
4-6. 木の探索順番に関する問題演習

本記事では、データ構造の木の探索法に関する問題演習をします。
問題 次の木を探索したところ、次のような順番で値をたどった。それぞれの探索法は何か。
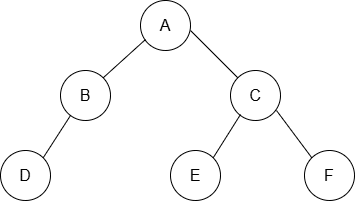
選択肢
(1) D → B → A → E → C → F
(2) A → B → C → D → E → F
(3) A → B → D → C → E → F
(4) D → B → E → F → C → A
解答
(1) (D → B) → A → (E → C → F) は中間順探索
(2) A → B → C → D → E → F は幅優先探索
(3) (A → (B → D )→ (C → E → F)) は先行順探索
(4) ((D → B) → (E → F → C) → A) は後行順探索
補足
それぞれの探索アルゴリズムを擬似コード
木構造の探索順(先行順・中間順・後行順・幅優先)は、それぞれの目的や用途に応じて使い分けられます。以下に、それぞれの特徴と適した用途を整理します。
1. 先行順探索(Preorder Traversal)
順序: 根 → 左部分木 → 右部分木
用途と目的
コピーやクローンの作成
先に根を処理するので、新しい木を構築するのに適している。
構文解析(抽象構文木, AST)
プログラムの構文解析で、演算子(親)が先に評価されるときに使う。
バックトラッキング・探索
ゲーム木や状態空間探索で、全体の構造を先に確認したい場合に有効。
具体例
式木の構文解析(例: + 3 * 2 5 → + (3, * (2,5)))
ファイルシステムのコピー(フォルダを先に作り、その後ファイルを作成)
Preorder(node):
if node is not NULL:
Visit(node) # ルートを処理
Preorder(node.left) # 左部分木を探索
Preorder(node.right) # 右部分木を探索
2. 中間順探索(Inorder Traversal)
順序: 左部分木 → 根 → 右部分木
用途と目的
二分探索木(BST)のソート
昇順にノードを処理できるため、ソート済みの出力が得られる。
木の順序保持が必要な場合
データの順序を維持しながら処理する必要がある場合に使用。
具体例
ソート済みのデータ取得(BSTの中間順探索でソート)
数式の中置記法への変換(例: 3 + (2 * 5))
Inorder(node):
if node is not NULL:
Inorder(node.left) # 左部分木を探索
Visit(node) # ルートを処理
Inorder(node.right) # 右部分木を探索
3. 後行順探索(Postorder Traversal)
順序: 左部分木 → 右部分木 → 根
用途と目的
メモリ管理(ガベージコレクション)
親を削除する前に、子ノードを処理する必要がある場面。
ディレクトリ削除
フォルダを削除する前に、中のファイルやサブフォルダをすべて削除する。
式木の評価(逆ポーランド記法, RPN)
数式の演算順に適用可能(例: 3 2 5 * +)
具体例
ファイルシステムの削除(サブフォルダを削除してから親を削除)
数式の評価(RPN計算)
Postorder(node):
if node is not NULL:
Postorder(node.left) # 左部分木を探索
Postorder(node.right) # 右部分木を探索
Visit(node) # ルートを処理
4. 幅優先探索(BFS: Breadth-First Search)
幅優先探索(BFS)は、木やグラフの探索アルゴリズムの一種で、「近いノード(頂点)」から順に探索する方法です。
BFS は キュー(Queue) というデータ構造を使って、
根(スタートノード)を最初に訪問
隣接するノードを順番に探索
次のレベルのノードへと進む
という手順で探索を行います。
BFSの基本アルゴリズム
擬似コード
BFS(root):
queue ← Empty Queue # 探索するノードを格納するキュー
queue.enqueue(root) # 最初に根をキューに入れる
while queue is not empty:
node ← queue.dequeue() # キューから先頭のノードを取り出す
Visit(node) # そのノードを訪問(処理)
if node.left is not NULL:
queue.enqueue(node.left) # 左の子をキューに追加
if node.right is not NULL:
queue.enqueue(node.right) # 右の子をキューに追加
具体例
例1: 二分木のBFS
入力となる木
A
/ \
B C
/ \ \
D E F
探索の流れ
A をキューに入れる → A を取り出して訪問
A の子 B, C をキューに入れる → B を取り出して訪問
B の子 D, E をキューに入れる → C を取り出して訪問
C の子 F をキューに入れる → D を取り出して訪問
E を取り出して訪問 → F を取り出して訪問
結果
A → B → C → D → E → F
応用例
最短経路探索(例: Google マップの経路検索)
Web クローリング(例: 検索エンジンがサイトを巡回)
迷路探索(例: ロボットのナビゲーション)
ネットワーク解析(例: コンピュータ間の通信パス探索)
まとめ
✅ BFSは「近いノードから順に探索する」アルゴリズム
✅ キューを使ってレベルごとに探索する
✅ 最短経路探索やWebクローリングに適している
用途別の探索選択

結論
木の構造を保持しながら処理するなら → 先行順
ソート目的なら → 中間順
後処理が必要(削除・演算など)なら → 後行順
最短ルートや階層ごとの処理なら → 幅優先探索
以上です。
いいなと思ったら応援しよう!
