
実在しない人の顔を生成するStyle-GANをのおはなし(論文解説)

こんにちは、こんばんは、teftefです。ここ最近、更新頻度が多いのは遠出していないからです。前回は敵対的生成ネットワーク、通称 GAN について基本的なところについて書きました。今回はいくつかある GAN うちの中でもStyle-GANについて書いていきたいと思います。というより、1本の論文をベースにその論文に書かれていることをできるだけわかりやすくまとめるというのがこのの記事です。毎度のことですが…主もまだつい最近まで初学者であり、説明が間違っていたり勘違いがある可能性が0ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
復習
GANは敵対的生成ネットワークといって、偽画像を生成する生成器(GEnerator)と真偽を鑑定し、判別する識別器(Discriminator)が互いに競い合って学習することで、クオリティーの高い画像生成器を作る機械学習でした。詳しくはリンクにある前回の記事をご覧ください。
参考文献
前回の記事でも紹介したように一言にGANといっても数多くの種類があり、今回はその中でも人の画像を生成することに特化した Style-GAN について書いていきます。今回参考にさせていただいた論文はこちらです。
https://arxiv.org/pdf/1812.04948.pdf
こちら2018年に発表された論文で、中身を軽く見てみると「え?これほんとに AI が生成したの?!」と思うくらいのクオリティーの顔写真が並んでいます。
また事前に Style-GAN の知識を仕入れるためにこちらの記事を参考にさせていただきました。
概要
どの論文も基本的に同じなのですが、「私たちの考えた方法が一番優れている!!」というのを言いたいので、そこをくみ取ってあげて読みました。
今回の論文では、Style-GAN は今までの GAN とは異なり、
1 . ノイズから精製するのではなく固定の4×4×512の固定テンソルから画像を生成している
2 . 潜在表現をベクトルにマッピングしてノイズも一緒にAdaINを通して層に導入する
こうすることでより実際の人間に似たような顔画像が生成できるんです!!これらが革新的なのです。え…なんか難しい用語がたくさん出てきました。それらも踏まえてかみ砕いて説明してみたいと思います。
ネットワーク構造
従来手法
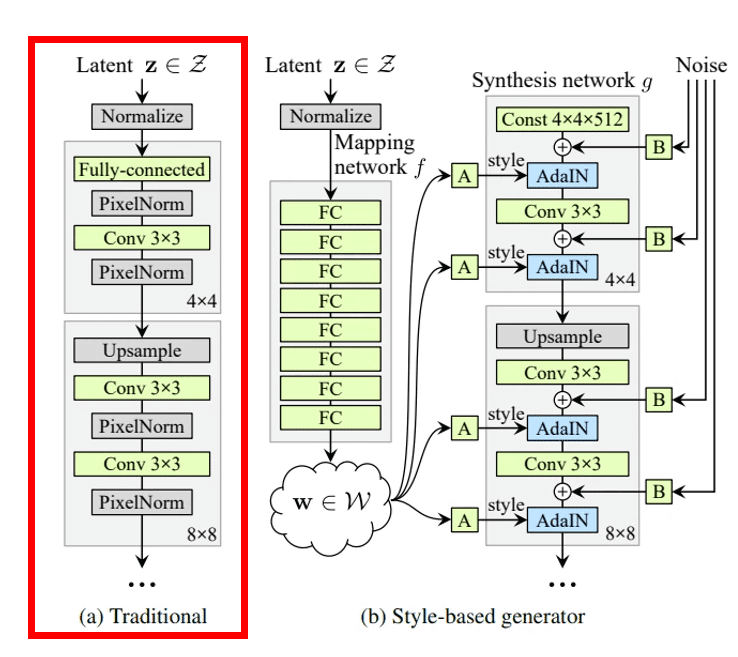
提案されたネットワーク →
まずは全体の構造を見ていきます。従来の Style-GAN は左のようになっています。これは潜在表現をどんどんアップサンプリング(畳み込みの逆)していって最終的に顔画像を生成する手法です。
潜在表現
少しこの潜在表現について詳しく見ていきます。画像などを扱う場合は512×512の次元を扱うことになり、これをそのまま1つずつノードに格納して、重みを学習させることはできません。CNNの解説をしたときに、適切な畳み込みを行うことで大切な情報を保持したまま、より少ない次元(パラメーター量)で表せることを書きました。実はCNNに限らず、機械学習ではデータを圧縮します。このよう圧縮したものを特徴量と呼びこれを保持したものを潜在表現(内部表現)といいます。わかりやすくするとこのようになります。
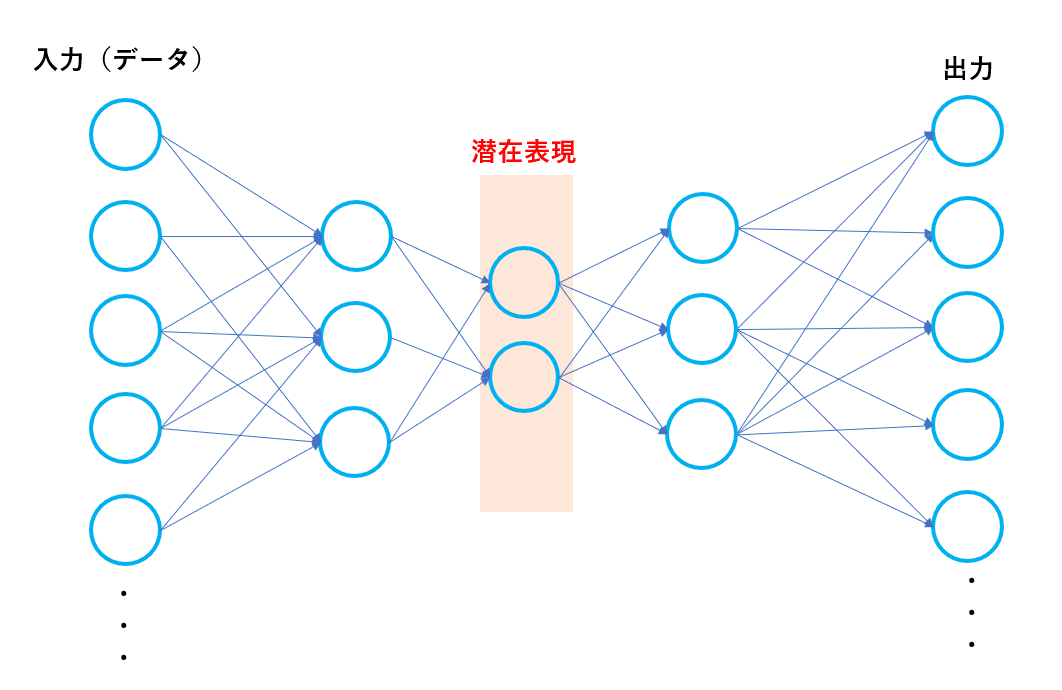
実際はもっとたくさんの層とニューロンがありますが、簡略化するとこのようになります。一言で説明すると、『何かを表す際にそれを最も簡潔に、そしてそれを最もよく表す情報(本質情報)の集まり』とかみ砕いてみました。
ではその潜在表現はそうやって作るの?という疑問がわいてきますが、それはまた表現学習、オートエンコーダーを解説した別の記事で詳しく説明します。とりあえず今は、そういう都合のいい潜在表現(今回は人間の顔の潜在表現)が用意されていて、それをStyle-GANに入れると人間の顔が生成されるという認識で大丈夫です。
提案手法の左側
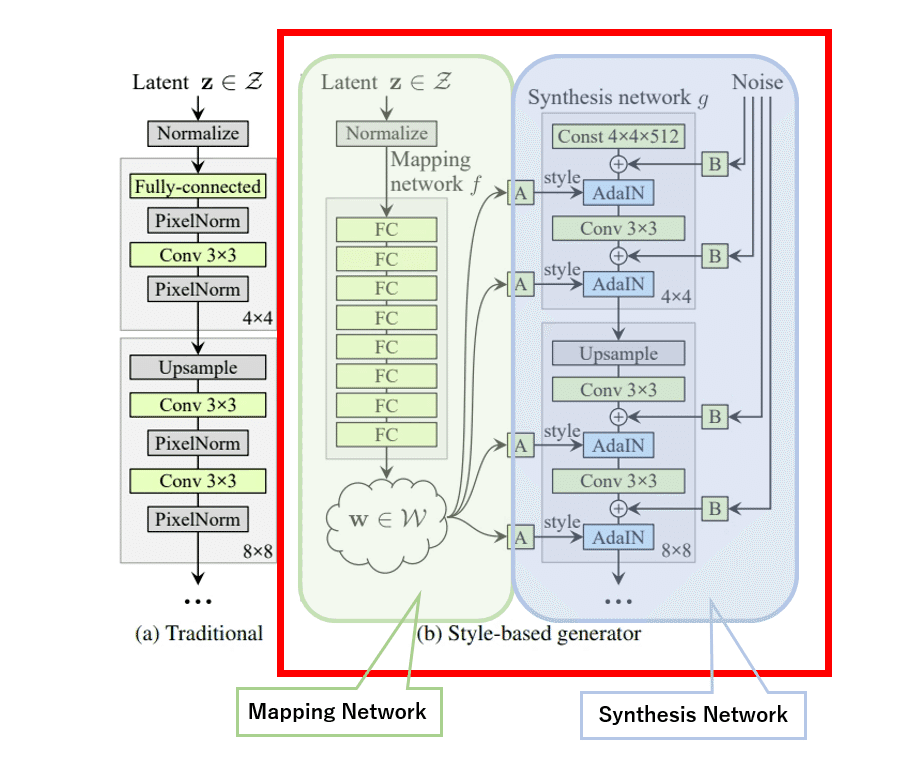
提案されたネットワーク →
それでは右側の提案手法のネットワークについて見ていきます。このネットワークでは主に2つの部品から成り立っています。
まずは左の緑で覆われた部分、 Mapping Network です。ここでは潜在表現を全結合層(FC)に格納し、多層パーセプトロンを通して学習させます。この結果を中間的な特徴空間Wにマッピングします。Wは潜在表現を学習させた結果を一時的に保管している保管庫のようなものです。
提案手法の右側
続いて右側の青で覆われた部分、Synthesis Networkです。ここでは従来のネットワークと同じようにCNNをアップサンプリングしていき画像を生成します。ただし、従来とは異なり、初めの部分が潜在表現ではなく4×4×512 の固定テンソル(「テンソル」を知らなければ行列のようなものと理解しましょう)から始まります。
また先ほどの中間の特徴空間W(中間保管庫)からランダムに w を取り出し、行列 A をかけた後に『AdaIN』というものを通して、特徴マップに適応させ(入れ込み)ます。この『AdaIN』では何をやっているのかというとこのような数式になっています。
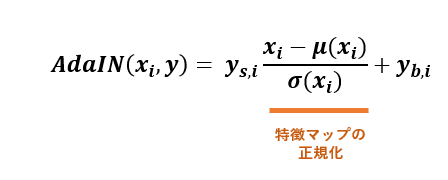
はい、意味不明ですね(笑)。正直、主もまだ完全にはよくわかっていません。わかる範囲で説明すると、 y_s,i と y_b,i は Mapping Network を通して生成された特徴マップの平均と分散とであり、このオレンジ色の部分で正則化しています。正則化することによって平均と分散を合わせることができて、この操作がとても重要なのです。ちなみに論文ではこの部分を『Style』と呼んでいます。
『Style』の意味
この『Style』をネットワークのどこに入れるかで生成画像が決まります。例えばネットワークの浅い部分で『Style』を指定するとその『Style』が大きく影響します。眼鏡をかけているか、顔の形はそうなのかなどの大まかな輪郭が決まります。そして逆にネットワークの深い部分で『Style』を指定するとその『Style』が影響しますが、それは肌の色や毛先の髪形など細かい部分しか影響しなくなります。実際に例を見てみましょう。
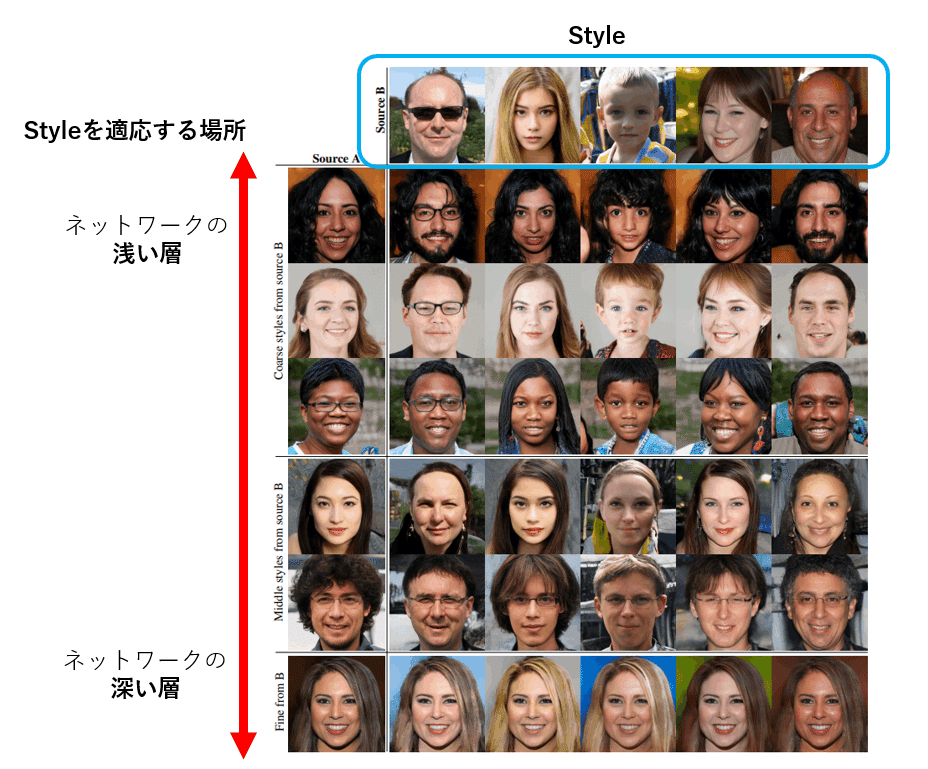
縦の列の画像に横の水色で囲んだ人の『Style』を適応させていきます。すると確かにネットワークの浅い部分で『Style』を適応した、いい番上の肌の色の濃い女性やその一つ下の女性は男性に変化し眼鏡をかけたり、子供に変化したり、と大きな変化が見られます。それに対して、一番下のットワークの深い部分で『Style』を適応した女性は髪色や肌の色しか変わっていません。つまりこのように『Style』を適応させるタイミングが重要なのです。
ノイズ
さらにそれに加えて、正規分布からサンプルしたノイズが行列B を通して特徴マップに適応させ(入れ込み)ます。このノイズの役割は生成された画像の髪の毛の乱れやしわの入り方など、細かい部分を少しだけ確率的に変更できます。これはあまり大きな影響を与えないので今回はさらっと流します。
きれいに変化させるコツ
人間の顔に『Style』を適応して変換する以前は、潜在空間(潜在表現が格納されている空間)を変化させていました。こうすると途中の部分で顔がゆがんだり、ひずみが出てしまうことがあります。これはなぜかというと潜在空間が「もつれ」ているためです。このもつれを改善することでより良い画像が生成されます。ちなみにこのもつれをPerceptual path lengthという指標を使って評価しています。
潜在空間を直線でつなぎ、変化させた場合、生成画像の特徴マップも線形になっているはずです。そして提案手法では生成された画像の特徴空間を見ると確かに曲がっていないのでより良い結果となっていることがわかっています。
感想
『Style』を適応させる部分を直感的に解釈してみました。実際に絵をかくときはラフである程度の輪郭を決めて、色を付けて最後に微調整します。最初のほうでは輪郭の調整はいくらでも利きますが、完成間近に輪郭を替えてと言われても無理ですよね。これが『Style』をネットワークのどこに適応させるかと感覚的に近いんじゃないかと思っています。
潜在空間の「もつれ」はまだ完全に把握したわけではないので、簡単にかみ砕いて説明できるようになったらそこの部分について詳しく記事を書こうと思います。
次回予告と宣伝
今回はここまでです。次回はCycle_GANに焦点を当ててみたいと思います。最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加してお絵描きAIを探ってみてはいかがでしょう。(teftef)