
AI を自分好みに調整できる、追加学習まとめ ( その6: Instruct Pix2Pix )

こんにちはこんばんは、teftef です。今回は画像に対して text を用いて操作内容を指示し、元画像と大きく離れることなく指定した内容を編集する手法、Instruct Pix2Pix です。
私もまだ初学者であり、説明が間違っていたり勘違いがある可能性が 0 ではないということをご了承ください。ぜひコメントなどをいただけたら幸いです。
それでは行きます。
使用した論文
今回、使用した論文はこちら
画像編集
画像編集というのは、深層学習 (Deep Learning )に基づいたて画像の属性(髪の毛や年齢、肌の色など)、セグメンテーション、物体の除去などを操作する手法ということは確か前にも書きました。そして生成モデルにおいて、画像の固有性を保持しつつ指定した部分のみを編集することは難しいということも、追加学習編で書いた Imagic の記事で書きました。今回はこの画像編集について Imagic とは異なる手法となっています。
Pix2Pix
Pix2Pixは、Generative Adversarial Network(GAN)を活用した画像変換モデルです。入力画像から対応する出力画像を生成することができます。例えば、グレースケールの画像からカラー画像を生成することや、線画からカラー画像の生成、セグメンテーションマスクから完全な画像を生成することなどができます。このモデルは、ピクセルレベルの画像変換タスクに特に優れています。Pix2Pix は教師あり学習であり、入力画像とそれに対応する出力画像のペアがデータセットに用いられます。

Instruct Pix2Pix
今回はこの Pix2Pix にあたるものを Diffusion Model を使用してやろうという手法です。入力画像に対して、元画像の固有性を失わずかつ人間が入力した text に沿った画像編集をさせるというのが目的になっています。
学習
Pix2Pix は学習にペアのデータセットが必要なため、まずはこれらのペアを作成するところから始まります。今回は線画や白黒画像を必要としないのですが、「入力画像」と「編集を指定した text 」と「出力画像 」というペアデータセットが必要となります。
しかしそのようなモデルを 0 から学習することは膨大な資源と時間を浪費することになるので、既存のモデルをうまく生かした手法を検討しています。大規模自然言語モデル(GPT-3)とtext2image モデル(Stable Diffusion)は言語と画像に関する補完的な知識を有しており、これらを組み合わせることで、両モダリティにまたがるタスクのためのペア学習データを作成するアプローチを提案しています。
ステップ1 : instruction とキャプションの生成
まず文に対して、instruction (すなわち指示)を出した時にどのように文章が変化するかを学習させなければなりません。テキスト領域で処理を行うことで、画像の変更とテキストの指示の対応関係を保ちつつ、多様で大量の編集情報を生成することができます。そこで LAION データセットの画像のキャプション(説明) に instruction を付け、その結果を人力で書き出します。例えば

”photograph of a girl riding a horse" というキャプション (これは LAION データセットからとってきた) が存在し、それに対して “have her ride a dragon” という指示を与え、“photograph of a girl riding a dragon” というようなキャプションとなるようなデータセットを 700 個ほど用意します。人力で!
これらを使って GPT-3 モデルをファインチューニングし、入力されたキャプションから、instruction とそれに対応する(理にかなった)出力のキャプションを大量に生成できるようにします。
ステップ 2 : ペアキャプションからペア画像の作成
続いて text2image モデルを使用して前ステップで作成したペアのキャプション(入力画像のキャプションとinstruction に従って操作された後のキャプション) の画像を生成します。しかしここで問題なのは、画像生成をされている方ならお分かりだと思いますが、Prompt の少しの変化で出力画像が大幅に変わってしまうことです。これはモデルが学習データに依存することが原因なのですが、今回は固有性を失いたくないため非常に厄介になってしまいます。
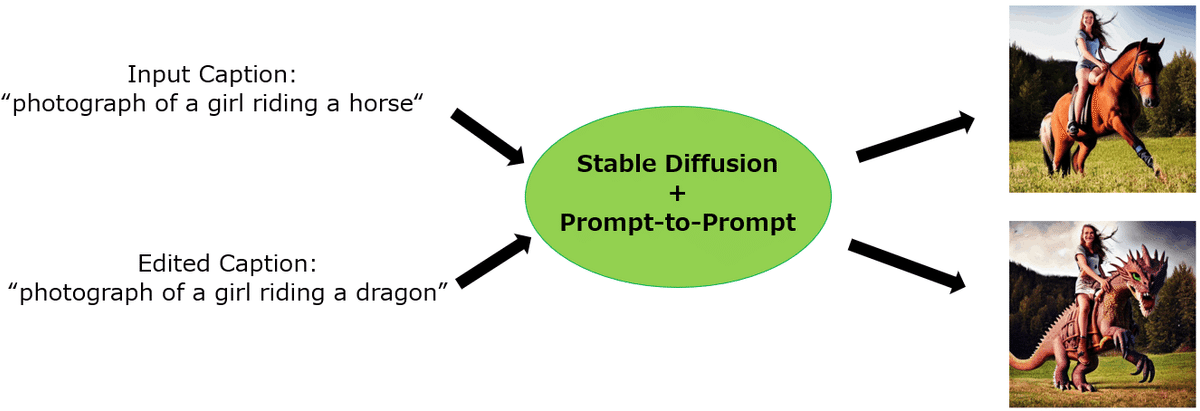
そのために Prompt-to-Prompt という Diffusion Model から出力する画像に類似性のあるような画像にする手法を使用します。今回は詳しくは説明しませんがノイズ除去において cross attention の重みをうまく制御してやることで、指定した部分のみの画像編集を可能にした手法となっています。(そもそも cross attention はそもそも画像のどの部分に注目するかをつかさどる部分なので…)
しかしこれだけでは不完全であり、場合によっては画像の固有性を大きく変わってほしいような場合もあります。例えば何か画像内のもの(object)を他のもの(object)に置き換えるときのような場合です。このような場合を制御するために、 Prompt-to-Prompt には画像間の類似度を制御するパラメーターが存在しています。しかしキャプションと instruction のみから最適なパラメーターの値を特定することは困難なため、キャプションペアごとに100組の画像サンプルをランダムなパラメーターで用意し、CLIP空間の方向性類似度(2つの画像キャプション間の変化との整合性を測定する指標、つまりどのくらい instruction に沿っているのかの指標) を使ってフィルタリングします。
これを行うことでLAION データセットにおける偏りやノイズを取り除くだけでなく、 Prompt-to-Prompt や Stable Diffusion で生成される失敗 (好ましくない、instruction 通りでない) 画像を省くことができ、よりロバストなモデルになります。

今回の結果は青い線で、
ちなみにこのフィルタリングを抜くと
(縦軸は、入力画像とどれだけ固有性を保っているか、横軸は instruction の忠実度の指標と考えてください。右上に行けば行くほどいい結果)
緑の線になり、 CLIP スコアが下がります。
そしてデータセットの数(大きさ)も大事で、データセットが少ないと質が下がってしまうこともわかっています。
ステップ 3 : Stable Diffusion の学習
これらの生成された画像とinstruction を用いて、Stable Diffusion モデルを instruct Pix2Pix モデルとして学習します。この時に0から学習するのではなく、既存の大規模モデル(Stable Diffusion など)を追加学習す方が優れた結果が出ています。そのため入力側の最初の畳み込み層に追加の入力チャンネルを追加します。Diffusion model の重みは学習済み Stable Diffusion の重みに初期化され、追加した入力チャンネルの重みは全て 0 に初期化します。そうです転移学習をします。
また text によるガイダンスとして、画像生成時にUnet に挿入される Prompt によるガイダンスではなく instruction によるガイダンスを用います。
ステップ4 : (おまけ)Classifier-free diffusion guidance
簡単に言うと cfg スケールをどう決めるか。
Classifier-free diffusion guidance を用いて生成される画像の品質(Prompt に寄っているか)と多様性はトレードオフの関係であり、それをコントロールするパラメーターがあります。今回はそれを制御することで、どれだけ Prompt (今回は instruction )に寄せるかを決めることができます。
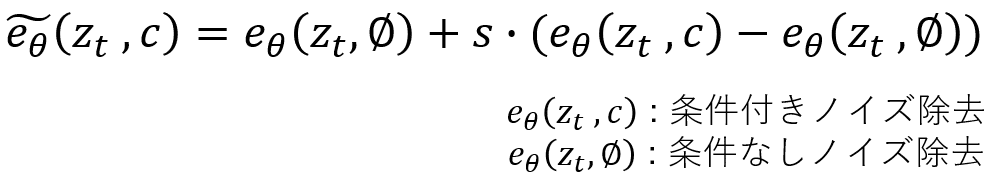
例えばこの式では s (cfg スケール)を指定することでノイズ除去の強さを指定できます。s が小さいと条件付きノイズ除去の影響が小さく、Prompt に過適応せず、条件なしノイズ除去のほうに寄ります。そのため、多様性が大きくなります。に対して、s が大きいと条件付きノイズ除去の影響が大きくなり、Prompt に沿った画像が出ますが多様性が失われます。(cfg スケールは7くらいにすると思います)

今回は応用して条件付けを入力画像 とinstruction の2つを調整できるようにしています。このような式を使って操作しています。今回のモデルは入力として、Input Image (画像) と instruction があります。そしてこれらの condition のどちらを強めるかを決めるために s_I と s_T があります。
s_I は元の Input Image (画像) とどれだけ一致させるか (大きいと一致度が高い)、
s_T はどれだけ instruction に沿った画像を生成するか (大きいと一致度が高い) の指標となっています。

結果
いろいろ試してみた
モナリザに instruction を付与させて、変更した結果。

ビートルズの 「Abbey Road」を instruction を使って変更


香港風→

宇宙→
既存手法との比較
(縦軸は、入力画像とどれだけ固有性を保っているか、横軸は instruction の忠実度の指標と考えてください。右上に行けば行くほどいい結果)
グラフを見ると 青線の instructPix2Pix が最も入力画像に忠実で、instruction に沿った画像編集であることがわかります。

定性的な結果だけみても、instructPix2Pix が最も入力画像に忠実で、instruction に沿った画像編集であることがわかります。

自分で試した結果
入力 : 東京タワー , instruction : "convert into effel tower"


入力 : ディカプリオ ,
① instruction : "turn into a blue T-shirt"
② instruction : "turn into a tie"



失敗例
視点変更のように過度な変更を加えることや、画像指定したオブジェクトを分離できないことや、オブジェクトの再編成や入れ替えが困難です。



偏り
これはデータセットに寄るので仕方がないのかなと思うのですが、医者→男性、キャビンアテンダント→女性のような偏りがあります。

日本人の顔はうまくいかない


Instruction Pix2Pix を"試す"
こちらの Space からお試しいただけます。
Colab でお試しする場合はこちら
Stable Diffusion WebUI の拡張機能
参考文献
次回予告と宣伝
今回は instruct Pix2Pix を論文をもとににまとめました。今回の手法は追加学習とはだいぶ離れているかもですが、一応追加学習というくくりに入れておきました。次回はまだ未定です…
公開されている様々なモデルを切り替え一つで変更できる Google Colab ノートブックも配布しています。
簡単に Stable Diffusion のモデルを試せる Google Colab の使い方ガイド|teftef @hanyingcl #note https://t.co/vqbpX7nEEu
— teftef (@hanyingcl) January 23, 2023
Colab で動かす Stable Diffusion の使い方です。GPUがなくても数多くのモデルを使って画像生成できます。#stablediffusionart #AI術師さんと繋がりたい #AIart
追加学習をやってみたい方はこちらの記事より
最後に
最後まで読んでいただきありがとうございました。最後に少し宣伝です。主のteftefが運営を行っているdiscordサーバーを載せます。このサーバーではMidjourneyやStble Diffusionのプロンプトを共有したり、研究したりしています。ぜひ参加して、お絵描きAIを探ってみてはいかがでしょう。(teftef)