

2024年6月の記事一覧

Image 特徴点 Clustering
Image feature Clustering
画像分類器のトレーニング方法について、特に Bag of Words (BoW) モデルとサポートベクターマシン (SVM) を用いた方法を詳しく説明します。以下に、コードを通して各ステップを詳細に解説します。
ステップ1: データセットの準備
まず、各画像の特徴点を抽出し、その特徴量をリストに格納します。また、画像のクラスラベルも準備します


一瞬で綺麗なdepthを取ることができる「Depth Anything V2」を試してみる
Depth Anythingがバージョン2で復活!Depth Anything がバージョン 2 で復活しました。
現在の他の方法よりも 10 倍高速とのこと。すごい!
さまざまなサイズのモデル (2500 万から 13 億のパラメータ) が Huggingface Hub で入手可能になっています。
Depth Anything V2とは?Depth Anything V2はカメラ1台で撮影し
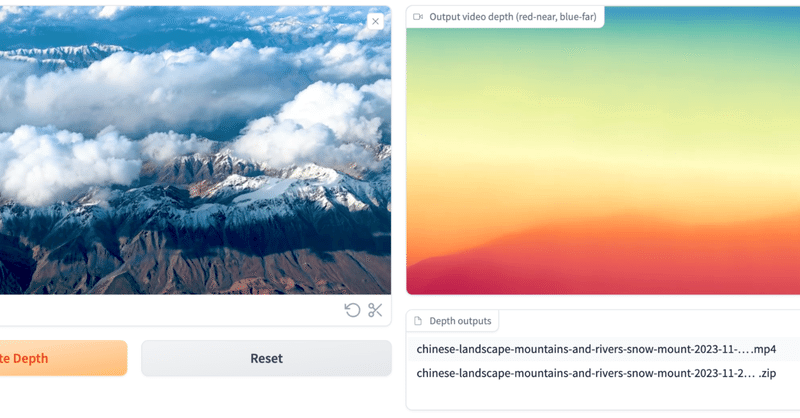
動画での深度推定AIの「ChronoDepth」を試してみる
「ChronoDepth」とはChronoDepthは超簡単に使える動画での深度推定AIツールです。
深度推定モデルをビデオに直接適用すると、フレーム間で不整合が生じる可能性がありますが、実際そういうちょっとした不整合でつかいものにならない残念さはクリエイターならみんな実感するとこと。
これはそういうこともなく簡単にできちゃうとのこと。ありがたや〜〜
なお、モデルはStable Video Dif


Depth anything2/Negitoolsでステレオ画像を作成して立体視を試す/ComfyUI x Xreal Air
Xreal Airは、「1920x1080」の画像をside by sideにしたものに対応しています。
通常の画像生成で1920x1080は若干厳しいと言わざる得ないサイズですので、「1280x720」で生成するのが良さそうです。
ノード項目の説明
①「Divergence」:深度のことのようです。デフォルトが5.00です。ただ、webui版は2.5がデフォルトです。
Divergence

論文解説 Style-NeRF2NeRF: 3D Style Transfer From Style-Aligned Multi-View Images
ひとことまとめ
概要画像生成AIの変換能力をNeRFに応用することで効率的な3Dスタイル変換を実現した。一度NeRFを学習させたあとSDXLでスタイル変換を行い、そのスタイル画像から再度NeRFを再学習させることで、品質の良いスタイル変換を可能にした
提案手法提案手法は、NeRFから複数の角度でレンダリングを行い、それをスタイル画像に変換する工程と、NeRFを生成したスタイル画像でfinetu


レガシーAIシリーズ(2) 簡単アニメキャラ抜き出しアプリ
画像中のアニメのキャラクタだけを抜き出したいことってありますよね。Illustratorなどの画像処理系アプリを使えばそれなりに出来ますし、WebUIなど、StableDiffusionで生成する時に背景削除も出来るようになっています。そのような中でキャラクタを取り出して画像の中央に配置し、ついでにアップスケールで自在に大きさを変えたり、キャンパスサイズを変更してキャラクタの一部、例えば顔やポート
もっとみる論文解説 4M-21: An Any-to-Any Vision Modelfor Tens of Tasks and Modalities
ひとことまとめ
概要Any to Anyの研究は以前から行われていたが、使用されているモーダル数が少なく変換に制限があった。そこでSAMや4DHumansなどの疑似ラベルや画像のメタデータやカラーパレットなどのモダリティを追加した。既存のモデルよりも性能の低下なしに3倍多くのタスクやモダリティを解けることを示した
提案手法提案手法は4M(https://arxiv.org/pdf/2312.0


画像認識AI YOLOの歴史
2024年10月更新:YOLOv11を追加しました
記事作成者について:ダンスの全国大会などで動きの分析のお仕事などをさせて頂いております。
YOLOとはAIの力で画像内の映っているものを分類し、それが何かを類推することが出来る技術です。YOLOは"You Only Look Once"を意味し、「一度見れば何が映っているか分かるよ」というメッセージの略となっています。
元々、YOLOは "
