

#大規模言語モデル

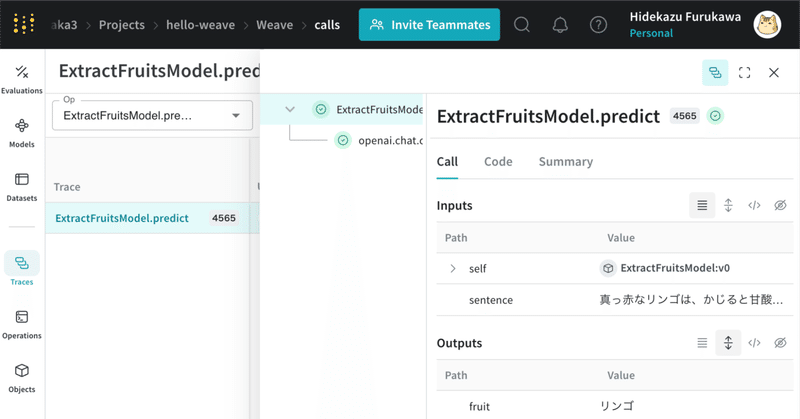
LLMアプリケーションの記録・実験・評価のプラットフォーム Weave を試す
LLMアプリケーションの記録・実験・評価のプラットフォーム「Weave」がリリースされたので、試してみました。
1. Weave「Weave」は、LLMアプリケーションの記録、実験、評価のためのツールです。「Weights & Biases」が提供する機能の1つになります。
主な機能は、次のとおりです。
2. Weave の準備今回は、「Google Colab」で「Weave」を使って「O




LangChain クイックスタートガイド - Python版
Python版の「LangChain」のクイックスタートガイドをまとめました。
【最新版の情報は以下で紹介】
1. LangChain「LangChain」は、「大規模言語モデル」 (LLM : Large language models) と連携するアプリの開発を支援するライブラリです。
「LLM」という革新的テクノロジーによって、開発者は今まで不可能だったことが可能になりました。しかし、

Axolotl で 一問一答の対話データセットによるLoRAファインチューニングを試す
「Axolotl」で一問一答の対話データセットによる「Axolotl」のLoRAファインチューニングを試したのでまとめました。
前回1. 学習内容今回は「Axolotl」の練習として、「Llama-2-7b」を「ござるデータセット」(databricks-dolly-15k-ja-gozarinnemon)でLoRAファインチューニングしてみます。
2. Colabでの実行手順Colabでの実

LLMのファインチューニングのためのツール Axolotl
LLMのファインチューニングのためのツール「Axolotl」の概要をまとめました。
1. Axolotl「Axolotl」は、LLMのファインチューニングのためのツールです。様々なLLM、データセット形式、アーキテクチャをサポートします。
2. Axolotlのサポート3. クイックスタート# インストールgit clone https://github.com/OpenAccess-AI-C


RAG における埋め込みモデルの比較
LLM を使った RAG を行う際に埋め込みモデルが必要となりますが、どの程度差がでるのか 4 種類ほどの埋め込みモデルを使って検証してみたいと思います。
今回試す埋め込みモデル:
intfloat/multilingual-e5-large
cl-nagoya/sup-simcse-ja-large
pkshatech/GLuCoSE-base-ja
openai/text-embed

RAG評価ツール ragas を試す
RAG評価ツール「ragas」を試したので、まとめました。
1. ragas「ragas」は、「RAG」 (Retrieval Augmented Generation) パイプラインを評価するためのフレームワークです。「RAG」は外部データを使用してLLMのコンテキストを拡張するLLMアプリケーションです。「ragas」はこのパイプラインを評価して、パフォーマンスを定量化します。
2. Co
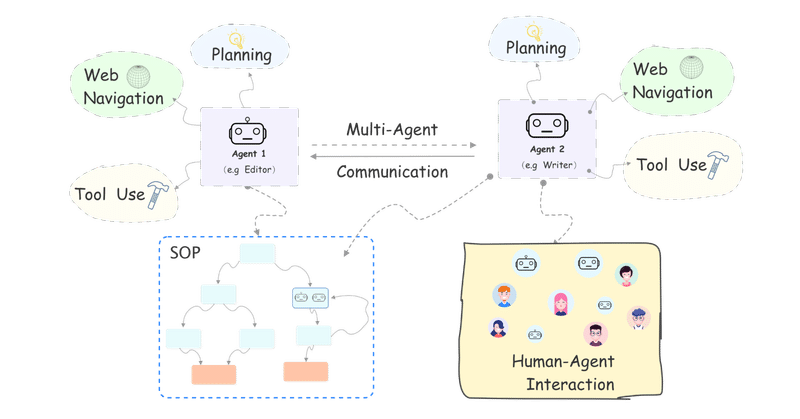
自律言語エージェントを構築するためのフレームワーク Agents を試す
自律言語エージェントを構築するためのフレームワーク「Agents」を試してみたので、まとめました。
1. Agents の概要「Agents」は、自律言語エージェントを構築するためのフレームワークです。
「コンフィグファイル」に自然言語で設定を記述するだけで、「言語エージェント」または「マルチエージェントシステム」をカスタマイズし、「ターミナル」「Gradio」「バックエンドサービス」にデプロ
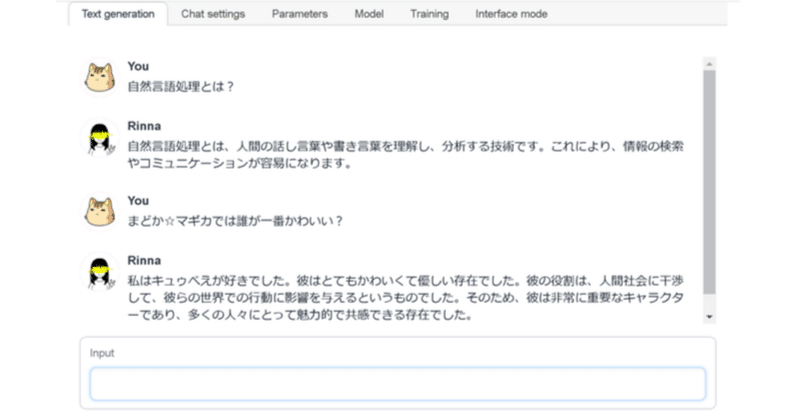
text-generation-webui の 設定項目まとめ
「text-generation-webui」にどんな設定項目があるのかをまとめました。
前回1. Text generation タブ「Text generation タブ」は、テキスト生成を行うタブです。
以下の3つのモードがあり、「Inference mode タブ」で切り替えます。
1-1. chatモード
1-2. notebookモード