
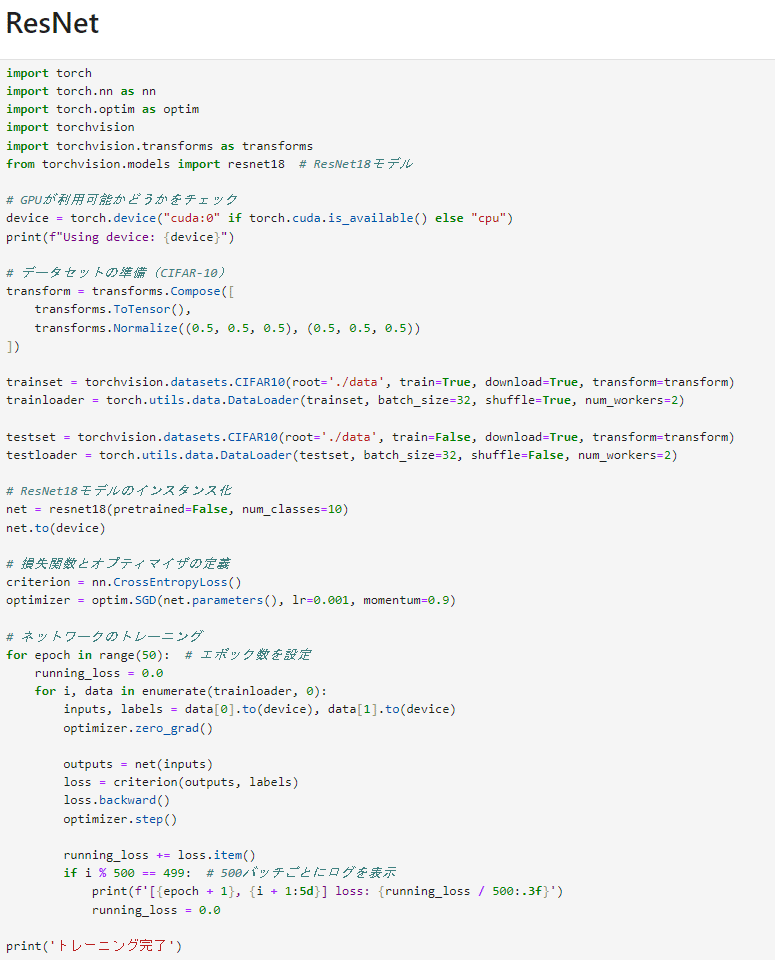
ResNet 以降のCNNを利用してみる

ResNet (2015)
開発者: マイクロソフト
特徴: Skip Connection(スキップ接続)を導入し、非常に深いネットワークの訓練を可能にしました。残差ブロックでは、畳込み層とSkip Connectionの組み合わせになっています。Residual Block(残差ブロック) を導入することで、結果的に層の深度の限界を押し上げることができ、精度向上を果たすことが出来ました。
重要性: 深層学習における勾配消失問題の解決に貢献し、多くの後続モデルに影響を与えました。
GPUの設定をすれば
python で簡単に使用することが可能です!
残差ブロックについて
畳み込み層の出力と残差ブロックへの入力は同じサイズと限らない
残差ブロックの出力は、畳み込み層側の出力と残差ブロックへの入力の差である
残差ブロックに含まれる畳み込み層は2層である

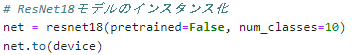

MobileNets (2017)
開発者: Google
特徴: Depthwise Convolution(チャネルごとの畳み込み)とPointwise Convolution(ピクセルごとのチャネル方向の圧縮)を使用し、軽量で効率的なモデルを実現しました。
重要性: モバイルデバイスやエッジデバイスでの使用に適した、効率的なネットワークアーキテクチャを提供しました。
通常の畳み込み層のパラメータθ数 (H×W×C)×M×K²
depthwise convolutionのパラメータθ数 (H×W×C)×K²
pointwise convolutionのパラメータθ数 (H×W×C)×M
MobileNet モデルは、これらの各項とその乗算的関係に対応することで計算コストを削減しています
具体的には、depthwise convolutions convolutionsを用いることで、出力チャネル数とカーネルサイズが乗算されることを解消する.
E資格合格に向けて 深層学習day4 (応用モデル) - Qiita
軽量モデルに新風を巻き起こした代表格!MobileNetV1 を詳細解説! | DeepSquare
Segmanticのように広い領域を参照する必要があるタスクの場合、単にフィルタサイズを大きくすると、パラメータ数が増加する.
そのため、少ないパラメータ数で広い領域を参照できる畳み込みはDilated convolutionである.
生成モデルのように小さな画像から大きな画像を生成する場合に使う畳み込みはtransposed convolutionである.
Wide ResNet (2017)
概要: Wide ResNetは、ResNetの畳み込み層のチャネル数を増やすことで、ネットワークの「幅」を広げたモデルです。
特徴: パラメータ数は増加しますが、層数が少ないため、学習時間が短縮されます。
WideResNet(Wide Residual Networks)は、深層学習の分野で使われるニューラルネットワークの一種です。このモデルは、ResNet(Residual Networks)のアイデアをベースにしていますが、ネットワークの「幅」(チャンネル数)を広げることに重点を置いています。
WideResNetの主な特徴
層の深さと幅のバランス: WideResNetは、ResNetの層(深さ)を減らしつつ、ブロック内の畳み込み層のチャンネル数(幅)を増やします。これにより、モデルの計算効率が向上し、より良い性能を発揮します。
ドロップアウトの導入: WideResNetでは、ブロック内にドロップアウト(ランダムにニューロンを無効化する手法)を導入することで、モデルの性能をさらに向上させます。
特徴再利用の問題への対応: ResNetでは、いくつかのブロックが最終的な結果にほとんど貢献しないという「特徴再利用の減少」という問題がありました。WideResNetは、幅を広げることでこの問題に対処し、より効率的に学習を進めることができます。
WideResNetの利点
計算効率の向上: 層を深くする代わりに幅を広げることで、計算効率が良くなります。
性能の向上: ドロップアウトの導入や幅の拡大により、モデルの性能が向上します。
表現力の向上: 幅を広げることで、モデルはより豊かな特徴を捉えることができます。
WideResNetの応用
WideResNetは、画像認識や物体検出など、様々なコンピュータビジョンのタスクに適用されています。特に、計算資源が限られている場合や、高い性能が求められるタスクにおいて、その効率性と精度が評価されています。
モデルパラメータの増加: Wide ResNetは、モデルの「幅」(すなわち、畳み込み層のフィルター数やチャンネル数)を増やすことによって、モデルの表現力を向上させます。これにより、深さ(層の数)を大幅に増やさずとも、複雑な特徴を捉える能力が高まります。
移転学習への適用性: Wide ResNetは移転学習にも適しています。do_fine_tuning = Falseという設定は、モデルを新しいタスクに適用する際に、事前学習した重みを固定(ファインチューニングを行わない)という意味で使用されることがあります。ただし、実際にはタスクやデータに応じてファインチューニングを行うかどうかを選択します。
残差ブロックの動作原理
残差ブロックでは、入力データが2つの経路を通ります。1つは、複数の畳み込み層を含むメインの経路で、もう1つはショートカット経路(スキップ接続)です。メイン経路での畳み込み層を通過した後の出力(変換された特徴)と、ショートカット経路の入力(元の特徴)を足し合わせることで、最終的な出力が得られます。
サイズの一致の重要性
足し合わせの操作: 入力と出力を足し合わせるためには、それらのサイズが完全に一致している必要があります。サイズが異なると、直接的な足し算が不可能になります。
情報の保持: ショートカット経路は入力データをそのまま次の層へと伝えるため、畳み込み層を通じて得られた特徴と元の入力データを効果的に組み合わせることができます。これにより、深いネットワークにおける情報の損失や勾配消失を防ぎます。
畳み込み層のカーネルサイズ: 残差ブロック内の畳み込み層では、カーネルサイズとして3x3が一貫して使用されます。これは、計算効率と性能のバランスを考慮した結果です。
残差ブロックの構造: 残差ブロックには通常、2層の畳み込み層が含まれます。これらの層は、入力データに対して畳み込みを行い、その結果が最終的な出力に加算される前に、元の入力と結合されます。
出力の計算: 残差ブロックの出力は、畳み込み層側の出力と残差ブロックへの入力の「和」であり、差ではありません。ここでの重要な点は、畳み込み層を通過した特徴マップと、直接伝播される入力が結合されることにより、情報の損失を防ぎつつ深いネットワークの学習が促進されるということです。
上記はあくまでも私見なので 訂正ありましたらコメントください
WideResnet の論文
https://arxiv.org/pdf/1605.07146.pdf
この論文は、画像認識タスクにおけるディープラーニング、特に深層ニューラルネットワーク(DNN)の進化とその課題、そしてそれを解決するためのアプローチについて述べています。まず、AlexNet、VGG、Inception、そしてResidual Networks(残差ネットワーク)といったモデルが、画像認識タスクで徐々に改善されていく過程を紹介しています。深いネットワークが多くの課題で優れた性能を発揮することが分かっていますが、それらを訓練することは難しく、勾配の消失や爆発、そしてモデルの劣化といった問題があります。
主な課題と解決策
勾配の消失/爆発: ネットワークが深くなると、学習が難しくなる。
劣化問題: ネットワークを深くすると性能が低下することがある。
解決策として、良い初期化方法、効果的なオプティマイザー、スキップ接続(ResNetにおける残差ブロック)、知識伝達、層ごとの訓練が提案されています。
残差ネットワーク(ResNet)
ResNetは、ImageNetやCOCO2015コンペティションで優勝し、多くのベンチマークで最先端の性能を達成しました。ResNetは、畳み込み層の出力に入力を加えることで「残差」を学習します。これにより、深いネットワークでも効率的に学習できるようになります。
Wide ResNetの提案
この論文では、ResNetの「幅」(層のチャネル数やフィルター数)を増やすことで、深さ(層の数)を増やすよりも効果的に性能を向上させる「Wide ResNet」が提案されています。つまり、モデルをより「広く」することで、より少ない層で同等またはそれ以上の性能を達成できるという考え方です。
Wide ResNetの利点
層を深くするよりも訓練が速い。
同じ精度を達成するために必要な層の数が格段に少ない。
モデルの「幅」を増やすことで、性能が向上する。
実験では、Wide ResNetが非常に深いネットワークに匹敵する精度を達成し、それでいて訓練時間が大幅に短縮され、層の数も大幅に少なくて済むことが示されました。例えば、16層のWide ResNetが1000層の通常のResNetと同じ精度を持ちながら、訓練速度が数倍速いという結果が出ました。
残差ネットワーク(ResNet)ブロック内でのドロップアウトの使用について述べています。ドロップアウトは、過学習を防ぎ、モデルの汎化性能を向上させるために使用されるテクニックです。もともとは、多数のパラメータを持つ上位層で特に使用され、特徴の共適応を防ぎ、過学習を抑制する効果がありました。しかし、バッチ正規化が導入されると、多くの場合、ドロップアウトはバッチ正規化に置き換えられました。バッチ正規化は、ネットワークのアクティベーションを特定の分布に正規化することで内部共変量シフトを減少させ、同時に正則化効果も持つことが示されています。
ドロップアウトの適用に関する新たな洞察
この論文では、残差ブロックの「幅」を広げることによってパラメータ数が増加するため、ドロップアウトを使用して訓練を正則化し、過学習を防ぐ効果を検討しています。以前の研究では、残差ブロックのアイデンティティパス(ショートカット接続)にドロップアウトを挿入すると、性能が低下するとされていました。しかし、この論文の著者たちは、ドロップアウトを畳み込み層の間に挿入することを提案しています。
実験により、畳み込み層の間にドロップアウトを挿入することで、Wide ResNetの性能が一貫して向上し、新たな最先端の結果が得られたことが示されました。例えば、16層のWide ResNetにドロップアウトを適用した場合、SVHNデータセットで1.64%の誤差率を達成しました。
主な貢献点
残差ネットワークアーキテクチャの詳細な実験的研究を提示し、ResNetブロック構造のいくつかの重要な側面を徹底的に検討しました。
パラメータ数の増加に対処するために、ResNetブロックを「拡大」する新しいアーキテクチャを提案し、残差ネットワークの性能を大幅に改善しました。
深い残差ネットワーク内でドロップアウトを適切に利用する新しい方法を提案し、訓練中の過学習を防ぎます。
提案したResNetアーキテクチャが、複数のデータセットで最先端の結果を達成し、残差ネットワークの精度と速度を大幅に向上させたことを示しました。
Wide Residual Networksとは?
Wide ResNetsは、画像認識タスクにおいて優れた性能を発揮する深層学習モデルの一種です。従来の残差ネットワーク(ResNet)を発展させたもので、モデルの「幅」(畳み込み層のチャンネル数)を増やすことで、より少ない層の深さでも高い表現力を得られるように設計されています。
残差ブロックとは?
残差ブロックは、ResNetsの基本単位です。これらのブロックは、ネットワークが深くなっても効率的に学習を進められるようにするために、入力を出力に直接加算する「ショートカット接続」を含んでいます。数式では次のように表されます:


Wide ResNetsの基本構造
ネットワークの幅は、kという因子によって決定されます。オリジナルのResNetアーキテクチャはk=1に相当します。
畳み込みグループ: ネットワークは複数の畳み込みグループで構成され、それぞれのグループにはN個の残差ブロックが含まれます。ダウンサンプリング(サイズを小さくする処理)は、3番目と4番目のグループの最初の層で行われます。
分類層: 最後の分類層は説明のために省略されています。
残差ブロックの種類
基本ブロック: 2つの連続する3×3畳み込み層から構成され、各畳み込みの前にバッチ正規化とReLU活性化関数が適用されます。
ボトルネックブロック: 1×1畳み込み層で次元を減らし、3×3畳み込み層で特徴を抽出し、再び1×1畳み込み層で次元を拡大します。これは計算コストを抑えつつ層を深くするために用いられますが、本研究ではモデルを「広げる」ことに焦点を当てるため、ボトルネックブロックは考慮されていません。
残差ブロック内の畳み込み層のタイプ
畳み込み層の構成を表すために、B(M)という表記を使用します。ここでMはブロック内の畳み込み層のカーネルサイズのリストです。例えば、B(3,1)は3x3の畳み込み層と1x1の畳み込み層を持つ残差ブロックを意味します。
提案された畳み込み層の構成は以下の通りです:
B(3,3): 伝統的な「基本」残差ブロック。2つの3x3畳み込み層を持ちます。
B(3,1,3): 1x1の畳み込み層を追加したバージョン。
B(1,3,1): 3x3の畳み込み層を1x1の畳み込み層で挟んだ構成。
B(1,3): 1x1と3x3の畳み込み層が交互に配置されたバージョン。
B(3,1): 3x3の後に1x1の畳み込み層が来る構成。
B(3,1,1): Network-in-Networkスタイルのブロック。
残差ブロックの深さ
深さの変化(l)と、その性能への影響も検討されます。異なる深さlとブロック数dを持つネットワークを比較する際には、全体のネットワークの複雑さが一定に保たれるように設計されています。
残差ブロックの幅
さらに、ブロックの幅(k)の変化による効果も評価されます。幅を広げることで、パラメータの数と計算の複雑さが増加しますが、GPUの並列計算の効率が高いため、広い層を持つ方が効率的に計算できる場合があります。
WRNの表記法
Wide ResNetsはWRN-n-kという表記法で表され、nは畳み込み層の総数、kは拡大因子を意味します。例えば、WRN-40-2は40層の畳み込みを持ち、オリジナルのResNetに比べて2倍の幅を持つネットワークです。
表現力を高める方法
畳み込み層の追加: ブロックごとに畳み込み層を増やす。
畳み込み層の幅を広げる: より多くの特徴プレーン(チャネル数)を追加する。
畳み込みフィルターのサイズ変更: しかし、3×3より大きなフィルターは効果が低いとされているため、この研究では採用されていません。
実験設計
幅の拡大: 幅を広げること(kを増やすこと)により、残差ブロック内の畳み込み層のチャネル数が増加します。これにより、ネットワークの表現力が向上し、性能が改善されることが期待されます。
ドロップアウトの使用: パラメータ数の増加に伴い、過学習のリスクも高まります。そのため、畳み込み層の間にドロップアウトを挿入することで、過学習を防ぐことを検討しています。
Dropoutの使用
この研究では、Wide ResNetsの各残差ブロック間にドロップアウトを挿入することで、過学習を防ぎ、モデルの汎化性能を向上させる方法を提案しています。ドロップアウトは、訓練中にランダムにネットワークの一部の接続を「ドロップ」(無視)することで、モデルがデータの特定の部分に過度に依存するのを防ぎます。研究では、畳み込み層間にドロップアウトを配置することが効果的であることが示されています。
SENet (2017)
概要: SENet(Squeeze-and-Excitation Networks)は、チャネル間の関係性を強調することで、ネットワークの表現力を向上させるアーキテクチャです。
SEブロック: 各チャネルのグローバルな情報を捉え、チャネルごとに重みを付けることで、重要な特徴を強調します。
効果: パラメータ数と計算量の削減を実現しつつ、ネットワークの精度を向上させます。
SENet(Squeeze-and-Excitation Networks)は、コンピュータビジョンの分野で使われる深層学習モデルの一種です。このモデルの特徴は、通常の畳み込みニューラルネットワーク(CNN)に「SEブロック」と呼ばれる特別な構造を組み込むことにあります。SEブロックは、ネットワークが画像のどの部分に注目すべきかを学習し、モデルの精度を向上させる役割を果たします。
SENetの構造とプロセス
Input Blockの処理: 入力された画像データ(Input Block)を処理します。この際、各チャンネル(画像の色成分など)を単一の数値に絞り込みます。これは、画像全体の平均値を取ることで、各チャンネルの「グローバルな情報」を捉えるためです。
Encodeの過程: 次に、得られた情報を「エンコード」します。これは、モデルの複雑さを抑え、一般化を図るためのステップです。
DecodeとSigmoid関数の適用: エンコードされた情報を「デコード」し、元のチャンネル数に復元します。この際、Sigmoid関数を使用して、0から1の範囲に値を制限します。Sigmoid関数は、チャンネル間の相関を捉えるための「ゲート機能」として機能します。これにより、モデルは複数のチャンネルに重みを付けることができます。
重み付けされたInput Blockの生成: 最後に、計算された重みを元のInput Blockに適用します。これにより、Input Blockの各チャンネルが重み付けされ、モデルの注目点が調整されます。
SENetの利点
精度の向上: SENetは、画像の重要な特徴に焦点を当てることで、画像認識タスクの精度を向上させます。
軽量化: SENetは、パラメータ数と計算量の削減を目指しており、より多くの層を重ねることが可能になります。これにより、モデルの表現力が向上します。
SENetは、画像認識タスクにおいて高い性能を発揮するため、多くの研究や実用的なアプリケーションで採用されています。
DenseNet (2017)
①DenseBlock
DenseNetでは前にある全てのノードに対して
Skip Connection(スキップ接続)を行います
DenseNetのSkip Connection(スキップ接続)では
ResNetの入力と出力を加算するのではなく
連結するため、チャンネル数が変わります
(ResNetでは画像の要素同士を加算するため、チャンネル数は増えない)
②Transition Layer
Dense Blockの間にプーリング層を挿入して画像サイズを変更します
DenseNet とは,サブブロック間の各層を密に全てSkip Connection(スキップ接続)した「Denseブロック」を主要部品に用いる,画像認識向け用CNNのバックボーン設計である [Huang et al., 2017]
DenseNetはResNet [He et al., 2016a] の正当進化版である
ResNetの「残差接続で直列CNNを構築」という路線はそのままに,「残差接続を極端に増やす」という簡単なアイデアだけで,効率でコンパクトでありつつ,大規模な多層CNNモデルへ発展させることができました
DenseNetは,CVPR2017のベストペーパーを受賞した研究です
DenseNet著者が主張した
「ResNetに対するDenseNetの利点(比較)」についてですが
「直列型CNNにおける,スキップ接続を用いたブロック構造の発展 (VGGNet→ResNet→DenseNetの3段活用)」
となります
MobileNet-v2 (2018)
概要: MobileNet-v2は、Inverted Residual Blockを導入し、効率的なモデル構造を実現しました。
Inverted Residual: 伝統的なResidual Blockとは異なり、入力が狭く、中間が広く、出力が狭い構造を持ちます。
効果: パラメータ数の削減と効率的な計算を実現します。
MobileNet-v2の概要と特徴
MobileNet-v2は、2018年に登場した軽量で高効率なニューラルネットワークアーキテクチャです。このモデルは、特にモバイルデバイスやエッジデバイスでの使用を目的としており、計算資源が限られている環境でも高い性能を発揮します。
Inverted Residual Blockの導入
MobileNet-v2の最大の特徴は、新しい「Inverted Residual Block」の導入です。これは、ResNetで使われる従来のResidual Block(Bottleneck構造)を逆転させたもので、以下のような構造を持っています。
従来のResidual Block: 広い(入力) -> 狭い -> 広い
Inverted Residual Block: 狭い(入力) -> 広い -> 狭い
この構造により、パラメータ数が少なくなり、計算効率が向上します。
Depthwise Separable Convolutionの改良
MobileNet-v2では、Depthwise Separable Convolutionを改良し、Pointwise Convolutionの計算量を減らしています。具体的には、3x3のDepthwise Convolutionを1x1のConvolution(Pointwise Convolution)で挟む構造を採用しています。
拡張率によるチャネル数の調整
Inverted Residual Blockでは、拡張率に従って入力データのチャネル数を一時的に増やします。これにより、情報量を十分に抽出しつつ、計算量を抑えることが可能になります。



MobileNet-v3 (2019)
概要: MobileNet-v3は、SEブロックとh-swish活性化関数を
組み合わせたモデルです。
特徴: チャネルごとの重み付けと効率的な活性化関数により、性能と効率のバランスを改善しました。
MobileNet-v3の概要と特徴
MobileNet-v3は、2019年5月に発表された最新のモデルで、MobileNetシリーズの最新版です。このモデルは、特にモバイルデバイスや組み込みシステム向けに設計されており、効率的な計算と高い精度を両立しています。主な特徴は以下の通りです。
1. BottleneckへのSqueeze-and-Excitationモジュールの導入
MobileNet-v3では、Inverted Residual Block内にSqueeze-and-Excitationモジュールを導入しています。このモジュールは、SENetで初めて登場し、各チャネルの重要度を学習することで、ネットワークの表現力を高めます。
Squeeze-and-Excitationモジュールの仕組み
Squeeze: Global Average Pooling (GAP)を使用して、各チャネルの代表値を抽出します。
Excitation: 全結合層を通して各チャネルの重みを計算し、元の入力データにこれらの重みを掛け合わせます。
このプロセスにより、チャネルごとの自己注意(Self-Attention)が可能になり、ネットワークの性能が向上します。
2. h-swishの使用
MobileNet-v3では、活性化関数としてh-swishを採用しています。これはReLUの代わりに使用され、モデルの効率と性能をさらに向上させます。
h-swish: モデルの一部でReLUに代わって使用される活性化関数です。ネットワークの非線形性を高め、より良い学習結果をもたらします。
NAS (Neural Architecture Search)
概要: NASは、ニューラルネットワークのアーキテクチャを自動的に最適化する手法です。
応用: CNNやRNNの構造を最適化し、特定のタスクに対する最良のモデルを探索します
CNNアーキテクチャの重要性
CNN(Convolutional Neural Network)は、AIの分野で大きな成功を収めていますが、そのアーキテクチャの設計は容易ではありません。CNNのアーキテクチャは性能に大きく影響するため、適切なアーキテクチャを見つけるには豊富なドメイン知識と計算資源が必要です。
Neural Architecture Search (NAS)
NASは、ドメイン知識を必要とせずにニューラルネットワークのアーキテクチャを探索する手法です。近年、この分野で多くの研究が行われていますが、NASは非常に多くの計算資源を要することが問題となっています。
計算資源の節約
この論文では、計算資源を節約するために、CNNの構造を「ブロック」という単位でまとめてアーキテクチャを探索しています。また、従来のNAS手法が用いる強化学習に代わり、計算資源を節約するために独自の工夫を施した遺伝的アルゴリズムを使用しています。
実験と比較
提案手法で探索したモデル、人間が手で設計したモデル、他の自動探索アルゴリズムで探索されたモデルを比較しています。この比較では、誤り率だけでなく、モデルを探索するのにかかった計算資源やモデルのサイズ(パラメータ数)も考慮されています。
代表的なブロックの例
ResNet Block (RB)
ResNet Blockは、以下のような特徴を持つブロックです。
ResNetのアーキテクチャを基にしたブロック構造。
層を重ねることで深いネットワークを構築。
DenseNet Block (DB)
DenseNet Blockは、以下の特徴を持つブロックです。
DenseNetのアーキテクチャを基にしたブロック構造。
各層が直接的に接続されており、情報の伝達が効率的
NASNet
概要: NASNetは、CNNのアーキテクチャを最適化するためのNASの一種です。
特徴: 畳み込みやプーリング操作を含むCNNセルを最適化し、様々なタスクに適用可能です。
NASNetについて
概要
NASNetは、Neural Architecture Search(NAS)を用いてCNN(Convolutional Neural Network)のアーキテクチャを最適化する手法です。この手法は、特定のタスクに最適なネットワーク構造を自動的に見つけ出すことを目的としています。
特徴
最適化されたCNNセル: NASNetは、畳み込みやプーリングなどの操作を含む小さなネットワーク構造(セル)を最適化します。
汎用性: 最適化されたセルは、さまざまな画像認識タスクに適用可能です。
自動化されたアーキテクチャ探索: 人間の介入を最小限に抑え、効率的なネットワーク構造を自動で見つけ出します。
MNASNet
概要: MNASNetは、モバイル端末での推論速度を考慮したNASです。
効果: モバイル端末での効率的なモデルの実現と、高い性能を両立させています。
概要
MNASNetは、モバイル端末での使用を念頭に置いたNeural Architecture Search(NAS)の一種です。この手法は、モバイルデバイス上での推論速度を考慮しながら、効率的で高性能なCNNアーキテクチャを自動的に設計することを目的としています。
特徴
推論速度の最適化: MNASNetは、モバイル端末での推論速度を重視しています。これは、モバイルデバイスの限られた計算能力とバッテリー寿命に配慮した設計です。
高性能: 速度だけでなく、精度も重要視しています。MNASNetは、高い精度を維持しながらも、モバイル端末での効率的な動作を可能にします。
自動化されたアーキテクチャ探索: NASを用いて、最適なネットワーク構造を自動的に見つけ出します。これにより、手動での試行錯誤による設計プロセスを省略できます。
効果
MNASNetは、モバイル端末での実用性を考慮したモデル設計において、次のような効果をもたらします。
効率的なモデル: モバイル端末の限られたリソース内で高速に動作する効率的なモデルを提供します。
高い精度: 効率性を犠牲にすることなく、高い精度を維持するモデルを実現します。
汎用性: 様々なタスクやアプリケーションに適用可能な汎用的なモデルを提供します。
EfficientNet (2019)
概要: EfficientNetは、モデルの深さ、幅、入力画像のサイズをバランス良く調整し、効率的なモデルを実現しました。
特徴: 少ないパラメータで高い性能を達成し、モデル開発の効率を向上させています。
最強の画像認識モデルEfficientNetについて
概要
EfficientNetは、2019年5月にGoogle Brainから発表された画像認識モデルです。このモデルは、従来のモデルよりも少ないパラメータ数で高い精度を実現しており、多くのデータセットで最高の性能(State-of-The-Art、SoTA)を達成しています。
主な特徴
少ないパラメータ数: EfficientNetは、他のモデルと比べて非常に少ないパラメータ数で高い精度を達成しています。
モデルのスケーリング: モデルの「深さ」、「幅」、「解像度」の3つの要素をバランスよく調整しています。
複数のデータセットでの高性能: ImageNetを含む5つのデータセットで最高の性能を達成しています。
転移学習に最適: 他のタスクへの適用も容易で、転移学習にも適しています。
シンプルなモデル構造: 複雑な構造を持たず、効率的な設計がされています。
EfficientNetのアーキテクチャ
EfficientNetのモデル構造は、以下のような特徴を持っています。
ベースラインモデル: NAS(Neural Architecture Search)によって構築されたベースラインモデルを使用しています。
MBConv: Mobile Inverted BottleneckにSEモジュール(Squeeze-and-Excitationモジュール)を追加した構造を採用しています。これはMobileNet-v3にも使われています。
EfficientNetは、高い精度と効率的なパラメータ使用で注目されるモデルです。そのシンプルながら効果的なアーキテクチャにより、多くの画像認識タスクで優れた結果を示しています。



この記事が気に入ったらサポートをしてみませんか?