
GlyphControl: 文字を描く ControlNet

こんにちはこんばんは、teftef です。今回は GlyphControl です。DeepFloyd IF は Imagen をベースにしたカスケード式モデルであり、Text Encoder に大規模自然言語モデル(LLM)に使われる T5 モデルを使用していて文字が出力できる Generative AI として大きな話題となりました。しかし T5 モデルは非常に大きなモデルでありパラメータ数が 30 B (300億) ある非常に大きいモデルになっています。今回、紹介する GlyphControl は文字が出力できる Generative AI であり、ControlNet をベースにしており、Text Encoder に CLIP を使用することでパラメータ数を抑え、CLIP スコアと OCR accuracy において DeepFloyd IF より高い性能を出しました。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
論文
今回参考にさせていただいた論文はこちら。
CLIPの限界
DiffusionModel はここ数年で驚くほど高品質 (あんまり品質という言葉を使いたくない) な画像を生成することができるようになりました。私たちが使っているような StableDiffusion はフォトリアリスティックの画像からアニメ調の美少女の画像まで幅広い範囲で生成することができます。しかし、ポスターや漫画などのように文字を含む画像を生成しようとするとどうしても可読性のある文字を生成することが難しくなっています。これは TextEncoder に使用される CLIP ではプロンプト内のスペル情報をCLIPテキスト埋め込みでは正確に表現できないとことに起因します。
CLIP (Contrastive Language-Image Pretraining) は Text と画像の間の意味的な関連性を学習しています(そのように作られている)。しかし、その設計上、CLIPはテキスト表現を生成する際に、個々の文字のレベルでの詳細な情報(つまり「スペル」情報)を十分に取り扱うことが難しいことがあげられます。これは、CLIPが主に単語やフレーズのレベルでテキストと画像の関連性を捉えることに重点を置いているためです。
そこで登場したのが DeepFloyd IF や e-Diff-I のような大規模自然言語モデル (LLM) に使われる T5 モデルを Text Encoder に使用したモデルです。
DeepFloyd IF
DeepFloyd IF は Imagen という手法がベースになっており、大規模自然言語モデル(LLM)に使われる T5 モデルを Text Encoder に使用しています。これによってモデルは個々の文字のレベルでの詳細な情報(つまり「スペル」情報)を持つことができ、可読性のある文字を生成することができました。しかし、T5 モデルは非常に大きなモデルであり、時間と計算機資源を大量に消費します。また、生成された画像には文字の欠落などが存在し、単にテキストを使った入力プロンプトに依存するだけでは、正確な視覚的テキストレンダリングには十分ではないことがわかります。
本論文の概要
この論文ではこの問題に対処するために、OCR を用いて画像にかかれた文字、Glyph 画像 (Glyph は絵文字、画像内の文字という意味です。以下 Glyph 画像を"Text の形状情報" とも書きます。) を文字に起こして、ControlNetをベースに条件付けします。それを Diffusion Model が整合性のある、形の整った可読性のあるテキストを生成するようにします。具体的には以下の3つを実現します。
モデルのパラメータ数を3倍以上削減しながら、OCR 精度と CLIP スコアの点で DeepFloyd IF と Stable Diffusion を超える Glyph 条件付きテキスト-画像生成モデルを提案する。GlyphControl
LAION-2B-en をフィルタリングし、最新の OCR システムを用いてビジュアルテキストコンテンツが豊富な画像を選択することで、LAION-Glyphというビジュアルテキスト生成ベンチマークを紹介します。
ユーザが生成されたビジュアルテキストの内容、位置、サイズを制御できるようにしました。
Stable Diffusion v2.0
StableDiffusion v2.0 は LDMs の一種であり、512×512ピクセルの解像度を持つ同じデータセットで継続的にモデルの学習を行うことで、より詳細で視覚に訴える画像を生成することができます。この研究では Stable Diffsuion v2.0 をベースモデルとして採用し、LAION 5B データセットの内、美的スコアが4.5以上のサブセットを対象に、解像度 256×256 で550kステップを実施しました。
OCR (Optical Character Recognition)
Optical Character Recognition(OCR)は画像の中の手書きまたは印刷された文字 (Glyph) をText として読み取ることができるようにする文字起こし機能です。この技術は、スキャンしたドキュメントや写真、手書きのメモなどからテキストを抽出し、デジタルデータに変換するこができます。OCR は画像内の文字領域を検出し、その各文字を認識します。最後にその文字を修正を経て正しいスペルや文法に変換され Text に変換されます。最近のスマホには OCR 機能がついていて、pdf などをにカメラをかざすと文字起こししてくれたりします。
ControlNet
今回は、ネットワークアーキテクチャのみを書きます。こちらに分かり易い記事を載せます。
ControlNet のアーキテクチャは大まかにこのようになっています。
簡単に説明すると DiffusionModel のデノイズ過程において、Prompt による condition (条件付け) だけでなく OpenPose や Depth や 線画などをControlNet によって処理された後に条件付けとして Unet Decoder にcondition として入力しています。

GlyphControlNet
GlyphControl フレームワークは、以下の要素で構成されています。
VAE : 入力画像の潜在ベクトルを抽出するVAE Encoder、潜在ベクトルから出力画像を再構築する画像VAE Decoder。
Text Encoder : 入力テキストをテキスト埋め込みに変換する。OpenAI のCLIP を使用しています。
U-Net : ノイズ除去拡散処理を行うU-Net Encoder,Decoder。
OCR Engine : 与えられた画像からテキスト情報を検出する。
Glyph Render : 検出されたテキストをホワイトボード画像の対応する位置にレンダリングする。
Glyph ControlNet : Glyph Render によってレンダリングされた Glyph 画像(Text の形状情報)を処理して条件グリフ情報をエンコードする。
事前準備
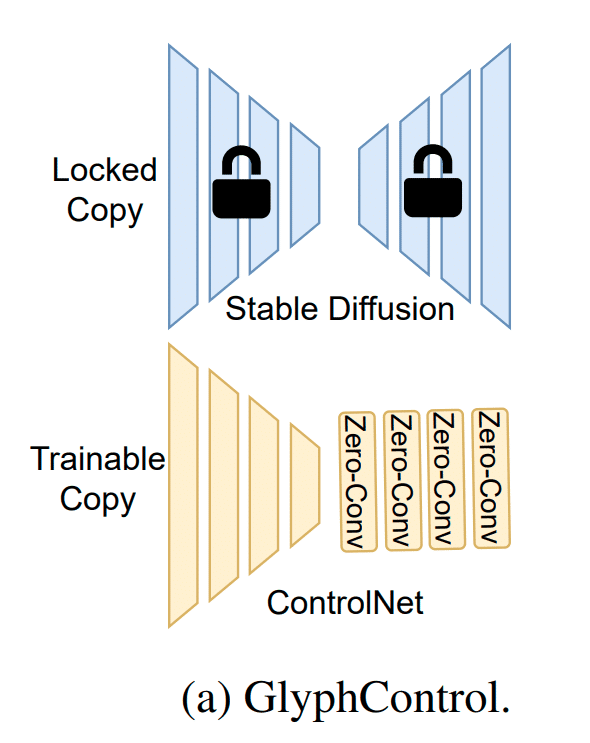
まずは事前に学習した StableDiffusion v2.0 を Freez します。これは学習に使用しません。ControlNet のみを学習させます。
LAION-Glyph データセット
今回は LAION-5B のサブセットである LAION-2B-e データセットから、美的スコア予測モデルを使用して、美的スコアが 4.5 以上の画像をフィルタリングし、その中でもテキスト内容が豊富なデータを PP-OCR エンジンを選出しました。その結果、詳細な OCR 情報と形の整った、正確なキャプションを含む高品質な LAION-Glyph データセット、合計 1000 万画像を作成しました。あとでも書きますが、このデータセットの画像枚数を調整して
・LAION-Glyph-100K
・LAION-Glyph-1M
・LAION-Glyph-10M
の 3 つのデータセットも用意しておきます。
学習フェーズ

このように ControlNet を少し変えた形となっています。入力画像 x はVAEエンコーダによる符号化を受け、潜在的な埋め込み z0 を作成します。続いてこの z0 に拡散処理を施し、ノイズを付与し、zt を作成します。
続いて入力画像 x から画像グリフ情報を取り込むために、Glyph Render を用いたレンダリングされた Glyph 画像 (Text の形状情報) をレンダリング (g) して ControlNet (ブランチ)に送り込むことで、Glyph 入力条件という概念を導入しています。また入力画像 x に対応する Prompt を CLIP Text Encoder に入力し、Text Embedding を作成します。
最後に zt の逆拡散過程において先ほど作成した Text Embedding を Unet に条件付け (condition) として入力すると同時に Glyph ControlNet にも条件付け (condition) として入力します。これによってノイズ項 ε(zt, t) が生成され ます。
推論フェーズ

まず Prompt に加えて、Glyph 画像を作成するための Text を入力します。
その後、ガウスノイズからノイズ潜在埋め込み zT をサンプリングし、DDIM方式を採用してノイズ除去処理を行い、ノイズ除去された潜在埋め込み z0 が生成されます。最後に z0 を VAE Decoder に送り、最終的な出力画像 y を生成します。
使用例
少しわかりにくいので例を挙げます。
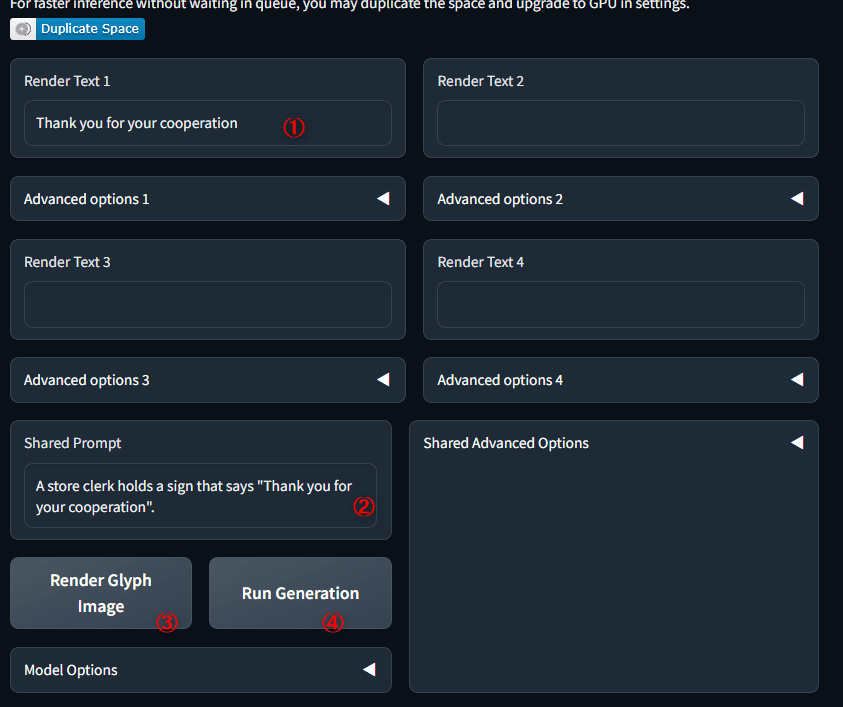
① : Render Text として生成したい Text を入力します。今回は「Thank you for your cooperation」(Advanced option から位置や大きさも指定できます。)
② : Prompt として「A store clerk holds a sign that says "Thank you for your cooperation".」を入力します。
③ : まずは Glyph 画像の生成です。すると下図の左上画像のようにレンダリングされ。。
④ : 最後に画像生成ボタンを押して完了です。

結果
文字の扱い
GlyphControl は 単語だけでなく、複数の単語からなるフレーズやセンテンスを指定することができます。
行数を調整することで、複数の行に単語を割り当てることが可能です。
フォントサイズ、回転、位置を指定することができます。

評価指標 (OCR accuracy , CLIP Score)
OCR accuracy
今回、生成された画像を評価するために OCR accuracy というものを用意しています。 OCR accuracy は生成された画像の OCR の認識結果と Prompt の真値との間の単語レベルの一致を測定します。 OCR accuracy では生成された文字が大文字か小文字化の区別を考慮した場合 (Acc) と考慮しない場合 (Accˆ) を用意します。(DeepFloyd はプロンプト内の単語が、大文字で生成される傾向があるため)
CLIP Score
CLIP Score はおなじみのテキストと画像の間の意味的な関連性を評価するために使用されます。生成された画像が与えられた Prompt にどれだけ一致しているかを評価するために、CLIP スコアが使用されています。
平均レーベンシュタイン距離(LD)
複数の文字列ペア間の距離、低ければ低いほどいい。詳しくは省きます。
ベンチマーク
評価の方法として2 つのテストベンチマークを用意しました。
SimpleBench:単純なベンチマーク。プロンプトの形式は同じで、「A sign that says "<word>"」という形式を維持します。
CreativeBench:GlyphDrawから適応したクリエイティブなベンチマーク。元のベンチマークの多様な英語バージョンの Prompt を採用し、その中の単語を置き換えます。例えば、プロンプトは「Little panda holding a sign that says "<word>".’ or ’A photographer wears a t-shirt with the word "<word>" printed on it’」のような複雑なものになっています。
定量評価
DeepFloyd と GlyphControl の両手法を比較します。DeepFloyd は LAION 1.2B データセットを用いて学習され、Text Encoder として T5-XXL を用いて学習・テストされています (表の上部)。
GlyphControl は LAION-Glyph データセットのデータ数を変えた データセットを用いて、Text Encoder として CLIP を用いて学習させました。
・LAION-Glyph-100K
・LAION-Glyph-1M
・LAION-Glyph-10M

LD は平均レーベンシュタイン距離
結果として表の左部の赤枠内で、GlyphControl は DeepFloyd と比べて少ないパラメータ (約半分) を用いて、どのスコアも上回っていることがわかりました。(右部の黄緑枠)
また GlyphControl 内ではデータセットが大きくなればなるほど結果が良くなっています。

続いて CLIP Score では最右部の LAION-Glyph-10M を用いて学習させた GlyphControl が最も高いスコアとなりました。(正直、画質に関してはあんまり大きく変わらない)
定性評価


このように GlyphControl は DeepFloyd IF に比べて(気持ち)文字がよく出ていることがわかります。しかし GlyphControl は文字の位置を指定できる点で大きな差別化となります。
Fine-Tune
GlyphControl を学習させたときに Unet を Freez しましたが、Fine-Tuneを用いて再学習することで精度が上がります。

下が Fine-Tune した結果


GlyphControl を使用する
HuggingFace のスペースで試すことができます。使い方は上で書きました。
結論
GlyphControl はビジュアルテキスト生成(画像上の文字生成)が目標であり、Glyph 画像 ("Text の形状情報") をエンコードする「glyph ControlNet」の利用したことで、 OCR(光学的文字認識)精度において DeepFloyd を上回る結果となりました。正直、画像の品質はそこまで変わっていないですが、なんといっても、文字の位置を指定できる点で大きな差別化となります。
参考文献
最後に
最後まで読んでいただきありがとうございました。今回はマインクラフトを AI がプレイするという関連で 3 本の論文をまとめてみました。
最後に少し宣伝です。主のteftefが運営を行っている discord サーバーを載せます。このサーバーでは Midjourney や Stble Diffusion のプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(6800字、teftef)
※注意 : 支援してくださる方へ
※注意 : ここから先は何も内容がありません。しかし、この記事をお読みいただき、良かったと感じていただけたのであれば、この記事と開発の支援お願いいたします!
ここから先は
Amazonギフトカード5,000円分が当たる
この記事が気に入ったらチップで応援してみませんか?