
超解像について (その2・SRGAN と ESRGAN)

こんにちはこんばんは、teftef です。超解像その1の続きです。前回は、画像を拡大するアルゴリズム手法から始まり、SRCNN といった機械学習手法を使って超解像をするところまで書きました。今回はさらに SRCNN を応用した SRGAN , ESRGAN , Real-ESRGAN について書いていきます。GAN の概要は飛ばすので、もし読みたい方がいればこちらをご覧ください。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
※この記事は有料となっていますが、最後まで内容が読めます。
軽く復習
画像をアルゴリズム的に拡大する手法として最近傍法、バイリニア補間、バイキュビック補間があげられました。画像を拡大したときに、最近傍法ではジャギー (ギザギザ) が目立っているのに対し、バイキュビック補間では計算量が多いものの、ジャギーがなくなっていました。 SRCNN ではさらにバイキュビック補間でできない細部の補間をすることができました。
しかし SRCNN ではネットワークが単純であるため、表現力が足りないという欠点が残っていました。また画像を見てみると輪郭線がぼやけていたり、小さい領域が消えてしまったりしているのがわかります。

SRGAN
SRCNN のようにネットワークが浅いと、十分な学習能力を持たず、複雑な特徴や関数を表現にするのに限界があります。かといってネットワークを深くす (レイヤーを増やすなど) れば良いというわけでもなく、深くしすぎると今度は勾配損失や過学習の原因になります。
ResNet
そこで、 ResNet のように情報の一部をネットワークの深い層に伝えてやることで、緩和してやることができます。そのため SRCNN のネットワークを ResNet に置き換えた改良版である SRResNet を用いた手法が登場しました。

損失関数
また、SRCNN では損失関数に MSE (平均二乗誤差) を用いています。これはとてもシンプルなのですが、平均二乗誤差を最小化することは画像の高周波成分 (エッジなど) の情報を過度に削ぎ落としてしまい、ディテールの再現がうまくいかなくなります (これは正則化が多すぎるという理由もある)。そのため、出力された画像は少しぼやけていることがわかります。


そこで損失関数に MSE でなく、 Content Loss (コンテンツ損失) と Adversarial Loss (敵対的損失) を追加します。( 論文中では Perceptual Loss (知覚損失) ≒ Content Loss (コンテンツ損失) + Adversarial Loss (敵対的損失) という意味で使っている思う、非常にわかりにくい )
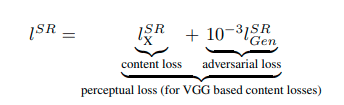
Content Loss (コンテンツ損失) では VGG ネットワークを用いて アップサンプリングで生成された画像と教師画像 (高解像度な元画像) との特徴表現間の差を測定しています。この損失は人間の視覚的感覚と非常に近く、差が小さいほど、よく復元されていることを表します。 = VGG Loss
Adversarial Loss (敵対的損失) はこちらの記事で解説しているので省きますが、大雑把に GAN の損失です。
ネットワーク

SRGAN は ResNet をベースにした Gennerator を用いています。これによって、過度な情報損失を抑えつつ、過学習を防ぎます。 Discriminator には複数の畳み込み層と 活性化関数に Leky ReLU が使われています(多分、勾配喪失防止のためだと思う)。
結果
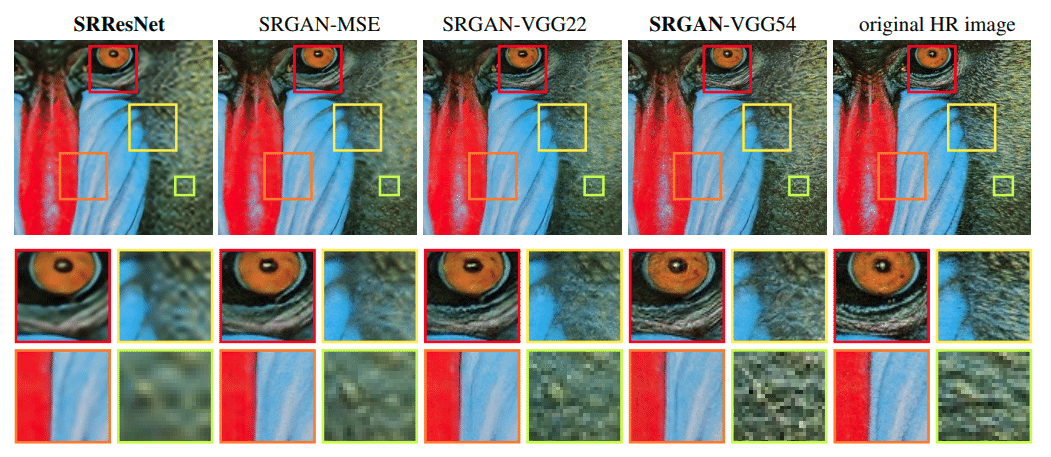
SRGAN では、高周波成分をうまく表現することができ、ぼやけが非常に少なく、元画像のような緻密な表現がある程度できていることがわかります。 SRResNet では、定量評価で SRGAN を上回ったものの、画像がぼやけていることがわかります。

ESRGAN
SRGAN を用いた超解像は従来の CNN を用いた手法と違い、高周波成分を再現することができました。しかし、まだまだ Grand Truth (元画像) とは程遠い結果となっています。

そこで、今回は以下の 4 つの改良を行います。
ネットワークアーキテクチャ (BN 層の除去)
ESRGAN では GAN の Generator 部分のネットワークに改良を加えて、下のような 「Residual-in-Residual Dense Block(RRDB)」というより深いネットワークを採用しています。RRDBは残差ブロックの中に残差接続の構造を持っており、異なるレベルでの残差学習をすることができます。(多分 U-net みたいな構造に近くなるんだと思う。)

さらに、Batch Normalization(BN)層を取り除くことで汎化性能向上と計算量が削減されます。(ネットワークが深い場合に BN 層がアーティファクトをもたらす可能性が高くなることが経験的にわかっているらしい。)

Relativistic Discriminator
従来手法の SRGAN の Discriminator はただ入力画像が本物かどうかの確率を推定するだけでしたが、Relativistic GANのアプローチを採用することで、新しいDiscriminatorは、本物の画像が偽物の画像よりもどれだけ現実的であるかの確率を予測するようになりました。本物の画像と偽物の画像の両方の情報を利用して、よりリアリスティックな評価を行います。

また、Discriminator と Generator の損失関数も実画像と生成された画像の両方の情報に基づいて設定されているので、学習時に生成された画像と実画像の両方からの勾配を利用することができるようになりました。(従来は生成画像からのフィードバックのみ利用可能)
損失関数 (Perceptual loss)
SRGANの知覚損失は特徴量が活性化層に入力されてから計算されていましたが、ESRGAN では活性化層の前の特徴を使用します。
また、従来の VGG を用いた知覚損失だけでなく、より超解像に適した知覚損失として、材料認識に焦点を当ててファインチューニングされた VGG ネットワークを用いて特徴量を抽出し、損失を計算しています。これはテクスチャに焦点を当てていて、画像がぼやてしまうことに対して効果があると考えられます。


活性前は活性化後に比べてぼやけがないことがわかる
Network Interpolation
GAN ベースの手法で超解像された画像には不快なノイズが乗ることがあります (高周波成分に乗る) 。そこで、知覚品質を維持するために、「Network Interpolation」を用います。まず、PSNR 指向 (従来手法は PSNR 重視) のネットワーク G_PSNR を学習します。その後、ファインチューンによってによってGANベースのネットワーク を取得します。

これら二つのネットワークを補間することによって GAN ベースの重みの割合を少し減らし、PSNR の重みの割合を増やしてあげることで、知覚的品質と忠実度のバランスを連続的に調整できます。直感的には、GAN ベースで発生してしまうアーティファクトに PSNR のぼやけを少し入れて改善している感じです。

ひだりに行くほど GAN 指向になる、つまり高周波成分にノイズがのる
その他
そのほか ablation は以下の通り、一番右が提案手法です

参考文献
次回予告
SRGAN と ESRGAN では高周波成分をしっかり再構成できるように改善された手法なのですが、そもそも使っているデータセットの画像って高品質なのでしょうか?というのが次の記事で書こうとしている Real-ESRGAN です。
最後に
最後まで読んでいただきありがとうございました。アップスケーリングの基本から CNN を用いた超解像までの大まかな流れを書きました。次回はこの Real-ESRGAN , DiffBir についてです。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(4,000 字,teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
※注意 : 支援してくださる方へ
※注意 :ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
¥ 500
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?