
ComfyUI : ノードベース WebUI 導入&使い方ガイド

こんにちはこんばんは、teftef です。今回は少し変わった Stable Diffusion WebUI の紹介と使い方です。いつもよく目にする Stable Diffusion WebUI とは違い、ノードベースでモデル、VAE、CLIP を制御することができます。これによって、簡単に VAE のみを変更したり、Text Encoder を変更することができます。blender のジオメトリノードを使用している方などには見やすい UI となっていると思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。 (2023/07/09 変更あり)
python と Git のインストール
今回こちらは多くは解説しません。python のバージョンは 3.10.xx としましょう。python 3.8.xx だとxformers の環境がビルドできない。そして CudaTool Kit をインストールするのを忘れずに。
フォルダの切り替え
まずローカル環境の python のバージョンを確認しましょう。左下の Windows の検索欄から cmd と入力し、コマンドプロンプトを立ち上げましょう。続いて好きな場所まで cd コマンドで移動しましょう。主は E ドライブ直下に置きたかったので
C:\Users\ユーザー名> E:として current directory を E ドライブに切り替えました。ここの作業はなくても大丈夫です。
Git clone
ディレクトリを移動したら、
git clone https://github.com/comfyanonymous/ComfyUI.gitで repository をクローンしてきます(Zip ダウンロードして E 直下に回答してもいい)
こんな感じになります。
仮想環境作成
python -V
python -m venv venv
venv\Scripts\activate
cd ComfyUI 1行目で python のバージョンを確認して、3.10. xx であることを確認してください。
続いて 2 行目で仮想環境を作りましょう。そうすると venv というフォルダができていることがわかります。
続いて 3 行目を実行して仮想環境を activate しましょう。
最後にcd で ComfyUI の中に入っていきます。
pip のアップデート
まずは pip のアップデートをしておきましょう。(最新の xformers のため)
pip install --upgrade pippytorchインストール
今一度、自分がいる directory の場所が ComfyUI の下かどうかを確認しましょう。
続いて各種モジュールを入れていきます。まずは Pytorch から入れましょう。これがないと xformers が入らないので…
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu117xformers インストール (この手法は古い手法です、少し下の xformers のインストール手順をお読みください)
(2023/07/09 時点で非推奨)
こちらから xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl をダウンロードして、 E/ComfyUI の下に入れて、
pip install xformers-0.0.14.dev0-cp310-cp310-win_amd64.whlこれでインストールできます。
2023/07/09 変更 xformers (推奨)
続いて、xformers のインストールです。
pip install xformers -U最後に各種モジュールをインストールするように
pip install -r requirements.txtこれでセットアップ完了です。
使用法
Model 準備
まず、ComfyUI/models の中に
checkpoint ファイル
Config ファイル(yml のこと)
VAE ファイル (拡張子が ckpt しか読まれないので注意)
を入れましょう。初めからデフォルトでいくつか入っているのは消さないように

起動
使う時は、先ほど建てた仮想環境内にいることと自分がいる directory の場所が ComfyUI の下であることを確認して
python main.pyで URL がこのように表示されるのでこれをコピーしてブラウザで開きましょう。

このような画面が開きます。
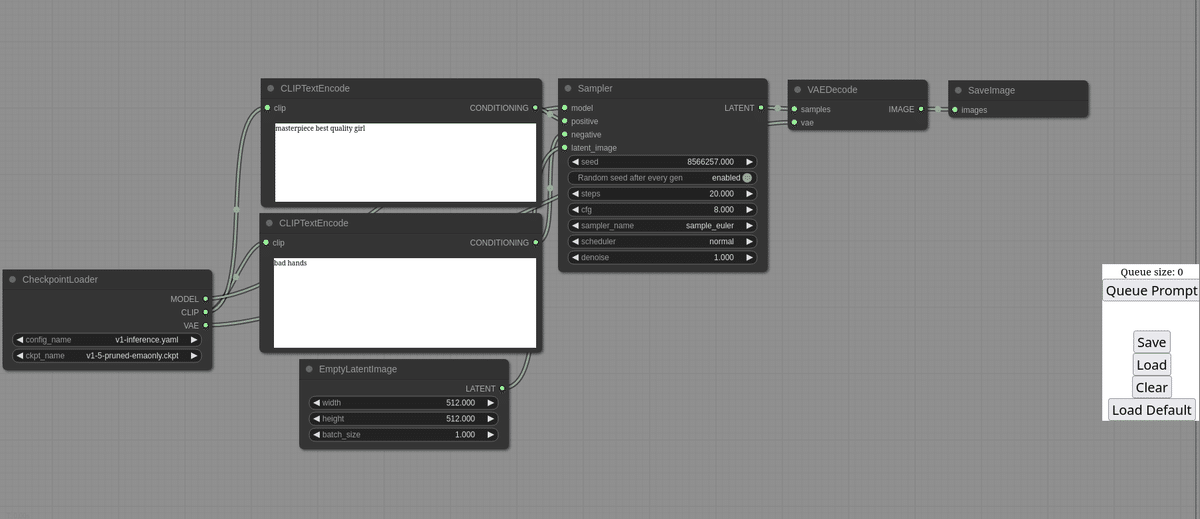
右クリックするとノード選択が現れて、ノードを追加したり消したりできます。ノードは
Add Node/loaders/CheckpointLoader
Add Node/loaders/VAELoader
Add Node/sampling/Ksampler
Add Node/conditioning/CLIPTextEncoder
Add Node/conditioning/ConditioningSetArea
Add Node/conditioning/ConditioningCombine
Add Node/latent/VAEDecode
Add Node/latent/VAEEncode
Add Node/latent/EmptyLatentImage
Add Node/sd/LatentUpscale
Add Node/image/LoadImage
Add Node/image/SaveImage
となっています。それぞれのノードの解説を書いていきます。
ノード (2023/07/09 変更点あり)
何もないところで右クリックをするとノード選択が出てきます。またノードに右クリックすると消したり複製したり選択できます。
CheckpointLoader
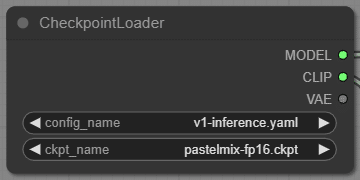
Model (ckpt ファイル)とそれに対応する config を選択します。config はModel (ckpt ファイル)に依存してベースが Stable Diffusion 1.0 ベースなのか、 2.0 ベースなのかを確かめて、config を選択しましょう。ここで一致しないとエラー吐きます。 config directory の中には config (yaml ファイル)を入れておいき、選択します。
VAELoader
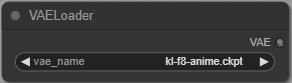
VAE を選択します。VAE は拡張子が ckpt しか読まないので注意です。
Ksampler

Seed , Steps , cfg_Scale , sampler , scheduler , denoise 方式 を選択します。
Random seed after every gen を enable にすると Random Seed となります。
CLIPTextEncoder

Prompt もしくは Negative Prompt を入れます。
ConditioningSetArea
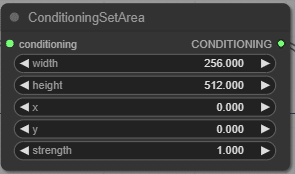
x,y を起点として、縦横それぞれの範囲を指定します。また重み(strength)も指定します。
ConditioningCombine
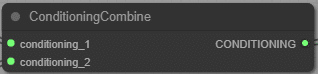
Condition を足す。
VAEDecode
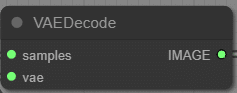
Latent (Unetから出たもの) を VAE に入れて画像として出力。
VAEEncode

VAE を使って画像を Latent にエンコード、 Image2Image で使用する。
EmptyLatentImage
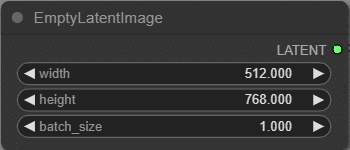
空の画像(?)の準備、画像サイズの指定に使う
LatentUpscale
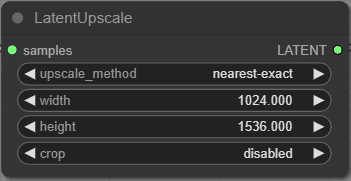
アップスケールに使う
LoadImage
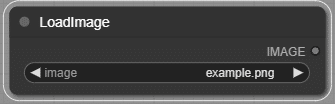
画像をロード、 Image2Image で使用する。
SaveImage
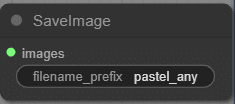
画像を保存、好きな名前を指定できる。
使用例
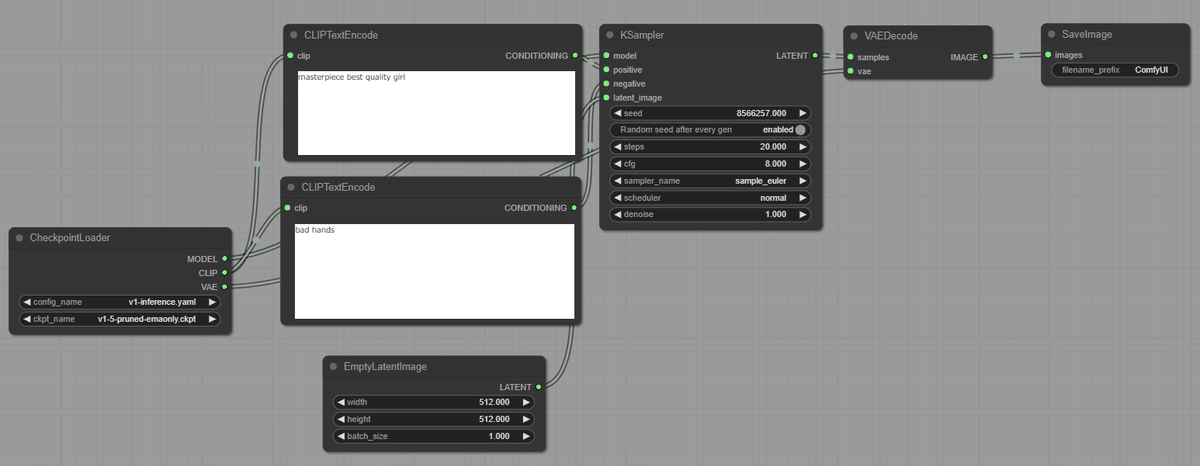
画像生成
普通に1枚の画像を生成します。デフォルト値がこれです。
VAE を変更して画像生成
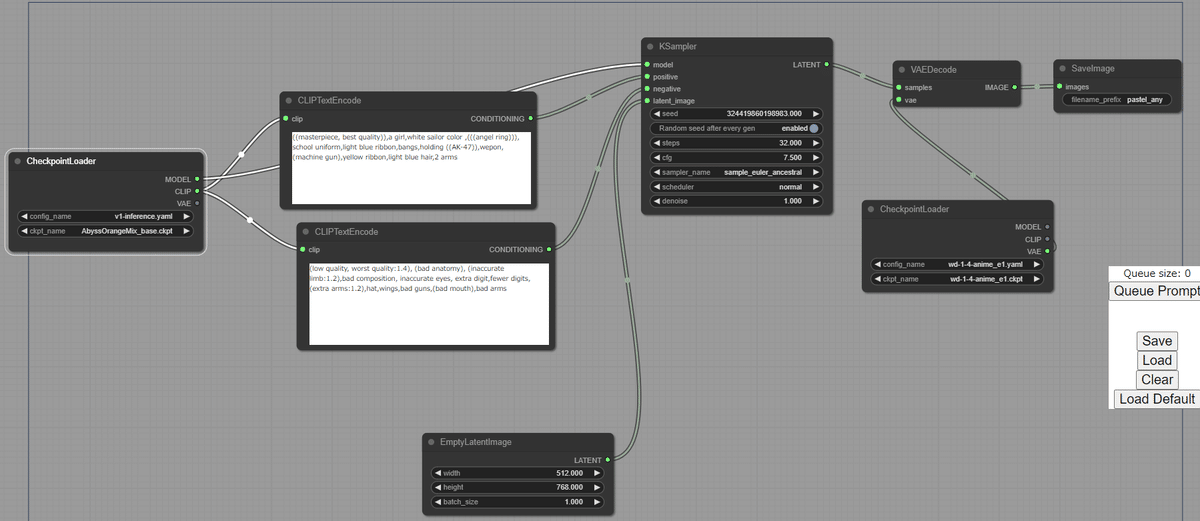
こんな感じで変更できます。

AE : counterv2

VAE : SD1.5
Prompt , Negative Prompt を別のモデルから使用
別々の CLIP を使います。
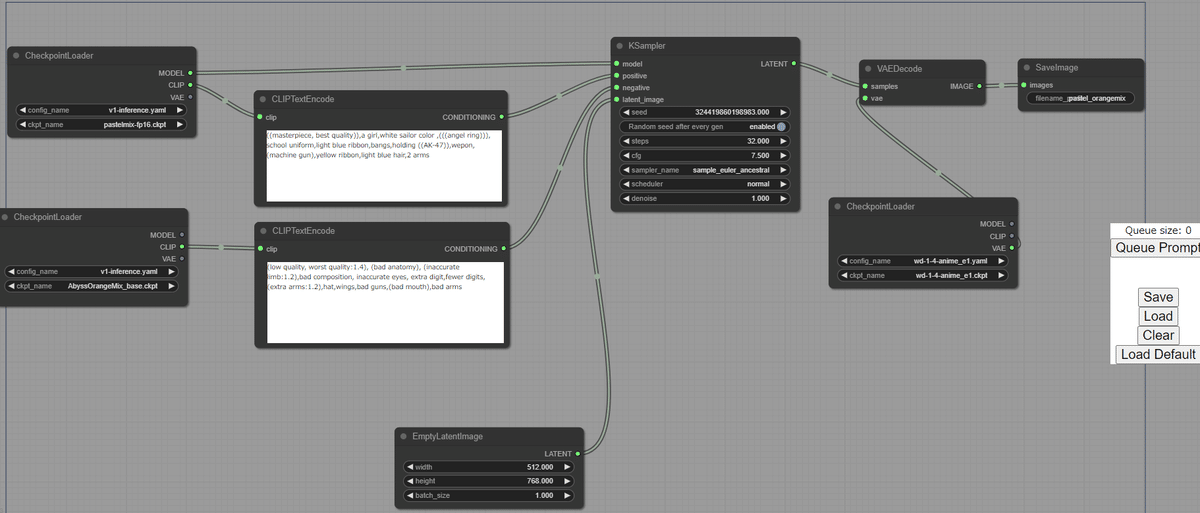
Model : pastel_mix
Prompt : pastel_mix
Negative Prompt : AbyssOrangeMix
VAE : WD1.4

Prompt : pastel_mix
Negative Prompt : AbyssOrangeMix
VAE : WD1.4
分けて生成
今回は左右分けバージョン、画質は下がるので 1024×1024 で生成したほうがいいかも



分けて、境目をなくす生成
Strength をうまく調整していい感じにつながっているようにしたい
もう少し練る必要がありそうです。



Image2Image
画像から画像へ変換



これらは基本的なノード構成なので、まだまだいろいろあります。
以下の Google Drive に共有します。この中の json ファイルをComfyUI
の下に置くと、このノード構成を右側の Load ボタンから持ってこれます。
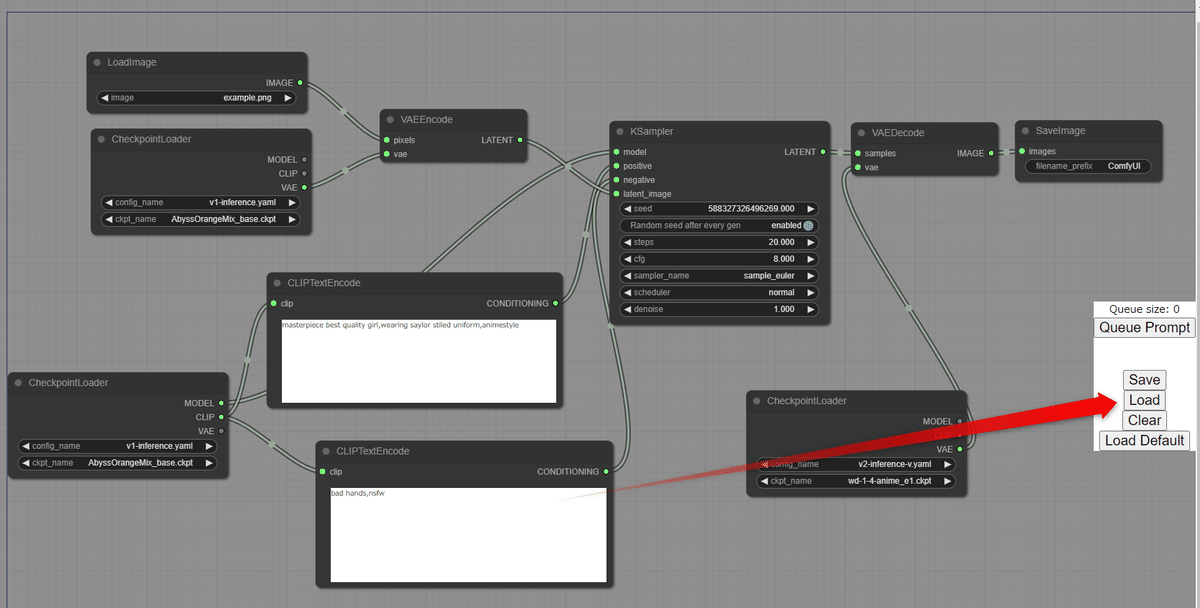
https://drive.google.com/file/d/1-_hCgrOl-bwrKkjCzxPzW2K84vMyZQE0/view?usp=sharing
次回予告と宣伝
今回は ComfyUI の実装してみた結果をまとめてみました。次回の内容はVAE や CLIP を変更した際にどのような画像が出るのか、Model を組み合わせた時に出てくる画像などについてまとめたいと思います。
今回ちらっと出てきましたが、左右分けバージョンをもっと精度よく生成できる Colab と説明はこちら
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!
この記事が気に入ったらサポートをしてみませんか?