コロナウイルスの日本の患者数を予測してみた

こんにちは。皆様いかがお過ごしでしょうか。私はですね、一日1種目100回ずつ筋トレをしております。日々です。様々な方法で一つの部位を鍛えるのもすごくいいと思うのですが、シンプルに数をこなす。これは想像してた以上にしんどいものでした。これをしばらく続けて、また、noteに結果を記していきたいと思います。
前置きは、これくらいにして、先日時間を持て余し過ぎていたので、有意義なことをやろうと、PyTorchの練習もかねてコロナウイルスの感染予測をudemyで、kazu takehanaさんのレッスンを参考にしてやりました。
ちなみにこちらになります。
PyTorch Boot Camp 2020 : Python AI PyTorchで機械学習とデータ分析完全攻略
予測結果
結果は、次のようになりました。
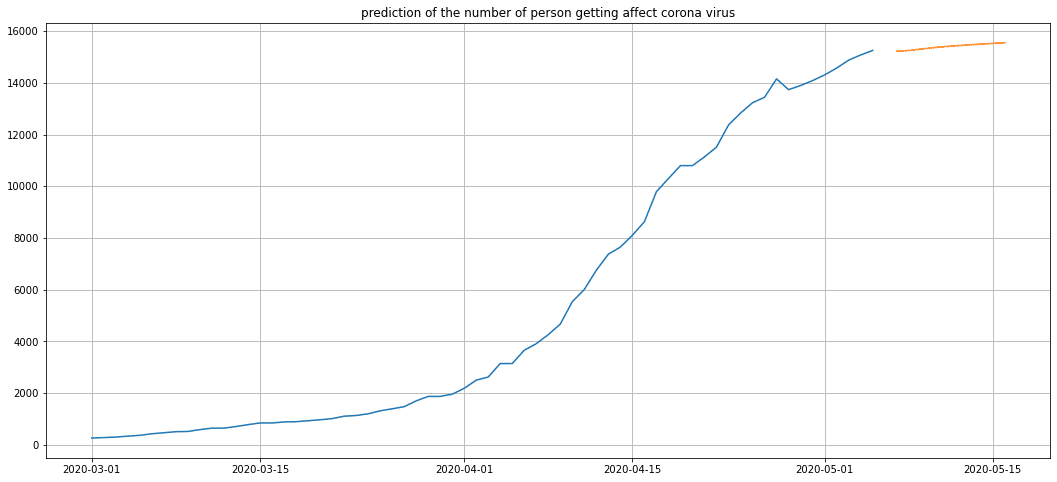
オレンジのとことが5/6から5/16までの予測をしてみました。結果によると、今後も増えていきそうですね。。。
ただ、勾配がさがってきていることから、収束方向に向かっていくとの予測をしています。この予測通り、コロナウイルスも収束していったら、いいですね。
それでは、次章以降で、技術的な部分とデータセットについてみていきたいと思います。
データ
データは、以下のサイトからgit cloneで引っ張てきました。自分なりにまとめたnoteがあるので、やり方が分からない方はそちらを参照してください。
git hubに飛びます
これを、pandasを用いて、データを出力してみました。

データの特徴から行ラベルが国(正確にはインデックスだけど、、、)
列には、緯度と経度、そして日付がありました。日付と国に対応して、その時の患者数が書かれているものとなっております。
ここで、正解ラベルは、患者数とするとして、機械学習を使うために何を特徴量にしようと考えました。シンプルにすべてのデータを活用して出力をしようかと考えましたが、それでは、時系列データの特徴が出すことができないと思い、特徴量を日付のみとして、RNNを用いることにしました。
※後日、自身の整理整頓のため、RNNやCNNについてnoteにまとめるかもしれません。期待はしないでください(笑)
前処理
前処理を行っていくのですが、データをよく見ると、最初の方の国名や緯度等はいらないため、データをdropしていきます。また、現在の急激な変化は最近の兆候ですので3月上旬ごろからのデータを参考にした方が、より正確な予測ができると考えました。そのため、3月1日以降のデータを取得するために、以下のように前処理を行いました。正確なデータなどで、あまり前処理には時間はかからないと思います。
df_japan = df.loc[df['Country/Region'] == 'Japan']
df_japan = df_japan.iloc[:,43:]
次に、日付をdatetime型にするために、次のように打ち込みました。
df_japan.index = pd.to_datetime(df_japan.index)df_japanをプロットしたものは次のようになります。これから、日本が急激に上がったのが緊急事態宣言発令時付近であることが分かりますね。もう少し早く宣言しとけば、ここまで増えなかったんじゃって心の中で思っていますが、つづいて予測の方をしていきたいと思います。

続いて、データを処理できるように、float型に形成しなおして、test_dataとtrain_dataに分けました。
y = df_japan.values.astype(float)
test_size = 3
train_original_data = y[:-test_size]
test_original_data = y[-test_size:]その上で、正規化してRNNなので、テストデータの作成もしなければなりません。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler(feature_range=(-1,1))
train_normalized = scaler.fit_transform(train_original_data.reshape(-1,1))
train_normalized = torch.FloatTensor(train_normalized).view(-1)
window_size = 3
def sequence_creator(input_data, window):
dataset = []
data_len = len(input_data)
for i in range(data_len - window):
window_fr = input_data[i:i+window]
label = input_data[i+window:i+window+1]
dataset.append((window_fr, label))
return dataset
train_data = sequence_creator(train_normalized, window_size)以上で、データ作成ができましたので、RNNのモデルをPyTorchを用いて作っていきたいと思います。
学習
よくある、モデルの作成と同じです。
class LSTM_Corona(nn.Module):
def __init__(self, in_size=1, h_size=30, out_size=1):
super().__init__()
self.h_size = h_size
self.lstm = nn.LSTM(in_size, h_size)
self.fc = nn.Linear(h_size, out_size)
self.hidden = (torch.zeros(1,1,h_size),torch.zeros(1,1,h_size))
def forward(self, sequence_data):
lstm_out, self.hidden = self.lstm(sequence_data.view(len(sequence_data),1,-1), self.hidden)
pred = self.fc(lstm_out.view(len(sequence_data), -1))
return pred[-1]簡単に説明すると、LSTMを作成する際に、input、hidden_layer, out_layerのサイズを設定する必要があるため、上記のように設定。また、LSTMを用いているため、hidden_layerは二つの隠れ層が存在するので、コードのように設定します。
※LSTMなどに関しては、おそらく後日noteに記載予定。
この後は、model, criterion, optimizer, seed, epoch数を設定し、学習させます。詳しくは、git hub を参照して下さい。
epochs = 100
for epoch in range(epochs):
for sequence_in, y_train in train_data:
y_pred = model(sequence_in)
loss = criterion(y_pred, y_train)
optimizer.zero_grad()
model.hidden = (torch.zeros(1,1,model.h_size),torch.zeros(1,1,model.h_size))
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1} Loss {loss.item(): .3f}')この後、testデータの部分に関して予測を行いプロットします。
test = 3
preds = train_normalized[-window_size:].tolist()
model.eval()
for i in range(test):
sequence = torch.FloatTensor(preds[-window_size:])
with torch.no_grad():
model.hidden = (torch.zeros(1,1,model.h_size), torch.zeros(1,1,model.h_size))
preds.append(model(sequence).item())この際、testデータを予測するときに毎回勾配を初期化する必要があるのでwith ~ で処理をしています。
その後は、スケーリングしたものを元の大きさに復元するために、次のように作り直した。
predictions = scaler.inverse_transform(np.array(preds[window_size:]).reshape(-1,1))トレーニングの結果は次のようになります。

予測
model.train()に変更して全データを学習させて、未来予測をしていきます。同様の内容などでコードはgit hubを参照していただきたいのですが、注意していただきたのですが、モデルはデータに依存してパラメータの数や初期値などは最適なものは変わってくるので、どんどん変えて試していってほしいです。
5/6からの予測結果は次のようになります。

予測してみて
ハイ、一気に収束してしまってますね(笑)。結果はおそらく惨敗な気がします。初期値をちゃんと置かなかったことも、特徴量が少なすぎたことも原因だと思います。今度RNNについてしっかり勉強したうえで、再度いつか再チャレンジしたいと思います。
ちなみに、コードは以下のgit hubを参考にしてください。
私のgit hub
この記事が参加している募集
この記事が気に入ったらサポートをしてみませんか?