
インクルーシブな行政サービスのための多言語翻訳AI

コロナウイルス禍によって、外国人訪日者は途絶えた。その減少率は、前年比▲97.7%(12月ベース)という途方もない数字だ。
その一方で、最近、多くの自治体が外国人向けの多言語サービスを強化している。これはどういうトレンドなのか。多言語サービスを支える機械翻訳技術がもたらす意義と限界を明らかにしつつ、今後の多元化社会、そして外国語との向き合い方を考えてみたい。
1.ソーシャルインクルージョンと翻訳AI
コロナウイルス禍によって、昨年度3,000万人を超えた外国人旅行者はほぼ完全に途絶えた(昨年12月の訪日外国人数は前年比▲97.7%*1)。東京五輪を控え、あれほど盛り上がっていたインバウンド需要取り込みへの期待は無残に打ち砕かれ、人々の意識から外国人の存在感は急速に薄れつつある。しかし、日本から外国人がいなくなったわけではない。以前から日本で暮らしていた在留外国人の生活は引き続き地域で息づいている。コロナウイルス禍以降、海外からの新たな流入が途絶え、それまでの増加基調は減少へと転じたものの、2020年6月時点の在留外国人数は依然、288.6万人に及んでおり、過去最高を記録した2019年12月の293.3万人からの減少率は▲1.6%にとどまっている*2。
288.6万人という数は、日本の総人口の2.3%、小学校の学級の1~2クラスに一人は外国人がいる計算になる。自治体窓口での外国人への対応も、減るどころかむしろ増えているという*3。コロナウイルス禍によって行政の支援を必要とする住民の数はむしろ増えているからである。そうした状況を背景としつつ、在留外国人向けに新たな多言語サービスを開始する自治体が相次いでいる。
公式な在留資格を得て、日本社会の一員となっている在留外国人に対し、いかに基本的人権に基づく生活を保障し、地域社会で活躍してもらうかは、コロナウイルス禍を通じて、一層重要な課題となりつつある。そうした外国人が生活していくうえで、言語の壁は大きい。日本に来たのだから日本語を習得し、日本社会に適応すべきとの考え方も一理あるかもしれない。しかし、海外に駐在する日本人の多くが言語の壁に苦しむように、日本に来ている外国人もやはり苦しんでいる。少し古いデータだが、2009年に法務省が行った調査では、在留外国人の72%が日本語の使用や学習に悩みや不満を抱えている。そして、日本語ができない外国人が最も克服したいと考えていることの筆頭に挙げられているのが行政サービスなのである(表1)。
【表1:日本語ができない外国人が最も克服したいと考えていること】

(出典)独立行政法人 国立国語研究所,「生活のための日本語:全国調査」 結果報告,2009,5/20,5.1.2,p.7
https://www2.ninjal.ac.jp/past-projects/nihongo-syllabus/research.html
近年、政府は社会の構成員の多様性を認め、積極的に受け入れていこうとするソーシャルインクルージョン(社会的包摂)を重視するようになっている。自治体の中には、政府が旗を振り始めるより遥かに以前から、このテーマに取り組んでいるところもある。しかし、こうした取組みを進める政府・自治体自身が、業務・サービスの中に言語の壁を放置することによって、インクルージョンの妨げになっているとすれば、看過されるべきではない。そして、そうした課題の解決を可能にする技術、とりわけ機械翻訳の技術は近年、長足の進歩を遂げつあり、行政向けのサービスも次々にリリースされている。本稿では、現在までの技術進歩によって、自治体の多言語対応にどのような新たな選択肢が生まれたのか、そしてその限界は何かを、機械翻訳技術の発展の過程を辿り、現在の製品・サービスが生まれた意義を探りながら明らかにしてゆきたい。そして、これらの技術がもたらす自治体行政への影響を展望することとしたい。
2.機械翻訳の類型と限界
機械翻訳の歴史は、概念としての研究であれば、コンピュータの誕生以前に遡る。その実用化が実践的な研究課題とみなされることとなった契機は、コンピュータと同様、第二次世界大戦にあった。言語間の翻訳技術の開発は、大戦中に発展した暗号解読技術のアナロジーとして始まった。ある言語列を、意味を保持したまま他の言語列に置き換えるという点において、翻訳と暗号解読の間に本質的な差異はないと考えられたからである。そしてその後、AI(人工知能)が技術の進歩と停滞、期待の高まりと幻滅を繰り返しながら徐々に発展してきたように、機械翻訳もその一領域として、同様のサイクルを経て、発展の途を辿ってきた。
機械翻訳は大きく、①ルールベース型機械翻訳、②統計的機械翻訳、③ニューラル機械翻訳の3つの技術の変遷を経て発展してきており、この流れがそのまま機械翻訳の歴史となっている。実際には、ニューラル機械翻訳についても、その基礎となるニューラルネットワークの原型となる理論が登場した時期は、他の技術が登場した時期とそう変わらないのだが、それを現実化できるだけの膨大なデータ量とコンピューティング能力が当時は存在しなかった。今世紀に入ってようやくその条件がみたされ、深層学習(ディープラーニング)の実用化が可能になったことで、ニューラル機械翻訳も急速に発展することになった。
①ルールベース型機械翻訳
さて、その機械翻訳の技術だが、大戦後まもなく、ルールベース型と呼ばれる方式から発展が始まった。これは、あらかじめ人が設定したルールにしたがって語やフレーズの変換を行う方式である。人間が決めたルールどおりに処理するので、意図通りの翻訳結果が得られる。他方で、ルールにないことは変換できない。そして、言語の変換パターンの多様性は人間の想像をはるかに超えるものだった。翻訳対象との対応関係をルールによって規定し尽くすことの困難さが明らかになるにつれ、ルールベース型機械翻訳への期待は失われていった。
ただし、この方式が使われなくなったわけではない。正確な翻訳結果を求められる場面では、現在でもルールベース型機械翻訳は主要な選択肢である。また、②統計的機械翻訳や③ニューラル機械翻訳は、機械学習を行うために膨大なデータを必要とするが、これらに恵まれない希少言語では、ルールベース型は唯一の選択肢であり、ある条件下では今でも実用的である。また、言語間の差異が小さい場合、例えば、方言間での翻訳では、変換に必要なルールは限られてくるので、ルールベース型だけで十分な精度を確保できる場合がある。
②統計的機械翻訳
言語間の変換を統計的な確率計算によって行う方式である。二カ国語の対訳の文章のペアを大量に用意し(このデータ群をコーパスという)、例えば、ある単語と、それに対応して最も高い頻度で出現している単語をもって同じ意味であると計算する。これをさらにフレーズ単位に拡張すれば、フレーズ同士のペアとなる対訳を導出できる。こうした原理を用いることで、すべてのルールを定めなくても、大量の対訳のペアを導出し、変換が可能となる。この方式が、③のニューラル機械翻訳が登場するまでは機械翻訳の研究の主流であり、現在でも特定分野に特化したビジネス用途では実用技術としての位置を維持している。他方で、汎用的な機械翻訳としては、翻訳の精度は実用レベルには達していない。最大の障壁は、文やフレーズ単位で区切って対応関係を分析するものの、前後の文脈は考慮されず、翻訳の精度にはおのずと限界が出てくることである。それ以上に問題なのは言語の曖昧さである。それは多義語だけの問題ではない。ありふれた単語一つとっても明確に対訳となる単語を特定することは難しい。さらに精度を上げるためには、技術的なブレークスルーが必要となるが、そのための大量の良質なコーパスと膨大なコンピューティング能力を投入できるプレーヤーは限られている。そして、そうした力を持つ事業者はすでに軸足を次に示すニューラル機械翻訳に移している。
③ニューラル機械翻訳
翻訳対象の文章の特徴を機械的に抽出し、その特徴から翻訳目的の文章を生成する方式である。カテゴリとしては、大量のデータから確率的に正しい訳文を抽出・生成するという意味では統計的機械翻訳の範疇に含まれるが、結果として出力される翻訳の精度や文章の流暢さは一段レベルが高いものとなる。文章に含まれる単語の特徴、フレーズの特徴、文の特徴と、階層的に特徴を抽象化していくことによって、文章レベルでの特徴を捉える。そして、同じような特徴を持つ構成要素を逆に生成していく。画像認識の深層学習で、(あくまで比喩的な表現だが)目や眉などの個々の部分の特徴から顔の特徴、全体の特徴へと抽象化して特徴を捉えていくのと同様である(注:機械が「目」とは何かを理解しているわけではない)。これらのプロセスはアルゴリズムによって自動的に行われる。人が行うのは主に抽象化の階層といったパラメータの調整である。
形式的な表現ではなく、抽象化された特徴をもとに変換を行うため、文章の表現の揺れに対しても頑健であり、原文と訳文の中の単語同士では一見、対応関係が見出せないにもかかわらず、文章全体としては含意が一致した訳文が生成されることも多い。この技術によって、機械翻訳は初めて実用的な汎用性を手にしたと言える。ニューラル機械翻訳の有効性が明らかになると、GAFAM(Google, Apple, facebook, Amazon, Microsoftをさす)などインターネット経由で機械翻訳サービスを提供している企業は、こぞってこの方式へと乗り換えていった。筆者もある時期にGoogle翻訳の精度が突然向上し、驚いたことがあったが、のちに翻訳手法の切り替えの時期にあたったことが分かった。(図1)
【図1:機械翻訳の発展の流れ】
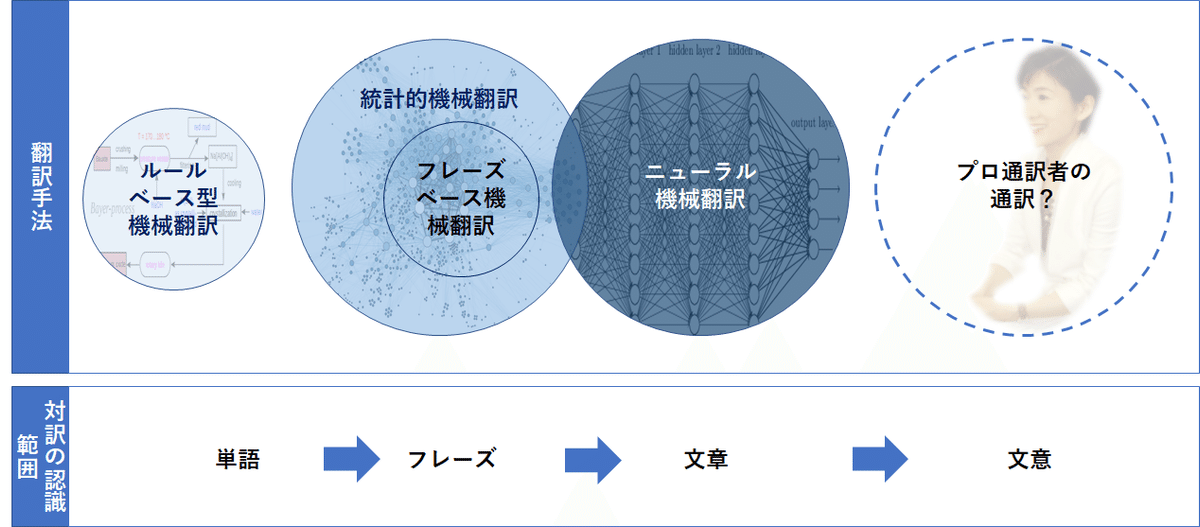
(機械翻訳の限界、向き合い方)
ニューラル機械翻訳の精度は、英語とフランス語など近縁の言語間であって、かつ大量のデータが入手できる場合はかなりのレベルに達している。他方で、こうした言語間の近縁性や十分なデータ量を欠く場合は精度が落ちる。
いかにニューラル機械翻訳といえども、学習していない表現に置き換えることはできないし、文法の違いが大きい英語と日本語では誤訳の確率も高まってくる。特定分野の専門用語を精度高く訳出することも難しい。さらに、ニューラルネットが捉える特徴は人間には読めない数値表現であり、訳語に問題があったとしても、原因の特定も、その修正も、さらにはそれに気づくことすら容易ではない。加えて、精度を向上させるには、全体を再学習させなければならず、膨大な計算を要する。これに対し、統計的機械翻訳であれば、まだしも問題箇所は特定しやすい。
現状では、機械翻訳はプロの翻訳者に置き換えられるものではないし、腕利きの翻訳者への需要は依然大きい。むしろコロナ禍で海外とのオンライン会議が増え、さらに需要が高まる傾向すらある。筆者はGoogle翻訳のヘビーユーザーであり、その訳文の見事さにはしばしば感嘆させられている。通常のプレゼンテーションなどであれば、Google翻訳したものを自らポストエディット(事後的編集)するだけで済ませてしまう。しかし、公式ウェブサイトへの英文掲載や、英文の査読付き学術論文の作成など重要な場面では、躊躇なくプロの翻訳者に依頼する。Google翻訳の普及によって、翻訳や通訳の依頼が減った感覚はなく、かえって英文作成のハードルが下がったために、翻訳を依頼する機会が増えた感さえある。機械翻訳はこうした棲み分けをもたらしつつ、全体として日本人の英語運用能力の底上げに寄与していくのだろう。
さて、機械翻訳技術には大きく以上3つの類型があるわけだが、実際には、機械翻訳サービスを提供する企業は、いずれか一つの手法を選んでいるわけではなく、これらを組み合わせたハイブリッド型でサービスを提供している。どのように組み合わせているのかについて、オープンになっている情報は少ないが、ここで認識しておくべきは、機械翻訳は今のところ上記のような、いずれも限界を抱えた3つの手法の組み合わせでしかなく、それ以上のものではないということである。もともとプロの翻訳者が行うような、対話そのものの意図や背景の理解に基づいて、話者以上に的確に文章を再構成するような技術は期待できるものではない。しかし、そのことをもって機械翻訳の力不足を指摘し、否定するのは非生産的であろう。いかに両者を使い分け、全体としての価値を最大化するかに知恵を絞るべきである(図2)。
【図2:各機械翻訳方式の得意領域】

3.行政サービスにとっての機械翻訳
次に自治体にとっての機械翻訳の意義と現在の活用状況に触れてみたい。
(1)国産の機械翻訳技術
現在、汎用的な機械翻訳の分野は、インターネットの世界を寡占する巨大IT企業が優位を占めている。これらの企業は、インターネットサービスを通じて手にしている膨大なデータ、世界最高レベルの人材、潤沢な資金に基づく膨大な計算リソースを武器に開発を進めており、後発組が同じ土俵でキャッチアップし、戦うことは困難なレベルに達しつつある。
他方で、日本には、日本語の翻訳に特化し、マニュアル作成や法務といった専門分野で独自の地歩を築いている企業がある。これらの企業は長年にわたり、顧客の専門分野への対応を通じてノウハウを蓄積し、ニーズに応じてカスタマイズされた、きめ細かいサービスを提供してきた。こうした領域にGAFAMが個別に進出してくることは今のところ考えにくい。当面はニューラル機械翻訳などの新しい技術要素も取り込みつつ、事業として進展し続けるだろう。
そして、ここ数年、日本語の機械翻訳技術開発における台風の目となってきたのが総務省外郭の研究機関である情報通信研究機構(以下「NICT」)である。NICTは総務省が2014年4月年に打ち出した「グローバルコミュニケーション計画」に基づいて、2020東京五輪を目標に、日本語の多言語対応に特化した機械翻訳技術の開発に取り組んできた。開発に必要なコーパスは「翻訳バンク」として国内から広く提供の協力を求めたほか、行政用途のコーパスについては、委託先企業が数十の自治体を訪問して新たにデータベースを構築するなど、データの収集段階から積極的・主体的な活動を展開してきた。
日本語オリジナルの翻訳システムは、日本語と英語圏以外の言語の翻訳においても独自の強みを生み出すことができる。GAFAMやDeepLなどの外国企業の機械翻訳システムは、日英語間ではかなりの精度が出るが、日本語と他の言語の翻訳については、基本的に英語を介した二次翻訳となっており、一種の伝言ゲームとなるため精度は落ちる。これに対し、日本語と英語以外の言語の直接のコーパスを利用できれば、より精度を高めることができる。
NICTによる研究開発の成果は、Voicetraというアプリとして無償公開され、600万ダウンロードを超える人気サービスとなっているが、その技術は様々な企業に取り入れられ、行政向けサービスも含め、翻訳ビジネスの発展に寄与している(図3)。日本の公的機関の研究成果がここまでの広がりを持つ技術を民間企業に提供できた例は稀であろう。
【図3:NICTの開発技術の民間応用】

(出典)NICTリーフレット「様々なシーンでの「多言語対応」にNICTの音声翻訳技術が拡がっています。」より引用
https://gcp.nict.go.jp/news/flyer_business_GCP.pdf
(2)行政サービスにおける機械翻訳の用途
自治体での機械翻訳利用の歴史はまだ浅く、用途は限られている。潜在的には、あらゆる情報が多言語対応の対象となり得るので、幅広い発展可能性があるのは間違いないが、いま現在、特に実用化が進展しているのは、ウェブサイトや広報誌などの情報発信媒体の翻訳と、窓口での来訪者への対応の支援である。
①情報発信媒体の多言語化
自治体は近年、情報発信媒体の多様化(例えばソーシャルメディア)を推し進めているが、依然として重要視されているのはウェブサイトと広報誌である。
(ウェブサイト)
多くの自治体はウェブサイトにGoogleが提供する機械翻訳ツールを利用している。このサービスは2019年に新規利用は終了してしまったのだが、既に導入済みのサイトでは引き続き利用できる。これは無料である上に、それなりに読めるレベルの翻訳が生成されるので、特に財政余力の乏しい中小規模自治体にとっては貴重な手段となっている。
しかし、Googleが提供するのはあくまで全世界共通の汎用サービスであり、個別自治体の専門用語等に対応するような配慮は基本的にはない。明らかな誤訳がGoogleの評判を貶めるような場合はアルゴリズムを修正することで対応するようだが、個別対応しない、人手での対応をしない、というポリシーを、Googleは、他のサービスと同様、翻訳サービスでも一貫させている。したがって自治体は、自らのウェブサイトの誤訳を修正することもできない。こうした限界を承知の上、ディスクレーマー(免責事項)を示しただけで公開しているのが現状である。行政にとって発信する情報の正確性は重要である。いかにディスクレーマーを明記しているとはいえ、誤訳の恐れがあるような情報が市民にとって本当に価値があるのか、むしろ誤解を招くだけではないか、という批判も成り立つだろう。もともと利用者はその気になれば、Google Chromeなどから右クリックの操作ひとつでページ翻訳が可能なのである。
こうした課題に対して、実用的なウェブサイト翻訳サービスを提供している企業がいくつかある。自治体で導入事例がある代表的なサービスを表2に挙げてみよう。
【表2 自治体向けのウェブサイト機械翻訳サービスの導入事例】

(広報誌)
情報発信手段として、多くの自治体では、ウェブサイトは補足的な位置付けであり、主力となっているのは広報誌である。したがって、その多言語翻訳は、ウェブサイト翻訳以上に重要な意味を持つ。この分野で大きな地歩を築いているのは株式会社モリサワのMCCatalog+である。元々は様々な紙媒体のコンテンツをデジタル化し、電子配信するサービスであるが、その機能の一つに機械翻訳がある。同社はまた、このサービスで提供された情報をタブレット端末等で閲覧するためのアプリであるCatalog Pocketを無償提供しており、全国の約140の自治体がこの媒体を通じてデジタル広報誌を配信している。10の言語に対応しており、文字も拡大・縮小可能であるほか、音声読み上げ対応や、広報誌にはないコンテンツの追加も可能であるなど、きめ細かなサービスとなっている*4。日本語で作成したレイアウトを維持したまま文章を多言語に置き換えるので、各段落の記述内容を一覧できず、クリックして吹き出しのようにウィンドウを開かなければならない点は不便を感じるが、慣れの問題かもしれない。
このほかサービスの案内にチャットボット(自動応答システム)を利用している自治体もある。この場合の応答は、完全にルールベースであり、あらかじめ決められた質問に対し、あらかじめ用意された選択肢で回答してゆくことになる。質問と回答の外国語文は人が用意するので、厳密には、機械翻訳とは言えないだろう。しかし、多言語サービスとして有用であることは間違いなく、自治体では港区などが在留外国人向けのチャットボットをfacebook上に導入しており、多くの利用実績がある*5。多言語チャットボットを商用サービスとして展開している企業もある*6。
②外国人の窓口対応支援
在留外国人の増加に伴って、様々な自治体に導入が広がりつつあるのが、窓口での外国語対応の支援である。人と人の対面なので、本来は通訳の領域なのだが、常に通訳者をアサインできるわけではないし、利用される言語は多岐にわたる。そこで、来訪外国人と自治体職員のコミュニケーションを翻訳用の端末の支援を得て行う方式が広がりつつある(図4)。
【図4:窓口対応支援ツールの利用】

一般消費者向けとしては、ソースネクスト社のポケトークのようなのサービスがあるし、簡易なやりとりだけであれば、スマートフォンのアプリでもGoogleやMicrosfotなどから無償の翻訳サービスが提供されている。これに対し、自治体向けの商用サービスでは、定型文の記録機能など業務に適した工夫が凝らされている。自治体での導入事例としては、表3が挙げられる。
【表3:自治体向けの音声翻訳サービスの導入事例】

これらのサービスも、ベースにあるのは機械翻訳の機能であり、日進月歩で精度の向上とサービスの改善・拡充が図られている。クラウドベースのサービスであれば、機能改善は即座にサービスに反映され、利用可能となる。
4.機械翻訳を現実の課題解決に役立てるには
現在の機械翻訳はプロの通訳とは違って、対話の仲介を完全に委ねられるものではなく、あくまで多言語間の対話をサポートするに過ぎない。行政サービスにおける機械翻訳の現時点での実用的な役割は、ポストエディットを前提としてドラフト作成に役立てるか、逆に、定型文でのやりとりがうまくいかなかった場合の補助的なコミュニケーションツールとして用いるかのいずれかである。しかし、そうした限定的な用途であっても、機械翻訳の意義は大きい。限界を冷静に見極めたうえで、いかに使いこなすかが問われるわけだが、その際に重要なのは、機械翻訳の技術的な課題のみに捉われず、在留外国人の視点に立って課題を捉えなおすことである。そこで最後に、今後求められる、こうした課題解決の視点をいくつか示したい。
(1)やさしい日本語
なぜ外国語に翻訳するのか、その目的と背景にある課題を突き詰めていけば、外国語への翻訳は、実は真の解決策ではない場合もあるだろう。翻訳の目的が、お互いの意図を伝えることであるならば、その目的さえ達成できるならば、意図を伝えるための手段は必ずしも外国語でなくてもよいはずである。その一つの解が「やさしい日本語」である。在留外国人が「日常生活に困らない言語」として最も多く挙げるのは、英語ではなく日本語なのである(表4)。
【表4:在留外国人が「日常生活に困らない言語」】
日本語 61.7%
英語 36.2%
スペイン語 2.8%
ポルトガル語 2.5%
中国語 1.7%
(出典)独立行政法人 国立国語研究所 日本語教育基盤情報センター,「生活のための日本語:全国調査」 結果報告<速報版>,1.6 日常生活に困らない言語,p.4
https://www2.ninjal.ac.jp/past-projects/nihongo-syllabus/research.html
少なくとも在留外国人の6割の人々が必要とするのは、英語ではない。また、母国語での対応にもそれほど期待していないかもしれない(日本人も外国で日本語サービスに大きな期待はしないだろう)。それより求められるのは日本語を使うときの配慮である。「やさしい日本語」は、難解な漢字熟語や謙譲語を多用した婉曲的な言い回しを避ける、文章を短く切る、やまと言葉を使う、ルビをふるといった工夫を行った表現方法である。在留外国人全体の便益にかんがみれば、多言語対応より先に、まずこちらを充実させるべきかもしれない。日本共通で通じる一種のユニバーサルデザインの言葉として、多国語と同様に使い分けていくべきだろう。多くの自治体が、やさしい日本語で書かれたガイドや、やさしい日本語そのもののガイド(例:春日井市)を作成・公開しており、文化庁も「在留支援のためのやさしい日本語ガイドライン」を動画を含めた教材コンテンツとともに公開している*7。このほか、通常の日本語をやさしい日本語に変換するウェブサービスも存在する。
なお、やさしい日本語と同様の文脈でいえば、東京五輪に向けた準備の過程で、たびたび話題に上った「ピクトグラム(絵文字)」なども限定的な範囲で、同様の役割を担い得るだろう。
(2)AIと人の協働
災害対応などの際は、正確な情報を迅速に提供することが求められる。2019年に台風19号が襲来し、河川氾濫の危険が迫った際、流域の自治体が在留ブラジル人に向けに行ったポルトガル語のアナウンスの内容が、川に行くことを促しているようにも読める訳語となっていることが問題視された。当事者となった自治体職員の言い分によれば、通訳担当者が不在の中、すぐにでも警報を発する必要があり、やむを得ず機械翻訳の結果をそのまま発信してしまったとのことである。様々な不運が重なった結果、起きてしまった偶発的事象の側面もある。本人も非を認め、謝罪と反省をしている。しかし、問題は、組織として、リスク管理の観点での想像力が不足し、準備が行き届いていなかったことだろう。災害時の対応は人命に直結する以上、あらゆる場面を想定しておく必要がある。機械翻訳をどう位置付け、活用するかも含めてあらかじめ考え方を整理し、マニュアル化しておくことが必要となる。
こうした対応のあり方としては、自動翻訳システムと通訳オペレーターとの連携も有力な選択肢に入ってくる。通常は機械翻訳で対応するが、応答に詰まった場合などにすぐにオペレーターを呼び出せるようにしておくのである。これによりスムーズなサービス運用と職員の負荷軽減を図ることが可能になる。実際に、前掲の表3の事例でも、AIの機能とオペレーターによるサポートを組み合わせてソリューションとして提供している企業が見られる。機械翻訳をかけた上でポストエディットする方式も、こうした分担の一類型であるといえよう。
(3)今後の展望
総務省は次期「グローバル・コミュニケーション計画2025」において、大阪の日本博覧会を見据え、AIによる「同時通訳」の実現を目指すことを目標として掲げた*8。もとより通訳者がAIに完全に置き換わることはないとしても、簡単なコミュニケーション程度であれば、相当な精度が期待できるだろう。そして、その成果は一般の自治体行政にも波及する。
その際、自治体には、広報誌の外国語対応や窓口対応をいかに改善するか、といった受け身の議論だけに終始してほしくないものである。
筆者は、日本の公務員の最大の欠点の一つは国際的な視野の欠落であると考えている。他国では実に活発に、行政機関間の意見交換や相互交流が行われている。そうした中で、日本の公務員だけが、言語の障壁によって、見事に世界から引きこもり状態になっている。近年は、アジア諸国の行政職員も、普通に英語で欧米圏の人々とコミュニケーションをとっている。自動通訳システムが、日本の行政職員のこうした閉塞状況を打開する糸口になることを期待したい。そこで本当に重要となるのは語学力ではなく、課題の解決策を、外に打って出て求めようとする気概であろう。自動通訳システムは、行政職員から言語の壁という言い訳を取り去ることで、積極的に外に打って出ることを促す仕掛けとして機能するのではないか、そんな淡い期待を抱いている。
<脚注>
*1 日本政府観光局,月別・年別統計データ(訪日外国人・出国日本人)
https://www.jnto.go.jp/jpn/statistics/visitor_trends/
*2 出入国在留管理庁,在留外国人統計
http://www.moj.go.jp/isa/policies/statistics/toukei_ichiran_touroku.html
*3 「新型コロナウイルス感染症の影響により、市役所に訪れる外国人住民も増加傾向にあり、身近な暮らしに関する相談等も増加」(富里市,多言語音声翻訳アプリを活用した窓口サービスの開始について)
https://www.city.tomisato.lg.jp/0000011660.html
*4 MCCatalog+及びCatalog Pocket(モリサワ)
https://www.morisawa.co.jp/products/multilingual-service/
*5 多言語AIチャットによる外国人向け情報発信を行っています!(港区)
https://www.city.minato.tokyo.jp/kokusaika/aichatservice.html
*6 「多言語AIチャットボットサービス」(ランゲージワン)
https://japan.cnet.com/release/30378857/
*7 文化庁,在留支援のためのやさしい日本語ガイドライン,2020.8
https://www.bunka.go.jp/seisaku/kokugo_nihongo/kyoiku/92484001.html
*8 「グローバルコミュニケーション計画2025」の公表
https://www.soumu.go.jp/menu_news/s-news/01tsushin03_02000298.html
<参考文献>
ティエリー・ポイボー,機械翻訳 歴史・技術・産業,森北出版,2020
日本音響学会編,音声言語の自動翻訳,コロナ社,2018