
fMRI から画像を生成する話

こんにちはこんばんは、teftef です。今回は大阪大学から出た fMRI 画像から Stable Diffusion を用いて画像生成する論文をベースに Brain 2 Image について書いていこうと思います。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。また、この記事を作成するにあたり、GPT-4 による校正、修正が含まれています。
それでは行きます。
初めに
今回のコンセプトは、人間の脳で処理されていることを間接的に取り出し、それを画像として表現させるということです。私たちが使っている Stable Diffusion や Midjourney などの Text2Image では自然言語をベースにバラエティ豊かな画像を生成することができます。最近では ControlNet や Latent 2 shot などを用いて姿勢や構造を制御するといった応用技術が用いられています。
しかし、それでも私たちが頭の中に思い浮かんだ画像を実際に出力させるためには、脳内のイメージを Prompt と呼ばれれる自然言語に変換し、画像生成をします。これは明らかに情報量が減ったり、誤差が生じることになります。そのため、Textual Inversion のような手法はこれを解決するために画像をベースに Inversion(画像に対応する潜在表現を探索) を行い、その画像を表現します。このように理想としては途中の自然言語や潜在表現をできるだけ会することなく、頭の中のイメージをそのまま取り出したいものです。

そこで、考えられるのが、脳に電極を刺してそれを元に画像生成すれば良いというマッドサイエンスじみたものなのですが、さすがに倫理的にアウトなので、何かほかの手法が必要です。そこで、脳波や fMRI を元にして画像生成するということが研究されています。
軽く歴史
この研究では視覚情報と脳活動との関連性を理解することを目的にされています。被験者が見ている視覚情報を脳波 (EEG) や fMRI 画像として取り出し、視覚的な画像を再構成する方法が研究されてきました。特に EEG より空間分解能が高い fMRI を用いた再構成が研究されました。 やがて機械学習、NN、ディープラーニングの発展により、生成敵対的ネットワーク(GAN)や変分オートエンコーダー(VAE)を用いた、より高度な画像生成が可能となり、さらに高精度な再構成が可能になりました。今回の論文では fMRI 画像を入力として、拡散モデル (LDM) を用いた再構成をします。
fMRI とは
fMRI(functional Magnetic Resonance Imaging)は脳内の血流や酸素濃度の変化を検出することで神経細胞の活発性の変化を調べます。というのも活動が活発な脳の分野は酸素を欲するため、酸素濃度が高くまります。この変化を図ることで、例えば言語を話しているときの脳の活発な部位 (言語中枢) の位置を知ることができたり、話す言語によってどこの部分が活発に使われているのかがわかります。
fMRI 画像から学ぶ
脳は、外界からの情報を処理し、それに応じて神経活動が変化するため、異なる画像を見た場合、つまり刺激が異なる場合には、脳内の神経活動にも違いが生じます。fMRIは、そのような脳内の神経活動の変化を検出することができます。例えば、ある人に赤い色の画像を見せた場合と青い色の画像を見せた場合で、脳内の神経活動が異なるため、fMRI画像も異なるものが得られる可能性があります。
画像を見た時の fMRI 画像を調べ、どのようことが起こっているのかという研究は様々されてきました。なる画像に対する脳の反応を調べることで、視覚処理に関連する脳の領域や回路を特定することができたり、認知機能(例えば、顔認識や物体認識)の仕組みを理解することができたりします。これを研究することで、リハビリやメンタルヘルスなどの医療分野に効果があると共に、人間の脳を解析することができ、BMI (Brain Machin Interface) などの応用に役に立ちます。
論文
今回使用した論文はこちら.
https://www.biorxiv.org/content/10.1101/2022.11.18.517004v3
今回の論文の目的
先ほど説明したように、画像を見た時の脳の領域の活性を元に、生成モデルを使って画像を生成することを目的にします。これまでは GAN などによるfMRI to Image 画研究されてきましたが、潜在拡散モデル (LDM) による高品質な画像生成の能力を用いることでより高精度な再構成ができるようになりました。また LDM のコンポーネント、画像の潜在ベクトル、condition、 U-Net などが脳のどのようなものと関連しているか調べることが目的となっています。以上一言でまとめると、人間の脳活動から画像を再構築するための有望な方法を提案し、拡散モデルを理解するための研究です。
既存手法
fMRI 画像から測定される脳活動画像から画像を再構築は様々な研究がありました。(さっきいいました)。しかし、fMRI 画像の取得には多大な時間と労力が必要であり、個人差が大きいため、利用可能なデータは限られてきます。
最近では敵対的生成ネットワーク (GAN) を用いたり、セマンティックセグメンテーションを用いて領域を明確にすることで画像生成の性能を上げています。例えば Reconstructing Perceptive Images from Brain Activity by Shape-Semantic GAN という論文には画像を形の情報と意味的な情報を分けて学習することで高精度な再構成をしています。しかし、残念ながらこの手法によって生成された画像はお世辞にも高精度とは言えません。

またこれらのモデルを作成するためには 0からモデルを学習する or ファインチューニングする必要があります、しかしこれは大量のデータ数が必要であり、 fMRI 画像が少ないという問題とバッティングします。
提案手法
これに対し、今回は拡散モデル (DM) を用いた画像の再構成を試みます。また今回はデータエンコーダー以外を学習をすることがないため、大量の fMRI データを必要としません。また拡散モデルの各特徴量 (画像 X の潜在ベクトル、条件付け入力 C、ノイズ除去 U-Net の要素など) が fMRI と比較することによってどのような関連性を持つかを調べ、生物学的な解釈をすることもできます。
デコード
fMRI 画像を元に画像を生成する方法としては以下の 3 つがあげられます。全ての場合において fMRI 画像を LDM の要素にマッピングするような線形モデルを構築しています。要するに fMRI 画像から対応する 画像 X の潜在ベクトル、条件付け入力 C、ノイズ除去 U-Net の要素にマッピングするということです。
(i) では 提示された画像 X の潜在表現 z を fMRI 信号から予測し、次に、z はオートエンコーダーのデコーダーによって処理され、320 × 320 の粗いデコード画像 X_z を生成し、512 × 512 にリサイズします。
(ii) では拡散プロセスでノイズを付与します。
(iii) では fMRI 信号から潜在テキスト表現 c をでコードし、それを condition として画像生成を行います。最後にデノイズされた Z_c を AE (VAEとは明記してない)に通すことことで画像生成しています。
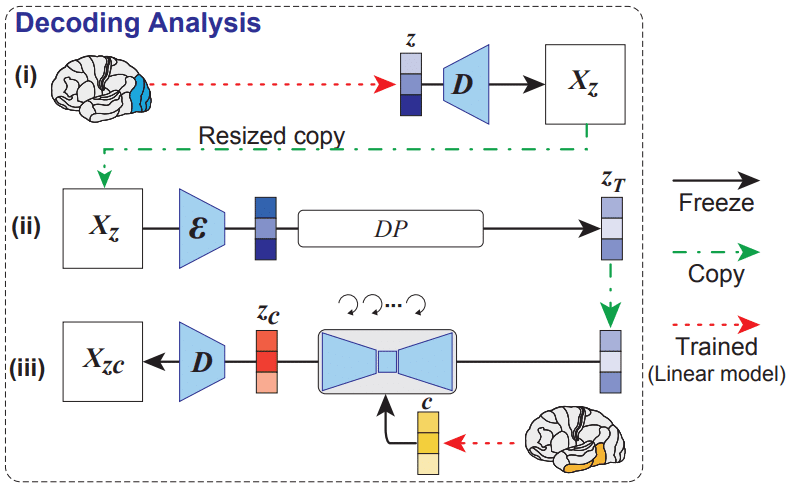
この操作を持て分かる通り、学習するのは赤矢印の部分であり、 fMRI 信号を LDM で使用される要素に線形モデルを使って変換している操作です。
定性評価
これによってこのような画像が生成されました。

縦にそれぞれ (左から)
入力画像(正解) X
画像 X の潜在表現 z のみを用いて再構成
condition c
c を条件にデノイズされた Z_c
を用いています。z のみを使用して再構成された画像 (2) は、元の画像と視覚的に一致していましたが、意味内容を捉えることができませんでした。一方、c 生成画像のみを使用して再構成された画像 (3) は、セマンティック忠実度が高いが視覚的に一貫性がありませんでした。最後に、Z_c を使用して再構成された画像 (4) は、意味的に忠実度が高い高解像度の画像を生成できます。(うーん、確かに前と比べるとよくなってはいるが…)
定量評価

異なる 4 人の被験者間でデータを取った結果 (?) 、客観的評価ではZ_c を使用して再構成された画像は、一般に、z または c のみを使用して再構成された画像よりも、さまざまな測定基準でより高い精度値となりました。z のみを使用した場合、CLIP および CNN の初期層で精度値が特に高くなりました。一方、c のみを使用した場合、CLIP および CNN の後ほうのレイヤーで精度値が高くなりました。
複数の人間による主観評価(人間の美的な価値化や感情などに強く依存 )は z < c < Z_c で精度が高くなりました。まあ定性評価を見てもこれは妥当ですね。
エンコード
今度は逆に LDM の要素を脳活動に機械学習を通じてマッピングすることで、LDM の潜在空間での動作を解釈します。これは以下のようなモデルで実装されています。

今回は 画像 X の潜在表現 z 、条件 (condition) c とそれによってデノイズされた Z_c を元に fMRI 画像を予測します。
(ii) : LDM の画像 X の潜在表現 z からデノイズされた Z_c の全体の過程を元に fMRI 画像を予測します。
(iii) : もう少し細かく見ていきます。LDM のデノイズ過程の各々のデノイズ後の画像 z_c を用いて、fMRI 画像を予測します。
(iv) : さらに細かく見ていきます。デノイズ過程で用いられる U-Net の潜在表現のレイヤーを元に、fMRI 画像を予測します。
定性評価
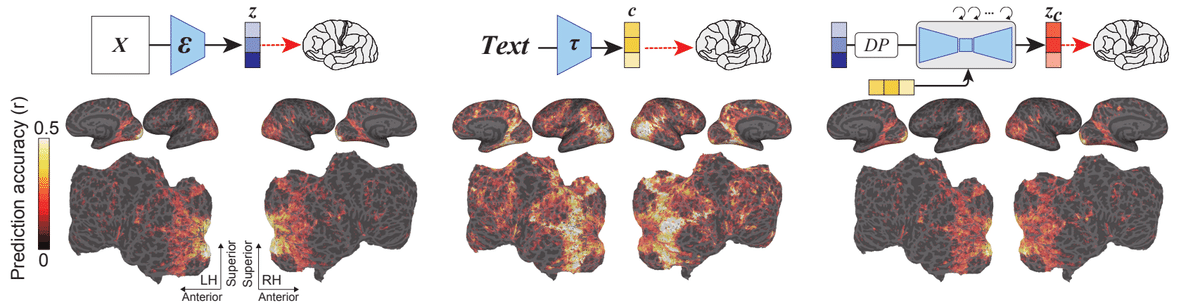
3つの要素はどれも後頭部に値が(ヒートマップが濃い)がついていることがわかります。実際に脳の後頭部は視覚野となっています。
z (左)は視覚野の後部(つまり初期視覚野)で高い値(ヒートマップが濃い)になりましたが前頭部ではヒートマップが薄くなっています。それに対し、 c (中央)は広い範囲にわたって高い値になりました。
Z_c は z に入力とし、c によってノイズ レベルが低減されています。また z と Z_c はよく似た表現を持つと予想されます。予想どおり Z_c では、z から得られるマップにと類似した予測マップが生成されることがわかりました。
それでは詳しく見ていきます。
エンコード の (ii) の結果

このようにノイズレベル (im2im の strengthのようなもの)を上げることで、ヒートマップの赤の色が濃くなっていきます。これは画像の意味内容が強くなっているということがわかります。後頭部が視覚野であり、ヒートマップの青い部分が多いことがわかります。対して赤い部分が濃くなってるのは視覚や以外の部分であり、これは ノイズレベルが高くなって時に濃くなっています。つまりノイズレベルが上がっていくにつれて脳はそれを画像ではなく、意味的(セマンティック)に解釈しているということです。
例を見てみましょう。画像を見ると、ノイズレベルが低い時はオリジナル画像と大きく変わりません、対してノイズレベルが高い時はオリジナル画像と異なる画像が生成されます。これから分かるのは、私たちは似たような画像同士は「画像→画像」として認識しているのに対して、同じ「キリン」の画像でも異なるものは私たちの脳の中で「画像→キリン→画像」として、一回、意味的に変換しているということがわかります。
エンコード の (iii) の結果

ノイズ除去の過程を fMRI 画像にマッピングしたときの結果です。ノイズが取られるにつれて赤い部分が増えていきます。これはc の要素が強まっていることを意味します。つまり Z_c は z に c を付けた画像であり、これは意味が強まっていくにつれてその意味をだんだん認識していくような感じです。 図を見ると Diffusion Model でもノイズが除去される過程でどんどん「猫」ということが明らかになっています。そのため、最初は認識ができなかった画像に対して、意味(=c を元にしたノイズ除去) をだんだん加えることで、「猫」であることがはっきりしてくるということが結果からわかります。
エンコード の (iv) の結果

U-Net の様々な過程の様子を fMRI 画像にマッピングした様子です。
ノイズ除去が進むにつれて、U-Net レイヤー間の機能的分離が視覚皮質内に現れます。つまり、最初のレイヤーは初期の視覚領域で細かいスケールの詳細を表す傾向がありますが、ボトルネックレイヤーはセマンティック領域(意味的な)の高次情報に対応します。
これは画像情報を畳み込むと、その画像の意味的な情報が残り、これがU-Net のボトルネック (オレンジ) です。対して、浅い層(青)では最初のテクスチャ情報(詳細情報)をつかさどっているということもわかります。
画像と対応付けてみましょう。デノイズが 20% の時には「何かある」程度の意味的な情報が多くあり、だんだんデノイズされるにつれて、それが資格情報に変わっていくということがわかります。
主の考察
以上の結果より、LDM のデノイズ過程は私たちの脳の神経活性化度合いと対応付けができ、それは直感的にも納得できるという結果に至りました。結局 LDM も人間も一度「意味的」な何かに押し込んで画像を理解していると言えるのではないでしょうか?今回は デノイズ過程の画像を線形 NN によって fMRI 画像に変換しています。これは意図的な変換であるにも関わらず、結果で見たように、何かしらの対応付けが説明できるというのは非常に興味深いのではないでしょうか?私たちの脳と LDM が似たような動きをしているとわかったとすると、 擬似的に脳を模倣したことにもなり、逆に脳の からの情報 (fMRI 画像など)を元に画像を再構成することができることも近いのかもしれません。
参考文献
最後に
最後まで読んでいただきありがとうございました。実はこの論文、最初読んだ時に、「こんなのただfMRI 2 Image を LDM 使ってやっただけじゃん」(失礼)と思っていました(ごめんなさい…)。しかし、読み返して、特に結果を読んでこの論文の興味深さに気づかされました。改めて、とても面白く、深い話が効けて良かったと思っています。
次回予告と宣伝
次回はまた画像生成の話をしようと思います。最近 LLM にうつつを抜かしているので(笑)。
最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)
↓↓もしよろしければこの記事と開発の支援お願いいたします!