
レシピサイトから砂肝と相性の良い食材を調べる【R/polite/netCoin】

●前書き
砂肝は安くておいしい。
和洋中様々なレシピがあり、どんな調理法や味付けが人気なのか気になるところです。
今回は砂肝のおいしい食べ方をレシピサイトで調べてみました。
Rで
今回の記事の経緯ですが、KHcoderの共起ネットワークをRのみで描きたいと試行錯誤していたところ、netCoinというパッケージでカッコイイインタラクティブな共起ネットワーク的なグラフを描けることが分かりました。
ただし、日本語はおろか英語すらnetCoinの使い方を解説しているページがほとんどない…。
netCoinの使い方を勉強するため、レシピサイトデータを例としてcoincident分析してネットワーク図を描いてみました。
●やること
windows11のローカルRStudio環境を使って
・レシピサイト(クックパッド)からpoliteとrvestで砂肝を含むレシピを抽出し
・stringiでデータ前処理をして
・netCoinで共起性解析をして
砂肝とどんな素材の相性が良いか、どんな原料の組み合わせのレシピが多いのかをデータ可視化していきます。
本記事はスクレイピングを扱いますが、実施に関しては一切の責任を負いかねます。
実施する場合は対象サイトの利用規約に目を通してください。
HPのデザイン変更によってデータが取れない場合がございます。
余裕を持ったウェイトタイムを設定し、絶対に相手方サーバーに負荷をかけないように十分ご注意ください。
① レシピサイトからデータを取得する
今回はクックパッドからデータを取得します。
・パッケージの読み込み
rm(list = ls())
gc()
gc()
if (!require("pacman")) install.packages("pacman")
pacman::p_load(
tidyverse,
stringi,
magrittr,
lubridate,
rvest, # scraping
polite, # polite
arules, # association
arulesViz,
htmlwidgets,
netCoin, # coincident
openxlsx
)・データの取得
今回は50ページ500件のレシピを取得して分析しました。
robotstxt::robotstxt("cookpad.com")
# polite::bow
host<- "https://cookpad.com/"
session <- polite::bow(host, delay = 5, force = TRUE, verbose = TRUE)
word <- "砂肝"
page_range <- 1:50
# url
scrape_cookpad_url <- function(word, page_num) {
# polite url set
session_nod <- polite::nod(bow = session,
path = paste0(host,
"search/",
URLencode(word),
sep = "")
)
# scrape politely!
html <- polite::scrape(bow = session_nod,
query = list(page = page_num))
# create url list
url_link <- html %>%
html_nodes("a") %>%
html_attr("href") %>%
unique() %>%
stri_subset(regex = "/recipe/[0-9]") %>%
na.omit() %>%
as.character() %>%
paste0("https://cookpad.com", .)
return(url_link)
}
lapply(page_range, function(i) {
message("Getting page ", i, " of ", length(page_range)) # Progress bar
Sys.sleep(runif(1, 1, 2)) # Take a break
if ((i %% 3) == 0) { # After every three scrapes... take another break
Sys.sleep(runif(1, 2, 3))
}
scrape_cookpad_url(word = word, page_num = i) # Scrape
}) %>%
unlist() -> output_url
# content
scrape_cookpad_content <- function(url) {
# polite url set
session_nod <- polite::nod(bow = session,
path = url
)
# scrape politely!
html <- polite::scrape(bow = session_nod)
# recipe_title
title <- html %>%
html_nodes("#recipe-title > h1") %>%
html_text() %>%
stri_replace_all(regex = "\n", replacement = "")
# description
desc <- html %>%
html_nodes("#description > div.description_text") %>%
html_text() %>%
stri_replace_all(regex = "\n", replacement = "")
# ingredients
ing <- html %>%
html_nodes("#ingredients_list") %>%
html_text() %>%
stri_replace_all(regex = "\n.*\n\n|\n\n■", replacement = "/") %>%
stri_replace_all(regex = "<U+2B50>|<U+25C9>|<U+2665>|<U+2661>|○|〇|■|●|▲|□|▼|△|▽|◇|◆|☆|★|◎", replacement = "") %>%
stri_replace_all(regex = "[[:punct:]]|[:blank:]", replacement = "/") %>%
stri_replace_all(regex = "\n", replacement = "") %>%
stri_replace_all(regex = "/+", replacement = "/") %>%
stri_replace_all(regex = "/$|^/", replacement = "")
# tsukurepo count
count <- html %>%
html_nodes("[class='tsukurepo_section_count']") %>%
html_text() %>%
stri_replace_all(regex = "\n", replacement = "") %>%
stri_replace_all(regex = "\\(.+?\\)", replacement = "") %>%
stri_sub(from = 1L, to = -2L) %>%
as.numeric()
if (is.na(count)) {
count <- 0
}
# publish date
pub_date <- html %>%
html_nodes("#meta_data_wrapper > span:nth-child(3)") %>%
html_text() %>%
stri_replace_all(regex = "\n", replacement = "") %>%
stri_replace_all(regex = "更新日 : ", replacement = "") %>%
ymd()
# dataframe
df <- tibble(title,
desc,
ing,
count,
pub_date,
page_url = url
)
return(df)
}
match_key <- tibble(
n = 1:length(output_url),
key = sample(1:length(output_url), length(output_url))
)
lapply(1:length(output_url), function(i) {
j <- match_key[match_key$n == i, ]$key
message("Getting page ", i, " of ", length(output_url), "; Actual: page ", j) # Progress bar
Sys.sleep(runif(1, 1, 2)) # Take a break
if ((i %% 3) == 0) { # After every three scrapes... take another break
Sys.sleep(runif(1, 2, 3))
}
scrape_cookpad_content(output_url[j]) # Scrape
}) %>%
dplyr::bind_rows() -> cp_data
write.xlsx(cp_data, file = "cp_data.xlsx", sheetName = "cp_data")
cp_data <- read.xlsx(choose.files())レシピ一覧ページから個別レシピのURLを取得してURLリストを作成→個別レシピページから内容を取得。という流れの動作になっております。
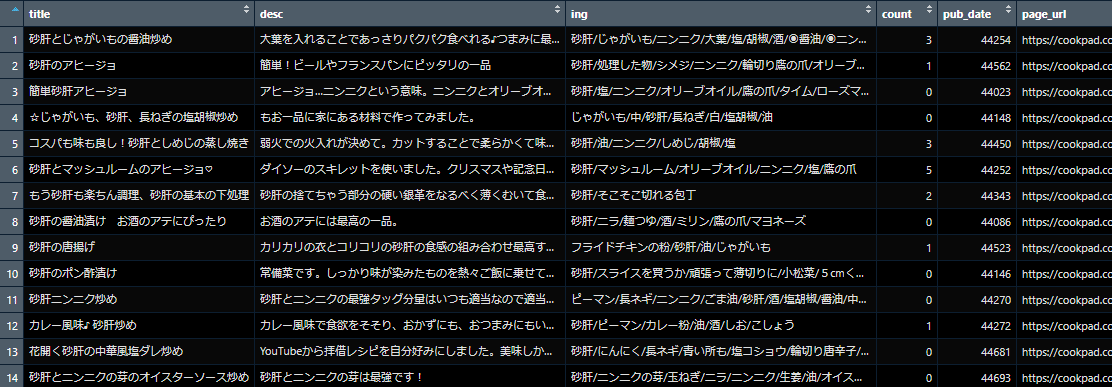
②stringiで前処理
得られたレシピの材料情報(ing列)からネットワーク解析をしていきたいのですが、レシピ作成者ごとにかなりの表記ゆれがあり、これらをなるべく同じ言葉に統一していきます。
・にんにく/ニンニク/大蒜 → にんにく
・ねぎ/青ねぎ/ネギ/白髪ねぎ/白ねぎ/長ネギ.… → ねぎ
・輪切り唐辛子/とうがらし/トウガラシ → とうがらし
stringiパッケージで文字列を変換して頑張って統一していきます。
全ての素材を網羅して記載統一するのは難しいので、主要な原料についてほどほどにやっていきます。
cp_data2 <- cp_data %>%
mutate(ing = stri_replace_all(.$ing, regex = "または|刻み|刻んだ|みじん切り|万能|パウダー|スライス|の素|下ろし|おろし|擦り|まるごと|チューブ|白髪|輪切り|一味|パック|[0-9a-zA-Z]|None", replacement = "")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "しょう油|醤油", replacement = "しょうゆ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "お酢|ビネガー", replacement = "酢")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "出汁|ほんだし|和風だし", replacement = "だし")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "麺汁|麺つゆ|めん汁", replacement = "めんつゆ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "サラダ油", replacement = "油")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "卵|タマゴ", replacement = "たまご")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "たまごの黄身", replacement = "卵黄")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ぎも|ギモ", replacement = "肝")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "すな肝|スナ肝", replacement = "砂肝")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "柚子|ユズ", replacement = "ゆず")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "味噌|ミソ", replacement = "みそ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "コンブ|昆布", replacement = "こんぶ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "/しお", replacement = "/塩")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "上白糖|グラニュー糖|さとう|三温糖|黒糖", replacement = "砂糖")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "鶏|鳥|トリ", replacement = "とり")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ガラ", replacement = "がら")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ポン酢|味ぽん", replacement = "ぽん酢")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "コショウ|粒こしょう|粒コショウ|粒胡椒|胡椒|ブラックペッパー|ホワイトペッパー|黒胡椒|黒粒胡椒|粒胡椒|黒こしょう", replacement = "こしょう")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "トウガラシ|唐辛子|レッドペッパー|鷹の爪|たかのつめ|赤とうがらし|赤トウガラシ|赤唐辛子", replacement = "とうがらし")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "コンニャク|蒟蒻", replacement = "こんにゃく")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ワサビ|山葵", replacement = "わさび")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ネギ|葱|長ねぎ|長ネギ|青ねぎ|青ネギ|白ねぎ|白ネギ", replacement = "ねぎ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ゴマ|胡麻", replacement = "ごま")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ライス|ご飯|白米", replacement = "ごはん")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "玉ねぎ|タマネギ|玉葱", replacement = "たまねぎ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ニンジン|人参", replacement = "にんじん")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ジャガイモ|じゃが芋|馬鈴薯", replacement = "じゃがいも")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "キュウリ|胡瓜", replacement = "きゅうり")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ニラ|韮", replacement = "にら")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "シシトウ|獅子唐|ししとうがらし|シシトウガラシ|獅子唐辛子|獅子とうがらし", replacement = "ししとう")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ニンニク|大蒜|ガーリック", replacement = "にんにく")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "シイタケ|椎茸", replacement = "しいたけ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "キクラゲ|木耳", replacement = "きくらげ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "シメジ|ブナピー|ぶなしめじ|ブナシメジ", replacement = "しめじ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "エリンギ", replacement = "えりんぎ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "エノキ茸|えのき茸|エノキダケ", replacement = "えのきだけ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ショウガ|生姜", replacement = "しょうが")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "シソ|大葉|青しそ|青じそ|青紫蘇|青ジソ|赤しそ|赤じそ|赤紫蘇|赤ジソ", replacement = "しそ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "らー油|辣油", replacement = "ラー油")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "味醂", replacement = "みりん")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "マイタケ|舞茸", replacement = "まいたけ")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "料理酒|調理酒|日本酒|お酒", replacement = "酒")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "ミリン|味醂|みりん風調味料", replacement = "みりん")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "/|//", replacement = "/")) %>%
mutate(ing = stri_replace_all(.$ing, regex = "/$", replacement = ""))netCoinの勉強が目的なのでこれくらいで許してください…。
③ ネットワーク図を作る
netCoinパッケージを使って食材のネットワーク図を作っていきます。
食材のデータは以下のような"/"区切りの文字列データです。

netCoinではnetCoin::dichotomize関数で区切り文字を指定して、共起の有無を0/1で示したdata.frameを作成することができます。
一行目と最後の行はネットワーク図作成時に不要なので消してやります。
data <- cp_data2 %>%
select(ing) %>%
dichotomize("ing", sep = "/")
data <- data[2:(length(data) - 1)]ここからnetCoinパッケージのasNodesとedgeList関数でノードとエッジを計算し、それぞれの必要な部分をfilterしてやってnetCoin関数に入れてやると…簡単にできます。
C <- coin(data)
N <- asNodes(C) %>%
filter(frequency > sum(frequency) / 200)
E <- edgeList(C) %>%
filter(.[, 4] < 0.05)
net <- netCoin(
nodes = N, links = E,
showArrows = TRUE, size = "frequency",
dir = "net"
)
plot(net)この場合、ノードを材料の出現頻度0.5%以上(support >0.005)、エッジをp(Z)<0.05でフィルターしています。
また、dir=で指定した場所にnet.htmlというファイル名で作成したネットワーク図htmlが保存されます。

NODES設定Size=frequency, Color = frequency
LINKS設定Width=p(Z), Color =p(Z)
GRAPHのDistanceとRepulsionを適当にいじる
と良い感じになります。


オリーブオイル+ニンニク+トウガラシでアヒージョ
ごま油+ねぎorたまねぎ+とりがらスープ
シンプルに塩コショウ
しょうが+砂糖+みりん+酢で甘酸っぱく
オイスターソース+ピーマン+にらで中華餡っぽく
などなど、おいしそうな食材組み合わせのレシピがネットワーク図とヒートマップから見えてきます。
もっと取得レシピ数を増やし、つくれぽの数などでフィルターしてから分析することでより人気なレシピの鉄板な組み合わせを絞り込むこともできます。
④アソシエーション分析の場合
アソシエーション分析arules+arulesVizパッケージのparacoordでも、confidenceソートにすると食材の組み合わせが分かりやすいグラフを作成することができます。
tran <- cp_data2 %>%
select(ing) %>%
mutate(ing = stri_replace_all(.$ing, regex = "/NA", replacement = "")) %>%
dplyr::filter(str_detect(.$ing, pattern = "/")) %>%
mutate(ing = str_split(str = .$ing, pattern = "/")) %>%
t() %>%
as.vector() %>%
map(base::list()) %>%
as("transactions")
rules <- apriori(tran,
parameter = list(
support = 0.05,
confidence = 0.8,
maxlen = 6
)
)
# liftで抽出
rules2 <- head(rules, n = 50, by = "confidence")
plot(rules2, method = "graph", control = list(engine = "visNetwork", max = 25))
plot(rules2, method = "paracoord")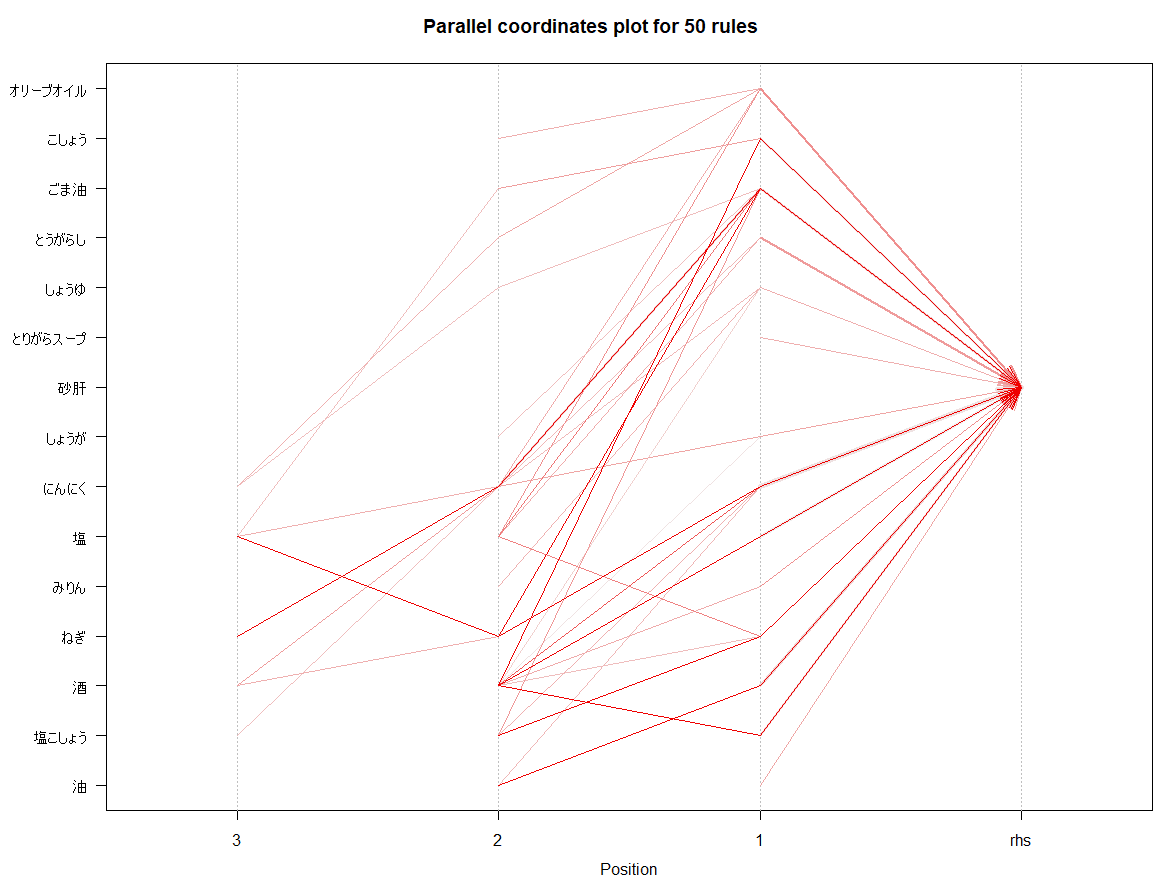
アソシエーション分析ではliftを使って「あまり知られてはいないけれど実はスゴい組み合わせ」を探ることができるため、見た目が分かりやすくて直感に合致しカッコイイnetCoinのネットワーク図とは使い分けができそうです。
以上です。
ありがとうございました。