
OpenRadiossでゴム製のくりまんじゅうを落下させてみた - 前編

お盆休みに触り始めたOpenRadiossが面白かったのでくりまんじゅう(※)をポヨンポヨンさせてみました。
※ちいかわ©naganoのキャラクター。お酒が大好き。
#openradioss #python #ちいかわ #オープンCAE
前編(本記事)
FreeCADで作ったくりまんじゅうのモデルをLS-PrePostを用いてメッシュ作成しLS-DYNA Keyword fileとして出力
出力したファイルのメッシュ情報をRadioss形式に変換するアプリをPythonで作成し変換(2024/08/31追記:変換なしでもOKなようですm(__)m)
後編
前編で変換したファイルを用いてstarterファイルおよびengineファイルを作成
計算の実行と可視化
概要
OpenRadiossを使ってゴムでできたくりまんじゅうを固定平面に落下させたときのシミュレーションを行ってみます。
シミュレーションに関する具体的な条件は後編に記載します。
前編では主にLS-PrePostの操作とメッシュ情報変換アプリについて記していきます。
FreeCADで作成したモデルの出力
先回記事(下記リンク)で登場した、過去FreeCADの練習として作成したくりまんじゅうのモデルを今回も使用します。 (さすがにこのモデルファイルを公開するのはまずそうなので控えておきます。。。)
https://note.com/tofusw/n/n708a5f622b61
出力するくりまんじゅうのモデルを選択後にFreeCADの画面左上の ファイル -> エクスポートからIGES formatを選択するとiges形式で出力されます。
iges以外でもLS-PrePostでちゃんと読めればなんでも良いかと思います。
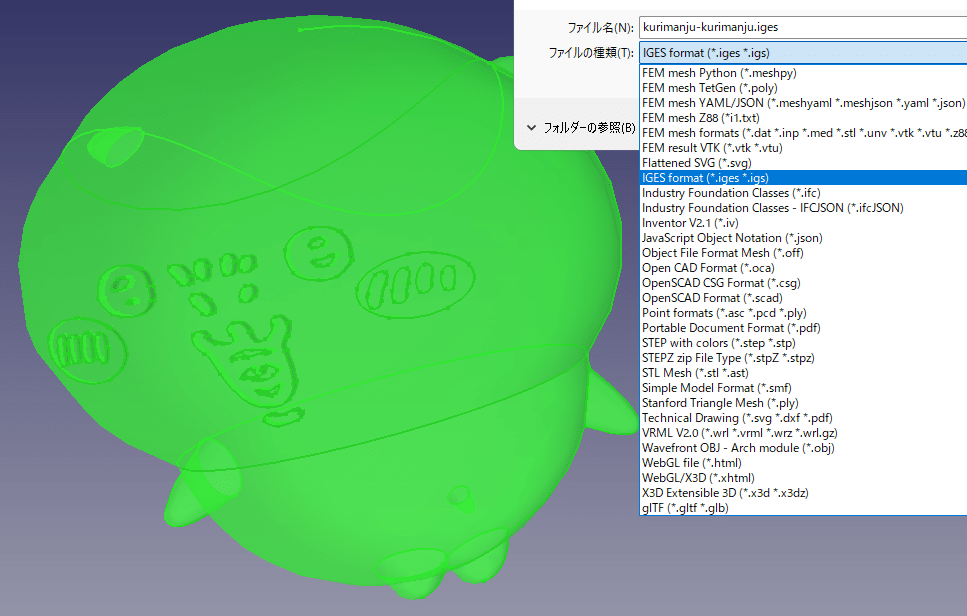
出力されたファイルをLS-PrePostへ読み込ませます。
LS-PrePostでのメッシュ作成
今回はメッシュ作成にGmshではなくあえてLS-PrePostを使ってみました。
GmshだとRadioss形式の出力に対応しているため本来はこちらを使うべきだと思うのですが・・・
前回やったような節点グループの取得などLS-PrePostのほうが小回りが利きそう?だったのと、なんとなくLS-PrePostのほうが使いやすいなぁと感じたからです。(個人の感想です^p^;)
出力したigesファイルをLS-PrePostへインポートします。
File -> Import -> IGES File から先ほど出力したファイルを選択すると下記のように表示されます。shiftを押しながらドラッグするとグリグリ動かせます。


ここから右側のアイコンのElement and Mesh -> Tetrahedron Mesher を選択すると下記のような画面が表示されます。

立ち上がった画面上部のMesh ModeのPick skin Geometryを選択。さらにSel. Geom.画面が表示されるので左上の area を選択し、くりまんじゅう全体が選択されるようにドラッグします。選択されるとその部分の色がグレーになります。

Edgeにメッシュの一辺の長さの目安値を入力し Tria Mesh をクリックするとメッシュ作成が始まります。だいたい一発でうまくいかずにアスペクト比が高すぎるいびつなメッシュがあるよーって怒られます。

頭頂部や手足の先端などでこのように細長いメッシュが形成されてしまっていました。

Skin RemeshのMin edge sizeとMax edge sizeに適当な値を入れてRemeshします。
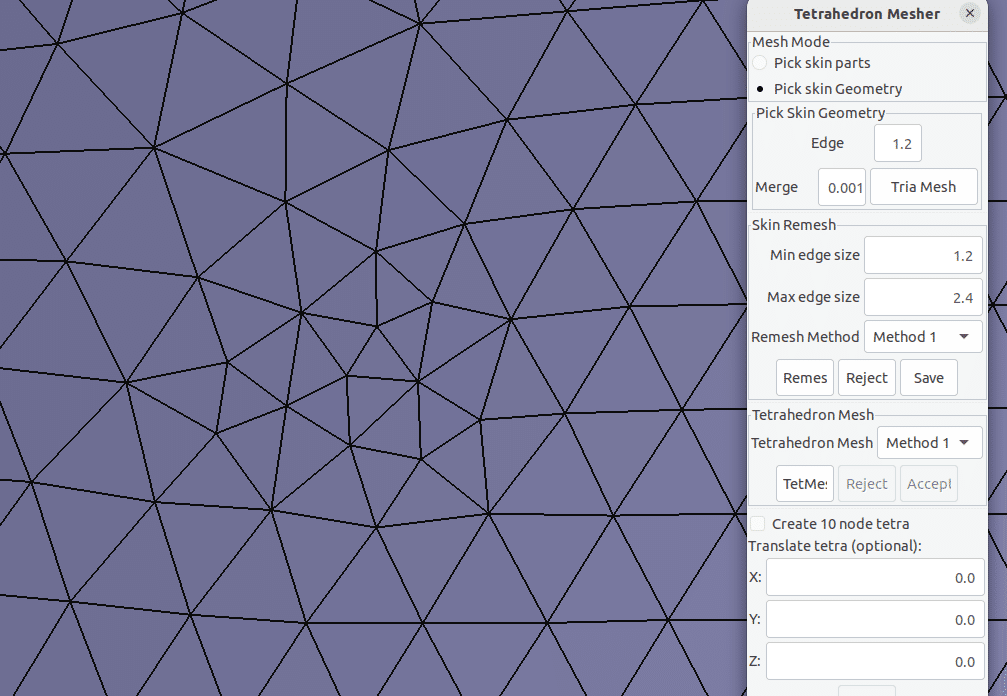
無事きれいになったことを確認できたら最後にTetrahedron MeshのTet Mesh(表示が途中で切れちゃってる・・・)ボタンをクリックするとくりまんじゅうの内部も含めて体全体がメッシュ化されます。

左上のツリーでメッシュ化された部分だけにチェックを入れてFile -> Save As -> Save Keyword As...でキーワードファイル(~.k)を出力します。

これでメッシュ作成とファイル出力は完了です。
参考:メッシュを自由に切り取りすることもできます^p^

変換アプリの作成
※2024/08/31追記:どうやらこんな回りくどいことしなくてもよかったみたいです\(^o^)/
LS-Dynaフォーマットのインプットを使ってOpenRadiossで計算実行する手順
*SET_NODE_LISTの部分だけはもしかしたら使えるかもしれませんので下記の記事およびコードはそのまま残しておきます。。。お目汚し失礼しましたm(__)m
LS-PrePostから出力されたファイルは下記のような形式のファイルになっています。
$# LS-DYNA Keyword file created by LS-PrePost(R) 2024/R2(4.11.8)-25Jul2024
$# Created on Aug-30-2024 (20:31:54)
*KEYWORD
*NODE
$# nid x y z tc rc
1 25.65533 0.0 80.40655 0 0
2 0.025503 0.152563 89.99805 0 0
3 24.78354 0.0 81.18334 0 0
...(省略)...
*PART
$# title
New part from tetrahedron mesher
$# pid secid mid eosid hgid grav adpopt tmid
1 0 0 0 0 0 0 0
*ELEMENT_SOLID
$# eid pid n1 n2 n3 n4 n5 n6 n7 n8
1 1 698 1022 19396 25274 25274 25274 25274 25274
2 1 30261 29946 33830 34867 34867 34867 34867 34867
3 1 14184 14044 21527 22852 22852 22852 22852 22852
...(省略)...
400616 1 72705 72643 72739 72764 72764 72764 72764 72764
400617 1 48045 58293 63680 72765 72765 72765 72765 72765
400618 1 58293 48045 58974 72765 72765 72765 72765 72765
*ENDこれをRadioss形式に変換するアプリをPythonで作成しました。
自分用に作成したものなのでまだまだ機能不足ですし、不具合も残っているかと思います。
コードは本記事の末尾にありますのでそのままPythonで実行してもらえば下記のような画面が立ち上がります。

pandas(numpy)とfletを使用しているのでインストールしていない場合は
pip install pandas fletで事前にインストールしておいてください。
Select fileをクリックするとファイル選択ダイアログが表示されるので変換するファイルを選択するとそのパスが表示されます。その状態でConvertをクリックすると変換が開始され画面下側にログが表示されるとともに選択ファイルと同じ場所に変換後のファイル(~.inc)が生成されます。
変換仕様は主に下記の通りです。
動作の詳細は末尾のコードを参照ください。
下記のキーワードに対応
*NODE, *ELEMENT_SOLID, *ELEMENT_SOLID (ten nodes format), *ELEMENT_SHELL,*SET_NODE_LIST入力ファイルと同じ場所に変換後の各ファイルを出力(出力ファイル名は固定なので上書きに注意)
*SET_NODE_LISTは1ファイル中に複数行ある場合は/GRNOD/NODE/(1,2,...)で区切って出力
*NODE, *ELEMENT_SOLID, *ELEMENT_SOLID (ten nodes format), *ELEMENT_SHELLは1ファイル中にそれぞれ1行しかないものと仮定
*ELEMENT_SOLIDはn4~n8がすべて等しい場合はTETRA4、それ以外の場合はBRICKとして出力(複数pid対応可)
*ELEMENT_SHELLはn3とn4が等しい場合はSH3N、等しくない場合はSHELLとして出力(複数pid対応可)
下記はsolid_t4_brick.incの先頭部分の例です。(*ELEMENT_SOLID部分の変換)pidが複数ある場合は~/1, ~/2と分けて出力されます。
/TETRA4/1
1 698 1022 19396 25274
2 30261 29946 33830 34867
3 14184 14044 21527 22852今回作成したくりまんじゅうのメッシュは*NODEと*ELEMENT_SHELL(全てTETRA4)のみなのでnode.incとsolid_t4_brick.incが生成されます。これをstarterファイル中で#includeしてやります。
後編へ
後編では生成した.incファイルを用いてOpenRadiossで計算を行い結果を可視化します。
参考資料
Create mesh in LS-Dyna R11 / ls-dyna tutorial
LS-Dynaフォーマットのインプットを使ってOpenRadiossで計算実行する手順
変換アプリPythonコード
# flake8.args = ["--ignore=E501, F401, W503"]
# lspp_output_ver = V971_R11
# ---------- Supported keywords ----------
# *NODE
# *ELEMENT_SOLID
# *ELEMENT_SOLID (ten nodes format)
# *ELEMENT_SHELL
# *SET_NODE_LIST
# ----------------------------------------
import os
import logging
import traceback
import math
import numpy as np
import pandas as pd
import flet as ft
from pathlib import Path
from typing import Tuple, Dict
VERSION = '1.0.0-beta'
def get_df_and_idx(keyword_file_path: str) -> Tuple[pd.DataFrame, Dict[str, pd.DataFrame]]:
"""
LS-PrePostのKeyWord出力ファイルのパスから生データdfとキーワード行のindex情報を返す
"""
# df取得
df = pd.read_table(keyword_file_path,
dtype=str,
encoding='utf-8',
names=['raw_data'])
# 先頭が*で始まる行を抽出し開始行と終了行を算出
df_asterisk = df[df['raw_data'].str.startswith('*')]
df_asterisk = df_asterisk.reset_index(drop=False, names=['idx', 'raw_data'])
df_asterisk['idx'] = df_asterisk['idx'].astype(int)
df_asterisk['idx_shift'] = df_asterisk['idx'].shift(-1).fillna(0).astype(int)
# 各キーワードの行を抽出しdictに格納
idx_node = df_asterisk[df_asterisk['raw_data'].str.startswith('*NODE')]
idx_solid_t4_and_brick = df_asterisk[df_asterisk['raw_data'].str.startswith('*ELEMENT_SOLID')]
idx_solid_t10 = df_asterisk[df_asterisk['raw_data'].str.startswith('*ELEMENT_SOLID (ten nodes format)')]
idx_shell = df_asterisk[df_asterisk['raw_data'].str.startswith('*ELEMENT_SHELL')]
idx_setnode = df_asterisk[df_asterisk['raw_data'].str.startswith('*SET_NODE_LIST')]
idx_allend = df_asterisk[df_asterisk['raw_data'].str.startswith('*END')]
idxs = {
'idx_node': idx_node,
'idx_solid_t4_and_brick': idx_solid_t4_and_brick,
'idx_solid_t10': idx_solid_t10,
'idx_shell': idx_shell,
'idx_setnode': idx_setnode,
'idx_allend': idx_allend
}
# *END以降の行を削除
if not idx_allend.empty:
idx_all_end = idx_allend['idx'].values[0]
df = df.iloc[:(idx_all_end + 1)]
else:
logging.error('*END not found')
return None
return df, idxs
def split_raw_data(input_df: pd.DataFrame,
input_colname: str,
output_coln: int) -> None:
"""
LS-PrePostのKeyWord出力生データ文字列を半角スペースで列に分割したデータフレームを返す
"""
df = input_df.copy()
df = df[input_colname].astype(str)
df = df.str.strip()
df = df.str.split(r' +', expand=True)
df = df[list(range(output_coln))]
return df
def convert_node(input_df: pd.DataFrame,
idx_df: pd.DataFrame,
output_path: str) -> None:
"""
LS-PrePostのKeyWord出力の*NODE部分をRadioss形式に変換して出力する
"""
# 開始行と終了行
idx_start = idx_df['idx'].values[0] + 2
idx_end = idx_df['idx_shift'].values[0]
# データフレームを分割
df = input_df.copy()
df = df.iloc[idx_start:idx_end].reset_index(drop=True)
# 文字列を分割
colnames = ['nid', 'x', 'y', 'z']
df = split_raw_data(df, 'raw_data', len(colnames))
df.columns = colnames
# 指定数の半角スペースで埋める
df['nid'] = df['nid'].str.rjust(10, ' ')
df['x'] = df['x'].str.rjust(20, ' ')
df['y'] = df['y'].str.rjust(20, ' ')
df['z'] = df['z'].str.rjust(20, ' ')
# 各列の結合およびヘッダ行の追記
node = df['nid'] + df['x'] + df['y'] + df['z']
header = pd.Series([r'/NODE'])
node_rad = pd.concat([header, node])
# 出力
node_rad.to_csv(output_path, index=False, header=False, encoding='utf-8')
return None
def convert_solid_t4_and_brick(input_df: pd.DataFrame,
idx_df: pd.DataFrame,
output_path: str = 'solid_t4_brick.inc') -> None:
"""
LS-PrePostのKeyWord出力の*ELEMENT_SOLID部分をRadioss形式に変換して出力する\n
n4~n8がすべて等しい場合: TETRA4として出力\n
それ以外の場合: BRICKとして出力\n
"""
# 開始行と終了行
idx_start = idx_df['idx'].values[0] + 2
idx_end = idx_df['idx_shift'].values[0]
# データフレームを分割
df = input_df.copy()
df = df.iloc[idx_start:idx_end].reset_index(drop=True)
# 文字列を分割
colnames = ['eid', 'pid', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8']
df = split_raw_data(df, 'raw_data', len(colnames))
df.columns = colnames
# 'pid'を除く列を指定数の半角スペースで埋める
for col in df.columns:
if col != 'pid':
df[col] = df[col].str.rjust(10, ' ')
# Part_IDごとにdfを分割して処理
solids = []
for pid, df_pid in df.groupby('pid'):
# n4~n8が全て等しい要素をTETRA4として抽出
is_t4 = ((df_pid['n4'] == df_pid['n5']) & (df_pid['n4'] == df_pid['n6'])
& (df_pid['n4'] == df_pid['n7']) & (df_pid['n4'] == df_pid['n8']))
df_pid_t4 = df_pid[is_t4]
# TETRA4以外をBRICKとして抽出
is_brick = ~is_t4
df_pid_brick = df_pid[is_brick]
# 抽出漏れがある場合はエラー
assert len(df_pid) == len(df_pid_t4) + len(df_pid_brick)
# 各列の結合およびヘッダ行の追記
solid_t4 = df_pid_t4['eid'] + df_pid_t4['n1'] + df_pid_t4['n2'] + df_pid_t4['n3'] + df_pid_t4['n4']
solid_brick = df_pid_brick['eid'] + df_pid_brick['n1'] + df_pid_brick['n2'] + df_pid_brick['n3'] \
+ df_pid_brick['n4'] + df_pid_brick['n5'] + df_pid_brick['n6'] + df_pid_brick['n7'] + df_pid_brick['n8']
header_t4 = pd.Series([rf'/TETRA4/{pid}'])
header_brick = pd.Series([rf'/BRICK/{pid}'])
if df_pid_t4.empty:
solid_pid = pd.concat([header_brick, solid_brick])
elif df_pid_brick.empty:
solid_pid = pd.concat([header_t4, solid_t4])
else:
solid_pid = pd.concat([header_brick, solid_brick, header_t4, solid_t4])
solids.append(solid_pid)
# 出力
solid_rad = pd.concat(solids)
solid_rad.to_csv(output_path, index=False, header=False, encoding='utf-8')
return None
def convert_solid_t10(input_df: pd.DataFrame,
idx_df: pd.DataFrame,
output_path: str = 'solid_t10.inc') -> None:
"""
LS-PrePostのKeyWord出力の*ELEMENT_SOLID (ten nodes format)部分をRadioss形式に変換して出力する\n
"""
# 開始行と終了行
idx_start = idx_df['idx'].values[0] + 2
idx_end = idx_df['idx_shift'].values[0]
# データフレームを分割
df = input_df.copy()
df = df.iloc[idx_start:idx_end].reset_index(drop=True)
# *ELEMENT_SOLID (ten nodes format)の先頭エレメントのコメント行を削除
df = df.drop(index=df.index[[1]]).reset_index(drop=True)
# 0,2,4...行目:eid, pid 1,3,5...行目:nid1~10をそれぞれ列に分割して結合
df_eid_pid = df.iloc[::2].reset_index(drop=True)
df_nid = df.iloc[1::2].reset_index(drop=True)
assert len(df_eid_pid) == len(df_nid)
df_eid_pid = split_raw_data(df_eid_pid, 'raw_data', 2)
df_nid = split_raw_data(df_nid, 'raw_data', 10)
df_eid_pid_nid = pd.merge(df_eid_pid, df_nid, left_index=True, right_index=True, how='inner')
df_eid_pid_nid.columns = ['eid', 'pid', 'n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10']
# 'pid'を除く列を指定数の半角スペースで埋める
for col in df_eid_pid_nid.columns:
if col != 'pid':
df_eid_pid_nid[col] = df_eid_pid_nid[col].str.rjust(10, ' ')
# Part_IDごとにdfを分割して処理
solids = []
for pid, df_pid in df_eid_pid_nid.groupby('pid'):
# 各列の結合
solid_t10_eid = df_pid['eid']
solid_t10_nid = df_pid['n1'] + df_pid['n2'] + df_pid['n3'] + df_pid['n4'] + df_pid['n5'] \
+ df_pid['n6'] + df_pid['n7'] + df_pid['n8'] + df_pid['n9'] + df_pid['n10']
# eid列は0,2,4,...行目にn1~n10列は1,3,5,...行目に格納したデータフレームを作成
solid_t10_eid.index = solid_t10_eid.index * 2
solid_t10_nid.index = solid_t10_nid.index * 2 + 1
solid_t10 = pd.concat([solid_t10_eid, solid_t10_nid]).sort_index()
# ヘッダ行の追記
header_t10 = pd.Series([rf'/TETRA10/{pid}'])
solid_pid = pd.concat([header_t10, solid_t10])
solids.append(solid_pid)
# 出力
solid_t10_rad = pd.concat(solids)
solid_t10_rad.to_csv(output_path, index=False, header=False, encoding='utf-8')
return None
def convert_shell(input_df: pd.DataFrame,
idx_df: pd.DataFrame,
output_path: str = 'shell.inc') -> None:
"""
LS-PrePostのKeyWord出力の*ELEMENT_SHELL部分をRadioss形式に変換して出力する\n
Part_IDごとに4点要素(SHELL)と3点要素(SH3N)を分けて出力する
"""
# 開始行と終了行
idx_start = idx_df['idx'].values[0] + 2
idx_end = idx_df['idx_shift'].values[0]
# データフレームを分割
df = input_df.copy()
df = df.iloc[idx_start:idx_end].reset_index(drop=True)
# 文字列を分割
colnames = ['eid', 'pid', 'n1', 'n2', 'n3', 'n4']
df = split_raw_data(df, 'raw_data', len(colnames))
df.columns = colnames
# 'pid'を除く列を指定数の半角スペースで埋める
for col in df.columns:
if col != 'pid':
df[col] = df[col].str.rjust(10, ' ')
# Part_IDごとにdfを分割して処理
shells = []
for pid, df_pid in df.groupby('pid'):
# 各Part_IDごとに4点要素と3点要素に分割
df_pid_s4 = df_pid[(df_pid['n3'] != df_pid['n4'])]
df_pid_s3 = df_pid[(df_pid['n3'] == df_pid['n4'])]
# 抽出漏れがある場合はエラー
assert len(df_pid_s4) + len(df_pid_s3) == len(df_pid)
# 各列の結合およびヘッダ行の追記
shell_s4 = df_pid_s4['eid'] + df_pid_s4['n1'] + df_pid_s4['n2'] + df_pid_s4['n3'] + df_pid_s4['n4']
shell_s3 = df_pid_s3['eid'] + df_pid_s3['n1'] + df_pid_s3['n2'] + df_pid_s3['n3']
header_s4 = pd.Series([rf'/SHELL/{pid}'])
header_s3 = pd.Series([rf'/SH3N/{pid}'])
if df_pid_s3.empty:
shell_pid = pd.concat([header_s4, shell_s4])
elif df_pid_s4.empty:
shell_pid = pd.concat([header_s3, shell_s3])
else:
shell_pid = pd.concat([header_s4, shell_s4, header_s3, shell_s3])
shells.append(shell_pid)
# 出力
shell_rad = pd.concat(shells)
shell_rad.to_csv(output_path, index=False, header=False, encoding='utf-8')
return None
def convert_setnode(input_df: pd.DataFrame,
idx_df: pd.DataFrame,
output_path: str = 'setnode.inc') -> None:
"""
LS-PrePostのKeyWord出力の*SET_NODE部分をRadioss形式に変換して出力する\n
/GRNOD/NODE/(1,2,...)で区切って出力する
"""
# 複数あるSETNODEの開始行と終了行の組
idx_setnode_start_and_end = idx_df[['idx', 'idx_shift']].values
# 各SETNODEのdfのリスト
df = input_df.copy()
dfs = [df.iloc[idx_start + 4:idx_end].reset_index(drop=True)
for idx_start, idx_end in idx_setnode_start_and_end]
# 各SETNODEのdfごとにソート処理
setnodes = []
for i, df_sid in enumerate(dfs):
# 文字列を分割
colnames = ['n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8']
df_sid = split_raw_data(df_sid, 'raw_data', len(colnames))
df_sid.columns = colnames
# 空白で埋めて10列にreshape
flat = df_sid.values.flatten()
flat_delzero = flat[flat != '0']
fill_n = math.ceil(flat_delzero.shape[0] / 10) * 10 - flat_delzero.shape[0]
flat_filled = np.append(flat_delzero, [''] * fill_n)
reshaped_df = pd.DataFrame(flat_filled.reshape(-1, 10))
reshaped_df.columns = ['n1', 'n2', 'n3', 'n4', 'n5', 'n6', 'n7', 'n8', 'n9', 'n10']
# 指定数の半角スペースで埋める
for col in reshaped_df.columns:
reshaped_df[col] = reshaped_df[col].str.rjust(10, ' ')
# 各列の結合およびヘッダ行の追記
setnode = reshaped_df['n1'] + reshaped_df['n2'] + reshaped_df['n3'] + reshaped_df['n4'] \
+ reshaped_df['n5'] + reshaped_df['n6'] + reshaped_df['n7'] + reshaped_df['n8'] \
+ reshaped_df['n9'] + reshaped_df['n10']
header_setn = pd.Series([rf'/GRNOD/NODE/{i + 1}'])
setnode_i = pd.concat([header_setn, setnode])
setnodes.append(setnode_i)
# 出力
setnode_rad = pd.concat(setnodes)
setnode_rad.to_csv(output_path, index=False, header=False, encoding='utf-8')
return None
def append_log(log: ft.ListView,
txt: str) -> None:
"""
画面上のlog表示とログフォルダ内のログファイルにログを追記する
"""
logging.info(txt)
log.controls.append(ft.Text(txt))
log.update()
return None
def main(page: ft.Page):
"""
main
"""
# page基本設定
page.title = f'LSPrePost Keyword file Converter - Version {VERSION}'
page.window.width = 1024
page.window.height = 320
# Select fileボタンクリック
def pick_files_result(e: ft.FilePickerResultEvent):
selected_files.value = (e.files[0].path if e.files else "Cancelled!")
selected_files.update()
# Convertボタンクリック
def convert_all(_):
try:
# ファイルが存在しない場合はエラー
is_exist = Path(selected_files.value).exists() if selected_files.value is not None else False
if not is_exist:
append_log(log, f'File not found: {selected_files.value}')
append_log(log, 'Please select a file')
return None
# ファイルの読み込み
append_log(log, 'Conversion Start')
df, idxs = get_df_and_idx(selected_files.value)
outdir = Path(selected_files.value).parent
# *NODEの変換
if not idxs['idx_node'].empty:
convert_node(df,
idxs['idx_node'],
outdir / 'node.inc')
append_log(log, '*NODE conversion finish')
else:
append_log(log, '*NODE not found')
# *ELEMENT_SOLIDの変換
if not idxs['idx_solid_t4_and_brick'].empty:
convert_solid_t4_and_brick(df,
idxs['idx_solid_t4_and_brick'],
outdir / 'solid_t4_brick.inc')
append_log(log, '*ELEMENT_SOLID conversion finish')
else:
append_log(log, '*ELEMENT_SOLID not found')
# *ELEMENT_SOLID (ten nodes format)の変換
if not idxs['idx_solid_t10'].empty:
convert_solid_t10(df,
idxs['idx_solid_t10'],
outdir / 'solid_t10.inc')
append_log(log, '*ELEMENT_SOLID (ten nodes format) conversion finish')
else:
append_log(log, '*ELEMENT_SOLID (ten nodes format) not found')
# *ELEMENT_SHELLの変換
if not idxs['idx_shell'].empty:
convert_shell(df,
idxs['idx_shell'],
outdir / 'shell.inc')
append_log(log, '*ELEMENT_SHELL conversion finish')
else:
append_log(log, '*ELEMENT_SHELL not found')
# *SET_NODE_LISTの変換
if not idxs['idx_setnode'].empty:
convert_setnode(df,
idxs['idx_setnode'],
outdir / 'setnode.inc')
append_log(log, '*SET_NODE_LIST conversion finish')
else:
append_log(log, '*SET_NODE_LIST not found')
append_log(log, 'Conversion ALL Finish')
return None
except Exception:
append_log(log, f'{traceback.format_exc()}')
return None
pick_files_dialog = ft.FilePicker(on_result=pick_files_result)
selected_files = ft.Text()
log = ft.ListView(expand=1, spacing=1, padding=10, auto_scroll=True)
page.overlay.extend([pick_files_dialog])
page.add(
ft.Row(
[
ft.ElevatedButton(
"Select file",
icon=ft.icons.UPLOAD_FILE,
on_click=lambda _: pick_files_dialog.pick_files(allow_multiple=False),
),
selected_files,
]),
ft.Row(
[
ft.ElevatedButton(
"Convert",
icon=ft.icons.NEXT_PLAN,
on_click=convert_all,
),
]),
log
)
return None
if __name__ == "__main__":
# ログ出力設定
exec_filepath = Path(os.path.abspath(__file__))
exec_dir = exec_filepath.parent
log_dir = exec_dir / 'log'
log_filepath = log_dir / 'log.log'
os.makedirs(log_dir, exist_ok=True)
logging.basicConfig(
filename=str(log_filepath),
level=logging.INFO,
format='%(asctime)s: %(levelname)s %(message)s'
)
ft.app(target=main)