
PyTorchの基礎からCNNでの応用まで

PyTorchの基礎: ディープラーニングのための便利なツール
PyTorchは、ディープラーニングの研究と開発に広く使用されているオープンソースの機械学習ライブラリです。この記事では、PyTorchの基本的な概念と特徴について紹介します。
PyTorchとは?
PyTorchは、FacebookのAI研究チームによって開発された機械学習ライブラリで、Pythonで書かれています。PyTorchは、その柔軟性と直感的な使用感から、研究者や開発者に人気があります。
主な特徴
動的計算グラフ: PyTorchは動的計算グラフ(Dynamic Computation Graph)を採用しており、実行時にネットワークの構造を変更できます。
直感的なインターフェース: Pythonの標準的な機能とシームレスに統合されており、直感的に使用できます。
強力なGPUサポート: NVIDIAのCUDAをサポートしており、高速なテンソル演算とディープラーニングのトレーニングが可能です。
PyTorchの基本コンポーネント
テンソル
テンソルはPyTorchの基本的なデータ構造で、多次元配列や行列を表します。NumPyのndarrayに似ていますが、GPUを使用して高速に計算できる点が異なります。
自動微分
PyTorchのautogradモジュールは、ニューラルネットワークのトレーニング中に必要な勾配計算を自動化します。
ニューラルネットワークモジュール
torch.nnモジュールは、ニューラルネットワークを構築するためのさまざまな層や関数を提供します。
最適化アルゴリズム
torch.optimモジュールは、SGD、Adamなどの最適化アルゴリズムを提供し、モデルのパラメータを更新します。
PyTorchのインストール
PyTorchはpipやcondaを使用して簡単にインストールできます。公式ウェブサイト(pytorch.org)から、自分の環境に合ったインストールコマンドを取得できます。
インポートの実施
以下の内容は一例です
# torchは、深層学習のためのライブラリで、テンソル計算や自動微分機能を提供します。
import torch
# torch.nnは、ニューラルネットワークを構築するためのモジュールです。
import torch.nn as nn
# torch.nn.functionalは、torch.nnの関数版で、活性化関数や損失関数などを提供します。
import torch.nn.functional as F
# torch.optimは、最適化アルゴリズムを提供するモジュールです。
import torch.optim as optim
# lr_schedulerは、学習率を調整するためのツールです。
from torch.optim.lr_scheduler import StepLR
# torchvisionは、画像処理に特化したライブラリで、データセットや画像変換ツールを提供します。
from torchvision import datasetsfrom torchvision import transforms
# torch.utils.data.Datasetは、データセットを定義するための基本クラスです。
from torch.utils.data import DatasetPyTorchでDataLoaderからイテレータの作成
PyTorchを使用する際、データのロードと処理は非常に重要な部分です。DataLoaderは、データセットからデータを効率的にロードし、イテレータを通じてデータを扱うための便利な方法を提供します。ここでは、DataLoaderからイテレータを作成する基本的なプロセスを説明します。
DataLoaderとは?
PyTorchのDataLoaderは、データセットからデータをバッチ単位でロードするためのクラスです。これにより、データセットを小さなバッチに分割し、各バッチを順番に処理することができます。
イテレータとは?
イテレータは、コレクション(例えばリストやタプル)内の要素を一つずつ取り出すオブジェクトです。PyTorchのDataLoaderから作成されるイテレータは、データセット内のデータをバッチ単位で取り出すことを可能にします。
DataLoaderからイテレータを作成する
ステップ1: DataLoaderのインスタンス化
まず、DataLoaderクラスのインスタンスを作成します。これには、データセットとバッチサイズなどのパラメータを指定します。
from torch.utils.data import DataLoader
# 仮のデータセットとバッチサイズを指定
data_loader = DataLoader(dataset, batch_size=4, shuffle=True)ステップ2: イテレータの作成
DataLoaderオブジェクトからイテレータを作成します。これにより、データセット内のデータをバッチ単位で取り出すことができます。
# DataLoaderからイテレータを作成
data_iterator = iter(data_loader)ステップ3: データの取り出し
イテレータを使用して、データセットからデータをバッチ単位で取り出します。
# データを一つのバッチ取り出す
batch = next(data_iterator)PyTorchのDataLoaderを使用すると、データセットから効率的にデータをロードし、イテレータを通じてバッチ単位でデータを処理することができます。これは、ディープラーニングモデルのトレーニングや評価において非常に重要なプロセスです。
バッチ正規化を含むニューラルネットワークの基本
PyTorchは、ディープラーニングモデルを構築し訓練するための人気のあるライブラリです。ここでは、PyTorchを使用してバッチ正規化を含む基本的なニューラルネットワークを構築する方法を説明します。
ニューラルネットワークとは?
ニューラルネットワークは、脳のニューロンの動作を模倣したコンピューターモデルです。これは、データから複雑なパターンを学習するために使用されます。
バッチ正規化とは?
バッチ正規化は、ニューラルネットワークの各層で入力を正規化(標準化)する手法です。これにより、モデルの学習が安定し、高速に進むことが期待されます。
PyTorchによる実装
以下は、PyTorchを使用してバッチ正規化を含むニューラルネットワークを構築する例です。
import torch
import torch.nn as nn
import torch.nn.functional as F
class BatchNormNet(nn.Module):
def __init__(self):
super(BatchNormNet, self).__init__()
self.fc1 = nn.Linear(784, 256)
self.bn1 = nn.BatchNorm1d(256, track_running_stats=True)
self.fc2 = nn.Linear(256, 128)
self.bn2 = nn.BatchNorm1d(128, track_running_stats=True)
self.fc3 = nn.Linear(128, 10)
def forward(self, x):
x = F.relu(self.bn1(self.fc1(x)))
x = F.relu(self.bn2(self.fc2(x)))
x = self.fc3(x)
return x
model = BatchNormNet()
model.eval()
output = model(torch.randn(10, 784))
コードの説明
モジュールのインポート:
torch はPyTorchの基本モジュールです。
torch.nn はニューラルネットワークの構築に必要なクラスや関数が含まれています。
torch.nn.functional には、活性化関数などの関数が含まれています。
ネットワークの定義:
BatchNormNet クラスは、ニューラルネットワークの構造を定義します。
__init__ メソッドで、ネットワークの層(全結合層とバッチ正規化層)を定義します。
forward メソッドで、データがネットワークを通過する際の流れを定義します。
モデルのインスタンス化と評価:
model = BatchNormNet() でネットワークのインスタンスを作成します。
model.eval() でモデルを評価モードに設定します。
モデルのテスト:
torch.randn(10, 784) でランダムなデータを生成し、モデルに入力します。
10 はバッチサイズ(一度に処理するデータの数)、784 は各データの特徴の数です。
このコードは、PyTorchを使用してバッチ正規化を含む基本的なニューラルネットワークを構築し、ランダムなデータでモデルをテストする方法を示しています。
nn.Linearの理解と活用
PyTorchにおけるnn.Linearは、ニューラルネットワークの基本的な構成要素の一つで、全結合層(線形層)を表します。ここでは、nn.Linearとそれに関連するPyTorchの概念について、わかりやすく説明します。
nn.Linearの基本
機能: nn.Linearは、入力特徴から出力特徴への線形変換を行います。これは、入力データに重みを掛け、バイアスを加えることで行われます。
使用例: nn.Linear(in_features, out_features) ここで、in_featuresは層に入力される特徴の数、out_featuresは層から出力される特徴の数です。
重みとバイアス
重み: nn.Linearの重みは、各入力特徴に掛けられる係数です。これらはモデルの学習中に調整されます。
バイアス: バイアスは、出力に加えられる定数項です。これも学習中に調整されます。
活性化関数
nn.Linearの出力は通常、非線形活性化関数を通過します。これにより、モデルは非線形の関係を学習できるようになります。
例: torch.nn.functional.relu(ReLU関数)は、一般的な活性化関数の一つです。
ニューラルネットワークにおける役割
nn.Linear層は、ニューラルネットワークの中で、入力データの特徴を組み合わせ、変換する役割を果たします。
複数のnn.Linear層を組み合わせることで、より複雑なデータのパターンを学習することができます。
基本的な構造
nn.Linearは以下のように定義されます:
nn.Linear(in_features, out_features, bias=True)in_features: 層に入力される特徴(次元)の数。
out_features: 層から出力される特徴(次元)の数。
bias: バイアス項を使用するかどうか。デフォルトはTrueです。
例
import torch.nn as nn
# 10個の入力特徴を持ち、20個の出力特徴を生成する全結合層
linear_layer = nn.Linear(10, 20)この例では、10個の入力特徴を受け取り、20個の出力特徴を生成する全結合層を作成しています。
例2
import torch.nn as nn
# 3つの入力特徴と2つの出力特徴を持つ全結合層
linear_layer = nn.Linear(3, 2)
# 活性化関数を適用
output = torch.nn.functional.relu(linear_layer(input_data))この例では、3つの入力特徴を受け取り、2つの出力特徴を生成する全結合層が作成されています。その後、ReLU活性化関数が適用されます。
nn.Linearの役割
全結合層は、ニューラルネットワークにおいて非常に重要な役割を果たします。これらの層は、入力データの特徴を組み合わせ、変換することで、パターンや関係性を学習します。例えば、画像認識、テキスト処理、回帰分析など、さまざまなタスクにおいて重要です。
DataLoader、バッチ正規化(nn.BatchNorm1d)、および全結合層(nn.Linear)
PyTorchのDataLoader、バッチ正規化(nn.BatchNorm1d)、および全結合層(nn.Linear)は、ディープラーニングモデルの構築とトレーニングにおいて重要な役割を果たします。これらのコンポーネントは、データの処理とモデルのアーキテクチャにおいて互いに関連しています。
DataLoader
役割: DataLoaderは、データセットからデータを効率的にロードし、バッチ単位で処理するために使用されます。
バッチ処理: DataLoaderは、データセットを小さなバッチに分割し、各バッチを順番にモデルに供給します。これにより、大量のデータを一度に処理する代わりに、小さなグループで効率的に処理することができます。
nn.Linear
役割: nn.Linearは、全結合層を表し、入力特徴から出力特徴への線形変換を行います。
データ処理: DataLoaderから供給された各バッチは、nn.Linear層を通過し、重みとバイアスによって変換されます。
nn.BatchNorm1d
役割: nn.BatchNorm1dは、バッチ正規化層を表し、層の入力を正規化してネットワークの学習を安定化させます。
バッチ単位の正規化: バッチ正規化は、DataLoaderによって供給された各バッチに対して行われます。これにより、各バッチ内のデータの平均と分散が調整され、モデルの学習が効率化されます。
これらの繋がり
データのロードとバッチ処理: DataLoaderは、トレーニングデータセットからデータをバッチ単位でロードし、これをニューラルネットワークに供給します。
バッチ正規化の適用: 各バッチは、nn.BatchNorm1d層を通過し、正規化されます。これにより、モデルの各層への入力が安定し、過学習を防ぎ、学習プロセスが高速化されます。
全結合層による変換: 正規化されたデータは、nn.Linear層(全結合層)を通過し、重みとバイアスによって変換されます。これにより、データの特徴が組み合わされ、モデルの出力が生成されます。
このように、DataLoader、バッチ正規化、およびnn.Linearは、データのロード、処理、および変換のプロセスにおいて密接に連携しています。これらの要素は、ディープラーニングモデルの効果的なトレーニングとパフォーマンス向上に不可欠です。
ディープラーニングにおけるデータ拡張の重要性とPyTorchの活用法
ディープラーニングの分野では、データは非常に重要です。特に医療業界のような分野では、高品質なデータセットを大量に入手することは簡単ではありません。このような状況で、データ拡張は非常に有効な手段となります。
データ拡張とは?
データ拡張は、既存のデータセットから新しいトレーニングサンプルを生成するプロセスです。これにより、モデルの一般化能力が向上し、過学習を防ぐことができます。特に、オンラインデータ拡張は、トレーニングプロセス中にリアルタイムでデータ変換を適用することで、モデルの堅牢性を高めます。
オンラインデータ拡張の利点
多様性の向上: トレーニングデータの多様性が増し、モデルはより現実的なシナリオに対応できるようになります。
メモリ効率: ディスクに保存された大量のデータセットを必要とせず、メモリ使用量を削減します。
過学習の防止: 新しいデータのバリエーションを導入することで、モデルがトレーニングデータに過度に適合するのを防ぎます。
主要なデータ拡張技術
水平フリップ(Horizontal Flip)
垂直フリップ(Vertical Flip)
明度(Brightness)
彩度(Saturation)
色相(Hue)
これらの技術は、画像を水平方向に反転させたり、明るさを調整したりすることで、データセットの多様性を高めます。
PyTorchのtransformsモジュール
PyTorchのtransformsモジュールは、画像データに対する前処理や拡張を行うための強力なツールです。以下に、transformsを使用したデータ拡張の一例を紹介します。
def apply_transforms(image):
transform = transforms.Compose([ transforms.RandomResizedCrop(300),
transforms.RandomHorizontalFlip(),
transforms.RandomVerticalFlip(),
transforms.RandomRotation(30),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.2),
transforms.RandomGrayscale(p=0.2) ])
return transform(image)
この関数は、画像にランダムな変換を適用し、データセットの多様性を高めます。
PyTorchのtransformsモジュールは、データ拡張や前処理のための便利なツールです。これを利用することで、データセットの多様性を高め、モデルの一般化能力を向上させることができます。データ拡張は、特にデータセットが限られている場合や、より堅牢なモデルを構築したい場合に非常に有効です。
CNN(Convolutional Neural Network)
臨床にいた頃、眼科のOPにも入っていました
例えば硝子体が出血などで濁ると
視力に影響を及ぼすのは
網膜とニューロンが関係します
AIの世界ではCNNとつながる部分
CNNとは、「Convolutional Neural Network」
を略した言葉であり、日本語では
「畳み込みニューラルネットワーク」とも呼ばれています
いくつもの深い層を持ったニューラルネットワークであり
主に画像認識の分野において価値を生んでいるネットワーク
CNNは、神経科学の知見に基づく構造を持つ
生物の視覚野には、たくさんの神経細胞(ニューロン)があり
外界からの入力に対する反応の違いによって
単純型細胞 複雑型細胞の2種類がある
ニューロンに影響を与える網膜上の範囲のことを「受容野」といいます
画像はたくさんの情報を持っている
CNNを使うことで、画像の内容や形状といった
特徴(情報)を抽出することができる特徴があります
これらの情報は「特徴マップ」と表現され
深い層に進むほど具体的な特徴(例: 物体の部分や形状)を捉える
人と違うことろはファインチューニングやグリットサーチを
導入することで自動でいろんなパラメーターで
網膜に入る情報をニューロンで永遠に学習し続けることができます
他の技術もパズルのように組み合わせていくことが可能です

例えば データ拡張なども実施することが可能です
CNNの歴史と概要
LeNet (1998)
開発者: Yann LeCun
特徴: CNNの初期の形態で、手書き数字の認識に使用されました。
重要性: CNNの基礎を築き、後の発展に大きな影響を与えました。
AlexNet (2012)
開発者: トロント大学のGeoffrey Hintonら
特徴: 「ImageNet Large Scale Visual Recognition Challenge(ILSVRC) 2012」で優勝し、深層学習の可能性を広く知らしめました。
重要性: CNNとディープラーニングのブレイクスルーとなり、広範な研究と応用を促進しました。
VGGNet (2014)
開発者: オックスフォード大学
特徴: 畳み込み層とプーリング層を重ねたシンプルな構造が特徴です。
重要性: ネットワークの深さが性能に与える影響を示し、多くの研究で使用されました。
GoogleNet (2014)
開発者: Google
特徴: Inceptionモジュールを導入し、計算資源の効率的な使用を実現しました。
補助的損失: ネットワークの中間部に補助的な損失を導入し、勾配消失問題を緩和しました。
ResNet (2015)
開発者: マイクロソフト
特徴: Skip Connection(スキップ接続)を導入し、非常に深いネットワークの訓練を可能にしました。残差ブロックでは、畳込み層とSkip Connectionの組み合わせになっています。Residual Block(残差ブロック) を導入することで、結果的に層の深度の限界を押し上げることができ、精度向上を果たすことが出来ました。
重要性: 深層学習における勾配消失問題の解決に貢献し、多くの後続モデルに影響を与えました。
MobileNets (2017)
開発者: Google
特徴: Depthwise Convolution(チャネルごとの畳み込み)とPointwise Convolution(ピクセルごとのチャネル方向の圧縮)を使用し、軽量で効率的なモデルを実現しました。
重要性: モバイルデバイスやエッジデバイスでの使用に適した、効率的なネットワークアーキテクチャを提供しました。
SENet (2017)
概要: SENet(Squeeze-and-Excitation Networks)は、チャネル間の関係性を強調することで、ネットワークの表現力を向上させるアーキテクチャです。
SEブロック: 各チャネルのグローバルな情報を捉え、チャネルごとに重みを付けることで、重要な特徴を強調します。
効果: パラメータ数と計算量の削減を実現しつつ、ネットワークの精度を向上させます。
Wide ResNet (2017)
概要: Wide ResNetは、ResNetの畳み込み層のチャネル数を増やすことで、ネットワークの「幅」を広げたモデルです。
特徴: パラメータ数は増加しますが、層数が少ないため、学習時間が短縮されます。
MobileNet-v2 (2018)
概要: MobileNet-v2は、Inverted Residual Blockを導入し、効率的なモデル構造を実現しました。
Inverted Residual: 伝統的なResidual Blockとは異なり、入力が狭く、中間が広く、出力が狭い構造を持ちます。
効果: パラメータ数の削減と効率的な計算を実現します。
MobileNet-v3 (2019)
概要: MobileNet-v3は、SEブロックとh-swish活性化関数を組み合わせたモデルです。
特徴: チャネルごとの重み付けと効率的な活性化関数により、性能と効率のバランスを改善しました。
NAS (Neural Architecture Search)
概要: NASは、ニューラルネットワークのアーキテクチャを自動的に最適化する手法です。
応用: CNNやRNNの構造を最適化し、特定のタスクに対する最良のモデルを探索します。
NASNet
概要: NASNetは、CNNのアーキテクチャを最適化するためのNASの一種です。
特徴: 畳み込みやプーリング操作を含むCNNセルを最適化し、様々なタスクに適用可能です。
MNASNet
概要: MNASNetは、モバイル端末での推論速度を考慮したNASです。
効果: モバイル端末での効率的なモデルの実現と、高い性能を両立させています。
EfficientNet (2019)
概要: EfficientNetは、モデルの深さ、幅、入力画像のサイズをバランス良く調整し、効率的なモデルを実現しました。
特徴: 少ないパラメータで高い性能を達成し、モデル開発の効率を向上させています。
これらのモデルは、CNNの進化において重要な役割を果たし、ディープラーニングの分野での多様な応用を可能にしています。
上記はあくまでも概要ですので もう少し詳しい理解が必要です
例えば wideResNet について詳しく説明したいと思います
WideResNet (2017)について詳しく
WideResNetは、従来のResNet(Residual Networks)のアーキテクチャを改良したものです。ResNetは、深いニューラルネットワークにおける勾配消失問題を解決するために導入されましたが、非常に深いネットワークでは計算コストが高くなるという問題がありました。
WideResNetの特徴
チャネル方向の拡張: WideResNetは、Residual Block内の畳み込み層のチャネル数を増やすことで、ネットワークの「幅」を広げます。これにより、ネットワークはより多くの特徴を捉えることができ、表現力が向上します。
効率的な学習: WideResNetは、深さを極端に増やす代わりに幅を広げることで、計算効率を保ちながら性能を向上させます。
正規化の重要性: 幅を広げることでパラメータの数が増加するため、過学習を防ぐための強力な正規化手法が必要になります。
性能の改善
WideResNetは、通常のResNetよりも優れた表現を学習することができます。これは、ネットワークがより多くの特徴を捉える能力があるためです。
深さと幅のバランスを取ることで、モデルは効率的に学習し、高い性能を発揮します。
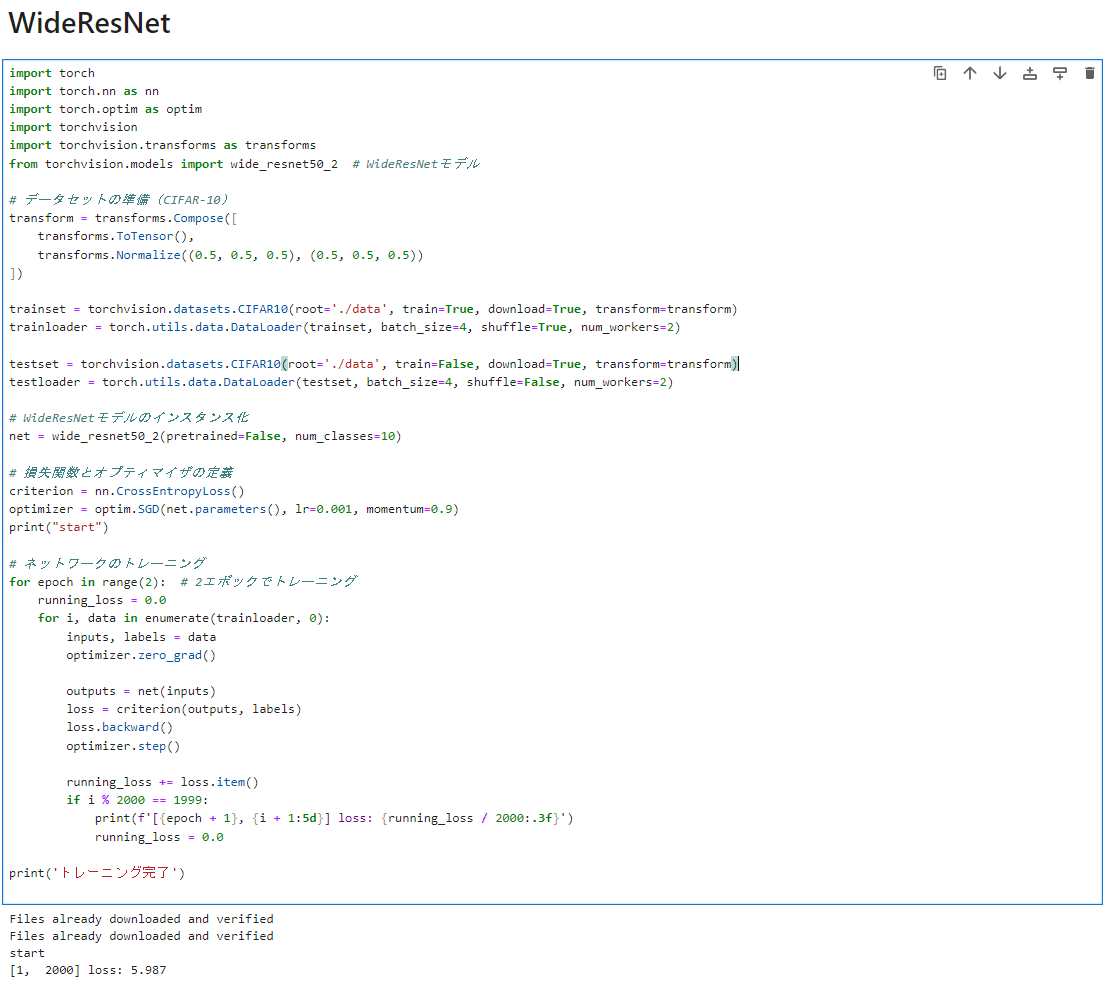
早速python で実施してみましょう
学習に時間がかかるため
結果は後日お伝えします
この記事が気に入ったらサポートをしてみませんか?