
Stable Diffusion : ハイパーネットワーク学習ガイド

こんにちは、こんばんは teftef です。今回の記事は automatic1111 様が作成した Stable Diffusion Web UI を使って自分好みのイラストの学習方法について解説していきたいと思います。この記事では Stable Diffusion Web UI の設定に関しては飛ばしめで行きます。主もまだつい最近まで初学者であり、説明が間違っていたり勘違いがある可能性が0ではないということをご了承ください。もう出てるかもしれませんが、一応備忘録なので書きます。
Stable Diffusion Web UI のセッティング
まず Stable Diffusion Web UI をセッティングしてきます。Automatic1111 様の Git hub はこちら。
Python のインストール
このページに行っていただき、必要なバージョンを選択し、ダウンロードしましょう。バージョンは 3.10.xx であれば問題ないです。
Git のダウンロード
続いて Git コマンドを使うためにこちらのページからダウンロードしましょう。主は今回 E ドライブ直下に置きました。
E:\stable-diffusion-webui
こんな感じです。
Stable Diffusion Web UI
それではGit clone を使ってコードを所定のパスにダウンロードし、学習済み重みファイル (ckpt) をダウンロードし、
E:\stable-diffusion-webui\models\Stable-diffusion
の下に実装したい ckpt ファイルを置きます。続いて webui-user.bat ファイルを編集します。
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS=--deepdanbooru
call webui.batこのように変更してあげましょう。
最後にダブルクリックで実行すれば Stable Diffusion Web UI が使えるようになります。ちなみに今回、主はこちらの ckpt ファイルを使わせていただきました。
ここまで大まかにざっくり説明しましたが、詳しく知りたい方はこちらからどうぞ。
ハイパーネットワークのトレーニング
ハイパーネットワークというのは簡単に言うと、指定した画像の特性を学習し、自分好みのキャラを生成しやすくできるようにするネットワークです。では自分好みの画像を20枚ほど入力し、これをトレーニングすることでその画像のスタイル(?)を学習し、その入力画像のような絵を出してくれます。
やり方はこちらの記事に載っていますが、英語で、しかも割と長いので、実際に主が試してみた記録と感想を書きます。
Stable Diffusion の起動
最初に Git hub からダウンロードしてきたファイルの中 "E:\stable-diffusion-webui\webui-user.bat" (主はEドライブ直下に置いたのでこのようなPath になっています。)をダブルクリックします。最初は必要ライブラリのインストールなのでしばらく待つ必要があります。画面に動きがなくても、下図のように URL が出るまで触らずに気長に待ちましょう。
この URL が出たら これをコピーしてお好きなブラウザに貼り付けます。
Stable Diffusion text2image の使い方
するとこのような画面になると思います。
左上のドロップダウンを先ほどダウンロードしてきた ckpt ファイルを選びます(今回はwaifu diffusion ver-1.3 を選択しています)。

後はこの図のように入力を調整して、右上の Generate を押すと画像が生成されます。ちなみに画像は自動でセーブされて
E:\stable-diffusion-webui\outputs\txt2img-images
に出てきます。
ハイパーネットワーク Setting
一番上のタブから Settings タブに行き、以下の写真の部分を設定します。


最後に一番上の Apply Setting を押すのを忘れずに!

画像用意
ここでトレーニングさせたい画像を 20~30 枚ほど用意します。
それをどこかのフォルダに保存しておきます。今回はこんな感じに。

このフォルダの Path をコピーしておきましょう。今回主はStable_Diffusion_hypernet_img という画像とPreprocess専用のフォルダを E 直下に作りました。
E:\Stable_Diffusion_hypernet_img\ver01
ここに画像を保存しました。
続いて Preprocess あとの画像および text を保存するフォルダを以下のように作りました。
E:\Stable_Diffusion_hypernet_img\ver1_test_preprocess
この Path をコピーしてこのように配置します。これ後で使うので忘れずに。
(上に画像フォルダへの Path、下に Preprocess あとの画像および text を保存する Path)

そしたらこのようにチェックを入れて、右下の Preprocess を押してしばらく待ちましょう。
ハイパーネットワーク Training
まずは Training タブ内の Create hypernetwork タブに行き、ここの name に好きな名前を入れて右下の Create hypernetwork を押します。今回は適当にSD_ver1 としました

Preprocess
続いてこの Path の下にtextファイルを作ります。
名前は自由です(主はdandooru_filewords.txt)。
E:\stable-diffusion-webui\hypernetWork
そしたらその text ファイルを編集します。
[filewords]とだけ入力し、保存しましょう。そしたらその text ファイルの Path をコピーしておきましょう。
続いて先ほどの Stable Diffusion web UI に戻りTrainタブのTrainのこの画面の入力です。
Hypernetwork : ハイパーネットワーク Training 作った名前を選択
Learning rate : 10^(-6) ~ 10^(-7) オーダーの数字
Batch size : 1
Dataset Directory : 画像用意の最後にコピーした Path 。 主は今回はE:\Stable_Diffusion_hypernet_img\ver1_test_preprocess
Log directiry : 出力なのでお好きな場所をどうぞ。 主は今回は E:\stable-diffusion-webui\hypernetWork
Prompt template file : はつい先ほど Preprocess で作った text ファイルの Parh 主は今回はE:\stable-diffusion-webui\hypernetWork\dandooru_filewords.txt
Width : 512
Hight : 512
Max step : 10000くらいのほうがいい
Save an image… : セーブ間隔(いじらなくてもいい)
Save an copy … : セーブ間隔(いじらなくてもいい)
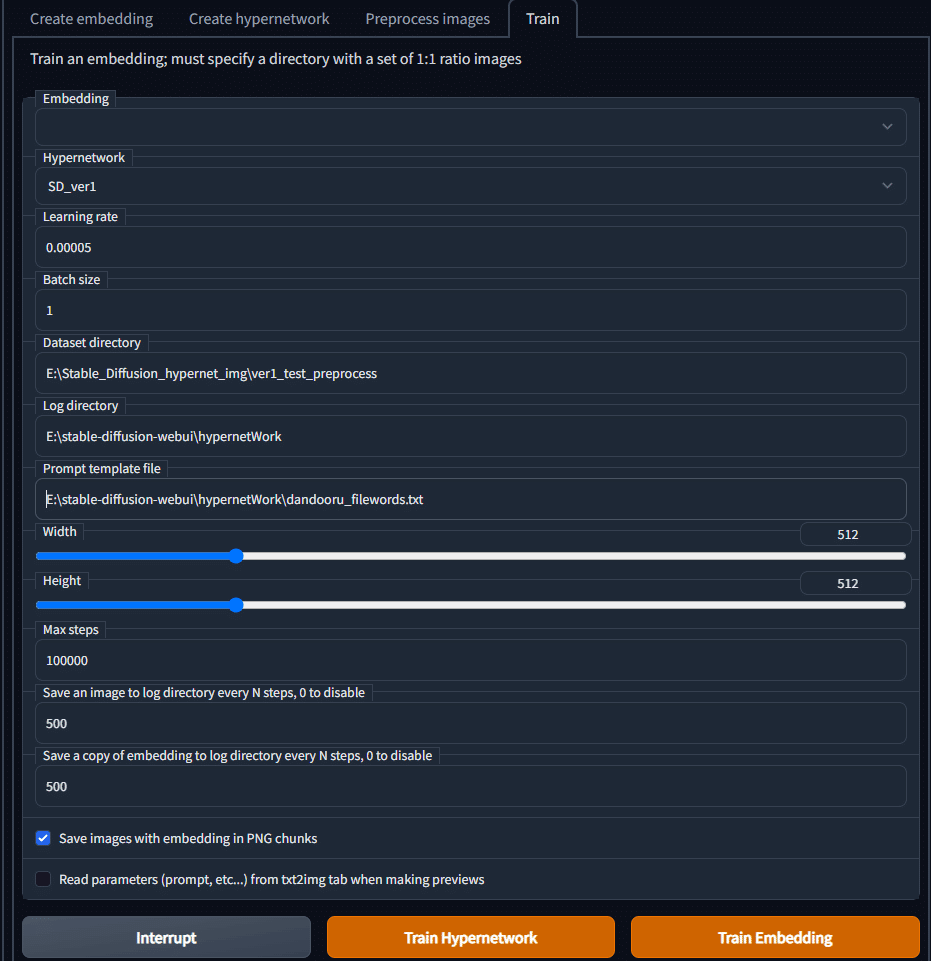
Trainng 開始
ここまでお疲れさまでした、いよいよこれで下のTrain Hypernetwork を押してトレーニング開始です!!
学習させたハイパーネットワークの使用
Prompt template file で入力した Path を見ると学習させたハイパーネットワークが出力されているので、それのいいやつを一つ選んで
E:\stable-diffusion-webui\models\hypernetworks
下にコピーします。そして Settings タブに行き真ん中下にこのような部分があるので、先ほどコピペしたHypernetworkを一つ選びます。このように設定し、そして最後に一番上の Apply Setting を押すのを忘れずに!
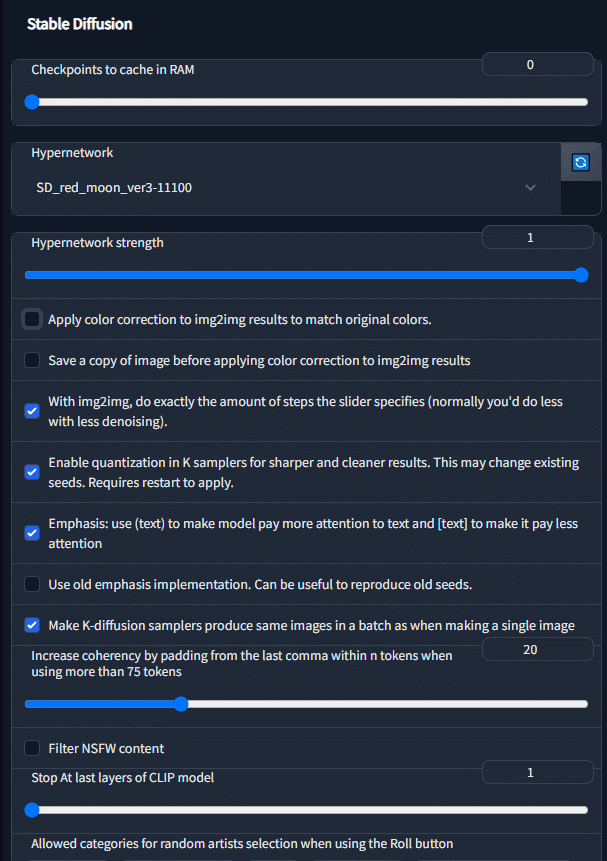
そしたら最後に text2image タブに戻り、プロンプトを打って Generate します、うまく学習されていると、少ない Prompt でも自分が初めに教えた画像のような雰囲気で生成してくれます。
まあなかなかうまくいかないもんです….
結果
例を載せておきます。今回の学習画像はこのように青と後ろ向きが多くなっています。

ちなみに主は30000stepほど訓練させてみて300ごとに結果を出してみてこうなりました。

まあ過学習(発散?)しましたが…とりあえず途中の11100あたりを選んで使ってみました。Prompt は "Agirl ,dress ,glass,moon"





うん、確かに雰囲気そんな感じだけど、ちょっと今回は失敗かもです。。。
でも姿勢とかは振り向く姿勢が多くてちょっとびっくり。
ちなみに後ろの方のStepを使って生成するとこんな感じ
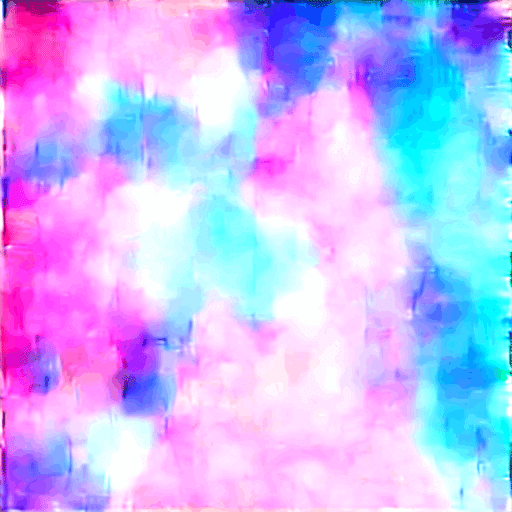

参考
今回の訓練なのですが、かなり成功してらっしゃる方がいて、ぜひこちらを合わせてお読みください!またDream booth もこちらの方のほうが主より断然熟練者です。ぜひ読んでみてください。
次回予告と宣伝
今回はここまでです。次回は Diffusion model です。これまで GAN の記事で 「GAN ってすごい!」感を出してきましたが、ついに最強の Diffusion model の登場です。最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加してお絵描きAIを探ってみてはいかがでしょう。(teftef)