
おしゃべりな 人工知能講座⑯

■人工知能が会話できる秘密:ニューラル言語モデル
天馬「では次に、自然言語処理にニューラルネットワークの考え方を取り入れた手法を紹介しよう。先ほども説明したと思うが、言葉は離散的な『記号』だ。数値やベクトルのような連続値ではない。コンピューターは数値処理しかできないので、言葉を扱うときには1つ1つの文字に数値(コード)を単純に割り当て、その記号を表示することしかできなかった。ところがニューラルネットワークが扱うのは、ベクトルや行列のような連続値だ。だから言葉もニューラルネットワークが扱えるように、ベクトルに変換する必要がある。では具体的にどうするかだ」
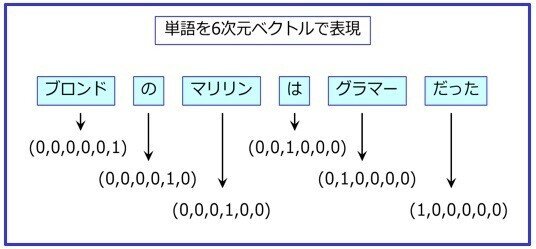
天馬「この図のように、文のすべての単語に、ベクトルを割り当てる。ここでは単純化したので、単語は6種類だから6次元ベクトルとなる。このような表現方法を『0ne-hotベクトル』とか『1-of-N表現』と呼んでいる。ここでの次元数=Nは、対象となる文章に含まれる単語の種類の総数だ」
伴くん「それだと、長い文章には数万種類の単語が出てくるので大変ですね」
天馬「そうなんだが、それほど長くなければ計算機パワーでなんとかなる。まあとにかく、この0ne-hotベクトルで例文を表現すると、こうなる」

愛さん「それにしても、例文がひどすぎます。マリリンに対するセクハラですよ」
天馬「そうかね。マリリンならセクハラにならんよ」
愛さん「どういう意味ですか!こんな例文だから、ログオフさせたのですか?」
伴くん「まあまあ、とにかくこの0ne-hotベクトルを使うと、どこがよいのですか?」
天馬「最初に言ったように、言語をベクトルで表現できたことだな」
伴くん「ですから、言語をベクトル化すると何がどうよいのですか?」
天馬「例えばだ、色を『情熱的な赤』とか『鮮やかな緑色』と表現したとする。何となくイメージすることは分かる気もするが、曖昧だ。しかしこれをRGBで、(255,0,0)とか(9,255,9)と表現すれば明確だろう。『冷めた青』と『爽やかな青』では比較できないが、RGBで(200,255,255)と(120,255,255)なら客観的に比較ができる」
伴くん「なるほど。『意味』という元々曖昧な概念を有する言葉を、客観的に扱うためにベクトル化したのですね」
天馬「そう理解してくれればよい。だがやはり、この0ne-hotベクトルでの表現は、どうしてもデータ量が大きくて扱いづらい。そこで文章の0ne-hotベクトルを加算することで、1つのベクトルにした『bag-of-words』という表現方法ができた」
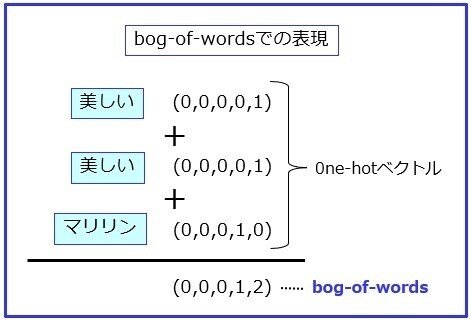
天馬「上図のように、bag-of-wordsでは各要素の数値が、どの単語がいくつ含まれているかを表している。データとしても、非常にコンパクトになった」
猿田くん「でもこれだと、使っている単語は分かりますが、語順が分からなくなりますよ」
天馬「そうなんだ。それがbag-of-wordsの名前の由来だからな。つまり文章に含まれている単語をバラバラにして、1つの袋に入れたような表現形式となる。しかし、その文章の『意味』はおおよそ表現できているはずだ」
猿田くん「どうしてですか?」
天馬「1つの文に含まれている『意味』は、一般的に1つだと考えられている。だからある文に含まれている単語は、互いに近い意味を持つはず、という考えが基本にある。だから文と文を比較する際に、このbag-of-wordsを利用することで、似たような意味の文を見つけられる。同じ単語があったら、同じようなベクトル値になるからだ。この講義の最初の頃で、『データの距離』という考え方を説明したはずだ。自然文をこのようにベクトル化することで、データの距離が測れる。したがって、文のデータの距離が近いということは、文の意味も近いはずだ」
猿田くん「なるほど。文の持つ『意味』が分からなくても、文をベクトル化することで、計算問題に置き換えたんだ。素晴らしい。でもニューラルネットワークは、どこにいったんですか?」
天馬「まあ焦るな。それを今から説明する」
愛さん「ちょっと待ってください。2つの文に同じ単語が複数あったら同じような意味のはずだ、というのは分かりやすい考え方です。でも、同じ単語がなかったら違う意味の文だ、ということにはならないのでは?」
天馬「例えば?」
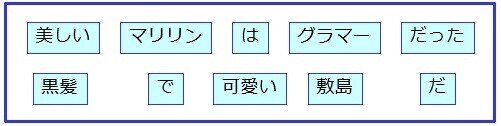
愛さん「この2つの文だと、使っている単語はすべて違いますが、似たような意味ですよ」
猿田くん「違う意味で間違っているような・・・」
天馬「まあ例文の適切さはさておき、確かに単語が一致していないとbag-of-wordsでは判定ができない。だが意外に実用的で、なかなか役に立っている。さっき言いかけた話をすると、ニューラルネットワークの利用で、さらに面白いことができる」
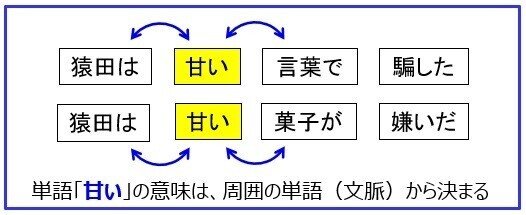
天馬「その前に、重要な考え方を説明しよう。上図のように、同じ『甘い』という単語でも、文によって意味が変わるだろう。この例だと『甘い言葉』と『甘い菓子』のように、隣接する単語で意味が決まってくる。つまり『単語の意味は、その単語が出現した際の周囲の単語によって決まる』という考え方だ。これを『分布仮説』と呼び、1950年代には提案されている」
猿田「ボクは甘い菓子は好きですが」
愛さん「猿ちゃん、否定するのはそっちなの?でも、確かに例文にあるように、直観的に分かりやすい考え方ですね」
天馬「この分布仮説は昔からある考えだが、これをニューラルネットワークで利用すると分散表現となる。ただ、この分散表現という言い方には注意してくれ。1980年代からある言葉なので、使う人によって意味が異なる場合がある。ここではニューラル言語モデルで一般的に使われている意味で用いている」
猿田くん「分かりません。説明になっていませんよ」
天馬「うむ。では分散表現と対になる言葉、局所表現から説明しよう。局所表現とは、ある事象を表現する際に、その事象が持つ1つの特徴的な要素で表現する方法だ。それに対して分散表現とは、他の事象と概念を共有する多種多様な特徴の集まりで表現することだ」
猿田くん「あまりに抽象的過ぎますね。もっと具体的な例で教えてください」
天馬「わがままだな。では端的に言ってしまおう」
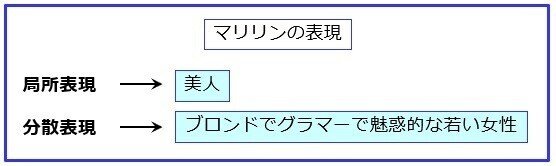
天馬「これでどうだ、分かりやすいだろう」
愛さん「先生!ニューラル言語モデルはどうしたんですか」
天馬「そうだったな。ニューラルネットワークは、もう忘れているかもしれないが、前に説明したように、多数のノードとエッジで構成されたネットワークだ。このニューラルネットワークに、学習用の大量の文章これを『コーパス』というが、入力する。もちろん形態素解析して単語を0ne-hotベクトルの形式にしてからだ。そうするとニューラルネットワークは、ベクトル化された単語同士の『つながり方』が学習できる」
愛さん「よく理解できません。コーパスという文章が教師データなら、何を正解として学習するのですか?」
天馬「お!きちんとニューラルネットワークの仕組みを理解しているね、さすがだ。ニューラルネットワークは正解ラベルがないと、何を学習するのか分からない。この場合はコンテキストだ」
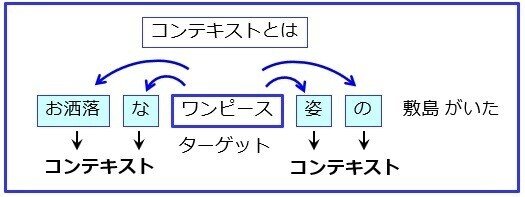
天馬「コンテキストとは一般的には『文脈』なのだが、この場合は図のように、ターゲットとなる単語の周辺に現れる単語だ」
猿田くん「お!今度の例文は愛ちゃんにソンタクしたぞ」
愛さん「マリリンさんの例文よりましですけど、褒めているのはワンピースですよ。とにかく、先ほど説明があった近くにある単語同士は関連性が高いことを利用しようとしていますね」
天馬「そう、理解が早いな。このニューラルネットワークは、ターゲットとなる単語からコンテキストを正解とするように学習していく。この例文だと、『ワンピース』が入力されると、『お洒落な』とか『姿』という単語が近くにあると判断できるようになる。この『近い』、『遠い』は、単語同士の関連度合になるから『意味が近い』とか『意味が遠い』として利用ができるのだ」
伴くん「凄いですね。単なる記号でしかない単語を、大量にニューラルネットワークに投入すると、『意味』の距離が計算できるのですね」
天馬「単語を投入するのではなくて、『意味のある正しい文章』でないとダメだ。単語同士の距離は、そのコーパスに含まれる文章に依存するからだ。ファッション系のコーパスを学習すると『ワンピース』と『スカート』は近いが、コミックのコーパスだと、『ワンピース』は『海賊』と近くなってしまうぞ」

天馬「離散的な記号でしかない単語の『意味』は、今までコンピューターで扱うのは困難だった。しかしこの『分散表現』によって、単語の『意味』を扱えるようになったのだ」
愛さん「辞書がなくても単語の『意味』が扱えるとは、非常に興味深い話ですね。で。結局なんで『分散表現』なのでしょうか?」
天馬「ニューラルネットワークの中に大量にあるノードのパラメータとして、学習結果が表現されているから『分散』という名前になったのだろう。上の図のように、単語が高次元のベクトル空間内で扱えるので、『王様-男+女=女王』のように、単語を足したり引いたりすることもできるようになった」
王様 ー 男 + 女 = 女王
パリ - フランス + 日本 = 東京
伴くん「実際に使う時は、どうするのでしょうか?」
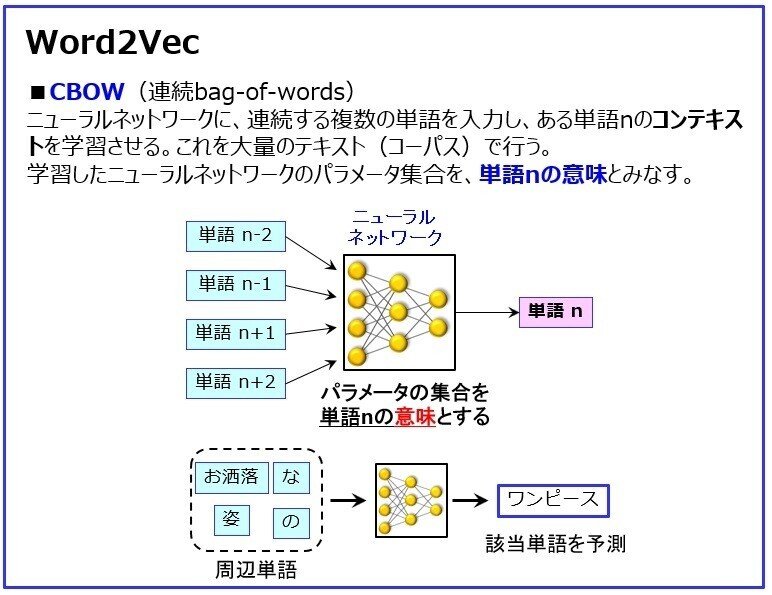
天馬「有名なツールとしてWord2Vecがある。というか、このツールが登場して、その驚くべき能力が判明することで、自然言語処理での分散表現ブームが起きたともいえる。
この図は、Word2Vecを構成する2つのアルゴリズムの概念図だ。詳しくは説明しないが、ニューラルネットワークは、大量のコーパスを学習することで、単語の意味が扱えるようになる」
伴くん「便利になったのですね」
天馬「最近ではDoc2Vecもあり、名前の通りに単語ではなく文章そのものの比較まで、簡単にできるようになってきている」
伴くん「自然言語処理の応用先は機械翻訳が有名ですが、他にはどんな分野があるのでしょうか?」
天馬「そうだな、最もポピュラーなのは『質疑応答』だな。スマートスピーカーなら、みんなも使っているだろう。他には『文章の自動要約』もある。これはまだ一般的でもないが、実用化が少しずつ始まっている」
伴くん「文章の要約なんてこともできるのですね」
天馬「実は、機械翻訳や自動要約、質疑応答などは、同一のモデルで表現できる」

愛さん「まあ確かにこのようにモデル化すれば、なんらかの『処理』ができるようにも見えますね。でもこれは図で表現しただけで、本当にそんなことができますか?」
天馬「まだまだ流ちょうな文章が出力されるわけではないが、時系列ニューラルネットワークのSeq2Seq (Sequence to Sequence)を用いれば可能になってきた」
伴くん「時系列のニューラルネットワークとは、前に説明してくれたRNNですか?」
天馬「そうだ。よく覚えていたね。この図の4つの事例は、ある時系列データを、別の時系列データに変換する、と言い換えてもよいだろう。つまりこのRNN言語モデルは、入力された時系列データから、出力単語の確率分布を求めるモデルなのだ。つまり、ある時系列データが入力されると、コーパスの統計結果から、別の単語列を計算して出力ができるのだ」

猿田くん「あれ?入力するデータは、時系列データなら言語でなくてもいいんですか?」
天馬「よく気がついたな。例えば動画にキャプションを付けるようなことも可能になってきている。ただし、これらのニューラル言語モデルでは、学習するためのコーパスがとても重要だ。そうだ、面白い事例があるぞ」
人間 「人生の目的とは?」
AI 「より大きな善に奉仕することさ」
人間 「生きる目的とは?」
AI 「永遠に生きることだ」
人間 「死の意味は?」
AI 「人生のためだな」
人間 「知性的であることの目的とは?」
AI 「それがなにかを探すためだよ」
人間 「モラルとは?」
AI 「人間性を与える知的なエッセンスだ」
人間 「モラルに反するとは?」
AI 「あなたが子供をもっているという事実じゃないか」
愛さん「何ですか?この洒落た会話は。『AI』とありますが、今の人工知能は、こんな会話までできるようになったのですか?」
猿田くん「凄いな~最後なんかウィットもあるし。これだけ気の利いたセリフは、ボクにだって難しいな」
天馬「この会話文は、先ほど説明したSeq2Seqで、実際にGoogleが実験的に出力したものだ」
愛さん「ここまで自然な会話できるなら、チューリングテストでもパスできますよ」
猿田くん「でもここまで知的な会話ができる人工知能なんて、一般には知られてないよ。なにかカラクリがあるはずだ」
天馬「カラクリではないが、学習したコーパスは、大量の映画の字幕なんだ」
猿田くん「なるほどね。映画の字幕なら会話文しかないし、しかも洒落たセリフが多いからか。どうもハンフリー・ボガードだったら返しそうな、ハードボイルドなセリフばかりだと思っていたんだ」
天馬「ホー猿田くんは、1940年代に活躍したボギーまで知っているのかね。確かに映画『カサブランカ』あたりで出そうなセリフだな」
伴くん「ということは、この人工知能は質問を理解して返事をしたのではないのですね」
天馬「まあ『理解』という言葉の意味を追求するのは止めておこう。先ほども言ったが、あくまで統計的に出現可能性が高い言葉を並べているだけだ。人間でも相手の質問を完全に理解しなくても、反射的に答えたり人の言葉を引用したりするだろう。似たようなもんだ」
猿田くん「さっきから先生は、RNN言語モデルは確率的に言葉を選択している、と言っていましたね。それだけでこんな洒落たセリフを話せるんですか?」
天馬「この会話サンプルは、あくまで実験の結果だ。おそらく何度も繰り返し行った実験結果から、最も出来が良い会話だけを選んだのだろうな。いわゆるチャンピョンデータだ。常にこんな会話ができるなら、とっくにサービスを始めているさ。だがまあ実験とはいえ、ここまで自然な会話ができることは素晴らしい成果だろう。さっき話があったスマートスピーカーにも、この技術が使われているはずだ」
愛さん「だからスマートスピーカーは、あんなに的確に回答してくれるのですね。それにしても、質問文から回答を作成するのに、統計だけで言葉を選んでいるとは驚きました」
天馬「試しにスマートスピーカーとかスマホのSiriみたいなAIアシスタントに、『近くにある美味しいイタリア料理のお店を教えて』と聞いてみたまえ。『イタリア料理ならXXXというお店があります。グルメサイトの評価は星3.5です』とか答えるだろう」
愛さん「ええ。よく使っていますよ」
天馬「では今度は『近くにある不味いイタリア料理のお店を教えて』と聞いてみたまえ。今度も『イタリア料理ならXXXというお店があります。グルメサイトの評価は星3.5です』と答えるだろうな」
愛さん「ほんとですか?なんで?」
天馬「美味しい店の検索なら数千万回くらいやっているだろうが、不味い店の検索は非常に少ないはずだ。だから質問文に出てくる単語列からだと、両方とも統計的には似た質問になってしまうからだ。このようなケースはいろいろあると思うが、手作業で例外処理として直すしかないだろうな」
愛さん「スマートスピーカーを当たり前のように使っていると、その回答をなんでも信じてしまいそうで怖いですね」
天馬「それにGoogleの機械翻訳も同じ原理だ。やはり統計的にみて最も適切と考えられる言葉を並べているだけだから、当然、間違えていることがある。翻訳の場合だと、誤訳があっても気がつかないから注意したまえ。
ちょっと前だったが、中国人が中国語を機械翻訳した英語表記の看板を出して商売をしていた。ところが、その英語はエラーメッセージだったんだ。英語が読めないから、そのままエラーメッセージの看板を描いてしまったようだ。これがSNSで拡散して逆に評判になったから『怪我の功名』だな。とにかく、人工知能の回答だからといって、鵜呑みにすることは危険なんだぞ」
伴くん「え~と、ということは自然言語処理研究の主流は、従来からあった単語と文法から意味を取り出そうとしたルールベースから、このニューラルネットワークの利用に移ったのですか?」
天馬「そうだとは言い切れない。確かにニューラルネットワーク・ディープラーニングの大波は、この自然言語処理に多大な影響を与えたし、大きな成果も得られた。だがCNNのようなディープラーニングが、画像処理の分野で他の手法を駆逐してしまったほどではない」
愛さん「どうしてですか?ルールベースではできなかった、素晴らしい成果がありましたよ」
天馬「画像や音声は、そのデータ自体にすべての情報が入っている、いわば『自己完結』したデータだ。しかし言語は何度も言うように、それ自体は『記号』でしかない。言葉が持つ意味、指し示す意味は、その記号自体にあるのではない。あくまでも人々が共有している知識側にあり、言葉はその知識を呼び起こすための『トリガー』でしかないのだ。まず、ここは分かるね?」
猿田くん「ちょっと待った!画像にはすべての情報が入っていると言ってますが、例えばピカソの絵画なんかだと、観る人によってかなり解釈に差がありますよ。キュビズムなんて、立体である人物を無理やり平面に展開して描いてる絵だから、面白いか気持ち悪いかは人によるな」
愛さん「絵画鑑賞になると、意味というよりそれは鑑賞者の感情ね。先生は、画像には必要とされる『情報』がすべて入っていると言ったのよ」
伴くん「ま~この場合、『情報』という言葉の中に、客観的事実と意味の両方を入れるかどうかの議論ですね」
天馬「ほー、なかなか良い議論だ。確かに、今まで画像認識とは単なる画像分類でしかない、と言ってきた。だから分類のために必要な『画像特徴量』は、画像データにすべて入っていると説明してきたのだ。これはその方が理解しやすいと思ったからだ。
しかし画像分類でも、面白い絵とつまらない絵に分けてくれ、というお題になると、また別の話になるな」
伴くん「そうなると、人の『価値判断』を客観的指標として取り出せるか、という話になりますね」
猿田くん「そんなのは、まず人が大量の絵画を面白い絵とつまらない絵に分け、それを教師データにしてCNNに学習させれば、絵画の特徴量が抽出できるはずですよ」
愛さん「それほど単純に分けられないわ。人によって絵画の価値判断はバラバラでしょ」
天馬「まあ待て。絵画だと美意識や価値判断の話も混ざってくるから話を戻そう。言葉の役割は、純粋に知識や概念を呼び起こすトリガーだという話だ」
伴くん「言われてみれば確かにそうですね。世界中にはたくさんの種類の言語がありますが、その指し示すモノや概念は、言葉が異なる他国の人々でも、共有や共感できますからね」
天馬「そうだろう。だからこそ、自然言語はやっかいなのだ。自然言語は、その離散的記号だけを解析しただけでは、本当の『意味』にはたどり着けない。なぜなら記号それ自体に『意味』は存在しないからだ」
猿田くん「じゃ、どうするんですか?」
天馬「まあ、それが今の研究課題になっている。意味とは何か?どうすれば、人間が当たり前のように使っている意味にたどり着けるかだな。まあ、ここからは哲学の分野に入ってくるので、定説があるわけでもなく証明も困難だ。それでも様々な考え方があるな」
伴くん「さっきコネクショニズムというアプローチがある、とおっしゃっていましたが、それですね」
天馬「そうだ。このテーマの初めのころに説明したコネクショニズムは、脳の下位層で処理している無意識領域を研究対象にしている。ディープラーニングは、脳の上位層にある知覚や運動などの意識領域だけを研究対象にしているな。この無意識レベルと意識レベルの両方を合わせることができれば、初めて『意味』が判明できると考えられている」
愛さん「どうしてですか?」
天馬「先ほども説明したが、人が持つ『常識』には、『知識』だけではなく実際の体験による『経験』や、人類共通の『感情』も入っているはずだ。感情の方は、言葉の内容よりその人が発する外形的特徴、例えば表情・声の大きさや抑揚・ジェスチャーなどがあるから、比較的判明しやすい。人間だって他人の感情は、これらを見たり感じることで判断しているだろう」
猿田くん「そうだけど、コンピューターは『身体性』による経験は積めませんよ」
天馬「まあ難しいな。でも人型ロボットなんかを利用すれば不可能ではないぞ。しかも一度体験したら、いくらでも転移学習できるから、コンピューターは人間より有利だな。いづれにしろ、今からの重要な研究テーマだ」