Pythonのsalabimで工場シミュレーション - 後編

Pythonの離散事象シミュレーション用のライブラリ「salabim」を用いて簡単な工場のシミュレーションを行ってみました。
前編: 工場シミュレータの作成と計画生産シミュレーション
⇒後編: 強化学習エージェントを組み合わせた自動生産指示にトライ
#python #salabim #離散事象シミュレーション #simpy
概要
後編では前編で作成した工場シミュレーションに手を加えて、強化学習エージェントと組み合わせて動かすことにトライします。
今回はsalabimのアニメーション機能は使用しません。
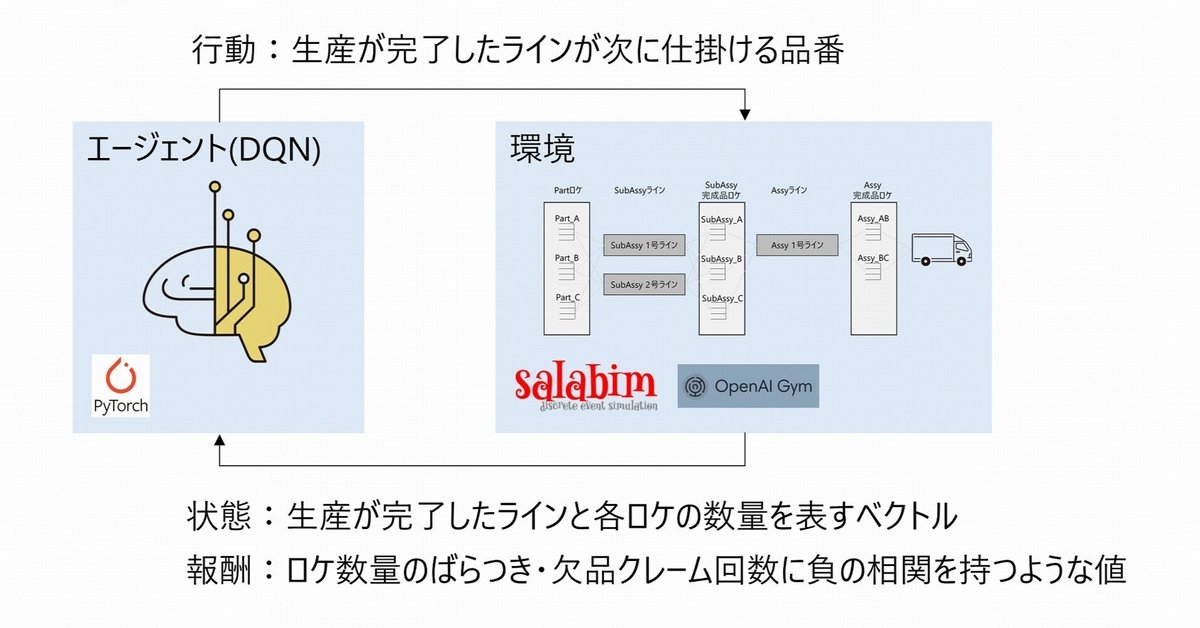
下記に今回動かすものの簡単な概要図を記します。

Subassy, Assyロケ数量の品番ごとのばらつきを少なく、かつ欠品を発生させないような各ラインへの生産指示を得ることが目的です。
環境の設定は基本的にほぼ前編と同じ(※)ですが顧客が持ち出す品番に偏りを設け、ASSY_AB:ASSY_ACを70%:30%の確率で持ち出すようにしました。
これによりただ単にランダムに仕掛けるだけでは絶対にASSY_AB(や、その部材であるSUB_A, SUB_B)が枯渇してしまうため、うまく学習できないと欠品クレームの嵐で報酬値が低くなってしまうようになっています。
(※計画の使用なし、SUB_Aのロケ初期値を10⇒50、顧客の持ち出し個数を10⇒5に変更)
なお強化学習については下記書籍(ゼロつく④)を一通り読んだ程度の初学者のため、深い解説等は行えないです。(´·ω·`)
今回の強化学習の部分の実装はこのゼロつく④の第8章の内容を踏襲して作成しました。
Gym形式に修正する部分についてはこちらのarXivの論文と実装例を参考にしました。
論文は通報から救急車到着までの時間を最短にするためには、どのように救急車を配置しておくのが良いか?という問題に対してシミュレーション環境を自作し強化学習を用いて最適化する内容で大変面白かったです。
使用したライブラリのバージョン
ちょっと古いですがご容赦下さい。
gymはopenAIによる開発は終了しており、24年7月現在はgymnasiumとして開発が続けられているようです。
stepの返り値の数が違うなど、いくつか破壊的変更があるようなのでgym(gymnasium)のバージョンにはご注意下さい。
salabim(yield) 23.2.0
pytorch 1.11.1
gym 0.26.2
前編で作成したシミュレータをGym形式に修正
概要で説明した論文の実装例を参考に、前編で作成したシミュレータをGym形式に修正していきます。使用するgym(gymnasium)のバージョンによりメソッドの定義ルールなどが異なる可能性があるので注意して下さい。
仕掛指示~生産完了ラインが発生するまでを1stepとしています。
# gym環境
class Env(gym.Env):
def __init__(self) -> None:
super().__init__()
self.env = sim.Environment(trace=TRACE)
self.env.animate(ANIME)
self.env.order_waiting_lines = []
self.env.claim_count = 0
self.step_count = 0
self.sim_duration = SIM_DURATION
self.action_space = gym.spaces.Discrete(ACTION_SIZE)
self.observation_space = gym.spaces.Box(low=0, high=float("inf"), shape=(STATE_SIZE,), dtype=np.float32)
self.reward_range = (-float("inf"), 0)
# 各種マスタの取得
self.part_mdf = pd.read_csv(MASTER_DIR / "part_master.csv")
self.subassy_mdf = pd.read_csv(MASTER_DIR / "subassy_master.csv")
self.assy_mdf = pd.read_csv(MASTER_DIR / "assy_master.csv")
# ライン名は[sub_1, sub_2,..., assy_1, assy_2,...]の順に記載のこと
self.linenames = ["line_sub_1", "line_sub_2", "line_assy_1"]
# ロケ生成
self.partlocas = generate_locas(self.part_mdf)
self.sublocas = generate_locas(self.subassy_mdf)
self.assylocas = generate_locas(self.assy_mdf)
# ライン生成
self.line_sub_1 = product_line(linename=self.linenames[0], mdf=self.subassy_mdf,
linecapacity=30, lt=100,
lotsize=10, initpn="SUB_A", prodpn=None, initqty=10,
partlocas=self.partlocas, locas=self.sublocas)
self.line_sub_2 = product_line(linename=self.linenames[1], mdf=self.subassy_mdf,
linecapacity=30, lt=100,
lotsize=10, initpn="SUB_B", prodpn=None, initqty=10,
partlocas=self.partlocas, locas=self.sublocas)
self.line_assy_1 = product_line(linename=self.linenames[2], mdf=self.assy_mdf,
linecapacity=30, lt=100,
lotsize=5, initpn="ASSY_AB", prodpn=None, initqty=5,
partlocas=self.sublocas, locas=self.assylocas)
# 顧客生成(ASSY_ABを70%, ASSY_ACを30%の確率で持ち出す)
self.customer_0 = customer(locas=self.assylocas, mdf=self.assy_mdf,
interval=50, buyqty=5,
chpn_list=[0, 1], chwt_list=[0.7, 0.3])
def _get_state(self):
# 指示するライン, subassyロケ数量, assyロケの数量をつなげたリスト
state = []
# 指示するラインのonehot
line_onehot = np.identity(ALL_LINE_N)[self.linenames.index(self.env.order_waiting_lines[0]._name)]
state.extend(line_onehot.tolist())
# subassyロケの数量(0~1)
for pn in self.subassy_mdf.sort_index()["pn"].values:
state.append(self.sublocas[pn].available_quantity() / self.sublocas[pn].capacity())
# assyロケの数量(0~1)
for pn in self.assy_mdf.sort_index()["pn"].values:
state.append(self.assylocas[pn].available_quantity() / self.assylocas[pn].capacity())
return state
def _get_reward(self, state):
# 各ロケの数量の標準偏差*(-1)の和を報酬とする
reward = (-1) * (np.std(state[ALL_LINE_N:(STATE_SIZE - ASSY_N)]) + np.std(state[(STATE_SIZE - ASSY_N):]))
# 欠品クレーム回数*(-1)を報酬に加える
reward += (-1) * self.env.claim_count
self.env.claim_count = 0
return reward
def close(self):
del self.partlocas, self.sublocas, self.assylocas
del self.line_sub_1, self.line_sub_2, self.line_assy_1
del self.customer_0
del self.env
return None
def render(self):
return None
def reset(self):
self.close()
self.__init__()
random.seed()
# どこかのラインで生産指示が必要となるまで初期生産品番のまま生産させ続ける
while len(self.env.order_waiting_lines) == 0:
self.env.run(till=self.env.now() + 1)
init_state = self._get_state()
return init_state
def step(self, action):
self.step_count += 1
# 生産指示待ちラインを一つ取り出す
order_line: product_line = self.env.order_waiting_lines.pop(0)
# actionを品番に変換
prodpn = order_line.mdf["pn"][action]
# 生産指示待ちラインの生産品番をactionに書き換えてactivateしておく
order_line.set_assypn_and_qty(prodpn)
order_line.activate()
while len(self.env.order_waiting_lines) == 0:
self.env.run(till=self.env.now() + 1)
# 状態・報酬・終了フラグ・info(今回は使用しないのでダミーデータ)の取得
state = self._get_state()
reward = self._get_reward(state)
terminal = True if self.step_count >= self.sim_duration else False
info = {'dummy': 'dummyinfo'}
return (state, reward, terminal, info)強化学習エージェント部分の実装
この部分は概要の項で説明した通り、ゼロから作るディープラーニング④の第8章の実装例を踏襲して作成しました。ノーマルなDQNを使用しています。
最近だとstablebaseline3などのライブラリを活用するのが主流だと思いますが、せっかく本で勉強した内容を何かに使ってみたいという思いからこのようにしてみました。 (なおstablebaselineは試していませんがpfrlではちゃんと学習できました。)
class ReplayBuffer:
def __init__(self, buffer_size, batch_size):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
return len(self.buffer)
def get_batch(self):
data = random.sample(self.buffer, self.batch_size)
state = torch.tensor(np.stack([x[0] for x in data]))
action = torch.tensor(np.array([x[1] for x in data]).astype(np.int64))
reward = torch.tensor(np.array([x[2] for x in data]).astype(np.float32))
next_state = torch.tensor(np.stack([x[3] for x in data]))
done = torch.tensor(np.array([x[4] for x in data]).astype(np.int64))
return state, action, reward, next_state, done
class QNet(torch.nn.Module):
def __init__(self, state_size, action_size):
super().__init__()
self.l1 = torch.nn.Linear(state_size, DQNLAYER_DIM)
self.l2 = torch.nn.Linear(DQNLAYER_DIM, DQNLAYER_DIM * 2)
self.l3 = torch.nn.Linear(DQNLAYER_DIM * 2, DQNLAYER_DIM)
self.l4 = torch.nn.Linear(DQNLAYER_DIM, action_size)
def forward(self, x):
x = x.to(torch.float32)
x = torch.nn.functional.relu(self.l1(x))
x = torch.nn.functional.relu(self.l2(x))
x = torch.nn.functional.relu(self.l3(x))
x = self.l4(x)
return x
class DQNAgent:
def __init__(self):
self.gamma = 0.9
self.lr = 0.001
self.epsilon = 0.1
self.buffer_size = 10000
self.batch_size = 32
self.action_size = ACTION_SIZE
self.state_size = STATE_SIZE
self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size)
self.qnet = QNet(self.state_size, self.action_size)
self.qnet_target = QNet(self.state_size, self.action_size)
self.optimizer = torch.optim.Adam(self.qnet.parameters(), lr=self.lr)
def get_action(self, state):
# ラインの最大品番数をaction_sizeに指定
if np.argmax(state[0:ALL_LINE_N]) < SUB_LINE_N:
action_size = SUB_N
elif np.argmax(state[0:ALL_LINE_N]) < ALL_LINE_N:
action_size = ASSY_N
if len(self.replay_buffer) < self.batch_size:
return random.randint(0, action_size - 1)
if random.random() < self.epsilon:
return random.randint(0, action_size - 1)
else:
state = torch.from_numpy(np.array(state))
qs = self.qnet(state)
# 存在しない品番Noは選択させないようにする
qs = qs[0:action_size]
return qs.argmax().item()
def update(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
if len(self.replay_buffer) < self.batch_size:
return None
state, action, reward, next_state, done = self.replay_buffer.get_batch()
qs = self.qnet(state)
idx = torch.from_numpy(np.arange(len(action)).astype(np.int64))
q = qs[idx, action]
next_qs = self.qnet_target(next_state)
next_q = next_qs.max(1)[0]
next_q.detach()
target = reward + (1 - done) * self.gamma * next_q
loss_fn = torch.nn.MSELoss()
loss = loss_fn(q, target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def sync_qnet(self):
self.qnet_target.load_state_dict(self.qnet.state_dict())
学習
私のGTX1650Tiが載ってるノートPCで3分くらいかかりました。
(DQNLAYER_DIM = 32, SIM_DURATION = 80, EPISODES = 100)
各エピソード毎の報酬和の推移です。
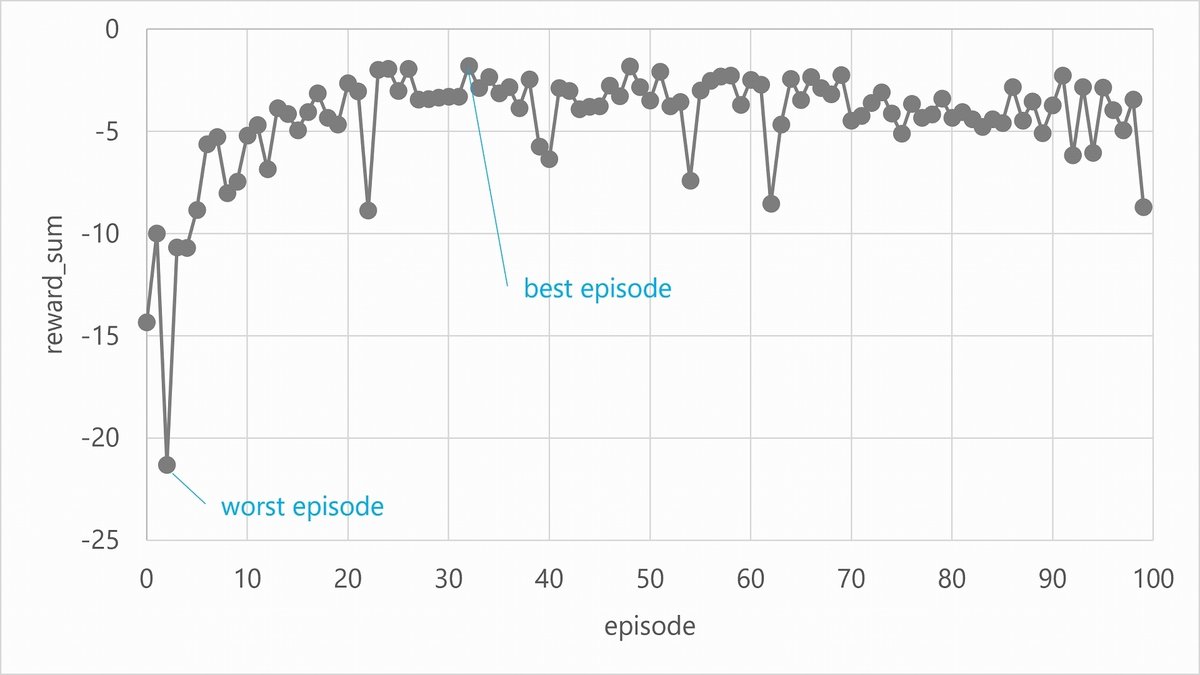
とりあえずちゃんと(?)学習が進むと報酬が向上している様子が確認できました。
ちょっとチェリーピッキングになってしまうかもしれませんがbest/worst episodeでのロケの数量の推移を次項にて確認してみます。
結果の確認
worst episodeでの各ロケの数量および報酬値の推移は下記の通りです。
(ロケ数量の単位は台数に直してあります)


worst episodeではSubassyラインではSUB_Aを過剰に生産しすぎてしまっており、SUB_Cが枯渇してしまっています。
また、AssyラインではASSY_ABの生産が足りず枯渇しており、後半は欠品クレームによるマイナス報酬を受けていることが読み取れます。
対して、best episodeでの各ロケの数量および報酬値の推移です。
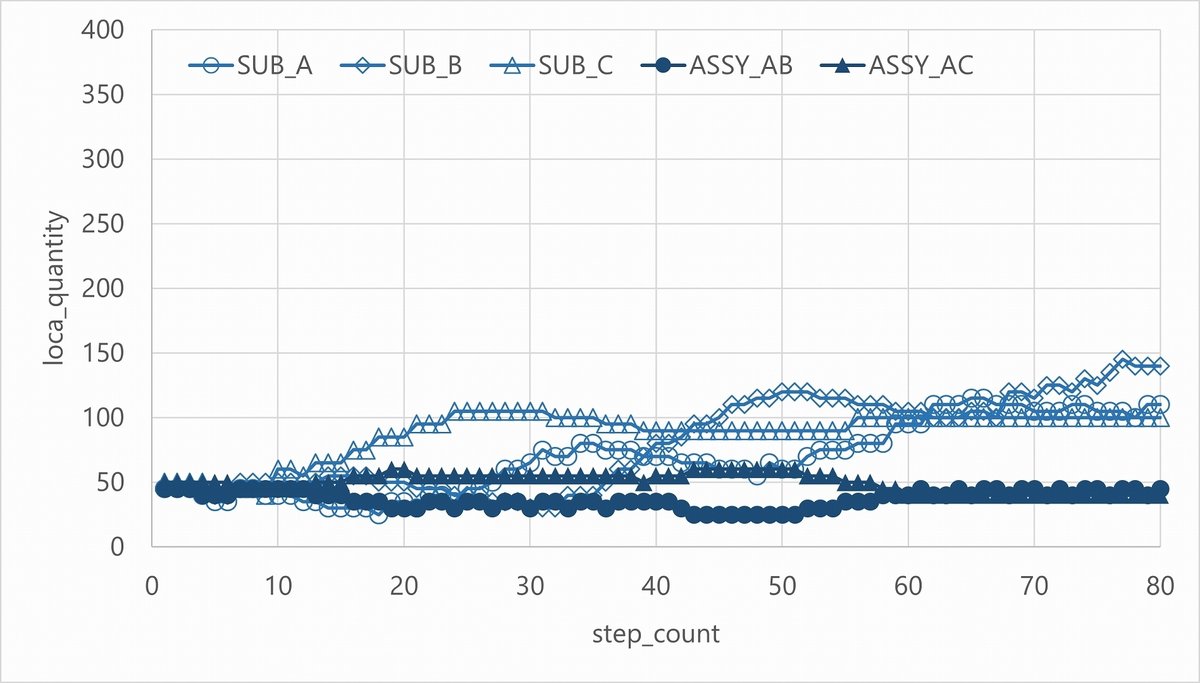

best episodeではSubassy,Assyともにバランスよく生産できています。欠品も出していないようです。
感想
むずかしかったです(白目)
ハードコーディングが多く不格好なコードになってしまったのが残念ですがとりあえずやりたかったことはできたので満足です。
とはいえまだまだ全然理解不足なので今後も継続して学習していきたいと思います。
参考資料
コード全体
import salabim as sim
import pandas as pd
import random
import numpy as np
import gym
import torch
import datetime
import os
from pathlib import Path
from tqdm import tqdm
from collections import deque
sim.yieldless(False)
# GPU動作チェック
print(torch.cuda.is_available())
print(torch.cuda.get_device_name())
print(torch.cuda.get_device_properties("cuda"))
class ReplayBuffer:
def __init__(self, buffer_size, batch_size):
self.buffer = deque(maxlen=buffer_size)
self.batch_size = batch_size
def add(self, state, action, reward, next_state, done):
data = (state, action, reward, next_state, done)
self.buffer.append(data)
def __len__(self):
return len(self.buffer)
def get_batch(self):
data = random.sample(self.buffer, self.batch_size)
state = torch.tensor(np.stack([x[0] for x in data]))
action = torch.tensor(np.array([x[1] for x in data]).astype(np.int64))
reward = torch.tensor(np.array([x[2] for x in data]).astype(np.float32))
next_state = torch.tensor(np.stack([x[3] for x in data]))
done = torch.tensor(np.array([x[4] for x in data]).astype(np.int64))
return state, action, reward, next_state, done
class QNet(torch.nn.Module):
def __init__(self, state_size, action_size):
super().__init__()
self.l1 = torch.nn.Linear(state_size, DQNLAYER_DIM)
self.l2 = torch.nn.Linear(DQNLAYER_DIM, DQNLAYER_DIM * 2)
self.l3 = torch.nn.Linear(DQNLAYER_DIM * 2, DQNLAYER_DIM)
self.l4 = torch.nn.Linear(DQNLAYER_DIM, action_size)
def forward(self, x):
x = x.to(torch.float32)
x = torch.nn.functional.relu(self.l1(x))
x = torch.nn.functional.relu(self.l2(x))
x = torch.nn.functional.relu(self.l3(x))
x = self.l4(x)
return x
class DQNAgent:
def __init__(self):
self.gamma = 0.9
self.lr = 0.001
self.epsilon = 0.1
self.buffer_size = 10000
self.batch_size = 32
self.action_size = ACTION_SIZE
self.state_size = STATE_SIZE
self.replay_buffer = ReplayBuffer(self.buffer_size, self.batch_size)
self.qnet = QNet(self.state_size, self.action_size)
self.qnet_target = QNet(self.state_size, self.action_size)
self.optimizer = torch.optim.Adam(self.qnet.parameters(), lr=self.lr)
def get_action(self, state):
# ラインの最大品番数をaction_sizeに指定
if np.argmax(state[0:ALL_LINE_N]) < SUB_LINE_N:
action_size = SUB_N
elif np.argmax(state[0:ALL_LINE_N]) < ALL_LINE_N:
action_size = ASSY_N
if len(self.replay_buffer) < self.batch_size:
return random.randint(0, action_size - 1)
if random.random() < self.epsilon:
return random.randint(0, action_size - 1)
else:
state = torch.from_numpy(np.array(state))
qs = self.qnet(state)
# 存在しない品番Noは選択させないようにする
qs = qs[0:action_size]
return qs.argmax().item()
def update(self, state, action, reward, next_state, done):
self.replay_buffer.add(state, action, reward, next_state, done)
if len(self.replay_buffer) < self.batch_size:
return None
state, action, reward, next_state, done = self.replay_buffer.get_batch()
qs = self.qnet(state)
idx = torch.from_numpy(np.arange(len(action)).astype(np.int64))
q = qs[idx, action]
next_qs = self.qnet_target(next_state)
next_q = next_qs.max(1)[0]
next_q.detach()
target = reward + (1 - done) * self.gamma * next_q
loss_fn = torch.nn.MSELoss()
loss = loss_fn(q, target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def sync_qnet(self):
self.qnet_target.load_state_dict(self.qnet.state_dict())
# ワーク
class work_obj(sim.Component):
def setup(self, lt, pn, color, in_q: sim.Queue, out_st: sim.Resource):
# リードタイムはワーク生成時にラインリードタイムが与えられる
self.lt = lt
self.pn = pn
self.in_q = in_q
self.out_st = out_st
self.color = color
def animation_objects(self, id):
ao0 = sim.AnimateRectangle((-45, -5, 50, 20),
text=self.pn + ": " + self.text(self.env.now() + self.lt),
arg=self,
fillcolor=self.color)
return 45, 30, ao0
def text(self, t):
return f"{t:0.1f}"
def process(self):
self.enter(self.in_q)
yield self.hold(self.lt)
self.leave(self.in_q)
yield self.put((self.out_st, 1))
# 生産ライン
class product_line(sim.Component):
def setup(self, linename, mdf, linecapacity, lt, lotsize, initpn, initqty, prodpn, partlocas, locas):
# ライン名
self._name = linename
# 生産品番マスタdf
self.mdf = mdf
# ラインリードタイム
self.lt = lt
# ラインロットサイズ
self.lotsize = lotsize
# ライン内容量
self.linecapaciy = linecapacity # (> LT / CT)
# 加工中キュー
self.in_q = sim.Queue("in_line", capacity=self.linecapaciy)
# 排出ステーション
self.out_st = sim.Resource("out_st", anonymous=True, capacity=self.linecapaciy, initial_claimed_quantity=self.linecapaciy)
# 部品ロケ
self.partlocas = partlocas
# 完成品ロケ
self.locas = locas
# 初期生産品番
self.initpn = initpn
# 前回生産品番(初期値はinitpn)
self.prepn = initpn
# 現在生産品番
self.prodpn = prodpn
# 現在生産数量(初期値はinitqty)
self.prodqty = initqty
# 生産品番と生産数量の登録(1lot固定の場合はprodqtyをself.lotsizeにする)
def set_assypn_and_qty(self, prodpn):
self.prodpn = prodpn
self.prodqty = self.lotsize
def process(self):
# initpnを生産している状態からスタート
self.prodpn = self.initpn
self.set_mode("operation")
while True:
# 生産するassy品番とその情報一式
pn = self.prodpn
pninfo = self.mdf[self.mdf["pn"] == pn].head(1)
# 生産する品番の部品品番・必要個数と, ct, colorを取得
parts = [(pninfo[f"c{i}_pn"].values[0], pninfo[f"c{i}_num"].values[0])
for i in range(1, 4) if not pd.isnull(pninfo[f"c{i}_pn"].values[0])]
ct = pninfo["ct"].values[0]
color = pninfo["color"].values[0]
# 生産数量を取得
qty = int(self.prodqty)
# 生産数量分の部材を部材ロケから取り出す(足りない場合は待ち続ける)
self.set_mode("wait_for_parts")
for part, num in parts:
yield self.get((self.partlocas[part], int(num) * qty))
self.set_mode("operation")
# 品番が異なる場合は段取り時間待つ
if pn != self.prepn:
self.set_mode("dandori")
yield self.hold(15)
self.set_mode("operation")
# CTごとに1個ずつワークオブジェクトを生成して加工中キューへ入れる
for _ in range(qty):
yield self.hold(ct)
# ワークは生成されてすぐに加工中キューに入りラインlt待って排出STに入る
work_obj(lt=self.lt, pn=pn, color=color, in_q=self.in_q, out_st=self.out_st)
# 全て加工中キューへ入れたら排出ステーションからロケへ渡すプロセスを起動し次の生産指示を取得しにいく
line_to_loca(line=self, num=qty, pn=pn)
# 生産した品番を先回生産品番として保持
self.prepn = pn
# 生産指示待ちリストへ自ラインを追加し次の生産指示があるまで待機
self.env.order_waiting_lines.append(self)
yield self.passivate()
# 生産ラインの排出STから完成品ロケに移すプロセス
class line_to_loca(sim.Component):
def setup(self, line: product_line, num, pn):
self.line = line
self.out_st = line.out_st
self.locas = line.locas
self.num = num
self.pn = pn
def process(self):
# 仕掛けた数が全て排出STに入るまで待つ
yield self.get((self.out_st, self.num))
# どのロケに入れるかを振り分ける
putloca = self.locas[self.pn]
# 全て排出STに入った時点で加工中キューが空なら生産終了扱いにする
if self.line.in_q.length.value == 0:
self.line.set_mode("prod_end")
# 仕掛けた数が全て排出STに入ったらその数を完成ロケに入れる
# 不良率を乗算するなど仕掛け数より完成品を減らす場合はこのタイミングで行う
# 排出STから完成ロケに入るまでの遅延時間も同じくここで設定する
yield self.put((putloca, self.num))
# 完成品ロケから定期的に製品を持ち出すプロセス
class customer(sim.Component):
def setup(self, locas, mdf, interval, buyqty, chpn_list=None, chwt_list=None):
self.locas = locas
self.mdf = mdf
self.interval = interval
self.buyqty = buyqty
self.chpn_list = chpn_list
self.chwt_list = chwt_list
def process(self):
# intervalごとにランダムな品番を1種類buyqty個持ち出す
while True:
yield self.hold(self.interval)
# 重みづけ無しか有りで品番をランダムに選ぶ
if self.chpn_list == None or self.chwt_list == None:
getpn_n = random.randint(0, self.mdf.shape[0] - 1)
getpn = self.mdf["pn"][getpn_n]
else:
getpn_n = random.choices(self.chpn_list, k=1, weights=self.chwt_list)[0]
getpn = self.mdf["pn"][getpn_n]
# 欲しい品番&数量がロケに無い場合は欠品クレームカウントを+1してgetせずに顧客は帰る
if self.locas[getpn].available_quantity.value < self.buyqty:
self.env.claim_count += 1
else:
yield self.get((self.locas[getpn], self.buyqty))
# ロケを生成する処理
def generate_locas(mdf: pd.DataFrame) -> dict:
locas = {
x["pn"]: sim.Resource(name=x["pn"],
anonymous=True,
capacity=x["capacity"],
initial_claimed_quantity=x["init_claimed"])
for _, x in mdf[["pn", "capacity", "init_claimed"]].iterrows()
}
return locas
# gym環境
class Env(gym.Env):
def __init__(self) -> None:
super().__init__()
self.env = sim.Environment(trace=TRACE)
self.env.animate(ANIME)
self.env.order_waiting_lines = []
self.env.claim_count = 0
self.step_count = 0
self.sim_duration = SIM_DURATION
self.action_space = gym.spaces.Discrete(ACTION_SIZE)
self.observation_space = gym.spaces.Box(low=0, high=float("inf"), shape=(STATE_SIZE,), dtype=np.float32)
self.reward_range = (-float("inf"), 0)
# 各種マスタの取得
self.part_mdf = pd.read_csv(MASTER_DIR / "part_master.csv")
self.subassy_mdf = pd.read_csv(MASTER_DIR / "subassy_master.csv")
self.assy_mdf = pd.read_csv(MASTER_DIR / "assy_master.csv")
# ライン名は[sub_1, sub_2,..., assy_1, assy_2,...]の順に記載のこと
self.linenames = ["line_sub_1", "line_sub_2", "line_assy_1"]
# ロケ生成
self.partlocas = generate_locas(self.part_mdf)
self.sublocas = generate_locas(self.subassy_mdf)
self.assylocas = generate_locas(self.assy_mdf)
# ライン生成
self.line_sub_1 = product_line(linename=self.linenames[0], mdf=self.subassy_mdf,
linecapacity=30, lt=100,
lotsize=10, initpn="SUB_A", prodpn=None, initqty=10,
partlocas=self.partlocas, locas=self.sublocas)
self.line_sub_2 = product_line(linename=self.linenames[1], mdf=self.subassy_mdf,
linecapacity=30, lt=100,
lotsize=10, initpn="SUB_B", prodpn=None, initqty=10,
partlocas=self.partlocas, locas=self.sublocas)
self.line_assy_1 = product_line(linename=self.linenames[2], mdf=self.assy_mdf,
linecapacity=30, lt=100,
lotsize=5, initpn="ASSY_AB", prodpn=None, initqty=5,
partlocas=self.sublocas, locas=self.assylocas)
# 顧客生成(ASSY_ABを70%, ASSY_ACを30%の確率で持ち出す)
self.customer_0 = customer(locas=self.assylocas, mdf=self.assy_mdf,
interval=50, buyqty=5,
chpn_list=[0, 1], chwt_list=[0.7, 0.3])
def _get_state(self):
# 指示するライン, subassyロケ数量, assyロケの数量をつなげたリスト
state = []
# 指示するラインのonehot
line_onehot = np.identity(ALL_LINE_N)[self.linenames.index(self.env.order_waiting_lines[0]._name)]
state.extend(line_onehot.tolist())
# subassyロケの数量(0~1)
for pn in self.subassy_mdf.sort_index()["pn"].values:
state.append(self.sublocas[pn].available_quantity() / self.sublocas[pn].capacity())
# assyロケの数量(0~1)
for pn in self.assy_mdf.sort_index()["pn"].values:
state.append(self.assylocas[pn].available_quantity() / self.assylocas[pn].capacity())
return state
def _get_reward(self, state):
# 各ロケの数量の標準偏差*(-1)の和を報酬とする
reward = (-1) * (np.std(state[ALL_LINE_N:(STATE_SIZE - ASSY_N)]) + np.std(state[(STATE_SIZE - ASSY_N):]))
# 欠品クレーム回数*(-1)を報酬に加える
reward += (-1) * self.env.claim_count
self.env.claim_count = 0
return reward
def close(self):
del self.partlocas, self.sublocas, self.assylocas
del self.line_sub_1, self.line_sub_2, self.line_assy_1
del self.customer_0
del self.env
return None
def render(self):
return None
def reset(self):
self.close()
self.__init__()
random.seed()
# どこかのラインで生産指示が必要となるまで初期生産品番のまま生産させ続ける
while len(self.env.order_waiting_lines) == 0:
self.env.run(till=self.env.now() + 1)
init_state = self._get_state()
return init_state
def step(self, action):
self.step_count += 1
# 生産指示待ちラインを一つ取り出す
order_line: product_line = self.env.order_waiting_lines.pop(0)
# actionを品番に変換
prodpn = order_line.mdf["pn"][action]
# 生産指示待ちラインの生産品番をactionに書き換えてactivateしておく
order_line.set_assypn_and_qty(prodpn)
order_line.activate()
while len(self.env.order_waiting_lines) == 0:
self.env.run(till=self.env.now() + 1)
# 状態・報酬・終了フラグ・info(今回は使用しないのでダミーデータ)の取得
state = self._get_state()
reward = self._get_reward(state)
terminal = True if self.step_count >= self.sim_duration else False
info = {'dummy': 'dummyinfo'}
return (state, reward, terminal, info)
def main() -> None:
basic_factory = Env()
agent = DQNAgent()
sync_interval = 5
reward_history = []
all_history = []
for episode in tqdm(range(EPISODES)):
print(f"episode No.: {episode}")
state = basic_factory.reset()
done = False
total_reward = 0
while not done:
action = agent.get_action(state)
next_state, reward, done, info = basic_factory.step(action)
print(basic_factory.env.now(), action, next_state, reward, done, basic_factory.step_count)
all_history.append([episode, basic_factory.env.now(), action, *state, reward, basic_factory.step_count, done])
agent.update(state=state, action=action, reward=reward, next_state=next_state, done=done)
state = next_state
total_reward += reward
if episode % sync_interval == 0:
agent.sync_qnet()
reward_history.append(total_reward)
print(f"episode{episode}: total_reward = {total_reward}, last_state = {state}")
# 結果ログ出力
timestamp = datetime.datetime.now().strftime('%Y%m%d%H%M%S')
outdir = EXE_DIR / timestamp
if not os.path.isdir(outdir):
os.mkdir(outdir)
reward_history = np.array(reward_history)
np.savetxt(outdir / "reward_history.csv", reward_history)
all_history_df = pd.DataFrame(all_history)
all_history_df.columns = ["episode", "time", "action",
*basic_factory.linenames,
*basic_factory.subassy_mdf["pn"].values,
*basic_factory.assy_mdf["pn"].values,
"reward", "step_count", "done"]
all_history_df.to_csv(outdir / "all_history.csv")
return None
if __name__ == "__main__":
TRACE = False
ANIME = False
EXE_DIR = Path(__file__).parent
MASTER_DIR = Path(__file__).parent / "master_rl"
SUB_LINE_N = 2 # Subassyライン数
ASSY_LINE_N = 1 # Assyライン数
ALL_LINE_N = SUB_LINE_N + ASSY_LINE_N # 総ライン数
SUB_N = 3 # Subassy品番数
ASSY_N = 2 # Assy品番数
ACTION_SIZE = max(SUB_N, ASSY_N)
STATE_SIZE = ALL_LINE_N + SUB_N + ASSY_N
DQNLAYER_DIM = 32
SIM_DURATION = 80
EPISODES = 100
main()