash
4) Alcalinity of ash
5) Magnesium
6) Total phenols
7) Flavanoids
8) Nonflavanoid phenols
9) Proanthocyanins
10)Color intensity
11)Hue
12)OD280/OD315 of diluted wines
13)Proline
今回はこの3つのグループを、13の属性データをつかって予測できないか調べてみた!
分類の実際
データをとって標準化し
その後でデータをトレーニングデータとテストデータにわけ、
ランダムフォレストクラァシファイヤーで分類
accuracy scoreを計算し
0.94444444444444442
とまずまずの結果である!
こうした分類の手法はAidemyのコースでもおなじみである。
またEric Maさんのチュートリアルだとさらに、13の属性のうちどれが予測に効いているかをプロット(plt.plot(clf.feature_importances_))させてみたりしているので、興味深い
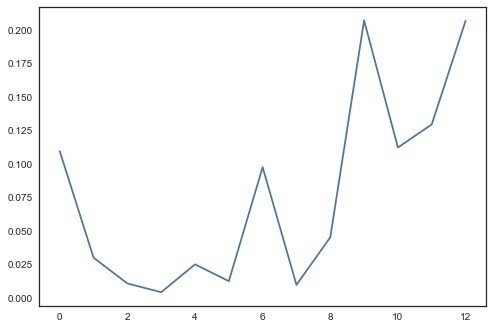
これだと0,6,9,12あたりが分類に効いているということだろう。
また他の分類方法、Decision Treeについてもおこなっており、
これだとaccuracy score
0.94444444444444442
とランダムフォレストと同じ
属性については
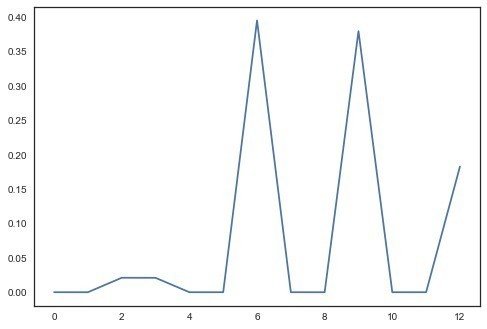
6,9,12が効いているらしい。
どちらの分類方法がいいのかな?というのが、Eric Maさんの質問だけれど、個人的にはDecision Treeの方がいいのかなとおもったりする。。
実際のところどうなんだろうか?
ここで利用したコードは
で参照できます。